Bahasa Pemrograman Rust
oleh Steve Klabnik, Carol Nichols, dan Chris Krycho, beserta kontribusi dari Komunitas Rust
Versi teks ini mengasumsikan kita menggunakan Rust 1.90.0 (rilis 18-09-2025)
atau yang lebih baru dengan edition = "2024" di dalam file Cargo.toml pada
semua proyek untuk mengonfigurasi mereka agar menggunakan idiom Edisi Rust 2024.
Lihat bagian “Instalasi” di Bab 1 untuk instruksi
pemasangan atau pembaruan Rust, dan lihat Lampiran E
untuk informasi mengenai edisi.
Format HTML tersedia secara online di
https://doc.rust-lang.org/stable/book/
dan offline pada instalasi Rust yang dilakukan dengan rustup; jalankan
rustup doc --book untuk membukanya.
Beberapa terjemahan komunitas juga tersedia.
Teks ini tersedia dalam format cetak dan ebook dari No Starch Press.
🚨 Ingin pengalaman belajar yang lebih interaktif? Silakan coba versi yang berbeda dari Buku Rust, dengan fitur: kuis, sorotan, visualisasi, dan lainnya: https://rust-book.cs.brown.edu
Kata Pengantar
Bahasa pemrograman Rust sudah menempuh perjalanan panjang dalam beberapa tahun terakhir, mulai dari penciptaan dan inkubasinya oleh komunitas kecil penggemar pemula, hingga menjadi salah satu bahasa pemrograman yang paling dicintai dan banyak dicari di dunia. Menengok ke belakang, rasanya memang tidak terelakkan kalau kekuatan dan janji yang ditawarkan Rust bakal menarik perhatian banyak orang dan mendapatkan pijakan kuat di pemrograman sistem. Namun yang tidak terelakkan adalah pertumbuhan minat dan inovasi global yang merambah melalui komunitas sumber terbuka (open source) dan mengatalisasi adopsi skala luas di berbagai industri.
Saat ini, sangat mudah untuk menunjuk ke fitur-fitur luar biasa yang ditawarkan Rust guna menjelaskan ledakan minat dan adopsi ini. Siapa yang tidak menginginkan keamanan memori, sekaligus performa yang kencang, sekaligus compiler yang ramah, sekaligus peralatan yang hebat, di antara banyak fitur luar biasa lainnya? Bahasa Rust yang kita lihat sekarang menggabungkan penelitian selama bertahun-tahun dalam pemrograman sistem dengan kebijaksanaan praktis dari komunitas yang lincah dan bersemangat. Bahasa ini didesain dengan tujuan dan dibuat dengan cermat, menawarkan alat bagi para pengembang yang mempermudah penulisan kode yang aman, kencang, dan andal.
Namun, apa yang membuat Rust benar-benar istimewa adalah akarnya yang memberikan kuasa kepada kita, sang pengguna, untuk mencapai tujuan kita. Ini adalah bahasa yang ingin kita sukses, dan prinsip pemberian kuasa (empowerment) ini mengalir melalui inti dari komunitas yang membangun, memelihara, dan mengadvokasi bahasa ini. Sejak edisi sebelumnya dari teks definitif ini, Rust telah berkembang lebih jauh menjadi bahasa yang benar-benar global dan terpercaya. Proyek Rust kini didukung secara kuat oleh Rust Foundation, yang juga berinvestasi dalam inisiatif-inisiatif kunci untuk memastikan Rust aman, stabil, dan berkelanjutan.
Edisi The Rust Programming Language ini adalah pemutakhiran komprehensif, mencerminkan evolusi bahasa ini selama bertahun-tahun dan menyediakan informasi baru yang berharga. Namun, ini bukan sekadar panduan sintaks dan pustaka—ini adalah ajakan untuk bergabung dengan komunitas yang menghargai kualitas, performa, dan desain yang matang. Baik kita pengembang berpengalaman yang ingin menjelajahi Rust untuk pertama kalinya atau seorang Rustacean berpengalaman yang ingin mengasah keterampilan kita, edisi ini menawarkan sesuatu untuk semua orang.
Perjalanan Rust adalah perjalanan kolaborasi, pembelajaran, dan iterasi. Pertumbuhan bahasa dan ekosistemnya adalah cerminan langsung dari komunitas yang lincah dan beragam di belakangnya. Kontribusi dari ribuan pengembang, mulai dari desainer inti bahasa hingga kontributor kasual, adalah apa yang membuat Rust menjadi alat yang unik dan kuat. Dengan membaca buku ini, kita tidak sekadar mempelajari bahasa pemrograman baru—kita bergabung dengan sebuah gerakan untuk membuat perangkat lunak menjadi lebih baik, lebih aman, dan lebih menyenangkan untuk dikerjakan.
Selamat datang di komunitas Rust!
— Bec Rumbul, Executive Director of the Rust Foundation
Pengenalan
Catatan: Edisi buku ini sama dengan The Rust Programming Language yang tersedia dalam format cetak dan ebook dari No Starch Press.
Selamat datang di The Rust Programming Language, sebuah buku pengantar tentang Rust. Bahasa pemrograman Rust membantu kita menulis perangkat lunak yang lebih cepat dan andal. Ergonomi tingkat tinggi dan kontrol tingkat rendah sering kali dianggap berlawanan dalam desain bahasa pemrograman; Rust menantang konflik tersebut. Dengan menyeimbangkan kapasitas teknis yang kuat dan pengalaman pengembang yang menyenangkan, Rust memberi kita opsi untuk mengendalikan detail tingkat rendah (seperti penggunaan memori) tanpa semua kerumitan yang biasanya terkait dengan kontrol semacam itu.
Rust untuk Siapa
Rust sangat ideal untuk banyak orang karena berbagai alasan. Mari kita lihat beberapa kelompok yang paling penting.
Tim Pengembang
Rust terbukti menjadi alat yang produktif untuk berkolaborasi di antara tim pengembang yang besar dengan berbagai tingkat pemahaman tentang pemrograman sistem. Kode tingkat rendah rentan terhadap berbagai bug halus, yang di kebanyakan bahasa lain hanya bisa dideteksi setelah melalui pengujian ekstensif dan audit kode yang teliti oleh pengembang berpengalaman. Di Rust, compiler berperan sebagai penjaga gerbang dengan menolak memproses kode yang mengandung bug-bug sulit ini, termasuk bug konkurensi. Dengan bekerja berdampingan dengan compiler, tim bisa fokus menggunakan waktunya untuk logika program daripada sibuk mencari bug.
Rust juga membawa peralatan pengembang kontemporer ke dunia pemrograman sistem:
- Cargo, manajer dependensi dan alat build bawaan, membuat proses menambah, mengompilasi, dan mengelola dependensi menjadi mudah dan konsisten di seluruh ekosistem Rust.
- Alat pemformatan
rustfmtmemastikan gaya penulisan kode yang konsisten di antara para pengembang. - Rust Language Server mendukung integrasi Integrated Development Environment (IDE) untuk melengkapi kode (code completion) dan menampilkan pesan error secara langsung.
Dengan menggunakan ini dan alat lainnya di ekosistem Rust, pengembang dapat menjadi lebih produktif ketika menulis kode tingkat sistem.
Pelajar
Rust cocok untuk pelajar dan mereka yang tertarik dalam mempelajari konsep sistem. Melalui Rust, banyak orang yang belajar mengenai topik seperti pengembangan sistem operasi. Komunitas Rust sangat ramah dan senang menjawab pertanyaan dari para pelajar. Melalui upaya-upaya seperti buku ini, tim Rust ingin membuat konsep sistem dapat diakses oleh lebih banyak orang, terutama mereka yang masih baru dalam pemrograman.
Perusahaan
Ratusan perusahaan, besar maupun kecil, menggunakan Rust di lingkungan produksi untuk berbagai macam keperluan, termasuk alat baris perintah, layanan web, peralatan DevOps, perangkat embedded, analisis dan transkoding audio serta video, mata uang kripto, bioinformatika, mesin pencari, aplikasi Internet of Things, machine learning, dan bahkan bagian-bagian utama dari peramban web Firefox.
Pengembang Sumber Terbuka (Open Source)
Rust ditujukan bagi orang-orang yang ingin membangun bahasa pemrograman Rust, komunitas, peralatan pengembang, dan pustaka (libraries). Kami menunggu kontribusi kita pada bahasa Rust.
Mereka yang Mengutamakan Kecepatan dan Stabilitas
Rust ditujukan untuk orang-orang yang mendambakan kecepatan dan stabilitas dalam sebuah bahasa. Dengan kecepatan, maksudnya adalah seberapa cepat kode Rust bisa dijalankan dan seberapa cepat Rust memungkinkan kita menulis program. Pemeriksaan yang dilakukan oleh compiler Rust memastikan stabilitas bahkan ketika ada penambahan fitur atau refactoring. Ini berbeda dengan kode warisan (legacy code) yang rapuh pada bahasa tanpa pemeriksaan seperti ini, yang sering membuat pengembang takut untuk memodifikasinya. Dengan berupaya mencapai zero-cost abstractions—fitur tingkat tinggi yang dikompilasi menjadi kode tingkat rendah secepat kode yang ditulis manual—Rust berusaha agar kode yang aman juga bisa menjadi kode yang cepat.
Bahasa Rust juga berharap bisa mendukung banyak pengguna lainnya; yang disebutkan di sini hanyalah beberapa pemangku kepentingan terbesar. Secara keseluruhan, ambisi terbesar Rust adalah menghapus kompromi yang telah diterima para programmer selama puluhan tahun dengan menyediakan keamanan dan produktivitas, kecepatan dan ergonomi. Cobalah Rust dan lihat apakah pilihan- pilihannya cocok untuk kita.
Buku ini Ditujukan untuk Siapa
Buku ini mengasumsikan bahwa kita sudah pernah menulis kode dalam bahasa pemrograman lain, tetapi tidak mengasumsikan bahasa mana yang kita gunakan. Kami berusaha membuat materi ini dapat diakses secara luas oleh siapa pun dengan berbagai latar belakang pemrograman. Kami tidak banyak membahas tentang apa itu pemrograman atau bagaimana cara berpikir tentangnya. Jika kita benar-benar baru dalam pemrograman, akan lebih baik membaca buku yang secara khusus memberikan pengantar tentang pemrograman.
Bagaimana Cara Menggunakan Buku ini
Secara umum, buku ini mengasumsikan kita membacanya secara berurutan dari depan ke belakang. Bab selanjutnya mendasarkan konsepnya pada bab sebelumnya, dan bab- bab awal mungkin tidak akan menjelaskan secara detail mengenai topik tertentu tetapi akan mengulasnya kembali pada bab selanjutnya.
Kita akan menemukan dua jenis bab dalam buku ini: bab konsep dan bab proyek. Dalam bab konsep, kita akan mempelajari satu aspek dari Rust. Dalam bab proyek, kita akan membangun program kecil bersama-sama, menerapkan apa yang sudah kita pelajari sejauh ini. Bab 2, Bab 12, dan Bab 21 adalah bab proyek; sisanya adalah bab konsep.
Bab 1 menjelaskan bagaimana memasang Rust, bagaimana membuat program “Hello, world!”, dan bagaimana cara menggunakan Cargo, manajer paket dan alat build Rust. Bab 2 adalah pengenalan langsung dalam menulis program di Rust, di mana kita akan membuat permainan tebak-tebakan angka. Di sini, kita membahas konsep pada tingkat yang relatif tinggi, dan bab selanjutnya akan memberikan detail tambahan. Jika kita ingin segera mencoba mempraktikkan koding, Bab 2 adalah tempat yang paling cocok untuk itu. Jika kita tipe pelajar yang sangat teliti yang lebih memilih mempelajari setiap detailnya sebelum berpindah ke topik selanjutnya, mungkin lebih baik kita lewati Bab 2 dan langsung ke Bab 3, yang membahas fitur-fitur Rust yang mirip dengan bahasa pemrograman lainnya; baru kemudian kita kembali ke Bab 2 jika ingin mengerjakan suatu proyek untuk menerapkan detail-detail yang sudah dipelajari.
Di Bab 4, kita akan mempelajari sistem ownership Rust. Bab 5 membahas
struct dan method. Bab 6 membahas enum, ekspresi match, serta konstruk
kontrol alur if let dan let...else. Kita akan menggunakan struct dan enum
untuk membuat tipe kustom.
Di Bab 7, kita akan mempelajari sistem modul Rust dan aturan privasi untuk mengelola kode kita dan API publiknya yang terkait. Bab 8 membahas beberapa struktur data koleksi umum yang tersedia pada pustaka standar, seperti vector, string, dan hash map. Bab 9 menjelajahi filosofi dan teknik penanganan error di Rust.
Bab 10 menggali lebih dalam mengenai generik, trait, dan lifetime, yang akan
memberikan kita kemampuan dalam mendefinisikan kode yang diterapkan pada
beberapa tipe. Bab 11 adalah semua hal tentang pengujian, di mana bahkan
dengan jaminan keamanan dari Rust, pengujian tetap dibutuhkan untuk memastikan
logika program kita benar. Di Bab 12, kita akan membangun implementasi
sendiri dari sebagian fungsionalitas aplikasi baris perintah grep yang
melakukan pencarian teks di dalam berkas. Untuk keperluan ini, kita akan
menggunakan banyak konsep yang telah dibahas pada bab-bab sebelumnya.
Bab 13 mengeksplorasi closures dan iterators: fitur-fitur Rust yang berasal dari bahasa pemrograman fungsional. Di Bab 14, kita akan memeriksa Cargo lebih dalam dan berbicara mengenai praktik terbaik untuk membagikan pustaka kita ke orang lain. Bab 15 membahas smart pointers yang disediakan pustaka standar dan trait yang mendukung fungsionalitasnya.
Di Bab 16, kita akan membahas berbagai model pemrograman konkuren dan mempelajari bagaimana Rust membantu kita menulis program di banyak threads tanpa rasa takut. Di Bab 17, kita membangun di atas hal tersebut dengan mengeksplorasi sintaks async dan await di Rust, beserta task, future, dan stream, serta model konkurensi ringan yang mereka mungkinkan.
Bab 18 melihat bagaimana idiom Rust dibandingkan dengan prinsip pemrograman berorientasi objek yang mungkin sudah kita kenal. Bab 19 adalah referensi tentang pola dan pattern matching, yang merupakan cara kuat untuk mengekspresikan ide di seluruh program Rust. Bab 20 berisi beragam topik lanjutan yang menarik, termasuk unsafe Rust, macros, serta pembahasan lebih lanjut tentang lifetime, trait, tipe, fungsi, dan closure.
Di Bab 21, kita akan menyelesaikan sebuah proyek dengan mengimplementasikan web server multithreaded tingkat rendah!
Akhirnya, beberapa lampiran berisi informasi berguna tentang bahasa Rust dalam format yang lebih mirip referensi. Lampiran A membahas kata kunci Rust, Lampiran B membahas operator dan simbol Rust, Lampiran C membahas trait turunan (derivable traits) yang disediakan pustaka standar, Lampiran D membahas beberapa alat pengembangan yang berguna, dan Lampiran E menjelaskan edisi Rust. Pada Lampiran F, kita bisa menemukan terjemahan dari buku ini, dan di Lampiran G kita akan membahas bagaimana Rust dibuat serta apa itu Rust nightly.
Tidak ada cara salah dalam membaca buku ini: jika kita ingin melompat ke bab depan, lakukan saja! Kita mungkin harus melompat kembali ke bab-bab awal jika mengalami kebingungan. Tapi lakukanlah apa pun yang cocok untuk kita.
Bagian penting dari proses pembelajaran Rust adalah mempelajari bagaimana membaca pesan error yang ditampilkan oleh compiler: hal-hal ini akan menuntun kita menuju kode yang berfungsi. Karena itu, kami akan menyediakan banyak contoh yang tidak bisa di-compile beserta pesan error dari compiler pada tiap situasi tersebut. Pahami bahwa jika kita memasukkan dan menjalankan contoh secara acak, ada kemungkinan ia tidak bisa di-compile! Pastikan kita membaca teks di sekitarnya untuk melihat apakah contoh tersebut memang ditujukan untuk error. Dalam kebanyakan situasi, kami akan mengarahkan kita ke versi yang benar dari kode yang tidak bisa di-compile tersebut. Ferris juga akan membantu kita membedakan kode yang memang tidak dimaksudkan agar berfungsi:
| Ferris | Makna |
|---|---|
 | Kode ini tidak bisa di-compile! |
 | Kode ini menghasilkan panic! |
 | Kode ini tidak menghasilkan perilaku yang diinginkan. |
Dalam kebanyakan situasi, kami akan mengarahkan kita ke versi yang benar dari kode apa pun yang tidak bisa di-compile.
Kode Sumber (Source Code)
Berkas sumber dari mana buku ini dibuat dapat ditemukan di GitHub.
Persiapan
Mari kita mulai perjalanan Rust kita! Ada banyak yg harus dipelajari, tetapi setiap perjalanan dimulai dari suatu permulaan. Pada bab ini, kita akan berbicara mengenai:
- Memasang Rust di Linux, macOS, dan Windows
- Menulis program yang mencetak
Hello, world! - Menggunakan
cargo, manajer paket dan sistem build Rust
Instalasi
Instalasi
Langkah pertama yang kita lakukan adalah instalasi bahasa Rust. Kita akan men-
download Rust melalui rustup, tool command line ini digunakan untuk mengatur
versi dari Rust dan beberapa tool - tool yang ada didalamnya. untuk instalasi ini
kita membutuhkan koneksi internet untuk mendownloadnya.
Catatan: Jika Kita lebih memilih untuk tidak menggunakan
rustupuntuk beberapa alasan, Kita bisa merujuk pada Halaman Instalasi Rust Lainnya untuk opsi lainnya
Langkah selanjutnya memasang versi stable dari compiler Rust. Jaminan stabilitas Rust memastikan bahwa semua contoh di buku ini yg bisa di compile akan tetap bisa di compile dengan versi Rust yg lebih baru. Hasil Output mungkin berbeda sedikit antarversi karena Rust sering kali memperbaiki pesan error dan peringatan. Dengan kata lain, semua versi stable Rust yg lebih baru, yg kita install menggunakan metode berikut, seharusnya bekerja sesuai harapan dengan isi buku ini.
Notasi Baris Perintah
Pada bab ini dan keseluruhan buku, kita akan ditunjukkan beberapa perintah yg
digunakan pada terminal. Baris yg seharusnya kita masukkan di terminal semua
diawali dengan $. kita tidak perlu mengetikkan karakter $; Itu adalah penanda
baris perintah yg ditampilkan untuk menunjukkan awal dari tiap perintah.
Baris yg tidak dimulai dengan $ biasanya menampilkan output dari perintah
sebelumnya. Sebagai tambahan, contoh khusus PowerShell akan menggunakan >
daripada $.
Pemasangan rustup pada Linux atau macOS
Jika kita menggunakan Linux atau macOS, buka sebuah terminal dan masukkan perintah berikut:
$ curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh
Perintah tersebut akan mengunduh sebuah script dan memulai pemasangan aplikasi
rustup, dan memasang versi stable terakhir Rust. Kita mungkin akan diminta
untuk memasukkan kata kunci. Jika pemasangan sukses, baris berikut akan muncul:
Rust is installed now. Great!
Kita juga akan memerlukan sebuah linker, yaitu sebuah program yang digunakan Rust untuk menggabungkan hasil kompilasi menjadi satu berkas. Kemungkinan besar kita sudah memilikinya. Jika kita mengalami error terkait linker, kita sebaiknya menginstal compiler C, yang biasanya sudah menyertakan linker. Compiler C juga berguna karena beberapa paket Rust yang umum bergantung pada kode C dan akan membutuhkan compiler C.
Di macOS, kita memasang compiler C dengan menjalankan:
$ xcode-select --install
Pengguna Linux biasanya memasang GCC atau Clang, sesuai dengan dokumentasi
masing-masing distribusi. Sebagai contoh, jika kita menggunakan Ubuntu, kita
bisa memasang paket build-essential.
Memasang rustup pada Windows
Di Windows, buka https://www.rust-lang.org/tools/install dan ikuti instruksi untuk memasang Rust. Pada suatu tahap dalam proses instalasi, kita akan diminta untuk menginstal Visual Studio. Ini akan menyediakan sebuah linker dan pustaka native yang dibutuhkan untuk mengompilasi program. Jika kita membutuhkan bantuan lebih lanjut pada langkah ini, lihat https://rust-lang.github.io/rustup/installation/windows-msvc.html
Sisa buku ini menggunakan perintah yang bisa dijalankan baik di cmd.exe maupun
PowerShell. Jika ada perbedaan khusus, kita akan menjelaskan mana yang harus digunakan.
Pemecahan Masalah
Untuk mengecek apakah kita memiliki Rust yg terpasang dengan baik, buka terminal dan masukkan:
$ rustc --version
Seharusnya keluar nomor versi, hash commit, dan tanggal commit untuk versi stable terakhir yg telah diterbitkan, dalam format:
rustc x.y.z (abcabcabc yyyy-mm-dd)
Jika kita mendapatkan informasi tersebut, berarti kita telah berhasil memasang
Rust! Jika kita tidak bertemu dengan informasi tersebut, silakan cek apakah Rust
berada di variabel sistem %PATH% sebagai berikut:
Di Windows CMD, gunakan:
> echo %PATH%
Di PowerShell, gunakan:
> echo $env:Path
Di Linux dan macOS, gunakan:
$ echo $PATH
Jika semuanya sudah benar tetapi Rust masih belum bekerja, ada beberapa tempat dimana kita bisa mencari bantuan. Cari tahu bagaimana berhubungan dengan Rustacean (sebutan bagi kita) lainnya di halaman komunitas.
Memperbarui dan Menghapus
Begitu Rust terpasang melalui rustup, memperbarui ke versi terbaru menjadi
lebih mudah. Dari terminal kita, jalankan perintah berikut:
$ rustup update
Untuk menghapus Rust dan rustup, jalankan perintah berikut dari terminal
kita:
$ rustup self uninstall
Dokumentasi Lokal
Pemasangan Rust juga menyertakan salinan dokumentasi lokal jadi kita dapat
membacanya secara luring. Jalankan rustup doc untuk membuka dokumentasi lokal
di peramban kita.
Setiap kali ada sebuah tipe atau fungsi yg tersedia di library std dan kita mungkin tidak paham mengenai apa dan bagaimana cara menggunakannya, gunakan dokumentasi API (Application Programming Interface) berikut untuk mencari tahu!
Editor Teks dan Lingkungan Pengembangan Terpadu
Buku ini tidak mengasumsikan alat apa yang kita gunakan untuk menulis kode Rust. Hampir semua editor teks bisa menyelesaikan pekerjaan! Namun, banyak editor teks dan Lingkungan Pengembangan Terpadu atau sering disebut Integrated Development Environments(IDE) yang memiliki dukungan bawaan untuk Rust. Kita selalu bisa menemukan daftar terkini dari berbagai editor dan IDE di halaman tools pada situs web Rust.
Bekerja Secara Offline dengan Buku Ini
Dalam beberapa contoh, kita akan menggunakan paket Rust di luar library standar.
Untuk mengikuti contoh-contoh tersebut, kita perlu memiliki koneksi internet
atau sudah mengunduh dependensi tersebut sebelumnya. Untuk mengunduh dependensi
lebih dulu, kita bisa menjalankan perintah berikut. (Nantinya kita akan menjelaskan
apa itu cargo dan apa fungsi dari setiap perintah ini secara lebih rinci.)
$ cargo new get-dependencies
$ cd get-dependencies
$ cargo add rand@0.8.5 trpl@0.2.0
Perintah ini akan menyimpan hasil unduhan paket-paket tersebut di cache sehingga
kita tidak perlu mengunduhnya lagi nanti. Setelah menjalankan perintah ini, kita
tidak perlu menyimpan folder get-dependencies. Jika kita sudah menjalankan
perintah ini, kita bisa menggunakan flag --offline pada semua perintah cargo
di sisa buku ini untuk memakai versi yang sudah tersimpan di cache alih-alih
mencoba menggunakan jaringan.
Halo, Dunia!
Hello, World!
Sekarang setelah kita memasang Rust, saatnya menulis program Rust pertama kita.
Sudah menjadi tradisi ketika belajar bahasa pemrograman baru untuk membuat program
kecil yang mencetak teks Hello, world! ke layar, jadi mari kita lakukan hal yang
sama di sini!
Catatan: Buku ini mengasumsikan kita memiliki pemahaman dasar tentang command line.
Rust tidak memiliki tuntutan khusus mengenai editor, tools, atau di mana kode kita berada,
jadi jika lebih suka menggunakan integrated development environment (IDE)
daripada command line, silakan gunakan IDE favorit kita sendiri. Banyak IDE sekarang sudah
memiliki dukungan tertentu untuk Rust; periksa dokumentasi IDE untuk detailnya.
Tim Rust berfokus pada peningkatan dukungan IDE melaluirust-analyzer.
Lihat Lampiran D untuk detail lebih lanjut.
Membuat Direktori Proyek
Kita akan mulai dengan membuat sebuah direktori untuk menyimpan kode Rust kita. Rust tidak peduli di mana kode kita berada, tetapi untuk latihan dan proyek dalam buku ini, kami menyarankan untuk membuat direktori projects di direktori home kita dan menyimpan semua proyek di sana.
Buka terminal dan masukkan perintah berikut untuk membuat direktori projects dan sebuah direktori untuk proyek “Hello, world!” di dalam direktori projects.
Untuk Linux, macOS, dan PowerShell di Windows, masukkan perintah ini:
$ mkdir ~/projects
$ cd ~/projects
$ mkdir hello_world
$ cd hello_world
untuk Command Line Windows, masukkan perintah ini:
> mkdir "%USERPROFILE%\projects"
> cd /d "%USERPROFILE%\projects"
> mkdir hello_world
> cd hello_world
Menulis dan Menjalankan Program Rust
Selanjutnya, buat sebuah berkas sumber baru dan beri nama main.rs. Berkas Rust selalu diakhiri dengan ekstensi .rs. Jika kita menggunakan lebih dari satu kata dalam nama berkas, konvensinya adalah menggunakan garis bawah (underscore) untuk memisahkan kata-kata tersebut. Misalnya, gunakan hello_world.rs daripada helloworld.rs.
Sekarang buka berkas main.rs yang baru saja kita buat dan masukkan kode pada Listing 1-1.
fn main() {
println!("Hello, world!");
}Hello, world!Simpan berkas tersebut lalu kembali ke jendela terminal kita di direktori
~/projects/hello_world. Pada Linux atau macOS, masukkan perintah berikut
untuk mengompilasi dan menjalankan berkas:
$ rustc main.rs
$ ./main
Hello, world!
Pada Windows, masukan perintah .\main daripada ./main:
> rustc main.rs
> .\main
Hello, world!
Terlepas dari sistem operasi yang kita gunakan, string Hello, world! seharusnya
muncul di terminal. Jika kita tidak melihat output ini, lihat kembali bagian
“Troubleshooting” pada bagian Instalasi untuk cara mendapatkan
bantuan.
Jika Hello, world! berhasil tercetak, selamat! Kita secara resmi telah menulis
program Rust. Itu berarti kita sudah menjadi seorang pemrogram Rust—selamat datang!
Anatomi Program Rust
Mari kita ulas program “Hello, world!” ini secara lebih rinci. Berikut adalah potongan pertama dari teka-teki tersebut:
fn main() {
}Baris-baris ini mendefinisikan sebuah fungsi bernama main. Fungsi main itu
spesial: selalu menjadi kode pertama yang dijalankan dalam setiap program Rust
yang bisa dieksekusi. Di sini, baris pertama mendeklarasikan fungsi bernamamain yang tidak memiliki parameter dan tidak mengembalikan nilai apa pun.
Jika ada parameter, maka mereka akan ditulis di dalam tanda kurung ().
Badan fungsi dibungkus dengan {}. Rust mewajibkan penggunaan kurung kurawal
pada semua badan fungsi. Gaya penulisan yang baik adalah meletakkan kurung kurawal
pembuka pada baris yang sama dengan deklarasi fungsi, dengan memberi satu spasi
di antaranya.
Catatan: Jika kita ingin tetap menggunakan gaya standar di seluruh proyek Rust,
kita bisa memakai alat pemformat otomatis bernamarustfmtuntuk memformat kode
sesuai gaya tertentu (lebih lanjut tentangrustfmtada di Lampiran D).
Tim Rust sudah menyertakan alat ini dalam distribusi standar Rust, sama sepertirustc,
jadi seharusnya sudah terpasang di komputer kita!
Badan fungsi main berisi kode berikut:
#![allow(unused)]
fn main() {
println!("Hello, world!");
}Baris ini melakukan seluruh pekerjaan dalam program kecil ini: mencetak teks ke layar. Ada tiga detail penting yang perlu kita perhatikan di sini.
Pertama, println! memanggil sebuah macro Rust. Jika yang dipanggil adalah fungsi biasa,
maka penulisannya akan println (tanpa !). Macro Rust adalah cara untuk menulis kode
yang menghasilkan kode lain untuk memperluas sintaks Rust, dan kita akan membahasnya lebih
lanjut di Bab 20. Untuk saat ini, kita hanya perlu tahu bahwa penggunaan !
berarti kita sedang memanggil macro, bukan fungsi biasa, dan macro tidak selalu mengikuti
aturan yang sama dengan fungsi.
Kedua, kita melihat string "Hello, world!". Kita meneruskan string ini sebagai argumen
ke println!, dan string tersebut akan dicetak ke layar.
Ketiga, kita mengakhiri baris dengan tanda titik koma (;), yang menunjukkan bahwa ekspresi
tersebut sudah selesai dan ekspresi berikutnya siap dimulai. Sebagian besar baris kode Rust
diakhiri dengan titik koma.
Kompilasi dan Eksekusi adalah Langkah yang Terpisah
Kita baru saja menjalankan sebuah program baru, jadi mari kita periksa setiap langkah dalam prosesnya.
Sebelum menjalankan program Rust, kita harus mengompilasinya dengan compiler Rust
dengan memasukkan perintah rustc dan menambahkan nama berkas sumber kita, seperti ini:
$ rustc main.rs
Jika kita memiliki latar belakang C atau C++, kita akan menyadari bahwa ini mirip
dengan gcc atau clang. Setelah kompilasi berhasil, Rust menghasilkan sebuah
biner yang bisa dieksekusi.
Di Linux, macOS, dan PowerShell di Windows, kita bisa melihat berkas executable
dengan memasukkan perintah ls di shell:
$ ls
main main.rs
Di Linux dan macOS, kita akan melihat dua berkas. Dengan PowerShell di Windows, kita akan melihat tiga berkas yang sama seperti yang muncul saat menggunakan CMD. Dengan CMD di Windows, kita akan memasukkan perintah berikut:
> dir /B %= the /B option says to only show the file names =%
main.exe
main.pdb
main.rs
Ini menampilkan berkas kode sumber dengan ekstensi .rs, berkas executable (main.exe di Windows, tetapi main di semua platform lain), dan, ketika menggunakan Windows, sebuah berkas yang berisi informasi debugging dengan ekstensi .pdb. Dari sini, kita bisa menjalankan berkas main atau main.exe, seperti ini:
$ ./main # or .\main on Windows
Jika main.rs kita adalah program “Hello, world!”, baris ini akan mencetak
Hello, world! ke terminal kita.
Jika kita lebih familiar dengan bahasa dinamis seperti Ruby, Python, atau JavaScript, kita mungkin belum terbiasa dengan proses kompilasi dan eksekusi sebagai langkah terpisah. Rust adalah bahasa ahead-of-time compiled, artinya kita bisa mengompilasi program lalu memberikan file executable-nya kepada orang lain, dan mereka dapat menjalankannya tanpa harus memasang Rust. Sebaliknya, jika kita memberikan berkas .rb, .py, atau .js, orang tersebut perlu memasang Ruby, Python, atau JavaScript (sesuai bahasa yang digunakan). Namun, pada bahasa-bahasa tersebut, kita hanya perlu satu perintah untuk mengompilasi sekaligus menjalankan program. Semua ini adalah bentuk kompromi dalam desain bahasa pemrograman.
Mengompilasi dengan rustc saja sudah cukup untuk program sederhana,
tetapi seiring pertumbuhan proyek, kita akan ingin mengatur semua opsi
dan mempermudah berbagi kode. Selanjutnya, kita akan berkenalan dengan alat Cargo,
yang akan membantu kita menulis program Rust untuk dunia nyata.
Halo, Cargo!
Hello, Cargo!
Cargo adalah sistem build dan manajer paket Rust. Sebagian besar Rustacean menggunakan alat ini untuk mengelola proyek Rust mereka karena Cargo menangani banyak tugas untuk kita, seperti membangun kode, mengunduh pustaka yang dibutuhkan kode kita, dan membangun pustaka tersebut. (Kita menyebut pustaka yang dibutuhkan oleh kode kita sebagai dependensi.)
Program Rust paling sederhana, seperti yang sudah kita tulis sejauh ini, tidak memiliki dependensi apa pun. Jika kita membangun proyek “Hello, world!” dengan Cargo, Cargo hanya akan menggunakan bagian yang menangani proses build kode kita. Seiring kita menulis program Rust yang lebih kompleks, kita akan menambahkan dependensi, dan jika kita memulai proyek dengan Cargo, menambahkan dependensi akan jauh lebih mudah dilakukan.
Karena sebagian besar proyek Rust menggunakan Cargo, sisa buku ini juga mengasumsikan kita menggunakan Cargo. Cargo sudah terpasang bersama Rust jika kita menggunakan installer resmi yang dibahas pada bagian “Instalasi”. Jika kita memasang Rust dengan cara lain, periksa apakah Cargo sudah terpasang dengan memasukkan perintah berikut di terminal:
$ cargo --version
Jika kita melihat nomor versi, berarti Cargo sudah ada! Jika yang muncul adalah error,
seperti command not found, lihat dokumentasi dari metode instalasi yang kita gunakan
untuk mengetahui cara memasang Cargo secara terpisah.
Membuat Proyek dengan Cargo
Mari kita buat proyek baru menggunakan Cargo dan melihat bagaimana perbedaannya dengan proyek “Hello, world!” yang asli. Arahkan kembali ke direktori projects (atau lokasi lain tempat kita menyimpan kode). Lalu, pada sistem operasi apa pun, jalankan perintah berikut:
$ cargo new hello_cargo
$ cd hello_cargo
Perintah pertama membuat direktori dan proyek baru bernama hello_cargo. Kita memberi nama proyek ini hello_cargo, dan Cargo membuat berkas-berkasnya di dalam direktori dengan nama yang sama.
Masuklah ke direktori hello_cargo dan lihat daftar berkasnya. Kita akan melihat bahwa Cargo telah menghasilkan dua berkas dan satu direktori untuk kita: sebuah berkas Cargo.toml dan direktori src dengan sebuah berkas main.rs di dalamnya.
Cargo juga telah menginisialisasi sebuah repositori Git baru beserta berkas .gitignore.
Berkas Git tidak akan dibuat jika kita menjalankan cargo new di dalam repositori Git
yang sudah ada; kita bisa menimpa perilaku ini dengan menggunakan cargo new --vcs=git.
Catatan: Git adalah sistem kontrol versi yang umum digunakan. Kita bisa mengubah
cargo newuntuk menggunakan sistem kontrol versi lain atau tanpa sistem kontrol versi
dengan menambahkan flag--vcs. Jalankancargo new --helpuntuk melihat opsi yang tersedia.
Buka Cargo.toml di editor teks pilihan kita. Isinya akan terlihat mirip dengan kode
pada Listing 1-2.
[package]
name = "hello_cargo"
version = "0.1.0"
edition = "2024"
[dependencies]
cargo newBerkas ini menggunakan format TOML (Tom’s Obvious, Minimal Language), yang merupakan format konfigurasi untuk Cargo.
Baris pertama, [package], adalah judul bagian yang menunjukkan bahwa pernyataan
berikutnya berfungsi untuk mengonfigurasi sebuah paket. Saat kita menambahkan lebih
banyak informasi ke berkas ini, kita akan menambahkan bagian lain.
Tiga baris berikutnya mengatur informasi konfigurasi yang dibutuhkan Cargo untuk
mengompilasi program kita: nama, versi, dan edition Rust yang digunakan. Kita akan
membahas kunci edition di Lampiran E.
Baris terakhir, [dependencies], adalah awal dari bagian tempat kita mencantumkan
dependensi proyek. Dalam Rust, paket kode disebut crate. Untuk proyek ini kita
tidak membutuhkan crate tambahan, tetapi pada proyek pertama di Bab 2 kita akan
membutuhkannya, jadi kita akan menggunakan bagian dependensi ini nanti.
Sekarang buka src/main.rs dan perhatikan isinya:
Nama berkas: src/main.rs
fn main() {
println!("Hello, world!");
}Cargo telah membuatkan program “Hello, world!” untuk kita, persis seperti yang kita tulis di Listing 1-1! Sejauh ini, perbedaan antara proyek kita dan proyek yang dihasilkan Cargo adalah bahwa Cargo menempatkan kode di dalam direktori src dan kita memiliki berkas konfigurasi Cargo.toml di direktori paling atas.
Cargo mengharapkan berkas sumber kita berada di dalam direktori src. Direktori proyek paling atas hanya untuk berkas README, informasi lisensi, berkas konfigurasi, dan hal lain yang tidak langsung berkaitan dengan kode. Menggunakan Cargo membantu kita mengatur proyek dengan rapi. Ada tempat untuk semuanya, dan semuanya berada di tempatnya.
Jika kita memulai sebuah proyek tanpa Cargo, seperti proyek “Hello, world!”,
kita bisa mengonversinya menjadi proyek yang menggunakan Cargo. Pindahkan kode
proyek ke dalam direktori src dan buat berkas Cargo.toml yang sesuai.
Salah satu cara mudah untuk mendapatkan berkas Cargo.toml adalah dengan
menjalankan cargo init, yang akan membuatkannya secara otomatis.
Membangun dan Menjalankan Proyek Cargo
Sekarang mari kita lihat perbedaan ketika kita membangun dan menjalankan program “Hello, world!” dengan Cargo! Dari direktori hello_cargo, bangun proyek kita dengan memasukkan perintah berikut:
$ cargo build
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 2.85 secs
Perintah ini membuat berkas executable di target/debug/hello_cargo
(atau target\debug\hello_cargo.exe di Windows) alih-alih di direktori kita saat ini.
Karena build bawaan adalah build debug, Cargo menaruh biner di dalam direktori bernama debug.
Kita bisa menjalankan berkas executable tersebut dengan perintah ini:
$ ./target/debug/hello_cargo # or .\target\debug\hello_cargo.exe on Windows
Hello, world!
Jika semuanya berjalan dengan baik, Hello, world! akan tercetak di terminal.
Menjalankan cargo build untuk pertama kalinya juga membuat Cargo menghasilkan
berkas baru di tingkat paling atas: Cargo.lock. Berkas ini menyimpan catatan
versi pasti dari dependensi dalam proyek kita. Proyek ini tidak memiliki dependensi,
jadi isi berkasnya masih cukup kosong. Kita tidak pernah perlu mengubah berkas ini secara manual;
Cargo akan mengelola isinya untuk kita.
Kita baru saja membangun proyek dengan cargo build dan menjalankannya dengan./target/debug/hello_cargo, tetapi kita juga bisa menggunakan cargo run
untuk mengompilasi kode dan kemudian menjalankan executable hasilnya hanya dengan satu perintah:
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs
Running `target/debug/hello_cargo`
Hello, world!
Menggunakan cargo run lebih praktis daripada harus mengingat untuk menjalankancargo build lalu menggunakan path lengkap ke biner, jadi kebanyakan pengembang
lebih memilih cargo run.
Perhatikan bahwa kali ini kita tidak melihat output yang menunjukkan bahwa Cargo
sedang mengompilasi hello_cargo. Cargo mengetahui bahwa berkas-berkas tidak berubah,
jadi ia tidak melakukan build ulang dan langsung menjalankan binernya. Jika kita
mengubah kode sumber, Cargo akan melakukan build ulang proyek sebelum menjalankannya,
dan kita akan melihat output seperti ini:
$ cargo run
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.33 secs
Running `target/debug/hello_cargo`
Hello, world!
Cargo juga menyediakan sebuah perintah yang dipanggil cargo check. perintah ini
secara cepat memeriksa kode kita untuk memastikan bahwa kode tersebut bisa di
kompilasi tetapi perintah ini tidak menghasilkan file eksekusi/executable:
$ cargo check
Checking hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.32 secs
Kenapa kita mungkin tidak ingin menghasilkan executable? Sering kali,
cargo check jauh lebih cepat dibandingkan cargo build karena ia melewati
langkah untuk membuat executable. Jika kita terus-menerus memeriksa pekerjaan
selagi menulis kode, menggunakan cargo check akan mempercepat proses untuk
memberi tahu apakah proyek kita masih bisa dikompilasi! Karena itu, banyak
Rustacean menjalankan cargo check secara berkala saat menulis program untuk
memastikan kodenya tetap bisa dikompilasi. Lalu, mereka menjalankan
cargo build ketika sudah siap menggunakan executable.
Mari kita rekap apa yang sudah kita pelajari tentang Cargo sejauh ini:
- Kita bisa membuat proyek dengan
cargo new. - Kita bisa membangun proyek dengan
cargo build. - Kita bisa membangun sekaligus menjalankan proyek dalam satu langkah dengan
cargo run. - Kita bisa membangun proyek tanpa menghasilkan biner untuk mengecek error dengan
cargo check. - Alih-alih menyimpan hasil build di direktori yang sama dengan kode kita, Cargo menyimpannya di direktori target/debug.
Keuntungan tambahan dari menggunakan Cargo adalah perintah-perintahnya sama tidak peduli sistem operasi apa yang kita gunakan. Jadi, mulai dari titik ini, kita tidak lagi memberikan instruksi khusus untuk Linux dan macOS dibandingkan Windows.
Membangun untuk Rilis
Ketika proyek kita akhirnya siap dirilis, kita bisa menggunakan
cargo build --release untuk mengompilasi dengan optimisasi. Perintah ini akan
membuat executable di target/release alih-alih di target/debug.
Optimisasi membuat kode Rust kita berjalan lebih cepat, tetapi mengaktifkannya
akan memperpanjang waktu kompilasi program. Inilah alasan mengapa ada dua profil
yang berbeda: satu untuk pengembangan, ketika kita ingin build cepat dan sering,
dan satu lagi untuk membangun program final yang akan kita berikan kepada pengguna,
yang tidak akan dibangun ulang berulang kali dan harus berjalan secepat mungkin.
Jika kita melakukan benchmarking waktu eksekusi kode, pastikan untuk menjalankan
cargo build --release dan melakukan benchmark dengan executable di target/release.
Cargo sebagai Konvensi
Untuk proyek sederhana, Cargo mungkin tidak terlihat jauh lebih berguna daripada
sekadar menggunakan rustc, tetapi nilainya akan terasa ketika program kita
menjadi lebih rumit. Begitu program berkembang menjadi banyak berkas atau
membutuhkan dependensi, jauh lebih mudah membiarkan Cargo yang mengoordinasikan build.
Meskipun proyek hello_cargo sederhana, ia sudah menggunakan banyak tooling nyata
yang akan kita gunakan sepanjang perjalanan kita dengan Rust. Bahkan, untuk
bekerja pada proyek yang sudah ada, kita bisa menggunakan perintah berikut untuk
mengambil kode dengan Git, berpindah ke direktori proyek tersebut, dan melakukan build:
$ git clone example.org/someproject
$ cd someproject
$ cargo build
Untuk informasi lebih lanjut tentang Cargo, lihat dokumentasinya.
Ringkasan
Kita sudah memulai perjalanan Rust dengan langkah yang hebat! Dalam bab ini, kita telah mempelajari cara:
- Memasang versi stabil terbaru Rust menggunakan
rustup - Memperbarui Rust ke versi yang lebih baru
- Membuka dokumentasi yang terpasang secara lokal
- Menulis dan menjalankan program “Hello, world!” langsung dengan
rustc - Membuat dan menjalankan proyek baru menggunakan konvensi Cargo
Ini adalah waktu yang tepat untuk membangun program yang lebih substansial agar terbiasa membaca dan menulis kode Rust. Jadi, pada Bab 2, kita akan membangun program permainan tebak angka. Jika kita lebih suka memulai dengan mempelajari bagaimana konsep pemrograman umum bekerja di Rust, lihat Bab 3 lalu kembali ke Bab 2.
Membuat Game Tebak Angka
Yuk, kita langsung terjun ke Rust dengan ngerjain project bareng-bareng! Di bab
ini, kita bakal kenalan sama beberapa konsep umum di Rust lewat program benar-benar.
Kita bakal belajar soal let, match, methods, associated functions, external
crates, dan banyak lagi! Di bab-bab selanjutnya, kita bakal bahas konsep ini
lebih dalem. Tapi buat sekarang, kita latihan yang basic-basic dulu ya.
Kita bakal bikin problem klasik buat pemula: game tebak angka. Cara mainnya simpel: program bakal nge-generate angka random antara 1 sampe 100. Terus, program bakal minta player buat masukin tebakannya. Setelah tebakan dimasukin, program bakal ngasih tau apakah tebakannya ketinggian atau kerendahan. Kalau bener, game-nya bakal ngasih ucapan selamat terus exit.
Setup Project Baru
Buat nge-setup project baru, masuk ke direktori projects yang udah kita bikin di Bab 1, terus bikin project baru pake Cargo kayak gini:
$ cargo new guessing_game
$ cd guessing_game
Perintah pertama, cargo new, ngambil nama project (guessing_game) sebagai
argumen pertamanya. Perintah kedua buat pindah ke direktori project yang baru
dibikin.
Coba liat file Cargo.toml yang dihasilkan:
Nama file: Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2024"
[dependencies]
Kayak yang kita liat di Bab 1, cargo new nge-generate program “Hello, world!”
buat kita. Cek file src/main.rs-nya:
Nama file: src/main.rs
fn main() {
println!("Hello, world!");
}Sekarang kita compile program “Hello, world!” ini terus jalanin sekalian pake
perintah cargo run:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/guessing_game`
Hello, world!
Perintah run ini kepake sekali pas kita butuh iterasi cepet di sebuah project,
kayak di game ini nanti, buat ngetes tiap perubahan sebelum lanjut ke langkah
berikutnya.
Buka lagi file src/main.rs. Kita bakal nulis semua kodenya di file ini.
Memproses Tebakan (Guess)
Bagian pertama dari program game tebak angka ini bakal minta input dari user, proses input-nya, terus nge-cek apakah input-nya udah sesuai format. Buat awal, kita bakal bolehin player buat masukin tebakan. Masukin kode di Listing 2-1 ke dalam src/main.rs.
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Kode ini isinya banyak informasi, jadi yuk kita bahas baris demi baris. Buat
dapet input user terus nge-print hasilnya sebagai output, kita perlu bawa
library io (input/output) ke dalam scope. Library io ini dateng dari
standard library, yang dikenal sebagai std:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Secara default, Rust punya sekumpulan item yang udah didefinisiin di standard library yang otomatis dibawa ke scope tiap program. Kumpulan ini namanya prelude, dan kita bisa liat isinya di dokumentasi standard library.
Kalau tipe yang mau kita pake nggak ada di prelude, kita harus bawa tipe itu ke
scope secara eksplisit pake statement use. Pake library std::io ngasih kita
beberapa fitur berguna, termasuk kemampuan buat nerima input user.
Kayak yang kita liat di Bab 1, fungsi main adalah entry point ke programnya:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Sintaks fn mendeklarasikan fungsi baru; tanda kurung () nunjukin kalau
nggak ada parameter; dan kurung kurawal { buat mulai body fungsinya.
Kita juga udah belajar di Bab 1 kalau println! itu macro buat nyetak string ke
layar:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Kode ini nyetak prompt yang ngasih tau gamenya apa dan minta input dari user.
Menyimpan Nilai dengan Variabel
Selanjutnya, kita bakal bikin sebuah variable buat nyimpen input user, kayak gini:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Nah, programnya mulai seru nih! Ada banyak hal yang terjadi di baris kecil ini.
Kita pake statement let buat bikin variabel. Ini contoh lainnya:
let apel = 5;Baris ini bikin variabel baru namanya apel dan nge-bind ke nilai 5. Di Rust,
variabel itu immutable (nggak bisa diubah) secara default, artinya sekali kita
kasih nilai ke variabelnya, nilainya nggak bakal berubah. Kita bakal bahas
konsep ini lebih detail di bagian “Variabel dan Mutabilitas”
di Bab 3. Buat bikin variabel jadi mutable (bisa diubah), kita tambahin mut
sebelum nama variabelnya:
let apel = 5; // immutable
let mut pisang = 5; // mutableCatatan: Sintaks
//buat mulai komentar sampe akhir baris. Rust bakal cuekin apa pun yang ada di dalam komentar. Kita bakal bahas komentar lebih detail di Bab 3.
Balik lagi ke program game tebak angka, sekarang kita tau kalau let mut guess
bakal ngenalin variabel mutable namanya guess. Tanda sama dengan (=) ngasih
tau Rust kalau kita mau nge-bind sesuatu ke variabelnya sekarang. Di sebelah
kanan tanda sama dengan adalah nilai yang di-bind ke guess, yaitu hasil dari
manggil String::new, fungsi yang balikin instance baru dari sebuah String.
String adalah tipe string yang dikasih standard library yang isinya
teks UTF-8 yang bisa nambah terus ukurannya (growable).
Sintaks :: di baris ::new nunjukin kalau new itu associated function dari
tipe String. Associated function adalah fungsi yang diimplementasikan pada
sebuah tipe, dalam hal ini String. Fungsi new ini bikin string baru yang
kosong. Kita bakal sering nemu fungsi new di banyak tipe karena itu nama umum
buat fungsi yang bikin nilai baru dari jenis tertentu.
Secara lengkap, baris let mut guess = String::new(); udah bikin variabel
mutable yang sekarang di-bind ke instance baru dari String yang masih kosong.
Fiuh!
Menerima Input User
Inget kan kalau kita udah masukin fungsi input/output dari standard library pake
use std::io; di baris pertama program. Sekarang kita bakal manggil fungsi
stdin dari modul io, yang bakal ngebolehin kita handle input user:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Kalau kita nggak import modul io pake use std::io; di awal program, kita
tetep bisa pake fungsinya dengan nulis pemanggilan fungsi ini jadi
std::io::stdin. Fungsi stdin balikin instance dari std::io::Stdin,
tipe yang merepresentasikan handle ke standard input buat terminal kita.
Selanjutnya, baris .read_line(&mut guess) manggil method read_line
pada handle standard input buat dapet input dari user. Kita juga masukin
&mut guess sebagai argumen ke read_line buat ngasih tau string mana yang
bakal dipake buat nyimpen input user. Tugas utama read_line adalah ngambil
apa pun yang diketik user ke standard input terus nambahin itu ke sebuah string
(tanpa nimpa isinya), makanya kita masukin string itu sebagai argumen. Argumen
string-nya harus mutable biar method-nya bisa ngerubah isi string-nya.
Tanda & nunjukin kalau argumen ini adalah sebuah reference (referensi),
yang ngasih cara biar beberapa bagian kode kita bisa akses satu data tanpa perlu
copy data itu ke memori berkali-kali. Reference itu fitur yang lumayan kompleks,
dan salah satu keunggulan utama Rust adalah seberapa aman dan gampangnya pake
reference. Kita nggak perlu tau banyak detailnya buat nyelesein program ini.
Buat sekarang, yang perlu kita tau adalah, kayak variabel, reference itu
immutable secara default. Makanya, kita perlu nulis &mut guess bukannya
&guess biar dia mutable. (Bab 4 bakal jelasin soal reference lebih mendalam.)
Menangani Potensi Gagal dengan Result
Kita masih bahas baris kode yang tadi ya. Sekarang kita lagi bahas bagian ketiganya, tapi inget kalau ini masih bagian dari satu baris kode yang logis. Bagian selanjutnya adalah method ini:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Kita bisa aja nulis kode ini kayak gini:
io::stdin().read_line(&mut guess).expect("Gagal baca baris");Tapi, satu baris panjang itu susah dibaca, jadi mendingan dibagi-bagi. Biasanya
lebih bijak buat nambahin baris baru dan whitespace lainnya buat bantu mecah
baris panjang pas kita manggil method pake sintaks .nama_method(). Sekarang
mari kita bahas fungsi baris ini.
Kayak yang udah disebutin tadi, read_line naruh apa pun yang user masukin ke
string yang kita kasih, tapi dia juga balikin nilai Result. Result
adalah sebuah enumeration, yang sering disebut enum, yaitu tipe
yang bisa ada di salah satu dari beberapa kemungkinan state. Kita sebut tiap
state itu sebagai variant.
Bab 6 bakal bahas enum lebih detail. Tujuan dari tipe-tipe Result ini
adalah buat nge-encode informasi penanganan error (error-handling).
Varian dari Result adalah Ok dan Err. Varian Ok nunjukin operasinya
berhasil, dan di dalemnya ada nilai yang berhasil di-generate. Varian Err
artinya operasinya gagal, dan isinya informasi soal gimana atau kenapa
operasinya gagal.
Nilai dari tipe Result, kayak nilai dari tipe apa pun, punya methods yang
didefinisiin di atasnya. Instance dari Result punya expect method
yang bisa kita panggil. Kalau instance Result ini adalah nilai Err, expect
bakal bikin programnya crash dan nampilin pesan yang kita kasih sebagai
argumen ke expect. Kalau method read_line balikin Err, itu kemungkinan
hasil dari error yang dateng dari sistem operasi di bawahnya. Kalau instance
Result ini adalah nilai Ok, expect bakal ngambil nilai balik yang dipegang
sama Ok terus balikin nilai itu aja biar bisa kita pake. Dalam kasus ini,
nilai itu adalah jumlah byte dari input user.
Kalau kita nggak manggil expect, programnya tetep bakal ke-compile, tapi kita
bakal dapet warning:
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
warning: unused `Result` that must be used
--> src/main.rs:10:5
|
10 | io::stdin().read_line(&mut guess);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
10 | let _ = io::stdin().read_line(&mut guess);
| +++++++
warning: `guessing_game` (bin "guessing_game") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.59s
Rust ngasih tau kalau kita nggak pake nilai Result yang dibalikin sama
read_line, yang nunjukin kalau programnya belum handle kemungkinan error.
Cara yang bener buat ilangin warning itu adalah dengan benar-benar nulis kode
error-handling, tapi dalam kasus kita, kita cuma mau nge-crash-in program ini
pas ada masalah, jadi kita bisa pake expect. Kita bakal belajar soal cara
bangkit dari error di Bab 9.
Mencetak Nilai dengan Placeholder println!
Selain kurung kurawal tutup, cuma ada satu baris lagi yang perlu dibahas di kode sejauh ini:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Baris ini nyetak string yang sekarang isinya input user. Tanda kurung kurawal
{} itu adalah placeholder: bayangin aja {} kayak capit kepiting kecil yang
megang sebuah nilai di tempatnya. Pas nyetak nilai variabel, nama variabelnya
bisa masuk ke dalem kurung kurawal. Pas nyetak hasil evaluasi sebuah ekspresi,
taruh kurung kurawal kosong di format string-nya, terus ikuti format string itu
dengan daftar ekspresi yang dipisahin koma buat dicetak di tiap placeholder
kurung kurawal kosong sesuai urutannya. Nyetak variabel dan hasil ekspresi dalam
satu panggilan ke println! bakal keliatan kayak gini:
#![allow(unused)]
fn main() {
let x = 5;
let y = 10;
println!("x = {x} dan y + 2 = {}", y + 2);
}Kode ini bakal nyetak x = 5 dan y + 2 = 12.
Ngetes Bagian Pertama
Yuk kita tes bagian pertama dari game tebak angka ini. Jalanin pake cargo run:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 6.44s
Running `target/debug/guessing_game`
Guess the number!
Please input your guess.
6
You guessed: 6
Sampai titik ini, bagian pertama game-nya udah jadi: kita dapet input dari keyboard terus nyetak hasilnya.
Menghasilkan Secret Number
Selanjutnya, kita perlu generate angka rahasia (secret number) yang bakal ditebak
sama user. Angka rahasianya harus beda terus tiap kali biar gamenya seru buat
dimainin berkali-kali. Kita bakal pake angka random antara 1 sampe 100 biar
gamenya nggak terlalu susah. Rust belum masukin fungsionalitas angka random di
standard library-nya. Tapi, tim Rust nyediain rand crate dengan
fungsionalitas tersebut.
Pake Crate buat Dapet Fitur Lebih
Inget ya, crate itu adalah kumpulan file source code Rust. Project yang lagi
kita bangun ini adalah sebuah binary crate, yaitu sebuah executable. rand
crate adalah sebuah library crate, yang isinya kode yang tujuannya buat dipake
di program lain dan nggak bisa dijalankan sendiri.
Koordinasi Cargo sama external crates adalah bagian di mana Cargo bener-bener
bersinar. Sebelum kita bisa nulis kode yang pake rand, kita perlu modifikasi
file Cargo.toml buat masukin rand crate sebagai dependensi. Buka filenya
sekarang terus tambahin baris berikut di paling bawah, di bawah header section
[dependencies] yang udah dibikinin Cargo. Pastiin buat nulis rand persis
kayak di sini, dengan nomor versi ini, biar contoh kode di tutorial ini bisa
jalan:
Nama file: Cargo.toml
[dependencies]
rand = "0.8.5"
Di file Cargo.toml, apa pun yang ngikutin sebuah header adalah bagian dari
section itu sampe section lain mulai. Di [dependencies] kita ngasih tau Cargo
external crates mana aja yang diperluin project kita dan versi mana yang kita
butuhin. Dalam hal ini, kita nentuin rand crate dengan penentu versi semantik
0.8.5. Cargo ngerti Semantic Versioning (kadang disebut SemVer),
yaitu standar buat nulis nomor versi. Penentu 0.8.5 sebenernya singkatan dari
^0.8.5, yang artinya versi apa pun yang minimal 0.8.5 tapi di bawah 0.9.0.
Cargo nganggep versi-versi ini punya public API yang kompatibel sama versi 0.8.5, dan spesifikasi ini mastiin kita dapet patch release terbaru yang tetep bisa di-compile sama kode di bab ini. Versi 0.9.0 atau yang lebih baru nggak dijamin punya API yang sama kayak contoh-contoh yang kita pake.
Sekarang, tanpa ngerubah kode apa pun, yuk kita build project-nya, kayak yang ditunjukin di Listing 2-2.
$ cargo build
Updating crates.io index
Locking 15 packages to latest Rust 1.85.0 compatible versions
Adding rand v0.8.5 (available: v0.9.0)
Compiling proc-macro2 v1.0.93
Compiling unicode-ident v1.0.17
Compiling libc v0.2.170
Compiling cfg-if v1.0.0
Compiling byteorder v1.5.0
Compiling getrandom v0.2.15
Compiling rand_core v0.6.4
Compiling quote v1.0.38
Compiling syn v2.0.98
Compiling zerocopy-derive v0.7.35
Compiling zerocopy v0.7.35
Compiling ppv-lite86 v0.2.20
Compiling rand_chacha v0.3.1
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 2.48s
cargo build setelah nambahin rand crate sebagai dependensiMungkin kita bakal liat nomor versi yang beda (tapi semuanya bakal kompatibel sama kodenya, makasih buat SemVer!) dan baris-baris yang beda (tergantung sistem operasi), dan urutannya mungkin beda juga.
Pas kita masukin external dependency, Cargo bakal ngambil versi terbaru dari segala hal yang dibutuhin dependency itu dari registry, yang merupakan copy data dari Crates.io. Crates.io adalah tempat orang-orang di ekosistem Rust posting project open source Rust mereka biar bisa dipake orang lain.
Setelah update registry, Cargo cek section [dependencies] terus download
crate apa pun yang terdaftar tapi belum ada di komputer kita. Dalam hal ini,
walaupun kita cuma daftarin rand sebagai dependensi, Cargo juga ngambil crates
lain yang dibutuhin rand biar bisa jalan. Setelah download crates-nya, Rust
bakal compile crates itu terus compile project kita dengan dependensi yang udah
siap.
Kalau kita langsung jalanin cargo build lagi tanpa ngerubah apa pun, kita
nggak bakal dapet output apa-apa selain baris Finished. Cargo tau kalau dia
udah download dan compile dependensi-nya, dan kita nggak ngerubah apa pun soal
itu di file Cargo.toml. Cargo juga tau kalau kita nggak ngerubah kode kita,
jadi dia nggak compile ulang juga. Karena nggak ada kerjaan, dia langsung exit.
Kalau kita buka file src/main.rs, bikin perubahan kecil, terus save dan build lagi, kita cuma bakal liat dua baris output:
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Baris-baris ini nunjukin kalau Cargo cuma update build-nya sama perubahan kecil kita di file src/main.rs. Dependensi kita nggak berubah, jadi Cargo tau dia bisa pake lagi apa yang udah dia download dan compile sebelumnya.
Mastiin Build Bisa Direproduksi (Reproducible) dengan File Cargo.lock
Cargo punya mekanisme yang mastiin kita bisa rebuild artifact yang sama tiap
kali kita atau orang lain build kode kita: Cargo cuma bakal pake versi
dependensi yang kita tentuin sampe kita bilang sebaliknya. Misalnya, katakanlah
minggu depan versi 0.8.6 dari rand crate keluar, dan versi itu isinya bug fix
penting, tapi ada juga regresi yang bikin kode kita rusak. Buat handle ini,
Rust bikin file Cargo.lock pas pertama kali kita jalanin cargo build, jadi
sekarang kita punya file ini di direktori guessing_game.
Pas kita build project buat pertama kali, Cargo cari tau semua versi dependensi yang cocok sama kriterianya terus nulis versi itu ke file Cargo.lock. Pas kita build project-nya nanti, Cargo bakal liat kalau file Cargo.lock ada terus bakal pake versi yang ditentuin di situ bukannya cari-cari versi lagi. Ini bikin kita punya reproducible build secara otomatis. Dengan kata lain, project kita bakal tetep di versi 0.8.5 sampe kita eksplisit buat upgrade, berkat file Cargo.lock. Karena file Cargo.lock itu penting buat reproducible builds, filenya sering kali dimasukan ke source control barengan sama kode project lainnya.
Update Crate buat Dapet Versi Baru
Pas kita emang mau update sebuah crate, Cargo nyediain perintah update,
yang bakal cuekin file Cargo.lock terus cari tau semua versi terbaru yang
cocok sama spesifikasi kita di Cargo.toml. Cargo terus bakal nulis versi itu
ke file Cargo.lock. Dalam hal ini, Cargo cuma bakal nyari versi yang lebih
gede dari 0.8.5 dan kurang dari 0.9.0. Kalau rand crate udah ngerilis dua
versi baru 0.8.6 dan 0.9.0, kita bakal liat output kayak gini pas jalanin
cargo update:
$ cargo update
Updating crates.io index
Locking 1 package to latest Rust 1.85.0 compatible version
Updating rand v0.8.5 -> v0.8.6 (available: v0.9.0)
Cargo cuekin rilis 0.9.0. Di titik ini, kita juga bakal nyadar ada perubahan
di file Cargo.lock yang nyatet kalau versi rand crate yang sekarang kita
pake itu 0.8.6. Buat pake rand versi 0.9.0 atau versi mana pun di seri
0.9.x, kita harus update file Cargo.toml-nya jadi kayak gini:
[dependencies]
rand = "0.9.0"
Lain kali kita jalanin cargo build, Cargo bakal update registry crate yang
tersedia terus evaluasi ulang kebutuhan rand kita sesuai versi baru yang
kita tentuin.
Masih banyak lagi hal soal Cargo dan ekosistemnya yang bakal kita bahas di Bab 14, tapi buat sekarang, itu aja yang perlu kita tau. Cargo bikin kita gampang sekali buat reuse library, jadi para Rustacean bisa nulis project kecil yang disusun dari banyak packages.
Menghasilkan Angka Random
Yuk mulai pake rand buat nge-generate angka buat ditebak. Langkah selanjutnya
adalah update src/main.rs, kayak yang ditunjukin di Listing 2-3.
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Pertama kita tambahin baris use rand::Rng;. Trait Rng nentuin methods yang
diimplementasiin sama random number generators, dan trait ini harus ada di
scope biar kita bisa pake methods itu. Bab 10 bakal bahas traits lebih detail.
Selanjutnya, kita nambahin dua baris di tengah. Di baris pertama, kita manggil
fungsi rand::thread_rng yang ngasih kita random number generator tertentu
yang bakal kita pake: yang lokal buat thread eksekusi saat ini dan dikasih
seed sama sistem operasi. Terus kita manggil method gen_range pada random
number generator-nya. Method ini didefinisiin sama trait Rng yang kita bawa
ke scope lewat statement use rand::Rng;. Method gen_range ngambil ekspresi
range sebagai argumen terus nge-generate angka random di dalem range itu. Jenis
ekspresi range yang kita pake di sini bentuknya start..=end dan inklusif
(termasuk) batas bawah sama batas atasnya, jadi kita perlu nulis 1..=100
buat minta angka antara 1 sampe 100.
Catatan: Kita nggak bakal tau gitu aja trait mana yang harus dipake sama method dan fungsi mana yang harus dipanggil dari sebuah crate, makanya tiap crate punya dokumentasi yang isinya instruksi buat pake crate itu. Fitur keren lainnya dari Cargo adalah jalanin perintah
cargo doc --openbakal build dokumentasi yang disediain sama semua dependensi kita secara lokal terus buka di browser. Kalau kita penasaran sama fitur lainnya dirandcrate, misalnya, jalanincargo doc --openterus klikranddi sidebar sebelah kiri.
Baris baru yang kedua nyetak secret number-nya. Ini berguna pas kita lagi ngembangin programnya biar bisa dites, tapi nanti kita hapus di versi final. Nggak seru dong gamenya kalau programnya langsung ngasih tau jawabannya pas baru mulai!
Coba jalanin programnya beberapa kali:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 7
Please input your guess.
4
You guessed: 4
$ cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 83
Please input your guess.
5
You guessed: 5
Kita harusnya dapet angka random yang beda-beda, dan semuanya harusnya angka antara 1 sampe 100. Mantap!
Membandingkan Tebakan dengan Secret Number
Sekarang setelah kita dapet input user sama angka random, kita bisa bandingin keduanya. Langkah itu ditunjukin di Listing 2-4. Inget ya kalau kode ini belum bisa di-compile sekarang, nanti kita jelasin kenapa.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
// --snip--
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}Pertama kita tambahin statement use lagi, bawa tipe namanya
std::cmp::Ordering ke scope dari standard library. Tipe Ordering ini adalah
enum lainnya dan punya varian Less, Greater, dan Equal. Ini adalah tiga
hasil yang mungkin terjadi pas kita bandingin dua nilai.
Terus kita tambahin lima baris baru di bawah yang pake tipe Ordering. Method
cmp bandingin dua nilai dan bisa dipanggil pada apa pun yang bisa dibandingin.
Dia ngambil reference ke apa pun yang mau kita bandingin: di sini dia bandingin
guess sama secret_number. Terus dia balikin varian dari enum Ordering yang
kita bawa ke scope tadi. Kita pake ekspresi match buat nentuin apa
yang harus dilakuin selanjutnya berdasarkan varian Ordering mana yang
dibalikin dari pemanggilan cmp sama nilai di guess dan secret_number.
Ekspresi match itu disusun dari arms. Sebuah arm isinya sebuah pattern
(pola) buat dicocokin, sama kode yang harus jalan kalau nilai yang dikasih ke
match cocok sama pattern di arm itu. Rust ngambil nilai yang dikasih ke
match terus liat tiap pattern di tiap arm secara bergantian. Pattern sama
konstruk match itu fitur Rust yang sangat kuat: mereka ngebolehin kita
mengekspresikan berbagai situasi yang mungkin dihadapi kode kita dan mastiin
kita handle semuanya. Fitur-fitur ini bakal dibahas detail di Bab 6 dan Bab 19.
Yuk kita telusuri contoh ekspresi match yang kita pake di sini. Katakanlah user
nebak 50 dan secret number yang di-generate random kali ini adalah 38.
Pas kodenya bandingin 50 sama 38, method cmp bakal balikin
Ordering::Greater karena 50 lebih besar dari 38. Ekspresi match dapet nilai
Ordering::Greater terus mulai cek tiap pattern di tiap arm. Dia liat pattern
di arm pertama, Ordering::Less, dan liat kalau nilai Ordering::Greater
nggak cocok sama Ordering::Less, jadi dia cuekin kode di arm itu terus lanjut
ke arm berikutnya. Pattern arm berikutnya itu Ordering::Greater, yang emang
cocok sama Ordering::Greater! Kode yang terkait di arm itu bakal jalan terus
nyetak Too big! ke layar. Ekspresi match berakhir setelah match pertama yang
berhasil, jadi dia nggak bakal liat arm terakhir di skenario ini.
Tapi, kode di Listing 2-4 belum bisa di-compile. Yuk kita coba:
$ cargo build
Compiling libc v0.2.86
Compiling getrandom v0.2.2
Compiling cfg-if v1.0.0
Compiling ppv-lite86 v0.2.10
Compiling rand_core v0.6.2
Compiling rand_chacha v0.3.0
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
error[E0308]: mismatched types
--> src/main.rs:23:21
|
23 | match guess.cmp(&secret_number) {
| --- ^^^^^^^^^^^^^^ expected `&String`, found `&{integer}`
| |
| arguments to this method are incorrect
|
= note: expected reference `&String`
found reference `&{integer}`
note: method defined here
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/cmp.rs:979:8
For more information about this error, try `rustc --explain E0308`.
error: could not compile `guessing_game` (bin "guessing_game") due to 1 previous error
Inti dari error-nya bilang kalau ada mismatched types (tipe nggak cocok). Rust
punya sistem tipe yang kuat dan statis. Tapi, dia juga punya type inference
(inferensi tipe). Pas kita nulis let mut guess = String::new(), Rust bisa tau
kalau guess harusnya sebuah String dan nggak maksa kita buat nulis tipenya.
Di sisi lain, secret_number itu tipe angka. Beberapa tipe angka di Rust bisa
punya nilai antara 1 sampe 100: i32, angka 32-bit; u32, angka 32-bit tanpa
tanda (unsigned); i64, angka 64-bit; dan lainnya. Kecuali ditentuin lain,
Rust default-nya ke i32, yang merupakan tipe dari secret_number kecuali kita
nambahin informasi tipe di tempat lain yang bakal bikin Rust tau tipe angka yang
beda. Alasan kenapa ada error itu karena Rust nggak bisa bandingin tipe string
sama tipe angka.
Akhirnya, kita mau convert String yang dibaca program sebagai input jadi tipe
angka biar kita bisa bandingin secara numerik sama secret number-nya. Kita
lakuin itu dengan nambahin baris ini ke body fungsi main:
Nama file: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}Barisnya adalah:
let guess: u32 = guess.trim().parse().expect("Please type a number!");Kita bikin variabel namanya guess. Tapi tunggu, bukannya programnya udah
punya variabel namanya guess? Emang punya, tapi untungnya Rust ngebolehin kita
buat shadow nilai guess yang lama sama yang baru. Shadowing ngebolehin kita
pake lagi nama variabel guess bukannya maksa kita bikin dua variabel unik,
kayak guess_str dan guess, misalnya. Kita bakal bahas ini lebih detail di
Bab 3, tapi buat sekarang, tau aja kalau fitur ini sering dipake
pas kita mau convert sebuah nilai dari satu tipe ke tipe lainnya.
Kita nge-bind variabel baru ini ke ekspresi guess.trim().parse(). guess yang
ada di ekspresi itu ngerujuk ke variabel guess asli yang isinya input sebagai
string. Method trim pada instance String bakal ngilangin whitespace apa pun
di awal dan akhir, yang emang harus kita lakuin sebelum kita bisa convert
string-nya jadi u32, yang cuma bisa berisi data numerik. User harus teken
enter buat menuhi read_line dan masukin tebakan mereka, yang
nambahin karakter baris baru (newline) ke string-nya. Misalnya, kalau user ketik
5 terus teken enter, guess bakal keliatan kayak gini:
5\n. \n itu simbol buat “newline.” (Di Windows, nekan enter
ngasilin carriage return sama newline, \r\n.) Method trim ngilangin \n
atau \r\n, hasilnya cuma 5.
Method parse pada string convert sebuah string ke tipe lain. Di sini,
kita pake itu buat convert dari string jadi angka. Kita perlu ngasih tau Rust
tipe angka pasti yang kita mau dengan pake let guess: u32. Titik dua (:)
setelah guess ngasih tau Rust kalau kita bakal annotasi tipe variabelnya.
Rust punya beberapa tipe angka bawaan; u32 yang diliat di sini adalah 32-bit
unsigned integer. Ini pilihan default yang bagus buat angka positif kecil. Kita
bakal belajar tipe angka lainnya di Bab 3.
Terus, annotasi u32 di program contoh ini dan perbandingan sama
secret_number bikin Rust tau kalau secret_number juga harusnya tipe u32.
Jadi sekarang perbandingannya bakal terjadi antara dua nilai dengan tipe yang
sama!
Method parse cuma bakal kerja pada karakter yang logisnya bisa di-convert jadi
angka, jadi dia gampang sekali bikin error. Kalau misalnya string-nya isinya
A👍%, nggak bakal ada cara buat convert itu jadi angka. Karena dia mungkin
gagal, method parse balikin tipe Result, mirip kayak method read_line (yang
udah dibahas tadi di “Menangani Potensi Gagal dengan Result”).
Kita bakal perlakukan Result ini dengan cara yang sama pake method expect
lagi. Kalau parse balikin varian Err dari Result karena dia nggak bisa
bikin angka dari string-nya, panggilan expect bakal bikin gamenya crash terus
nyetak pesan yang kita kasih. Kalau parse berhasil convert string-nya jadi
angka, dia bakal balikin varian Ok dari Result, terus expect bakal
balikin angka yang kita mau dari nilai Ok itu.
Yuk kita jalanin programnya sekarang:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.26s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 58
Please input your guess.
76
You guessed: 76
Too big!
Keren! Walaupun ada spasi yang ditambahin sebelum tebakannya, programnya tetep tau kalau user nebak 76. Jalanin programnya beberapa kali buat mastiin perilaku yang beda-beda dengan berbagai jenis input: tebak angkanya dengan bener, tebak angka yang ketinggian, sama tebak angka yang kerendahan.
Kita udah punya sebagian besar gamenya jalan sekarang, tapi user cuma bisa nebak sekali. Yuk kita ubah itu dengan nambahin loop!
Ngebolehin Banyak Tebakan dengan Looping
Keyword loop bikin loop yang nggak bakal berhenti (infinite loop). Kita bakal
tambahin loop biar user punya lebih banyak kesempatan buat nebak angkanya:
Nama file: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
// --snip--
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}
}Kayak yang kita liat, kita udah mindahin segala hal dari prompt input tebakan dan seterusnya ke dalem sebuah loop. Pastiin buat indentasi baris-baris di dalem loop-nya nambah empat spasi lagi masing-masing terus jalanin programnya lagi. Programnya sekarang bakal minta tebakan lagi selamanya, yang sebenernya malah bikin masalah baru. Kayaknya user nggak bisa quit nih!
User sebenernya selalu bisa matiin programnya pake keyboard shortcut
ctrl-c. Tapi ada cara lain buat kabur dari monster yang
nggak pernah kenyang ini, kayak yang disebutin pas bahas parse di “Membandingkan Tebakan dengan Secret Number”:
kalau user masukin jawaban yang bukan angka, programnya bakal crash. Kita bisa
manfaatin itu biar user bisa quit, kayak yang ditunjukin di sini:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.23s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 59
Please input your guess.
45
You guessed: 45
Too small!
Please input your guess.
60
You guessed: 60
Too big!
Please input your guess.
59
You guessed: 59
You win!
Please input your guess.
quit
thread 'main' panicked at src/main.rs:28:47:
Please type a number!: ParseIntError { kind: InvalidDigit }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Ngetik quit bakal bikin gamenya berhenti, tapi kayak yang kita liat, masukin
input apa pun yang bukan angka juga bakal bikin gitu. Ini kurang oke sih; kita
mau gamenya juga berhenti pas angkanya udah berhasil ditebak dengan bener.
Quit Setelah Tebakan Bener
Yuk program gamenya biar quit pas user menang dengan nambahin statement break:
Nama file: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Nambahin baris break setelah You win! bikin programnya keluar dari loop pas
user nebak secret number-nya dengan bener. Keluar dari loop juga berarti keluar
dari program, karena loop itu bagian terakhir dari main.
Menangani Input Nggak Valid
Buat makin memperhalus perilaku gamenya, bukannya nge-crash-in program pas user
input bukan angka, mendingan kita bikin gamenya cuekin input bukan angka itu
biar user bisa lanjut nebak. Kita bisa lakuin itu dengan ngerubah baris di mana
guess di-convert dari String jadi u32, kayak yang ditunjukin di Listing 2-5.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
// --snip--
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Kita ganti dari panggilan expect jadi ekspresi match biar bisa pindah dari
nge-crash pas error jadi handle error-nya. Inget kalau parse balikin tipe
Result dan Result itu enum yang punya varian Ok dan Err. Kita pake
ekspresi match di sini, kayak yang kita lakuin sama hasil Ordering dari
method cmp.
Kalau parse berhasil ngerubah string jadi angka, dia bakal balikin nilai Ok
yang isinya angka hasilnya. Nilai Ok itu bakal cocok sama pattern arm pertama,
terus ekspresi match bakal langsung balikin nilai num yang dihasilin
parse dan ditaruh di dalem nilai Ok itu. Angka itu bakal berakhir tepat di
tempat yang kita mau di variabel guess baru yang kita bikin.
Kalau parse nggak bisa ngerubah string jadi angka, dia bakal balikin nilai
Err yang isinya informasi lebih lanjut soal error-nya. Nilai Err itu nggak
cocok sama pattern Ok(num) di arm match pertama, tapi dia cocok sama
pattern Err(_) di arm kedua. Garis bawah, _, itu nilai catch-all; di
contoh ini, kita bilang kita mau nyocokin semua nilai Err, nggak peduli
informasi apa yang ada di dalemnya. Jadi programnya bakal jalanin kode arm
kedua, continue, yang ngasih tau program buat lanjut ke iterasi loop
berikutnya dan minta tebakan lagi. Jadi, secara efektif, programnya cuekin semua
error yang mungkin ditemuin parse!
Sekarang segala hal di programnya harusnya jalan sesuai harapan. Yuk coba:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 61
Please input your guess.
10
You guessed: 10
Too small!
Please input your guess.
99
You guessed: 99
Too big!
Please input your guess.
foo
Please input your guess.
61
You guessed: 61
You win!
Mantul! Dengan satu perubahan kecil terakhir, kita bakal selesein game tebak
angka ini. Inget kalau programnya masih nyetak secret number-nya. Itu emang enak
buat ngetes, tapi ngerusak gamenya. Yuk kita hapus println! yang ngeluarin
secret number itu. Listing 2-6 nunjukin kode final-nya.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Sampai titik ini, kita udah berhasil bikin game tebak angka. Selamat ya!
Ringkasan
Project ini adalah cara belajar langsung (hands-on) buat ngenalin kita ke banyak
konsep baru di Rust: let, match, fungsi, penggunaan external crates, dan
banyak lagi. Di beberapa bab ke depan, kita bakal belajar konsep-konsep ini
lebih detail. Bab 3 bahas konsep yang ada di kebanyakan bahasa pemrograman,
kayak variabel, tipe data, dan fungsi, terus nunjukin cara pakenya di Rust.
Bab 4 bahas ownership, fitur yang bikin Rust beda dari bahasa lain. Bab 5 bahas
structs sama sintaks method, terus Bab 6 jelasin gimana cara kerja enum.
Konsep Pemrograman Umum
Bab ini ngebahas konsep-konsep yang ada di hampir semua bahasa pemrograman dan gimana cara kerjanya di Rust. Banyak bahasa pemrograman yang sebenernya punya kemiripan di intinya. Nggak ada konsep di bab ini yang unik cuma buat Rust doang, tapi kita bakal bahas dalam konteks Rust dan jelasin konvensi cara pakenya.
Spesifiknya, kita bakal belajar soal variabel, tipe dasar, fungsi, komentar, sama control flow. Dasar-dasar ini bakal ada di tiap program Rust, dan mempelajarinya dari awal bakal ngasih kita pondasi yang kuat buat mulai.
Keywords
Bahasa Rust punya sekumpulan keywords yang dipesen (reserved) cuma buat dipake sama bahasanya aja, sama kayak di bahasa lain. Inget ya kalau kita nggak bisa pake kata-kata ini sebagai nama variabel atau fungsi. Kebanyakan keyword punya makna khusus, dan kita bakal pakenya buat macem-macem tugas di program Rust kita; ada beberapa yang sekarang belum ada fungsinya tapi udah di-reserve buat fitur yang mungkin ditambahin ke Rust nanti. Kita bisa liat daftar keyword-nya di Lampiran A.
Variabel dan Mutabilitas
Variabel dan Mutabilitas
Kayak yang udah disebutin di bagian “Menyimpan Nilai dengan Variabel”, secara default, variabel itu immutable (nggak bisa diubah). Ini salah satu cara Rust “nyenggol” kita buat nulis kode yang manfaatin keamanan dan kemudahan concurrency yang ditawarin Rust. Tapi, kita tetep punya opsi buat bikin variabel jadi mutable (bisa diubah). Yuk kita eksplor gimana dan kenapa Rust nyaranin kita buat lebih milih immutability, dan kenapa kadang kita malah mau milih buat nggak pakenya.
Pas sebuah variabel itu immutable, sekali nilainya di-bind ke sebuah nama,
kita nggak bisa ngerubah nilai itu. Buat gambarin ini, coba bikin project baru
namanya variables di direktori projects kita pake cargo new variables.
Terus, di direktori variables yang baru, buka src/main.rs terus ganti kodenya jadi kayak gini, yang sebenernya belum bisa di-compile sekarang:
Nama file: src/main.rs
fn main() {
let x = 5;
println!("The value of x is: {x}");
x = 6;
println!("The value of x is: {x}");
}Simpan terus jalanin programnya pake cargo run. Kita bakal dapet pesan error
soal immutability error, kayak yang ditunjukin di output ini:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0384]: cannot assign twice to immutable variable `x`
--> src/main.rs:4:5
|
2 | let x = 5;
| - first assignment to `x`
3 | println!("The value of x is: {x}");
4 | x = 6;
| ^^^^^ cannot assign twice to immutable variable
|
help: consider making this binding mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0384`.
error: could not compile `variables` (bin "variables") due to 1 previous error
Contoh ini nunjukin gimana compiler ngebantu kita nemuin error di program kita. Error dari compiler emang kadang bikin kesel, tapi sebenernya itu cuma berarti program kita belum aman buat ngelakuin apa yang kita mau; itu bukan berarti kita bukan programmer yang jago! Para Rustacean yang udah pro pun tetep sering dapet error dari compiler.
Kita dapet pesan error cannot assign twice to immutable variable `x`
karena kita nyoba buat ngasih nilai kedua ke variabel x yang immutable.
Penting sekali buat kita dapet compile-time error pas kita nyoba ngerubah nilai yang udah ditentuin sebagai immutable karena situasi ini bisa memicu bug. Kalau satu bagian kode kita jalan dengan asumsi kalau sebuah nilai nggak bakal berubah, terus bagian kode lain malah ngerubah nilai itu, ada kemungkinan bagian pertama tadi nggak bakal jalan sesuai desainnya. Penyebab bug kayak gini bisa susah sekali dilacak setelah kejadian, apalagi kalau bagian kode kedua ngerubah nilainya cuma “kadang-kadang” doang. Compiler Rust ngejamin kalau pas kita bilang sebuah nilai nggak bakal berubah, ya dia benar-benar nggak bakal berubah, jadi kita nggak perlu repot-repot jagain sendiri. Kode kita jadi lebih gampang buat dipahamin alurnya.
Tapi mutability emang bisa sangat berguna, dan bisa bikin kode lebih nyaman
buat ditulis. Walaupun variabel itu immutable secara default, kita bisa bikin
mereka jadi mutable dengan nambahin mut di depan nama variabelnya kayak yang
kita lakuin di Bab 2. Nambahin mut juga
ngasih tau maksud (intent) kita ke orang yang baca kode kita nanti kalau bagian
lain dari kode bakal ngerubah nilai variabel ini.
Contohnya, yuk kita ubah src/main.rs jadi kayak gini:
Nama file: src/main.rs
fn main() {
let mut x = 5;
println!("The value of x is: {x}");
x = 6;
println!("The value of x is: {x}");
}Pas kita jalanin programnya sekarang, hasilnya kayak gini:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/variables`
The value of x is: 5
The value of x is: 6
Kita diperbolehkan buat ngerubah nilai yang di-bind ke x dari 5 jadi 6
pas mut dipake. Akhirnya, keputusan buat pake mutability atau nggak itu
balik lagi ke kita dan tergantung apa yang menurut kita paling jelas di situasi
tertentu itu.
Konstanta (Constants)
Kayak variabel immutable, konstanta adalah nilai yang di-bind ke sebuah nama dan nggak boleh berubah, tapi ada beberapa perbedaan antara konstanta sama variabel.
Pertama, kita nggak boleh pake mut sama konstanta. Konstanta nggak cuma
immutable secara default—mereka selalu immutable. Kita mendeklarasikan
konstanta pake keyword const bukannya let, dan tipe nilainya harus
diannotasi. Kita bakal bahas soal tipe dan annotasi tipe di bagian selanjutnya,
“Tipe Data”, jadi nggak usah pusing dulu soal detailnya sekarang.
Pokoknya tau aja kalau kita harus selalu nulis tipenya.
Konstanta bisa dideklarasikan di scope mana pun, termasuk scope global, yang bikin mereka berguna buat nilai yang perlu diketahuin sama banyak bagian kode.
Perbedaan terakhir adalah konstanta cuma boleh di-set ke constant expression, bukan hasil dari nilai yang cuma bisa dihitung pas runtime.
Ini contoh deklarasi konstanta:
#![allow(unused)]
fn main() {
const THREE_HOURS_IN_SECONDS: u32 = 60 * 60 * 3;
}Nama konstantanya adalah THREE_HOURS_IN_SECONDS dan nilainya di-set ke hasil
perkalian 60 (jumlah detik dalam satu menit) dikali 60 (jumlah menit dalam satu
jam) dikali 3 (jumlah jam yang mau kita itung di program ini). Konvensi
penamaan Rust buat konstanta adalah pake huruf kapital semua (uppercase) dengan
garis bawah (underscore) di antara kata-katanya. Compiler bisa nge-evaluasi
sekumpulan operasi terbatas pas compile time, yang bikin kita bisa milih buat
nulis nilai ini dengan cara yang lebih gampang dipahamin dan diverifikasi,
bukannya langsung nulis nilai 10.800. Liat bagian Rust Reference soal constant
evaluation buat info lebih lanjut soal operasi apa aja yang bisa
dipake pas deklarasi konstanta.
Konstanta itu valid selama program jalan, di dalem scope tempat mereka dideklarasikan. Sifat ini bikin konstanta berguna buat nilai di domain aplikasi kita yang mungkin perlu diketahuin sama banyak bagian program, kayak jumlah poin maksimal yang boleh didapet player sebuah game, atau kecepatan cahaya.
Ngambil nilai hardcoded yang dipake di seluruh program terus dikasih nama sebagai konstanta itu sangat berguna buat nyampein makna nilai itu ke orang yang bakal maintain kodenya nanti. Ini juga ngebantu biar cuma ada satu tempat di kode kita yang perlu diubah kalau nilai hardcoded itu perlu di-update di masa depan.
Shadowing
Kayak yang kita liat di tutorial game tebak angka di Bab 2,
kita bisa mendeklarasikan variabel baru dengan nama yang sama kayak variabel
sebelumnya. Para Rustacean bilang kalau variabel pertama itu di-shadow
(dibayangi) sama variabel kedua, yang artinya variabel kedua lah yang bakal
diliat sama compiler pas kita pake nama variabel itu. Efektifnya, variabel
kedua menutupi variabel pertama, ngambil semua penggunaan nama variabel itu buat
dirinya sendiri sampe dia sendiri di-shadow atau scope-nya abis. Kita bisa
nge-shadow sebuah variabel dengan pake nama variabel yang sama dan ngulangin
penggunaan keyword let kayak gini:
Nama file: src/main.rs
fn main() {
let x = 5;
let x = x + 1;
{
let x = x * 2;
println!("The value of x in the inner scope is: {x}");
}
println!("The value of x is: {x}");
}Program ini pertama-tama nge-bind x ke nilai 5. Terus dia bikin variabel
baru x dengan ngulangin let x =, ngambil nilai aslinya terus ditambahin 1
biar nilai x jadi 6. Terus, di dalem scope dalem yang dibuat pake kurung
kurawal, statement let yang ketiga juga nge-shadow x dan bikin variabel
baru, ngaliin nilai sebelumnya sama 2 biar x jadi 12. Pas scope itu abis,
shadowing dalemnya kelar dan x balik lagi jadi 6. Pas kita jalanin
program ini, output-nya bakal kayak gini:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/variables`
The value of x in the inner scope is: 12
The value of x is: 6
Shadowing itu beda sama nandain variabel sebagai mut karena kita bakal dapet
compile-time error kalau kita nggak sengaja nyoba buat nge-assign ulang ke
variabel ini tanpa pake keyword let. Dengan pake let, kita bisa ngelakuin
beberapa transformasi pada sebuah nilai tapi tetep bikin variabelnya jadi
immutable setelah transformasi itu selesai.
Perbedaan lain antara mut sama shadowing adalah karena kita sebenernya bikin
variabel baru pas kita pake keyword let lagi, kita bisa ngerubah tipe nilainya
tapi tetep pake nama yang sama. Misalnya, katakanlah program kita minta user
buat nunjukin berapa banyak spasi yang mereka mau di antara teks dengan masukin
karakter spasi, terus kita mau nyimpen input itu sebagai angka:
fn main() {
let spaces = " ";
let spaces = spaces.len();
}Variabel spaces yang pertama itu tipe string dan variabel spaces yang kedua
itu tipe angka. Jadi shadowing bikin kita nggak perlu repot mikirin nama yang
beda, kayak spaces_str dan spaces_num; mendingan kita pake lagi nama
spaces yang lebih simpel. Tapi, kalau kita nyoba pake mut buat hal ini,
kayak yang ditunjukin di sini, kita bakal dapet compile-time error:
fn main() {
let mut spaces = " ";
spaces = spaces.len();
}Error-nya bilang kalau kita nggak diperbolehkan buat nge-mutasi tipe variabel:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0308]: mismatched types
--> src/main.rs:3:14
|
2 | let mut spaces = " ";
| ----- expected due to this value
3 | spaces = spaces.len();
| ^^^^^^^^^^^^ expected `&str`, found `usize`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `variables` (bin "variables") due to 1 previous error
Sekarang setelah kita eksplor gimana cara kerja variabel, yuk kita liat tipe data lainnya yang bisa mereka punya.
Tipe Data
Tipe Data
Tiap nilai di Rust itu punya data type (tipe data) tertentu, yang ngasih tau Rust jenis data apa yang kita maksud biar dia tau gimana cara nanganin data itu. Kita bakal liat dua subset tipe data: scalar sama compound.
Inget ya kalau Rust itu bahasa yang statically typed, artinya dia harus tau
tipe dari semua variabel pas compile time. Compiler biasanya bisa tau (infer)
tipe apa yang mau kita pake berdasarkan nilainya dan gimana kita pakenya. Di
kasus di mana ada banyak kemungkinan tipe, kayak pas kita convert sebuah
String jadi tipe numerik pake parse di bagian “Membandingkan Tebakan dengan Secret Number”
di Bab 2, kita harus nambahin annotasi tipe, kayak gini:
#![allow(unused)]
fn main() {
let guess: u32 = "42".parse().expect("Bukan angka!");
}Kalau kita nggak nambahin annotasi tipe : u32 kayak di atas, Rust bakal
nampilin error berikut, yang artinya compiler butuh info lebih lanjut dari
kita biar tau tipe mana yang mau kita pake:
$ cargo build
Compiling no_type_annotations v0.1.0 (file:///projects/no_type_annotations)
error[E0284]: type annotations needed
--> src/main.rs:2:9
|
2 | let guess = "42".parse().expect("Not a number!");
| ^^^^^ ----- type must be known at this point
|
= note: cannot satisfy `<_ as FromStr>::Err == _`
help: consider giving `guess` an explicit type
|
2 | let guess: /* Type */ = "42".parse().expect("Not a number!");
| ++++++++++++
For more information about this error, try `rustc --explain E0284`.
error: could not compile `no_type_annotations` (bin "no_type_annotations") due to 1 previous error
Kita bakal liat annotasi tipe yang beda buat tipe data lainnya.
Tipe Scalar
Tipe scalar merepresentasikan sebuah nilai tunggal. Rust punya empat tipe scalar utama: integer, floating-point numbers, Boolean, dan karakter. Kita mungkin udah kenal ini dari bahasa pemrograman lain. Yuk kita liat gimana cara kerjanya di Rust.
Tipe Integer
Integer itu angka tanpa komponen pecahan. Kita udah pake satu tipe integer di
Bab 2, yaitu tipe u32. Deklarasi tipe ini nunjukin kalau nilai yang terkait
harusnya sebuah unsigned integer (tipe signed integer diawali sama i
bukannya u) yang makan tempat 32 bits. Tabel 3-1 nunjukin tipe-tipe integer
bawaan di Rust. Kita bisa pake varian mana pun dari ini buat mendeklarasikan
tipe dari sebuah nilai integer.
Tabel 3-1: Tipe Integer di Rust
| Panjang | Signed | Unsigned |
|---|---|---|
| 8-bit | i8 | u8 |
| 16-bit | i16 | u16 |
| 32-bit | i32 | u32 |
| 64-bit | i64 | u64 |
| 128-bit | i128 | u128 |
| architecture dependent | isize | usize |
Tiap varian bisa jadi signed atau unsigned dan punya ukuran yang eksplisit. Signed sama unsigned ngerujuk ke apakah mungkin buat angkanya bernilai negatif—dengan kata lain, apakah angkanya perlu punya tanda (sign) barengannya (signed) atau apakah dia cuma bakal selalu positif dan makanya bisa direpresentasikan tanpa tanda (unsigned). Ini kayak nulis angka di kertas: pas tandanya penting, angka ditunjukin pake tanda plus atau minus; tapi pas aman buat diasumsikan kalau angkanya positif, dia ditunjukin tanpa tanda. Angka signed disimpan pake representasi two’s complement.
Tiap varian signed bisa nyimpen angka dari −(2n − 1) sampe
2n − 1 − 1 inklusif, di mana n itu jumlah bit yang dipake varian
tersebut. Jadi sebuah i8 bisa nyimpen angka dari −(27) sampe
27 − 1, yang sama dengan −128 sampe 127. Varian unsigned bisa
nyimpen angka dari 0 sampe 2n − 1, jadi sebuah u8 bisa nyimpen
angka dari 0 sampe 28 − 1, yang sama dengan 0 sampe 255.
Terus, tipe isize sama usize itu tergantung dari arsitektur komputer tempat
program kita jalan: 64 bits kalau kita di arsitektur 64-bit dan 32 bits kalau
kita di arsitektur 32-bit.
Kita bisa nulis literal integer dalam bentuk apa pun yang ditunjukin di Tabel 3-2.
Inget ya kalau literal angka yang bisa punya banyak tipe numerik ngebolehin ada
akhiran (suffix) tipe, kayak 57u8, buat nentuin tipenya. Literal angka juga
bisa pake _ sebagai pemisah visual biar angkanya lebih gampang dibaca, kayak
1_000, yang bakal punya nilai yang sama kayak kalau kita tulis 1000.
Tabel 3-2: Literal Integer di Rust
| Literal Angka | Contoh |
|---|---|
| Desimal | 98_222 |
| Hex | 0xff |
| Oktal | 0o77 |
| Biner | 0b1111_0000 |
Byte (u8 doang) | b'A' |
Terus gimana kita tau tipe integer mana yang harus dipake? Kalau bingung,
default-nya Rust biasanya udah oke sekali: tipe integer default ke i32.
Situasi utama di mana kita bakal pake isize atau usize itu pas lagi
ngindeks sekumpulan koleksi (collection).
Integer Overflow
Katakanlah kita punya variabel tipe u8 yang bisa nampung nilai antara 0
sampe 255. Kalau kita nyoba ngerubah variabel itu jadi nilai di luar range
itu, kayak 256, bakal terjadi integer overflow, yang bisa ngasilin salah
satu dari dua perilaku. Pas kita compile di mode debug, Rust masukin
pengecekan buat integer overflow yang bikin program kita panic pas
runtime kalau perilaku ini kejadian. Rust pake istilah panicking pas
sebuah program exit karena error; kita bakal bahas panic lebih dalem di
bagian “Error yang Tidak Bisa Dipulihkan dengan panic!”
di Bab 9.
Pas kita compile di mode release pake flag --release, Rust nggak
masukin pengecekan buat integer overflow yang bikin panic. Sebaliknya,
kalau overflow kejadian, Rust ngelakuin two’s complement wrapping.
Singkatnya, nilai yang lebih gede dari nilai maksimal yang bisa ditampung
tipenya bakal “bungkus muter” (wrap around) ke nilai minimal yang bisa
ditampung tipenya. Di kasus u8, nilai 256 jadi 0, nilai 257 jadi 1, dan
seterusnya. Programnya nggak bakal panic, tapi variabelnya bakal punya
nilai yang mungkin nggak sesuai ekspektasi kita. Ngandelin perilaku wrapping
dari integer overflow itu dianggap sebagai error.
Buat handle kemungkinan overflow secara eksplisit, kita bisa pake keluarga method yang dikasih standard library buat tipe numerik primitif:
- Wrap di semua mode pake method
wrapping_*, kayakwrapping_add. - Balikin nilai
Nonekalau ada overflow pake methodchecked_*. - Balikin nilainya sama Boolean yang nunjukin apakah ada overflow pake
method
overflowing_*. - Saturate di nilai minimal atau maksimal tipenya pake method
saturating_*.
Tipe Floating-Point
Rust juga punya dua tipe primitif buat floating-point numbers, yaitu angka
dengan titik desimal. Tipe floating-point di Rust adalah f32 dan f64,
yang masing-masing ukurannya 32 bits dan 64 bits. Tipe default-nya adalah f64
karena di CPU modern, kecepatannya hampir sama kayak f32 tapi bisa lebih
presisi. Semua tipe floating-point itu signed.
Ini contoh tipe floating-point beraksi:
Nama file: src/main.rs
fn main() {
let x = 2.0; // f64
let y: f32 = 3.0; // f32
}Angka floating-point direpresentasikan sesuai standar IEEE-754.
Operasi Numerik
Rust support operasi matematika dasar yang kita harapin buat semua tipe angka:
penambahan, pengurangan, perkalian, pembagian, dan sisa bagi (remainder).
Pembagian integer bakal dipotong (truncate) ke arah nol ke integer terdekat.
Kode berikut nunjukin gimana cara pake tiap operasi numerik di statement let:
Nama file: src/main.rs
fn main() {
// addition
let sum = 5 + 10;
// subtraction
let difference = 95.5 - 4.3;
// multiplication
let product = 4 * 30;
// division
let quotient = 56.7 / 32.2;
let truncated = -5 / 3; // Results in -1
// remainder
let remainder = 43 % 5;
}Tiap ekspresi di statement ini pake operator matematika terus dievaluasi jadi satu nilai tunggal, yang terus di-bind ke sebuah variabel. Lampiran B isinya daftar semua operator yang disediain Rust.
Tipe Boolean
Kayak di kebanyakan bahasa pemrograman lain, tipe Boolean di Rust punya dua
kemungkinan nilai: true sama false. Boolean ukurannya satu byte. Tipe
Boolean di Rust ditentuin pake bool. Contohnya:
Nama file: src/main.rs
fn main() {
let t = true;
let f: bool = false; // with explicit type annotation
}Cara utama buat pake nilai Boolean itu lewat kondisional, kayak ekspresi if.
Kita bakal bahas gimana cara kerja ekspresi if di Rust di bagian “Control Flow”.
Tipe Karakter (Character)
Tipe char di Rust adalah tipe alfabetik paling primitif di bahasanya. Ini
beberapa contoh deklarasi nilai char:
Nama file: src/main.rs
fn main() {
let c = 'z';
let z: char = 'ℤ'; // with explicit type annotation
let heart_eyed_cat = '😻';
}Inget ya kalau kita nentuin literal char pake kutip tunggal, beda sama literal
string yang pake kutip ganda. Tipe char di Rust ukurannya empat byte dan
merepresentasikan Unicode Scalar Value, yang artinya dia bisa merepresentasikan
jauh lebih banyak dari cuma ASCII doang. Huruf beraksen; karakter Cina, Jepang,
dan Korea; emoji; sama zero-width spaces itu semua adalah nilai char yang
valid di Rust. Unicode Scalar Values range-nya dari U+0000 sampe U+D7FF dan
U+E000 sampe U+10FFFF inklusif. Tapi, sebuah “karakter” itu sebenernya
bukan konsep di Unicode, jadi intuisi manusia kita soal apa itu “karakter”
mungkin nggak pas sama apa itu char di Rust. Kita bakal bahas topik ini
detail di “Menyimpan Teks Berkode UTF-8 dengan Strings” di Bab 8.
Tipe Compound
Tipe compound (campuran) bisa ngelempokin banyak nilai jadi satu tipe. Rust punya dua tipe compound primitif: tuple sama array.
Tipe Tuple
Sebuah tuple adalah cara umum buat ngelempokin sejumlah nilai dengan berbagai macam tipe jadi satu tipe compound. Tuple punya panjang yang tetap: sekali dideklarasikan, ukurannya nggak bisa nambah atau berkurang.
Kita bikin tuple dengan nulis daftar nilai yang dipisahin koma di dalem tanda kurung. Tiap posisi di tuple punya tipe, dan tipe-tipe dari nilai yang beda di tuple itu nggak harus sama. Kita udah nambahin annotasi tipe opsional di contoh ini:
Nama file: src/main.rs
fn main() {
let tup: (i32, f64, u8) = (500, 6.4, 1);
}Variabel tup nge-bind ke seluruh tuple karena sebuah tuple dianggap sebagai
elemen compound tunggal. Buat dapet nilai individunya dari sebuah tuple, kita
bisa pake pattern matching buat destructure sebuah nilai tuple, kayak gini:
Nama file: src/main.rs
fn main() {
let tup = (500, 6.4, 1);
let (x, y, z) = tup;
println!("The value of y is: {y}");
}Program ini pertama-tama bikin tuple terus nge-bind ke variabel tup. Terus
dia pake pattern bareng let buat ngambil tup terus diubah jadi tiga variabel
terpisah, x, y, dan z. Ini namanya destructuring karena dia mecah satu
tuple jadi tiga bagian. Akhirnya, programnya nyetak nilai y, yaitu 6.4.
Kita juga bisa akses elemen tuple secara langsung pake tanda titik (.) diikuti
sama indeks nilai yang mau kita akses. Contohnya:
Nama file: src/main.rs
fn main() {
let x: (i32, f64, u8) = (500, 6.4, 1);
let five_hundred = x.0;
let six_point_four = x.1;
let one = x.2;
}Program ini bikin tuple x terus akses tiap elemen tuple pake indeksnya
masing-masing. Kayak di kebanyakan bahasa pemrograman, indeks pertama di tuple
itu 0.
Tuple tanpa nilai apa pun punya nama khusus, yaitu unit. Nilai ini sama tipe
terkaitnya sama-sama ditulis () dan merepresentasikan nilai kosong atau tipe
return kosong. Ekspresi secara implisit balikin nilai unit kalau mereka nggak
balikin nilai lainnya.
Tipe Array
Cara lain buat punya sekumpulan banyak nilai itu pake array. Beda sama tuple, tiap elemen array harus punya tipe yang sama. Beda sama array di beberapa bahasa lain, array di Rust punya panjang yang tetap.
Kita nulis nilai-nilai di array sebagai daftar yang dipisahin koma di dalem kurung siku:
Nama file: src/main.rs
fn main() {
let a = [1, 2, 3, 4, 5];
}Array itu berguna pas kita mau data kita dialokasikan di stack, sama kayak tipe-tipe lain yang udah kita liat sejauh ini, bukannya di heap (kita bakal bahas stack sama heap lebih lanjut di Bab 4) atau pas kita mau mastiin kalau kita selalu punya jumlah elemen yang tetap. Tapi array itu nggak sefleksibel tipe vector. Vector adalah tipe koleksi serupa yang disediain standard library yang boleh nambah atau berkurang ukurannya karena isinya ada di heap. Kalau bingung mau pake array atau vector, kemungkinan besar mending pake vector. Bab 8 bahas vector lebih detail.
Tapi, array lebih berguna pas kita tau jumlah elemennya nggak perlu berubah. Misalnya, kalau kita lagi pake nama-nama bulan di sebuah program, kita mungkin bakal pake array bukannya vector karena kita tau isinya bakal selalu 12 elemen:
#![allow(unused)]
fn main() {
let months = ["Januari", "Februari", "Maret", "April", "Mei", "Juni", "Juli",
"Agustus", "September", "Oktober", "November", "Desember"];
}Kita nulis tipe array pake kurung siku yang isinya tipe tiap elemen, titik koma, terus jumlah elemen di array-nya, kayak gini:
#![allow(unused)]
fn main() {
let a: [i32; 5] = [1, 2, 3, 4, 5];
}Di sini, i32 itu tipe tiap elemen. Setelah titik koma, angka 5 nunjukin
kalau array-nya isinya lima elemen.
Kita juga bisa menginisialisasi array biar isinya nilai yang sama buat tiap elemen dengan nentuin nilai awalnya, diikuti titik koma, terus panjang array-nya di dalem kurung siku, kayak yang ditunjukin di sini:
#![allow(unused)]
fn main() {
let a = [3; 5];
}Array namanya a bakal isinya 5 elemen yang semuanya bakal di-set ke nilai
3 pas awal. Ini sama aja kayak nulis let a = [3, 3, 3, 3, 3]; tapi dengan
cara yang lebih singkat.
Akses Elemen Array
Array itu satu potongan memori tunggal dengan ukuran yang udah tau dan tetap yang bisa dialokasikan di stack. Kita bisa akses elemen array pake indexing, kayak gini:
Nama file: src/main.rs
fn main() {
let a = [1, 2, 3, 4, 5];
let first = a[0];
let second = a[1];
}Di contoh ini, variabel namanya first bakal dapet nilai 1 karena itu nilai
di indeks [0] di array-nya. Variabel namanya second bakal dapet nilai 2
dari indeks [1] di array-nya.
Akses Elemen Array Nggak Valid
Yuk kita liat apa yang terjadi kalau kita nyoba akses elemen array yang ngelewatin akhir dari array-nya. Katakanlah kita jalanin kode ini, mirip kayak game tebak angka di Bab 2, buat dapet indeks array dari user:
Nama file: src/main.rs
use std::io;
fn main() {
let a = [1, 2, 3, 4, 5];
println!("Please enter an array index.");
let mut index = String::new();
io::stdin()
.read_line(&mut index)
.expect("Failed to read line");
let index: usize = index
.trim()
.parse()
.expect("Index entered was not a number");
let element = a[index];
println!("The value of the element at index {index} is: {element}");
}Kode ini berhasil di-compile. Kalau kita jalanin kode ini pake cargo run terus
masukin 0, 1, 2, 3, atau 4, programnya bakal nyetak nilai yang
terkait di indeks itu di array-nya. Kalau kita malah masukin angka yang
ngelewatin akhir array, kayak 10, kita bakal liat output kayak gini:
thread 'main' panicked at src/main.rs:19:19:
index out of bounds: the len is 5 but the index is 10
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Programnya ngasilin runtime error pas lagi pake nilai nggak valid di operasi
indexing-nya. Programnya exit dengan pesan error dan nggak ngejalankan
statement println! yang terakhir. Pas kita nyoba akses sebuah elemen pake
indexing, Rust bakal nge-cek kalau indeks yang kita tentuin itu kurang dari
panjang array-nya. Kalau indeksnya lebih gede dari atau sama dengan panjangnya,
Rust bakal panic. Pengecekan ini harus kejadian pas runtime, apalagi di kasus
ini, karena compiler nggak mungkin tau nilai apa yang bakal dimasukin user
pas mereka jalanin kodenya nanti.
Ini contoh dari prinsip memory safety Rust yang lagi beraksi. Di banyak bahasa tingkat rendah (low-level), pengecekan kayak gini nggak dilakuin, dan pas kita ngasih indeks yang salah, memori yang nggak valid bisa diakses. Rust ngelindungin kita dari jenis error kayak gini dengan langsung exit bukannya ngebolehin akses memori itu terus lanjut. Bab 9 bakal bahas lebih banyak soal penanganan error di Rust dan gimana kita bisa nulis kode yang enak dibaca dan aman yang nggak panic maupun ngebolehin akses memori nggak valid.
Fungsi
Fungsi
Fungsi itu ada di mana-mana di kode Rust. Kita udah liat salah satu fungsi
paling penting di bahasanya: fungsi main, yang jadi entry point buat banyak
program. Kita juga udah liat keyword fn, yang ngebolehin kita mendeklarasikan
fungsi baru.
Kode Rust pake snake case sebagai gaya konvensional buat nama fungsi sama variabel, di mana semua hurufnya kecil (lowercase) dan pake garis bawah (underscore) buat misahin kata. Ini program yang isinya contoh definisi fungsi:
Nama file: src/main.rs
fn main() {
println!("Hello, world!");
another_function();
}
fn another_function() {
println!("Another function.");
}Kita mendefinisikan fungsi di Rust dengan nulis fn diikuti sama nama fungsi
dan tanda kurung. Kurung kurawal ngasih tau compiler di mana body fungsinya
mulai sama selesai.
Kita bisa manggil fungsi apa pun yang udah kita definisikan dengan nulis namanya
diikuti tanda kurung. Karena another_function didefinisikan di programnya,
dia bisa dipanggil dari dalem fungsi main. Inget ya kalau kita mendefinisikan
another_function setelah fungsi main di source code-nya; kita bisa aja
mendefinisikannya sebelum main juga kok. Rust nggak peduli di mana kita
mendefinisikan fungsi kita, yang penting mereka didefinisikan di suatu tempat
di scope yang bisa diliat sama pemanggilnya.
Yuk kita bikin project biner baru namanya functions buat eksplor fungsi lebih
lanjut. Taruh contoh another_function tadi di src/main.rs terus jalanin.
Kita bakal liat output kayak gini:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.28s
Running `target/debug/functions`
Hello, world!
Another function.
Baris-baris kodenya jalan sesuai urutan kemunculannya di fungsi main. Pertama
pesan “Hello, world!” dicetak, terus another_function dipanggil dan pesannya
dicetak.
Parameter
Kita bisa mendefinisikan fungsi biar punya parameter, yaitu variabel khusus yang jadi bagian dari signature sebuah fungsi. Pas sebuah fungsi punya parameter, kita bisa ngasih nilai konkret buat parameter itu. Secara teknis, nilai konkret itu namanya argument, tapi pas lagi ngobrol santai, orang-orang cenderung pake kata parameter sama argument secara bergantian buat nyebut variabel di definisi fungsi maupun nilai konkret yang dimasukin pas manggil fungsinya.
Di versi another_function ini kita nambahin satu parameter:
Nama file: src/main.rs
fn main() {
another_function(5);
}
fn another_function(x: i32) {
println!("The value of x is: {x}");
}Coba jalanin program ini; kita bakal dapet output kayak gini:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.21s
Running `target/debug/functions`
The value of x is: 5
Deklarasi another_function punya satu parameter namanya x. Tipe dari x
ditentuin sebagai i32. Pas kita masukin 5 ke another_function, macro
println! naruh 5 di tempat pasangan kurung kurawal yang isinya x di
format string-nya.
Di signature fungsi, kita harus mendeklarasikan tipe dari tiap parameter. Ini keputusan yang disengaja di desainnya Rust: nuntut annotasi tipe di definisi fungsi artinya compiler hampir nggak pernah butuh kita buat nulis tipenya di tempat lain di kode buat cari tau tipe mana yang kita maksud. Compiler juga bisa ngasih pesan error yang lebih ngebantu kalau dia tau tipe apa yang diharapin sama fungsinya.
Pas mendefinisikan banyak parameter, pisahin deklarasi parameternya pake koma, kayak gini:
Nama file: src/main.rs
fn main() {
print_labeled_measurement(5, 'h');
}
fn print_labeled_measurement(value: i32, unit_label: char) {
println!("The measurement is: {value}{unit_label}");
}Contoh ini bikin fungsi namanya print_labeled_measurement dengan dua
parameter. Parameter pertama namanya value dan tipenya i32. Yang kedua
namanya unit_label dan tipenya char. Fungsinya terus nyetak teks yang isinya
baik value maupun unit_label.
Yuk coba jalanin kode ini. Ganti program yang ada di project functions kita
di file src/main.rs sama contoh di atas terus jalanin pake cargo run:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/functions`
The measurement is: 5h
Karena kita manggil fungsinya dengan 5 sebagai nilai buat value dan 'h'
sebagai nilai buat unit_label, output programnya isinya nilai-nilai itu.
Statement dan Ekspresi (Statements and Expressions)
Body fungsi itu disusun dari serangkaian statement yang opsional bisa diakhiri sama sebuah ekspresi. Sejauh ini, fungsi-fungsi yang kita bahas belum ada ekspresi akhirnya, tapi kita udah liat ekspresi sebagai bagian dari sebuah statement. Karena Rust itu bahasa yang berbasis ekspresi (expression-based language), ini perbedaan penting yang harus dipahamin. Bahasa lain nggak punya perbedaan yang sama, jadi yuk kita liat apa itu statement sama ekspresi dan gimana perbedaannya ngaruh ke body fungsi.
- Statement adalah instruksi yang ngelakuin suatu aksi dan nggak balikin nilai.
- Ekspresi dievaluasi jadi sebuah nilai hasil.
Yuk kita liat beberapa contoh.
Sebenernya kita udah pake statement sama ekspresi. Bikin variabel terus ngasih
nilai ke variabel itu pake keyword let itu adalah sebuah statement. Di
Listing 3-1, let y = 6; adalah sebuah statement.
fn main() {
let y = 6;
}main yang isinya satu statementDefinisi fungsi juga termasuk statement; seluruh contoh di atas itu sebenernya sebuah statement. (Tapi kayak yang bakal kita liat di bawah, manggil fungsi itu bukan statement.)
Statement nggak balikin nilai. Makanya, kita nggak bisa nge-assign sebuah
statement let ke variabel lain, kayak yang dicoba sama kode berikut; kita
bakal dapet error:
Nama file: src/main.rs
fn main() {
let x = (let y = 6);
}Pas kita jalanin program ini, error yang kita dapet bakal keliatan kayak gini:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error: expected expression, found `let` statement
--> src/main.rs:2:14
|
2 | let x = (let y = 6);
| ^^^
|
= note: only supported directly in conditions of `if` and `while` expressions
warning: unnecessary parentheses around assigned value
--> src/main.rs:2:13
|
2 | let x = (let y = 6);
| ^ ^
|
= note: `#[warn(unused_parens)]` on by default
help: remove these parentheses
|
2 - let x = (let y = 6);
2 + let x = let y = 6;
|
warning: `functions` (bin "functions") generated 1 warning
error: could not compile `functions` (bin "functions") due to 1 previous error; 1 warning emitted
Statement let y = 6 nggak balikin nilai, jadi nggak ada apa-apa buat di-bind
ke x. Ini beda sama apa yang terjadi di bahasa lain, kayak C sama Ruby, di
mana assignment balikin nilai dari assignment-nya. Di bahasa-bahasa itu, kita
bisa nulis x = y = 6 terus bikin baik x maupun y punya nilai 6; hal itu
nggak berlaku di Rust.
Ekspresi dievaluasi jadi sebuah nilai dan nyusun sebagian besar sisa kode yang
bakal kita tulis di Rust. Coba pikirin operasi matematika, kayak 5 + 6, yang
merupakan ekspresi yang dievaluasi jadi nilai 11. Ekspresi bisa jadi bagian
dari statement: di Listing 3-1, angka 6 di statement let y = 6; adalah
sebuah ekspresi yang dievaluasi jadi nilai 6. Manggil fungsi itu adalah sebuah
ekspresi. Manggil macro itu adalah sebuah ekspresi. Sebuah blok scope baru yang
dibuat pake kurung kurawal juga ekspresi, contohnya:
Nama file: src/main.rs
fn main() {
let y = {
let x = 3;
x + 1
};
println!("The value of y is: {y}");
}Ekspresi ini:
{
let x = 3;
x + 1
}adalah sebuah blok yang, dalam kasus ini, dievaluasi jadi 4. Nilai itu terus
di-bind ke y sebagai bagian dari statement let. Inget ya kalau baris
x + 1 nggak punya titik koma di akhirnya, beda sama kebanyakan baris yang
udah kita liat sejauh ini. Ekspresi nggak pake titik koma di akhir. Kalau kita
nambahin titik koma di akhir ekspresi, kita ngerubahnya jadi statement, dan dia
nggak bakal balikin nilai. Terus inget ini pas kita eksplor nilai return fungsi
sama ekspresi selanjutnya.
Fungsi dengan Nilai Return
Fungsi bisa balikin nilai ke kode yang manggil mereka. Kita nggak ngasih nama
buat nilai return, tapi kita harus mendeklarasikan tipenya setelah tanda panah
(->). Di Rust, nilai return dari sebuah fungsi itu sinonim sama nilai dari
ekspresi terakhir di blok body fungsinya. Kita bisa return lebih awal dari
sebuah fungsi pake keyword return terus nentuin nilainya, tapi kebanyakan
fungsi balikin ekspresi terakhir secara implisit. Ini contoh fungsi yang
balikin nilai:
Nama file: src/main.rs
fn five() -> i32 {
5
}
fn main() {
let x = five();
println!("The value of x is: {x}");
}Nggak ada pemanggilan fungsi, macro, atau bahkan statement let di fungsi
five—cuma ada angka 5 sendirian. Itu fungsi yang sangat valid di Rust.
Inget ya kalau tipe return fungsinya ditentuin juga, yaitu -> i32. Coba
jalanin kode ini; output-nya bakal kayak gini:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/functions`
The value of x is: 5
Angka 5 di five adalah nilai return fungsinya, makanya tipe return-nya
i32. Yuk kita pelajari ini lebih detail. Ada dua bagian penting: pertama,
baris let x = five(); nunjukin kalau kita pake nilai return fungsi buat
menginisialisasi variabel. Karena fungsi five balikin 5, baris itu sama
aja kayak gini:
#![allow(unused)]
fn main() {
let x = 5;
}Kedua, fungsi five nggak punya parameter dan mendefinisikan tipe nilai
return-nya, tapi body fungsinya cuma angka 5 kesepian tanpa titik koma karena
itu adalah ekspresi yang nilainya mau kita balikin.
Yuk liat contoh lainnya:
Nama file: src/main.rs
fn main() {
let x = plus_one(5);
println!("The value of x is: {x}");
}
fn plus_one(x: i32) -> i32 {
x + 1
}Jalanin kode ini bakal nyetak The value of x is: 6. Tapi kalau kita naruh
titik koma di akhir baris yang isinya x + 1, ngerubahnya dari ekspresi jadi
statement, kita bakal dapet error:
Nama file: src/main.rs
fn main() {
let x = plus_one(5);
println!("The value of x is: {x}");
}
fn plus_one(x: i32) -> i32 {
x + 1;
}Compile kode ini ngasilin error kayak gini:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error[E0308]: mismatched types
--> src/main.rs:7:24
|
7 | fn plus_one(x: i32) -> i32 {
| -------- ^^^ expected `i32`, found `()`
| |
| implicitly returns `()` as its body has no tail or `return` expression
8 | x + 1;
| - help: remove this semicolon to return this value
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions` (bin "functions") due to 1 previous error
Pesan error utamanya, mismatched types, ngungkapin inti masalah kodenya.
Definisi fungsi plus_one bilang kalau dia bakal balikin i32, tapi statement
nggak dievaluasi jadi sebuah nilai, yang direpresentasikan sama (), yaitu tipe
unit. Makanya, nggak ada apa pun yang dibalikin, yang bertentangan sama
definisi fungsi dan ngasilin error. Di output ini, Rust ngasih pesan yang
mungkin bisa ngebantu benerin masalah ini: dia nyaranin buat ngapus titik
komanya, yang bakal benerin error-nya.
Komentar
Komentar
Semua programmer pasti pengen kodenya gampang dipahamin, tapi kadang emang butuh penjelasan tambahan. Di kasus kayak gini, programmer naruh komentar di source code mereka yang bakal dicuekin sama compiler tapi bakal berguna buat orang yang baca kodenya.
Ini contoh komentar simpel:
#![allow(unused)]
fn main() {
// hello, world
}Di Rust, gaya komentar yang idiomatik itu dimulai pake dua garis miring (//),
dan komentarnya lanjut sampe akhir baris. Buat komentar yang panjangnya lebih
dari satu baris, kita perlu masukin // di tiap barisnya, kayak gini:
#![allow(unused)]
fn main() {
// Jadi kita lagi ngerjain sesuatu yang ribet di sini, cukup panjang sampe
// kita butuh beberapa baris komentar buat jelasinnya! Fiuh! Semoga komentar
// ini bisa jelasin apa yang sebenernya lagi terjadi.
}Komentar juga bisa ditaruh di akhir baris yang isinya kode:
Nama file: src/main.rs
fn main() {
let lucky_number = 7; // I'm feeling lucky today
}Tapi kita bakal lebih sering liat komentar dipake dengan format kayak gini, di mana komentarnya ada di baris terpisah di atas kode yang lagi dianotasi:
Nama file: src/main.rs
fn main() {
// I'm feeling lucky today
let lucky_number = 7;
}Rust juga punya jenis komentar lain, yaitu documentation comments, yang bakal kita bahas di bagian “Publishing a Crate to Crates.io” di Bab 14.
Control Flow (Alur Kontrol)
Control Flow
Kemampuan buat ngejalanin kode tergantung dari apakah sebuah kondisi itu true
dan buat ngejalanin kode berulang kali pas sebuah kondisi itu true adalah blok
dasar di kebanyakan bahasa pemrograman. Konstruk paling umum yang ngebolehin
kita ngatur alur eksekusi kode Rust adalah ekspresi if sama loop.
Ekspresi if
Ekspresi if ngebolehin kita buat nyabangin kode tergantung kondisinya. Kita
ngasih sebuah kondisi terus bilang, “Kalau kondisi ini terpenuhi, jalanin blok
kode ini. Kalau nggak terpenuhi, jangan jalanin blok kode ini.”
Bikin project baru namanya branches di direktori projects kita buat eksplor
ekspresi if. Di file src/main.rs, masukin kode berikut:
Nama file: src/main.rs
fn main() {
let number = 3;
if number < 5 {
println!("condition was true");
} else {
println!("condition was false");
}
}Semua ekspresi if dimulai pake keyword if, diikuti sama sebuah kondisi. Di
kasus ini, kondisinya nge-cek apakah variabel number punya nilai kurang dari 5.
Kita taruh blok kode yang bakal jalan kalau kondisinya true tepat setelah
kondisinya di dalem kurung kurawal. Blok kode yang terkait sama kondisi di
ekspresi if kadang disebut arms (lengan), sama kayak arms di ekspresi
match yang kita bahas di bagian “Membandingkan Tebakan dengan Secret Number”
di Bab 2.
Opsionalnya, kita juga bisa masukin ekspresi else, kayak yang kita lakuin di
sini, buat ngasih program blok kode alternatif buat jalan kalau kondisinya
ternyata false. Kalau kita nggak ngasih ekspresi else dan kondisinya
false, programnya bakal langsung lewatin blok if terus lanjut ke kode
selanjutnya.
Coba jalanin kode ini; kita bakal dapet output kayak gini:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
condition was true
Yuk coba ubah nilai number jadi nilai yang bikin kondisinya false buat liat
apa yang terjadi:
fn main() {
let number = 7;
if number < 5 {
println!("condition was true");
} else {
println!("condition was false");
}
}Jalanin programnya lagi, terus liat output-nya:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
condition was false
Penting juga buat dicatet kalau kondisi di kode ini harus sebuah bool. Kalau
kondisinya bukan bool, kita bakal dapet error. Contohnya, coba jalanin kode
berikut:
Nama file: src/main.rs
fn main() {
let number = 3;
if number {
println!("number was three");
}
}Kondisi if dievaluasi jadi nilai 3 kali ini, dan Rust ngelepar error:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: mismatched types
--> src/main.rs:4:8
|
4 | if number {
| ^^^^^^ expected `bool`, found integer
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
Error-nya nunjukin kalau Rust ngarepin bool tapi dapetnya integer. Beda sama
bahasa kayak Ruby sama JavaScript, Rust nggak bakal otomatis nyoba convert tipe
non-Boolean jadi Boolean. Kita harus eksplisit dan selalu ngasih if sebuah
Boolean sebagai kondisinya. Kalau kita mau blok kode if jalan cuma pas sebuah
angka nggak sama dengan 0, misalnya, kita bisa ubah ekspresi if-nya jadi
kayak gini:
Nama file: src/main.rs
fn main() {
let number = 3;
if number != 0 {
println!("number was something other than zero");
}
}Jalanin kode ini bakal nyetak number was something other than zero.
Handle Banyak Kondisi dengan else if
Kita bisa pake banyak kondisi dengan ngelempokin if sama else di sebuah
ekspresi else if. Contohnya:
Nama file: src/main.rs
fn main() {
let number = 6;
if number % 4 == 0 {
println!("number is divisible by 4");
} else if number % 3 == 0 {
println!("number is divisible by 3");
} else if number % 2 == 0 {
println!("number is divisible by 2");
} else {
println!("number is not divisible by 4, 3, or 2");
}
}Program ini punya empat kemungkinan jalur yang bisa diambil. Setelah jalanin programnya, kita bakal liat output kayak gini:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
number is divisible by 3
Pas program ini jalan, dia cek tiap ekspresi if secara berurutan terus
ngejalanin body pertama yang kondisinya dievaluasi jadi true. Inget ya
walaupun 6 itu bisa dibagi 2, kita nggak liat output number is divisible by 2,
dan kita juga nggak liat teks number is not divisible by 4, 3, or 2 dari blok
else. Itu karena Rust cuma ngejalanin blok buat kondisi true yang pertama,
dan sekali dia nemu satu, dia bahkan nggak bakal cek sisanya.
Pake terlalu banyak ekspresi else if bisa bikin kode kita berantakan, jadi
kalau kita punya lebih dari satu, mendingan di-refactor kodenya. Bab 6 jelasin
konstruk percabangan Rust yang sangat kuat namanya match buat kasus-kasus
kayak gini.
Pake if di Statement let
Karena if itu adalah sebuah ekspresi, kita bisa pakenya di sisi kanan
statement let buat ngasih hasil kondisinya ke sebuah variabel, kayak di
Listing 3-2.
fn main() {
let condition = true;
let number = if condition { 5 } else { 6 };
println!("The value of number is: {number}");
}if ke sebuah variabelVariabel number bakal di-bind ke sebuah nilai berdasarkan hasil dari ekspresi
if. Jalanin kode ini buat liat apa yang terjadi:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/branches`
The value of number is: 5
Inget ya kalau blok kode dievaluasi jadi ekspresi terakhir di dalemnya, dan
angka sendirian itu juga sebuah ekspresi. Di kasus ini, nilai dari seluruh
ekspresi if tergantung dari blok kode mana yang jalan. Ini artinya nilai yang
berpotensi jadi hasil dari tiap arm di if harus punya tipe yang sama; di
Listing 3-2, hasil dari baik arm if maupun arm else adalah integer
i32. Kalau tipenya nggak cocok, kayak di contoh berikut, kita bakal dapet
error:
Nama file: src/main.rs
fn main() {
let condition = true;
let number = if condition { 5 } else { "six" };
println!("The value of number is: {number}");
}Pas kita nyoba compile kode ini, kita bakal dapet error. Arm if sama else
punya tipe nilai yang nggak kompatibel, dan Rust nunjukin tepat di mana letak
masalahnya di program kita:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: `if` and `else` have incompatible types
--> src/main.rs:4:44
|
4 | let number = if condition { 5 } else { "six" };
| - ^^^^^ expected integer, found `&str`
| |
| expected because of this
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
Ekspresi di blok if dievaluasi jadi integer, dan ekspresi di blok else
dievaluasi jadi string. Ini nggak bakal bisa karena variabel harus punya tipe
tunggal, dan Rust perlu tau pas compile time tipe apa variabel number itu,
secara definitif. Tau tipe dari number bikin compiler bisa verifikasi kalau
tipenya valid di mana pun kita pake number. Rust nggak bakal bisa ngelakuin
itu kalau tipe number cuma bisa ditentuin pas runtime; compiler-nya bakal
jadi lebih ribet dan bakal ngasih jaminan yang lebih dikit soal kodenya kalau
dia harus jagain banyak tipe hipotetis buat variabel apa pun.
Pengulangan dengan Loops
Sering kali berguna buat ngejalanin sebuah blok kode lebih dari sekali. Buat tugas ini, Rust nyediain beberapa jenis loops, yang bakal ngejalanin kode di dalem body loop sampe selesai terus langsung mulai lagi dari awal. Buat eksperimen sama loops, yuk kita bikin project baru namanya loops.
Rust punya tiga jenis loop: loop, while, dan for. Yuk kita coba satu-satu.
Ngulang Kode pake loop
Keyword loop ngasih tau Rust buat ngejalanin sebuah blok kode terus-menerus
selamanya sampe kita eksplisit nyuruh dia berhenti.
Sebagai contoh, ubah file src/main.rs di direktori loops kita jadi kayak gini:
Nama file: src/main.rs
fn main() {
loop {
println!("again!");
}
}Pas kita jalanin program ini, kita bakal liat again! dicetak terus-menerus
tanpa henti sampe kita stop programnya secara manual. Kebanyakan terminal
support keyboard shortcut ctrl-c buat interupsi program
yang terjebak di loop terus-menerus. Cobain deh:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/loops`
again!
again!
again!
again!
^Cagain!
Simbol ^C merepresentasikan di mana kita teken ctrl-c.
Kita mungkin liat atau nggak liat kata again! dicetak setelah ^C, tergantung
di mana kodenya lagi ada di dalem loop pas dia nerima sinyal interupsi.
Untungnya, Rust juga nyediain cara buat keluar dari loop pake kode. Kita bisa
naruh keyword break di dalem loop buat ngasih tau program kapan harus berhenti
ngejalanin loop-nya. Inget kan kita udah lakuin ini di game tebak angka di bagian
“Quit Setelah Tebakan Bener” di Bab 2 buat
keluar dari program pas user menangin gamenya dengan nebak angka yang bener.
Kita juga pake continue di game tebak angka, yang di dalem loop ngasih tau
program buat lewatin sisa kode di iterasi loop ini terus lanjut ke iterasi
berikutnya.
Balikin Nilai dari Loops
Salah satu kegunaan loop itu buat nyoba lagi sebuah operasi yang kita tau
mungkin gagal, kayak nge-cek apakah sebuah thread udah kelar tugasnya. Kita
mungkin juga perlu masukin hasil dari operasi itu keluar dari loop ke sisa kode
kita. Buat lakuin ini, kita bisa nambahin nilai yang mau dibalikin setelah
ekspresi break yang kita pake buat stop loop-nya; nilai itu bakal dibalikin
keluar dari loop biar bisa kita pake, kayak yang ditunjukin di sini:
fn main() {
let mut counter = 0;
let result = loop {
counter += 1;
if counter == 10 {
break counter * 2;
}
};
println!("The result is {result}");
}Sebelum loop, kita mendeklarasikan variabel namanya counter terus
diinisialisasi jadi 0. Terus kita mendeklarasikan variabel namanya result
buat nampung nilai yang dibalikin dari loop. Di tiap iterasi loop-nya, kita
nambahin 1 ke variabel counter, terus cek apakah counter sama dengan
10. Pas udah sama, kita pake keyword break bareng nilai counter * 2.
Setelah loop, kita pake titik koma buat ngakhiri statement yang ngasih nilainya
ke result. Akhirnya, kita nyetak nilai di result, yang di kasus ini
hasilnya 20.
Kita juga bisa return dari dalem loop. Kalau break cuma keluar dari loop
saat ini, return bakal selalu keluar dari fungsi saat ini.
Loop Labels buat Bedain Banyak Loops
Kalau kita punya loop di dalem loop, break sama continue berlaku buat loop
paling dalem di titik itu. Kita opsional bisa nentuin loop label di sebuah
loop yang terus bisa kita pake bareng break atau continue buat nentuin
kalau keyword itu berlaku buat loop yang dikasih label bukannya loop paling
dalem. Loop label harus dimulai pake kutip tunggal. Ini contoh dengan dua loop
bersarang:
fn main() {
let mut count = 0;
'counting_up: loop {
println!("count = {count}");
let mut remaining = 10;
loop {
println!("remaining = {remaining}");
if remaining == 9 {
break;
}
if count == 2 {
break 'counting_up;
}
remaining -= 1;
}
count += 1;
}
println!("End count = {count}");
}Loop luarnya punya label 'counting_up, dan dia bakal ngitung dari 0 sampe 2.
Loop dalemnya tanpa label ngitung mundur dari 10 sampe 9. break pertama yang
nggak nentuin label cuma bakal keluar dari loop dalem aja. Statement
break 'counting_up; bakal keluar dari loop luar. Kode ini nyetak:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.58s
Running `target/debug/loops`
count = 0
remaining = 10
remaining = 9
count = 1
remaining = 10
remaining = 9
count = 2
remaining = 10
End count = 2
Conditional Loops dengan while
Sebuah program sering kali perlu nge-evaluasi sebuah kondisi di dalem loop. Pas
kondisinya true, loop-nya jalan. Pas kondisinya udah nggak true lagi,
programnya manggil break, yang stop loop-nya. Mungkin aja buat
mengimplementasikan perilaku kayak gini pake kombinasi loop, if, else,
sama break; kita bisa cobain itu sekarang di sebuah program kalau mau. Tapi,
pola ini saking umumnya sampe Rust punya konstruk bahasa bawaan buat itu,
namanya while loop. Di Listing 3-3, kita pake while buat ngulang programnya
tiga kali, ngitung mundur tiap kalinya, terus setelah loop-nya kelar, nyetak
pesan terus exit.
fn main() {
let mut number = 3;
while number != 0 {
println!("{number}!");
number -= 1;
}
println!("LIFTOFF!!!");
}while loop buat jalanin kode pas sebuah kondisi dievaluasi jadi true outdoorKonstruk ini ngilangin banyak nesting (sarang) yang bakal diperluin kalau kita
pake loop, if, else, sama break, dan dia lebih jelas. Selama sebuah
kondisi dievaluasi jadi true, kodenya jalan; kalau nggak, dia keluar dari
loop.
Looping Lewat Koleksi dengan for
Kita bisa milih buat pake konstruk while buat looping elemen-elemen dari
sebuah koleksi, kayak array. Contohnya, loop di Listing 3-4 nyetak tiap elemen
di array a.
fn main() {
let a = [10, 20, 30, 40, 50];
let mut index = 0;
while index < 5 {
println!("the value is: {}", a[index]);
index += 1;
}
}while loopDi sini, kodenya ngitung naik lewat elemen-elemen di array-nya. Dia mulai di
indeks 0, terus looping sampe nyampe indeks terakhir di array-nya (yaitu pas
index < 5 udah nggak true lagi). Jalanin kode ini bakal nyetak tiap elemen
di array:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.32s
Running `target/debug/loops`
the value is: 10
the value is: 20
the value is: 30
the value is: 40
the value is: 50
Semua lima nilai array muncul di terminal, sesuai ekspektasi. Walaupun index
bakal nyampe nilai 5 di suatu titik, loop-nya berhenti jalan sebelum nyoba
ngambil nilai keenam dari array-nya.
Tapi, pendekatan ini gampang bikin error; kita bisa bikin programnya panic
kalau nilai indeks atau kondisi tes-nya salah. Misalnya, kalau kita ngerubah
definisi array a jadi punya empat elemen tapi lupa update kondisinya jadi
while index < 4, kodenya bakal panic. Dia juga pelan, karena compiler
nambahin kode runtime buat ngelakuin pengecekan kondisional apakah indeksnya
masih di dalem batas array-nya di tiap iterasi loop-nya.
Sebagai alternatif yang lebih singkat, kita bisa pake for loop terus
ngejalanin kode buat tiap item di koleksi. for loop keliatannya kayak kode di
Listing 3-5.
fn main() {
let a = [10, 20, 30, 40, 50];
for element in a {
println!("the value is: {element}");
}
}for loopPas kita jalanin kode ini, kita bakal liat output yang sama kayak di Listing 3-4.
Yang lebih penting, sekarang kita udah ningkatin keamanan kodenya dan ngilangin
kemungkinan bug yang bisa hasil dari ngelewatin akhir array atau nggak cukup
jauh dan ngelewatin beberapa item. Kode mesin yang dihasilin dari for loops
juga bisa lebih efisien, karena indeksnya nggak perlu dibandingin sama panjang
array-nya di tiap iterasi.
Pake for loop, kita nggak perlu repot-repot ngerubah kode lain kalau kita
ngerubah jumlah nilai di array-nya, beda sama metode yang dipake di Listing 3-4.
Keamanan sama kesingkatan for loops bikin mereka jadi konstruk loop yang
paling sering dipake di Rust. Bahkan di situasi di mana kita mau ngejalanin kode
sejumlah kali tertentu, kayak di contoh hitung mundur yang pake while loop di
Listing 3-3, kebanyakan Rustacean bakal pake for loop. Caranya adalah pake
Range, yang disediain sama standard library, yang nge-generate semua angka
secara berurutan mulai dari satu angka dan berakhir sebelum angka lainnya.
Ini penampakan hitung mundur kalau pake for loop sama metode lain yang belum
kita bahas, rev, buat nge-reverse (balikin) range-nya:
Nama file: src/main.rs
fn main() {
for number in (1..4).rev() {
println!("{number}!");
}
println!("LIFTOFF!!!");
}Kode ini jauh lebih keren, kan?
Ringkasan
Kita berhasil! Ini bab yang lumayan gede: kita udah belajar soal variabel,
tipe data scalar sama compound, fungsi, komentar, ekspresi if, sama loop!
Buat latihan konsep-konsep yang dibahas di bab ini, coba bikin program buat
ngelakuin hal-hal berikut:
- Convert temperatur antara Fahrenheit sama Celsius.
- Generate angka Fibonacci ke-n.
- Nyetak lirik lagu Natal “The Twelve Days of Christmas,” manfaatin pengulangan yang ada di lagunya.
Pas kita udah siap buat lanjut, kita bakal bahas konsep di Rust yang nggak umum ada di bahasa pemrograman lain: ownership.
Memahami Ownership
Ownership (Kepemilikan) adalah fitur paling unik di Rust dan punya pengaruh yang sangat dalem buat sisa bahasanya. Fitur ini bikin Rust bisa ngasih jaminan memory safety tanpa butuh garbage collector, jadi penting sekali buat kita paham gimana cara kerja ownership. Di bab ini, kita bakal bahas soal ownership barengan sama beberapa fitur terkait lainnya: borrowing, slices, dan gimana Rust nyusun data di memori.
Apa itu Ownership?
Apa itu Ownership?
Ownership (Kepemilikan) adalah sekumpulan aturan yang ngatur gimana program Rust ngelola memori. Semua program harus ngatur cara mereka pake memori komputer pas lagi jalan. Beberapa bahasa punya garbage collection (GC) yang secara rutin nyari memori yang udah nggak kepake pas programnya jalan; di bahasa lain, programmer harus secara eksplisit ngalokasiin dan ngebebasin memorinya. Rust pake pendekatan ketiga: memori dikelola lewat sistem ownership dengan sekumpulan aturan yang dicek sama compiler. Kalau ada aturan yang dilanggar, programnya nggak bakal ke-compile. Nggak ada satu pun fitur dari ownership yang bakal bikin program kita jadi lemot pas lagi jalan.
Karena ownership itu konsep baru buat banyak programmer, emang butuh waktu buat terbiasa. Kabar baiknya, makin kita berpengalaman sama Rust dan aturan sistem ownership-nya, kita bakal makin gampang buat nulis kode yang aman dan efisien secara alami. Semangat terus ya!
Pas kita paham ownership, kita bakal punya pondasi yang kuat buat mahamin fitur-fitur yang bikin Rust unik. Di bab ini, kita bakal belajar ownership lewat beberapa contoh yang fokus ke struktur data yang sangat umum: strings.
Stack dan Heap
Banyak bahasa pemrograman nggak nuntut kita buat sering-sering mikirin soal stack sama heap. Tapi di bahasa pemrograman sistem kayak Rust, apakah sebuah nilai ada di stack atau heap itu ngaruh ke gimana bahasanya berperilaku dan kenapa kita harus ngambil keputusan tertentu. Bagian-bagian dari ownership bakal dijelasin hubungannya sama stack dan heap nanti di bab ini, jadi ini penjelasan singkat buat persiapan.
Baik stack maupun heap adalah bagian dari memori yang tersedia buat dipake kode kita pas runtime, tapi mereka disusun dengan cara yang beda. Stack nyimpen nilai sesuai urutan yang dia dapet terus ngapus nilainya dengan urutan kebalikannya. Ini disebut last in, first out (LIFO). Bayangin tumpukan piring: pas kita nambahin piring lagi, kita taruh di atas tumpukannya, dan pas kita butuh piring, kita ambil satu dari paling atas. Nambahin atau ngambil piring dari tengah atau bawah nggak bakal semudah itu! Nambahin data disebut pushing onto the stack, dan ngambil data disebut popping off the stack. Semua data yang disimpan di stack harus punya ukuran yang udah tau dan tetap. Data dengan ukuran yang nggak tau pas compile time atau ukuran yang mungkin berubah harus disimpan di heap.
Heap itu kurang teratur: pas kita naruh data di heap, kita minta sejumlah tempat tertentu. Memory allocator bakal nemuin tempat kosong di heap yang cukup gede, nandain tempat itu lagi dipake, terus balikin sebuah pointer, yaitu alamat dari lokasi itu. Proses ini disebut allocating on the heap dan kadang disingkat jadi allocating doang (naruh nilai ke stack nggak dianggap sebagai allocating). Karena pointer ke heap itu ukurannya udah tau dan tetap, kita bisa nyimpen pointer-nya di stack, tapi pas kita mau datanya benar-benar, kita harus ngikutin pointer-nya. Bayangin kayak duduk di restoran. Pas masuk, kita bilang jumlah orang di grup kita, terus pelayannya nemuin meja kosong yang pas buat semuanya terus nganterin kita ke sana. Kalau ada temen kita yang telat dateng, mereka bisa nanya kita duduk di mana buat nemuin kita.
Pushing to the stack itu lebih cepet daripada allocating on the heap karena allocator nggak perlu cari-cari tempat buat nyimpen data baru; lokasinya selalu di paling atas stack. Sebagai perbandingan, ngalokasiin tempat di heap butuh kerja ekstra karena allocator harus nemuin dulu tempat yang cukup gede buat nampung datanya terus ngelakuin pembukuan buat persiapan alokasi selanjutnya.
Akses data di heap umumnya lebih lambat daripada akses data di stack karena kita harus ngikutin pointer buat nyampe ke sana. Prosesor zaman sekarang bakal lebih cepet kalau mereka nggak terlalu banyak lompat-lompat di memori. Lanjutin analoginya, bayangin seorang pelayan di restoran yang ngambil orderan dari banyak meja. Bakal paling efisien kalau dia ngambil semua orderan di satu meja sebelum lanjut ke meja berikutnya. Ngambil orderan dari meja A, terus meja B, terus meja A lagi, terus meja B lagi bakal jadi proses yang jauh lebih lambat. Dengan cara yang sama, prosesor biasanya bisa ngerjain tugasnya lebih baik kalau dia kerja sama data yang deket sama data lainnya (kayak di stack) bukannya yang jauh (kayak yang mungkin terjadi di heap).
Pas kode kita manggil sebuah fungsi, nilai-nilai yang dimasukin ke fungsinya (termasuk, mungkin, pointer ke data di heap) sama variabel lokal fungsinya bakal di-push ke stack. Pas fungsinya kelar, nilai-nilai itu bakal di-pop keluar dari stack.
Mantau bagian kode mana yang lagi pake data apa di heap, minimalisir jumlah data duplikat di heap, dan ngebersihin data yang udah nggak kepake di heap biar nggak keabisan tempat adalah masalah-masalah yang diselesein sama ownership. Sekali kita paham ownership, kita nggak bakal butuh sering- sering mikirin soal stack sama heap, tapi tau kalau tujuan utama ownership adalah buat ngelola data heap bisa bantu jelasin kenapa dia cara kerjanya kayak gitu.
Aturan Ownership
Pertama, yuk kita liat aturan-aturan ownership. Inget terus aturan ini pas kita ngerjain contoh-contoh yang bakal ngejelasin aturan ini:
- Tiap nilai di Rust punya seorang owner (pemilik).
- Cuma boleh ada satu owner dalam satu waktu.
- Pas owner-nya keluar dari scope, nilainya bakal di-drop (dihapus).
Scope Variabel
Sekarang setelah kita ngelewatin sintaks dasar Rust, kita nggak bakal masukin
semua kode fn main() { di contoh-contohnya, jadi kalau kita lagi ngikutin,
pastiin buat masukin contoh-contoh berikut ke dalem fungsi main secara manual.
Hasilnya, contoh-contoh kita bakal lebih singkat, biar kita bisa fokus ke
detail aslinya bukannya kode boilerplate.
Sebagai contoh pertama dari ownership, kita bakal liat scope dari beberapa variabel. Sebuah scope adalah range di dalem program di mana sebuah item itu valid. Coba liat variabel ini:
#![allow(unused)]
fn main() {
let s = "hello";
}Variabel s ngerujuk ke sebuah literal string, di mana nilai string-nya di-hardcoded
ke teks program kita. Variabelnya valid dari titik di mana dia dideklarasikan
sampe akhir dari scope saat ini. Listing 4-1 nunjukin program dengan komentar
yang dianotasi di mana variabel s bakal valid.
fn main() {
{ // s is not valid here, since it's not yet declared
let s = "hello"; // s is valid from this point forward
// do stuff with s
} // this scope is now over, and s is no longer valid
}Dengan kata lain, ada dua titik waktu penting di sini:
- Pas
smasuk ke dalam scope, dia jadi valid. - Dia tetep valid sampe dia keluar dari scope.
Sampai titik ini, hubungan antara scope sama kapan variabel itu valid mirip
sama bahasa pemrograman lainnya. Sekarang kita bakal kembangin pemahaman ini
dengan ngenalin tipe String.
Tipe String
Buat gambarin aturan ownership, kita butuh tipe data yang lebih kompleks dari
yang udah kita bahas di bagian “Tipe Data” di Bab 3. Tipe-tipe
yang udah dibahas sebelumnya ukurannya udah tau, bisa disimpan di stack dan
di-pop keluar dari stack pas scope-nya abis, dan bisa di-copy secara cepet
dan gampang buat bikin instance baru yang independen kalau bagian kode lain
perlu pake nilai yang sama di scope yang beda. Tapi kita mau liat data yang
disimpan di heap dan eksplor gimana Rust tau kapan harus ngebersihin data itu,
dan tipe String adalah contoh yang oke sekali.
Kita bakal fokus ke bagian-bagian String yang terkait sama ownership.
Aspek-aspek ini juga berlaku buat tipe data kompleks lainnya, baik yang
disediain standard library maupun yang kita bikin sendiri. Kita bakal bahas
String lebih dalem di Bab 8.
Kita udah liat literal string, di mana nilai string-nya di-hardcoded ke program
kita. Literal string emang nyaman, tapi mereka nggak cocok buat semua situasi
di mana kita mungkin mau pake teks. Salah satu alasannya karena mereka itu
immutable. Alasan lainnya karena nggak semua nilai string bisa diketahuin pas
kita nulis kode: misalnya, gimana kalau kita mau ngambil input user terus nyimpannya?
Buat situasi kayak gini, Rust punya tipe string kedua, yaitu String. Tipe ini
ngelola data yang dialokasikan di heap dan makanya dia bisa nyimpen sejumlah
teks yang ukurannya nggak kita ketahuin pas compile time. Kita bisa bikin
sebuah String dari literal string pake fungsi from, kayak gini:
#![allow(unused)]
fn main() {
let s = String::from("hello");
}Operator titik dua ganda :: ngebolehin kita buat ngelempokin fungsi from
ini di bawah tipe String bukannya pake nama kayak string_from. Kita bakal
bahas sintaks ini lebih lanjut di bagian “Sintaks Method” di
Bab 5, dan pas kita bahas soal namespacing pake modul di “Path buat Ngerujuk Item di Pohon Modul”
di Bab 7.
Jenis string ini bisa diubah (mutated):
fn main() {
let mut s = String::from("hello");
s.push_str(", world!"); // push_str() appends a literal to a String
println!("{s}"); // this will print `hello, world!`
}Jadi, apa bedanya di sini? Kenapa String bisa diubah tapi literal nggak bisa?
Bedanya ada di gimana kedua tipe ini nanganin memori.
Memori dan Alokasi
Di kasus literal string, kita tau isinya pas compile time, jadi teksnya di-hardcoded langsung ke file executable final-nya. Ini kenapa literal string itu cepet dan efisien. Tapi sifat-sifat ini cuma dateng dari sifat immutability literal string-nya. Sayangnya, kita nggak bisa naruh sepotong memori ke dalem biner buat tiap teks yang ukurannya nggak tau pas compile time dan ukurannya mungkin berubah pas lagi jalanin programnya.
Dengan tipe String, buat support sepotong teks yang mutable dan bisa nambah
ukurannya, kita perlu ngalokasiin sejumlah memori di heap, yang nggak tau pas
compile time, buat nampung isinya. Ini artinya:
- Memorinya harus diminta dari memory allocator pas runtime.
- Kita butuh cara buat balikin memori ini ke allocator pas kita udah selese
pake
Stringkita.
Bagian pertama itu kita yang ngerjain: pas kita manggil String::from,
implementasinya minta memori yang dia butuhin. Ini hal yang cukup universal di
bahasa pemrograman.
Tapi, bagian kedua itu beda. Di bahasa yang punya garbage collector (GC), GC
bakal terus mantau dan ngebersihin memori yang udah nggak dipake lagi, dan kita
nggak perlu mikirin itu. Di kebanyakan bahasa tanpa GC, itu tanggung jawab kita
buat ngenalin kapan memori udah nggak dipake lagi terus manggil kode buat secara
eksplisit ngebebasinnya, sama kayak pas kita memintanya. Ngelakuin ini dengan
bener secara historis udah jadi masalah pemrograman yang susah. Kalau kita lupa,
kita bakal buang-buang memori. Kalau kita lakuin terlalu cepet, kita bakal punya
variabel yang nggak valid. Kalau kita lakuin dua kali, itu juga sebuah bug.
Kita perlu masangin tepat satu allocate sama tepat satu free.
Rust ngambil jalur yang beda: memorinya otomatis dibalikin begitu variabel yang
punya (owns) memori itu keluar dari scope. Ini versi contoh scope kita dari
Listing 4-1 pake String bukannya literal string:
fn main() {
{
let s = String::from("hello"); // s is valid from this point forward
// do stuff with s
} // this scope is now over, and s is no
// longer valid
}Ada titik waktu alami di mana kita bisa balikin memori yang dibutuhin String
kita ke allocator: pas s keluar dari scope. Pas sebuah variabel keluar dari
scope, Rust manggil fungsi khusus buat kita. Fungsi ini namanya drop,
dan di situlah pembuat String bisa naruh kode buat balikin memorinya. Rust
manggil drop secara otomatis di kurung kurawal tutup.
Catatan: Di C++, pola nge-dealokasi resource di akhir masa hidup sebuah item ini kadang disebut Resource Acquisition Is Initialization (RAII). Fungsi
dropdi Rust bakal terasa familiar kalau kita pernah pake pola-pola RAII.
Pola ini punya pengaruh yang sangat dalem ke gimana kode Rust ditulis. Mungkin keliatan simpel sekarang, tapi perilaku kodenya bisa jadi nggak terduga di situasi yang lebih ribet pas kita mau punya banyak variabel pake data yang udah kita alokasiin di heap. Yuk kita eksplor beberapa situasi itu sekarang.
Interaksi Variabel dan Data dengan Move
Beberapa variabel bisa berinteraksi sama data yang sama dengan berbagai cara di Rust. Yuk kita liat contoh pake integer di Listing 4-2.
fn main() {
let x = 5;
let y = x;
}x ke yKita mungkin bisa nebak apa yang dilakuin kode ini: “bind nilai 5 ke x; terus
bikin copy dari nilai di x terus bind ke y.” Kita sekarang punya dua
variabel, x sama y, dan keduanya sama dengan 5. Ini emang bener yang
terjadi, karena integer adalah nilai simpel dengan ukuran yang udah tau dan
tetap, dan dua nilai 5 ini di-push ke stack.
Sekarang yuk liat versi String-nya:
fn main() {
let s1 = String::from("hello");
let s2 = s1;
}Ini keliatannya mirip sekali, jadi kita mungkin asumsikan kalau cara kerjanya
bakal sama: yaitu, baris kedua bakal bikin copy dari nilai di s1 terus bind
ke s2. Tapi nggak gitu yang sebenernya terjadi.
Coba liat Gambar 4-1 buat liat apa yang terjadi di String di balik layar.
Sebuah String disusun dari tiga bagian, yang ditunjukin di sebelah kiri:
sebuah pointer ke memori yang nampung isi string-nya, sebuah length (panjang),
dan sebuah capacity (kapasitas). Grup data ini disimpan di stack. Di sebelah
kanan adalah memori di heap yang nampung isinya.

Gambar 4-1: Representasi di memori dari sebuah String
yang nampung nilai "hello" yang di-bind ke s1
Length itu seberapa banyak memori, dalam byte, yang lagi dipake isinya
String saat ini. Capacity itu total jumlah memori, dalam byte, yang diterima
String dari allocator. Perbedaan antara length sama capacity itu penting,
tapi nggak di konteks ini, jadi buat sekarang, cuekin aja capacity-nya.
Pas kita nge-assign s1 ke s2, data String-nya di-copy, artinya kita copy
pointer, length, dan capacity yang ada di stack. Kita nggak copy data
yang ada di heap yang dirujuk sama pointer-nya. Dengan kata lain,
representasi data di memori keliatannya kayak Gambar 4-2.

Gambar 4-2: Representasi di memori dari variabel s2
yang punya copy dari pointer, length, dan capacity dari s1
Representasinya nggak keliatan kayak Gambar 4-3, yang merupakan penampakan
memori kalau misalnya Rust malah ikut copy data heap-nya juga. Kalau Rust
lakuin ini, operasi s2 = s1 bisa jadi sangat mahal dalam hal performa
Pas runtime kalau datanya di heap itu sangat besar.

Gambar 4-3: Kemungkinan lain soal apa yang mungkin
dilakuin s2 = s1 kalau Rust ikut copy data heap-nya juga
Tadi kita bilang kalau pas sebuah variabel keluar dari scope, Rust otomatis
manggil fungsi drop dan ngebersihin memori heap buat variabel itu. Tapi
Gambar 4-2 nunjukin kedua pointer data nunjuk ke lokasi yang sama. Ini masalah:
pas s2 sama s1 keluar dari scope, mereka berdua bakal nyoba buat ngebebasin
memori yang sama. Ini dikenal sebagai double free error dan merupakan salah
satu bug memory safety yang kita sebutin sebelumnya. Ngebebasin memori dua
kali bisa bikin kerusakan memori (memory corruption), yang berpotensi memicu
kerentanan keamanan.
Buat mastiin keamanan memori, setelah baris let s2 = s1;, Rust nganggep s1
udah nggak valid lagi. Makanya, Rust nggak perlu ngebebasin apa pun pas s1
keluar dari scope. Coba liat apa yang terjadi pas kita nyoba pake s1 setelah
s2 dibuat; nggak bakal bisa:
fn main() {
let s1 = String::from("hello");
let s2 = s1;
println!("{s1}, world!");
}Kita bakal dapet error kayak gini karena Rust ngelarang kita pake referensi yang udah nggak valid:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:5:16
|
2 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{s1}, world!");
| ^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
3 | let s2 = s1.clone();
| ++++++++
For more information about this error, try `rustc --explain E0382`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Kalau kita pernah denger istilah shallow copy (copy dangkal) sama deep copy
(copy dalem) pas lagi belajar bahasa lain, konsep nyalin pointer, length,
dan capacity tanpa nyalin datanya mungkin kedengeran kayak lagi bikin shallow
copy. Tapi karena Rust juga ngebatalin variabel pertamanya, bukannya disebut
shallow copy, ini dikenal sebagai move (pindah). Di contoh ini, kita bakal
bilang kalau s1 udah di-move ke dalem s2. Jadi, apa yang benar-benar terjadi
ditunjukin di Gambar 4-4.

Gambar 4-4: Representasi di memori setelah s1 udah
dibatalkan
Itu nyelesein masalah kita! Dengan cuma s2 yang valid, pas dia keluar dari
scope cuma dia sendiri yang bakal ngebebasin memorinya, dan beres deh.
Sebagai tambahan, ada pilihan desain yang tersirat dari sini: Rust nggak bakal pernah otomatis bikin “deep” copy dari data kita. Makanya, penyalinan otomatis apa pun bisa diasumsikan nggak mahal dalam hal performa pas runtime.
Scope dan Assignment
Kebalikan dari ini juga bener buat hubungan antara scoping, ownership, dan
memori yang dibebasin lewat fungsi drop juga. Pas kita ngasih nilai yang
bener-bener baru ke variabel yang udah ada, Rust bakal manggil drop dan
ngebebasin memori nilai aslinya langsung. Coba liat kode ini, contohnya:
fn main() {
let mut s = String::from("hello");
s = String::from("ahoy");
println!("{s}, world!");
}Kita awalnya mendeklarasikan variabel s terus di-bind ke sebuah String
dengan nilai "hello". Terus kita langsung bikin String baru dengan nilai
"ahoy" terus di-assign ke s. Di titik ini, nggak ada apa pun yang ngerujuk
ke nilai asli di heap sama sekali.

Gambar 4-5: Representasi di memori setelah nilai awal udah diganti seluruhnya.
String aslinya makanya langsung keluar dari scope. Rust bakal jalanin fungsi
drop padanya dan memorinya bakal langsung dibebasin. Pas kita nyetak nilainya
di akhir, hasilnya bakal "ahoy, world!".
Interaksi Variabel dan Data dengan Clone
Kalau kita emang mau copy data heap dari String secara dalem (deeply copy),
nggak cuma data stack-nya aja, kita bisa pake method umum namanya clone.
Kita bakal bahas sintaks method di Bab 5, tapi karena method adalah fitur umum
di banyak bahasa pemrograman, kita mungkin udah pernah liat sebelumnya.
Ini contoh method clone beraksi:
fn main() {
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {s1}, s2 = {s2}");
}Ini jalan dengan lancar dan secara eksplisit ngasilin perilaku yang ditunjukin di Gambar 4-3, di mana data heap-nya emang ikut di-copy.
Pas kita liat pemanggilan ke clone, kita tau kalau ada sejumlah kode sembarang
yang lagi dijalankan dan kode itu mungkin mahal harganya. Ini adalah indikator
visual kalau ada sesuatu yang beda yang lagi terjadi.
Data Khusus Stack: Copy
Ada hal unik lain yang belum kita bahas. Kode yang pake integer ini—yang sebagiannya ditunjukin di Listing 4-2—jalan dan valid:
fn main() {
let x = 5;
let y = x;
println!("x = {x}, y = {y}");
}Tapi kode ini kayaknya bertentangan sama apa yang baru aja kita pelajari: kita
nggak manggil clone, tapi x tetep valid dan nggak di-move ke dalem y.
Alasannya karena tipe-tipe kayak integer yang ukurannya udah tau pas compile
time disimpan seluruhnya di stack, jadi nyalin nilai aslinya itu cepet buat
dilakuin. Itu artinya nggak ada alasan kenapa kita mau ngelarang x buat tetep
valid setelah kita bikin variabel y. Dengan kata lain, nggak ada bedanya
antara deep copy sama shallow copy di sini, jadi manggil clone nggak bakal
ngelakuin hal yang beda dari shallow copy biasa, makanya kita bisa
ngelewatinnya.
Rust punya anotasi khusus namanya trait Copy yang bisa kita taruh di tipe-tipe
yang disimpan di stack, kayak integer (kita bakal bahas traits lebih banyak
di Bab 10). Kalau sebuah tipe mengimplementasikan trait Copy,
variabel yang pakenya nggak bakal di-move, tapi lebih ke disalin secara
sepele, bikin mereka tetep valid setelah di-assign ke variabel lain.
Rust nggak bakal ngebolehin kita ngasih anotasi Copy ke sebuah tipe kalau
tipe itu, atau bagian apa pun darinya, udah mengimplementasikan trait Drop.
Kalau tipenya butuh sesuatu yang khusus terjadi pas nilainya keluar dari scope
terus kita nambahin anotasi Copy ke tipe itu, kita bakal dapet compile-time
error. Buat belajar gimana cara nambahin anotasi Copy ke tipe kita buat
mengimplementasikan trait-nya, liat “Derivable Traits” di
Lampiran C.
Jadi, tipe apa aja yang mengimplementasikan trait Copy? Kita bisa cek
dokumentasi buat tipe tertentu buat mastiin, tapi sebagai aturan umum,
kumpulan nilai scalar simpel apa pun bisa mengimplementasikan Copy, dan nggak
ada satu pun yang butuh alokasi atau bentuk resource apa pun yang bisa
mengimplementasikan Copy. Ini beberapa tipe yang mengimplementasikan Copy:
- Semua tipe integer, kayak
u32. - Tipe Boolean,
bool, dengan nilaitruesamafalse. - Semua tipe floating-point, kayak
f64. - Tipe karakter,
char. - Tuple, kalau isinya cuma tipe-tipe yang juga mengimplementasikan
Copy. Contohnya,(i32, i32)mengimplementasikanCopy, tapi(i32, String)nggak.
Ownership dan Fungsi
Mekanisme masukin nilai ke sebuah fungsi mirip sama pas kita ngasih nilai ke sebuah variabel. Masukin variabel ke fungsi bakal nge-move atau copy, sama kayak assignment. Listing 4-3 punya contoh dengan beberapa anotasi yang nunjukin di mana variabel masuk dan keluar dari scope.
fn main() {
let s = String::from("hello"); // s comes into scope
takes_ownership(s); // s's value moves into the function...
// ... and so is no longer valid here
let x = 5; // x comes into scope
makes_copy(x); // Because i32 implements the Copy trait,
// x does NOT move into the function,
// so it's okay to use x afterward.
} // Here, x goes out of scope, then s. However, because s's value was moved,
// nothing special happens.
fn takes_ownership(some_string: String) { // some_string comes into scope
println!("{some_string}");
} // Here, some_string goes out of scope and `drop` is called. The backing
// memory is freed.
fn makes_copy(some_integer: i32) { // some_integer comes into scope
println!("{some_integer}");
} // Here, some_integer goes out of scope. Nothing special happens.Kalau kita nyoba pake s setelah manggil takes_ownership, Rust bakal ngelepar
compile-time error. Pengecekan statis ini ngelindungin kita dari kesalahan.
Coba tambahin kode ke main yang pake s sama x buat liat di mana kita bisa
pake mereka dan di mana aturan ownership ngelarang kita buat ngelakuin itu.
Nilai Return dan Scope
Balikin nilai (returning values) juga bisa mentransfer ownership. Listing 4-4 nunjukin contoh fungsi yang balikin sebuah nilai, dengan anotasi yang mirip kayak di Listing 4-3.
fn main() {
let s1 = gives_ownership(); // gives_ownership moves its return
// value into s1
let s2 = String::from("hello"); // s2 comes into scope
let s3 = takes_and_gives_back(s2); // s2 is moved into
// takes_and_gives_back, which also
// moves its return value into s3
} // Here, s3 goes out of scope and is dropped. s2 was moved, so nothing
// happens. s1 goes out of scope and is dropped.
fn gives_ownership() -> String { // gives_ownership will move its
// return value into the function
// that calls it
let some_string = String::from("yours"); // some_string comes into scope
some_string // some_string is returned and
// moves out to the calling
// function
}
// This function takes a String and returns a String.
fn takes_and_gives_back(a_string: String) -> String {
// a_string comes into
// scope
a_string // a_string is returned and moves out to the calling function
}Ownership sebuah variabel ngikutin pola yang sama tiap kalinya: ngasih nilai
ke variabel lain bakal nge-move nilainya. Pas sebuah variabel yang isinya
data di heap keluar dari scope, nilainya bakal dibersihin sama drop kecuali
kalau ownership datanya udah di-move ke variabel lain.
Walaupun ini jalan, ngambil ownership terus balikin lagi di tiap fungsi itu agak ribet. Gimana kalau kita mau ngebolehin sebuah fungsi pake sebuah nilai tapi nggak usah ngambil ownership-nya? Agak nyebelin kan kalau apa pun yang kita masukin juga harus dibalikin lagi kalau kita mau pake lagi, ditambah data apa pun hasil dari body fungsinya yang mungkin juga mau kita balikin.
Rust ngebolehin kita buat balikin banyak nilai pake tuple, kayak yang ditunjukin di Listing 4-5.
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("The length of '{s2}' is {len}.");
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() returns the length of a String
(s, length)
}Tapi ini terlalu banyak upacaranya (ceremony) dan kerjaan sekali buat konsep yang harusnya umum. Untungnya buat kita, Rust punya fitur buat pake sebuah nilai tanpa mentransfer ownership, namanya references (referensi).
References (Referensi) dan Borrowing (Peminjaman)
Referensi dan Borrowing
Masalah dari kode tuple di Listing 4-5 adalah kita harus balikin String-nya ke
fungsi pemanggil biar kita tetep bisa pake String-nya setelah manggil
calculate_length, soalnya String-nya udah di-move ke dalem
calculate_length. Sebagai gantinya, kita bisa ngasih sebuah referensi ke nilai
String itu. Sebuah reference (referensi) itu kayak pointer karena dia
adalah alamat yang bisa kita ikutin buat akses data yang disimpan di alamat itu;
data itu dimiliki sama variabel lain. Beda sama pointer, sebuah referensi
dijamin bakal nunjuk ke sebuah nilai yang valid dari tipe tertentu selama masa
hidup referensi itu.
Ini cara kita mendefinisikan dan pake fungsi calculate_length yang punya
referensi ke sebuah objek sebagai parameter bukannya ngambil ownership dari
nilainya:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{s1}' is {len}.");
}
fn calculate_length(s: &String) -> usize {
s.len()
}Pertama, perhatiin kalau semua kode tuple di deklarasi variabel sama nilai
return fungsi udah nggak ada. Kedua, perhatiin kalau kita masukin &s1 ke
calculate_length dan, di definisinya, kita nerima &String bukannya String.
Tanda ampersand ini merepresentasikan references, dan mereka ngebolehin kita
buat ngerujuk ke suatu nilai tanpa ngambil ownership-nya. Gambar 4-6
ngeliatin konsep ini.

Gambar 4-6: Diagram &String s yang nunjuk ke String s1
Catatan: Kebalikan dari bikin referensi pake
&adalah dereferencing, yang dilakuin pake operator dereference,*. Kita bakal liat beberapa penggunaan operator dereference di Bab 8 dan bahas detail soal dereferencing di Bab 15.
Yuk kita liat lebih deket pemanggilan fungsinya di sini:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{s1}' is {len}.");
}
fn calculate_length(s: &String) -> usize {
s.len()
}Sintaks &s1 ngebolehin kita bikin sebuah referensi yang ngerujuk ke nilai
dari s1 tapi nggak memilikinya. Karena referensinya nggak memiliki nilainya,
nilai yang dia tunjuk nggak bakal di-drop pas referensinya udah nggak dipake
lagi.
Begitu juga sama signature fungsinya yang pake & buat nunjukin kalau tipe
parameternya s itu adalah sebuah referensi. Yuk kita tambahin beberapa
anotasi penjelasan:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{s1}' is {len}.");
}
fn calculate_length(s: &String) -> usize { // s is a reference to a String
s.len()
} // Here, s goes out of scope. But because s does not have ownership of what
// it refers to, the String is not dropped.Scope di mana variabel s itu valid sama kayak scope parameter fungsi mana pun,
tapi nilai yang ditunjuk sama referensinya nggak bakal di-drop pas s udah
nggak dipake lagi, karena s nggak punya ownership. Pas fungsi punya
referensi sebagai parameter bukannya nilai aslinya, kita nggak perlu balikin
nilai-nilainya buat ngasih balik ownership, karena emang kita nggak pernah
punya ownership-nya dari awal.
Kita sebut aksi bikin referensi ini sebagai borrowing (meminjam). Kayak di dunia nyata, kalau seseorang punya sesuatu, kita bisa pinjem dari mereka. Pas udah selese, kita harus balikin. Kita nggak memilikinya.
Jadi, apa yang terjadi kalau kita nyoba ngerubah sesuatu yang kita pinjem? Coba kode di Listing 4-6. Spoiler: kodenya nggak bakal jalan!
fn main() {
let s = String::from("hello");
change(&s);
}
fn change(some_string: &String) {
some_string.push_str(", world");
}Ini error-nya:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0596]: cannot borrow `*some_string` as mutable, as it is behind a `&` reference
--> src/main.rs:8:5
|
8 | some_string.push_str(", world");
| ^^^^^^^^^^^ `some_string` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference
|
7 | fn change(some_string: &mut String) {
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Sama kayak variabel yang immutable secara default, referensi juga gitu. Kita nggak dibolehin ngerubah sesuatu yang kita punya referensinya.
Mutable References
Kita bisa benerin kode dari Listing 4-6 biar kita dibolehin ngerubah nilai yang dipinjem dengan cuma beberapa perubahan kecil yang pake mutable reference sebagai gantinya:
fn main() {
let mut s = String::from("hello");
change(&mut s);
}
fn change(some_string: &mut String) {
some_string.push_str(", world");
}Pertama kita ubah s jadi mut. Terus kita bikin sebuah mutable reference
pake &mut s pas kita manggil fungsi change, terus update signature fungsinya
biar nerima sebuah mutable reference pake some_string: &mut String. Ini
bikin keliatan jelas sekali kalau fungsi change bakal ngerubah (mutate)
nilai yang dia pinjem.
Mutable references punya satu larangan gede: kalau kita punya sebuah mutable
reference ke sebuah nilai, kita nggak boleh punya referensi lain ke nilai itu.
Kode ini yang nyoba bikin dua mutable reference ke s bakal gagal:
fn main() {
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{r1}, {r2}");
}Ini error-nya:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src/main.rs:5:14
|
4 | let r1 = &mut s;
| ------ first mutable borrow occurs here
5 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
6 |
7 | println!("{r1}, {r2}");
| -- first borrow later used here
For more information about this error, try `rustc --explain E0499`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Error ini bilang kalau kodenya nggak valid karena kita nggak bisa minjem s
sebagai mutable lebih dari sekali dalam satu waktu. Mutable borrow yang
pertama ada di r1 dan harus bertahan sampe dia dipake di println!, tapi di
antara pembuatan mutable reference itu sampe penggunaannya, kita nyoba bikin
mutable reference lain di r2 yang minjem data yang sama kayak r1.
Larangan yang nyegah banyak mutable reference ke data yang sama di waktu yang bersamaan ini ngebolehin adanya mutasi tapi dengan cara yang sangat terkontrol. Ini hal yang biasanya bikin Rustacean baru rada pusing karena kebanyakan bahasa ngebolehin kita ngerubah nilai kapan pun kita mau. Keuntungan punya larangan ini adalah Rust bisa nyegah data races pas compile time. Sebuah data race itu mirip kayak race condition dan terjadi pas tiga perilaku ini muncul:
- Dua atau lebih pointer akses data yang sama di waktu yang sama.
- Minimal salah satu dari pointer-nya dipake buat nulis ke datanya.
- Nggak ada mekanisme yang dipake buat sinkronisasi akses ke datanya.
Data races bikin perilaku yang nggak terdefinisi (undefined behavior) dan bisa susah buat didiagnosa dan diperbaiki pas kita nyoba nyari tau pas runtime; Rust nyegah masalah ini dengan nolak buat nge-compile kode yang punya data races!
Kayak biasa, kita bisa pake kurung kurawal buat bikin scope baru, yang ngebolehin adanya banyak mutable reference, cuma bukan yang bersamaan:
fn main() {
let mut s = String::from("hello");
{
let r1 = &mut s;
} // r1 goes out of scope here, so we can make a new reference with no problems.
let r2 = &mut s;
}Rust juga nerapin aturan yang mirip buat ngelempokin mutable sama immutable references. Kode ini ngasilin error:
fn main() {
let mut s = String::from("hello");
let r1 = &s; // no problem
let r2 = &s; // no problem
let r3 = &mut s; // BIG PROBLEM
println!("{r1}, {r2}, and {r3}");
}Ini error-nya:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:6:14
|
4 | let r1 = &s; // no problem
| -- immutable borrow occurs here
5 | let r2 = &s; // no problem
6 | let r3 = &mut s; // BIG PROBLEM
| ^^^^^^ mutable borrow occurs here
7 |
8 | println!("{r1}, {r2}, and {r3}");
| -- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Fiuh! Kita juga nggak bisa punya sebuah mutable reference pas kita lagi punya sebuah immutable reference ke nilai yang sama.
User dari sebuah immutable reference nggak bakal nyangka kalau nilainya tiba- tiba berubah gitu aja! Tapi, banyak immutable references diperbolehkan karena nggak ada orang yang cuma baca datanya punya kemampuan buat ngaruhin bacaan data orang lain.
Perhatiin ya kalau scope sebuah referensi dimulai dari tempat dia dikenalin
sampe terakhir kali referensi itu dipake. Misalnya, kode ini bakal ke-compile
karena penggunaan terakhir dari immutable references ada di println!, sebelum
mutable reference-nya dikenalin:
fn main() {
let mut s = String::from("hello");
let r1 = &s; // no problem
let r2 = &s; // no problem
println!("{r1} and {r2}");
// Variables r1 and r2 will not be used after this point.
let r3 = &mut s; // no problem
println!("{r3}");
}Scope dari immutable references r1 sama r2 abis setelah println! di mana
mereka terakhir dipake, yang mana itu sebelum mutable reference r3 dibuat.
Scope-scope ini nggak tumpang tindih, jadi kode ini diperbolehkan: compiler
bisa tau kalau referensinya udah nggak dipake lagi di titik sebelum akhir dari
scope-nya.
Walaupun error borrowing kadang bikin kesel, inget ya kalau itu adalah compiler Rust yang lagi nunjukin potensi bug dari awal (pas compile time bukannya pas runtime) dan nunjukin tepat di mana letak masalahnya. Jadi kita nggak perlu repot-repot nyari tau kenapa data kita nggak sesuai sama apa yang kita pikirkan.
Dangling References
Di bahasa yang punya pointer, gampang sekali buat nggak sengaja bikin sebuah dangling pointer—sebuah pointer yang ngerujuk ke sebuah lokasi di memori yang mungkin udah dikasih ke orang lain—dengan cara ngebebasin sejumlah memori tapi tetep nyimpen pointer ke memori itu. Di Rust, sebaliknya, compiler ngejamin kalau referensi nggak bakal pernah jadi dangling references: kalau kita punya sebuah referensi ke suatu data, compiler bakal mastiin kalau datanya nggak bakal keluar dari scope sebelum referensi ke datanya keluar duluan.
Yuk kita coba bikin sebuah dangling reference buat liat gimana Rust nyegah mereka pake compile-time error:
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s
}Ini error-nya:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0106]: missing lifetime specifier
--> src/main.rs:5:16
|
5 | fn dangle() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime, but this is uncommon unless you're returning a borrowed value from a `const` or a `static`
|
5 | fn dangle() -> &'static String {
| +++++++
help: instead, you are more likely to want to return an owned value
|
5 - fn dangle() -> &String {
5 + fn dangle() -> String {
|
For more information about this error, try `rustc --explain E0106`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Pesan error ini ngerujuk ke fitur yang belum kita bahas: lifetimes. Kita bakal bahas lifetimes secara detail di Bab 10. Tapi, kalau kita cuekin bagian soal lifetimes-nya, pesannya emang isinya kunci kenapa kode ini bermasalah:
this function's return type contains a borrowed value, but there is no value
for it to be borrowed from
Yuk kita liat lebih deket apa sebenernya yang terjadi di tiap tahap kode
dangle kita:
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String { // dangle returns a reference to a String
let s = String::from("hello"); // s is a new String
&s // we return a reference to the String, s
} // Here, s goes out of scope and is dropped, so its memory goes away.
// Danger!Karena s dibuat di dalem dangle, pas kode dangle selesai, s bakal
di-dealokasi. Tapi kita nyoba buat balikin sebuah referensi kepadanya. Itu
artinya referensi ini bakal nunjuk ke sebuah String yang nggak valid. Itu
nggak oke sekali! Rust nggak bakal ngebolehin kita ngelakuin ini.
Solusinya di sini adalah dengan balikin String-nya secara langsung:
fn main() {
let string = no_dangle();
}
fn no_dangle() -> String {
let s = String::from("hello");
s
}Ini jalan tanpa masalah apa pun. Ownership di-move keluar, dan nggak ada apa pun yang di-dealokasi.
Aturan Referensi
Yuk kita ringkas apa yang udah kita bahas soal referensi:
- Dalam satu waktu, kita bisa punya antara satu mutable reference atau sejumlah berapa pun immutable references.
- Referensi harus selalu valid.
Selanjutnya, kita bakal liat jenis referensi yang beda: slices.
Tipe Slice
Tipe Slice
Slices ngebolehin kita buat ngerujuk ke serangkaian elemen yang berurutan di sebuah koleksi. Slice itu sejenis referensi, jadi dia nggak punya ownership.
Ini ada masalah pemrograman kecil: bikin sebuah fungsi yang nerima sebuah string kata-kata yang dipisahin spasi terus balikin kata pertama yang dia nemu di string itu. Kalau fungsinya nggak nemu spasi di string-nya, berarti seluruh string-nya adalah satu kata, jadi seluruh string-nya harus dibalikin.
Catatan: Buat tujuan ngenalin string slices, kita asumsikan cuma pake ASCII aja di bagian ini; pembahasan lebih mendalam soal penanganan UTF-8 ada di bagian “Menyimpan Teks Berkode UTF-8 dengan Strings” di Bab 8.
Yuk kita pelajari gimana cara kita nulis signature fungsi ini tanpa pake slices, biar paham masalah apa yang bakal diselesain sama slices:
fn first_word(s: &String) -> ?Fungsi first_word punya parameter tipe &String. Kita nggak butuh
ownership, jadi ini oke-oke aja. (Di Rust yang idiomatik, fungsi nggak ngambil
ownership dari argumennya kecuali emang butuh, dan alasannya bakal makin
jelas seiring kita lanjut.) Tapi apa yang harus kita balikin? Kita sebenernya
nggak punya cara buat nyebut sebagian dari sebuah string. Tapi, kita bisa
balikin indeks dari akhir katanya, yang ditandain sama spasi. Yuk kita cobain,
kayak yang ditunjukin di Listing 4-7.
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}first_word yang balikin nilai indeks byte ke dalam parameter StringKarena kita perlu nelusurin String-nya elemen demi elemen terus cek apakah
sebuah nilai itu spasi, kita bakal convert String kita jadi sebuah array dari
byte pake method as_bytes.
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Selanjutnya, kita bikin sebuah iterator lewat array byte tadi pake method iter:
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Kita bakal bahas iterator lebih detail di Bab 13. Buat sekarang, tau aja
kalau iter itu method yang balikin tiap elemen di sebuah koleksi dan
enumerate ngebungkus hasil dari iter terus balikin tiap elemen sebagai
bagian dari sebuah tuple. Elemen pertama dari tuple yang dibalikin sama
enumerate itu adalah indeksnya, dan elemen keduanya adalah referensi ke
elemennya. Ini lumayan lebih nyaman daripada ngitung indeksnya sendiri.
Karena method enumerate balikin tuple, kita bisa pake pattern buat
destructure tuple itu. Kita bakal bahas pattern lebih banyak di Bab 6.
Di dalem for loop, kita nentuin pattern yang punya i buat indeks di tuple
dan &item buat satu byte di tuple. Karena kita dapet referensi ke elemennya
dari .iter().enumerate(), kita pake & di pattern-nya.
Di dalem for loop, kita cari byte yang merepresentasikan spasi pake sintaks
literal byte. Kalau kita nemu spasi, kita balikin posisinya. Kalau nggak, kita
balikin panjang string-nya pake s.len().
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Kita sekarang punya cara buat nemuin indeks akhir dari kata pertama di string,
tapi ada masalah. Kita balikin usize sendirian, tapi itu cuma angka yang
bermakna di konteks &String. Dengan kata lain, karena itu nilai yang terpisah
dari String, nggak ada jaminan kalau dia tetep bakal valid di masa depan.
Coba liat program di Listing 4-8 yang pake fungsi first_word dari Listing 4-7.
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s); // word will get the value 5
s.clear(); // this empties the String, making it equal to ""
// word still has the value 5 here, but s no longer has any content that we
// could meaningfully use with the value 5, so word is now totally invalid!
}first_word terus ngerubah isi StringProgram ini berhasil di-compile tanpa error apa pun dan bakal tetep gitu kalau
kita pake word setelah manggil s.clear(). Karena word sama sekali nggak
hubung sama state dari s, word tetep isinya nilai 5. Kita bisa pake nilai
5 itu bareng variabel s buat nyoba ngambil kata pertamanya, tapi ini bakal
jadi sebuah bug karena isi dari s udah berubah sejak kita nyimpen 5 di
word.
Harus pusing mikirin indeks di word yang bisa nggak sinkron sama data di s
itu ribet dan gampang bikin error! Ngelola indeks-indeks ini bakal makin rapuh
lagi kalau kita nulis fungsi second_word. Signature-nya harusnya kayak gini:
fn second_word(s: &String) -> (usize, usize) {Sekarang kita mantau indeks awal dan akhir, dan kita punya makin banyak nilai yang dihitung dari data di state tertentu tapi nggak terikat sama state itu sama sekali. Kita punya tiga variabel nggak berhubungan yang melayang-layang yang perlu dijaga biar tetep sinkron.
Untungnya, Rust punya solusi buat masalah ini: string slices.
String Slices
Sebuah string slice adalah referensi ke serangkaian elemen yang berurutan
dari sebuah String, dan bentuknya kayak gini:
fn main() {
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
}Bukannya referensi ke seluruh String, hello adalah referensi ke sebagian
dari String, yang ditentuin di bagian tambahan [0..5]. Kita bikin slices
pake range di dalem kurung siku dengan nentuin [indeks_awal..indeks_akhir],
di mana indeks_awal itu posisi pertama di slice-nya dan indeks_akhir itu
satu lebih banyak dari posisi terakhir di slice-nya. Secara internal, struktur
data slice nyimpen posisi awal sama panjang slice-nya, yang sesuai sama
indeks_akhir dikurang indeks_awal. Jadi, di kasus let world = &s[6..11];,
world bakal jadi slice yang isinya sebuah pointer ke byte di indeks 6 dari s
dengan nilai panjang 5.
Gambar 4-7 nunjukin ini di sebuah diagram.

Gambar 4-7: String slice yang ngerujuk ke bagian dari sebuah String
Dengan sintaks range .. di Rust, kalau kita mau mulai di indeks 0, kita bisa
ngilangin nilai sebelum dua titik itu. Dengan kata lain, ini sama aja:
#![allow(unused)]
fn main() {
let s = String::from("hello");
let slice = &s[0..2];
let slice = &s[..2];
}Sama juga halnya, kalau slice kita masukin byte terakhir dari String, kita
bisa ngilangin angka belakangnya. Itu artinya ini sama aja:
#![allow(unused)]
fn main() {
let s = String::from("hello");
let len = s.len();
let slice = &s[3..len];
let slice = &s[3..];
}Kita juga bisa ngilangin kedua nilainya buat ngambil slice dari seluruh string. Jadi ini juga sama aja:
#![allow(unused)]
fn main() {
let s = String::from("hello");
let len = s.len();
let slice = &s[0..len];
let slice = &s[..];
}Catatan: Indeks range string slice harus ada di batas karakter UTF-8 yang valid. Kalau kita nyoba bikin string slice di tengah-tengah karakter multi-byte, program kita bakal exit dengan error.
Dengan semua info ini, yuk kita tulis ulang first_word biar balikin sebuah
slice. Tipe yang nandain “string slice” ditulisnya &str:
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {}Kita dapet indeks buat akhir katanya dengan cara yang sama kayak di Listing 4-7, dengan nyari spasi pertama. Pas kita nemu spasi, kita balikin sebuah string slice pake awal string-nya sama indeks spasi tadi sebagai indeks awal dan akhirnya.
Sekarang pas kita manggil first_word, kita dapet balik satu nilai tunggal
yang terikat ke data aslinya. Nilainya disusun dari referensi ke titik awal
slice-nya sama jumlah elemen di slice-nya.
Balikin sebuah slice juga bakal jalan buat fungsi second_word:
fn second_word(s: &String) -> &str {Kita sekarang punya API yang jelas yang jauh lebih susah buat salah pakenya
karena compiler bakal mastiin kalau referensi ke dalem String-nya tetep
valid. Inget kan bug di program di Listing 4-8, pas kita dapet indeks buat
akhir kata pertama tapi terus nge-clear string-nya sampe indeks kita jadi nggak
valid? Kode itu secara logis salah tapi nggak nunjukin error langsung.
Masalahnya baru muncul nanti kalau kita terus nyoba pake indeks kata pertama
sama string yang udah kosong. Slices bikin bug ini jadi mustahil dan ngasih
tau kita kalau ada masalah sama kode kita jauh lebih awal. Pake versi slice dari
first_word bakal ngelepar compile-time error:
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // error!
println!("the first word is: {word}");
}Ini error compiler-nya:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let word = first_word(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("the first word is: {word}");
| ---- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Inget kan dari aturan borrowing kalau kita punya immutable reference ke
sesuatu, kita nggak boleh juga ngambil mutable reference. Karena clear perlu
memotong String-nya, dia perlu dapet mutable reference. println! setelah
manggil clear pake referensi di word, jadi immutable reference-nya harus
tetep aktif di titik itu. Rust ngelarang mutable reference di clear sama
immutable reference di word buat ada di waktu yang sama, makanya kompilasinya
gagal. Nggak cuma Rust bikin API kita lebih gampang dipake, tapi dia juga
ngilangin seluruh kelas error pas compile time!
Literal String sebagai Slices
Inget kan kita pernah bahas soal literal string yang disimpan di dalem biner. Sekarang setelah kita tau soal slices, kita bisa paham literal string dengan bener:
#![allow(unused)]
fn main() {
let s = "Hello, world!";
}Tipe s di sini adalah &str: dia adalah sebuah slice yang nunjuk ke titik
spesifik di binernya. Ini juga kenapa literal string itu immutable; &str
adalah sebuah immutable reference.
String Slices sebagai Parameter
Tau kalau kita bisa ngambil slices dari literal sama nilai String bawa kita
ke satu lagi peningkatan buat first_word, yaitu di signature-nya:
fn first_word(s: &String) -> &str {Seorang Rustacean yang lebih berpengalaman bakal nulis signature yang
ditunjukin di Listing 4-9 sebagai gantinya karena dia ngebolehin kita pake
fungsi yang sama buat baik nilai &String maupun nilai &str.
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
// `first_word` works on slices of `String`s, whether partial or whole.
let word = first_word(&my_string[0..6]);
let word = first_word(&my_string[..]);
// `first_word` also works on references to `String`s, which are equivalent
// to whole slices of `String`s.
let word = first_word(&my_string);
let my_string_literal = "hello world";
// `first_word` works on slices of string literals, whether partial or
// whole.
let word = first_word(&my_string_literal[0..6]);
let word = first_word(&my_string_literal[..]);
// Because string literals *are* string slices already,
// this works too, without the slice syntax!
let word = first_word(my_string_literal);
}first_word dengan pake string slice buat tipe parameter s-nyaKalau kita punya sebuah string slice, kita bisa masukin itu langsung. Kalau
kita punya sebuah String, kita bisa masukin slice dari String-nya atau
referensi ke String-nya. Fleksibilitas ini manfaatin deref coercions, sebuah
fitur yang bakal kita bahas di bagian “Implicit Deref Coercions dengan Fungsi
dan Method” di Bab 15.
Mendefinisikan fungsi buat nerima string slice bukannya referensi ke sebuah
String bikin API kita jadi lebih umum dan berguna tanpa ngurangin fungsionalitas
apa pun:
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
// `first_word` works on slices of `String`s, whether partial or whole.
let word = first_word(&my_string[0..6]);
let word = first_word(&my_string[..]);
// `first_word` also works on references to `String`s, which are equivalent
// to whole slices of `String`s.
let word = first_word(&my_string);
let my_string_literal = "hello world";
// `first_word` works on slices of string literals, whether partial or
// whole.
let word = first_word(&my_string_literal[0..6]);
let word = first_word(&my_string_literal[..]);
// Because string literals *are* string slices already,
// this works too, without the slice syntax!
let word = first_word(my_string_literal);
}Slices Lainnya
String slices, kayak yang bisa kita bayangin, itu spesifik buat string. Tapi ada tipe slice yang lebih umum juga. Coba liat array ini:
#![allow(unused)]
fn main() {
let a = [1, 2, 3, 4, 5];
}Sama kayak kita mungkin mau ngerujuk ke bagian dari sebuah string, kita mungkin juga mau ngerujuk ke bagian dari sebuah array. Kita lakuin kayak gini:
#![allow(unused)]
fn main() {
let a = [1, 2, 3, 4, 5];
let slice = &a[1..3];
assert_eq!(slice, &[2, 3]);
}Slice ini punya tipe &[i32]. Dia cara kerjanya sama kayak string slices,
dengan nyimpen referensi ke elemen pertama sama sebuah panjangnya. Kita bakal
pake jenis slice ini buat macem-macem koleksi lainnya. Kita bakal bahas koleksi
ini secara detail pas kita bahas vector di Bab 8.
Ringkasan
Konsep ownership, borrowing, sama slices ngejamin keamanan memori di program Rust pas compile time. Bahasa Rust ngasih kita kontrol atas penggunaan memori dengan cara yang sama kayak bahasa pemrograman sistem lainnya, tapi dengan adanya pemilik data yang otomatis ngebersihin data itu pas pemiliknya keluar dari scope, artinya kita nggak perlu nulis dan debug kode tambahan buat dapet kontrol ini.
Ownership ngaruh ke banyak bagian Rust lainnya, jadi kita bakal bahas konsep-
konsep ini lebih lanjut di sepanjang sisa bukunya. Yuk kita lanjut ke Bab 5
buat liat gimana ngelempokin potongan-potongan data jadi satu di sebuah
struct.
Pake Structs buat Ngatur Data Terkait
Sebuah struct, atau structure, adalah tipe data kustom yang ngebolehin kita ngebungkus dan ngasih nama ke beberapa nilai terkait yang ngebentuk sebuah grup yang bermakna. Kalau kita udah kenal sama bahasa pemrograman berbasis objek (object-oriented), sebuah struct itu kayak atribut data dari sebuah objek. Di bab ini, kita bakal bandingin tuple sama struct buat ngembangin apa yang udah kita tau dan nunjukin kapan struct jadi cara yang lebih oke buat ngelempokin data.
Kita bakal praktekin gimana cara mendefinisikan sama menginisialisasi struct. Kita bakal bahas gimana cara mendefinisikan associated functions, terutama jenis associated functions yang disebut methods, buat nentuin perilaku yang terkait sama sebuah tipe struct. Struct sama enum (yang dibahas di Bab 6) adalah blok dasar buat bikin tipe-tipe baru di domain program kita buat manfaatin pengecekan tipe compile-time Rust secara maksimal.
Mendefinisikan dan Membikin Instance Structs
Mendefinisikan sama Menginisialisasi Structs
Struct itu mirip sama tuple yang udah kita bahas di bagian “Tipe Tuple”, karena keduanya sama-sama nampung banyak nilai yang terkait. Kayak tuple, bagian-bagian dari sebuah struct bisa punya tipe yang beda-beda. Bedanya sama tuple, di dalem struct kita ngasih nama ke tiap potongan datanya biar jelas apa makna dari nilai-nilai itu. Dengan adanya nama-nama ini, struct jadi lebih fleksibel daripada tuple: kita nggak perlu ngandelin urutan datanya buat nentuin atau akses nilai dari sebuah instance.
Buat mendefinisikan sebuah struct, kita tulis keyword struct terus kasih nama
ke seluruh struct-nya. Nama struct harusnya ngejelasin seberapa penting potongan
data yang lagi dikelompokin itu. Terus, di dalem kurung kurawal, kita
mendefinisikan nama sama tipe dari potongan datanya, yang kita sebut sebagai
fields. Contohnya, Listing 5-1 nunjukin sebuah struct yang nyimpen info soal
akun user.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {}UserBuat pake sebuah struct setelah kita definisikan, kita bikin sebuah instance
dari struct itu dengan nentuin nilai konkret buat tiap field-nya. Kita bikin
sebuah instance dengan nulis nama struct-nya terus nambahin kurung kurawal yang
isinya pasangan key: value, di mana key-nya adalah nama field-nya dan
value-nya adalah data yang mau kita simpen di field itu. Kita nggak harus
nentuin field-nya sesuai urutan pas kita mendeklarasikannya di struct-nya.
Dengan kata lain, definisi struct itu kayak template umum buat tipenya, dan
instance ngisi template itu dengan data tertentu buat bikin nilai dari tipe
tersebut. Contohnya, kita bisa mendeklarasikan seorang user tertentu kayak yang
ditunjukin di Listing 5-2.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
let user1 = User {
active: true,
username: String::from("someusername123"),
email: String::from("someone@example.com"),
sign_in_count: 1,
};
}UserBuat dapet nilai spesifik dari sebuah struct, kita pake notasi titik (dot
notation). Misalnya, buat akses alamat email user ini, kita pake user1.email.
Kalau instance-nya mutable, kita bisa ngerubah nilainya pake notasi titik terus
di-assign ke field tertentu. Listing 5-3 nunjukin gimana cara ngerubah nilai di
field email dari sebuah instance User yang mutable.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
let mut user1 = User {
active: true,
username: String::from("someusername123"),
email: String::from("someone@example.com"),
sign_in_count: 1,
};
user1.email = String::from("anotheremail@example.com");
}email dari sebuah instance User yang mutablePerhatiin ya kalau seluruh instance-nya harus mutable; Rust nggak ngebolehin kita nandain cuma field tertentu doang sebagai mutable. Sama kayak ekspresi mana pun, kita bisa ngekonstruksi instance baru dari struct-nya sebagai ekspresi terakhir di body fungsi buat secara implisit balikin instance baru itu.
Listing 5-4 nunjukin sebuah fungsi build_user yang balikin instance User
dengan email sama username yang dikasih. Field active dapet nilai true,
dan sign_in_count dapet nilai 1.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn build_user(email: String, username: String) -> User {
User {
active: true,
username: username,
email: email,
sign_in_count: 1,
}
}
fn main() {
let user1 = build_user(
String::from("someone@example.com"),
String::from("someusername123"),
);
}build_user yang nerima email sama username terus balikin instance UserMasuk akal sekali kan buat ngasih nama parameter fungsi sama kayak nama field
struct-nya, tapi harus ngulang-ngulang nama field email sama username dan
variabelnya itu agak ribet. Kalau struct-nya punya lebih banyak field lagi,
ngulangin tiap namanya bakal makin nyebelin. Untungnya, ada cara singkat yang
nyaman!
Pake Shorthand Inisialisasi Field (Field Init Shorthand)
Karena nama parameternya sama nama field struct-nya persis sama di Listing 5-4,
kita bisa pake sintaks field init shorthand buat nulis ulang build_user
biar perilakunya persis sama tapi nggak ada pengulangan username sama email,
kayak yang ditunjukin di Listing 5-5.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn build_user(email: String, username: String) -> User {
User {
active: true,
username,
email,
sign_in_count: 1,
}
}
fn main() {
let user1 = build_user(
String::from("someone@example.com"),
String::from("someusername123"),
);
}build_user yang pake field init shorthand karena parameter username sama email punya nama yang sama kayak field struct-nyaDi sini, kita lagi bikin instance baru dari struct User, yang punya field
namanya email. Kita mau set nilai field email ke nilai di parameter email
dari fungsi build_user. Karena field email sama parameter email punya
nama yang sama, kita cuma perlu nulis email doang bukannya email: email.
Bikin Instance dari Instance Lain pake Sintaks Update Struct (Struct Update Syntax)
Sering kali berguna buat bikin instance baru dari sebuah struct yang isinya kebanyakan nilai dari instance lain dengan tipe yang sama, tapi ngerubah beberapa nilainya. Kita bisa lakuin ini pake struct update syntax.
Pertama, di Listing 5-6 kita liat cara bikin instance User baru di user2
secara biasa, tanpa pake update syntax. Kita set nilai baru buat email tapi
selain itu pake nilai-nilai yang sama dari user1 yang udah kita bikin di
Listing 5-2.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
// --snip--
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
let user2 = User {
active: user1.active,
username: user1.username,
email: String::from("another@example.com"),
sign_in_count: user1.sign_in_count,
};
}User baru pake hampir semua nilai dari user1 kecuali satuPake struct update syntax, kita bisa dapet efek yang sama dengan kode yang
lebih dikit, kayak yang ditunjukin di Listing 5-7. Sintaks .. nentuin kalau
sisa field yang nggak di-set secara eksplisit harusnya punya nilai yang sama
kayak field di instance yang dikasih.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
// --snip--
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
let user2 = User {
email: String::from("another@example.com"),
..user1
};
}email baru buat instance User tapi pake sisa nilai dari user1 lainnyaKode di Listing 5-7 juga bikin instance di user2 yang punya nilai beda buat
email tapi punya nilai yang sama buat field username, active, dan
sign_in_count dari user1. Tanda ..user1 harus ditaruh di paling akhir
buat nentuin kalau sisa field apa pun harus dapet nilainya dari field yang
terkait di user1, tapi kita bebas nentuin nilai buat sebanyak apa pun field
yang kita mau dengan urutan apa pun, nggak peduli urutan field-nya di definisi
struct-nya.
Perhatiin ya kalau struct update syntax pake = kayak sebuah assignment;
ini karena dia nge-move datanya, sama kayak yang kita liat di bagian
“Interaksi Variabel dan Data dengan Move”. Di contoh ini, kita udah
nggak bisa lagi pake user1 setelah bikin user2 karena String di field
username dari user1 udah di-move ke dalem user2. Kalau kita ngasih
user2 nilai String baru buat baik email maupun username, dan makanya
cuma pake nilai active sama sign_in_count dari user1, berarti user1
bakal tetep valid setelah bikin user2. Baik active maupun sign_in_count
adalah tipe yang mengimplementasikan trait Copy, jadi perilaku yang kita
bahas di bagian “Data Khusus Stack: Copy” bakal berlaku. Kita juga
tetep bisa pake user1.email di contoh ini, karena nilainya nggak di-move
keluar dari user1.
Pake Tuple Structs tanpa Field Bernama buat Bikin Tipe yang Beda
Rust juga support struct yang tampilannya mirip sama tuple, namanya tuple structs. Tuple structs punya makna tambahan yang dikasih sama nama struct-nya tapi nggak punya nama yang terkait sama field-field-nya; sebaliknya, mereka cuma punya tipe dari field-field-nya aja. Tuple structs berguna pas kita mau ngasih nama ke seluruh tuple-nya dan bikin tuple itu jadi tipe yang beda dari tuple lainnya, dan pas ngasih nama ke tiap field kayak di struct biasa bakal terasa terlalu panjang (verbose) atau redundan.
Buat mendefinisikan sebuah tuple struct, mulai pake keyword struct dan nama
struct-nya diikuti sama tipe-tipe di dalem tuple-nya. Misalnya, di sini kita
mendefinisikan dan pake dua tuple structs namanya Color dan Point:
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
fn main() {
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);
}Perhatiin ya kalau nilai black sama origin itu tipe yang beda karena mereka
adalah instance dari tuple structs yang beda. Tiap struct yang kita definisikan
itu adalah tipenya sendiri, walaupun field-field di dalem struct-nya mungkin
punya tipe yang sama. Misalnya, sebuah fungsi yang nerima parameter tipe Color
nggak bisa nerima sebuah Point sebagai argumen, walaupun kedua tipenya sama-
sama disusun dari tiga nilai i32. Selain itu, instance tuple struct mirip
sama tuple karena kita bisa destructure mereka jadi bagian-bagian individunya,
dan kita bisa pake tanda . diikuti indeks buat akses nilai individunya. Beda
sama tuple, tuple struct nuntut kita buat nulis nama tipe struct-nya pas kita
destructure mereka. Misalnya, kita bakal nulis let Point(x, y, z) = origin;
buat destructure nilai di titik origin jadi variabel namanya x, y, dan z.
Struct Mirip-Unit (Unit-Like Structs) tanpa Field Apa pun
Kita juga bisa mendefinisikan struct yang nggak punya field apa pun! Ini namanya
unit-like structs karena perilakunya mirip sama (), yaitu tipe unit yang
pernah kita sebutin di bagian “Tipe Tuple”. Unit-like structs bisa
berguna pas kita perlu mengimplementasikan sebuah trait pada suatu tipe tapi
nggak punya data apa pun yang mau kita simpen di tipe itu sendiri. Kita bakal
bahas traits di Bab 10. Ini contoh deklarasi sama inisialisasi struct unit
namanya AlwaysEqual:
struct AlwaysEqual;
fn main() {
let subject = AlwaysEqual;
}Buat mendefinisikan AlwaysEqual, kita pake keyword struct, nama yang kita
mau, terus tanda titik koma. Nggak perlu kurung kurawal atau tanda kurung!
Terus kita bisa dapet instance dari AlwaysEqual di variabel subject dengan
cara yang mirip: pake nama yang udah kita definisikan, tanpa kurung kurawal
atau tanda kurung apa pun. Bayangin kalau nanti kita bakal mengimplementasikan
perilaku buat tipe ini biar tiap instance dari AlwaysEqual itu selalu sama
dengan tiap instance dari tipe lainnya, mungkin buat punya hasil yang udah tau
buat tujuan testing. Kita nggak bakal butuh data apa pun buat
mengimplementasikan perilaku itu! Kita bakal liat di Bab 10 gimana cara
mendefinisikan traits dan mengimplementasikannya pada tipe apa pun, termasuk
unit-like structs.
Ownership dari Data Struct
Di definisi struct User di Listing 5-1, kita pake tipe String yang
dimiliki (owned) bukannya tipe string slice &str. Ini pilihan yang
disengaja karena kita mau tiap instance dari struct ini punya semua datanya
sendiri dan biar datanya valid selama seluruh struct-nya juga valid.
Mungkin juga buat struct nyimpen referensi ke data yang dimiliki sama hal lain, tapi buat lakuin itu butuh penggunaan lifetimes, sebuah fitur Rust yang bakal kita bahas di Bab 10. Lifetimes mastiin kalau data yang dirujuk sama sebuah struct itu valid selama struct-nya masih ada. Katakanlah kita nyoba nyimpen sebuah referensi di sebuah struct tanpa nentuin lifetimes, kayak berikut; ini nggak bakal jalan:
struct User {
active: bool,
username: &str,
email: &str,
sign_in_count: u64,
}
fn main() {
let user1 = User {
active: true,
username: "someusername123",
email: "someone@example.com",
sign_in_count: 1,
};
}Compiler bakal protes kalau dia butuh penentu lifetime (lifetime specifiers):
$ cargo run
Compiling structs v0.1.0 (file:///projects/structs)
error[E0106]: missing lifetime specifier
--> src/main.rs:3:15
|
3 | username: &str,
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
1 ~ struct User<'a> {
2 | active: bool,
3 ~ username: &'a str,
|
error[E0106]: missing lifetime specifier
--> src/main.rs:4:12
|
4 | email: &str,
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
1 ~ struct User<'a> {
2 | active: bool,
3 | username: &str,
4 ~ email: &'a str,
|
For more information about this error, try `rustc --explain E0106`.
error: could not compile `structs` (bin "structs") due to 2 previous errors
Di Bab 10, kita bakal bahas gimana cara benerin error-error ini biar kita bisa
nyimpen referensi di struct, tapi buat sekarang, kita bakal benerin error
kayak gini pake tipe owned kayak String bukannya referensi kayak &str.
Contoh Program Memakai Structs
Contoh Program pake Structs
Buat mahamin kapan kita mungkin mau pake struct, yuk kita tulis program yang ngitung luas (area) dari sebuah persegi panjang. Kita bakal mulai dengan pake variabel satu-satu, terus kita refactor programnya sampe kita pake struct sebagai gantinya.
Yuk kita bikin project biner baru pake Cargo namanya rectangles yang bakal nerima lebar (width) sama tinggi (height) dari persegi panjang dalam pixel terus ngitung luasnya. Listing 5-8 nunjukin program pendek dengan satu cara buat ngelakuin itu di file src/main.rs project kita.
fn main() {
let width1 = 30;
let height1 = 50;
println!(
"The area of the rectangle is {} square pixels.",
area(width1, height1)
);
}
fn area(width: u32, height: u32) -> u32 {
width * height
}Sekarang, jalanin program ini pake cargo run:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/rectangles`
The area of the rectangle is 1500 square pixels.
Kode ini berhasil nyari tau luas persegi panjangnya dengan manggil fungsi
area pake tiap dimensinya, tapi kita bisa lakuin lebih banyak lagi buat bikin
kode ini lebih jelas dan enak dibaca.
Masalah dari kode ini keliatan sekali di signature fungsi area:
fn main() {
let width1 = 30;
let height1 = 50;
println!(
"The area of the rectangle is {} square pixels.",
area(width1, height1)
);
}
fn area(width: u32, height: u32) -> u32 {
width * height
}Fungsi area harusnya ngitung luas dari satu persegi panjang, tapi fungsi yang
kita tulis punya dua parameter, dan nggak jelas di mana pun di program kita
kalau parameter-parameter itu sebenernya berhubungan. Bakal lebih enak dibaca
dan lebih gampang dikelola kalau kita ngelempokin lebar sama tinggi jadi satu.
Kita udah bahas salah satu cara buat lakuin itu di bagian “Tipe Tuple”
di Bab 3: yaitu pake tuple.
Refactoring pake Tuples
Listing 5-9 nunjukin versi lain dari program kita yang pake tuple.
fn main() {
let rect1 = (30, 50);
println!(
"The area of the rectangle is {} square pixels.",
area(rect1)
);
}
fn area(dimensions: (u32, u32)) -> u32 {
dimensions.0 * dimensions.1
}Dalam satu sisi, program ini lebih baik. Tuple ngebolehin kita nambahin sedikit struktur, dan kita sekarang cuma masukin satu argumen doang. Tapi di sisi lain, versi ini kurang jelas: tuple nggak ngasih nama ke elemen-elemennya, jadi kita harus ngindeks ke bagian-bagian tuple-nya, yang bikin kalkulasi kita jadi kurang gamblang.
Ketuker antara lebar sama tinggi nggak bakal ngaruh buat kalkulasi luas, tapi
kalau kita mau gambar persegi panjangnya di layar, itu baru ngaruh sekali!
Kita harus terus inget kalau width itu indeks tuple 0 dan height itu
indeks tuple 1. Ini bakal makin susah buat orang lain buat cari tau dan
diinget-inget kalau mereka mau pake kode kita. Karena kita nggak nyampein
makna dari data kita di kode, sekarang jadi lebih gampang buat masukin error.
Refactoring pake Structs: Nambahin Lebih Banyak Makna
Kita pake struct buat nambahin makna dengan ngasih label ke datanya. Kita bisa ngubah tuple yang kita pake jadi sebuah struct dengan nama buat keseluruhannya sama nama buat tiap bagiannya, kayak yang ditunjukin di Listing 5-10.
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!(
"The area of the rectangle is {} square pixels.",
area(&rect1)
);
}
fn area(rectangle: &Rectangle) -> u32 {
rectangle.width * rectangle.height
}RectangleDi sini, kita udah mendefinisikan sebuah struct terus dikasih nama Rectangle.
Di dalem kurung kurawal, kita mendefinisikan field-field-nya sebagai width
sama height, yang keduanya punya tipe u32. Terus, di main, kita bikin
instance tertentu dari Rectangle yang punya lebar 30 sama tinggi 50.
Fungsi area kita sekarang didefinisikan dengan satu parameter, yang kita
kasih nama rectangle, yang tipenya adalah immutable borrow dari sebuah
instance struct Rectangle. Kayak yang udah disebutin di Bab 4, kita mau minjem
(borrow) struct-nya bukannya ngambil ownership-nya. Dengan cara ini, main
tetep megang ownership-nya dan bisa lanjut pake rect1, yang merupakan
alasan kenapa kita pake & di signature fungsi sama pas kita manggil fungsinya.
Fungsi area akses field width sama height dari instance Rectangle
(perhatiin ya kalau akses field dari instance struct yang dipinjem nggak bakal
nge-move nilai field-nya, makanya kita sering liat peminjaman struct).
Signature fungsi kita buat area sekarang bilang persis apa yang kita maksud:
itung luas dari Rectangle, pake field width sama height-nya. Ini
nyampein kalau lebar sama tinggi itu berhubungan satu sama lain, dan ngasih
nama deskriptif ke nilai-nilainya bukannya pake nilai indeks tuple 0 sama 1.
Ini kemenangan buat kejelasan kodenya.
Nambahin Fungsionalitas Berguna pake Derived Traits
Bakal sangat berguna kalau kita bisa nyetak sebuah instance dari Rectangle
pas lagi debugging program kita dan liat nilai buat semua field-nya. Listing 5-11
nyoba pake macro println! kayak yang udah kita pake di bab-bab
sebelumnya. Tapi, ini nggak bakal jalan.
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {rect1}");
}RectanglePas kita compile kode ini, kita dapet error dengan pesan inti kayak gini:
error[E0277]: `Rectangle` doesn't implement `std::fmt::Display`
Macro println! bisa ngelakuin banyak jenis format, dan secara default, kurung
kurawal ngasih tau println! buat pake format yang dikenal sebagai Display:
output yang tujuannya buat dikonsumsi langsung sama end user. Tipe-tipe
primitif yang udah kita liat sejauh ini mengimplementasikan Display secara
default karena cuma ada satu cara kita mau nunjukin angka 1 atau tipe
primitif lainnya ke user. Tapi sama struct, gimana cara println! harus
format output-nya itu kurang jelas karena ada banyak kemungkinan tampilan: Mau
pake koma apa nggak? Mau nyetak kurung kurawal-nya juga? Apakah semua field
harus ditunjukin? Karena ambiguitas ini, Rust nggak nyoba buat nebak apa yang
kita mau, dan struct nggak dikasih implementasi bawaan dari Display buat
dipake bareng println! sama placeholder {}.
Kalau kita lanjut baca error-nya, kita bakal nemu catatan berguna ini:
| |`Rectangle` cannot be formatted with the default formatter
| required by this formatting parameter
Yuk kita coba! Pemanggilan macro println! sekarang bakal keliatan kayak
println!("rect1 is {rect1:?}");. Naruh penentu :? di dalem kurung kurawal
ngasih tau println! kalau kita mau pake format output namanya Debug. Trait
Debug ngebolehin kita nyetak struct kita dengan cara yang berguna buat
developer biar kita bisa liat nilainya pas lagi debugging kode kita.
Compile kodenya dengan perubahan ini. Yah! Masih dapet error:
error[E0277]: `Rectangle` doesn't implement `Debug`
Tapi lagi-lagi, compiler-nya ngasih catatan yang ngebantu:
| required by this formatting parameter
|
Rust emang masukin fungsionalitas buat nyetak info debugging, tapi kita harus
secara eksplisit milih (opt in) buat bikin fungsionalitas itu tersedia buat
struct kita. Caranya, kita tambahin atribut luar #[derive(Debug)] tepat
sebelum definisi struct-nya, kayak yang ditunjukin di Listing 5-12.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {rect1:?}");
}Debug terus nyetak instance Rectangle pake debug formattingSekarang pas kita jalanin programnya, kita nggak bakal dapet error apa-apa, dan kita bakal liat output berikut:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle { width: 30, height: 50 }
Mantap! Emang bukan output yang paling cakep sih, tapi dia nunjukin nilai dari
semua field buat instance ini, yang pasti bakal ngebantu sekali pas lagi
debugging. Pas kita punya struct yang lebih gede, bakal berguna kalau punya
output yang sedikit lebih gampang dibaca; di kasus kayak gitu, kita bisa pake
{:#?} bukannya {:?} di string println!. Di contoh ini, pake gaya {:#?}
bakal ngeluarin output kayak gini:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle {
width: 30,
height: 50,
}
Cara lain buat nyetak sebuah nilai pake format Debug itu pake macro dbg!,
yang ngambil ownership dari sebuah ekspresi (beda sama println!, yang
ngambil referensi), nyetak nama file sama nomor baris di mana pemanggilan macro
dbg! itu ada di kode kita barengan sama nilai hasil dari ekspresi itu, terus
balikin ownership nilainya.
Catatan: Manggil macro
dbg!itu nyetaknya ke stream konsol standard error (stderr), beda samaprintln!, yang nyetaknya ke stream konsol standard output (stdout). Kita bakal bahas lebih banyak soalstderrsamastdoutdi bagian “Menulis Pesan Error ke Standard Error Bukannya Standard Output” di Bab 12.
Ini contoh di mana kita tertarik sama nilai yang di-assign ke field width,
sekaligus nilai dari seluruh struct di rect1:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let scale = 2;
let rect1 = Rectangle {
width: dbg!(30 * scale),
height: 50,
};
dbg!(&rect1);
}Kita bisa naruh dbg! di sekitar ekspresi 30 * scale dan, karena dbg!
balikin ownership dari nilai ekspresinya, field width bakal dapet nilai yang
sama kayak kalau kita nggak ada pemanggilan dbg! di situ. Kita nggak mau
dbg! ngambil ownership dari rect1, jadi kita pake sebuah referensi ke
rect1 di pemanggilan selanjutnya. Ini penampakan output dari contoh ini:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/rectangles`
[src/main.rs:10:16] 30 * scale = 60
[src/main.rs:14:5] &rect1 = Rectangle {
width: 60,
height: 50,
}
Kita bisa liat bagian output pertama dateng dari src/main.rs baris 10 di mana
kita lagi debugging ekspresi 30 * scale, dan nilai hasilnya adalah 60
(formatting Debug yang diimplementasikan buat integer itu nyetak nilainya
doang). Pemanggilan dbg! di baris 14 dari src/main.rs ngeluarin nilai dari
&rect1, yaitu struct Rectangle. Output ini pake formatting Debug yang
rapi dari tipe Rectangle. Macro dbg! ini bisa ngebantu sekali pas kita
lagi nyoba cari tau apa yang sebenernya lagi dilakuin kode kita!
Selain trait Debug, Rust juga nyediain sejumlah traits buat kita pake bareng
atribut derive yang bisa nambahin perilaku berguna ke tipe data kustom kita.
Traits itu sama perilakunya ada di daftar di Lampiran C. Kita bakal
bahas gimana cara mengimplementasikan traits ini dengan perilaku kustom
sekaligus gimana cara bikin traits kita sendiri di Bab 10. Ada juga banyak
atribut lain selain derive; buat info lebih lanjut, liat bagian “Attributes”
di Rust Reference.
Fungsi area kita itu sangat spesifik: dia cuma ngitung luas persegi panjang.
Bakal ngebantu kalau kita ngiket perilaku ini lebih deket ke struct Rectangle
kita karena dia nggak bakal jalan sama tipe lainnya. Yuk kita liat gimana kita
bisa lanjut refactor kode ini dengan ngerubah fungsi area jadi sebuah
method area yang didefinisikan pada tipe Rectangle kita.
Sintaks Method
Sintaks Method
Methods itu mirip sama fungsi: kita mendeklarasikan mereka pake keyword fn
sama sebuah nama, mereka bisa punya parameter sama nilai return, dan mereka
isinya sejumlah kode yang dijalanin pas method-nya dipanggil dari tempat lain.
Beda sama fungsi, method didefinisikan di dalem konteks sebuah struct (atau enum
atau trait object, yang bakal kita bahas masing-masing di Bab 6 sama
Bab 18), dan parameter pertamanya selalu self, yang
merepresentasikan instance dari struct tempat method itu dipanggil.
Mendefinisikan Methods
Yuk kita ubah fungsi area yang punya instance Rectangle sebagai parameter
terus dijadiin sebuah method area yang didefinisikan pada struct Rectangle,
kayak yang ditunjukin di Listing 5-13.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!(
"The area of the rectangle is {} square pixels.",
rect1.area()
);
}area pada struct RectangleBuat mendefinisikan fungsi di dalem konteks Rectangle, kita mulai blok
impl (implementasi) buat Rectangle. Segala hal di dalem blok impl ini
bakal terkait sama tipe Rectangle. Terus kita pindahin fungsi area ke dalem
kurung kurawal impl dan ngubah parameter pertama (dan di kasus ini, satu-
satunya parameter) jadi self di signature sama di mana-mana di dalem body-nya.
Di main, tempat kita manggil fungsi area terus masukin rect1 sebagai
argumen, kita sekarang bisa pake sintaks method buat manggil method area
pada instance Rectangle kita. Sintaks method ditaruh setelah sebuah instance:
kita tambahin titik diikuti sama nama method, tanda kurung, sama argumen apa pun.
Di signature buat area, kita pake &self bukannya rectangle: &Rectangle.
&self sebenernya singkatan dari self: &Self. Di dalem blok impl, tipe
Self adalah alias buat tipe yang lagi diimplementasikan sama blok impl itu.
Methods harus punya parameter namanya self bertipe Self buat parameter
pertama mereka, jadi Rust ngebolehin kita nyingkat ini dengan cuma nama self
di tempat parameter pertama. Perhatiin ya kalau kita tetep perlu pake & di
depan singkatan self buat nunjukin kalau method ini minjem (borrows) instance
Self, sama kayak pas kita nulis rectangle: &Rectangle. Methods bisa ngambil
ownership dari self, minjem self secara immutable, kayak yang kita
lakuin di sini, atau minjem self secara mutable, sama kayak parameter
lainnya.
Kita milih &self di sini dengan alasan yang sama kayak kenapa kita pake
&Rectangle di versi fungsinya: kita nggak mau ngambil ownership, dan kita
cuma mau baca data di struct-nya, bukan nulis ke sana. Kalau kita mau ngerubah
instance yang kita panggil method-nya sebagai bagian dari apa yang dilakuin
method-nya, kita bakal pake &mut self sebagai parameter pertamanya. Punya
method yang ngambil ownership dari instance dengan cuma pake self sebagai
parameter pertama itu jarang; teknik ini biasanya dipake pas method-nya ngerubah
(transform) self jadi sesuatu yang lain terus kita mau nyegah pemanggilnya
buat pake instance aslinya setelah transformasi itu.
Alasan utama buat pake method bukannya fungsi, selain ngasih sintaks method
dan nggak perlu ngulang-ngulang nulis tipe self di tiap signature method,
adalah buat pengaturan kode (organization). Kita naruh semua hal yang bisa kita
lakuin sama sebuah instance dari suatu tipe di dalem satu blok impl bukannya
bikin orang yang nanti pake kode kita harus nyari-nyari kemampuan dari
Rectangle di berbagai tempat di library yang kita kasih.
Perhatiin ya kalau kita bisa milih buat ngasih nama method sama kayak salah
satu nama field struct-nya. Misalnya, kita bisa mendefinisikan method di
Rectangle yang juga namanya width:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn width(&self) -> bool {
self.width > 0
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
if rect1.width() {
println!("The rectangle has a nonzero width; it is {}", rect1.width);
}
}Di sini, kita milih buat bikin method width balikin true kalau nilai di
field width dari instance-nya lebih gede dari 0 dan false kalau nilainya
0: kita bisa pake field di dalem method dengan nama yang sama buat tujuan apa
pun. Di main, pas kita ngikutin rect1.width pake tanda kurung, Rust tau
kita maksudnya method width. Pas kita nggak pake tanda kurung, Rust tau
maksudnya field width.
Sering kali, tapi nggak selalu, pas kita ngasih method nama yang sama kayak sebuah field, kita mau method itu cuma balikin nilai di field-nya dan nggak ngelakuin hal lain. Method kayak gini namanya getters, dan Rust nggak mengimplementasikan mereka secara otomatis buat field struct kayak yang dilakuin beberapa bahasa lain. Getters itu berguna karena kita bisa bikin field-nya jadi private tapi method-nya public, dan dengan gitu ngasih akses read-only ke field itu sebagai bagian dari API public tipe tersebut. Kita bakal bahas apa itu public dan private dan gimana cara nandain field atau method sebagai public atau private di Bab 7.
Ke Mana Perginya Operator ->?
Di C sama C++, dua operator yang beda dipake buat manggil method: kita pake
. kalau kita manggil method di objeknya secara langsung dan -> kalau
kita manggil method di sebuah pointer ke objeknya dan perlu nge-dereference
pointer-nya dulu. Dengan kata lain, kalau object itu sebuah pointer,
object->something() itu mirip sama (*object).something().
Rust nggak punya padanan buat operator ->; sebaliknya, Rust punya fitur
namanya automatic referencing and dereferencing (referencing dan
dereferencing otomatis). Manggil method adalah salah satu dari sedikit tempat
di Rust yang punya perilaku ini.
Ini cara kerjanya: pas kita manggil sebuah method pake object.something(),
Rust secara otomatis nambahin &, &mut, atau * biar object cocok sama
signature dari method-nya. Dengan kata lain, dua baris berikut itu sama aja:
#![allow(unused)]
fn main() {
#[derive(Debug,Copy,Clone)]
struct Point {
x: f64,
y: f64,
}
impl Point {
fn distance(&self, other: &Point) -> f64 {
let x_squared = f64::powi(other.x - self.x, 2);
let y_squared = f64::powi(other.y - self.y, 2);
f64::sqrt(x_squared + y_squared)
}
}
let p1 = Point { x: 0.0, y: 0.0 };
let p2 = Point { x: 5.0, y: 6.5 };
p1.distance(&p2);
(&p1).distance(&p2);
}Yang pertama keliatan jauh lebih bersih. Perilaku automatic referencing ini
bisa jalan karena method punya penerima (receiver) yang jelas—yaitu tipe dari
self. Berdasarkan penerima dan nama method-nya, Rust bisa tau secara
definitif apakah method itu lagi baca (&self), nge-mutasi (&mut self),
atau ngonsumsi (self). Fakta kalau Rust bikin borrowing jadi implisit buat
penerima method adalah bagian gede dari kenapa ownership terasa ergonomis
di praktiknya.
Methods dengan Lebih Banyak Parameter
Yuk kita latihan pake method dengan mengimplementasikan method kedua di struct
Rectangle. Kali ini kita mau sebuah instance Rectangle nerima instance
Rectangle lainnya dan balikin true kalau Rectangle yang kedua bisa muat
sepenuhnya di dalem self (Rectangle yang pertama); kalau nggak, dia harus
balikin false. Jadi, setelah kita mendefinisikan method can_hold, kita mau
bisa nulis program kayak yang ditunjukin di Listing 5-14.
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2));
println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3));
}can_hold yang belum ditulisOutput yang diharepin bakal keliatan kayak gini karena kedua dimensi rect2
itu lebih kecil dari dimensi rect1, tapi rect3 lebih lebar dari rect1:
Can rect1 hold rect2? true
Can rect1 hold rect3? false
Kita tau kita mau mendefinisikan sebuah method, jadi dia bakal ada di dalem blok
impl Rectangle. Nama method-nya adalah can_hold, dan dia bakal nerima
immutable borrow dari Rectangle lainnya sebagai parameter. Kita bisa tau apa
tipe parameternya dengan ngeliat kode yang manggil method-nya:
rect1.can_hold(&rect2) masukin &rect2, yang merupakan immutable borrow ke
rect2, sebuah instance dari Rectangle. Ini masuk akal karena kita cuma
perlu baca rect2 (bukannya nulis, yang bakal berarti kita butuh mutable
borrow), dan kita mau main tetep punya ownership dari rect2 biar kita
bisa pake lagi setelah manggil method can_hold. Nilai return dari can_hold
bakal berupa Boolean, dan implementasinya bakal nge-cek apakah lebar sama tinggi
dari self lebih gede dari lebar sama tinggi dari Rectangle yang satunya.
Yuk kita tambahin method can_hold baru ini ke blok impl dari Listing 5-13,
yang ditunjukin di Listing 5-15.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2));
println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3));
}can_hold di Rectangle yang nerima instance Rectangle lainnya sebagai parameterPas kita jalanin kode ini sama fungsi main di Listing 5-14, kita bakal dapet
output yang kita mau. Method bisa nerima banyak parameter yang kita tambahin di
signature setelah parameter self, dan parameter-parameter itu cara kerjanya
persis sama kayak parameter di fungsi biasa.
Associated Functions
Semua fungsi yang didefinisikan di dalem blok impl disebut associated functions
(fungsi terkait) karena mereka terkait sama tipe yang dinamain setelah kata
impl. Kita bisa mendefinisikan associated functions yang nggak punya self
sebagai parameter pertamanya (dan makanya bukan methods) karena mereka nggak
butuh instance dari tipe itu buat jalan. Kita udah pake salah satu fungsi kayak
gini: fungsi String::from yang didefinisikan pada tipe String.
Associated functions yang bukan methods sering dipake buat constructors yang
bakal balikin instance baru dari struct-nya. Ini sering dikasih nama new, tapi
new bukan nama khusus dan nggak bawaan dari bahasanya. Misalnya, kita bisa
milih buat nyediain associated function namanya square yang punya satu
parameter dimensi dan pakenya buat lebar sama tingginya, jadi lebih gampang
buat bikin Rectangle bentuk persegi bukannya harus nentuin nilai yang sama dua
kali:
Nama file: src/main.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn square(size: u32) -> Self {
Self {
width: size,
height: size,
}
}
}
fn main() {
let sq = Rectangle::square(3);
}Keyword Self di tipe return sama di dalem body fungsinya itu alias buat tipe
yang muncul setelah keyword impl, yang di kasus ini adalah Rectangle.
Buat manggil associated function ini, kita pake sintaks :: bareng nama
struct-nya; let sq = Rectangle::square(3); adalah contohnya. Fungsi ini punya
namespace oleh struct-nya: sintaks :: dipake buat baik associated functions
maupun namespaces yang dibuat sama modul. Kita bakal bahas modul di Bab 7.
Banyak Blok impl
Tiap struct dibolehin buat punya banyak blok impl. Contohnya, Listing 5-15
itu ekuivalen sama kode yang ditunjukin di Listing 5-16, yang punya tiap
method di blok impl-nya masing-masing.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2));
println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3));
}implNggak ada alesan khusus buat misahin method-method ini ke dalem banyak blok
impl di sini, tapi ini sintaks yang valid. Kita bakal liat kasus di mana
banyak blok impl berguna di Bab 10, pas kita bahas soal generic types dan
traits.
Ringkasan
Structs ngebolehin kita bikin tipe kustom yang bermakna buat domain kita. Dengan
pake struct, kita bisa nyimpen potongan data yang terkait tetep nyambung satu
sama lain dan ngasih nama ke tiap potongannya buat bikin kode kita jelas. Di
dalem blok impl, kita bisa mendefinisikan fungsi-fungsi yang terkait sama
tipe kita, dan methods adalah jenis associated function yang ngebolehin kita
nentuin perilaku yang dimiliki sama instance dari struct kita.
Tapi struct bukan satu-satunya cara kita bisa bikin tipe kustom: yuk kita beralih ke fitur enum di Rust buat nambahin tool lain ke toolbox kita.
Enum dan Pattern Matching
Di bab ini, kita bakal liat enumerations, yang juga sering disebut sebagai
enums. Enum ngebolehin kita buat mendefinisikan sebuah tipe dengan menjabarkan
kemungkinan variants-nya (varian). Pertama kita bakal mendefinisikan dan pake
sebuah enum buat nunjukin gimana enum bisa nyimpen makna barengan sama data.
Selanjutnya, kita bakal eksplor enum yang kepake sekali, namanya Option, yang
mengekspresikan kalau sebuah nilai itu bisa ada isinya (something) atau nggak ada
isinya sama sekali (nothing). Terus kita bakal liat gimana pattern matching
(pencocokan pola) di ekspresi match bikin gampang buat ngejalanin kode yang
beda-beda buat nilai enum yang beda. Terakhir, kita bakal bahas gimana konstruk
if let jadi idiom lain yang nyaman dan ringkas buat handle enum di kode kita.
Mendefinisikan sebuah Enum
Mendefinisikan sebuah Enum
Kalau struct ngasih kita cara buat ngelempokin field sama data yang terkait
bareng-bareng, kayak sebuah Rectangle (persegi panjang) dengan width
(lebar) sama height (tinggi)-nya, enum ngasih kita cara buat bilang kalau
sebuah nilai itu adalah salah satu dari sekumpulan nilai yang mungkin. Misalnya,
kita mungkin mau bilang kalau Rectangle itu salah satu dari sekumpulan bentuk
yang mungkin yang juga termasuk Circle (lingkaran) sama Triangle (segitiga).
Buat lakuin ini, Rust ngebolehin kita buat nyimpen (encode) kemungkinan-kemungkinan
ini sebagai sebuah enum.
Yuk kita liat situasi yang mungkin mau kita ekspresikan di kode dan liat kenapa enum itu berguna dan lebih cocok daripada struct di kasus ini. Katakanlah kita perlu ngurusin IP addresses (alamat IP). Saat ini, ada dua standar utama yang dipake buat alamat IP: versi empat (v4) dan versi enam (v6). Karena cuma ini kemungkinan alamat IP yang bakal ditemuin sama program kita, kita bisa nge- enumerate (menjabarkan) semua varian yang mungkin, dari sinilah enumeration dapet namanya.
Alamat IP mana pun bisa jadi alamat versi empat atau versi enam, tapi nggak bisa dua-duanya sekaligus. Sifat alamat IP itu bikin struktur data enum cocok karena sebuah nilai enum cuma bisa jadi salah satu dari varian-variannya. Baik alamat versi empat maupun versi enam itu tetep secara fundamental adalah alamat IP, jadi mereka harus diperlakukan sebagai tipe yang sama pas kode lagi nanganin situasi yang berlaku buat jenis alamat IP apa pun.
Kita bisa ekspresikan konsep ini di kode dengan mendefinisikan sebuah enumeration
IpAddrKind terus nge-list jenis-jenis alamat IP yang mungkin, yaitu V4 dan
V6. Ini adalah varian-varian dari enum-nya:
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}IpAddrKind sekarang adalah tipe data kustom yang bisa kita pake di tempat lain
di kode kita.
Nilai Enum
Kita bisa bikin instance dari masing-masing dari dua varian IpAddrKind kayak
gini:
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}Perhatiin ya kalau varian dari enum-nya punya namespace di bawah nama
enum-nya (identifier), dan kita pake titik dua ganda buat misahin keduanya. Ini
berguna karena sekarang kedua nilai IpAddrKind::V4 sama IpAddrKind::V6 itu
punya tipe yang sama: IpAddrKind. Kita terus bisa, misalnya, mendefinisikan
sebuah fungsi yang nerima IpAddrKind mana pun:
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}Dan kita bisa manggil fungsi ini pake varian yang mana aja:
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}Pake enum punya lebih banyak keuntungan lagi. Kalau dipikir-pikir lagi soal tipe alamat IP kita, saat ini kita nggak punya cara buat nyimpen data alamat IP aslinya; kita cuma tau apa jenis-nya doang. Berhubung kita baru aja belajar soal struct di Bab 5, kita mungkin tergoda buat nyelesein masalah ini pake struct kayak yang ditunjukin di Listing 6-1.
fn main() {
enum IpAddrKind {
V4,
V6,
}
struct IpAddr {
kind: IpAddrKind,
address: String,
}
let home = IpAddr {
kind: IpAddrKind::V4,
address: String::from("127.0.0.1"),
};
let loopback = IpAddr {
kind: IpAddrKind::V6,
address: String::from("::1"),
};
}IpAddrKind dari sebuah alamat IP pake structDi sini, kita mendefinisikan sebuah struct IpAddr yang punya dua field: sebuah
field kind yang tipenya IpAddrKind (enum yang kita definisikan sebelumnya)
dan sebuah field address yang tipenya String. Kita punya dua instance dari
struct ini. Yang pertama itu home, dan dia punya nilai IpAddrKind::V4
sebagai kind-nya sama data alamat terkait 127.0.0.1. Instance kedua adalah
loopback. Dia punya varian lain dari IpAddrKind sebagai nilai kind-nya,
yaitu V6, dan punya alamat ::1 yang terkait dengannya. Kita pake struct
buat ngebungkus nilai kind sama address barengan, jadi sekarang variannya
terkait sama nilainya.
Tapi, merepresentasikan konsep yang sama pake enum doang itu lebih singkat:
bukannya naruh enum di dalem struct, kita bisa naruh datanya langsung ke dalem
tiap varian enum. Definisi baru dari enum IpAddr ini bilang kalau baik varian
V4 maupun V6 bakal punya nilai String yang terkait dengannya:
fn main() {
enum IpAddr {
V4(String),
V6(String),
}
let home = IpAddr::V4(String::from("127.0.0.1"));
let loopback = IpAddr::V6(String::from("::1"));
}Kita nempelin data ke tiap varian dari enum secara langsung, jadi nggak perlu
lagi struct tambahan. Di sini, juga lebih gampang buat liat detail lain soal
gimana cara kerja enum: nama dari tiap varian enum yang kita definisikan juga
jadi sebuah fungsi yang ngonstruksi sebuah instance dari enum itu. Yaitu,
IpAddr::V4() adalah pemanggilan fungsi yang nerima argumen String terus
balikin sebuah instance dari tipe IpAddr. Kita otomatis dapet fungsi
constructor ini sebagai hasil dari mendefinisikan enum-nya.
Ada lagi keuntungan pake enum bukannya struct: tiap varian bisa punya tipe dan
jumlah data terkait yang beda-beda. Alamat IP versi empat bakal selalu punya
empat komponen numerik yang nilainya antara 0 sampe 255. Kalau kita mau nyimpen
alamat V4 sebagai empat nilai u8 tapi tetep mengekspresikan alamat V6
sebagai satu nilai String, kita nggak bakal bisa lakuin itu pake struct. Enum
nanganin kasus ini dengan gampang:
fn main() {
enum IpAddr {
V4(u8, u8, u8, u8),
V6(String),
}
let home = IpAddr::V4(127, 0, 0, 1);
let loopback = IpAddr::V6(String::from("::1"));
}Kita udah nunjukin beberapa cara beda buat mendefinisikan struktur data buat
nyimpen alamat IP versi empat sama versi enam. Tapi nyatanya, pengen nyimpen
alamat IP dan nyimpen info soal jenis alamat apa mereka itu hal yang sangat
umum sampe-sampe standard library punya definisi yang bisa kita pake!
Yuk kita liat gimana standard library mendefinisikan IpAddr: dia punya enum
dan varian yang persis sama kayak yang udah kita definisikan dan pake, tapi dia
nempelin data alamat di dalem variannya dalam bentuk dua struct yang beda, yang
didefinisikan secara beda buat tiap varian:
#![allow(unused)]
fn main() {
struct Ipv4Addr {
// --snip--
}
struct Ipv6Addr {
// --snip--
}
enum IpAddr {
V4(Ipv4Addr),
V6(Ipv6Addr),
}
}Kode ini ngegambarin kalau kita bisa masukin data jenis apa pun ke dalem varian enum: strings, tipe numerik, atau structs, misalnya. Kita bahkan bisa masukin enum lain! Selain itu, tipe-tipe standard library sering kali nggak jauh lebih ribet dari apa yang mungkin kita bikin sendiri.
Perhatiin ya walaupun standard library punya definisi buat IpAddr, kita tetep
bisa bikin dan pake definisi kita sendiri tanpa bentrok karena kita belum bawa
definisi dari standard library itu ke scope kita. Kita bakal bahas lebih lanjut
soal bawa tipe ke scope di Bab 7.
Yuk kita liat contoh enum lain di Listing 6-2: yang ini punya macem-macem tipe yang disematkan (embedded) di variannya.
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {}Message yang tiap variannya nyimpen jumlah dan tipe nilai yang bedaEnum ini punya empat varian dengan tipe yang beda-beda:
Quit: Nggak punya data yang terkait dengannya sama sekali.Move: Punya field bernama, kayak sebuah struct.Write: Termasuk sebuahStringtunggal.ChangeColor: Termasuk tiga nilaii32.
Mendefinisikan sebuah enum dengan varian kayak yang ada di Listing 6-2 itu mirip
sama mendefinisikan berbagai macam definisi struct, bedanya enum nggak pake
keyword struct dan semua variannya dikelompokin di bawah satu tipe Message.
Struct-struct berikut bisa nampung data yang sama kayak varian enum di atas:
struct QuitMessage; // unit struct
struct MoveMessage {
x: i32,
y: i32,
}
struct WriteMessage(String); // tuple struct
struct ChangeColorMessage(i32, i32, i32); // tuple struct
fn main() {}Tapi kalau kita pake struct yang beda-beda, yang mana masing-masing punya
tipenya sendiri, kita nggak bakal segampang itu mendefinisikan fungsi buat
nerima semua jenis pesan ini kayak yang bisa kita lakuin sama enum Message
yang didefinisikan di Listing 6-2, yang merupakan sebuah tipe tunggal.
Ada satu lagi kemiripan antara enum sama struct: sama kayak kita bisa
mendefinisikan methods pada structs pake impl, kita juga bisa mendefinisikan
methods pada enums. Ini sebuah method namanya call yang bisa kita definisikan
pada enum Message kita:
fn main() {
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
impl Message {
fn call(&self) {
// method body would be defined here
}
}
let m = Message::Write(String::from("hello"));
m.call();
}Body dari method ini bakal pake self buat dapet nilai di mana kita manggil
method itu. Di contoh ini, kita bikin variabel m yang punya nilai
Message::Write(String::from("hello")), dan itulah yang bakal jadi self di
dalem body method call pas m.call() jalan.
Yuk kita liat enum lain di standard library yang sangat umum dan kepake sekali:
Option.
Enum Option dan Keuntungannya Dibandingin Nilai Null
Bagian ini ngeksplor studi kasus Option, yang merupakan enum lain yang
didefinisikan sama standard library. Tipe Option nyimpen skenario yang sangat
umum di mana sebuah nilai bisa ada isinya (something) atau bisa aja kosong
nggak ada isinya sama sekali (nothing).
Misalnya, kalau kita minta item pertama dari list yang nggak kosong, kita bakal dapet sebuah nilai. Kalau kita minta item pertama dari list yang kosong, kita nggak dapet apa-apa. Mengekspresikan konsep ini dalam sistem tipe artinya compiler bisa nge-cek apakah kita udah handle semua kasus yang seharusnya kita handle; fungsionalitas ini bisa nyegah bug yang bener-bener umum di bahasa pemrograman lainnya.
Desain bahasa pemrograman sering kali dipikirin dari segi fitur apa aja yang dimasukin, tapi fitur apa aja yang nggak dimasukin (di-exclude) itu juga penting. Rust nggak punya fitur null kayak yang dipunyai banyak bahasa lain. Null adalah sebuah nilai yang artinya nggak ada nilai di sana. Di bahasa yang pake null, variabel itu selalu ada di salah satu dari dua state: null atau tidak-null.
Di presentasinya tahun 2009 yang judulnya “Null References: The Billion Dollar Mistake,” Tony Hoare, penemu null, bilang gini:
Saya sebut ini kesalahan satu miliar dolar saya. Waktu itu, saya lagi desain sistem tipe komprehensif pertama buat referensi di bahasa berbasis objek. Tujuan saya adalah buat mastiin kalau semua penggunaan referensi harus bener-bener aman, dengan pengecekan yang dilakuin otomatis sama compiler. Tapi saya nggak bisa nahan godaan buat masukin referensi null, cuma karena itu gampang sekali buat diimplementasikan. Ini udah memicu error, kerentanan, dan kerusakan sistem yang nggak kehitung jumlahnya, yang mungkin udah nyebabin penderitaan dan kerugian satu miliar dolar di empat puluh tahun terakhir.
Masalah dari nilai null adalah kalau kita nyoba pake nilai null seolah-olah itu nilai yang bukan-null, kita bakal dapet semacam error. Karena properti null atau tidak-null ini ada di mana-mana (pervasive), gampang sekali buat bikin error kayak gini.
Tapi, konsep yang dicoba diekspresikan sama null itu tetep berguna: sebuah null adalah nilai yang saat ini nggak valid atau absen karena suatu alasan.
Masalahnya sebenernya bukan di konsepnya tapi di implementasinya yang spesifik.
Maka dari itu, Rust nggak punya null, tapi dia punya sebuah enum yang bisa
mengekspresikan konsep kalau sebuah nilai itu ada atau absen. Enum ini adalah
Option<T>, dan dia didefinisikan sama standard library kayak gini:
#![allow(unused)]
fn main() {
enum Option<T> {
None,
Some(T),
}
}Enum Option<T> ini saking bergunanya sampe dia dimasukkan ke dalem prelude;
kita nggak perlu bawa dia ke scope secara eksplisit. Varian-variannya juga
dimasukkan ke prelude: kita bisa pake Some sama None secara langsung
tanpa prefix Option::. Enum Option<T> ini tetep cuma enum biasa, dan Some(T)
serta None itu tetep varian dari tipe Option<T>.
Sintaks <T> adalah fitur di Rust yang belum kita bahas. Itu adalah generic
type parameter (parameter tipe generik), dan kita bakal bahas generik lebih
detail di Bab 10. Buat sekarang, yang perlu kita tau adalah <T> artinya
varian Some dari enum Option bisa nampung satu potong data dari tipe apa
pun, dan tiap tipe konkret yang dipake gantiin T bakal bikin tipe Option<T>
secara keseluruhan jadi tipe yang beda. Ini beberapa contoh pake nilai Option
buat nampung tipe angka sama tipe char:
fn main() {
let some_number = Some(5);
let some_char = Some('e');
let absent_number: Option<i32> = None;
}Tipe dari some_number adalah Option<i32>. Tipe dari some_char adalah
Option<char>, yang merupakan tipe yang beda. Rust bisa nebak (infer) tipe-tipe
ini karena kita udah nentuin nilai di dalem varian Some. Buat absent_number,
Rust nuntut kita buat nganotasi tipe Option secara keseluruhan: compiler nggak
bisa nebak tipe yang bakal ditampung sama varian Some pasangannya kalau cuma
liat dari nilai None doang. Di sini, kita ngasih tau Rust kalau maksud kita
adalah absent_number itu tipenya Option<i32>.
Pas kita punya nilai Some, kita tau kalau nilainya ada dan nilainya ditampung
di dalem Some-nya. Pas kita punya nilai None, dalam arti tertentu maknanya
sama kayak null: kita nggak punya nilai yang valid. Terus kenapa punya
Option<T> itu lebih baik daripada punya null?
Singkatnya, karena Option<T> sama T (di mana T bisa tipe apa pun) adalah
tipe yang beda, compiler nggak bakal ngebolehin kita pake nilai Option<T>
seolah-olah itu pasti nilai yang valid. Misalnya, kode ini nggak bakal bisa
di-compile, karena dia nyoba nambahin i8 ke dalem Option<i8>:
fn main() {
let x: i8 = 5;
let y: Option<i8> = Some(5);
let sum = x + y;
}Kalau kita jalanin kode ini, kita dapet pesan error kayak gini:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0277]: cannot add `Option<i8>` to `i8`
--> src/main.rs:5:17
|
5 | let sum = x + y;
| ^ no implementation for `i8 + Option<i8>`
|
= help: the trait `Add<Option<i8>>` is not implemented for `i8`
= help: the following other types implement trait `Add<Rhs>`:
`&i8` implements `Add<i8>`
`&i8` implements `Add`
`i8` implements `Add<&i8>`
`i8` implements `Add`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `enums` (bin "enums") due to 1 previous error
Sadis ya! Intinya, pesan error ini artinya Rust nggak paham gimana cara nambahin
i8 sama Option<i8>, karena mereka berdua tipe yang beda. Pas kita punya
nilai dari suatu tipe kayak i8 di Rust, compiler bakal mastiin kalau kita
selalu punya nilai yang valid. Kita bisa lanjut dengan pede tanpa harus nge-cek
null dulu sebelum pake nilai itu. Cuma pas kita punya Option<i8> (atau tipe
nilai apa pun yang lagi kita kerjain) barulah kita harus khawatir soal kemungkinan
nggak punya nilai, dan compiler bakal mastiin kita handle kasus itu sebelum
pake nilainya.
Dengan kata lain, kita harus convert Option<T> jadi T dulu sebelum kita bisa
ngelakuin operasi T pake itu. Umumnya, ini ngebantu nangkap salah satu masalah
paling umum sama null: ngasumsikan kalau sesuatu itu nggak null padahal
sebenernya iya.
Ngilangin risiko salah ngasumsikan nilai nggak-null ngebantu kita biar lebih pede
sama kode kita. Buat punya nilai yang mungkin bisa null, kita harus secara
eksplisit milih (opt in) dengan bikin tipe dari nilai itu jadi Option<T>.
Terus, pas kita pake nilai itu, kita diwajibkan buat secara eksplisit nanganin
kasus pas nilainya itu null. Di mana pun ada nilai yang tipenya bukan Option<T>,
kita bisa dengan aman ngasumsikan kalau nilai itu bukan null. Ini adalah
keputusan desain yang disengaja buat Rust buat ngebatesin null yang ada di
mana-mana dan ningkatin keamanan kode Rust.
Terus gimana cara ngeluarin nilai T dari sebuah varian Some pas kita punya
nilai bertipe Option<T> biar kita bisa pake nilainya? Enum Option<T> punya
sangat banyak method yang kepake di berbagai situasi; kita bisa cek mereka di
dokumentasinya. Biasain diri sama method-method di Option<T> bakal
sangat berguna di perjalanan kita bareng Rust.
Umumnya, buat pake sebuah nilai Option<T>, kita mau punya kode yang bakal
nanganin tiap variannya. Kita mau ada kode yang bakal jalan cuma pas kita punya
nilai Some(T), dan kode ini dibolehin buat pake T di dalemnya. Kita mau ada
kode lain yang jalan cuma kalau kita punya nilai None, dan kode itu nggak
punya nilai T yang bisa dipake. Ekspresi match adalah konstruk control flow
yang ngelakuin hal ini pas dipake bareng enum: dia bakal ngejalanin kode yang
beda-beda tergantung varian enum mana yang dia punya, dan kode itu bisa pake
data yang ada di dalem nilai yang cocok.
Konstruk Control Flow match
Konstruk Control Flow match
Rust punya konstruk control flow yang sangat kuat (powerful) namanya match
yang ngebolehin kita bandingin sebuah nilai sama serangkaian pattern (pola)
terus ngejalanin kode berdasarkan pattern mana yang cocok. Pattern bisa dibuat
dari nilai literal, nama variabel, wildcards, dan banyak hal lainnya;
Bab 19 ngebahas semua jenis pattern yang beda dan apa fungsinya.
Kekuatan dari match dateng dari ekspresifitas pattern-nya dan fakta kalau
compiler mastiin semua kemungkinan kasus udah di-handle.
Bayangin ekspresi match itu kayak mesin penyortir koin: koin meluncur turun di
jalur yang punya lubang dengan berbagai ukuran, dan tiap koin bakal jatuh ke
lubang pertama yang pas buat dia. Dengan cara yang sama, nilai bakal ngelewatin
tiap pattern di sebuah match, dan di pattern pertama di mana nilainya “pas,”
nilai itu bakal masuk ke blok kode terkait buat dipake pas eksekusi.
Ngomong-ngomong soal koin, yuk kita pake mereka sebagai contoh buat match!
Kita bisa nulis fungsi yang nerima koin US yang nggak tau jenisnya apa dan,
dengan cara yang mirip kayak mesin penghitung, nentuin koin apa itu terus
balikin nilainya dalam satuan sen (cents), kayak yang ditunjukin di Listing 6-3.
enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
}
}
fn main() {}match yang punya varian enum sebagai pattern-nyaYuk kita bedah ekspresi match di fungsi value_in_cents. Pertama kita nulis
keyword match diikuti sama sebuah ekspresi, yang di kasus ini adalah nilai
coin. Ini keliatannya mirip sekali sama ekspresi kondisional yang dipake bareng
if, tapi ada perbedaan gede: kalau pake if, kondisinya harus dievaluasi jadi
nilai Boolean, tapi di sini dia bisa jadi tipe apa pun. Tipe dari coin di
contoh ini adalah enum Coin yang kita definisikan di baris pertama.
Selanjutnya adalah arms (lengan) dari match. Sebuah arm punya dua bagian:
sebuah pattern dan sejumlah kode. Arm pertama di sini punya pattern yaitu nilai
Coin::Penny dan terus operator => yang misahin pattern sama kode yang bakal
dijalanin. Kode di kasus ini cuma nilai 1. Tiap arm dipisahin dari arm
berikutnya pake tanda koma.
Pas ekspresi match jalan, dia bandingin nilai hasilnya sama pattern dari tiap
arm, secara berurutan. Kalau ada pattern yang cocok sama nilainya, kode yang
terkait sama pattern itu bakal dijalanin. Kalau pattern itu nggak cocok sama
nilainya, eksekusi bakal lanjut ke arm berikutnya, sama persis kayak di mesin
penyortir koin. Kita bisa punya sebanyak apa pun arm yang kita butuhin: di
Listing 6-3, match kita punya empat arm.
Kode yang terkait sama tiap arm itu adalah sebuah ekspresi, dan nilai hasil dari
ekspresi di arm yang cocok adalah nilai yang bakal dibalikin buat seluruh
ekspresi match-nya.
Kita biasanya nggak pake kurung kurawal kalau kode match arm-nya pendek, kayak
di Listing 6-3 di mana tiap arm cuma balikin sebuah nilai. Kalau kita mau
ngejalanin beberapa baris kode di sebuah match arm, kita wajib pake kurung
kurawal, dan koma setelah arm-nya itu jadi opsional. Misalnya, kode berikut
nyetak “Lucky penny!” tiap kali method-nya dipanggil pake Coin::Penny, tapi
tetep balikin nilai terakhir dari blok-nya, yaitu 1:
enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => {
println!("Lucky penny!");
1
}
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
}
}
fn main() {}Pattern yang Nge-bind ke Nilai
Fitur berguna lainnya dari match arms adalah mereka bisa nge-bind ke bagian- bagian nilai yang cocok sama pattern-nya. Ini cara kita ngekstrak nilai keluar dari varian enum.
Sebagai contoh, yuk kita ubah salah satu varian enum kita biar nyimpen data di
dalemnya. Dari tahun 1999 sampe 2008, Amerika Serikat nyetak koin quarter
(25 sen) dengan desain beda-beda buat tiap 50 negara bagian di satu sisinya.
Nggak ada koin lain yang dapet desain negara bagian, jadi cuma quarter yang
punya nilai ekstra ini. Kita bisa nambahin informasi ini ke enum kita dengan
ngerubah varian Quarter biar masukin nilai UsState yang disimpan di dalemnya,
kayak yang kita lakuin di Listing 6-4.
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn main() {}Coin di mana varian Quarter juga nyimpen nilai UsStateBayangin ada temen kita yang lagi nyoba ngumpulin semua 50 state quarters. Pas kita lagi nyortir uang receh berdasarkan jenis koinnya, kita juga bakal nyebutin nama negara bagian yang terkait sama tiap quarter biar kalau temen kita belum punya yang itu, dia bisa nambahin ke koleksinya.
Di ekspresi match buat kode ini, kita nambahin variabel namanya state ke
pattern yang nyocokin nilai varian Coin::Quarter. Pas sebuah Coin::Quarter
cocok, variabel state bakal di-bind ke nilai negara bagian dari quarter itu.
Terus kita bisa pake state di kode buat arm itu, kayak gini:
#[derive(Debug)]
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter(state) => {
println!("State quarter from {state:?}!");
25
}
}
}
fn main() {
value_in_cents(Coin::Quarter(UsState::Alaska));
}Kalau kita manggil value_in_cents(Coin::Quarter(UsState::Alaska)), coin bakal
jadi Coin::Quarter(UsState::Alaska). Pas kita bandingin nilai itu sama tiap
match arms, nggak ada satu pun yang cocok sampe kita nyampe Coin::Quarter(state).
Di titik itu, binding buat state bakal jadi nilai UsState::Alaska. Kita
terus bisa pake binding itu di ekspresi println!, dan dengan gitu kita dapet
nilai state dalemnya keluar dari varian enum Coin buat Quarter.
Matching dengan Option<T>
Di bagian sebelumnya, kita mau dapet nilai T di dalem dari kasus Some pas
lagi pake Option<T>; kita juga bisa nanganin Option<T> pake match, sama
kayak yang kita lakuin sama enum Coin! Bukannya ngebandingin koin, kita bakal
ngebandingin varian Option<T>, tapi cara kerja ekspresi match-nya tetep sama.
Katakanlah kita mau nulis fungsi yang nerima sebuah Option<i32> dan, kalau ada
nilai di dalemnya, nambahin 1 ke nilai itu. Kalau nggak ada nilainya, fungsi itu
harus balikin nilai None dan nggak nyoba ngelakuin operasi apa pun.
Fungsi ini gampang sekali ditulis, berkat match, dan bakal keliatan kayak
Listing 6-5.
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}match pada sebuah Option<i32>Yuk kita teliti eksekusi pertama dari plus_one lebih dalem. Pas kita manggil
plus_one(five), variabel x di body plus_one bakal punya nilai Some(5).
Kita terus bandingin itu sama tiap match arm:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Nilai Some(5) nggak cocok sama pattern None, jadi kita lanjut ke arm
berikutnya:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Apakah Some(5) cocok sama Some(i)? Cocok dong! Kita dapet varian yang sama.
i di-bind ke nilai yang ditampung di Some, jadi i ngambil nilai 5. Kode
di match arm itu kemudian dijalanin, jadi kita nambahin 1 ke nilai i dan
bikin nilai Some baru dengan total 6 kita di dalemnya.
Sekarang yuk kita pertimbangkan pemanggilan kedua dari plus_one di Listing 6-5,
di mana x itu None. Kita masuk ke match dan bandingin sama arm pertama:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Cocok! Nggak ada nilai buat ditambahin, jadi programnya berhenti dan balikin
nilai None di sisi kanan =>. Karena arm pertama cocok, nggak ada arm lain
yang dibandingin.
Gabungin match sama enum itu berguna di banyak situasi. Kita bakal sering
liat pola ini di kode Rust: nge-match terhadap sebuah enum, nge-bind variabel
ke data di dalemnya, terus ngejalanin kode berdasarkan data itu. Agak ribet di
awal emang, tapi sekali kita udah terbiasa, kita bakal ngarep ini ada di semua
bahasa. Ini terus-terusan jadi favorit user.
Matches Itu Exhaustive (Menyeluruh)
Ada satu aspek lain dari match yang perlu kita bahas: pattern-pattern di
arm-nya harus mencakup semua kemungkinan. Coba liat versi dari fungsi plus_one
kita ini, yang punya bug dan nggak bakal bisa di-compile:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Kita nggak nge-handle kasus None, jadi kode ini bakal nyebabin bug. Untungnya,
ini adalah bug yang Rust tau cara nangkepnya. Kalau kita nyoba compile kode
ini, kita bakal dapet error kayak gini:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0004]: non-exhaustive patterns: `None` not covered
--> src/main.rs:3:15
|
3 | match x {
| ^ pattern `None` not covered
|
note: `Option<i32>` defined here
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/option.rs:593:1
::: /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/option.rs:597:5
|
= note: not covered
= note: the matched value is of type `Option<i32>`
help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern or an explicit pattern as shown
|
4 ~ Some(i) => Some(i + 1),
5 ~ None => todo!(),
|
For more information about this error, try `rustc --explain E0004`.
error: could not compile `enums` (bin "enums") due to 1 previous error
Rust tau kalau kita nggak mencakup semua kasus yang mungkin, dan bahkan tau
pattern mana yang kita kelupaan! Matches di Rust itu exhaustive: kita harus
ngabisin setiap kemungkinan yang ada biar kodenya jadi valid. Terutama buat kasus
Option<T>, pas Rust nyegah kita dari lupa buat secara eksplisit nanganin kasus
None, dia ngelindungin kita dari ngasumsikan kalau kita punya nilai padahal
mungkin kita punya null, makanya ini ngebikin kesalahan satu miliar dolar yang
dibahas sebelumnya jadi mustahil terjadi.
Catch-All Patterns dan Placeholder _
Pake enum, kita juga bisa ngambil aksi khusus buat beberapa nilai tertentu, tapi
buat semua nilai lainnya kita mau ngambil satu aksi default. Bayangin kita lagi
bikin game di mana kalau kita ngelempar dadu dan dapet 3, player kita nggak gerak,
tapi malah dapet topi fancy baru. Kalau dapet 7, player kita kehilangan topi
fancy-nya. Buat semua nilai lainnya, player kita maju sejumlah langkah sesuai
angka itu di papan game. Ini ekspresi match yang mengimplementasikan logika itu,
dengan hasil lemparan dadu yang di-hardcoded bukannya nilai random, dan semua
logika lainnya direpresentasikan sama fungsi tanpa body karena implementasi
aslinya di luar cakupan contoh ini:
fn main() {
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
other => move_player(other),
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
fn move_player(num_spaces: u8) {}
}Buat dua arm pertama, pattern-nya adalah nilai literal 3 dan 7. Buat arm
terakhir yang nyakup semua kemungkinan nilai lainnya, pattern-nya adalah
variabel yang kita pilih buat dikasih nama other. Kode yang jalan buat arm
other pake variabel itu dengan masukin dia ke fungsi move_player.
Kode ini berhasil di-compile, walaupun kita belum nyebutin semua nilai yang
mungkin dipunyai u8, karena pattern terakhir bakal nyocokin semua nilai yang
nggak disebutin secara spesifik. Catch-all pattern ini menuhin syarat kalau
match itu harus exhaustive. Perhatiin ya kalau kita harus naruh arm
catch-all di paling akhir karena pattern-nya dievaluasi berurutan. Kalau kita
naruh arm catch-all lebih awal, arm lainnya nggak bakal pernah jalan, jadi
Rust bakal ngasih tau kita kalau kita nambahin arm setelah catch-all!
Rust juga punya pattern yang bisa kita pake pas kita butuh catch-all tapi nggak
mau pake nilainya di pattern catch-all itu: _ adalah pattern khusus yang
nyocokin nilai apa pun dan nggak nge-bind ke nilai itu. Ini ngasih tau Rust
kalau kita nggak bakal pake nilainya, jadi Rust nggak bakal ngasih warning soal
variabel yang nggak kepake.
Yuk kita ubah aturan gamenya: sekarang, kalau kita ngelempar dadu selain angka
3 atau 7, kita harus ngelempar lagi. Kita udah nggak perlu pake nilai catch-all,
jadi kita bisa ubah kode kita pake _ bukannya variabel namanya other:
fn main() {
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
_ => reroll(),
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
fn reroll() {}
}Contoh ini juga menuhin syarat exhaustiveness karena secara eksplisit kita ngabaikan semua nilai lain di arm terakhir; kita nggak ada yang kelupaan.
Terakhir, kita bakal ubah aturan gamenya sekali lagi biar nggak ada yang terjadi
pas giliran kita kalau kita ngelempar selain angka 3 atau 7. Kita bisa ekspresikan
itu pake nilai unit (tipe tuple kosong yang pernah kita sebut di bagian “Tipe
Tuple”) sebagai kode yang nyertain arm _:
fn main() {
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
_ => (),
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
}Di sini, kita ngasih tau Rust secara eksplisit kalau kita nggak bakal pake nilai lain apa pun yang nggak cocok sama pattern di arm sebelumnya, dan kita nggak mau ngejalanin kode apa pun di kasus ini.
Masih banyak hal lain soal pattern dan matching yang bakal kita bahas di Bab 19.
Buat sekarang, kita bakal lanjut ke sintaks if let, yang bisa kepake di
situasi-situasi di mana ekspresi match dirasa agak kepanjangan (wordy).
Control Flow Singkat Memakai if let dan let...else
Control Flow yang Ringkas pake if let sama let else
Sintaks if let ngebolehin kita ngegabungin if sama let jadi cara yang lebih
ringkas buat nge-handle nilai yang cocok sama satu pattern sambil nyuekin sisanya.
Coba liat program di Listing 6-6 yang nge-match nilai Option<u8> di variabel
config_max tapi cuma mau ngejalanin kode kalau nilainya itu varian Some.
fn main() {
let config_max = Some(3u8);
match config_max {
Some(max) => println!("The maximum is configured to be {max}"),
_ => (),
}
}match yang cuma peduli buat ngejalanin kode pas nilainya SomeKalau nilainya Some, kita nyetak nilainya di varian Some dengan nge-bind
nilai itu ke variabel max di dalem pattern-nya. Kita nggak mau ngelakuin apa-
apa sama nilai None. Buat menuhin syarat ekspresi match, kita harus nambahin
_ => () setelah memproses cuma satu varian, yang mana ini lumayan nyebelin
karena jadi boilerplate code yang harus ditambahin.
Sebagai gantinya, kita bisa nulis ini dengan cara yang lebih singkat pake if let.
Kode berikut perilakunya sama persis kayak match di Listing 6-6:
fn main() {
let config_max = Some(3u8);
if let Some(max) = config_max {
println!("The maximum is configured to be {max}");
}
}Sintaks if let nerima sebuah pattern sama sebuah ekspresi yang dipisahin sama
tanda sama dengan. Dia cara kerjanya sama kayak sebuah match, di mana
ekspresinya dikasih ke match dan pattern-nya itu adalah arm pertamanya.
Di kasus ini, pattern-nya adalah Some(max), dan max di-bind ke nilai di dalem
Some. Terus kita bisa pake max di dalem body blok if let dengan cara yang
sama kayak kita pake max di arm match yang terkait. Kode di dalem blok if let
cuma jalan kalau nilainya cocok sama pattern-nya.
Pake if let artinya lebih dikit ngetik, lebih dikit indentasi, dan lebih dikit
boilerplate code. Tapi, kita kehilangan pengecekan exhaustive (menyeluruh)
yang diterapin sama match yang mastiin kalau kita nggak lupa nge-handle kasus
apa pun. Milih antara match sama if let tergantung dari apa yang lagi kita
lakuin di situasi kita saat itu dan apakah dapet keringkasan itu sebuah trade-off
yang pas buat ngorbanin pengecekan menyeluruh.
Dengan kata lain, kita bisa mikirin if let sebagai syntax sugar buat sebuah
match yang ngejalanin kode pas nilainya cocok sama satu pattern terus nyuekin
semua nilai lainnya.
Kita bisa masukin sebuah else barengan sama if let. Blok kode yang ngikutin
else itu sama kayak blok kode yang ngikutin kasus _ di ekspresi match
yang setara sama if let dan else itu. Inget definisi enum Coin di
Listing 6-4, di mana varian Quarter juga nyimpen nilai UsState. Kalau kita
mau ngitung semua koin yang bukan quarter sambil nyebutin negara bagian dari si
quarter, kita bisa lakuin itu pake ekspresi match, kayak gini:
#[derive(Debug)]
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn main() {
let coin = Coin::Penny;
let mut count = 0;
match coin {
Coin::Quarter(state) => println!("State quarter from {state:?}!"),
_ => count += 1,
}
}Atau kita bisa pake ekspresi if let dan else, kayak gini:
#[derive(Debug)]
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn main() {
let coin = Coin::Penny;
let mut count = 0;
if let Coin::Quarter(state) = coin {
println!("State quarter from {state:?}!");
} else {
count += 1;
}
}Tetep di Jalur Aman (“Happy Path”) pake let...else
Pola yang umum adalah ngelakuin sebuah komputasi pas sebuah nilai ada isinya
dan balikin nilai default kalau sebaliknya. Lanjut pake contoh kita soal koin
dengan nilai UsState, kalau kita mau ngomong sesuatu yang lucu tergantung
seberapa tua negara bagian di koin quarter itu, kita mungkin bakal nambahin
sebuah method di UsState buat nge-cek umur sebuah negara bagian, kayak gini:
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
if let Coin::Quarter(state) = coin {
if state.existed_in(1900) {
Some(format!("{state:?} is pretty old, for America!"))
} else {
Some(format!("{state:?} is relatively new."))
}
} else {
None
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}Terus kita mungkin pake if let buat nge-match tipe koinnya, ngenalin variabel
state di dalem body kondisinya, kayak di Listing 6-7.
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
if let Coin::Quarter(state) = coin {
if state.existed_in(1900) {
Some(format!("{state:?} is pretty old, for America!"))
} else {
Some(format!("{state:?} is relatively new."))
}
} else {
None
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}if let.Emang beres sih kerjaannya, tapi ini ngegeser kerjaannya ke dalem body
statement if let, dan kalau kerjaan yang harus dilakuin lebih ribet, bakal
susah buat ngikutin persis gimana cabang-cabang top-level (tingkat atas)-nya
berhubungan. Kita juga bisa manfaatin fakta kalau ekspresi ngasilin nilai buat
ngasilin state dari if let atau return early (kembali lebih awal), kayak
di Listing 6-8. (Kita juga bisa ngelakuin hal yang mirip pake match.)
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
let state = if let Coin::Quarter(state) = coin {
state
} else {
return None;
};
if state.existed_in(1900) {
Some(format!("{state:?} is pretty old, for America!"))
} else {
Some(format!("{state:?} is relatively new."))
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}if let buat ngasilin sebuah nilai atau return early.Tapi ini agak nyebelin buat diikutin dengan caranya sendiri! Satu cabang dari
if let ngasilin nilai, dan yang satunya return dari fungsi sepenuhnya.
Buat bikin pola umum ini lebih enak buat diekspresikan, Rust punya let...else.
Sintaks let...else nerima sebuah pattern di sisi kiri dan sebuah ekspresi di
sisi kanan, mirip sekali sama if let, tapi dia nggak punya cabang if, cuma
cabang else. Kalau pattern-nya cocok, dia bakal nge-bind nilai dari pattern
ke scope luar. Kalau pattern-nya nggak cocok, programnya bakal ngalir ke
dalem arm else, yang harus return (kembali) dari fungsinya.
Di Listing 6-9, kita bisa liat gimana penampakan Listing 6-8 pas pake let...else
sebagai ganti dari if let.
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
let Coin::Quarter(state) = coin else {
return None;
};
if state.existed_in(1900) {
Some(format!("{state:?} is pretty old, for America!"))
} else {
Some(format!("{state:?} is relatively new."))
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}let...else buat ngejelasin alur (flow) lewat fungsinya.Perhatiin ya kalau dia tetep “on the happy path” (di jalur aman yang diharapkan)
di body utama fungsinya pake cara ini, tanpa harus punya alur kontrol yang
bener-bener beda jauh buat dua cabang kayak yang dilakuin sama if let.
Kalau kita ada di situasi di mana program kita punya logika yang terlalu panjang
(verbose) buat diekspresikan pake match, inget ya kalau if let sama
let...else juga ada di dalem toolbox Rust kita.
Ringkasan
Kita sekarang udah ngebahas gimana cara pake enum buat bikin tipe kustom yang
bisa jadi salah satu dari sekumpulan nilai yang di-enumerate. Kita udah
nunjukin gimana tipe Option<T> bawaan standard library ngebantu kita pake
sistem tipe buat nyegah error. Pas nilai enum punya data di dalemnya, kita bisa
pake match atau if let buat ngekstrak dan pake nilai-nilai itu, tergantung
dari seberapa banyak kasus yang perlu kita handle.
Program Rust kita sekarang bisa mengekspresikan konsep di domain kita pake struct dan enum. Bikin tipe kustom buat dipake di API kita mastiin keamanan tipe (type safety): compiler bakal mastiin fungsi kita cuma dapet nilai dari tipe yang diharapkan sama tiap fungsinya.
Buat nyediain API yang terorganisir dengan baik ke user kita yang gampang buat dipake dan cuma nge-ekspos tepat apa yang dibutuhin sama user kita aja, yuk sekarang kita beralih ke modules (modul) di Rust.
Mengelola Project yang Makin Gede pake Packages, Crates, sama Modules
Seiring kita nulis program yang makin gede, ngatur organisasi kode kita bakal makin penting. Dengan ngelempokin fungsionalitas yang terkait dan misahin kode dengan fitur yang beda, kita bakal lebih gampang nemuin di mana kode yang mengimplementasikan fitur tertentu dan ke mana harus pergi buat ngerubah cara kerja sebuah fitur.
Program-program yang udah kita tulis sejauh ini semuanya ada di satu modul di dalem satu file. Seiring berkembangnya project, kita harus ngatur kodenya dengan mecahnya jadi banyak modul dan terus jadi banyak file. Sebuah package bisa isinya banyak binary crates dan opsionalnya satu library crate. Pas sebuah package makin gede, kita bisa ngekstrak bagian-bagiannya jadi crates terpisah yang bakal jadi dependensi eksternal. Bab ini ngebahas semua teknik ini. Buat project yang bener-bener gede yang disusun dari sekumpulan packages yang saling berhubungan dan berkembang bareng, Cargo nyediain workspaces, yang bakal kita bahas di “Cargo Workspaces” di Bab 14.
Kita juga bakal bahas gimana nyembunyiin (encapsulating) detail implementasi, yang ngebolehin kita buat pake ulang (reuse) kode di tingkat yang lebih tinggi: sekali kita udah mengimplementasikan sebuah operasi, kode lain bisa manggil kode kita lewat antarmuka public-nya tanpa harus tau gimana detail implementasinya jalan. Cara kita nulis kode bakal nentuin bagian mana yang public buat dipake kode lain dan bagian mana yang merupakan detail implementasi private yang kita punya hak buat ngubahnya kapan aja. Ini cara lain buat ngebatesin jumlah detail yang harus kita inget-inget di kepala kita.
Konsep yang terkait adalah scope (ruang lingkup): konteks bersarang (nested) di mana kode itu ditulis punya sekumpulan nama yang didefinisikan sebagai “di dalem scope.” Pas baca, nulis, dan nge-compile kode, programmer dan compiler perlu tau apakah nama tertentu di tempat tertentu itu ngerujuk ke variabel, fungsi, struct, enum, modul, konstanta, atau item lainnya dan apa makna dari item itu. Kita bisa bikin scopes dan ngerubah nama apa aja yang masuk atau keluar dari scope. Kita nggak bisa punya dua item dengan nama yang sama di scope yang sama; ada tools yang tersedia buat nyelesein konflik nama.
Rust punya sejumlah fitur yang ngebolehin kita ngatur organisasi kode kita, termasuk detail apa yang diekspos, detail apa yang private, dan nama apa aja yang ada di tiap scope di program kita. Fitur-fitur ini, yang kadang secara kolektif disebut module system (sistem modul), meliputi:
- Packages: Fitur Cargo yang ngebolehin kita buat build, test, dan nge-share crates.
- Crates: Struktur pohon modul yang ngasilin library atau file executable.
- Modules dan use: Ngebolehin kita buat ngontrol organisasi, scope, dan privasi dari paths.
- Paths: Cara buat namain sebuah item, kayak struct, fungsi, atau modul.
Di bab ini, kita bakal ngebahas semua fitur ini, liat gimana mereka berinteraksi, dan ngejelasin gimana cara pakenya buat ngelola scope. Pas selesai nanti, kita bakal punya pemahaman yang solid soal sistem modul dan bisa main-main sama scope layaknya pro!
Packages dan Crates
Packages dan Crates
Bagian pertama dari sistem modul yang bakal kita bahas adalah packages (paket) dan crates.
Sebuah crate adalah jumlah kode paling kecil yang dipertimbangkan sama compiler
Rust dalam satu waktu. Walaupun kita jalanin rustc bukannya cargo terus
masukin satu file source code (kayak yang kita lakuin dulu sekali di “Menulis
dan Menjalankan Program Rust” di Bab 1), compiler nganggep file itu sebagai
sebuah crate. Crates bisa isinya modul, dan modul itu mungkin didefinisikan di
file lain yang bakal di-compile barengan sama crate-nya, kayak yang bakal kita
liat di bagian-bagian selanjutnya.
Sebuah crate bisa dateng dalam salah satu dari dua bentuk: sebuah binary crate
atau sebuah library crate. Binary crates adalah program yang bisa kita
compile jadi executable yang bisa dijalanin, kayak program command line
atau sebuah server. Masing-masing harus punya fungsi namanya main yang
nentuin apa yang terjadi pas program executable itu jalan. Semua crates yang
udah kita bikin sejauh ini adalah binary crates.
Library crates nggak punya fungsi main, dan mereka nggak di-compile jadi
executable. Sebaliknya, mereka mendefinisikan fungsionalitas yang tujuannya
buat di-share ke banyak project. Misalnya, rand crate yang kita pake di
Bab 2 nyediain fungsionalitas buat nge-generate angka random. Kebanyakan
waktu pas Rustacean bilang “crate,” maksudnya adalah library crate, dan mereka
pake kata “crate” secara bergantian sama konsep pemrograman umum dari sebuah
“library” (perpustakaan).
Crate root adalah file sumber (source file) tempat compiler Rust mulai dan ngebentuk modul root (akar) dari crate kita (kita bakal jelasin modul secara mendalam di “Mendefinisikan Modul untuk Mengontrol Scope dan Privasi”).
Sebuah package adalah bundel dari satu atau lebih crates yang nyediain sekumpulan fungsionalitas. Sebuah package punya file Cargo.toml yang ngejelasin gimana cara nge-build crates itu. Cargo sebenernya adalah sebuah package yang isinya binary crate buat tool command line yang selama ini kita pake buat nge-build kode kita. Package Cargo juga punya sebuah library crate yang bergantung pada binary crate-nya. Project lain bisa bergantung pada library crate Cargo buat pake logika yang sama kayak yang dipake sama tool command line Cargo.
Sebuah package bisa isinya sebanyak apa pun binary crates yang kita mau, tapi maksimal cuma boleh punya satu library crate. Sebuah package minimal harus punya satu crate, entah itu library crate atau binary crate.
Yuk kita telusuri apa yang terjadi pas kita bikin sebuah package. Pertama kita
jalanin perintah cargo new my-project:
$ cargo new my-project
Created binary (application) `my-project` package
$ ls my-project
Cargo.toml
src
$ ls my-project/src
main.rs
Setelah kita jalanin cargo new my-project, kita pake ls buat liat apa yang
dibuat sama Cargo. Di direktori project-nya, ada file Cargo.toml, yang ngasih
kita sebuah package. Ada juga direktori src yang isinya main.rs. Buka file
Cargo.toml di text editor kita, dan perhatiin kalau nggak ada sebutan soal
src/main.rs. Cargo ngikutin konvensi kalau src/main.rs itu adalah crate root
dari sebuah binary crate dengan nama yang sama kayak package-nya. Sama juga,
Cargo tau kalau direktori package-nya punya src/lib.rs, berarti package itu
punya library crate dengan nama yang sama kayak package-nya, dan src/lib.rs
itu adalah crate root-nya. Cargo bakal ngasih file crate root ini ke rustc
buat nge-build library atau binary-nya.
Di sini, kita punya package yang isinya cuma src/main.rs, artinya dia cuma
punya sebuah binary crate namanya my-project. Kalau sebuah package punya
src/main.rs sama src/lib.rs, dia punya dua crates: sebuah binary dan
sebuah library, yang keduanya punya nama yang sama kayak package-nya. Sebuah
package bisa punya banyak binary crates dengan naruh file-file-nya di direktori
src/bin: tiap file bakal jadi binary crate yang terpisah.
Mengontrol Scope dan Privacy Memakai Modul
Mendefinisikan Modul untuk Mengontrol Scope dan Privasi
Di bagian ini, kita bakal bahas modul dan bagian lain dari sistem modul, yaitu
paths (jalur), yang ngebolehin kita buat namain item; keyword use yang bawa
sebuah path ke dalem scope; dan keyword pub buat bikin item jadi public.
Kita juga bakal bahas keyword as, external packages (package eksternal), dan
operator glob.
Contekan (Cheat Sheet) Modul
Sebelum kita masuk ke detail soal modul dan paths, di sini kita nyediain
referensi cepet soal gimana cara kerja modul, paths, keyword use, sama
keyword pub di compiler, dan gimana kebanyakan developer ngatur kode
mereka. Kita bakal ngebahas contoh-contoh dari tiap aturan ini di sepanjang bab
ini, tapi tempat ini cocok sekali buat dijadiin pengingat soal gimana modul itu
jalan.
- Mulai dari crate root: Pas nge-compile sebuah crate, compiler pertama kali nyari di file crate root (biasanya src/lib.rs buat library crate atau src/main.rs buat binary crate) buat nyari kode yang mau di-compile.
- Mendeklarasikan modul: Di file crate root, kita bisa mendeklarasikan
modul baru; katakanlah kita mendeklarasikan modul “garden” pake
mod garden;. Compiler bakal nyari kode modul itu di tempat-tempat ini:- Inline, di dalem kurung kurawal yang nggantiin titik koma setelah
mod garden - Di file src/garden.rs
- Di file src/garden/mod.rs
- Inline, di dalem kurung kurawal yang nggantiin titik koma setelah
- Mendeklarasikan submodul: Di file mana pun selain crate root, kita bisa
mendeklarasikan submodul. Misalnya, kita mungkin mendeklarasikan
mod vegetables;di src/garden.rs. Compiler bakal nyari kode submodul itu di dalem direktori yang namanya sama kayak modul induk (parent)-nya di tempat-tempat ini:- Inline, langsung setelah
mod vegetables, di dalem kurung kurawal bukannya titik koma - Di file src/garden/vegetables.rs
- Di file src/garden/vegetables/mod.rs
- Inline, langsung setelah
- Paths ke kode di modul: Begitu sebuah modul jadi bagian dari crate kita,
kita bisa ngerujuk ke kode di modul itu dari mana pun di crate yang sama,
selama aturan privasinya ngebolehin, pake path ke kodenya. Misalnya, tipe
Asparagusdi modul vegetables dari garden bakal ditemuin dicrate::garden::vegetables::Asparagus. - Private vs. public: Kode di dalem sebuah modul itu private (privat)
dari modul induknya secara default. Buat bikin modul jadi public (publik),
deklarasikan pake
pub modbukannyamod. Buat bikin item di dalem modul public ikutan jadi public juga, pakepubsebelum deklarasinya. - Keyword
use: Di dalem sebuah scope, keywordusebikin shortcut (jalan pintas) ke item buat ngurangin pengulangan paths yang panjang. Di scope mana pun yang bisa ngerujuk kecrate::garden::vegetables::Asparagus, kita bisa bikin shortcut pakeuse crate::garden::vegetables::Asparagus;dan dari situ kita cuma perlu nulisAsparagusbuat pake tipe itu di scope tersebut.
Di sini, kita bikin sebuah binary crate namanya backyard yang nunjukin
aturan-aturan ini. Direktori crate-nya, yang juga namanya backyard, punya file
dan direktori ini:
backyard
├── Cargo.lock
├── Cargo.toml
└── src
├── garden
│ └── vegetables.rs
├── garden.rs
└── main.rs
File crate root di kasus ini adalah src/main.rs, dan isinya:
use crate::garden::vegetables::Asparagus;
pub mod garden;
fn main() {
let plant = Asparagus {};
println!("I'm growing {plant:?}!");
}Baris pub mod garden; ngasih tau compiler buat masukin kode yang dia nemu
di src/garden.rs, yaitu:
pub mod vegetables;Di sini, pub mod vegetables; artinya kode di src/garden/vegetables.rs juga
dimasukin. Kode itu adalah:
#[derive(Debug)]
pub struct Asparagus {}Sekarang yuk kita masuk ke detail dari aturan-aturan ini dan demonstrasikan pas lagi dipake!
Ngelempokin Kode yang Terkait di Modul
Modul ngebolehin kita ngatur kode di dalem sebuah crate buat readability (keterbacaan) dan biar gampang dipake ulang (reuse). Modul juga ngebolehin kita ngontrol privasi dari item karena kode di dalem sebuah modul itu private secara default. Item private adalah detail implementasi internal yang nggak tersedia buat dipake dari luar. Kita bisa milih buat bikin modul dan item di dalemnya jadi public, yang nge-ekspos mereka biar kode eksternal bisa pake dan bergantung pada mereka.
Sebagai contoh, yuk kita tulis sebuah library crate yang nyediain fungsionalitas dari sebuah restoran. Kita bakal mendefinisikan signature dari fungsi-fungsinya tapi ngebiarin body-nya kosong buat fokus ke organisasi kodenya bukannya implementasi dari restorannya.
Di industri restoran, beberapa bagian dari restoran disebut front of house (bagian depan) dan yang lainnya back of house (bagian dapur). Front of house itu tempat para pelanggan berada; ini nyakup tempat para host ngarahin pelanggan ke tempat duduk, pelayan nerima pesanan dan pembayaran, dan bartender bikin minuman. Back of house itu tempat para koki dan tukang masak kerja di dapur, pencuci piring bersih-bersih, dan manajer ngelakuin kerjaan administratif.
Buat menstruktur crate kita pake cara ini, kita bisa ngatur fungsi-fungsinya ke
dalem modul yang bersarang. Bikin library baru namanya restaurant dengan
jalanin cargo new restaurant --lib. Terus masukin kode di Listing 7-1 ke
src/lib.rs buat mendefinisikan beberapa modul dan signature fungsi; kode ini
adalah bagian front of house.
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
fn seat_at_table() {}
}
mod serving {
fn take_order() {}
fn serve_order() {}
fn take_payment() {}
}
}front_of_house yang nyimpen modul lain yang terus nyimpen fungsiKita mendefinisikan sebuah modul pake keyword mod diikuti sama nama modulnya
(di kasus ini, front_of_house). Body dari modulnya ditaruh di dalem kurung
kurawal. Di dalem modul, kita bisa naruh modul lain, kayak di kasus ini pake
modul hosting sama serving. Modul juga bisa nampung definisi buat item lain,
kayak struct, enum, konstanta, trait, dan kayak di Listing 7-1, fungsi.
Dengan pake modul, kita bisa ngelempokin definisi yang terkait dan ngasih nama kenapa mereka terkait. Programmer yang pake kode ini bisa navigasi kodenya berdasarkan kelompok-kelompoknya bukannya harus baca semua definisinya satu-satu, bikin lebih gampang buat nemuin definisi yang relevan buat mereka. Programmer yang nambahin fungsionalitas baru ke kode ini bakal tau ke mana harus naruh kodenya biar programnya tetep teratur.
Tadi, kita sempet nyebut kalau src/main.rs sama src/lib.rs itu disebut
crate roots. Alasan dinamain gitu karena isi dari salah satu dari dua file
ini ngebentuk modul namanya crate di root dari struktur modul crate itu,
yang dikenal sebagai module tree (pohon modul).
Listing 7-2 nunjukin pohon modul buat struktur di Listing 7-1.
crate
└── front_of_house
├── hosting
│ ├── add_to_waitlist
│ └── seat_at_table
└── serving
├── take_order
├── serve_order
└── take_payment
Pohon ini nunjukin gimana beberapa modul bersarang di dalem modul lain;
misalnya, hosting bersarang di dalem front_of_house. Pohonnya juga nunjukin
kalau beberapa modul itu saling sodaraan (siblings), artinya mereka
didefinisikan di modul yang sama; hosting sama serving itu sodaraan yang
didefinisikan di dalem front_of_house. Kalau modul A ada di dalem modul B,
kita bilang kalau modul A itu anaknya (child) modul B dan modul B itu induknya
(parent) modul A. Perhatiin ya kalau seluruh pohon modul itu berakar di bawah
modul implisit yang namanya crate.
Pohon modul mungkin ngingetin kita sama pohon direktori sistem file di komputer kita; ini perbandingan yang pas sekali! Kayak direktori di sistem file, kita pake modul buat ngatur kode kita. Dan kayak file di dalem direktori, kita perlu cara buat nemuin modul kita.
Paths buat Merujuk sebuah Item di dalam Pohon Modul
Paths (Jalur) buat Ngerujuk Item di Pohon Modul
Buat ngasih tau Rust di mana harus nyari sebuah item di pohon modul, kita pake path (jalur) dengan cara yang sama kayak kita pake path pas navigasi sistem file. Buat manggil sebuah fungsi, kita harus tau path-nya.
Sebuah path bisa punya dua bentuk:
- Absolute path (path absolut) adalah path lengkap mulai dari crate root;
buat kode dari crate eksternal, absolute path dimulai pake nama crate-nya,
dan buat kode dari crate saat ini, dia dimulai pake literal
crate. - Relative path (path relatif) dimulai dari modul saat ini terus pake
self,super, atau identifier (nama) di modul saat ini.
Baik absolute maupun relative path diikuti sama satu atau lebih identifier yang
dipisahin pake titik dua ganda (::).
Balik lagi ke Listing 7-1, katakanlah kita mau manggil fungsi add_to_waitlist.
Ini sama aja kayak nanya: apa sih path dari fungsi add_to_waitlist?
Listing 7-3 isinya Listing 7-1 tapi beberapa modul sama fungsinya dihapus biar
fokus.
Kita bakal nunjukin dua cara buat manggil fungsi add_to_waitlist dari fungsi
baru, eat_at_restaurant, yang didefinisikan di crate root. Path-path ini
udah bener, tapi ada satu masalah lagi yang bakal nyegah contoh ini buat bisa
di-compile gitu aja. Kita bakal jelasin alasannya bentar lagi.
Fungsi eat_at_restaurant itu bagian dari API public dari library crate
kita, jadi kita nandain dia pake keyword pub. Di bagian “Mengekspos Paths
dengan Keyword pub”, kita bakal bahas pub lebih detail.
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}add_to_waitlist pake absolute dan relative pathsPertama kali kita manggil fungsi add_to_waitlist di eat_at_restaurant,
kita pake absolute path. Fungsi add_to_waitlist didefinisikan di crate yang
sama kayak eat_at_restaurant, yang artinya kita bisa pake keyword crate
buat mulai absolute path-nya. Terus kita masukin tiap modul secara berurutan
sampe kita nyampe ke add_to_waitlist. Bayangin aja sistem file dengan
struktur yang sama: kita bakal nentuin path
/front_of_house/hosting/add_to_waitlist buat jalanin program add_to_waitlist;
pake nama crate buat mulai dari crate root itu kayak pake / buat mulai
dari root sistem file di terminal (shell) kita.
Kedua kalinya kita manggil add_to_waitlist di eat_at_restaurant, kita
pake relative path. Path-nya dimulai dari front_of_house, nama modul yang
didefinisikan di level yang sama di pohon modul dengan eat_at_restaurant. Di
sini, kalau di sistem file, ini sama aja kayak pake path
front_of_house/hosting/add_to_waitlist. Mulai pake nama modul artinya
path-nya itu relatif.
Milih buat pake relative atau absolute path itu keputusan yang bakal kita ambil
berdasarkan project kita, dan itu tergantung apakah kita lebih sering mindahin
kode definisi item secara terpisah atau barengan sama kode yang pake item itu.
Misalnya, kalau kita mindahin modul front_of_house sama fungsi
eat_at_restaurant ke dalem modul namanya customer_experience, kita harus
update absolute path ke add_to_waitlist, tapi relative path-nya tetep bakal
valid. Sebaliknya, kalau kita mindahin fungsi eat_at_restaurant secara
terpisah ke dalem modul namanya dining, absolute path buat manggil
add_to_waitlist bakal tetep sama, tapi relative path-nya harus di-update.
Preferensi kita secara umum adalah nentuin pake absolute path karena biasanya
kita lebih sering mindahin definisi kode sama pemanggilan item secara
independen satu sama lain.
Yuk kita coba compile Listing 7-3 dan cari tau kenapa ini belum bisa di-compile! Error yang kita dapet ditunjukin di Listing 7-4.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: module `hosting` is private
--> src/lib.rs:9:28
|
9 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ --------------- function `add_to_waitlist` is not publicly re-exported
| |
| private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
error[E0603]: module `hosting` is private
--> src/lib.rs:12:21
|
12 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ --------------- function `add_to_waitlist` is not publicly re-exported
| |
| private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
Pesan error-nya bilang kalau modul hosting itu private. Dengan kata lain,
kita udah punya path yang bener buat modul hosting sama fungsi
add_to_waitlist, tapi Rust nggak ngebolehin kita pake mereka karena Rust
nggak punya akses ke bagian private-nya. Di Rust, semua item (fungsi, method,
struct, enum, modul, sama konstanta) itu private terhadap modul induknya
secara default. Kalau kita mau bikin sebuah item kayak fungsi atau struct jadi
private, kita taruh dia di dalem modul.
Item di modul induk nggak bisa pake item private di dalem anak modulnya (child modules), tapi item di anak modul bisa pake item di modul leluhurnya (ancestor modules). Ini karena anak modul ngebungkus dan nyembunyiin detail implementasinya, tapi anak modul bisa liat konteks di mana mereka didefinisikan. Lanjutin analogi kita, bayangin aturan privasi ini kayak dapur restoran (back office): apa yang terjadi di sana itu private buat pelanggan restoran, tapi manajer bisa liat dan ngelakuin apa aja di restoran yang mereka jalanin.
Rust milih buat bikin sistem modul jalan kayak gini biar nyembunyiin detail
implementasi internal jadi default. Dengan gitu, kita tau bagian kode internal
mana yang bisa kita ubah tanpa ngerusak kode eksternalnya. Tapi, Rust tetep
ngasih kita opsi buat ngekspos bagian internal dari kode anak modul ke modul
leluhurnya pake keyword pub buat bikin item jadi public.
Mengekspos Paths dengan Keyword pub
Yuk balik lagi ke error di Listing 7-4 yang ngasih tau kita kalau modul
hosting itu private. Kita mau fungsi eat_at_restaurant di modul induknya
punya akses ke fungsi add_to_waitlist di anak modulnya, jadi kita nandain
modul hosting pake keyword pub, kayak yang ditunjukin di Listing 7-5.
mod front_of_house {
pub mod hosting {
fn add_to_waitlist() {}
}
}
// -- snip --
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}hosting sebagai pub biar bisa dipake dari eat_at_restaurantSayangnya, kode di Listing 7-5 tetep ngasilin error compiler, kayak yang ditunjukin di Listing 7-6.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:10:37
|
10 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:13:30
|
13 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
Apa yang terjadi? Nambahin keyword pub di depan mod hosting bikin modul
itu jadi public. Dengan perubahan ini, kalau kita bisa akses front_of_house,
kita bisa akses hosting. Tapi isi dari hosting itu tetep private;
bikin modul jadi public nggak bikin isinya otomatis ikutan public. Keyword
pub pada sebuah modul cuma ngebolehin kode di modul leluhurnya buat ngerujuk
ke dia, bukan buat akses kode di dalemnya. Karena modul itu adalah wadah
(container), nggak banyak yang bisa kita lakuin dengan cuma bikin modulnya jadi
public; kita perlu melangkah lebih jauh terus milih buat bikin satu atau lebih
item di dalem modulnya ikutan jadi public juga.
Error di Listing 7-6 bilang kalau fungsi add_to_waitlist itu private. Aturan
privasi berlaku buat struct, enum, fungsi, dan method, dan juga modul.
Yuk kita bikin fungsi add_to_waitlist jadi public juga dengan nambahin
keyword pub sebelum definisinya, kayak di Listing 7-7.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
// -- snip --
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}pub ke mod hosting dan fn add_to_waitlist ngebolehin kita manggil fungsinya dari eat_at_restaurantSekarang kodenya bisa di-compile! Buat liat kenapa nambahin keyword pub
ngebolehin kita pake path-path ini di eat_at_restaurant sesuai sama aturan
privasi, yuk kita bahas absolute sama relative path-nya.
Di absolute path, kita mulai pake crate, yaitu akar (root) dari pohon
modul crate kita. Modul front_of_house didefinisikan di crate root. Walaupun
front_of_house itu bukan public, tapi karena fungsi eat_at_restaurant
didefinisikan di modul yang sama kayak front_of_house (artinya eat_at_restaurant
sama front_of_house itu sodaraan), kita bisa ngerujuk ke front_of_house dari
eat_at_restaurant. Terus lanjut ke modul hosting yang udah ditandain pake
pub. Kita bisa akses modul induk dari hosting, jadi kita bisa akses
hosting. Terakhir, fungsi add_to_waitlist ditandain pake pub dan kita
bisa akses modul induknya, jadi pemanggilan fungsi ini berhasil!
Di relative path, logikanya sama persis kayak absolute path kecuali buat langkah
pertama: bukannya mulai dari crate root, path-nya mulai dari front_of_house.
Modul front_of_house didefinisikan di dalem modul yang sama kayak
eat_at_restaurant, jadi relative path yang dimulai dari modul tempat
eat_at_restaurant didefinisikan itu berhasil. Terus, karena hosting sama
add_to_waitlist ditandain pake pub, sisa path-nya berhasil, dan pemanggilan
fungsi ini jadi valid!
Kalau kita berencana buat nge-share library crate kita biar project lain bisa pake kode kita, API public kita adalah kontrak kita sama user dari crate kita yang nentuin gimana mereka bisa berinteraksi sama kode kita. Ada banyak pertimbangan soal cara ngelola perubahan di API public kita buat ngebikin orang lebih gampang bergantung sama crate kita. Pertimbangan-pertimbangan ini di luar cakupan buku ini; kalau kita tertarik sama topik ini, cek The Rust API Guidelines.
Best Practices buat Packages yang Punya Binary sama Library
Kita sempet nyebut kalau sebuah package bisa punya baik crate root binary di src/main.rs maupun crate root library di src/lib.rs, dan kedua crates ini bakal punya nama yang sama secara default. Biasanya, packages dengan pola ini yang punya baik library maupun binary crate bakal punya kode di binary crate-nya secukupnya aja buat mulai executable yang manggil kode yang didefinisikan di library crate. Ini bikin project lain bisa dapet manfaat dari sebagian besar fungsionalitas yang disediain package-nya karena kode di library crate-nya bisa di-share.
Pohon modul harusnya didefinisikan di src/lib.rs. Terus, item public mana pun bisa dipake di binary crate dengan mulai path-nya pake nama package-nya. Binary crate itu jadi user dari library crate-nya sama kayak crate eksternal lainnya yang bakal pake library crate itu: dia cuma bisa pake API public-nya. Ini ngebantu kita desain API yang bagus; kita nggak cuma jadi author-nya, tapi kita juga jadi kliennya!
Di Bab 12, kita bakal nunjukin praktik organisasi ini pake program command line yang bakal isinya binary crate sekaligus library crate.
Memulai Relative Paths dengan super
Kita bisa ngebangun relative paths yang mulai dari modul induknya, bukannya
modul saat ini atau crate root, pake super di awal path-nya. Ini kayak
mulai path sistem file pake sintaks .. yang artinya naik ke direktori
induknya. Pake super ngebolehin kita ngerujuk item yang kita tau ada di
modul induknya, yang bisa ngebikin penataan ulang pohon modul jadi lebih gampang
kalau modul itu terkait erat sama induknya tapi si induk mungkin dipindah ke
tempat lain di pohon modul suatu hari nanti.
Coba liat kode di Listing 7-8 yang mensimulasikan situasi di mana seorang koki
benerin pesanan yang salah terus ngasih langsung ke pelanggannya. Fungsi
fix_incorrect_order yang didefinisikan di modul back_of_house manggil
fungsi deliver_order yang didefinisikan di modul induknya dengan nentuin
path ke deliver_order, mulai pake super.
fn deliver_order() {}
mod back_of_house {
fn fix_incorrect_order() {
cook_order();
super::deliver_order();
}
fn cook_order() {}
}superFungsi fix_incorrect_order ada di modul back_of_house, jadi kita bisa pake
super buat pindah ke modul induk dari back_of_house, yang di kasus ini
adalah crate, yaitu root-nya. Dari situ, kita nyari deliver_order dan
nemuin dia. Mantap! Kita rasa modul back_of_house sama fungsi deliver_order
kemungkinan bakal tetep punya hubungan yang sama satu sama lain dan bakal
dipindah barengan kalau kita mutusin buat ngerombak pohon modul crate kita.
Makanya, kita pake super biar lebih dikit tempat yang harus di-update nanti
kalau kode ini dipindah ke modul yang beda.
Bikin Structs dan Enums Jadi Public
Kita juga bisa pake pub buat nandain structs sama enums jadi public, tapi
ada beberapa detail tambahan buat penggunaan pub bareng structs sama enums.
Kalau kita pake pub sebelum definisi struct, kita bikin struct-nya jadi
public, tapi field-field di struct-nya bakal tetep private. Kita bisa
bikin tiap field jadi public atau nggak sesuai kasusnya masing-masing. Di
Listing 7-9, kita mendefinisikan sebuah struct public back_of_house::Breakfast
dengan field toast yang public tapi field seasonal_fruit yang private.
Ini mensimulasikan kasus di restoran di mana pelanggan bisa milih roti yang
dateng bareng makanannya, tapi koki yang mutusin buah apa yang nyertain makanannya
berdasarkan musim sama stoknya. Ketersediaan buah berubah-ubah dengan cepet,
jadi pelanggan nggak bisa milih buahnya atau bahkan tau buah apa yang bakal
mereka dapet.
mod back_of_house {
pub struct Breakfast {
pub toast: String,
seasonal_fruit: String,
}
impl Breakfast {
pub fn summer(toast: &str) -> Breakfast {
Breakfast {
toast: String::from(toast),
seasonal_fruit: String::from("peaches"),
}
}
}
}
pub fn eat_at_restaurant() {
// Order a breakfast in the summer with Rye toast.
let mut meal = back_of_house::Breakfast::summer("Rye");
// Change our mind about what bread we'd like.
meal.toast = String::from("Wheat");
println!("I'd like {} toast please", meal.toast);
// The next line won't compile if we uncomment it; we're not allowed
// to see or modify the seasonal fruit that comes with the meal.
// meal.seasonal_fruit = String::from("blueberries");
}Karena field toast di struct back_of_house::Breakfast itu public, di
eat_at_restaurant kita bisa nulis dan baca field toast pake notasi titik.
Perhatiin kalau kita nggak bisa pake field seasonal_fruit di eat_at_restaurant,
karena seasonal_fruit itu private. Coba di-uncomment baris yang ngubah nilai
field seasonal_fruit buat liat error apa yang bakal dapet!
Terus, perhatiin karena back_of_house::Breakfast punya field private, struct
ini harus nyediain fungsi associated yang public yang ngebikin (mengkonstruksi)
instance dari Breakfast (kita namain summer di sini). Kalau Breakfast nggak
punya fungsi kayak gitu, kita nggak bakal bisa bikin instance dari Breakfast
di eat_at_restaurant karena kita nggak bisa set nilai dari field
seasonal_fruit yang private di eat_at_restaurant.
Sebaliknya, kalau kita bikin sebuah enum jadi public, semua variannya ikutan
jadi public. Kita cuma perlu naruh pub sebelum keyword enum, kayak yang
ditunjukin di Listing 7-10.
mod back_of_house {
pub enum Appetizer {
Soup,
Salad,
}
}
pub fn eat_at_restaurant() {
let order1 = back_of_house::Appetizer::Soup;
let order2 = back_of_house::Appetizer::Salad;
}Karena kita bikin enum Appetizer jadi public, kita bisa pake varian Soup
sama Salad di eat_at_restaurant.
Enums nggak terlalu berguna kalau variannya nggak public; bakal nyebelin
sekali kalau harus nganotasi semua varian enum pake pub di setiap kasus, jadi
default buat varian enum adalah public. Structs biasanya berguna walaupun
field-nya nggak public, jadi field struct ngikutin aturan umum bahwa segala
hal itu private secara default kecuali dianotasi pake pub.
Ada satu lagi situasi yang ngelibatin pub yang belum kita bahas, dan itu
adalah fitur sistem modul kita yang terakhir: keyword use. Kita bakal ngebahas
use sendirian dulu, terus kita bakal nunjukin gimana cara gabungin pub sama
use.
Membawa Paths ke dalam Scope Memakai Keyword use
Bawa Paths ke Dalem Scope pake Keyword use
Harus nulis paths lengkap-lengkap buat manggil fungsi tuh rasanya kurang nyaman
dan ngulang-ngulang terus. Di Listing 7-7, entah kita milih absolute atau
relative path buat manggil fungsi add_to_waitlist, tiap kali kita mau manggil
add_to_waitlist kita harus nulis front_of_house sama hosting juga.
Untungnya, ada cara buat nyederhanain proses ini: kita bisa bikin shortcut
(jalan pintas) ke sebuah path pake keyword use sekali aja, dan terus pake
nama yang lebih pendek itu di mana-mana di dalem scope-nya.
Di Listing 7-11, kita bawa modul crate::front_of_house::hosting ke dalem scope
dari fungsi eat_at_restaurant biar kita cuma perlu nentuin
hosting::add_to_waitlist buat manggil fungsi add_to_waitlist di
eat_at_restaurant.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}useNambahin use sama sebuah path di dalem sebuah scope itu mirip kayak bikin
symbolic link di sistem file. Dengan nambahin
use crate::front_of_house::hosting di crate root, hosting sekarang jadi
nama yang valid di scope itu, seolah-olah modul hosting itu didefinisikan di
crate root. Path yang dibawa ke scope pake use juga bakal nge-cek privasi,
sama kayak path lainnya.
Perhatiin ya kalau use cuma bikin shortcut buat scope tertentu di mana use
itu dipanggil. Listing 7-12 mindahin fungsi eat_at_restaurant ke dalem anak
modul baru namanya customer, yang mana itu beda scope dari statement use-nya,
jadi body fungsinya nggak bakal bisa di-compile.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
mod customer {
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}
}use cuma berlaku di scope tempat dia ditaruh.Error compiler nunjukin kalau shortcut-nya udah nggak berlaku lagi di dalem
modul customer:
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0433]: failed to resolve: use of unresolved module or unlinked crate `hosting`
--> src/lib.rs:11:9
|
11 | hosting::add_to_waitlist();
| ^^^^^^^ use of unresolved module or unlinked crate `hosting`
|
= help: if you wanted to use a crate named `hosting`, use `cargo add hosting` to add it to your `Cargo.toml`
help: consider importing this module through its public re-export
|
10 + use crate::hosting;
|
warning: unused import: `crate::front_of_house::hosting`
--> src/lib.rs:7:5
|
7 | use crate::front_of_house::hosting;
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
For more information about this error, try `rustc --explain E0433`.
warning: `restaurant` (lib) generated 1 warning
error: could not compile `restaurant` (lib) due to 1 previous error; 1 warning emitted
Perhatiin ada warning juga yang bilang kalau use-nya nggak dipake di scope-nya!
Buat benerin masalah ini, pindahin use-nya ke dalem modul customer juga,
atau rujuk shortcut yang ada di modul induk pake super::hosting dari dalem
anak modul customer.
Bikin Paths use yang Idiomatik
Di Listing 7-11, kita mungkin mikir kenapa kita nulis
use crate::front_of_house::hosting terus manggil hosting::add_to_waitlist di
eat_at_restaurant, bukannya nulis path use sampe ke fungsi add_to_waitlist
buat dapet hasil yang sama, kayak di Listing 7-13.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting::add_to_waitlist;
pub fn eat_at_restaurant() {
add_to_waitlist();
}add_to_waitlist ke dalem scope pake use, yang nggak idiomatikWalaupun Listing 7-11 sama Listing 7-13 ngelakuin tugas yang sama, Listing 7-11
adalah cara yang idiomatik buat bawa sebuah fungsi ke dalem scope pake use.
Bawa modul induk dari sebuah fungsi ke dalem scope pake use artinya kita
harus nyebutin modul induknya pas manggil fungsi itu. Nyebutin modul induk pas
manggil fungsi bikin jelas kalau fungsi itu nggak didefinisikan secara lokal,
tapi tetep minimalisir pengulangan nulis absolute path-nya. Kode di Listing 7-13
bikin nggak jelas di mana add_to_waitlist itu sebenernya didefinisikan.
Sebaliknya, pas kita bawa structs, enums, dan item lain pake use, itu
idiomatik buat nyebutin full path-nya. Listing 7-14 nunjukin cara idiomatik
buat bawa struct HashMap dari standard library ke dalem scope dari sebuah
binary crate.
use std::collections::HashMap;
fn main() {
let mut map = HashMap::new();
map.insert(1, 2);
}HashMap ke dalem scope pake cara yang idiomatikNggak ada alesan kuat sih di balik idiom ini: ini cuma konvensi yang udah muncul, dan orang-orang udah kebiasa baca sama nulis kode Rust dengan cara kayak gini.
Pengecualian buat idiom ini adalah kalau kita bawa dua item yang namanya sama ke
dalem scope pake statement use, karena Rust nggak ngebolehin itu. Listing 7-15
nunjukin gimana cara bawa dua tipe Result yang namanya sama tapi modul induknya
beda ke dalem scope, dan gimana cara merujuk ke mereka.
use std::fmt;
use std::io;
fn function1() -> fmt::Result {
// --snip--
Ok(())
}
fn function2() -> io::Result<()> {
// --snip--
Ok(())
}Kayak yang bisa kita liat, pake modul induk bisa ngebedain kedua tipe Result
ini. Kalau kita malah nulis use std::fmt::Result sama use std::io::Result,
kita bakal punya dua tipe Result di scope yang sama, dan Rust nggak bakal tau
mana yang kita maksud pas kita pake nama Result.
Ngasih Nama Baru pake Keyword as
Ada solusi lain buat masalah bawa dua tipe dengan nama yang sama ke dalem scope
yang sama pake use: setelah path, kita bisa nambahin as sama nama lokal baru,
atau alias, buat tipe itu. Listing 7-16 nunjukin cara lain buat nulis kode
di Listing 7-15 dengan nge-rename salah satu dari tipe Result itu pake as.
use std::fmt::Result;
use std::io::Result as IoResult;
fn function1() -> Result {
// --snip--
Ok(())
}
fn function2() -> IoResult<()> {
// --snip--
Ok(())
}asDi statement use yang kedua, kita milih nama baru IoResult buat tipe
std::io::Result, yang nggak bakal bentrok sama Result dari std::fmt yang
juga udah kita bawa ke dalem scope. Listing 7-15 sama Listing 7-16 sama-sama
dianggap idiomatik, jadi milih yang mana itu terserah kita!
Re-exporting Nama pake pub use
Pas kita bawa sebuah nama ke dalem scope pake keyword use, nama itu private
buat scope tempat kita nge-import dia. Buat ngebolehin kode di luar scope itu
buat ngerujuk ke nama itu seolah-olah nama itu didefinisikan di scope tersebut,
kita bisa gabungin pub sama use. Teknik ini namanya re-exporting karena
kita bawa item ke dalem scope tapi juga nge-ekspos item itu biar orang lain
bisa bawa item itu ke scope mereka.
Listing 7-17 nunjukin kode di Listing 7-11 dengan use di modul root diganti
jadi pub use.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}pub useSebelum perubahan ini, kode eksternal harus manggil fungsi add_to_waitlist
pake path restaurant::front_of_house::hosting::add_to_waitlist(), yang juga
bakal mewajibkan modul front_of_house buat ditandain sebagai pub. Sekarang,
karena pub use ini udah nge-re-export modul hosting dari modul root,
kode eksternal bisa pake path restaurant::hosting::add_to_waitlist() sebagai
gantinya.
Re-exporting berguna pas struktur internal kode kita itu beda dari gimana
programmer yang manggil kode kita bakal mikirin soal domain-nya. Misalnya, di
analogi restoran ini, orang yang jalanin restorannya mikirnya “front of house”
sama “back of house.” Tapi pelanggan yang dateng ke restoran mungkin nggak bakal
mikirin bagian-bagian restoran pake istilah-istilah itu. Pake pub use, kita
bisa nulis kode kita pake satu struktur tapi nge-ekspos struktur yang beda.
Ngelakuin ini bikin library kita terorganisir dengan baik buat programmer yang
ngerjain library-nya dan juga buat programmer yang manggil library-nya. Kita
bakal liat contoh lain dari pub use dan gimana pengaruhnya ke dokumentasi crate
kita di “Ngekspor API Public yang Nyaman pake pub use” di Bab 14.
Pake Package Eksternal
Di Bab 2, kita bikin project game tebak angka yang pake package eksternal
namanya rand buat dapet angka random. Buat pake rand di project kita, kita
nambahin baris ini ke Cargo.toml:
rand = "0.8.5"
Nambahin rand sebagai dependency (dependensi) di Cargo.toml ngasih tau
Cargo buat download package rand sama dependensinya dari crates.io
terus nyediain rand buat project kita.
Terus, buat bawa definisi rand ke dalem scope package kita, kita nambahin
baris use yang dimulai dari nama crate-nya, rand, dan nge-list item-item
yang mau kita bawa ke dalem scope. Inget kan di “Menghasilkan Angka Random”
di Bab 2, kita bawa trait Rng ke dalem scope terus manggil fungsi
rand::thread_rng:
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Anggota komunitas Rust udah bikin sangat banyak package yang tersedia di
crates.io, dan masukin salah satu dari mereka ke package
kita itu ngelibatin langkah-langkah yang sama: daftarin mereka di file
Cargo.toml package kita terus pake use buat bawa item dari crate mereka ke
dalem scope.
Perhatiin ya kalau standard library std itu juga sebuah crate yang eksternal
buat package kita. Karena standard library udah dipaket bareng bahasa Rust, kita
nggak perlu ngubah Cargo.toml buat masukin std. Tapi kita tetep perlu
ngerujuk ke dia pake use buat bawa item-item dari sana ke dalem scope package
kita. Misalnya, buat HashMap kita bakal pake baris ini:
#![allow(unused)]
fn main() {
use std::collections::HashMap;
}Ini adalah absolute path yang dimulai dari std, nama dari crate standard
library.
Pake Nested Paths Buat Ngerapihin Daftar use yang Panjang
Kalau kita pake banyak item yang didefinisikan di crate yang sama atau modul
yang sama, nulisin tiap item di barisnya sendiri-sendiri bakal menuhin tempat
secara vertikal di file kita. Misalnya, dua statement use ini yang kita pake
di game tebak angka di Listing 2-4 bawa item-item dari std ke dalem scope:
use rand::Rng;
// --snip--
use std::cmp::Ordering;
use std::io;
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}Sebagai gantinya, kita bisa pake nested paths (path bersarang) buat bawa item-
item yang sama ke dalem scope dalam satu baris. Kita lakuin ini dengan nulisin
bagian yang sama dari path-nya, diikuti sama dua titik dua (::), terus kurung
kurawal di sekitar list dari bagian-bagian path yang beda, kayak yang ditunjukin
di Listing 7-18.
use rand::Rng;
// --snip--
use std::{cmp::Ordering, io};
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}Di program yang lebih gede, bawa banyak item ke dalem scope dari crate atau modul
yang sama pake nested paths bisa ngurangin sekali jumlah statement use
terpisah yang dibutuhin!
Kita bisa pake nested path di level mana pun di dalem sebuah path, yang berguna
sekali pas ngegabungin dua statement use yang nge-share subpath. Misalnya,
Listing 7-19 nunjukin dua statement use: satu yang bawa std::io ke dalem
scope dan satu lagi yang bawa std::io::Write ke dalem scope.
use std::io;
use std::io::Write;use di mana salah satunya adalah subpath dari yang lainBagian yang sama dari kedua path ini adalah std::io, dan itu adalah path
lengkap pertama. Buat ngegabungin dua path ini jadi satu statement use, kita
bisa pake self di dalem nested path, kayak yang ditunjukin di Listing 7-20.
use std::io::{self, Write};useBaris ini bawa std::io sama std::io::Write ke dalem scope.
Operator Glob
Kalau kita mau bawa semua item public yang didefinisikan di sebuah path ke
dalem scope, kita bisa nulis path itu diikuti sama operator glob *:
#![allow(unused)]
fn main() {
use std::collections::*;
}Statement use ini bawa semua item public yang didefinisikan di
std::collections ke dalem scope saat ini. Hati-hati ya pas pake operator
glob! Glob bisa bikin kita lebih susah buat tau nama apa aja yang ada di dalem
scope dan di mana nama yang dipake di program kita itu didefinisikan. Selain itu,
kalau dependensinya ngerubah definisi mereka, apa yang kita import juga ikut
berubah, yang bisa memicu error compiler pas kita upgrade dependensi kalau
dependensinya nambahin definisi dengan nama yang sama kayak definisi punya kita
di scope yang sama, misalnya.
Operator glob sering sekali dipake pas lagi testing buat bawa semua hal yang
mau di-test ke dalem modul tests; kita bakal bahas itu di “Gimana Cara Nulis
Test” di Bab 11. Operator glob juga kadang dipake sebagai bagian
dari pola prelude: liat dokumentasi standard library
buat info lebih lanjut soal pola itu.
Memisahkan Modul ke dalam File Berbeda
Misahin Modul ke Dalem File yang Beda
Sejauh ini, semua contoh di bab ini mendefinisikan beberapa modul di dalem satu file. Pas modulnya jadi makin gede, kita mungkin mau mindahin definisi mereka ke file terpisah biar kodenya lebih gampang dinavigasi.
Sebagai contoh, yuk kita mulai dari kode di Listing 7-17 yang punya beberapa modul restoran. Kita bakal ngekstrak modul-modulnya ke dalem file bukannya punya semua modul didefinisikan di file crate root. Di kasus ini, file crate root-nya adalah src/lib.rs, tapi prosedur ini juga berlaku buat binary crates yang mana file crate root-nya adalah src/main.rs.
Pertama kita bakal ngekstrak modul front_of_house ke dalem filenya sendiri.
Hapus kode di dalem kurung kurawal buat modul front_of_house, nyisain cuma
deklarasi mod front_of_house; aja, jadi src/lib.rs isinya cuma kode yang
ditunjukin di Listing 7-21. Perhatiin ya kalau ini nggak bakal bisa di-compile
sampe kita bikin file src/front_of_house.rs di Listing 7-22.
mod front_of_house;
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}front_of_house yang body-nya bakal ada di src/front_of_house.rsSelanjutnya, taruh kode yang tadinya ada di dalem kurung kurawal ke file baru
namanya src/front_of_house.rs, kayak yang ditunjukin di Listing 7-22.
Compiler tau buat nyari di file ini karena dia nemu deklarasi modul di
crate root dengan nama front_of_house.
pub mod hosting {
pub fn add_to_waitlist() {}
}front_of_house di src/front_of_house.rsPerhatiin ya kalau kita cuma perlu load (muat) file pake deklarasi mod
sekali aja di pohon modul kita. Begitu compiler tau filenya adalah bagian
dari project (dan tau di mana letak kode itu di pohon modul gara-gara tempat
kita naruh statement mod), file lain di project kita harus ngerujuk ke kode
di file yang di-load pake path ke tempat di mana dia dideklarasikan, kayak
yang udah dibahas di bagian “Paths (Jalur) buat Ngerujuk Item di Pohon Modul”.
Dengan kata lain, mod itu bukan operasi “include” kayak yang mungkin kita
liat di bahasa pemrograman lainnya.
Selanjutnya, kita bakal ngekstrak modul hosting ke dalem filenya sendiri.
Prosesnya agak beda karena hosting adalah anak modul dari front_of_house,
bukan dari modul root. Kita bakal naruh file buat hosting di direktori
baru yang namanya ngikutin leluhurnya di pohon modul, di kasus ini
src/front_of_house.
Buat mulai mindahin hosting, kita ubah src/front_of_house.rs biar isinya
cuma deklarasi dari modul hosting aja:
pub mod hosting;Terus kita bikin direktori src/front_of_house sama file hosting.rs buat
nampung definisi yang dibikin di modul hosting:
pub fn add_to_waitlist() {}Kalau kita malah naruh hosting.rs di direktori src, compiler bakal ngarepin
kode hosting.rs ada di modul hosting yang dideklarasikan di crate root,
dan bukan dideklarasikan sebagai anak dari modul front_of_house. Aturan
compiler soal file mana yang harus dicek buat kode modul mana bikin direktori
dan file jadi lebih mirip (match) sama pohon modulnya.
Alternate File Paths (Path File Alternatif)
Sejauh ini kita udah ngebahas path file yang paling idiomatik yang dipake sama
compiler Rust, tapi Rust juga support gaya path file yang lebih lama. Buat
modul namanya front_of_house yang dideklarasikan di crate root, compiler
bakal nyari kode modulnya di:
- src/front_of_house.rs (yang baru aja kita bahas)
- src/front_of_house/mod.rs (gaya lama, tetep di-support path-nya)
Buat modul namanya hosting yang merupakan submodul dari front_of_house,
compiler bakal nyari kode modulnya di:
- src/front_of_house/hosting.rs (yang baru aja kita bahas)
- src/front_of_house/hosting/mod.rs (gaya lama, tetep di-support path-nya)
Kalau kita pake kedua gaya ini buat modul yang sama, kita bakal dapet error compiler. Pake campuran kedua gaya buat modul yang beda di project yang sama itu dibolehin, tapi mungkin bakal ngebingungin orang yang lagi navigasi project kita.
Kekurangan utama dari gaya yang pake file namanya mod.rs adalah project kita bisa berakhir dengan banyak file yang namanya mod.rs, yang bisa ngebingungin pas kita ngebuka mereka semua di editor secara bersamaan.
Kita udah mindahin kode tiap modul ke file yang terpisah, dan pohon modulnya
tetep sama. Pemanggilan fungsi di eat_at_restaurant bakal jalan tanpa
modifikasi apa pun, walaupun definisinya sekarang tinggal di file yang beda.
Teknik ini ngebolehin kita mindahin modul ke file baru seiring ukurannya makin
gede.
Perhatiin ya kalau statement pub use crate::front_of_house::hosting di
src/lib.rs juga nggak berubah, dan use juga nggak punya pengaruh apa pun
ke file mana yang di-compile sebagai bagian dari crate-nya. Keyword mod
mendeklarasikan modul, dan Rust nyari di file dengan nama yang sama kayak
modulnya buat nyari kode yang masuk ke modul itu.
Ringkasan
Rust ngebolehin kita misahin sebuah package jadi beberapa crates dan sebuah
crate jadi beberapa modul biar kita bisa ngerujuk ke item yang didefinisikan
di satu modul dari modul lain. Kita bisa lakuin ini dengan nentuin absolute
atau relative paths. Path-path ini bisa dibawa ke dalem scope pake statement
use biar kita bisa pake path yang lebih pendek buat banyak pemakaian item itu
di scope tersebut. Kode modul itu private secara default, tapi kita bisa
bikin definisinya jadi public dengan nambahin keyword pub.
Di bab berikutnya, kita bakal liat beberapa struktur data koleksi (collection) di standard library yang bisa kita pake di dalem kode kita yang udah terorganisir dengan rapi.
Koleksi Umum (Common Collections)
Standard library Rust nyediain sejumlah struktur data yang sangat berguna yang disebut collections (koleksi). Kebanyakan tipe data lain merepresentasikan satu nilai spesifik, tapi koleksi bisa nampung banyak nilai. Beda sama tipe array sama tuple bawaan, data yang ditunjuk sama koleksi ini disimpan di heap, yang artinya jumlah datanya nggak perlu diketahuin pas compile time dan bisa nambah atau berkurang seiring programnya jalan. Tiap jenis koleksi punya kemampuan dan biaya (cost) yang beda-beda, dan milih yang paling pas buat situasi kita saat itu adalah skill yang bakal kita kembangin seiring berjalannya waktu. Di bab ini, kita bakal ngebahas tiga koleksi yang sering sekali dipake di program Rust:
- Sebuah vector ngebolehin kita nyimpen sejumlah nilai yang jumlahnya bisa berubah-ubah dan posisinya bersebelahan satu sama lain.
- Sebuah string adalah koleksi dari karakter-karakter. Kita udah sempet nyebut
tipe
Stringsebelumnya, tapi di bab ini kita bakal bahas lebih mendalam. - Sebuah hash map ngebolehin kita buat ngaitin (associate) sebuah nilai sama sebuah key tertentu. Ini adalah implementasi spesifik dari struktur data yang lebih umum yang disebut map.
Buat belajar soal jenis koleksi lain yang disediain sama standard library, cek dokumentasinya.
Kita bakal bahas gimana cara bikin dan ngubah vectors, strings, dan hash maps, serta apa yang bikin masing-masing dari mereka itu spesial.
Menyimpan Daftar Nilai Memakai Vectors
Nyimpen Daftar Nilai pake Vectors
Tipe koleksi pertama yang bakal kita liat adalah Vec<T>, yang juga dikenal
sebagai vector. Vectors ngebolehin kita nyimpen lebih dari satu nilai di dalem
satu struktur data tunggal yang naruh semua nilai itu bersebelahan di memori.
Vectors cuma bisa nyimpen nilai dengan tipe yang sama. Mereka berguna pas kita
punya daftar (list) item, kayak baris-baris teks di sebuah file atau harga-harga
barang di keranjang belanja.
Bikin Vector Baru
Buat bikin vector baru yang kosong, kita manggil fungsi Vec::new, kayak yang
ditunjukin di Listing 8-1.
fn main() {
let v: Vec<i32> = Vec::new();
}i32Perhatiin ya kalau kita nambahin anotasi tipe di sini. Karena kita nggak masukin
nilai apa pun ke vector ini, Rust nggak tau jenis elemen apa yang mau kita simpen.
Ini poin penting. Vectors diimplementasikan pake generik (generics); kita bakal
bahas cara pake generik bareng tipe kita sendiri di Bab 10. Buat sekarang, tau
aja kalau tipe Vec<T> yang disediain sama standard library bisa nampung tipe
apa pun. Pas kita bikin vector buat nampung tipe spesifik, kita bisa nentuin
tipenya di dalem kurung siku. Di Listing 8-1, kita ngasih tau Rust kalau
Vec<T> di variabel v bakal nampung elemen dengan tipe i32.
Biasanya, kita bakal bikin Vec<T> dengan nilai awal dan Rust bakal nebak (infer)
tipe nilai yang mau kita simpen, jadi kita jarang sekali butuh anotasi tipe
kayak gini. Rust nyediain macro yang praktis sekali, vec!, yang bakal bikin
vector baru yang isinya nilai-nilai yang kita kasih. Listing 8-2 bikin
Vec<i32> baru yang isinya nilai 1, 2, dan 3. Tipe integer-nya adalah
i32 karena itu adalah tipe integer default, kayak yang kita bahas di bagian
“Tipe Data” di Bab 3.
fn main() {
let v = vec![1, 2, 3];
}Karena kita udah ngasih nilai awal i32, Rust bisa nebak kalau tipe dari v
adalah Vec<i32>, dan anotasi tipenya nggak dibutuhin. Selanjutnya, kita bakal
liat cara ngubah sebuah vector.
Ngubah Vector
Buat bikin vector terus nambahin elemen ke dalemnya, kita bisa pake method
push, kayak yang ditunjukin di Listing 8-3.
fn main() {
let mut v = Vec::new();
v.push(5);
v.push(6);
v.push(7);
v.push(8);
}push buat nambahin nilai ke vectorSama kayak variabel mana pun, kalau kita mau bisa ngubah nilainya, kita harus
bikin variabelnya mutable pake keyword mut, kayak yang dibahas di Bab 3.
Angka-angka yang kita taruh di dalemnya semuanya bertipe i32, dan Rust nebak
ini dari datanya, jadi kita nggak perlu anotasi Vec<i32>.
Ngebaca Elemen dari Vectors
Ada dua cara buat ngerujuk ke nilai yang disimpan di sebuah vector: lewat
indexing atau pake method get. Di contoh-contoh berikut, kita udah
nganotasi tipe dari nilai yang dibalikin sama fungsi-fungsi ini biar lebih jelas.
Listing 8-4 nunjukin kedua cara buat akses nilai di dalem vector, pake sintaks
indexing dan method get.
fn main() {
let v = vec![1, 2, 3, 4, 5];
let third: &i32 = &v[2];
println!("The third element is {third}");
let third: Option<&i32> = v.get(2);
match third {
Some(third) => println!("The third element is {third}"),
None => println!("There is no third element."),
}
}get buat akses item di vectorAda beberapa detail yang perlu diperhatiin di sini. Kita pake nilai indeks 2
buat dapet elemen ketiga karena vectors diindeks pake angka, mulai dari nol.
Pake & sama [] ngasih kita sebuah referensi ke elemen di nilai indeks
tersebut. Pas kita pake method get dengan indeks yang dimasukin sebagai argumen,
kita dapet Option<&T> yang bisa kita pake bareng match.
Rust nyediain dua cara buat ngerujuk elemen biar kita bisa milih gimana program kita bereaksi pas kita nyoba pake nilai indeks yang di luar rentang (range) elemen yang ada. Sebagai contoh, yuk kita liat apa yang terjadi pas kita punya vector isinya lima elemen terus kita nyoba akses elemen di indeks 100 pake kedua teknik ini, kayak yang ditunjukin di Listing 8-5.
fn main() {
let v = vec![1, 2, 3, 4, 5];
let does_not_exist = &v[100];
let does_not_exist = v.get(100);
}Pas kita jalanin kode ini, metode pertama [] bakal bikin program panic
karena dia ngerujuk ke elemen yang nggak ada. Metode ini paling pas dipake
kalau kita mau program kita nge-crash kalau ada percobaan buat akses elemen
ngelewatin akhir vector.
Pas method get dikasih indeks yang di luar vector, dia bakal balikin None
tanpa bikin panic. Kita bakal pake metode ini kalau akses elemen di luar
rentang vector mungkin sesekali kejadian di bawah kondisi normal. Kode kita
terus bakal punya logika buat nanganin dapet Some(&element) atau None,
kayak yang dibahas di Bab 6. Misalnya, indeksnya bisa jadi dateng dari orang
yang masukin angka. Kalau mereka nggak sengaja masukin angka yang kegedean dan
programnya dapet nilai None, kita bisa ngasih tau user berapa banyak item
yang ada di vector saat ini dan ngasih mereka kesempatan lagi buat masukin
nilai yang valid. Itu bakal lebih user-friendly daripada nge-crash-in
program gara-gara typo!
Pas programnya punya referensi yang valid, borrow checker bakal nerapin aturan ownership dan borrowing (yang dibahas di Bab 4) buat mastiin referensi ini dan referensi apa pun lainnya ke isi vector tetep valid. Inget aturan yang bilang kalau kita nggak bisa punya referensi mutable sama immutable di scope yang sama. Aturan itu berlaku di Listing 8-6, di mana kita megang immutable reference ke elemen pertama di vector terus nyoba nambahin elemen di akhir vector. Program ini nggak bakal jalan kalau kita juga nyoba ngerujuk ke elemen itu nanti di fungsinya.
fn main() {
let mut v = vec![1, 2, 3, 4, 5];
let first = &v[0];
v.push(6);
println!("The first element is: {first}");
}Compile kode ini bakal ngasilin error ini:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable
--> src/main.rs:6:5
|
4 | let first = &v[0];
| - immutable borrow occurs here
5 |
6 | v.push(6);
| ^^^^^^^^^ mutable borrow occurs here
7 |
8 | println!("The first element is: {first}");
| ----- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `collections` (bin "collections") due to 1 previous error
Kode di Listing 8-6 mungkin keliatannya harusnya jalan: kenapa referensi ke elemen pertama harus peduli sama perubahan di akhir vector? Error ini terjadi karena cara kerja vectors: karena vectors naruh nilai bersebelahan satu sama lain di memori, nambahin elemen baru di akhir vector mungkin butuh ngalokasiin memori baru dan ngopi elemen-elemen lama ke ruang yang baru, kalau ternyata nggak ada ruang yang cukup buat naruh semua elemen bersebelahan di tempat vector itu saat ini disimpan. Di kasus itu, referensi ke elemen pertama bakal nunjuk ke memori yang udah di-dealokasi (deallocated memory). Aturan borrowing nyegah program berakhir di situasi kayak gitu.
Catatan: Buat detail implementasi lebih lanjut dari tipe
Vec<T>, liat “The Rustonomicon”.
Iterasi Lewat Nilai-nilai di dalem Vector
Buat akses tiap elemen di vector secara bergiliran, kita bakal iterasi lewat
semua elemennya bukannya pake indeks buat akses satu-satu. Listing 8-7 nunjukin
cara pake for loop buat dapet immutable references ke tiap elemen di vector
nilai i32 terus nyetak semuanya.
fn main() {
let v = vec![100, 32, 57];
for i in &v {
println!("{i}");
}
}for loopKita juga bisa iterasi lewat mutable references ke tiap elemen di mutable
vector buat bikin perubahan ke semua elemen. for loop di Listing 8-8 bakal
nambahin 50 ke tiap elemen.
fn main() {
let mut v = vec![100, 32, 57];
for i in &mut v {
*i += 50;
}
}Buat ngubah nilai yang ditunjuk sama mutable reference, kita harus pake
operator dereference * buat nyampe ke nilai di i sebelum kita bisa pake
operator +=. Kita bakal bahas operator dereference lebih dalem di bagian
“Ngikutin Pointer ke Nilai pake Operator Dereference” di Bab 15.
Iterasi lewat sebuah vector, entah itu secara immutable atau mutable,
selalu aman berkat aturan borrow checker. Kalau kita nyoba insert atau
remove item di body for loop di Listing 8-7 sama Listing 8-8, kita bakal
dapet error compiler yang mirip kayak yang kita dapet dari kode di Listing 8-6.
Referensi ke vector yang dipegang sama for loop nyegah modifikasi
keseluruhan vector di waktu yang sama.
Pake Enum Buat Nyimpen Banyak Tipe
Vectors cuma bisa nyimpen nilai yang tipenya sama. Ini bisa jadi kurang nyaman; pasti ada kasus di mana kita butuh nyimpen daftar item yang tipenya beda-beda. Untungnya, varian dari sebuah enum didefinisikan di bawah tipe enum yang sama, jadi pas kita butuh satu tipe buat ngewakilin elemen dari berbagai tipe, kita bisa bikin dan pake enum!
Misalnya, katakanlah kita mau dapet nilai dari sebuah baris di spreadsheet di mana beberapa kolom di baris itu isinya integer, beberapa angka floating-point, dan beberapa lagi strings. Kita bisa mendefinisikan enum yang varian-variannya bakal nampung tipe nilai yang beda, dan semua varian enum itu bakal dianggap sebagai tipe yang sama: yaitu tipe dari enum tersebut. Terus kita bisa bikin vector buat nampung enum itu dan akhirnya bisa nampung tipe yang beda-beda. Kita udah demonstrasikan ini di Listing 8-9.
fn main() {
enum SpreadsheetCell {
Int(i32),
Float(f64),
Text(String),
}
let row = vec![
SpreadsheetCell::Int(3),
SpreadsheetCell::Text(String::from("blue")),
SpreadsheetCell::Float(10.12),
];
}enum buat nyimpen nilai dari tipe yang beda di dalem satu vectorRust perlu tau tipe apa aja yang bakal ada di vector pas compile time biar dia
tau persis berapa banyak memori di heap yang bakal dibutuhin buat nyimpen
tiap elemen. Kita juga harus eksplisit soal tipe apa aja yang dibolehin di
vector ini. Kalau Rust ngebolehin sebuah vector buat nampung tipe apa aja, ada
kemungkinan satu atau lebih dari tipe itu bakal nyebabin error sama operasi yang
dijalanin pada elemen vector-nya. Pake enum ditambah ekspresi match artinya
Rust bakal mastiin pas compile time kalau setiap kasus yang mungkin terjadi
itu di-handle, kayak yang dibahas di Bab 6.
Kalau kita nggak tau daftar lengkap dari tipe-tipe yang bakal didapet program pas runtime buat disimpan di vector, teknik enum ini nggak bakal jalan. Sebagai gantinya, kita bisa pake trait object, yang bakal kita bahas di Bab 18.
Sekarang setelah kita bahas beberapa cara paling umum buat pake vectors, pastiin
buat cek dokumentasi API-nya buat semua method berguna yang
didefinisikan pada Vec<T> sama standard library. Misalnya, selain push, ada
method pop yang ngehapus dan balikin elemen terakhir.
Nge-drop Vector Bakal Nge-drop Elemennya Juga
Kayak struct lainnya, sebuah vector bakal dibebasin (freed) pas dia keluar
dari scope, kayak yang dianotasi di Listing 8-10.
fn main() {
{
let v = vec![1, 2, 3, 4];
// do stuff with v
} // <- v goes out of scope and is freed here
}Pas vector di-drop, semua isinya juga ikut di-drop, artinya integer-integer yang ada di dalemnya bakal dibersihin. Borrow checker mastiin kalau referensi apa pun ke isi dari vector cuma dipake selama vector itu sendiri masih valid.
Yuk kita lanjut ke tipe koleksi berikutnya: String!
Menyimpan Teks Terenkod UTF-8 Memakai Strings
Nyimpen Teks Berkode UTF-8 pake Strings
Kita udah pernah ngebahas strings di Bab 4, tapi sekarang kita bakal bahas lebih mendalam. Rustaceans (programmer Rust) baru biasanya sering mentok di strings karena kombinasi tiga alasan: kecenderungan Rust buat nge-ekspos kemungkinan error, strings yang ternyata adalah struktur data yang lebih ribet daripada yang dikira banyak programmer, dan UTF-8. Faktor-faktor ini kegabung dengan cara yang mungkin kerasa susah kalau kita asalnya dari bahasa pemrograman lain.
Kita ngebahas strings di dalem konteks koleksi (collections) karena strings
diimplementasikan sebagai koleksi dari byte-byte, ditambah beberapa method buat
nyediain fungsionalitas yang berguna pas byte-byte itu diterjemahin (interpreted)
sebagai teks. Di bagian ini, kita bakal bahas operasi-operasi pada String
yang dipunyai sama setiap tipe koleksi, kayak bikin (creating), ngubah (updating),
sama ngebaca (reading). Kita juga bakal bahas gimana String itu beda dari
koleksi lainnya, yaitu gimana proses indexing ke dalem String itu dibikin
ribet karena perbedaan antara gimana manusia sama komputer nerjemahin data
String.
Apa Itu String?
Pertama-tama kita bakal nentuin apa yang kita maksud dengan istilah string.
Rust cuma punya satu tipe string di dalem bahasa intinya (core language),
yaitu string slice str yang biasanya keliatan dalam bentuk referensi &str.
Di Bab 4, kita udah ngebahas soal string slices, yang merupakan referensi ke
sejumlah data string berkode UTF-8 yang disimpan di tempat lain. Literal
string, misalnya, disimpan di dalem binary program kita dan makanya mereka
itu adalah string slices.
Tipe String, yang disediain sama standard library Rust bukannya dikodein
langsung ke bahasa intinya, adalah tipe string berkode UTF-8 yang bisa nambah
ukurannya (growable), mutable, dan dimiliki (owned). Pas Rustaceans nyebut
“strings” di Rust, mereka mungkin maksudnya tipe String atau tipe string
slice &str, bukan cuma salah satunya doang. Walaupun bagian ini sebagian
besar bahas soal String, kedua tipe ini sering sekali dipake di standard
library Rust, dan baik String maupun string slices itu sama-sama berkode
UTF-8.
Bikin String Baru
Banyak operasi yang sama yang tersedia buat Vec<T> itu tersedia buat String
juga karena String sebenernya diimplementasikan sebagai bungkus (wrapper) dari
sebuah vector berisi byte-byte dengan beberapa jaminan (guarantees), batasan,
dan kemampuan tambahan. Salah satu contoh fungsi yang cara kerjanya sama buat
Vec<T> sama String adalah fungsi new buat bikin instance baru, kayak yang
ditunjukin di Listing 8-11.
fn main() {
let mut s = String::new();
}String baru yang kosongBaris ini bikin string baru yang kosong namanya s, yang nantinya bisa kita
isiin data. Biasanya, kita punya data awal yang mau kita pake buat mulai string-nya.
Buat kasus itu, kita pake method to_string, yang tersedia di tipe apa pun yang
mengimplementasikan trait Display, kayak literal string. Listing 8-12 nunjukin
dua contohnya.
fn main() {
let data = "initial contents";
let s = data.to_string();
// The method also works on a literal directly:
let s = "initial contents".to_string();
}to_string buat bikin String dari literal stringKode ini bikin sebuah string yang isinya teks initial contents.
Kita juga bisa pake fungsi String::from buat bikin String dari literal
string. Kode di Listing 8-13 itu ekuivalen (sama) sama kode di Listing 8-12
yang pake to_string.
fn main() {
let s = String::from("initial contents");
}String::from buat bikin String dari literal stringKarena strings dipake buat macem-macem hal, kita bisa pake banyak API generik
yang beda-beda buat strings, ngasih kita sangat banyak opsi. Beberapa mungkin
keliatannya berlebihan (redundant), tapi semuanya punya tempatnya masing-masing!
Di kasus ini, String::from sama to_string ngelakuin hal yang persis sama,
jadi milih yang mana itu cuma masalah gaya (style) dan readability (keterbacaan)
aja.
Inget ya kalau strings itu berkode UTF-8, jadi kita bisa masukin data apa pun yang di-encode dengan bener ke dalemnya, kayak yang ditunjukin di Listing 8-14.
fn main() {
let hello = String::from("السلام عليكم");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שלום");
let hello = String::from("नमस्ते");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
}Semua ini adalah nilai String yang valid.
Ngubah String
Sebuah String bisa nambah ukurannya dan isinya bisa berubah, sama kayak isi
dari Vec<T>, kalau kita nge-push (masukin) lebih banyak data ke dalemnya.
Selain itu, kita bisa pake operator + atau macro format! buat ngegabungin
(concatenate) nilai-nilai String dengan gampang.
Nambahin Teks ke String pake push_str sama push
Kita bisa nambah ukuran String dengan pake method push_str buat nambahin
string slice di akhirnya, kayak yang ditunjukin di Listing 8-15.
fn main() {
let mut s = String::from("foo");
s.push_str("bar");
}String pake method push_strSetelah dua baris ini, s bakal isinya foobar. Method push_str nerima
string slice karena kita nggak selamanya mau ngambil ownership dari
parameternya. Misalnya, di kode di Listing 8-16, kita mau tetep bisa pake s2
setelah nambahin isinya ke s1.
fn main() {
let mut s1 = String::from("foo");
let s2 = "bar";
s1.push_str(s2);
println!("s2 is {s2}");
}StringKalau method push_str ngambil ownership dari s2, kita nggak bakal bisa
nyetak nilainya di baris terakhir. Tapi, kode ini jalan sesuai yang kita mau kok!
Method push nerima satu karakter sebagai parameter dan nambahin itu ke String.
Listing 8-17 nambahin huruf l ke dalem String pake method push.
fn main() {
let mut s = String::from("lo");
s.push('l');
}String pake pushHasilnya, s bakal isinya lol.
Penggabungan (Concatenation) pake Operator + atau Macro format!
Sering kali, kita mau ngegabungin dua string yang udah ada. Salah satu
caranya adalah pake operator +, kayak yang ditunjukin di Listing 8-18.
fn main() {
let s1 = String::from("Hello, ");
let s2 = String::from("world!");
let s3 = s1 + &s2; // note s1 has been moved here and can no longer be used
}+ buat ngegabungin dua nilai String jadi nilai String baruString s3 bakal isinya Hello, world!. Alasan kenapa s1 udah nggak
valid lagi setelah penjumlahannya, dan alasan kenapa kita pake referensi ke s2,
ada hubungannya sama signature dari method yang dipanggil pas kita pake
operator +. Operator + pake method add, yang signature-nya kira-kira
kayak gini:
fn add(self, s: &str) -> String {Di standard library, kita bakal liat add didefinisikan pake generik
(generics) sama associated types. Di sini, kita udah ngegantiinnya pake tipe
konkret, yang merupakan apa yang terjadi pas kita manggil method ini pake nilai
String. Kita bakal bahas generik di Bab 10. Signature ini ngasih kita
petunjuk yang kita butuhin buat mahamin bagian-bagian tricky dari operator +.
Pertama, s2 punya &, yang artinya kita nambahin referensi dari string
kedua ke string pertama. Ini gara-gara parameter s di fungsi add: kita
cuma bisa nambahin &str ke dalem String; kita nggak bisa nambahin dua nilai
String bareng-bareng. Tapi tunggu—tipe dari &s2 itu &String, bukan &str,
kayak yang ditentuin di parameter kedua dari add. Terus kenapa Listing 8-18
bisa di-compile?
Alasan kenapa kita bisa pake &s2 di pemanggilan add adalah karena compiler
bisa nge-coerce (maksa/ngubah) argumen &String jadi &str. Pas kita manggil
method add, Rust pake yang namanya deref coercion, yang di sini ngerubah
&s2 jadi &s2[..]. Kita bakal bahas deref coercion lebih dalem di Bab 15.
Karena add nggak ngambil ownership dari parameter s, s2 bakal tetep jadi
String yang valid setelah operasi ini.
Kedua, kita bisa liat di signature-nya kalau add ngambil ownership dari
self karena self nggak punya &. Ini artinya s1 di Listing 8-18 bakal
di-move ke dalem pemanggilan add dan nggak bakal valid lagi setelahnya.
Jadi, walaupun let s3 = s1 + &s2; keliatannya kayak bakal ngopi kedua
string dan bikin yang baru, statement ini sebenernya ngambil ownership dari
s1, nambahin (append) salinan isi dari s2 ke dalemnya, terus balikin
ownership dari hasilnya. Dengan kata lain, keliatannya dia bikin banyak
salinan, tapi sebenernya nggak; implementasinya jauh lebih efisien daripada ngopi.
Kalau kita butuh ngegabungin banyak strings, perilaku dari operator + bakal
jadi ribet sekali:
fn main() {
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = s1 + "-" + &s2 + "-" + &s3;
}Di titik ini, s bakal jadi tic-tac-toe. Dengan semua karakter + sama ",
susah buat liat apa yang sebenernya lagi terjadi. Buat ngegabungin strings
dengan cara yang lebih kompleks, kita bisa pake macro format! sebagai
gantinya:
fn main() {
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = format!("{s1}-{s2}-{s3}");
}Kode ini juga nge-set s jadi tic-tac-toe. Macro format! cara kerjanya
mirip println!, tapi bukannya nyetak output ke layar, dia balikin String
yang isinya teks hasil formatnya. Versi kode yang pake format! itu jauh lebih
gampang dibaca, dan kode yang dihasilin sama macro format! pake referensi jadi
pemanggilan ini nggak bakal ngambil ownership dari parameter mana pun.
Indexing ke dalem Strings
Di banyak bahasa pemrograman lain, akses tiap karakter individu di dalem string
dengan ngerujuk ke indeks mereka itu adalah operasi yang valid dan umum sekali.
Tapi, kalau kita nyoba akses bagian dari String pake sintaks indexing di
Rust, kita bakal dapet error. Coba liat kode yang nggak valid di Listing 8-19.
fn main() {
let s1 = String::from("hi");
let h = s1[0];
}StringKode ini bakal ngasilin error berikut:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0277]: the type `str` cannot be indexed by `{integer}`
--> src/main.rs:3:16
|
3 | let h = s1[0];
| ^ string indices are ranges of `usize`
|
= help: the trait `SliceIndex<str>` is not implemented for `{integer}`
= note: you can use `.chars().nth()` or `.bytes().nth()`
for more information, see chapter 8 in The Book: <https://doc.rust-lang.org/book/ch08-02-strings.html#indexing-into-strings>
= help: the following other types implement trait `SliceIndex<T>`:
`usize` implements `SliceIndex<ByteStr>`
`usize` implements `SliceIndex<[T]>`
= note: required for `String` to implement `Index<{integer}>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `collections` (bin "collections") due to 1 previous error
Error dan catatannya nyeritain ceritanya: strings di Rust nggak support indexing. Tapi kenapa nggak? Buat ngejawab pertanyaan itu, kita harus bahas gimana Rust nyimpen strings di memori.
Representasi Internal
Sebuah String adalah bungkus (wrapper) buat Vec<u8>. Yuk kita liat beberapa
contoh strings berkode UTF-8 kita dari Listing 8-14. Pertama, yang ini:
fn main() {
let hello = String::from("السلام عليكم");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שלום");
let hello = String::from("नमस्ते");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
}Di kasus ini, len bakal bernilai 4, yang artinya vector yang nyimpen string
"Hola" itu panjangnya 4 byte. Tiap huruf ini butuh satu byte pas di-encode
dalam UTF-8. Tapi, baris berikut ini mungkin bikin kita kaget (perhatiin ya
kalau string ini dimulai pake huruf kapital Cyrillic Ze, bukan angka 3):
fn main() {
let hello = String::from("السلام عليكم");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שלום");
let hello = String::from("नमस्ते");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
}Kalau kita ditanya seberapa panjang string ini, kita mungkin bakal jawab 12. Nyatanya, jawaban Rust adalah 24: itu adalah jumlah byte yang dibutuhin buat nge- encode “Здравствуйте” dalam UTF-8, karena tiap nilai scalar Unicode di dalem string itu butuh memori sebesar 2 byte. Karena itu, sebuah indeks ke dalem byte-byte dari string nggak bakal selalu sejalan sama nilai scalar Unicode yang valid. Buat ngedemonstrasiin ini, coba liat kode Rust yang nggak valid ini:
let hello = "Здравствуйте";
let answer = &hello[0];Kita udah tau kalau answer nggak bakal isinya З, yaitu huruf pertamanya.
Pas di-encode di UTF-8, byte pertama dari З itu 208 dan yang kedua itu
151, jadi kayaknya answer harusnya sebenernya 208, tapi 208 itu bukan
karakter yang valid kalau sendirian. Balikin nilai 208 kemungkinannya bukan
apa yang dipengenin user pas mereka minta huruf pertama dari string ini;
tapi, cuma itu data yang dipunyai Rust di indeks byte 0. User biasanya nggak
mau nilai byte-nya yang dibalikin, walaupun string-nya cuma isinya huruf Latin
doang: kalau &"hi"[0] adalah kode valid yang balikin nilai byte-nya, dia bakal
balikin 104, bukan h.
Jadi jawabannya adalah buat ngehindarin balikin nilai yang nggak disangka-sangka dan nyebabin bug yang mungkin nggak langsung ketahuan, Rust milih buat sama sekali nggak nge-compile kode ini dan nyegah kesalahpahaman dari awal di proses development (pengembangan).
Bytes dan Nilai Scalar dan Grapheme Clusters! Waduh!
Poin lainnya soal UTF-8 adalah sebenernya ada tiga cara yang relevan buat ngeliat strings dari sudut pandang Rust: sebagai bytes (byte-byte), nilai scalar (scalar values), sama grapheme clusters (hal yang paling mendekati sama apa yang bakal kita sebut letters atau huruf).
Kalau kita liat kata Hindi “नमस्ते” yang ditulis dalam aksara Devanagari, dia
disimpan sebagai vector dari nilai u8 yang keliatannya kayak gini:
[224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164,
224, 165, 135]
Itu ada 18 byte dan ini adalah gimana komputer akhirnya nyimpen data ini. Kalau
kita liat mereka sebagai nilai scalar Unicode, yang mana itu adalah representasi
tipe char di Rust, byte-byte itu bakal keliatan kayak gini:
['न', 'म', 'स', '्', 'त', 'े']
Ada enam nilai char di sini, tapi yang keempat sama keenam itu bukan huruf:
mereka itu diacritics (tanda baca tambahan) yang nggak ada artinya kalau
berdiri sendiri. Terakhir, kalau kita liat mereka sebagai grapheme clusters,
kita bakal dapet apa yang bakal disebut orang sebagai empat huruf yang ngebentuk
kata Hindi tersebut:
["न", "म", "स्", "ते"]
Rust nyediain cara beda-beda buat nerjemahin (interpreting) data string mentah yang disimpan komputer biar tiap program bisa milih terjemahan yang dia butuhin, nggak peduli apa bahasa manusia dari data tersebut.
Alasan terakhir kenapa Rust nggak ngebolehin kita nge-index ke dalem String
buat dapet sebuah karakter adalah karena operasi indexing diharapkan bakal
selalu butuh waktu konstan (O(1)). Tapi nggak mungkin buat ngejamin performa itu
kalo pake String, karena Rust harus jalanin (walk through) isinya mulai dari
awal sampe indeks tersebut buat nentuin berapa banyak karakter valid yang ada di
sana.
Slicing Strings
Indexing ke dalem string itu sering kali adalah ide yang jelek karena nggak jelas tipe return apa yang seharusnya dihasilin dari operasi indexing string itu: apakah nilai byte, karakter, grapheme cluster, atau sebuah string slice. Jadi, kalau kita bener-bener butuh pake indeks buat bikin string slice, Rust minta kita buat lebih spesifik.
Bukannya indexing pake [] sama satu angka doang, kita bisa pake []
bareng range (rentang) buat bikin string slice yang isinya byte-byte tertentu:
#![allow(unused)]
fn main() {
let hello = "Здравствуйте";
let s = &hello[0..4];
}Di sini, s bakal jadi &str yang isinya empat byte pertama dari string
tersebut. Tadi, kita udah bilang kalau tiap karakter ini ukurannya dua byte,
yang artinya s bakal jadi Зд.
Kalau kita nyoba nge-slice cuma sebagian dari byte-byte punya satu karakter,
misalnya pake &hello[0..1], Rust bakal panic pas runtime sama kayak
kalau ada indeks yang nggak valid yang diakses di vector:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/collections`
thread 'main' panicked at src/main.rs:4:19:
byte index 1 is not a char boundary; it is inside 'З' (bytes 0..2) of `Здравствуйте`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Kita harus hati-hati pas bikin string slices pake range, karena ngelakuin itu bisa bikin program kita crash.
Methods buat Iterasi Lewat Strings
Cara terbaik buat ngoperasiin potongan-potongan dari strings adalah dengan
jelas (explicit) nentuin apakah kita mau karakter atau byte-nya. Buat dapet
nilai scalar Unicode individu, pake method chars. Manggil chars di “Зд”
bakal misahin dan balikin dua nilai bertipe char, dan kita bisa iterasi
hasilnya buat akses tiap elemennya:
#![allow(unused)]
fn main() {
for c in "Зд".chars() {
println!("{c}");
}
}Kode ini bakal nyetak output berikut:
З
д
Alternatifnya, method bytes balikin tiap byte mentahnya (raw byte), yang
mungkin cocok buat domain (ranah) kita:
#![allow(unused)]
fn main() {
for b in "Зд".bytes() {
println!("{b}");
}
}Kode ini bakal nyetak empat byte yang ngebentuk string ini:
208
151
208
180
Tapi pastiin buat inget kalau nilai scalar Unicode yang valid itu mungkin disusun dari lebih dari satu byte.
Dapetin grapheme clusters dari strings, kayak pas pake aksara Devanagari tadi, itu kompleks, jadi fungsionalitas ini nggak disediain sama standard library. Ada crates yang tersedia di crates.io kalau ini fungsionalitas yang kita butuhin.
Strings Nggak Sesimpel Itu
Sebagai ringkasan, strings itu ribet (complicated). Bahasa pemrograman yang
beda milih cara yang beda-beda juga soal gimana nyajiin keribetan ini ke
programmer. Rust milih buat ngebikin cara nanganin data String dengan bener
sebagai perilaku default buat semua program Rust, yang artinya programmer
harus mikir lebih dalem buat nanganin data UTF-8 di awal. Trade-off (pertukaran)
ini nge-ekspos lebih banyak keribetan strings daripada yang keliatan di bahasa
pemrograman lain, tapi ini nyegah kita dari harus nanganin error yang
ngelibatin karakter non-ASCII di masa depan pas siklus pengembangan (development
life cycle).
Kabar baiknya adalah standard library nawarin sangat banyak fungsionalitas
yang dibangun di atas tipe String sama &str buat ngebantu kita nanganin
situasi kompleks ini dengan bener. Pastiin buat cek dokumentasi buat method-method
berguna kayak contains buat nyari sesuatu di dalem string dan replace buat
nggantiin bagian dari string pake string lainnya.
Yuk kita beralih ke sesuatu yang sedikit kurang ribet: hash maps!
Menyimpan Keys dengan Nilai Terkait di Hash Maps
Nyimpen Keys (Kunci) dengan Nilai Terkait di Hash Maps
Koleksi umum kita yang terakhir adalah hash map. Tipe HashMap<K, V> nyimpen
pemetaan dari keys (kunci) bertipe K ke nilai bertipe V pake sebuah fungsi
hashing, yang nentuin gimana cara naruh keys sama nilai-nilai ini ke dalem
memori. Banyak bahasa pemrograman support struktur data jenis ini, tapi mereka
sering pake nama yang beda-beda, kayak hash, map, object, hash table,
dictionary, atau associative array, buat nyebut beberapa di antaranya.
Hash maps sangat berguna pas kita mau nyari data bukan pake indeks, kayak yang kita lakuin pake vectors, tapi pake key yang tipenya bisa apa aja. Misalnya, di dalem game, kita bisa nyatet skor tiap tim di dalem hash map di mana tiap key-nya adalah nama timnya dan nilainya adalah skor tiap tim. Kalo kita punya nama timnya, kita bisa ngambil skornya.
Kita bakal ngebahas API dasar dari hash maps di bagian ini, tapi masih banyak
lagi fungsionalitas keren yang ngumpet di fungsi-fungsi yang didefinisikan pada
HashMap<K, V> sama standard library. Kayak biasa, cek dokumentasi standard
library buat info lebih lanjut.
Bikin Hash Map Baru
Salah satu cara buat bikin hash map kosong adalah pake new terus nambahin
elemennya pake insert. Di Listing 8-20, kita lagi nyatet skor dari dua tim
yang namanya Blue sama Yellow. Tim Blue mulai dengan 10 poin, dan tim Yellow
mulai dengan 50 poin.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
}Perhatiin ya kalau kita pertama-tama harus bawa HashMap dari porsi collections
di standard library ke dalem scope pake use. Dari ketiga koleksi umum kita,
yang satu ini paling jarang dipake, jadi dia nggak dimasukin ke fitur-fitur yang
otomatis dibawa ke dalem scope lewat prelude. Hash maps juga dapet lebih
dikit support dari standard library; nggak ada macro bawaan buat
ngonstruksi mereka, misalnya.
Sama kayak vectors, hash maps nyimpen datanya di heap. HashMap ini punya
keys tipe String sama nilai tipe i32. Sama juga kayak vectors, hash maps
itu homogen: semua keys harus punya tipe yang sama, dan semua nilai harus
punya tipe yang sama.
Akses Nilai di dalem Hash Map
Kita bisa ngambil nilai dari hash map dengan masukin key-nya ke method get,
kayak yang ditunjukin di Listing 8-21.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
let team_name = String::from("Blue");
let score = scores.get(&team_name).copied().unwrap_or(0);
}Di sini, score bakal punya nilai yang terkait sama tim Blue, dan hasilnya
bakal 10. Method get balikin sebuah Option<&V>; kalau nggak ada nilai
buat key itu di hash map-nya, get bakal balikin None. Program ini nanganin
Option-nya pake manggil copied buat dapet Option<i32> bukannya
Option<&i32>, terus pake unwrap_or buat nge-set score jadi nol kalau
scores nggak punya entri buat key tersebut.
Kita bisa iterasi lewat tiap pasangan key-value (kunci-nilai) di hash map pake
cara yang mirip kayak di vectors, pake for loop:
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
for (key, value) in &scores {
println!("{key}: {value}");
}
}Kode ini bakal nyetak tiap pasangan dengan urutan yang sembarangan (arbitrary):
Yellow: 50
Blue: 10
Hash Maps dan Ownership
Buat tipe-tipe yang mengimplementasikan trait Copy, kayak i32, nilainya
di-copy ke dalem hash map. Buat nilai yang dimiliki (owned values) kayak
String, nilainya bakal di-move dan hash map bakal jadi pemilik (owner)
dari nilai-nilai itu, kayak yang didemonstrasiin di Listing 8-22.
fn main() {
use std::collections::HashMap;
let field_name = String::from("Favorite color");
let field_value = String::from("Blue");
let mut map = HashMap::new();
map.insert(field_name, field_value);
// field_name and field_value are invalid at this point, try using them and
// see what compiler error you get!
}Kita nggak bisa pake variabel field_name sama field_value setelah mereka di-
move ke dalem hash map pake pemanggilan insert.
Kalau kita masukin referensi ke nilai ke dalem hash map, nilainya nggak bakal di-move ke dalem hash map-nya. Nilai yang ditunjuk sama referensi itu harus tetep valid setidaknya selama hash map-nya valid. Kita bakal bahas masalah ini lebih banyak di “Mervalidasi Referensi pake Lifetimes” di Bab 10.
Ngubah Hash Map
Walaupun jumlah pasangan key sama value bisa nambah, tiap unique key cuma bisa
punya satu nilai yang terkait dengannya dalam satu waktu (tapi nggak berlaku
sebaliknya: misalnya, baik tim Blue maupun tim Yellow bisa punya nilai 10
yang disimpan di hash map scores).
Pas kita mau ngubah data di dalem hash map, kita harus mutusin gimana cara nanganin kasus pas sebuah key udah punya nilai yang di-assign ke dia. Kita bisa nggantiin nilai lama pake nilai baru, sama sekali nyuekin nilai yang lama. Kita bisa pertahanin nilai lama dan nyuekin nilai baru, dan cuma nambahin nilai baru kalau key itu belum punya nilai. Atau kita bisa ngegabungin nilai lama sama nilai baru. Yuk kita liat gimana cara ngelakuin semua hal ini!
Nindih Nilai (Overwriting a Value)
Kalau kita nge-insert sebuah key sama nilai ke hash map terus nge-insert
key yang sama pake nilai yang beda, nilai yang terkait sama key itu bakal
diganti. Walaupun kode di Listing 8-23 manggil insert dua kali, hash map-nya
cuma bakal punya satu pasangan key-value karena kita nge-insert nilai buat
key tim Blue dua kali.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Blue"), 25);
println!("{scores:?}");
}Kode ini bakal nyetak {"Blue": 25}. Nilai asli 10 udah ditindih.
Nambahin Key dan Nilai Cuma Kalau Key-nya Belum Ada
Sering sekali kita mau nge-cek apakah sebuah key tertentu udah ada di hash map dengan suatu nilai terus ngambil tindakan berikut: kalau key itu emang udah ada di hash map, nilai yang udah ada biarin aja kayak gitu; kalau key-nya belum ada, insert key itu bareng nilainya.
Hash maps punya API khusus buat ini namanya entry yang nerima key yang mau
kita cek sebagai parameternya. Nilai return dari method entry ini adalah enum
namanya Entry yang ngewakilin nilai yang mungkin udah ada atau mungkin belum.
Katakanlah kita mau nge-cek apakah key buat tim Yellow punya nilai yang terkait
dengannya. Kalau belum ada, kita mau nge-insert nilai 50, dan lakuin hal yang
sama buat tim Blue. Pake API entry, kodenya keliatan kayak Listing 8-24.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.entry(String::from("Yellow")).or_insert(50);
scores.entry(String::from("Blue")).or_insert(50);
println!("{scores:?}");
}entry buat nge-insert cuma kalau key-nya belum punya nilaiMethod or_insert pada Entry didefinisikan buat balikin sebuah mutable
reference ke nilai buat key Entry yang terkait kalau key itu ada, dan kalau
nggak ada, dia nge-insert parameternya sebagai nilai baru buat key ini terus
balikin mutable reference ke nilai yang baru. Teknik ini jauh lebih bersih
daripada nulis logikanya sendiri dan, selain itu, main lebih akur sama borrow
checker.
Jalanin kode di Listing 8-24 bakal nyetak {"Yellow": 50, "Blue": 10}.
Pemanggilan entry yang pertama bakal nge-insert key buat tim Yellow dengan
nilai 50 karena tim Yellow belum punya nilai. Pemanggilan entry yang kedua
nggak bakal ngubah hash map-nya karena tim Blue udah punya nilai 10.
Ngubah Nilai Berdasarkan Nilai Lamanya
Skenario umum lainnya buat hash maps adalah nyari nilai dari sebuah key terus
ngubah nilainya berdasarkan nilai yang lama. Misalnya, Listing 8-25 nunjukin
kode yang ngitung berapa kali tiap kata muncul di sebuah teks. Kita pake hash
map dengan kata-katanya sebagai keys dan nambahin (increment) nilainya buat
nyatet berapa kali kita ngeliat kata itu. Kalau ini pertama kalinya kita liat
kata itu, kita bakal nge-insert nilai 0 dulu.
fn main() {
use std::collections::HashMap;
let text = "hello world wonderful world";
let mut map = HashMap::new();
for word in text.split_whitespace() {
let count = map.entry(word).or_insert(0);
*count += 1;
}
println!("{map:?}");
}Kode ini bakal nyetak {"world": 2, "hello": 1, "wonderful": 1}. Kita mungkin
bakal ngeliat pasangan key-value yang sama dicetak pake urutan yang beda: inget
kan di “Akses Nilai di dalem Hash Map” kalau iterasi lewat hash map
itu terjadi dengan urutan yang sembarangan (arbitrary).
Method split_whitespace balikin iterator yang ngelewatin subslices,
dipisahin sama spasi (whitespace), dari nilai di text. Method or_insert
balikin sebuah mutable reference (&mut V) ke nilai buat key yang spesifik
itu. Di sini, kita nyimpen mutable reference itu di variabel count, jadi
buat nge-assign (ngasih nilai) ke nilai itu, kita pertama-tama harus pake dereference
pada count pake tanda bintang (*). Mutable reference-nya keluar dari
scope di akhir dari for loop, jadi semua perubahan ini aman dan dibolehin sama
aturan borrowing.
Fungsi Hashing
Secara default, HashMap pake fungsi hashing namanya SipHash yang bisa ngasih
ketahanan dari serangan denial-of-service (DoS) yang ngelibatin hash
tables1. Ini bukan algoritma hashing paling cepet yang ada, tapi
trade-off buat keamanan yang lebih baik dengan sedikit penurunan performa
itu sepadan sekali. Kalau kita nge-profile kode kita dan ngerasa kalau
fungsi hash default-nya terlalu lambat buat tujuan kita, kita bisa ganti ke
fungsi lain dengan nentuin hasher yang beda. Sebuah hasher adalah tipe yang
mengimplementasikan trait BuildHasher. Kita bakal bahas traits dan cara
mengimplementasikan mereka di Bab 10. Kita nggak perlu harus
mengimplementasikan hasher kita sendiri dari nol kok;
crates.io punya library-library yang di-share sama user
Rust lainnya yang nyediain hashers yang mengimplementasikan banyak algoritma
hashing umum.
Ringkasan
Vectors, strings, sama hash maps bakal nyediain banyak fungsionalitas yang dibutuhin di program kita pas kita perlu nyimpen, akses, dan ngubah data. Ini ada beberapa latihan yang sekarang harusnya udah bisa kita selesein:
- Dikasih sekumpulan integer, pake sebuah vector dan balikin median (pas diurutin, nilai di posisi tengah) sama modus (nilai yang paling sering muncul; hash map bakal ngebantu sekali di sini) dari sekumpulan nilai itu.
- Convert strings ke pig latin. Konsonan pertama dari tiap kata dipindah ke akhir kata terus ditambahin ay, jadi first jadi irst-fay. Kata-kata yang diawali sama huruf vokal ditambahin hay di akhirnya (apple jadi apple-hay). Inget detail soal encoding UTF-8 ya!
- Pake hash map sama vectors, bikin interface teks buat ngebolehin user nambahin nama pegawai ke sebuah departemen di sebuah perusahaan; misalnya, “Tambahin Sally ke Engineering” atau “Tambahin Amir ke Sales.” Terus bolehin user buat narik (retrieve) daftar semua orang di suatu departemen atau semua orang di perusahaan berdasarkan departemen, diurutin secara alfabet.
Dokumentasi API standard library ngejelasin method-method yang dipunyai sama vectors, strings, sama hash maps yang bakal ngebantu sekali buat latihan- latihan ini!
Kita lagi masuk ke program-program yang lebih kompleks di mana operasi bisa aja gagal, jadi ini waktu yang paling pas buat bahas penanganan error (error handling). Kita bakal ngelakuin itu berikutnya!
Error Handling (Penanganan Error)
Error itu adalah kenyataan hidup di software, jadi Rust punya sejumlah fitur buat nanganin situasi di mana ada sesuatu yang salah. Di banyak kasus, Rust mewajibkan kita buat ngakuin kemungkinan adanya error dan ngambil suatu aksi sebelum kode kita bisa di-compile. Persyaratan ini bikin program kita jadi lebih kuat (robust) dengan mastiin kalau kita bakal nemuin error dan nanganin mereka dengan bener sebelum kita nge-deploy kode kita ke production!
Rust ngelempokin error jadi dua kategori besar: error recoverable (yang bisa dipulihkan) dan unrecoverable (yang nggak bisa dipulihkan). Buat error yang recoverable, kayak error file not found (file nggak ditemuin), kemungkinan besar kita cuma mau ngelaporin masalahnya ke user terus nyoba operasinya lagi. Error yang unrecoverable selalu jadi gejala dari bugs, kayak nyoba akses lokasi yang ngelewatin akhir dari sebuah array, dan makanya kita mau langsung ngehentiin programnya.
Kebanyakan bahasa nggak ngebedain dua jenis error ini dan nanganin keduanya
pake cara yang sama, pake mekanisme kayak exceptions (pengecualian). Rust nggak
punya exceptions. Sebaliknya, dia punya tipe Result<T, E> buat error yang
recoverable dan macro panic! yang ngehentiin eksekusi pas program nemu error
yang unrecoverable. Bab ini bakal bahas soal manggil panic! dulu terus bahas
soal balikin nilai Result<T, E>. Selain itu, kita bakal eksplor pertimbangan-
pertimbangan pas milih buat nyoba pulih (recover) dari error atau ngehentiin
eksekusi.
Error yang Tidak Bisa Dipulihkan Memakai panic!
Error Unrecoverable pake panic!
Kadang hal-hal buruk terjadi di kode kita, dan nggak ada yang bisa kita lakuin
buat ngatasinnya. Di kasus kayak gini, Rust punya macro panic!. Ada dua cara
buat micu sebuah panic di praktiknya: dengan ngambil aksi yang bikin kode
kita panic (kayak akses array ngelewatin akhirnya) atau dengan secara
eksplisit manggil macro panic!. Di dua kasus itu, kita nyebabin sebuah panic
di program kita. Secara default, panics ini bakal nyetak pesan kegagalan,
unwind (nggulung balik), ngebersihin stack, terus quit (keluar). Lewat
environment variable (variabel lingkungan), kita juga bisa nyuruh Rust buat
nampilin call stack pas sebuah panic terjadi biar lebih gampang buat ngelacak
sumber dari panic itu.
Unwinding the Stack atau Aborting sebagai Respon ke Panic
Secara default, pas sebuah panic terjadi, program mulai proses unwinding, yang artinya Rust jalan mundur ke atas stack terus ngebersihin data dari tiap fungsi yang dia temuin. Tapi, jalan mundur terus ngebersihin data itu butuh banyak kerjaan. Makanya, Rust ngebolehin kita milih alternatif yaitu langsung aborting (ngebatalin), yang ngeakhirin program tanpa ngebersihin apa-apa.
Memori yang tadinya dipake program terus bakal perlu dibersihin sama sistem
operasi (OS). Kalau di project kita kita butuh ngebikin file binary hasil
akhirnya sekecil mungkin, kita bisa pindah dari unwinding jadi aborting
pas terjadi panic dengan nambahin panic = 'abort' ke bagian [profile]
yang sesuai di file Cargo.toml kita. Misalnya, kalau kita mau abort pas
panic di release mode, tambahin ini:
[profile.release]
panic = 'abort'
Yuk kita coba manggil panic! di program yang simpel:
fn main() {
panic!("crash and burn");
}Pas kita jalanin programnya, kita bakal liat yang kayak gini:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.25s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:2:5:
crash and burn
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Pemanggilan panic! nyebabin pesan error yang ada di dua baris terakhir. Baris
pertama nunjukin pesan panic kita dan lokasi di source code kita di mana
panic-nya terjadi: src/main.rs:2:5 nunjukin kalau itu ada di baris kedua,
karakter kelima di file src/main.rs kita.
Di kasus ini, baris yang ditunjuk adalah bagian dari kode kita, dan kalau kita
buka baris itu, kita bakal liat pemanggilan macro panic!. Di kasus lain,
pemanggilan panic! mungkin ada di kode yang dipanggil sama kode kita, dan
nama file serta nomor baris yang dilaporin sama pesan error-nya bakal nunjukin
kode punya orang lain di mana macro panic! itu dipanggil, bukan baris kode
kita yang akhirnya nyebabin pemanggilan panic! itu.
Kita bisa pake backtrace dari fungsi-fungsi tempat panic! dipanggil buat
nyari tau bagian mana dari kode kita yang nyebabin masalahnya. Buat mahamin
gimana cara pake backtrace panic!, yuk kita liat contoh lain dan liat
gimana rasanya pas pemanggilan panic! dateng dari sebuah library gara-gara
ada bug di kode kita, bukannya dari kode kita yang manggil macro-nya secara
langsung. Listing 9-1 punya kode yang nyoba akses indeks di vector yang ngelewatin
rentang (range) indeks yang valid.
fn main() {
let v = vec![1, 2, 3];
v[99];
}panic!Di sini, kita lagi nyoba akses elemen ke-100 dari vector kita (yang ada di indeks
99 karena indexing mulai dari nol), tapi vector-nya cuma punya tiga elemen. Di
situasi ini, Rust bakal panic. Pake [] seharusnya balikin sebuah elemen,
tapi kalau kita ngasih indeks yang nggak valid, nggak ada elemen yang bisa
dibalikin Rust di sini yang bener.
Di C, nyoba baca data ngelewatin akhir dari struktur data itu dianggap sebagai undefined behavior (perilaku yang nggak terdefinisi). Kita mungkin bakal dapet apa pun yang ada di lokasi memori yang harusnya sesuai sama elemen itu di struktur datanya, walaupun memori itu bukan milik struktur data tersebut. Ini disebut buffer overread dan bisa memicu celah keamanan (security vulnerabilities) kalau seorang attacker (penyerang) bisa memanipulasi indeks sedemikian rupa biar bisa baca data yang nggak boleh mereka baca yang disimpan setelah struktur data itu.
Buat ngelindungin program kita dari celah semacam ini, kalau kita nyoba baca elemen di indeks yang nggak ada, Rust bakal ngehentiin eksekusi dan nolak buat lanjut. Yuk kita coba dan liat hasilnya:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Error ini nunjuk ke baris 4 dari main.rs kita di mana kita nyoba akses indeks
99 dari vector di v.
Baris note: ngasih tau kita kalau kita bisa nge-set environment variable
RUST_BACKTRACE buat dapetin backtrace dari apa persisnya yang terjadi yang
nyebabin error itu. Sebuah backtrace adalah daftar dari semua fungsi yang
udah dipanggil sampe bisa nyampe ke titik ini. Backtraces di Rust cara
kerjanya sama kayak di bahasa lain: kunci buat baca backtrace adalah mulai
dari atas terus baca sampe kita liat file yang kita tulis sendiri. Itu adalah
titik di mana masalahnya bermula. Baris-baris di atas titik itu adalah kode yang
dipanggil sama kode kita; baris-baris di bawahnya adalah kode yang manggil kode
kita. Baris-baris sebelum dan sesudah ini mungkin nyakup kode inti Rust, kode
standard library, atau crates yang lagi kita pake. Yuk kita coba dapetin
backtrace dengan nge-set environment variable RUST_BACKTRACE ke nilai apa
pun kecuali 0. Listing 9-2 nunjukin output yang mirip sama apa yang bakal kita
liat.
$ RUST_BACKTRACE=1 cargo run
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
stack backtrace:
0: rust_begin_unwind
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/std/src/panicking.rs:692:5
1: core::panicking::panic_fmt
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:75:14
2: core::panicking::panic_bounds_check
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:273:5
3: <usize as core::slice::index::SliceIndex<[T]>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:274:10
4: core::slice::index::<impl core::ops::index::Index<I> for [T]>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:16:9
5: <alloc::vec::Vec<T,A> as core::ops::index::Index<I>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/alloc/src/vec/mod.rs:3361:9
6: panic::main
at ./src/main.rs:4:6
7: core::ops::function::FnOnce::call_once
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/ops/function.rs:250:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
panic! yang ditampilin pas environment variable RUST_BACKTRACE di-setOutputnya lumayan banyak tuh! Output pasti yang bakal kita liat mungkin beda-beda
tergantung dari sistem operasi sama versi Rust yang dipake. Biar dapet
backtraces dengan informasi sebanyak ini, debug symbols harus dinyalain.
Debug symbols dinyalain secara default pas kita pake cargo build atau
cargo run tanpa flag --release, kayak yang kita lakuin di sini.
Di output di Listing 9-2, baris 6 dari backtrace-nya nunjuk ke baris di project kita yang nyebabin masalahnya: baris 4 dari src/main.rs. Kalau kita nggak mau program kita panic, kita harus mulai nyari masalahnya di lokasi yang ditunjuk sama baris pertama yang nyebutin file yang kita tulis sendiri. Di Listing 9-1, di mana kita sengaja nulis kode yang bakal panic, cara buat benerin panic-nya adalah dengan nggak minta elemen yang ada di luar rentang indeks vector-nya. Pas kode kita panic di masa depan nanti, kita harus nyari tau aksi apa yang lagi dilakuin sama kode itu pake nilai apa sampe bisa nyebabin panic dan apa yang seharusnya dilakuin sama kode itu sebagai gantinya.
Kita bakal balik lagi bahas panic! dan kapan kita harus dan nggak harus pake
panic! buat nanganin kondisi error di bagian “To panic! or Not to
panic!” nanti di bab ini. Selanjutnya, kita bakal
liat gimana caranya buat pulih dari sebuah error pake Result.
Error yang Bisa Dipulihkan Memakai Result
Error Recoverable pake Result
Sebagian besar error nggak terlalu serius sampe harus ngehentiin program sepenuhnya. Kadang pas sebuah fungsi gagal itu karena alasan yang bisa kita interpretasi dan respon dengan gampang. Misalnya, kalau kita nyoba buka file dan operasi itu gagal gara-gara filenya nggak ada, kita mungkin mau bikin file itu bukannya malah nge-terminate (menghentikan) prosesnya.
Inget dari “Menangani Potensi Kegagalan dengan Result” di
Bab 2 kalau enum Result didefinisikan punya dua varian, Ok sama Err,
kayak gini:
#![allow(unused)]
fn main() {
enum Result<T, E> {
Ok(T),
Err(E),
}
}T sama E itu generic type parameters (parameter tipe generik): kita bakal
bahas generik lebih detail di Bab 10. Yang perlu kita tau sekarang adalah T
merepresentasikan tipe dari nilai yang bakal dibalikin di kasus sukses di dalem
varian Ok, dan E merepresentasikan tipe dari error yang bakal dibalikin di
kasus gagal di dalem varian Err. Karena Result punya generic type
parameters ini, kita bisa pake tipe Result dan fungsi-fungsi yang
didefinisikan padanya di banyak situasi yang beda di mana nilai sukses dan nilai
error yang mau kita balikin mungkin beda-beda.
Yuk kita manggil fungsi yang balikin nilai Result karena fungsinya bisa aja
gagal. Di Listing 9-3 kita nyoba ngebuka sebuah file.
use std::fs::File;
fn main() {
let greeting_file_result = File::open("hello.txt");
}Tipe kembalian (return type) dari File::open adalah Result<T, E>. Parameter
generik T udah diisi sama implementasi dari File::open dengan tipe dari
nilai suksesnya, yaitu std::fs::File, yang merupakan sebuah file handle.
Tipe dari E yang dipake di nilai error adalah std::io::Error. Tipe kembalian
ini artinya pemanggilan ke File::open bisa aja sukses dan balikin file
handle yang bisa kita baca atau tulis. Pemanggilan fungsi ini juga bisa aja
gagal: misalnya, filenya mungkin nggak ada, atau kita mungkin nggak punya izin
(permission) buat akses file itu. Fungsi File::open butuh cara buat ngasih
tau kita apakah dia sukses atau gagal dan di saat yang sama ngasih kita antara
file handle atau informasi error. Informasi ini persis apa yang disampein
sama enum Result.
Di kasus di mana File::open sukses, nilai di variabel greeting_file_result
bakal jadi instance dari Ok yang nampung file handle. Di kasus di mana dia
gagal, nilai di greeting_file_result bakal jadi instance dari Err yang
nampung lebih banyak info soal jenis error yang terjadi.
Kita perlu nambahin kode di Listing 9-3 buat ngambil tindakan yang beda
tergantung dari nilai yang dibalikin sama File::open. Listing 9-4 nunjukin
salah satu cara buat nanganin Result pake tool dasar, yaitu ekspresi match
yang udah kita bahas di Bab 6.
use std::fs::File;
fn main() {
let greeting_file_result = File::open("hello.txt");
let greeting_file = match greeting_file_result {
Ok(file) => file,
Err(error) => panic!("Problem opening the file: {error:?}"),
};
}match buat nanganin varian Result yang mungkin dibalikinPerhatiin ya kalau sama kayak enum Option, enum Result sama varian-variannya
udah dibawa ke dalem scope lewat prelude, jadi kita nggak perlu nentuin
Result:: sebelum varian Ok sama Err di arms dari match-nya.
Pas hasilnya Ok, kode ini bakal balikin nilai file di dalem varian Ok-nya,
dan terus kita nge-assign nilai file handle itu ke variabel greeting_file.
Setelah match, kita bisa pake file handle-nya buat baca atau nulis.
Arm lain dari match-nya nanganin kasus di mana kita dapet nilai Err dari
File::open. Di contoh ini, kita milih buat manggil macro panic!. Kalau
nggak ada file namanya hello.txt di direktori kita saat ini dan kita jalanin
kode ini, kita bakal liat output berikut dari macro panic!:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/error-handling`
thread 'main' panicked at src/main.rs:8:23:
Problem opening the file: Os { code: 2, kind: NotFound, message: "No such file or directory" }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Kayak biasa, output ini ngasih tau kita persis apa yang salah.
Nge-match di Error yang Beda-beda
Kode di Listing 9-4 bakal panic! nggak peduli apa alasan File::open gagal.
Padahal, kita mau ngambil tindakan yang beda buat alasan kegagalan yang beda
juga. Kalau File::open gagal gara-gara filenya nggak ada, kita mau bikin
file itu terus balikin handle ke file baru itu. Kalau File::open gagal buat
alasan apa pun lainnya—misalnya, karena kita nggak punya izin buat buka
filenya—kita tetep mau kodenya buat panic! dengan cara yang sama kayak di
Listing 9-4. Buat ini, kita nambahin ekspresi match bersarang (inner match),
yang ditunjukin di Listing 9-5.
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let greeting_file_result = File::open("hello.txt");
let greeting_file = match greeting_file_result {
Ok(file) => file,
Err(error) => match error.kind() {
ErrorKind::NotFound => match File::create("hello.txt") {
Ok(fc) => fc,
Err(e) => panic!("Problem creating the file: {e:?}"),
},
_ => {
panic!("Problem opening the file: {error:?}");
}
},
};
}Tipe dari nilai yang dibalikin sama File::open di dalem varian Err adalah
io::Error, yang merupakan struct yang disediain sama standard library.
Struct ini punya method kind yang bisa kita panggil buat dapet nilai
io::ErrorKind. Enum io::ErrorKind disediain sama standard library dan
punya varian-varian yang merepresentasikan berbagai jenis error yang mungkin
terjadi dari sebuah operasi io. Varian yang mau kita pake adalah
ErrorKind::NotFound, yang ngindikasikan kalau file yang lagi kita coba buka
itu belum ada. Jadi kita nge-match greeting_file_result, tapi kita juga punya
inner match di error.kind().
Kondisi yang mau kita cek di inner match adalah apakah nilai yang dibalikin
sama error.kind() itu adalah varian NotFound dari enum ErrorKind. Kalau
iya, kita nyoba bikin filenya pake File::create. Tapi, karena File::create
juga bisa aja gagal, kita butuh arm kedua di ekspresi inner match kita. Pas
filenya nggak bisa dibuat, pesan error yang beda bakal dicetak. Arm kedua dari
match bagian luar (outer match) tetep sama, jadi programnya bakal panic
buat error apa pun selain error file nggak ditemuin.
Alternatif Buat Penggunaan match dengan Result<T, E>
Banyak sekali ya match-nya! Ekspresi match itu sangat berguna tapi dia
juga lumayan primitif. Di Bab 13, kita bakal belajar soal closures, yang
dipake bareng banyak method yang didefinisikan pada Result<T, E>. Method-
method ini bisa lebih ringkas daripada pake match pas nanganin nilai
Result<T, E> di kode kita.
Misalnya, ini cara lain buat nulis logika yang sama kayak yang ditunjukin di
Listing 9-5, kali ini pake closures dan method unwrap_or_else:
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let greeting_file = File::open("hello.txt").unwrap_or_else(|error| {
if error.kind() == ErrorKind::NotFound {
File::create("hello.txt").unwrap_or_else(|error| {
panic!("Masalah pas bikin file: {error:?}");
})
} else {
panic!("Masalah pas buka file: {error:?}");
}
});
}Walaupun kode ini punya perilaku yang sama kayak Listing 9-5, dia nggak punya
ekspresi match apa pun dan lebih bersih buat dibaca. Balik lagi ke contoh
ini setelah kita kelar baca Bab 13, terus cek method unwrap_or_else di
dokumentasi standard library. Masih banyak lagi method kayak gini yang bisa
ngerapihin ekspresi match bersarang yang sangat besar pas kita lagi berurusan
sama error.
Jalan Pintas buat Panic Kalo Error: unwrap sama expect
Pake match emang jalan dengan baik sih, tapi bisa agak kepanjangan (verbose)
dan nggak selalu ngomunikasikan maksud kita dengan baik. Tipe Result<T, E>
punya banyak method pembantu (helper methods) yang didefinisikan padanya buat
ngelakuin berbagai tugas yang lebih spesifik. Method unwrap itu adalah method
shortcut (jalan pintas) yang diimplementasikan persis kayak ekspresi match
yang kita tulis di Listing 9-4. Kalau nilai Result-nya adalah varian Ok,
unwrap bakal balikin nilai di dalem Ok-nya. Kalau Result-nya adalah
varian Err, unwrap bakal manggil macro panic! buat kita. Ini contoh
penggunaan unwrap:
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt").unwrap();
}Kalau kita jalanin kode ini tanpa file hello.txt, kita bakal liat pesan error
dari pemanggilan panic! yang dilakuin sama method unwrap:
thread 'main' panicked at src/main.rs:4:49:
called `Result::unwrap()` on an `Err` value: Os { code: 2, kind: NotFound, message: "No such file or directory" }
Sama halnya, method expect juga ngebolehin kita buat milih pesan error panic!-nya
sendiri. Pake expect bukannya unwrap dan ngasih pesan error yang bagus
bisa nyampein maksud kita dan bikin ngelacak sumber panic jadi lebih gampang.
Sintaks dari expect keliatan kayak gini:
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt")
.expect("hello.txt should be included in this project");
}Kita pake expect dengan cara yang sama kayak unwrap: buat balikin file
handle-nya atau manggil macro panic!. Pesan error yang dipake sama expect
di pemanggilan panic!-nya bakal jadi parameter yang kita masukin ke expect,
bukannya pesan panic! default yang dipake sama unwrap. Ini contoh outputnya:
thread 'main' panicked at src/main.rs:5:10:
hello.txt harusnya udah disertain di project ini: Os { code: 2, kind: NotFound, message: "No such file or directory" }
Di production-quality code (kode level produksi), kebanyakan Rustacean milih
expect daripada unwrap dan ngasih konteks lebih banyak soal kenapa operasi
itu diharapkan bakal selalu berhasil. Dengan gitu, kalau asumsi kita terbukti
salah, kita punya lebih banyak informasi yang bisa dipake pas debugging.
Ngelepar Balik Error (Propagating Errors)
Pas implementasi sebuah fungsi manggil sesuatu yang mungkin gagal, bukannya nanganin error-nya di dalem fungsi itu sendiri, kita bisa milih buat balikin error-nya ke kode yang manggil fungsi itu biar mereka yang mutusin mau ngapain. Ini dikenal sebagai propagating the error (ngelepar balik error) dan ngasih kontrol lebih banyak ke kode pemanggil, di mana mungkin ada lebih banyak informasi atau logika yang nentuin gimana error itu harus di-handle daripada apa yang tersedia di konteks fungsi kita.
Misalnya, Listing 9-6 nunjukin fungsi yang ngebaca username dari sebuah file. Kalau filenya nggak ada atau nggak bisa dibaca, fungsi ini bakal balikin error- error itu ke kode yang manggil fungsi ini.
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let username_file_result = File::open("hello.txt");
let mut username_file = match username_file_result {
Ok(file) => file,
Err(e) => return Err(e),
};
let mut username = String::new();
match username_file.read_to_string(&mut username) {
Ok(_) => Ok(username),
Err(e) => Err(e),
}
}
}matchFungsi ini sebenernya bisa ditulis pake cara yang jauh lebih pendek, tapi kita
bakal mulai dengan ngelakuinnya secara manual biar bisa eksplor cara nanganin
error; nanti di akhir, kita bakal tunjukin cara yang lebih singkat. Yuk kita
liat tipe kembalian (return type) dari fungsinya dulu:
Result<String, io::Error>. Ini artinya fungsinya balikin nilai dari tipe
Result<T, E>, di mana parameter generik T udah diisi pake tipe konkret
String dan tipe generik E udah diisi pake tipe konkret io::Error.
Kalau fungsinya berhasil tanpa masalah apa pun, kode yang manggil fungsi ini
bakal nerima nilai Ok yang nampung sebuah String—yaitu username yang
dibaca sama fungsi ini dari file. Kalau fungsi ini nemu masalah apa pun, kode
pemanggil bakal nerima nilai Err yang nampung instance dari io::Error yang
isinya informasi lebih lanjut soal masalahnya. Kita milih io::Error sebagai
tipe kembalian dari fungsi ini karena kebetulan itu adalah tipe dari nilai error
yang dibalikin dari kedua operasi yang lagi kita panggil di dalem body fungsi ini
yang mungkin gagal: yaitu fungsi File::open sama method read_to_string.
Body dari fungsi ini dimulai dengan manggil fungsi File::open. Terus kita
nanganin nilai Result-nya pake match yang mirip kayak match di Listing 9-4.
Kalau File::open berhasil, file handle di variabel pattern file bakal jadi
nilai di variabel mutable username_file dan fungsinya lanjut. Di kasus Err,
bukannya manggil panic!, kita pake keyword return buat balik (return)
lebih awal dari fungsi sepenuhnya dan ngelepar nilai error dari File::open,
yang sekarang ada di variabel pattern e, balik ke kode pemanggil sebagai
nilai error dari fungsi ini.
Jadi, kalau kita punya file handle di username_file, fungsinya terus bikin
String baru di variabel username terus manggil method read_to_string pada
file handle di username_file buat baca isi filenya ke dalem username.
Method read_to_string juga balikin sebuah Result karena dia bisa aja gagal,
walaupun File::open tadi udah berhasil. Jadi kita butuh match satu lagi
buat nanganin Result itu: kalau read_to_string berhasil, berarti fungsi
kita udah berhasil, dan kita balikin username dari filenya yang sekarang udah
ada di variabel username yang dibungkus di dalem sebuah Ok. Kalau
read_to_string gagal, kita balikin nilai error-nya pake cara yang sama kayak
kita balikin nilai error di dalem match yang nanganin nilai kembalian dari
File::open. Tapi, kita nggak perlu secara eksplisit bilang return, karena ini
adalah ekspresi terakhir di fungsinya.
Kode yang manggil fungsi ini nanti bakal dapet antara nilai Ok yang isinya
sebuah username atau nilai Err yang isinya sebuah io::Error. Terserah kode
pemanggilnya mau ngapain sama nilai-nilai itu. Kalau kode pemanggilnya dapet
nilai Err, dia bisa aja manggil panic! terus nge-crash-in programnya,
pake username default, atau nyari username dari tempat lain selain dari file,
misalnya. Kita nggak punya informasi yang cukup soal apa yang sebenernya lagi
dicoba lakuin sama kode pemanggil, jadi kita nge-lempar balik semua informasi
sukses atau error ke atas biar di-handle sama dia dengan bener.
Pola ngelepar balik error ini saking umumnya di Rust sampe Rust nyediain
operator tanda tanya ? buat bikin proses ini lebih gampang.
Jalan Pintas Buat Ngelepar Error: Operator ?
Listing 9-7 nunjukin implementasi dari read_username_from_file yang punya
fungsionalitas yang sama kayak di Listing 9-6, tapi implementasi ini pake
operator ?.
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let mut username_file = File::open("hello.txt")?;
let mut username = String::new();
username_file.read_to_string(&mut username)?;
Ok(username)
}
}?Tanda ? yang ditaruh setelah sebuah nilai Result itu didefinisikan buat
kerja dengan cara yang hampir persis sama kayak ekspresi match yang kita
definisikan buat nanganin nilai Result di Listing 9-6. Kalau nilai Result-nya
adalah Ok, nilai di dalem Ok-nya bakal dibalikin dari ekspresi ini, dan
programnya bakal lanjut. Kalau nilainya adalah Err, Err itu bakal dibalikin
dari keseluruhan fungsi seolah-olah kita udah pake keyword return, jadi nilai
error-nya bakal dilempar balik ke kode pemanggil.
Ada sedikit perbedaan antara apa yang dilakuin ekspresi match di Listing 9-6
sama apa yang dilakuin operator ?: nilai error yang dikenain operator ?
bakal ngelewatin fungsi from, yang didefinisikan di trait From di standard
library, yang dipake buat nge-convert nilai dari satu tipe ke tipe lainnya.
Pas operator ? manggil fungsi from, tipe error yang diterima bakal di-convert
jadi tipe error yang didefinisikan di tipe kembalian (return type) dari fungsi
saat ini. Ini sangat berguna pas sebuah fungsi balikin satu tipe error kustom
buat merepresentasikan semua kemungkinan cara fungsi itu bisa gagal, walaupun
bagian-bagian di dalemnya mungkin gagal karena banyak alasan yang beda.
Misalnya, kita bisa ngubah fungsi read_username_from_file di Listing 9-7 buat
balikin tipe error kustom namanya OurError yang kita definisikan sendiri. Kalau
kita juga mendefinisikan impl From<io::Error> for OurError buat ngonstruksi
sebuah instance dari OurError dari sebuah io::Error, maka pemanggilan
operator ? di dalem body read_username_from_file bakal manggil from dan
nge-convert tipe error-nya tanpa perlu nambahin kode lain lagi ke fungsinya.
Di konteks Listing 9-7, tanda ? di akhir pemanggilan File::open bakal
balikin nilai di dalem Ok ke variabel username_file. Kalau ada error yang
terjadi, operator ? bakal langsung keluar (return early) dari keseluruhan
fungsi dan ngasih nilai Err apa pun ke kode pemanggil. Hal yang sama juga
berlaku buat tanda ? di akhir pemanggilan read_to_string.
Operator ? ngilangin sangat banyak boilerplate code dan bikin implementasi
fungsi ini jadi lebih simpel. Kita bahkan bisa nyederhanain kode ini lebih
lanjut dengan nge-chaining (nyambungin) pemanggilan method langsung setelah ?,
kayak yang ditunjukin di Listing 9-8.
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let mut username = String::new();
File::open("hello.txt")?.read_to_string(&mut username)?;
Ok(username)
}
}?Kita udah mindahin pembuatan String baru di variabel username ke awal dari
fungsinya; bagian itu nggak berubah. Bukannya bikin variabel username_file,
kita nge-chaining pemanggilan read_to_string secara langsung ke hasil dari
File::open("hello.txt")?. Kita tetep punya tanda ? di akhir pemanggilan
read_to_string, dan kita tetep balikin nilai Ok yang nampung username
pas baik File::open maupun read_to_string berhasil, bukannya balikin
error-nya. Fungsionalitasnya tetep sama persis kayak di Listing 9-6 sama
Listing 9-7; ini cuma cara yang beda dan lebih ergonomis buat nulis kodenya.
Listing 9-9 nunjukin cara buat ngebikin ini jadi lebih singkat lagi pake
fs::read_to_string.
#![allow(unused)]
fn main() {
use std::fs;
use std::io;
fn read_username_from_file() -> Result<String, io::Error> {
fs::read_to_string("hello.txt")
}
}fs::read_to_string bukannya buka terus baca filenya secara manualBaca sebuah file jadi string itu operasi yang lumayan umum, jadi standard
library nyediain fungsi praktis fs::read_to_string yang buka filenya, bikin
String baru, baca isinya dari file, masukin isinya ke dalem String itu,
terus balikin nilai String-nya. Tentunya, kalau langsung pake
fs::read_to_string dari awal kita jadi nggak dapet kesempatan buat ngejelasin
semua penanganan error tadi, makanya kita bahas cara panjangnya dulu.
Di Mana Aja Operator ? Bisa Dipake
Operator ? cuma bisa dipake di fungsi-fungsi yang tipe kembaliannya (return
type) kompatibel (cocok) sama nilai di mana tanda ? itu dipake. Ini karena
operator ? didefinisikan buat ngelakuin early return (kembali lebih awal)
sebuah nilai keluar dari fungsi, sama kayak ekspresi match yang kita definisikan
di Listing 9-6. Di Listing 9-6, match-nya pake nilai Result, dan arm early
return-nya balikin nilai Err(e). Tipe kembalian dari fungsinya juga harus
berupa sebuah Result biar cocok sama return ini.
Di Listing 9-10, yuk kita liat error apa yang bakal kita dapet kalau kita nyoba
pake operator ? di dalem fungsi main yang punya tipe kembalian yang nggak
kompatibel sama tipe dari nilai di mana kita pake tanda ?.
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt")?;
}? di fungsi main yang balikin () nggak bakal bisa di-compile.Kode ini buka sebuah file, yang bisa aja gagal. Operator ? ngikutin nilai
Result yang dibalikin sama File::open, tapi fungsi main ini punya tipe
kembalian (), bukan Result. Pas kita nge-compile kode ini, kita bakal dapet
pesan error berikut:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
error[E0277]: the `?` operator can only be used in a function that returns `Result` or `Option` (or another type that implements `FromResidual`)
--> src/main.rs:4:48
|
3 | fn main() {
| --------- this function should return `Result` or `Option` to accept `?`
4 | let greeting_file = File::open("hello.txt")?;
| ^ cannot use the `?` operator in a function that returns `()`
|
help: consider adding return type
|
3 ~ fn main() -> Result<(), Box<dyn std::error::Error>> {
4 | let greeting_file = File::open("hello.txt")?;
5 + Ok(())
|
For more information about this error, try `rustc --explain E0277`.
error: could not compile `error-handling` (bin "error-handling") due to 1 previous error
Error ini nunjukin kalau kita cuma dibolehin pake operator ? di fungsi yang
balikin Result, Option, atau tipe lain yang mengimplementasikan FromResidual.
Buat benerin error-nya, kita punya dua pilihan. Pilihan pertama adalah ngubah
tipe kembalian dari fungsinya biar kompatibel sama nilai yang lagi kita
kenain operator ? selama kita nggak punya batasan yang ngelarang hal itu.
Pilihan lainnya adalah pake sebuah match atau salah satu dari method di
Result<T, E> buat nanganin nilai Result<T, E>-nya dengan cara apa pun yang
paling pas.
Pesan error-nya juga nyebutin kalau ? bisa dipake bareng nilai Option<T>
juga. Sama kayak pas pake ? di dalem Result, kita cuma bisa pake ? di
dalem Option di sebuah fungsi yang juga balikin sebuah Option. Perilaku
dari operator ? pas dipanggil di dalem sebuah Option<T> itu mirip sama
perilakunya pas dipanggil di dalem sebuah Result<T, E>: kalau nilainya adalah
None, nilai None bakal dibalikin lebih awal dari fungsi di titik itu. Kalau
nilainya adalah Some, nilai di dalem Some-nya bakal jadi nilai hasil dari
ekspresi tersebut, dan fungsinya lanjut jalan. Listing 9-11 punya contoh
sebuah fungsi yang nyari karakter terakhir dari baris pertama di dalem sebuah
teks.
fn last_char_of_first_line(text: &str) -> Option<char> {
text.lines().next()?.chars().last()
}
fn main() {
assert_eq!(
last_char_of_first_line("Hello, world\nHow are you today?"),
Some('d')
);
assert_eq!(last_char_of_first_line(""), None);
assert_eq!(last_char_of_first_line("\nhi"), None);
}? di nilai Option<T>Fungsi ini balikin Option<char> karena mungkin aja ada karakter di sana, tapi
mungkin juga nggak ada. Kode ini ngambil argumen string slice text terus
manggil method lines pada string tersebut, yang bakal balikin sebuah iterator
yang ngelewatin baris-baris di string-nya. Karena fungsi ini pengen nge-cek
baris pertamanya, dia manggil next pada iterator-nya buat dapet nilai pertama
dari iterator tersebut. Kalau text isinya string kosong, pemanggilan
next ini bakal balikin None, dan di kasus itu kita pake ? buat berhenti
terus balikin None dari last_char_of_first_line. Kalau text bukan string
kosong, next bakal balikin nilai Some yang nampung string slice dari
baris pertama di dalem text.
Tanda ? ngekstrak string slice itu, dan kita bisa manggil chars pada
string slice tersebut buat dapet iterator dari karakter-karakternya. Kita
tertarik sama karakter terakhir di baris pertama ini, jadi kita manggil last
buat balikin item terakhir di iterator-nya. Ini adalah sebuah Option karena
mungkin aja baris pertamanya itu string kosong; misalnya, kalau text dimulai
pake baris kosong tapi punya karakter di baris lainnya, kayak di "\nhi". Tapi,
kalau emang ada karakter terakhir di baris pertama, dia bakal dibalikin di dalem
varian Some. Operator ? di tengah-tengah itu ngasih kita cara yang ringkas
buat mengekspresikan logika ini, ngebolehin kita mengimplementasikan fungsi ini
di dalem satu baris aja. Kalau kita nggak bisa pake operator ? di dalem Option,
kita harus mengimplementasikan logika ini pake lebih banyak pemanggilan method
atau pake ekspresi match.
Perhatiin ya kalau kita bisa pake operator ? di dalem Result di sebuah fungsi
yang balikin Result, dan kita bisa pake operator ? di dalem Option di
sebuah fungsi yang balikin Option, tapi kita nggak bisa nyampur aduk. Operator
? nggak bakal otomatis nge-convert sebuah Result jadi sebuah Option atau
sebaliknya; di kasus kayak gitu, kita bisa pake method kayak ok pada Result
atau method ok_or pada Option buat ngelakuin proses konversi-nya secara
eksplisit.
Sejauh ini, semua fungsi main yang udah kita pake itu balikin (). Fungsi
main itu spesial karena dia adalah entry point dan exit point dari program
executable, dan ada batasan soal tipe kembaliannya apa aja yang dibolehin
biar programnya bisa jalan sesuai ekspektasi.
Untungnya, main juga bisa balikin Result<(), E>. Listing 9-12 punya kode dari
Listing 9-10, tapi kita udah ubah tipe kembalian dari main jadi
Result<(), Box<dyn Error>> dan nambahin nilai kembalian Ok(()) di akhirnya.
Kode ini sekarang bakal bisa di-compile.
use std::error::Error;
use std::fs::File;
fn main() -> Result<(), Box<dyn Error>> {
let greeting_file = File::open("hello.txt")?;
Ok(())
}main buat balikin Result<(), E> ngebolehin penggunaan operator ? pada nilai Result.Tipe Box<dyn Error> adalah sebuah trait object, yang bakal kita bahas di
“Menggunakan Trait Objects Yang Mengizinkan Nilai Dari Tipe Yang Beda-beda”
di Bab 18. Buat sekarang, kita bisa anggep Box<dyn Error> artinya “jenis error
apa pun.” Pake ? di dalem nilai Result di fungsi main yang punya tipe
error Box<dyn Error> itu dibolehin karena ini ngizinin nilai Err apa pun
buat dibalikin lebih awal. Walaupun body dari fungsi main ini cuma bakal pernah
balikin error bertipe std::io::Error, dengan nentuin Box<dyn Error>,
signature ini bakal tetep bener biarpun nanti ada lebih banyak kode yang
balikin error tipe lain yang ditambahin ke dalem body main.
Pas fungsi main balikin Result<(), E>, executable-nya bakal exit (keluar)
dengan nilai 0 kalau main balikin Ok(()) dan bakal exit dengan nilai selain
nol kalau main balikin nilai Err. Program executable yang ditulis dalam C
bakal balikin integer pas mereka exit: program yang berhasil bakal balikin
integer 0, dan program yang error bakal balikin integer selain 0. Rust juga
balikin integer dari program executable buat tetep kompatibel sama konvensi ini.
Fungsi main bisa balikin tipe apa pun yang mengimplementasikan trait
std::process::Termination, yang punya fungsi report yang
balikin sebuah ExitCode. Cek dokumentasi standard library buat info lebih
lanjut soal gimana cara mengimplementasikan trait Termination buat tipe kustom
kita sendiri.
Sekarang setelah kita bahas detail soal manggil panic! atau balikin Result,
yuk kita balik ke topik soal gimana cara mutusin mana yang pas buat dipake di
kasus yang mana.
Mending Pakai panic! atau Tidak?
Kapan Harus panic! dan Kapan Nggak
Terus gimana caranya kita mutusin kapan harus manggil panic! dan kapan harus
balikin Result? Pas kode panic, nggak ada cara buat pulih (recover). Kita
bisa aja manggil panic! buat situasi error apa pun, mau ada cara buat pulih
atau nggak, tapi kalau gitu kita jadi ngambil keputusan atas nama kode pemanggil
kalau situasinya emang nggak bisa dipulihin. Pas kita milih buat balikin nilai
Result, kita ngasih opsi ke kode pemanggil. Kode pemanggil bisa milih buat
nyoba pulih dengan cara yang pas buat situasinya, atau dia bisa mutusin kalau
nilai Err di kasus ini emang nggak bisa dipulihin, jadi dia bisa manggil
panic! dan ngerubah error recoverable kita jadi error unrecoverable.
Makanya, balikin Result itu pilihan default yang bagus pas kita lagi
mendefinisikan fungsi yang mungkin aja gagal.
Di situasi-situasi kayak ngasih contoh, kode prototipe, sama nulis test, lebih
pantes buat nulis kode yang bakal panic daripada balikin Result. Yuk kita
eksplor alasannya, terus bahas situasi-situasi di mana compiler nggak bisa
tau kalau kegagalan itu mustahil terjadi, tapi kita sebagai manusia tau. Bab ini
bakal ditutup pake beberapa panduan umum (guidelines) soal gimana cara mutusin
apakah harus panic di kode library atau nggak.
Contoh-contoh, Kode Prototipe, sama Tests
Pas kita lagi nulis contoh buat ngejelasin suatu konsep, masukin kode penanganan
error yang kuat (robust) malah bisa bikin contohnya jadi kurang jelas. Di dalam
contoh-contoh, udah dimaklumin kalau pemanggilan ke method kayak unwrap yang
bisa panic itu dimaksudkan sebagai placeholder (tempat pengganti) buat
gimana kita maunya aplikasi kita nanganin error, yang mana bisa beda-beda
tergantung dari apa yang lagi dilakuin sama sisa kode kita.
Sama halnya, method unwrap sama expect itu praktis sekali pas lagi
prototyping (bikin prototipe), sebelum kita siap mutusin gimana cara nanganin
error. Mereka ninggalin tanda yang jelas di kode kita buat pas kita udah siap
bikin program kita jadi lebih kuat (robust).
Kalau pemanggilan method gagal di dalem sebuah test, kita pasti mau seluruh
test-nya ikutan gagal, biarpun method itu bukan fungsionalitas yang lagi dites.
Karena panic! adalah cara sebuah test ditandain gagal, manggil unwrap atau
expect adalah hal yang bener-bener seharusnya dilakuin.
Kasus di mana Kita Punya Lebih Banyak Informasi daripada Compiler
Bakal pantes juga buat manggil expect pas kita punya logika lain yang mastiin
kalau Result-nya bakal punya nilai Ok, tapi logikanya bukan sesuatu yang
dipahamin sama compiler. Kita bakal tetep punya nilai Result yang harus
ditanganin: operasi apa pun yang lagi kita panggil secara umum tetep punya
kemungkinan buat gagal, biarpun itu mustahil terjadi secara logika di situasi
spesifik kita. Kalau kita bisa mastiin dengan nge-cek kodenya secara manual
kalau kita nggak bakal pernah dapet varian Err, itu sah-sah aja buat manggil
expect dan dokumentasiin alesan kenapa kita yakin kita nggak bakal pernah dapet
varian Err di dalem teks argumennya. Ini contohnya:
fn main() {
use std::net::IpAddr;
let home: IpAddr = "127.0.0.1"
.parse()
.expect("Hardcoded IP address should be valid");
}Kita bikin instance IpAddr dengan nge-parse (mengurai) sebuah hardcoded
string. Kita bisa liat kalau 127.0.0.1 itu alamat IP yang valid, jadi sah-sah
aja buat pake expect di sini. Tapi, punya hardcoded string yang valid nggak
ngubah tipe kembalian dari method parse: kita tetep dapet nilai Result, dan
compiler tetep bakal nyuruh kita nanganin Result-nya seolah-olah varian Err
itu mungkin terjadi karena compiler nggak cukup pinter buat ngeliat kalau
string ini bakal selalu jadi alamat IP yang valid. Kalau string alamat IP-nya
dateng dari user bukannya di-hardcode ke program dan makanya emang punya
kemungkinan gagal, kita pastinya mau nanganin Result-nya dengan cara yang
lebih kuat (robust) sebagai gantinya. Nyebutin asumsi kalau alamat IP ini di-
hardcode bakal ngingetin kita buat ngubah expect jadi kode penanganan error
yang lebih baik kalau, di masa depan, kita harus ngedapetin alamat IP dari
sumber lain.
Panduan buat Error Handling
Sangat disaranin buat bikin kode kita panic pas ada kemungkinan kode kita bisa berakhir di keadaan yang buruk (bad state). Di konteks ini, bad state adalah pas ada asumsi, jaminan, kontrak, atau invarian (aturan yang harus selalu benar) yang dilanggar, misalnya pas nilai yang nggak valid, nilai yang saling bertentangan, atau nilai yang ilang dimasukin ke kode kita—ditambah satu atau lebih dari hal- hal berikut:
- Bad state itu adalah sesuatu yang nggak diduga-duga, beda sama sesuatu yang kemungkinan bakal sesekali kejadian, kayak user masukin data pake format yang salah.
- Kode kita setelah titik ini harus ngandelin kalau dia nggak lagi di bad state itu, bukannya nge-cek masalah itu di tiap langkahnya.
- Nggak ada cara yang bagus buat nge-encode (nyimpen) informasi ini ke tipe- tipe yang kita pake. Kita bakal bahas contoh dari apa yang kita maksud di “Meng-encode Keadaan dan Perilaku sebagai Tipe” di Bab 18.
Kalau seseorang manggil kode kita terus ngasih nilai-nilai yang nggak masuk akal,
paling bener sih balikin sebuah error kalau bisa biar user dari library-nya
bisa mutusin apa yang mau mereka lakuin di kasus itu. Tapi, di kasus di mana
lanjut jalan bisa ngebahayain keamanan atau ngerusak, pilihan terbaik mungkin
adalah manggil panic! terus ngingetin orang yang pake library kita soal bug
di kode mereka biar mereka bisa benerin pas masa development (pengembangan).
Sama juga, panic! itu sering kali pas kalau kita lagi manggil kode eksternal
yang ada di luar kendali kita terus dia balikin invalid state yang nggak bisa
kita benerin.
Tapi, pas kegagalan emang udah di-ekspektasi, lebih pantes buat balikin sebuah
Result daripada manggil panic!. Contohnya kayak sebuah parser yang dikasih
data yang cacat formatnya (malformed) atau sebuah HTTP request yang balikin
status yang ngindikasikan kalau kita udah kena rate limit (batas batas frekuensi
permintaan). Di kasus-kasus ini, balikin Result nunjukin kalau kegagalan
adalah kemungkinan yang di-ekspektasi yang harus diputusin sama kode pemanggil
gimana cara nanganinnya.
Pas kode kita ngejalanin operasi yang bisa ngebahayain user kalau dipanggil
pake nilai-nilai yang nggak valid, kode kita harusnya nge-verifikasi kalau nilai-
nilainya valid dulu terus panic kalau ternyata nggak valid. Ini sebagian besar
karena alasan keamanan (safety): nyoba beroperasi pada data yang nggak valid
bisa nge-ekspos kode kita ke celah keamanan (vulnerabilities). Ini alasan utama
kenapa standard library bakal manggil panic! kalau kita nyoba akses memori
di luar batas (out-of-bounds): nyoba akses memori yang bukan milik struktur
data saat ini adalah masalah keamanan yang umum sekali. Fungsi-fungsi sering
kali punya contracts (kontrak): perilaku mereka cuma dijamin kalau inputnya
menuhin syarat tertentu. Panic pas kontrak dilanggar itu masuk akal karena
pelanggaran kontrak selalu ngindikasikan ada bug di pihak pemanggil (caller-side),
dan ini bukan jenis error yang kita mau kode pemanggil harus tangani secara
eksplisit. Malah, nggak ada cara yang masuk akal buat kode pemanggil buat bisa
pulih; si programmer yang bikin kode pemanggil harus benerin kodenya. Kontrak
buat sebuah fungsi, terutama pas ada pelanggaran yang bakal nyebabin panic,
harusnya dijelasin di dokumentasi API buat fungsi itu.
Tapi, punya sangat banyak pengecekan error di semua fungsi kita bakal panjang
sekali (verbose) dan nyebelin. Untungnya, kita bisa pake sistem tipe (type system)
Rust (dan karena itu dapet pengecekan tipe yang dilakuin sama compiler) buat
ngelakuin banyak pengecekan buat kita. Kalau fungsi kita nerima tipe tertentu
sebagai parameternya, kita bisa lanjut sama logika kode kita dengan tenang
karena tau compiler udah mastiin kalau kita punya nilai yang valid. Misalnya,
kalau kita nerima sebuah tipe bukannya sebuah Option, program kita berharap
dapet sesuatu bukannya nggak ada apa-apa. Kode kita terus nggak perlu
nanganin dua kasus buat varian Some sama None: dia cuma bakal punya satu
kasus di mana dia pasti dapet sebuah nilai. Kode yang nyoba masukin nggak ada
apa-apa ke fungsi kita bahkan nggak bakal bisa di-compile, jadi fungsi kita
nggak perlu nge-cek kasus itu pas runtime. Contoh lain adalah pake tipe integer
unsigned (nggak ada tanda minus) kayak u32, yang mastiin kalau parameternya
nggak bakal pernah negatif.
Bikin Tipe Kustom Buat Validasi
Yuk kita bawa ide pake sistem tipe Rust buat mastiin kita punya nilai yang valid satu langkah lebih jauh terus liat cara bikin tipe kustom buat validasi. Inget game tebak angka di Bab 2 di mana kode kita minta user buat nebak angka antara 1 sampe 100. Kita nggak pernah mevalidasi kalau tebakan user bener-bener ada di antara angka-angka itu sebelum kita bandingin sama angka rahasia kita; kita cuma mevalidasi kalau tebakannya itu positif. Di kasus ini, konsekuensinya nggak terlalu parah sih: output “Ketinggian” atau “Kerendahan” kita bakal tetep bener. Tapi ini bakal jadi peningkatan yang berguna buat mandu user ke arah tebakan yang valid dan punya perilaku yang beda pas user nebak angka di luar rentang versus pas user ngetik huruf, misalnya.
Salah satu cara buat ngelakuin ini adalah dengan nge-parse (mengurai) tebakannya
sebagai sebuah i32 bukannya cuma u32 buat ngebolehin angka yang potensial
negatif, terus nambahin pengecekan apakah angkanya ada di dalem rentang, kayak
gini:
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
// --snip--
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: i32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
if guess < 1 || guess > 100 {
println!("The secret number will be between 1 and 100.");
continue;
}
match guess.cmp(&secret_number) {
// --snip--
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Ekspresi if nge-cek apakah nilai kita ada di luar rentang, ngasih tau user
soal masalahnya, terus manggil continue buat mulai iterasi loop berikutnya
dan minta tebakan lain. Setelah ekspresi if, kita bisa lanjut sama perbandingan
antara guess sama angka rahasianya dengan tenang karena tau guess pasti di
antara 1 sampe 100.
Tapi, ini bukan solusi yang ideal: kalau bener-bener kritis sekali (absolutely critical) kalau programnya cuma beroperasi pada nilai di antara 1 sampe 100, dan program itu punya banyak fungsi dengan persyaratan ini, punya pengecekan kayak gini di tiap fungsi bakal ngebosenin dan repetitif sekali (dan mungkin ngaruh ke performa juga).
Sebagai gantinya, kita bisa bikin tipe baru di dalem modul yang didedikasikan
khusus dan naruh validasinya di dalem sebuah fungsi buat bikin instance dari
tipe itu bukannya ngulangin validasinya di mana-mana. Dengan gitu, bakal aman
buat fungsi-fungsi buat pake tipe baru ini di signature mereka dan pake nilai
yang mereka terima dengan pede. Listing 9-13 nunjukin salah satu cara buat
mendefinisikan tipe Guess yang cuma bakal bikin instance dari Guess kalau
fungsi new nerima nilai di antara 1 sampe 100.
#![allow(unused)]
fn main() {
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
pub fn value(&self) -> i32 {
self.value
}
}
}Guess yang cuma bakal lanjut kalau nilainya di antara 1 sampe 100Perhatiin ya kalau kode ini di src/guessing_game.rs bergantung sama penambahan
deklarasi modul mod guessing_game; di src/lib.rs yang belum kita tunjukin
di sini. Di dalem file modul baru ini, kita mendefinisikan sebuah struct namanya
Guess yang punya field namanya value yang nampung sebuah i32. Di sinilah
angkanya bakal disimpan.
Terus kita mengimplementasikan sebuah fungsi associated namanya new pada
Guess yang bertugas bikin instance-instance dari nilai Guess. Fungsi new
didefinisikan buat punya satu parameter namanya value dari tipe i32 dan
balikin sebuah Guess. Kode di body fungsi new ngetes value buat mastiin
kalau dia ada di antara 1 sampe 100. Kalau value nggak lolos tes ini, kita
manggil panic!, yang bakal ngingetin programmer yang nulis kode pemanggil
kalau mereka punya bug yang harus dibenerin, karena bikin sebuah Guess
dengan value di luar rentang ini bakal melanggar kontrak yang diandelin sama
Guess::new. Kondisi-kondisi di mana Guess::new mungkin bakal panic
harusnya didiskusikan di dokumentasi API yang ngadep public (public-facing API);
kita bakal ngebahas konvensi dokumentasi buat nunjukin kemungkinan panic! di
dokumentasi API yang kita bikin di Bab 14. Kalau value lolos tes, kita bikin
Guess baru dengan field value-nya di-set ke parameter value terus balikin
Guess-nya.
Selanjutnya, kita mengimplementasikan sebuah method namanya value yang minjem
(borrows) self, nggak punya parameter lain apa pun, dan balikin sebuah i32.
Tipe method kayak gini kadang disebut getter karena tujuannya adalah buat dapet
beberapa data dari field-nya terus balikin datanya. Method public ini dibutuhin
karena field value dari struct Guess itu private. Ini penting sekali biar
field value tetep private biar kode yang pake struct Guess nggak dibolehin
nge-set value secara langsung: kode di luar modul guessing_game harus pake
fungsi Guess::new buat bikin instance dari Guess, dan dengan gitu ngejamin
nggak ada cara buat sebuah Guess buat punya value yang belum dicek sama
kondisi di fungsi Guess::new.
Fungsi yang punya parameter atau balikin cuma angka di antara 1 sampe 100
kemudian bisa mendeklarasikan di signature-nya kalau dia nerima atau balikin
sebuah Guess bukannya sebuah i32 dan nggak perlu ngelakuin pengecekan
tambahan apa pun di body-nya.
Ringkasan
Fitur error-handling di Rust didesain buat ngebantu kita nulis kode yang
lebih kuat (robust). Macro panic! nandain kalau program kita ada di keadaan
yang dia nggak bisa tanganin dan ngasih kita cara buat nyuruh prosesnya buat
berhenti bukannya nyoba lanjut pake nilai yang nggak valid atau salah. Enum
Result pake sistem tipe Rust buat ngindikasikan kalau operasi bisa aja gagal
dengan cara yang kode kita bisa pulih (recover) darinya. Kita bisa pake Result
buat ngasih tau kode yang manggil kode kita kalau dia harus nanganin potensi
sukses atau gagal juga. Pake panic! sama Result di situasi yang pas bakal
bikin kode kita lebih bisa diandelin pas ngadepin masalah yang nggak bisa
dihindarin.
Sekarang setelah kita liat cara yang kepake sekali di mana standard library
pake generik bareng enum Option sama Result, kita bakal bahas gimana cara
kerja generik (generics) dan gimana kita bisa pakenya di kode kita.
Tipe Generik, Traits, dan Lifetimes
Setiap bahasa pemrograman punya tools buat menangani duplikasi konsep secara efektif. Di Rust, salah satu tool itu adalah generics (generik): pengganti abstrak buat tipe konkret atau properti lainnya. Kita bisa mengekspresikan perilaku dari generik atau gimana mereka berhubungan dengan generik lainnya tanpa perlu tau apa yang bakal menempati posisi mereka saat kode di-compile dan dijalankan.
Fungsi bisa menerima parameter dari suatu tipe generik, bukannya tipe konkret
seperti i32 atau String, dengan cara yang sama seperti mereka menerima
parameter dengan nilai yang belum diketahui untuk menjalankan kode yang sama di
beberapa nilai konkret. Sebenarnya, kita sudah memakai generik di Bab 6 dengan
Option<T>, di Bab 8 dengan Vec<T> dan HashMap<K, V>, serta di Bab 9
dengan Result<T, E>. Di bab ini, kita bakal eksplor gimana cara
mendefinisikan tipe, fungsi, dan method kita sendiri pakai generik!
Pertama-tama kita bakal mengulang gimana cara mengekstrak sebuah fungsi buat mengurangi duplikasi kode. Kemudian kita bakal memakai teknik yang sama buat bikin fungsi generik dari dua fungsi yang hanya berbeda di tipe parameternya. Kita juga bakal menjelaskan gimana cara memakai tipe generik di dalam definisi struct dan enum.
Setelah itu, kita bakal belajar gimana cara memakai traits untuk mendefinisikan perilaku dengan cara yang generik. Kita bisa menggabungkan traits dengan tipe generik untuk membatasi tipe generik agar cuma menerima tipe yang punya perilaku tertentu, dan tidak asal menerima tipe apa saja.
Terakhir, kita bakal membahas lifetimes: berbagai jenis generik yang memberi compiler informasi soal gimana referensi saling berhubungan. Lifetimes memungkinkan kita ngasih informasi yang cukup ke compiler soal borrowed values (nilai yang dipinjam) agar compiler bisa memastikan referensinya bakal valid di lebih banyak situasi yang tidak akan dia sanggup lakukan tanpa bantuan kita.
Menghapus Duplikasi dengan Mengekstrak Fungsi
Generik memungkinkan kita mengganti tipe spesifik pakai placeholder (tempat pengganti) yang mewakili banyak tipe buat menghilangkan duplikasi kode. Sebelum masuk ke sintaks generik, mari kita lihat dulu gimana cara menghilangkan duplikasi pakai cara yang tidak melibatkan tipe generik, yaitu dengan mengekstrak sebuah fungsi yang menggantikan nilai spesifik pakai placeholder yang mewakili banyak nilai. Habis itu, kita bakal menerapkan teknik yang sama buat mengekstrak fungsi generik! Dengan melihat gimana cara mengenali kode duplikat yang bisa diekstrak jadi sebuah fungsi, kita bakal mulai terbiasa mengenali kode duplikat yang bisa memakai generik.
Kita bakal mulai dari program pendek di Listing 10-1 yang mencari angka paling besar di dalam sebuah daftar (list).
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let mut largest = &number_list[0];
for number in &number_list {
if number > largest {
largest = number;
}
}
println!("The largest number is {largest}");
assert_eq!(*largest, 100);
}Kita menyimpan daftar integer di variabel number_list dan menaruh referensi
ke angka pertama di daftar itu di variabel bernama largest. Kemudian kita
iterasi melewati semua angka di daftar itu, dan kalau angka saat ini lebih
besar dari angka yang disimpan di largest, kita mengganti referensi di
variabel itu. Tapi, kalau angka saat ini lebih kecil atau sama dengan angka
paling besar yang dilihat sejauh ini, variabelnya tidak berubah, dan kodenya
lanjut ke angka berikutnya di daftar itu. Setelah memeriksa semua angka di
daftar, largest seharusnya merujuk ke angka paling besar, yang di kasus ini
adalah 100.
Sekarang kita dapat tugas buat mencari angka paling besar di dua daftar angka yang berbeda. Untuk melakukan itu, kita bisa memilih buat menduplikasi kode di Listing 10-1 lalu memakai logika yang sama di dua tempat yang berbeda di program, seperti yang ditunjukkan di Listing 10-2.
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let mut largest = &number_list[0];
for number in &number_list {
if number > largest {
largest = number;
}
}
println!("The largest number is {largest}");
let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8];
let mut largest = &number_list[0];
for number in &number_list {
if number > largest {
largest = number;
}
}
println!("The largest number is {largest}");
}Walaupun kode ini jalan, menduplikasi kode itu merepotkan dan rawan error. Kita juga harus ingat buat meng-update kodenya di banyak tempat kalau kita mau mengubahnya.
Buat menghilangkan duplikasi ini, kita bakal bikin abstraksi dengan mendefinisikan sebuah fungsi yang beroperasi pada daftar integer apa pun yang dimasukkan sebagai parameternya. Solusi ini bikin kode kita lebih jelas dan memungkinkan kita mengekspresikan konsep pencarian angka paling besar di sebuah daftar secara abstrak.
Di Listing 10-3, kita mengekstrak kode yang mencari angka paling besar ke dalam
fungsi bernama largest. Terus kita panggil fungsi itu buat mencari angka
paling besar di dua daftar dari Listing 10-2. Kita juga bisa memakai fungsi itu
di daftar nilai i32 lain yang mungkin kita punya di masa depan.
fn largest(list: &[i32]) -> &i32 {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {result}");
assert_eq!(*result, 100);
let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8];
let result = largest(&number_list);
println!("The largest number is {result}");
assert_eq!(*result, 6000);
}Fungsi largest punya parameter bernama list, yang mewakili slice konkret
apa pun dari nilai i32 yang mungkin kita masukkan ke fungsi tersebut. Hasilnya,
pas kita memanggil fungsinya, kodenya jalan di nilai-nilai spesifik yang kita
masukkan.
Sebagai ringkasan, ini langkah-langkah yang kita ambil buat ngubah kode dari Listing 10-2 jadi Listing 10-3:
- Kenali kode yang terduplikasi.
- Ekstrak kode yang terduplikasi ke dalam body fungsi, lalu tentukan input dan nilai kembalian dari kode itu di signature fungsinya.
- Update dua instance kode yang terduplikasi buat memanggil fungsinya sebagai gantinya.
Berikutnya, kita bakal pakai langkah-langkah yang sama ini dengan generik buat
mengurangi duplikasi kode. Sama seperti body fungsi yang bisa beroperasi di list
abstrak bukannya nilai spesifik, generik memungkinkan kode buat beroperasi di
tipe abstrak.
Misalnya, katakanlah kita punya dua fungsi: satu yang mencari item paling besar
di slice nilai i32 dan satu lagi yang mencari item paling besar di slice
nilai char. Gimana cara kita menghilangkan duplikasi itu? Mari kita cari tahu!
Tipe Data Generik
Tipe Data Generik
Kita memakai generik buat membuat definisi untuk item seperti signature fungsi atau struct, yang nantinya bisa kita pakai dengan berbagai macam tipe data konkret. Mari kita lihat dulu gimana cara mendefinisikan fungsi, struct, enum, dan method memakai generik. Setelah itu, kita bakal membahas gimana pengaruh generik terhadap performa kode.
Di Definisi Fungsi
Saat mendefinisikan fungsi yang memakai generik, kita menaruh generik itu di signature fungsi di tempat kita biasanya menentukan tipe data untuk parameter dan nilai kembalian. Melakukan hal ini bikin kode kita jadi lebih fleksibel dan memberikan lebih banyak fungsionalitas bagi pemanggil fungsi kita sekaligus mencegah duplikasi kode.
Melanjutkan fungsi largest kita, Listing 10-4 menunjukkan dua fungsi yang
keduanya mencari nilai paling besar di dalam sebuah slice. Kita bakal
menggabungkan kedua fungsi ini jadi satu fungsi tunggal yang memakai generik.
fn largest_i32(list: &[i32]) -> &i32 {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn largest_char(list: &[char]) -> &char {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest_i32(&number_list);
println!("The largest number is {result}");
assert_eq!(*result, 100);
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest_char(&char_list);
println!("The largest char is {result}");
assert_eq!(*result, 'y');
}Fungsi largest_i32 adalah fungsi yang kita ekstrak di Listing 10-3 untuk
mencari i32 paling besar di dalam slice. Fungsi largest_char mencari
char paling besar di dalam slice. Body fungsinya punya kode yang persis
sama, jadi mari kita hilangkan duplikasi ini dengan memperkenalkan parameter
tipe generik di satu fungsi tunggal.
Buat memparameterisasi tipe di fungsi tunggal yang baru, kita harus menamai
parameter tipenya, sama seperti kita menamai parameter nilai buat sebuah fungsi.
Kita bisa memakai identifier (nama) apa saja sebagai nama parameter tipe. Tapi
kita bakal memakai T karena, secara konvensi, nama parameter tipe di Rust itu
pendek, sering kali cuma satu huruf, dan konvensi penamaan tipe di Rust adalah
CamelCase. Singkatan dari type (tipe), T adalah pilihan default buat
kebanyakan programmer Rust.
Pas kita memakai sebuah parameter di dalam body fungsi, kita harus
mendeklarasikan nama parameter itu di signature agar compiler tau apa makna
nama tersebut. Demikian juga, pas kita memakai nama parameter tipe di signature
fungsi, kita harus mendeklarasikan nama parameter tipe itu sebelum memakainya.
Untuk mendefinisikan fungsi largest yang generik, kita menaruh deklarasi nama
tipe di dalam kurung sudut, <>, di antara nama fungsinya dan daftar parameternya,
seperti ini:
fn largest<T>(list: &[T]) -> &T {Kita ngebaca definisi ini sebagai: fungsi largest bersifat generik terhadap
suatu tipe T. Fungsi ini punya satu parameter bernama list, yang merupakan
sebuah slice berisi nilai bertipe T. Fungsi largest bakal mengembalikan
referensi ke nilai dengan tipe T yang sama.
Listing 10-5 menunjukkan definisi fungsi largest gabungan yang memakai tipe
data generik di signature-nya. Listing ini juga menunjukkan gimana kita bisa
memanggil fungsi tersebut baik dengan slice nilai i32 maupun nilai char.
Perhatikan bahwa kode ini belum bisa di-compile.
fn largest<T>(list: &[T]) -> &T {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {result}");
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("The largest char is {result}");
}largest yang memakai parameter tipe generik; kode ini belum bisa di-compileKalau kita men-compile kode ini sekarang, kita bakal dapat error ini:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0369]: binary operation `>` cannot be applied to type `&T`
--> src/main.rs:5:17
|
5 | if item > largest {
| ---- ^ ------- &T
| |
| &T
|
help: consider restricting type parameter `T` with trait `PartialOrd`
|
1 | fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> &T {
| ++++++++++++++++++++++
For more information about this error, try `rustc --explain E0369`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Teks bantuannya menyebutkan std::cmp::PartialOrd, yang mana itu adalah sebuah
trait, dan kita bakal membahas traits di bagian selanjutnya. Buat sekarang,
ketahuilah bahwa error ini menyatakan kalau body dari largest tidak bakal jalan
untuk semua tipe yang mungkin bakal mengisi T. Karena kita mau membandingkan
nilai-nilai bertipe T di dalam body-nya, kita cuma bisa memakai tipe-tipe
yang nilainya bisa diurutkan. Buat memungkinkan perbandingan, standard library
punya trait std::cmp::PartialOrd yang bisa kita implementasikan di tipe-tipe
tertentu (lihat Lampiran C buat info lebih lanjut soal trait ini). Buat
memperbaiki Listing 10-5, kita bisa mengikuti saran di teks bantuannya dan
membatasi tipe-tipe yang valid buat T hanya pada tipe-tipe yang
mengimplementasikan PartialOrd. Listing ini kemudian bakal bisa di-compile,
karena standard library mengimplementasikan PartialOrd buat i32 dan char.
Di Definisi Struct
Kita juga bisa mendefinisikan struct agar memakai parameter tipe generik di
satu atau lebih field-nya menggunakan sintaks <>. Listing 10-6 mendefinisikan
sebuah struct Point<T> buat menampung nilai koordinat x dan y dari tipe
apa pun.
struct Point<T> {
x: T,
y: T,
}
fn main() {
let integer = Point { x: 5, y: 10 };
let float = Point { x: 1.0, y: 4.0 };
}Point<T> yang menampung nilai x dan y bertipe TSintaks buat memakai generik di definisi struct itu mirip kayak yang dipakai di definisi fungsi. Pertama kita deklarasikan nama parameter tipenya di dalam kurung sudut persis setelah nama struct-nya. Kemudian kita pakai tipe generik itu di definisi struct-nya di tempat kita biasanya memasukkan tipe data konkret.
Perhatikan bahwa karena kita cuma pakai satu tipe generik buat mendefinisikan
Point<T>, definisi ini berarti struct Point<T> bersifat generik terhadap
suatu tipe T, dan field x serta y itu keduanya memiliki tipe yang sama
tersebut, tidak peduli apa tipe aslinya. Kalau kita bikin instance dari
Point<T> yang punya nilai dengan tipe yang berbeda, seperti di Listing 10-7,
kode kita tidak bakal bisa di-compile.
struct Point<T> {
x: T,
y: T,
}
fn main() {
let wont_work = Point { x: 5, y: 4.0 };
}x dan y harus punya tipe yang sama karena keduanya punya tipe data generik yang sama yaitu T.Di contoh ini, saat kita nge-assign nilai integer 5 ke x, kita memberitahu
compiler kalau tipe generik T bakal jadi integer untuk instance Point<T>
ini. Lalu saat kita memberikan 4.0 untuk y, yang mana sebelumnya kita
definisikan punya tipe yang sama dengan x, kita bakal dapat error ketidakcocokan
tipe (type mismatch) seperti ini:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0308]: mismatched types
--> src/main.rs:7:38
|
7 | let wont_work = Point { x: 5, y: 4.0 };
| ^^^ expected integer, found floating-point number
For more information about this error, try `rustc --explain E0308`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Buat mendefinisikan struct Point di mana x dan y keduanya adalah generik
tapi bisa punya tipe yang berbeda, kita bisa memakai banyak parameter tipe generik.
Misalnya, di Listing 10-8, kita mengubah definisi Point agar bersifat generik
terhadap tipe T dan U, di mana x bertipe T dan y bertipe U.
struct Point<T, U> {
x: T,
y: U,
}
fn main() {
let both_integer = Point { x: 5, y: 10 };
let both_float = Point { x: 1.0, y: 4.0 };
let integer_and_float = Point { x: 5, y: 4.0 };
}Point<T, U> yang generik terhadap dua tipe sehingga x dan y bisa menampung nilai dengan tipe yang berbedaSekarang semua instance dari Point yang ditunjukkan itu diperbolehkan! Kita
bisa memakai sebanyak apa pun parameter tipe generik di sebuah definisi, tapi
memakai lebih dari beberapa bakal bikin kode kita jadi susah dibaca. Kalau kita
merasa butuh banyak tipe generik di kode kita, itu bisa jadi pertanda kalau
kode kita butuh direstrukturisasi jadi bagian-bagian yang lebih kecil.
Di Definisi Enum
Sama seperti struct, kita bisa mendefinisikan enum buat menampung tipe
data generik di dalam variannya. Mari kita lihat lagi enum Option<T> yang
disediakan oleh standard library, yang kita pakai di Bab 6:
#![allow(unused)]
fn main() {
enum Option<T> {
Some(T),
None,
}
}Definisi ini seharusnya sekarang jadi lebih masuk akal. Seperti yang bisa kita
lihat, enum Option<T> bersifat generik terhadap tipe T dan punya dua varian:
Some, yang menampung satu nilai bertipe T, dan varian None yang tidak
menampung nilai apa pun. Dengan memakai enum Option<T>, kita bisa
mengekspresikan konsep abstrak dari nilai yang opsional (bisa ada isinya atau
tidak), dan karena Option<T> itu generik, kita bisa memakai abstraksi ini
apa pun tipe dari nilai opsional tersebut.
Enum juga bisa memakai banyak tipe generik. Definisi dari enum Result
yang kita pakai di Bab 9 adalah salah satu contohnya:
#![allow(unused)]
fn main() {
enum Result<T, E> {
Ok(T),
Err(E),
}
}Enum Result bersifat generik terhadap dua tipe, T dan E, dan punya dua
varian: Ok, yang menampung nilai bertipe T, dan Err, yang menampung nilai
bertipe E. Definisi ini membuatnya sangat nyaman untuk memakai enum Result
di mana pun kita punya operasi yang mungkin berhasil (mengembalikan nilai bertipe
T) atau gagal (mengembalikan error bertipe E). Kenyataannya, inilah yang kita
pakai buat membuka file di Listing 9-3, di mana T diisi dengan tipe
std::fs::File saat filenya berhasil dibuka dan E diisi dengan tipe
std::io::Error pas ada masalah saat membuka file tersebut.
Kalau kita mengenali situasi di kode kita di mana banyak definisi struct atau enum yang cuma berbeda di tipe nilai yang mereka tampung, kita bisa menghindari duplikasi dengan memakai tipe generik.
Di Definisi Method
Kita bisa mengimplementasikan method di struct dan enum (seperti yang kita
lakukan di Bab 5) dan memakai tipe generik di definisinya juga. Listing 10-9
menunjukkan struct Point<T> yang kita definisikan di Listing 10-6 dilengkapi
sebuah method bernama x yang diimplementasikan di atasnya.
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
fn main() {
let p = Point { x: 5, y: 10 };
println!("p.x = {}", p.x());
}x di struct Point<T> yang bakal mengembalikan referensi ke field x bertipe TDi sini, kita sudah mendefinisikan sebuah method bernama x pada Point<T>
yang mengembalikan referensi ke data di field x.
Perhatikan bahwa kita harus mendeklarasikan T persis setelah impl supaya kita
bisa memakai T buat menentukan kalau kita lagi mengimplementasikan method di
tipe Point<T>. Dengan mendeklarasikan T sebagai tipe generik setelah impl,
Rust bisa mengidentifikasi kalau tipe di dalam kurung sudut di Point itu adalah
tipe generik, bukan tipe konkret. Kita bisa saja memilih nama yang berbeda buat
parameter generik ini daripada parameter generik yang dideklarasikan di definisi
struct, tapi memakai nama yang sama adalah konvensi yang umum. Kalau kita menulis
method di dalam impl yang mendeklarasikan tipe generik, method itu bakal
didefinisikan pada instance tipe apa pun, tidak peduli tipe konkret apa yang
akhirnya menggantikan tipe generiknya.
Kita juga bisa ngasih batasan pada tipe generik saat mendefinisikan method
pada suatu tipe. Misalnya, kita bisa mengimplementasikan method hanya pada
instance Point<f32> saja bukannya pada instance Point<T> dengan tipe generik
apa pun. Di Listing 10-10 kita memakai tipe konkret f32, yang artinya kita
tidak mendeklarasikan tipe apa pun setelah impl.
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
impl Point<f32> {
fn distance_from_origin(&self) -> f32 {
(self.x.powi(2) + self.y.powi(2)).sqrt()
}
}
fn main() {
let p = Point { x: 5, y: 10 };
println!("p.x = {}", p.x());
}impl yang hanya berlaku buat struct dengan tipe konkret tertentu buat parameter tipe generik TKode ini berarti tipe Point<f32> bakal punya method distance_from_origin;
instance Point<T> lain di mana T bukan tipe f32 tidak bakal punya method
ini. Method ini mengukur seberapa jauh titik kita dari titik origin di
koordinat (0.0, 0.0) dan memakai operasi matematika yang hanya tersedia buat tipe
floating-point.
Parameter tipe generik di definisi struct tidak selalu sama dengan parameter
yang kita pakai di signature method pada struct yang sama. Listing 10-11
memakai tipe generik X1 dan Y1 buat struct Point serta X2 Y2 buat
signature method mixup buat bikin contohnya jadi lebih jelas. Method ini
bikin instance Point baru dengan nilai x dari Point yang mewakili self
(bertipe X1) dan nilai y dari Point yang di-pass masuk (bertipe Y2).
struct Point<X1, Y1> {
x: X1,
y: Y1,
}
impl<X1, Y1> Point<X1, Y1> {
fn mixup<X2, Y2>(self, other: Point<X2, Y2>) -> Point<X1, Y2> {
Point {
x: self.x,
y: other.y,
}
}
}
fn main() {
let p1 = Point { x: 5, y: 10.4 };
let p2 = Point { x: "Hello", y: 'c' };
let p3 = p1.mixup(p2);
println!("p3.x = {}, p3.y = {}", p3.x, p3.y);
}Di main, kita sudah mendefinisikan sebuah Point yang punya i32 buat x
(dengan nilai 5) dan f64 buat y (dengan nilai 10.4). Variabel p2
adalah struct Point yang punya string slice buat x (dengan nilai
"Hello") dan char buat y (dengan nilai c). Memanggil mixup pada p1
dengan argumen p2 bakal menghasilkan p3, yang bakal punya i32 buat x
karena x-nya datang dari p1. Variabel p3 bakal punya char buat y karena
y-nya datang dari p2. Pemanggilan macro println! bakal mencetak
p3.x = 5, p3.y = c.
Tujuan dari contoh ini adalah buat mendemonstrasikan situasi di mana beberapa
parameter generik dideklarasikan bersama impl dan beberapa lainnya dideklarasikan
bersama definisi method-nya. Di sini, parameter generik X1 dan Y1
dideklarasikan setelah impl karena mereka ditujukan buat definisi struct-nya.
Parameter generik X2 dan Y2 dideklarasikan setelah fn mixup karena mereka
cuma relevan buat method itu aja.
Performa Kode yang Memakai Generik
Kita mungkin bertanya-tanya apakah ada biaya performa saat runtime kalau kita pakai parameter tipe generik. Kabar baiknya adalah memakai tipe generik tidak bakal bikin program kita berjalan lebih lambat dibanding kalau kita memakai tipe konkret.
Rust mencapai ini dengan melakukan monomorphization pada kode yang memakai generik di saat compile time. Monomorphization adalah proses mengubah kode generik jadi kode spesifik dengan mengisi tipe-tipe konkret yang dipakai pas di-compile. Dalam proses ini, compiler melakukan hal kebalikan dari langkah- langkah yang kita ambil buat bikin fungsi generik di Listing 10-5: compiler melihat semua tempat di mana kode generik itu dipanggil dan menghasilkan kode buat tipe-tipe konkret tempat kode generik itu dipanggil.
Mari kita lihat gimana proses ini bekerja dengan menggunakan enum generik
Option<T> dari standard library:
#![allow(unused)]
fn main() {
let integer = Some(5);
let float = Some(5.0);
}Pas Rust men-compile kode ini, dia melakukan monomorphization. Selama proses
itu, compiler membaca nilai-nilai yang udah dipakai di instance Option<T>
dan mengenali dua jenis Option<T>: satu buat i32 dan satu lagi buat f64.
Oleh karena itu, dia memperluas definisi generik dari Option<T> jadi dua
definisi yang dikhususkan buat i32 dan f64, sehingga mengganti definisi
generik dengan yang spesifik.
Versi kode hasil monomorphization terlihat mirip seperti berikut (compiler sebenarnya memakai nama yang berbeda dari apa yang kita pakai di sini buat ilustrasi):
enum Option_i32 {
Some(i32),
None,
}
enum Option_f64 {
Some(f64),
None,
}
fn main() {
let integer = Option_i32::Some(5);
let float = Option_f64::Some(5.0);
}Generik Option<T> digantikan dengan definisi spesifik yang dibikin sama
compiler. Karena Rust men-compile kode generik jadi kode yang menentukan tipe
asli di masing-masing instance, kita tidak harus membayar biaya apa pun saat
runtime akibat pemakaian generik. Pas kodenya jalan, performanya sama persis
seperti kalau kita menduplikasi masing-masing definisi pakai tangan sendiri.
Proses monomorphization ini bikin generik di Rust jadi sangat efisien pas
runtime.
Mendefinisikan Perilaku Bersama Memakai Traits
Traits: Mendefinisikan Perilaku Bersama
Sebuah trait mendefinisikan fungsionalitas yang dimiliki suatu tipe tertentu dan bisa dibagikan (di-share) dengan tipe lainnya. Kita bisa memakai traits buat mendefinisikan perilaku bersama (shared behavior) secara abstrak. Kita bisa memakai trait bounds buat menentukan kalau sebuah tipe generik bisa berupa tipe apa pun asalkan punya perilaku tertentu.
Catatan: Traits itu mirip sama fitur yang sering disebut interfaces di bahasa pemrograman lain, walaupun ada beberapa perbedaan.
Mendefinisikan sebuah Trait
Perilaku dari sebuah tipe terdiri dari methods yang bisa kita panggil pada tipe tersebut. Berbagai tipe bisa berbagi perilaku yang sama kalau kita bisa memanggil methods yang sama pada semua tipe itu. Definisi trait adalah cara buat mengelompokkan method signatures (tanda tangan metode) bersama-sama untuk mendefinisikan sekumpulan perilaku yang dibutuhkan untuk mencapai suatu tujuan.
Misalnya, katakanlah kita punya beberapa struct yang menampung berbagai
macam dan jumlah teks: sebuah struct NewsArticle yang menampung berita di
lokasi tertentu dan sebuah SocialPost yang maksimal isinya 280 karakter
beserta metadata yang menunjukkan apakah itu postingan baru, di-repost,
atau balasan buat postingan lain.
Kita mau bikin library crate agregator media bernama aggregator yang bisa
nampilin ringkasan data yang mungkin disimpan di dalam instance NewsArticle
atau SocialPost. Untuk melakukan ini, kita butuh ringkasan dari tiap tipe,
dan kita bakal minta ringkasan itu dengan memanggil method summarize di
tiap instance-nya. Listing 10-12 menunjukkan definisi trait publik Summary
yang mengekspresikan perilaku ini.
pub trait Summary {
fn summarize(&self) -> String;
}Summary yang terdiri dari perilaku yang disediakan oleh method summarizeDi sini, kita mendeklarasikan sebuah trait memakai keyword trait lalu nama
trait-nya, yang mana adalah Summary di kasus ini. Kita juga mendeklarasikan
trait ini sebagai pub supaya crates yang bergantung pada crate ini
bisa memanfaatkan trait ini juga, seperti yang bakal kita lihat di beberapa
contoh nanti. Di dalam kurung kurawal, kita mendeklarasikan method signatures
yang menggambarkan perilaku tipe-tipe yang mengimplementasikan trait ini,
yang di kasus ini adalah fn summarize(&self) -> String.
Setelah method signature, bukannya ngasih implementasi di dalam kurung kurawal,
kita memakai titik koma. Tiap tipe yang mengimplementasikan trait ini harus
menyediakan perilaku khususnya sendiri buat body (isi) dari method ini.
Compiler bakal memastikan kalau tipe apa pun yang punya trait Summary
bakal punya method summarize yang didefinisikan dengan signature yang
persis sama kayak gini.
Sebuah trait bisa punya banyak method di dalamnya: method signatures didaftarkan satu baris satu, dan tiap baris diakhiri dengan titik koma.
Mengimplementasikan sebuah Trait pada suatu Tipe
Sekarang setelah kita mendefinisikan signatures yang diinginkan dari method
trait Summary, kita bisa mengimplementasikannya pada tipe-tipe di agregator
media kita. Listing 10-13 menunjukkan implementasi trait Summary pada
struct NewsArticle yang memakai judul (headline), penulis, dan lokasi buat
bikin nilai kembalian dari summarize. Buat struct SocialPost, kita
mendefinisikan summarize sebagai username diikuti sama seluruh teks postingannya,
dengan asumsi kalau konten postingan sudah dibatasi sampai 280 karakter.
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}Summary pada tipe NewsArticle dan SocialPostMengimplementasikan trait pada suatu tipe itu mirip dengan mengimplementasikan
method biasa. Bedanya adalah setelah impl, kita menaruh nama trait yang
mau kita implementasikan, lalu memakai keyword for, dan kemudian menentukan
nama tipe di mana kita mau mengimplementasikan trait tersebut. Di dalam blok
impl, kita menaruh method signatures yang sudah didefinisikan sama definisi
trait-nya. Alih-alih menambahkan titik koma setelah setiap signature, kita
memakai kurung kurawal dan mengisi isi method dengan perilaku spesifik yang
kita mau dari method trait tersebut untuk tipe khususnya.
Sekarang setelah library ini mengimplementasikan trait Summary pada
NewsArticle dan SocialPost, pengguna dari crate ini bisa memanggil
method dari trait tersebut pada instance NewsArticle dan SocialPost
dengan cara yang sama seperti memanggil method biasa. Bedanya cuma si pengguna
harus membawa trait tersebut ke dalam scope sekaligus membawa tipe-tipenya.
Ini contoh gimana sebuah binary crate bisa memakai library crate
aggregator kita:
use aggregator::{SocialPost, Summary};
fn main() {
let post = SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
};
println!("1 new post: {}", post.summarize());
}Kode ini bakal mencetak 1 new post: horse_ebooks: of course, as you probably already know, people.
Crates lain yang bergantung pada crate aggregator juga bisa membawa trait
Summary ke dalam scope untuk mengimplementasikan Summary di tipe mereka
sendiri. Satu batasan yang perlu dicatat adalah kita cuma bisa mengimplementasikan
sebuah trait pada suatu tipe kalau setidaknya trait-nya atau tipenya, atau
keduanya, berada di crate kita sendiri (local to our crate). Misalnya, kita
bisa mengimplementasikan trait dari standard library seperti Display
pada tipe kustom seperti SocialPost sebagai bagian dari fungsionalitas
crate aggregator kita karena tipe SocialPost itu ada di crate
aggregator kita. Kita juga bisa mengimplementasikan Summary pada Vec<T>
di crate aggregator kita karena trait Summary itu ada di crate
aggregator kita.
Tapi kita tidak bisa mengimplementasikan traits eksternal pada tipe eksternal.
Misalnya, kita tidak bisa mengimplementasikan trait Display pada Vec<T>
di dalam crate aggregator kita karena Display dan Vec<T> dua-duanya
didefinisikan di standard library dan bukan bagian dari crate aggregator
kita. Batasan ini adalah bagian dari properti yang disebut coherence
(koherensi), dan lebih spesifik lagi disebut orphan rule (aturan yatim piatu),
dinamai begitu karena tipe induknya tidak ada. Aturan ini memastikan kalau kode
milik orang lain tidak bisa merusak kode kita dan sebaliknya. Tanpa aturan ini,
dua crates bisa saja mengimplementasikan trait yang sama untuk tipe yang sama,
dan Rust tidak bakal tau implementasi mana yang harus dipakai.
Implementasi Default
Kadang-kadang akan berguna kalau kita punya perilaku default untuk beberapa atau semua method di sebuah trait daripada mewajibkan implementasi untuk semua method di setiap tipe. Dengan begitu, saat kita mengimplementasikan trait pada tipe tertentu, kita bisa tetap menyimpan atau menimpa (override) perilaku default dari tiap method.
Di Listing 10-14, kita menentukan string default buat method summarize
dari trait Summary alih-alih cuma mendefinisikan method signature-nya,
seperti yang kita lakukan di Listing 10-12.
pub trait Summary {
fn summarize(&self) -> String {
String::from("(Read more...)")
}
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}Summary dengan implementasi default buat method summarizeUntuk memakai implementasi default buat meringkas instance dari NewsArticle,
kita cukup menentukan blok impl yang kosong dengan
impl Summary for NewsArticle {}.
Meskipun kita tidak lagi mendefinisikan method summarize di NewsArticle
secara langsung, kita sudah menyediakan implementasi default dan menentukan
kalau NewsArticle mengimplementasikan trait Summary. Hasilnya, kita tetap
bisa memanggil method summarize pada instance NewsArticle, seperti ini:
use aggregator::{self, NewsArticle, Summary};
fn main() {
let article = NewsArticle {
headline: String::from("Penguins win the Stanley Cup Championship!"),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
};
println!("New article available! {}", article.summarize());
}Kode ini mencetak New article available! (Read more...).
Membuat implementasi default tidak mengharuskan kita untuk mengubah apa pun
dari implementasi Summary pada SocialPost di Listing 10-13. Alasannya adalah
sintaks buat menimpa implementasi default itu persis sama kayak sintaks buat
mengimplementasikan method trait yang tidak punya implementasi default.
Implementasi default bisa memanggil method lain di trait yang sama,
bahkan kalau method lain itu tidak punya implementasi default. Dengan cara
ini, sebuah trait bisa menyediakan banyak fungsionalitas berguna dan cuma
mewajibkan si peng-implementasi buat menentukan sebagian kecil saja. Misalnya,
kita bisa mendefinisikan trait Summary agar punya method summarize_author
yang implementasinya wajib, lalu mendefinisikan method summarize yang
punya implementasi default yang memanggil method summarize_author:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}Untuk memakai versi Summary ini, kita cuma perlu mendefinisikan
summarize_author pas kita mengimplementasikan trait-nya pada sebuah tipe:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}Setelah kita mendefinisikan summarize_author, kita bisa memanggil summarize
pada instance dari struct SocialPost, dan implementasi default dari
summarize bakal memanggil definisi summarize_author yang sudah kita sediakan.
Karena kita sudah mengimplementasikan summarize_author, trait Summary
sudah ngasih kita perilaku dari method summarize tanpa mengharuskan kita
menulis kode tambahan lagi. Berikut contoh pemakaiannya:
use aggregator::{self, SocialPost, Summary};
fn main() {
let post = SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
};
println!("1 new post: {}", post.summarize());
}Kode ini mencetak 1 new post: (Read more from @horse_ebooks...).
Perhatikan kalau tidak mungkin untuk memanggil implementasi default dari dalam implementasi yang lagi menimpa (overriding) method yang sama.
Traits sebagai Parameter
Sekarang setelah kita tahu cara mendefinisikan dan mengimplementasikan traits,
kita bisa eksplor gimana cara memakai traits buat mendefinisikan fungsi yang
bisa menerima berbagai macam tipe. Kita bakal memakai trait Summary yang
sudah kita implementasikan di tipe NewsArticle dan SocialPost di Listing
10-13 untuk mendefinisikan fungsi notify yang memanggil method summarize
pada parameter item-nya, yang bertipe apa pun selama tipe itu
mengimplementasikan trait Summary. Buat melakukannya, kita memakai sintaks
impl Trait, seperti ini:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
pub fn notify(item: &impl Summary) {
println!("Breaking news! {}", item.summarize());
}Alih-alih tipe konkret buat parameter item, kita memakai keyword impl
bersama dengan nama trait-nya. Parameter ini bakal menerima tipe apa pun yang
mengimplementasikan trait yang ditentukan. Di dalam body dari notify,
kita bisa memanggil method apa pun pada item yang asalnya dari trait
Summary, contohnya summarize. Kita bisa memanggil notify dan memberikan
instance apa pun dari NewsArticle atau SocialPost. Kode yang memanggil
fungsi tersebut dengan tipe lain, misalnya String atau i32, tidak bakal bisa
di-compile karena tipe-tipe tersebut tidak mengimplementasikan Summary.
Sintaks Trait Bound
Sintaks impl Trait memang praktis buat kasus-kasus sederhana tapi sebenarnya
itu cuma syntax sugar (sintaks pemanis) dari bentuk yang lebih panjang yang
dikenal sebagai trait bound; bentuknya kayak gini:
pub fn notify<T: Summary>(item: &T) {
println!("Breaking news! {}", item.summarize());
}Bentuk yang lebih panjang ini ekuivalen (sama) dengan contoh di bagian
sebelumnya, tapi lebih panjang (verbose). Kita menaruh trait bounds
bersamaan dengan deklarasi parameter tipe generik setelah tanda titik dua (:)
dan di dalam kurung sudut.
Sintaks impl Trait itu nyaman dan bikin kode lebih ringkas buat kasus-kasus
sederhana, sementara sintaks trait bound yang lebih lengkap bisa
mengekspresikan lebih banyak kerumitan buat kasus lain. Misalnya, kita bisa punya
dua parameter yang dua-duanya mengimplementasikan Summary. Kalau pakai sintaks
impl Trait, bentuknya bakal seperti ini:
pub fn notify(item1: &impl Summary, item2: &impl Summary) {Memakai impl Trait cocok kalau kita mau fungsi ini mengizinkan item1 dan
item2 untuk punya tipe yang berbeda (asalkan dua-duanya mengimplementasikan
Summary). Tapi, kalau kita mau memaksa kedua parameter tersebut buat punya
tipe yang sama persis, kita harus memakai trait bound, seperti ini:
pub fn notify<T: Summary>(item1: &T, item2: &T) {Tipe generik T yang ditentukan sebagai tipe dari parameter item1 dan item2
membatasi fungsi ini sehingga tipe konkret dari nilai yang diberikan buat argumen
item1 dan item2 itu harus sama.
Menentukan Beberapa Trait Bounds dengan Sintaks +
Kita juga bisa menentukan lebih dari satu trait bound. Katakanlah kita mau
notify bisa memakai display formatting di samping memanggil summarize
pada item: kita tentukan di definisi notify kalau item harus
mengimplementasikan Display sekaligus Summary. Kita bisa melakukannya
menggunakan sintaks +:
pub fn notify(item: &(impl Summary + Display)) {Sintaks + ini juga valid buat dipakai sama trait bounds pada tipe generik:
pub fn notify<T: Summary + Display>(item: &T) {Dengan dua trait bounds yang ditentukan, body dari notify bisa memanggil
summarize dan juga memakai {} buat memformat item.
Trait Bounds yang Lebih Rapi pake Klausa where
Memakai terlalu banyak trait bounds ada sisi negatifnya. Masing-masing generik
punya trait bounds-nya sendiri, jadi fungsi dengan banyak parameter tipe generik
bisa mengandung sangat banyak informasi trait bound di antara nama fungsi dan
daftar parameternya, yang mana bisa bikin signature fungsinya jadi susah
dibaca. Karena alasan ini, Rust punya sintaks alternatif buat menentukan
trait bounds di dalam sebuah klausa where setelah signature fungsinya.
Jadi, alih-alih nulis begini:
fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {kita bisa pakai klausa where, kayak gini:
fn some_function<T, U>(t: &T, u: &U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
unimplemented!()
}Signature fungsinya jadi tidak terlalu penuh: nama fungsi, daftar parameter, dan tipe kembalian semuanya berdekatan, mirip seperti fungsi yang tidak punya banyak trait bounds.
Mengembalikan Tipe yang Mengimplementasikan Traits
Kita juga bisa memakai sintaks impl Trait di posisi kembalian (return position)
buat mengembalikan nilai dari suatu tipe yang mengimplementasikan sebuah trait,
kayak gini:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable() -> impl Summary {
SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
}
}Dengan memakai impl Summary buat tipe kembaliannya, kita menentukan kalau
fungsi returns_summarizable bakal mengembalikan suatu tipe yang
mengimplementasikan trait Summary tanpa harus menyebut nama tipe konkretnya.
Di kasus ini, returns_summarizable mengembalikan sebuah SocialPost, tapi
kode yang memanggil fungsi ini tidak perlu tau soal itu.
Kemampuan buat menentukan tipe kembalian hanya berdasarkan trait yang
diimplementasikannya itu sangat berguna, apalagi di konteks closures dan
iterators, yang bakal kita bahas di Bab 13. Closures dan iterators bikin
tipe-tipe yang cuma compiler doang yang tau, atau tipe-tipe yang namanya
kepanjangan buat ditulis. Sintaks impl Trait memudahkan kita menentukan secara
ringkas kalau sebuah fungsi mengembalikan tipe tertentu yang mengimplementasikan
trait Iterator tanpa perlu nulis tipe yang kepanjangan.
Tapi, kita cuma bisa memakai impl Trait kalau kita mengembalikan satu tipe
tunggal. Misalnya, kode ini, yang mengembalikan entah NewsArticle atau
SocialPost dengan tipe kembalian impl Summary, tidak bakal bisa jalan:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable(switch: bool) -> impl Summary {
if switch {
NewsArticle {
headline: String::from(
"Penguins win the Stanley Cup Championship!",
),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
}
} else {
SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
}
}
}Mengembalikan entah NewsArticle atau SocialPost itu tidak diperbolehkan
karena adanya batasan dari gimana sintaks impl Trait diimplementasikan di
dalam compiler. Kita bakal bahas gimana cara nulis fungsi dengan perilaku
kayak gini di bagian “Memakai Trait Objects yang Mengizinkan Nilai Dari
Tipe yang Berbeda-beda”
di Bab 18.
Memakai Trait Bounds Buat Mengimplementasikan Method secara Bersyarat
Dengan memakai trait bound bareng sebuah blok impl yang memakai parameter
tipe generik, kita bisa mengimplementasikan methods secara bersyarat
(conditionally) buat tipe-tipe yang mengimplementasikan traits yang ditentukan.
Misalnya, tipe Pair<T> di Listing 10-15 selalu mengimplementasikan fungsi new
buat mengembalikan instance baru dari Pair<T> (ingat dari bagian
“Mendefinisikan Methods” di Bab 5 bahwa Self adalah alias tipe buat
tipe dari blok impl-nya, yang mana di kasus ini adalah Pair<T>). Tapi di
blok impl berikutnya, Pair<T> cuma mengimplementasikan method
cmp_display kalau tipe di dalamnya T mengimplementasikan trait
PartialOrd (yang memungkinkan perbandingan) dan trait Display (yang
memungkinkan untuk dicetak).
use std::fmt::Display;
struct Pair<T> {
x: T,
y: T,
}
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {}", self.x);
} else {
println!("The largest member is y = {}", self.y);
}
}
}Kita juga bisa mengimplementasikan secara bersyarat sebuah trait buat tipe apa
pun yang mengimplementasikan trait lain. Implementasi sebuah trait pada
tipe apa pun yang memenuhi trait bounds-nya disebut sebagai blanket
implementations (implementasi selimut) dan ini sangat banyak dipakai di standard
library Rust. Misalnya, standard library mengimplementasikan trait ToString
pada tipe apa pun yang mengimplementasikan trait Display. Blok impl di
standard library keliatan mirip kayak kode ini:
impl<T: Display> ToString for T {
// --snip--
}Karena standard library punya blanket implementation ini, kita bisa
memanggil method to_string yang didefinisikan sama trait ToString
pada tipe apa pun yang mengimplementasikan trait Display. Misalnya, kita bisa
mengubah integer jadi nilai String miliknya seperti ini karena integer
mengimplementasikan Display:
#![allow(unused)]
fn main() {
let s = 3.to_string();
}Blanket implementations ini biasanya muncul di dokumentasi buat suatu trait di bagian “Implementors”.
Traits dan trait bounds memungkinkan kita nulis kode yang memakai parameter tipe generik untuk mengurangi duplikasi, sekaligus ngasih tau compiler kalau kita maunya tipe generik itu punya perilaku tertentu. Compiler kemudian bakal memakai informasi trait bound tersebut buat mengecek apakah semua tipe konkret yang dipakai di kode kita sudah menyediakan perilaku yang benar. Di bahasa pemrograman yang dynamically typed (tipe dinamis), kita bakal dapat error pas runtime kalau kita memanggil method di suatu tipe yang sebenarnya tidak punya definisi method tersebut. Tapi Rust mindahin error-error ini ke fase compile time jadi kita dipaksa buat membenarkan masalah ini sebelum kode kita bahkan bisa dijalankan. Sebagai bonus, kita tidak perlu nulis kode buat ngecek perilaku saat runtime karena kita sudah mengeceknya pas compile time. Melakukan ini bakal meningkatkan performa tanpa harus mengorbankan fleksibilitas dari generik.
Validasi Referensi Memakai Lifetimes
Memvalidasi Referensi dengan Lifetimes
Lifetimes (waktu hidup) adalah jenis generik lain yang sebenarnya sudah kita pakai. Bukannya memastikan kalau sebuah tipe punya perilaku yang kita mau, lifetimes memastikan kalau referensi bakal tetap valid selama kita masih butuh.
Satu detail yang tidak kita bahas di bagian “Referensi dan Borrowing” di Bab 4 adalah setiap referensi di Rust punya sebuah lifetime, yaitu scope di mana referensi itu valid. Sebagian besar waktu, lifetimes itu bersifat implisit dan ditebak (inferred), sama halnya kayak sebagian besar waktu tipe juga ditebak. Kita baru diwajibkan buat menganotasi tipe kalau ada beberapa kemungkinan tipe yang bisa dipakai. Mirip dengan itu, kita harus menganotasi lifetimes kalau lifetimes dari referensi-referensi yang ada bisa berhubungan dengan beberapa cara yang berbeda. Rust mewajibkan kita menganotasi hubungan ini memakai parameter lifetime generik untuk memastikan referensi sebenarnya yang dipakai pas runtime bakal pasti valid.
Menganotasi lifetimes bahkan bukan konsep yang dimiliki kebanyakan bahasa pemrograman lain, jadi ini mungkin bakal terasa asing. Meskipun kita tidak bakal membahas lifetimes secara menyeluruh di bab ini, kita bakal membahas cara-cara umum yang mungkin bakal kita temui terkait sintaks lifetime supaya kita bisa nyaman dengan konsepnya.
Mencegah Dangling References dengan Lifetimes
Tujuan utama dari lifetimes adalah buat mencegah dangling references (referensi menggantung), yang bikin program merujuk ke data yang salah alih- alih data yang sebenarnya dituju. Coba perhatikan program di Listing 10-16, yang punya scope luar dan scope dalam.
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {r}");
}Catatan: Contoh di Listing 10-16, 10-17, dan 10-23 mendeklarasikan variabel tanpa memberi mereka nilai awal, jadi nama variabelnya eksis di scope luar. Sekilas, ini mungkin kelihatannya bertentangan sama aturan Rust yang tidak mengizinkan nilai null. Tapi, kalau kita mencoba memakai sebuah variabel sebelum memberinya nilai, kita bakal dapat error compile-time, yang menunjukkan kalau Rust memang tidak mengizinkan nilai null.
Scope luar mendeklarasikan variabel bernama r tanpa nilai awal, dan
scope dalam mendeklarasikan variabel bernama x dengan nilai awal 5. Di
dalam scope dalam, kita mencoba nge-set nilai r jadi referensi ke x.
Kemudian scope dalamnya berakhir, dan kita mencoba mencetak nilai di r.
Kode ini tidak bakal bisa di-compile karena nilai yang dirujuk sama r sudah
keluar dari scope sebelum kita mencoba memakainya. Ini pesan error-nya:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `x` does not live long enough
--> src/main.rs:6:13
|
5 | let x = 5;
| - binding `x` declared here
6 | r = &x;
| ^^ borrowed value does not live long enough
7 | }
| - `x` dropped here while still borrowed
8 |
9 | println!("r: {r}");
| - borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Pesan error-nya bilang kalau variabel x “tidak hidup cukup lama” (does not live long enough).
Alasannya adalah x bakal keluar dari scope saat scope dalam berakhir di
baris 7. Tapi r masih valid untuk scope luar; karena scope-nya lebih
besar, kita bilang kalau dia “hidup lebih lama.” Kalau Rust membiarkan kode ini
jalan, r bakal merujuk ke memori yang sudah di-dealokasi saat x keluar dari
scope, dan apa pun yang kita coba lakukan dengan r tidak bakal jalan dengan
benar. Terus gimana caranya Rust bisa nentuin kalau kode ini tidak valid? Rust
memakai sebuah borrow checker.
Borrow Checker
Compiler Rust punya sebuah borrow checker yang membandingkan scopes buat menentukan apakah semua referensi yang dipinjam (borrows) itu valid. Listing 10-17 menunjukkan kode yang sama seperti Listing 10-16 tapi dengan anotasi yang menunjukkan lifetimes dari variabel-variabelnya.
fn main() {
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {r}"); // |
} // ---------+r dan x, dinamakan masing-masing 'a dan 'bDi sini, kita sudah menganotasi lifetime dari r dengan 'a dan lifetime
dari x dengan 'b. Seperti yang bisa dilihat, blok 'b di dalam itu jauh
lebih kecil daripada blok lifetime 'a di luar. Pada saat compile time, Rust
membandingkan ukuran dari dua lifetimes ini dan melihat kalau r punya
lifetime 'a tapi dia merujuk ke memori dengan lifetime 'b. Programnya
ditolak karena 'b lebih pendek dari 'a: subjek yang dirujuk tidak hidup
selama referensinya.
Listing 10-18 memperbaiki kodenya biar dia tidak punya dangling reference dan bisa di-compile tanpa error sama sekali.
fn main() {
let x = 5; // ----------+-- 'b
// |
let r = &x; // --+-- 'a |
// | |
println!("r: {r}"); // | |
// --+ |
} // ----------+Di sini, x punya lifetime 'b, yang mana di kasus ini lebih besar dari 'a.
Ini berarti r bisa merujuk ke x karena Rust tahu kalau referensi di r bakal
selalu valid selama x masih valid.
Sekarang setelah kita tahu di mana lifetimes dari referensi berada dan gimana Rust menganalisis lifetimes buat memastikan referensi bakal selalu valid, mari kita eksplor lifetimes generik buat parameter dan nilai kembalian di dalam konteks fungsi.
Generic Lifetimes di Fungsi
Kita bakal nulis fungsi yang mengembalikan string slice yang lebih panjang
di antara dua string slice. Fungsi ini bakal menerima dua string slice dan
mengembalikan satu string slice. Setelah kita mengimplementasikan fungsi longest,
kode di Listing 10-19 seharusnya mencetak The longest string is abcd.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}main yang memanggil fungsi longest buat mencari mana yang lebih panjang dari dua string slicesPerhatikan bahwa kita mau fungsi ini menerima string slices, yang merupakan
referensi, bukannya strings, karena kita tidak mau fungsi longest mengambil
ownership dari parameter-parameternya. Coba cek lagi bagian “String Slices
sebagai Parameter” di Bab 4 buat pembahasan lebih
lanjut soal kenapa parameter yang kita pakai di Listing 10-19 adalah yang memang
kita perlukan.
Kalau kita mencoba mengimplementasikan fungsi longest seperti yang ditunjukkan
di Listing 10-20, kode ini tidak bakal bisa di-compile.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() { x } else { y }
}longest yang mengembalikan yang lebih panjang dari dua string slices tapi belum bisa di-compileAlih-alih jalan, kita dapat error berikut yang membahas soal lifetimes:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0106]: missing lifetime specifier
--> src/main.rs:9:33
|
9 | fn longest(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
help: consider introducing a named lifetime parameter
|
9 | fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Teks bantuannya ngasih tau kalau tipe kembaliannya butuh parameter lifetime
generik di situ karena Rust tidak bisa menebak apakah referensi yang bakal
dikembalikan itu merujuk ke x atau ke y. Nyatanya, kita juga tidak tahu,
karena blok if di dalam body fungsi ini mengembalikan referensi ke x dan
blok else mengembalikan referensi ke y!
Saat mendefinisikan fungsi ini, kita tidak tahu nilai konkret apa yang bakal
dimasukkan ke fungsi ini, jadi kita tidak tahu apakah blok if atau blok else
yang bakal dijalankan. Kita juga tidak tahu lifetimes konkret dari referensi
yang bakal dimasukkan, jadi kita tidak bisa melihat scopes seperti yang kita
lakukan di Listing 10-17 dan 10-18 untuk menentukan apakah referensi yang kita
kembalikan itu bakal selalu valid. Borrow checker juga tidak bisa menentukannya,
karena dia tidak tahu gimana lifetimes dari x dan y berhubungan sama
lifetime dari nilai kembaliannya. Buat membenarkan error ini, kita bakal
menambahkan parameter lifetime generik yang mendefinisikan hubungan antara
referensi-referensi tersebut agar borrow checker bisa melakukan analisisnya.
Sintaks Anotasi Lifetime
Anotasi lifetime tidak mengubah seberapa lama suatu referensi hidup. Mereka justru menggambarkan hubungan dari lifetimes antara banyak referensi satu sama lain tanpa memengaruhi lifetimes itu sendiri. Sama seperti fungsi yang bisa menerima tipe apa pun saat signature-nya menentukan parameter tipe generik, fungsi juga bisa menerima referensi dengan lifetime apa pun dengan menentukan parameter lifetime generik.
Anotasi lifetime punya sintaks yang agak tidak biasa: nama parameter lifetime
harus dimulai dengan apostrof (tanda kutip tunggal, ') dan biasanya semuanya
huruf kecil dan sangat pendek, sama seperti tipe generik. Kebanyakan orang
memakai nama 'a untuk anotasi lifetime yang pertama. Kita menaruh anotasi
parameter lifetime setelah tanda & dari sebuah referensi, dengan memakai
spasi untuk memisahkan anotasinya dari tipe referensinya.
Ini beberapa contohnya: sebuah referensi ke i32 tanpa parameter lifetime,
sebuah referensi ke i32 yang punya parameter lifetime bernama 'a, dan
sebuah referensi mutable ke i32 yang juga punya lifetime 'a.
&i32 // sebuah referensi
&'a i32 // sebuah referensi dengan _lifetime_ eksplisit
&'a mut i32 // sebuah referensi _mutable_ dengan _lifetime_ eksplisitSatu anotasi lifetime yang berdiri sendiri tidak punya banyak arti karena
anotasi itu ditujukan untuk memberi tahu Rust gimana parameter lifetime generik
dari berbagai referensi saling berhubungan. Mari kita teliti gimana anotasi
lifetime berhubungan satu sama lain di dalam konteks fungsi longest.
Anotasi Lifetime di Signature Fungsi
Buat memakai anotasi lifetime di signature fungsi, kita harus mendeklarasikan parameter lifetime generik di dalam kurung sudut di antara nama fungsi dan daftar parameter, sama persis seperti yang kita lakukan sama parameter tipe generik.
Kita mau signature ini mengekspresikan batasan ini: referensi yang
dikembalikan bakal valid setidaknya selama kedua parameter itu juga valid. Ini
adalah hubungan antara lifetimes dari parameter dan nilai kembaliannya.
Kita bakal menamakan lifetime itu 'a lalu menambahkannya ke setiap
referensi, seperti yang ditunjukkan di Listing 10-21.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}longest yang menentukan kalau semua referensi di signature tersebut harus punya lifetime 'a yang samaKode ini seharusnya bisa di-compile dan menghasilkan hasil yang kita inginkan
saat kita memakainya bersama fungsi main di Listing 10-19.
Signature fungsinya sekarang memberi tahu Rust bahwa untuk suatu lifetime
'a, fungsi ini menerima dua parameter, di mana keduanya adalah string slices
yang hidup setidaknya sepanjang lifetime 'a. Signature fungsinya juga
memberi tahu Rust bahwa string slice yang dikembalikan dari fungsi itu bakal
hidup setidaknya sepanjang lifetime 'a. Di praktiknya, ini berarti lifetime
dari referensi yang dikembalikan oleh fungsi longest itu sama dengan
lifetime yang paling kecil dari antara nilai-nilai yang dirujuk oleh
argumen-argumen fungsi tersebut. Hubungan-hubungan inilah yang kita mau Rust
pakai saat menganalisis kode ini.
Ingat, saat kita menentukan parameter lifetime di signature fungsi ini, kita
tidak sedang mengubah lifetimes dari nilai apa pun yang masuk atau keluar.
Tapi, kita sedang menentukan kalau borrow checker harus menolak nilai apa pun
yang tidak mematuhi batasan-batasan ini. Perhatikan bahwa fungsi longest
tidak perlu tahu persis berapa lama x dan y bakal hidup, dia cuma perlu
tahu kalau ada suatu scope yang bisa disubstitusi untuk 'a yang bakal memenuhi
signature ini.
Saat menganotasi lifetimes di fungsi, anotasinya ditaruh di signature fungsi, bukan di body fungsi. Anotasi lifetime menjadi bagian dari kontrak fungsi itu, mirip dengan tipe-tipe di signature-nya. Memiliki signature fungsi yang mengandung kontrak lifetime berarti analisis yang dilakukan compiler Rust bisa jadi lebih sederhana. Kalau ada masalah dengan cara sebuah fungsi dianotasi atau cara dia dipanggil, pesan error compiler bisa menunjuk ke bagian kode kita serta batasannya dengan lebih tepat. Kalau sebaliknya compiler Rust menebak-nebak lebih banyak soal apa yang kita maksud terkait hubungan antar lifetimes, compiler mungkin cuma bakal bisa nunjukin pemakaian kode kita yang berjarak beberapa langkah dari sumber masalah aslinya.
Saat kita memasukkan referensi konkret ke longest, lifetime konkret yang
disubstitusikan untuk 'a adalah bagian dari scope x yang tumpang tindih
(overlap) dengan scope y. Dengan kata lain, lifetime generik 'a
bakal mendapatkan lifetime konkret yang setara dengan yang lebih kecil
di antara lifetimes x dan y. Karena kita sudah menganotasi referensi yang
dikembalikan dengan parameter lifetime 'a yang sama, referensi kembalian
itu juga bakal valid sepanjang yang lebih kecil di antara lifetimes x dan y.
Mari kita lihat gimana anotasi lifetime membatasi fungsi longest dengan
memasukkan referensi yang punya lifetimes konkret yang berbeda. Listing 10-22
adalah contoh yang simpel.
fn main() {
let string1 = String::from("long string is long");
{
let string2 = String::from("xyz");
let result = longest(string1.as_str(), string2.as_str());
println!("The longest string is {result}");
}
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}longest dengan referensi ke nilai String yang punya lifetimes konkret yang berbedaDi contoh ini, string1 itu valid sampai akhir dari scope luar, string2 itu
valid sampai akhir scope dalam, dan result merujuk ke sesuatu yang valid
sampai akhir scope dalam. Jalankan kode ini dan kita bakal lihat kalau borrow
checker menyetujuinya; kodenya bakal di-compile dan mencetak The longest string is long string is long.
Berikutnya, mari kita coba contoh yang menunjukkan kalau lifetime dari
referensi di result harus merupakan lifetime yang lebih kecil dari dua
argumennya. Kita bakal memindahkan deklarasi variabel result ke luar scope
dalam tapi membiarkan proses assignment nilai ke variabel result di dalam
scope bareng string2. Lalu kita bakal pindahin println! yang memakai
result ke luar scope dalam, setelah scope dalam tersebut berakhir.
Kode di Listing 10-23 tidak bakal bisa di-compile.
fn main() {
let string1 = String::from("long string is long");
let result;
{
let string2 = String::from("xyz");
result = longest(string1.as_str(), string2.as_str());
}
println!("The longest string is {result}");
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}result setelah string2 keluar dari scopePas kita nyoba compile kode ini, kita bakal dapet error ini:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `string2` does not live long enough
--> src/main.rs:6:44
|
5 | let string2 = String::from("xyz");
| ------- binding `string2` declared here
6 | result = longest(string1.as_str(), string2.as_str());
| ^^^^^^^ borrowed value does not live long enough
7 | }
| - `string2` dropped here while still borrowed
8 | println!("The longest string is {result}");
| ------ borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Error ini menunjukkan kalau biar result valid buat statement println!,
string2 harusnya valid sampai akhir dari scope luar. Rust tahu ini karena
kita sudah menganotasi lifetimes dari parameter fungsi dan nilai kembalian
dengan memakai parameter lifetime 'a yang sama.
Sebagai manusia, kita bisa melihat kode ini dan langsung tahu kalau string1
lebih panjang dari string2, dan karenanya, result bakal berisi referensi ke
string1. Karena string1 belum keluar dari scope, referensi ke string1
seharusnya masih valid buat statement println!. Tapi, compiler tidak
bisa melihat kalau referensinya valid di kasus ini. Kita sudah memberi tahu Rust
kalau lifetime referensi yang dikembalikan oleh fungsi longest itu sama dengan
yang lebih kecil di antara lifetimes dari referensi-referensi yang dimasukkan.
Maka dari itu, borrow checker menolak kode di Listing 10-23 karena
kemungkinannya punya referensi yang tidak valid.
Coba desain eksperimen lain yang memvariasikan nilai dan lifetimes dari
referensi yang di-pass ke fungsi longest serta gimana referensi kembaliannya
dipakai. Bikin hipotesis tentang apakah eksperimen kita bakal lolos borrow
checker sebelum men-compile; lalu cek apakah kita benar!
Berpikir dalam Konteks Lifetimes
Gimana cara kita menentukan parameter lifetime itu bergantung pada apa yang
sedang dilakukan sama fungsi kita. Misalnya, kalau kita mengubah implementasi
fungsi longest biar selalu mengembalikan parameter pertama bukannya
string slice yang paling panjang, kita tidak perlu menentukan lifetime
pada parameter y. Kode berikut ini bakal bisa di-compile:
fn main() {
let string1 = String::from("abcd");
let string2 = "efghijklmnopqrstuvwxyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest<'a>(x: &'a str, y: &str) -> &'a str {
x
}Kita sudah menentukan parameter lifetime 'a buat parameter x dan tipe
kembaliannya, tapi tidak buat parameter y, karena lifetime y tidak punya
hubungan apa pun dengan lifetime x atau nilai kembaliannya.
Saat mengembalikan sebuah referensi dari sebuah fungsi, parameter lifetime
buat tipe kembaliannya harus cocok dengan parameter lifetime buat salah satu
dari parameternya. Kalau referensi yang dikembalikan tidak merujuk ke salah
satu parameter, maka referensi itu pasti merujuk ke suatu nilai yang dibuat di
dalam fungsi itu sendiri. Namun, ini bakal jadi dangling reference karena
nilai itu bakal keluar dari scope di akhir dari fungsinya. Coba perhatikan
usaha implementasi fungsi longest yang tidak bakal bisa di-compile ini:
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest<'a>(x: &str, y: &str) -> &'a str {
let result = String::from("really long string");
result.as_str()
}Di sini, meskipun kita sudah menentukan parameter lifetime 'a buat tipe
kembaliannya, implementasi ini bakal gagal di-compile karena lifetime nilai
kembaliannya sama sekali tidak berhubungan dengan lifetime parameter-parameternya.
Ini pesan error yang bakal kita dapat:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0515]: cannot return value referencing local variable `result`
--> src/main.rs:11:5
|
11 | result.as_str()
| ------^^^^^^^^^
| |
| returns a value referencing data owned by the current function
| `result` is borrowed here
For more information about this error, try `rustc --explain E0515`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Masalahnya adalah result keluar dari scope dan dibersihkan di akhir dari
fungsi longest. Kita juga mencoba mengembalikan referensi ke result dari
fungsinya. Tidak ada cara buat kita menentukan parameter lifetime yang bisa
mengubah dangling reference tersebut, dan Rust tidak bakal ngebiarin kita bikin
dangling reference. Di kasus ini, perbaikan terbaiknya adalah dengan
mengembalikan tipe data yang owned (dimiliki) bukannya sebuah referensi
sehingga fungsi yang memanggilnya nanti bertanggung jawab buat membersihkan
nilai tersebut.
Pada akhirnya, sintaks lifetime adalah soal menghubungkan lifetimes dari berbagai parameter dan nilai kembalian dari suatu fungsi. Begitu mereka terhubung, Rust punya informasi yang cukup buat mengizinkan operasi yang aman buat memori (memory-safe operations) dan menolak operasi yang bakal membuat dangling pointers atau melanggar keamanan memori.
Anotasi Lifetime di Definisi Struct
Sejauh ini, struct yang kita definisikan semuanya menampung tipe-tipe yang
owned. Kita bisa mendefinisikan struct buat menampung referensi, tapi di
kasus itu kita perlu menambahkan anotasi lifetime pada setiap referensi di
dalam definisi struct tersebut. Listing 10-24 punya struct bernama
ImportantExcerpt yang menampung sebuah string slice.
struct ImportantExcerpt<'a> {
part: &'a str,
}
fn main() {
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.').next().unwrap();
let i = ImportantExcerpt {
part: first_sentence,
};
}Struct ini punya field tunggal part yang menampung string slice, yang
merupakan sebuah referensi. Sama kayak tipe data generik, kita mendeklarasikan
nama parameter lifetime generik di dalam kurung sudut setelah nama struct
sehingga kita bisa memakai parameter lifetime itu di dalam definisi struct-nya.
Anotasi ini berarti sebuah instance dari ImportantExcerpt tidak bisa hidup
lebih lama dari referensi yang ditampungnya di field part.
Fungsi main di sini bikin instance dari struct ImportantExcerpt yang
menampung referensi ke kalimat pertama dari String yang dimiliki sama variabel
novel. Data di novel sudah ada sebelum instance ImportantExcerpt itu
dibikin. Selain itu, novel belum keluar dari scope sampai setelah
ImportantExcerpt keluar dari scope, jadi referensi di dalam instance
ImportantExcerpt itu dipastikan valid.
Lifetime Elision (Penghilangan Lifetime)
Kita udah belajar kalau setiap referensi punya lifetime dan kita harus menentukan parameter lifetime untuk fungsi atau struct yang memakai referensi. Namun, kita tadi punya fungsi di Listing 4-9, yang ditampilkan lagi di Listing 10-25, yang berhasil di-compile tanpa anotasi lifetime.
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
// first_word works on slices of `String`s
let word = first_word(&my_string[..]);
let my_string_literal = "hello world";
// first_word works on slices of string literals
let word = first_word(&my_string_literal[..]);
// Because string literals *are* string slices already,
// this works too, without the slice syntax!
let word = first_word(my_string_literal);
}Alasan kenapa fungsi ini bisa di-compile tanpa anotasi lifetime murni karena sejarah: di versi awal (sebelum 1.0) dari Rust, kode ini tidak bakal bisa di-compile karena setiap referensi butuh lifetime yang eksplisit. Waktu itu, signature fungsi ini bakal ditulis kayak gini:
fn first_word<'a>(s: &'a str) -> &'a str {Setelah menulis banyak kode Rust, tim Rust menemukan kalau programmer Rust memasukkan anotasi lifetime yang sama berulang kali di situasi-situasi tertentu. Situasi-situasi ini bisa diprediksi dan mengikuti beberapa pola yang deterministik. Para pengembang memprogram pola-pola ini ke dalam kode compiler supaya borrow checker bisa menebak (infer) lifetimes di situasi-situasi ini dan tidak membutuhkan anotasi yang eksplisit lagi.
Sejarah Rust ini cukup relevan karena mungkin saja ke depannya bakal ada pola deterministik lain yang muncul dan ditambahkan ke dalam compiler. Di masa depan, mungkin bakal lebih sedikit lagi anotasi lifetime yang diwajibkan.
Pola-pola yang diprogram ke dalam analisis referensi Rust disebut lifetime elision rules (aturan penghilangan lifetime). Ini bukan aturan buat dipatuhi sama programmer; mereka ini adalah serangkaian kasus tertentu yang bakal dipertimbangkan oleh compiler, dan kalau kode kita masuk ke kasus-kasus ini, kita tidak perlu nulis lifetimes-nya secara eksplisit.
Aturan elision ini tidak memberikan tebakan (inference) yang komplit. Kalau masih ada kebingungan atau ketidakpastian (ambiguity) soal apa lifetimes dari referensi tersebut setelah Rust menerapkan aturan-aturannya, compiler tidak bakal menebak-nebak apa seharusnya lifetime untuk referensi yang tersisa. Alih-alih menebak, compiler bakal ngasih kita error yang bisa diselesaikan dengan menambahkan anotasi lifetime secara manual.
Lifetimes pada parameter fungsi atau method disebut input lifetimes, dan lifetimes pada nilai kembalian disebut output lifetimes.
Compiler memakai tiga aturan buat mencari tahu lifetimes dari referensi saat
tidak ada anotasi yang eksplisit. Aturan pertama berlaku buat input lifetimes,
sedangkan aturan kedua dan ketiga berlaku buat output lifetimes. Kalau
compiler sudah sampai ke akhir dari tiga aturan ini dan masih ada referensi
yang tidak diketahui lifetimes-nya, compiler bakal berhenti dengan sebuah
error. Aturan-aturan ini berlaku buat definisi fn maupun blok impl.
Aturan pertama adalah compiler meng-assign parameter lifetime ke setiap
parameter yang berupa referensi. Dengan kata lain, fungsi dengan satu parameter
dapat satu parameter lifetime: fn foo<'a>(x: &'a i32); fungsi dengan dua
parameter dapat dua parameter lifetime terpisah: fn foo<'a, 'b>(x: &'a i32, y: &'b i32); dan seterusnya.
Aturan kedua adalah, kalau ada tepat satu parameter input lifetime,
lifetime itu di-assign ke semua parameter output lifetime: fn foo<'a>(x: &'a i32) -> &'a i32.
Aturan ketiga adalah, kalau ada beberapa parameter input lifetime, tapi salah
satunya adalah &self atau &mut self karena ini adalah sebuah method, maka
lifetime dari self itu bakal di-assign ke semua parameter output lifetime.
Aturan ketiga ini bikin methods jauh lebih enak buat dibaca dan ditulis karena
kita butuh lebih sedikit simbol.
Mari pura-pura kita adalah compiler. Kita bakal menerapkan aturan-aturan ini
buat mencari tahu lifetimes dari referensi di dalam signature fungsi
first_word di Listing 10-25. Signature-nya mulai tanpa ada lifetimes apa
pun yang berkaitan dengan referensi-referensinya:
fn first_word(s: &str) -> &str {Kemudian compiler menerapkan aturan pertama, yang menentukan bahwa tiap
parameter dapat lifetime-nya masing-masing. Kita bakal menyebutnya 'a
seperti biasa, jadi sekarang signature-nya seperti ini:
fn first_word<'a>(s: &'a str) -> &str {Aturan kedua bisa diterapkan karena ada tepat satu input lifetime. Aturan kedua menentukan bahwa lifetime dari satu parameter input itu di-assign ke output lifetime, jadi signature-nya sekarang jadi kayak gini:
fn first_word<'a>(s: &'a str) -> &'a str {Sekarang semua referensi di signature fungsi ini sudah punya lifetimes, dan compiler bisa melanjutkan analisisnya tanpa perlu programmer buat menganotasi lifetimes di signature fungsi ini.
Mari kita lihat contoh lain, kali ini memakai fungsi longest yang tidak punya
parameter lifetime pas kita mulai ngerjain di Listing 10-20:
fn longest(x: &str, y: &str) -> &str {Mari terapkan aturan pertama: tiap parameter dapat lifetime-nya sendiri. Kali ini kita punya dua parameter bukannya satu, jadi kita punya dua lifetimes:
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {Kita bisa lihat kalau aturan kedua tidak bisa diterapkan karena ada lebih dari
satu input lifetime. Aturan ketiga juga tidak bisa diterapkan, karena longest
adalah sebuah fungsi bukannya method, jadi tidak ada parameter yang berupa
self. Setelah melewati ketiga aturan ini, kita masih belum tahu apa lifetime
dari tipe kembaliannya. Inilah alasan kenapa kita dapat error pas nyoba
men-compile kode di Listing 10-20: compiler sudah melewati aturan-aturan
lifetime elision tapi masih belum bisa mencari tahu semua lifetimes dari
referensi yang ada di signature tersebut.
Karena aturan ketiga sebenarnya cuma berlaku buat method signatures, kita bakal membahas lifetimes di konteks tersebut selanjutnya buat melihat kenapa aturan ketiga ini bikin kita tidak perlu menganotasi lifetimes di method signatures terlalu sering.
Anotasi Lifetime di Definisi Method
Saat kita mengimplementasikan methods pada struct yang punya lifetimes, kita memakai sintaks yang sama persis seperti parameter tipe generik, yang ditunjukkan di Listing 10-11. Di mana kita mendeklarasikan dan memakai parameter lifetimes itu bergantung pada apakah mereka berhubungan dengan field struct-nya atau parameter dan nilai kembalian method-nya.
Nama lifetime buat field struct selalu harus dideklarasikan setelah keyword
impl dan kemudian dipakai setelah nama struct-nya karena lifetimes itu
adalah bagian dari tipe struct-nya.
Di dalam method signatures di dalam blok impl, referensi mungkin terikat ke
lifetime dari referensi di dalam field struct, atau mungkin mereka independen.
Selain itu, aturan lifetime elision sering kali bikin anotasi lifetime tidak
diperlukan lagi di method signatures. Mari kita lihat beberapa contoh yang
memakai struct bernama ImportantExcerpt yang kita definisikan di Listing
10-24.
Pertama kita bakal memakai sebuah method bernama level yang satu-satunya
parameternya adalah referensi ke self dan nilai kembaliannya adalah sebuah i32,
yang mana bukan referensi ke apa pun:
struct ImportantExcerpt<'a> {
part: &'a str,
}
impl<'a> ImportantExcerpt<'a> {
fn level(&self) -> i32 {
3
}
}
impl<'a> ImportantExcerpt<'a> {
fn announce_and_return_part(&self, announcement: &str) -> &str {
println!("Attention please: {announcement}");
self.part
}
}
fn main() {
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.').next().unwrap();
let i = ImportantExcerpt {
part: first_sentence,
};
}Deklarasi parameter lifetime setelah impl dan pemakaiannya setelah nama tipe
itu wajib, tapi kita tidak diwajibkan buat menganotasi lifetime dari referensi
ke self berkat aturan elision yang pertama.
Ini adalah contoh di mana aturan lifetime elision yang ketiga bisa diterapkan:
struct ImportantExcerpt<'a> {
part: &'a str,
}
impl<'a> ImportantExcerpt<'a> {
fn level(&self) -> i32 {
3
}
}
impl<'a> ImportantExcerpt<'a> {
fn announce_and_return_part(&self, announcement: &str) -> &str {
println!("Attention please: {announcement}");
self.part
}
}
fn main() {
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.').next().unwrap();
let i = ImportantExcerpt {
part: first_sentence,
};
}Ada dua input lifetimes, jadi Rust menerapkan aturan lifetime elision pertama
dan memberi baik &self maupun announcement lifetimes mereka masing-masing.
Lalu, karena salah satu parameternya adalah &self, tipe kembaliannya bakal dapat
lifetime dari &self, dan semua lifetimes sudah lengkap terjelaskan.
Lifetime Static
Ada satu lifetime spesial yang perlu kita bahas yaitu 'static, yang
menandakan kalau referensi yang bersangkutan bisa hidup selama keseluruhan durasi
dari program. Semua string literals punya lifetime 'static, yang bisa
kita anotasi seperti berikut:
#![allow(unused)]
fn main() {
let s: &'static str = "Saya punya lifetime static.";
}Teks dari string ini disimpan langsung di dalam binary program kita, yang mana
bakal selalu tersedia. Maka dari itu, lifetime dari semua string literals
adalah 'static.
Kita mungkin bakal melihat saran di pesan error untuk memakai lifetime 'static.
Tapi sebelum menentukan 'static sebagai lifetime buat sebuah referensi,
pikirkan dulu apakah referensi yang kita punya itu sebenarnya hidup selama
keseluruhan lifetime program kita atau tidak, dan apakah kita emang maunya
begitu. Sebagian besar waktu, pesan error yang menyarankan lifetime 'static
itu terjadi gara-gara kita mencoba membuat dangling reference atau ada
ketidakcocokan (mismatch) antara lifetimes yang tersedia. Di kasus seperti
itu, solusinya adalah dengan memperbaiki masalah utamanya, bukannya asal
menentukan lifetime 'static.
Parameter Tipe Generik, Trait Bounds, dan Lifetimes Secara Bersamaan
Mari kita lihat secara singkat sintaks buat menentukan parameter tipe generik, trait bounds, dan lifetimes semuanya di satu fungsi!
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest_with_an_announcement(
string1.as_str(),
string2,
"Today is someone's birthday!",
);
println!("The longest string is {result}");
}
use std::fmt::Display;
fn longest_with_an_announcement<'a, T>(
x: &'a str,
y: &'a str,
ann: T,
) -> &'a str
where
T: Display,
{
println!("Announcement! {ann}");
if x.len() > y.len() { x } else { y }
}Ini adalah fungsi longest dari Listing 10-21 yang mengembalikan string slice
yang lebih panjang dari antara dua string slices. Tapi sekarang fungsi ini
punya parameter ekstra bernama ann dari tipe generik T, yang mana bisa
diisi oleh tipe apa pun yang mengimplementasikan trait Display seperti yang
ditentukan sama klausa where. Parameter ekstra ini bakal dicetak memakai {},
itulah kenapa kita butuh trait bound Display. Karena lifetimes itu adalah
salah satu tipe dari generik, deklarasi parameter lifetime 'a dan parameter
tipe generik T berada di dalam satu daftar yang sama di dalam kurung sudut
setelah nama fungsinya.
Ringkasan
Kita sudah ngebahas banyak hal di bab ini! Sekarang setelah kita paham tentang parameter tipe generik, traits dan trait bounds, serta parameter lifetime generik, kita udah siap buat nulis kode tanpa pengulangan yang bisa jalan di berbagai situasi yang beda-beda. Parameter tipe generik ngasih kita kemampuan buat menerapkan kode ke tipe yang berbeda. Traits dan trait bounds memastikan kalau walaupun tipe-tipenya generik, mereka tetap bakal punya perilaku yang dibutuhin sama kode kita. Kita udah belajar gimana cara memakai anotasi lifetime buat memastikan kalau kode fleksibel ini tidak bakal punya dangling references (referensi yang menggantung). Dan semua analisis ini terjadi saat compile time, yang sama sekali tidak memengaruhi performa saat runtime!
Percaya atau tidak, masih banyak lagi yang bisa dipelajari soal topik-topik yang kita bahas di bab ini: Bab 18 bakal ngebahas trait objects, yang merupakan cara lain buat memakai traits. Ada juga skenario-skenario yang lebih rumit yang melibatkan anotasi lifetime yang cuma bakal kita perlukan di situasi yang sangat tingkat lanjut (advanced); buat itu, kita bisa membaca Rust Reference. Tapi buat langkah selanjutnya, kita bakal belajar gimana cara menulis tests di Rust supaya kita bisa memastikan kalau kode kita berjalan persis seperti yang seharusnya.
Menulis Pengujian Otomatis (Automated Tests)
Di esainya pada tahun 1972 yang berjudul “The Humble Programmer,” Edsger W. Dijkstra bilang kalau “pengujian program (program testing) bisa jadi cara yang sangat efektif buat menunjukkan adanya bugs, tapi sangat tidak memadai buat menunjukkan kalau bugs itu tidak ada.” Itu bukan berarti kita tidak boleh mencoba melakukan pengujian sebanyak mungkin!
Kebenaran (correctness) dalam program kita adalah sejauh mana kode kita melakukan apa yang kita inginkan. Rust didesain dengan tingkat kepedulian yang tinggi soal kebenaran dari program, tapi kebenaran itu kompleks dan tidak mudah dibuktikan. Sistem tipe (type system) Rust menanggung sebagian besar beban ini, tapi sistem tipe tidak bisa menangkap semuanya. Oleh karena itu, Rust menyertakan dukungan buat menulis pengujian perangkat lunak otomatis (automated software tests).
Katakanlah kita menulis sebuah fungsi add_two yang menambahkan 2 ke angka
apa pun yang dimasukkan ke dalamnya. Signature dari fungsi ini menerima
sebuah integer sebagai parameter dan mengembalikan sebuah integer sebagai
hasil. Saat kita mengimplementasikan dan men-compile fungsi tersebut, Rust
melakukan semua pengecekan tipe dan borrow checking yang sudah kita
pelajari sejauh ini untuk memastikan bahwa, misalnya, kita tidak memberikan
nilai String atau referensi yang tidak valid ke fungsi ini. Tapi Rust
tidak bisa mengecek apakah fungsi ini bakal melakukan persis apa yang kita
inginkan, yaitu mengembalikan parameternya ditambah 2, bukannya malah
parameternya ditambah 10 atau dikurang 50! Di sinilah pengujian (tests)
berperan.
Kita bisa menulis pengujian yang menegaskan (assert), misalnya, bahwa saat
kita memasukkan angka 3 ke fungsi add_two, nilai yang dikembalikan
adalah 5. Kita bisa menjalankan pengujian-pengujian ini kapan pun kita
membuat perubahan pada kode kita buat memastikan setiap perilaku benar yang
sudah ada itu tidak berubah.
Pengujian adalah keterampilan yang kompleks: walaupun kita tidak bisa membahas setiap detail soal gimana cara nulis pengujian yang bagus di dalam satu bab, di bab ini kita bakal membahas mekanisme dari fasilitas pengujian Rust. Kita bakal membahas anotasi dan macros yang tersedia pas kita menulis pengujian kita, perilaku default dan opsi-opsi yang disediakan buat menjalankan pengujian kita, dan gimana cara mengatur pengujian jadi unit tests (pengujian unit) dan integration tests (pengujian integrasi).
Gimana Cara Menulis Tests
Cara Menulis Pengujian (Tests)
Pengujian (tests) adalah fungsi Rust yang memverifikasi kalau kode selain kode pengujian berjalan sesuai yang diharapkan. Body dari fungsi pengujian biasanya melakukan tiga aksi ini:
- Menyiapkan data atau state (keadaan) yang dibutuhkan.
- Menjalankan kode yang mau diuji.
- Menegaskan (assert) kalau hasilnya sesuai dengan yang diharapkan.
Mari kita lihat fitur-fitur yang disediakan Rust khusus buat menulis pengujian
yang mengambil aksi-aksi ini, termasuk atribut test, beberapa macro, dan
atribut should_panic.
Anatomi Fungsi Pengujian
Paling sederhananya, pengujian di Rust adalah sebuah fungsi yang dianotasi
dengan atribut test. Atribut adalah metadata tentang kode Rust; salah satu
contohnya adalah atribut derive yang kita pakai buat structs di Bab 5.
Untuk mengubah sebuah fungsi menjadi fungsi pengujian, tambahkan #[test] di
baris sebelum fn. Saat kita menjalankan pengujian menggunakan perintah
cargo test, Rust bakal mem-build sebuah test runner binary yang menjalankan
fungsi-fungsi yang dianotasi ini dan melaporkan apakah setiap fungsi pengujian
tersebut sukses atau gagal.
Kapan pun kita membuat project library baru dengan Cargo, sebuah modul pengujian (test module) dengan satu fungsi pengujian di dalamnya akan otomatis dibuatkan buat kita. Modul ini ngasih kita template buat nulis pengujian jadi kita tidak perlu repot-repot nyari struktur dan sintaks persisnya setiap kali mulai project baru. Kita bisa menambahkan sebanyak apa pun fungsi pengujian tambahan dan modul pengujian yang kita mau!
Kita bakal eksplorasi beberapa aspek soal gimana pengujian itu bekerja dengan ber-eksperimen menggunakan pengujian template ini sebelum kita benar-benar menguji kode apa pun. Lalu kita bakal nulis beberapa pengujian dunia nyata yang memanggil kode yang sudah kita tulis dan menegaskan kalau perilakunya sudah benar.
Mari kita buat project library baru bernama adder yang bakal menjumlahkan
dua angka:
$ cargo new adder --lib
Created library `adder` project
$ cd adder
Isi dari file src/lib.rs di library adder kita seharusnya kelihatan seperti
Listing 11-1.
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}cargo newFile ini dimulai dengan sebuah contoh fungsi add, supaya kita punya sesuatu
buat diuji.
Buat sekarang, mari fokus pada fungsi it_works aja. Perhatikan anotasi
#[test]: atribut ini menunjukkan kalau ini adalah fungsi pengujian, jadi
test runner tahu buat memperlakukan fungsi ini sebagai pengujian. Kita juga
bisa punya fungsi biasa di dalam modul tests untuk membantu menyiapkan
skenario umum atau menjalankan operasi umum, jadi kita harus selalu menunjukkan
fungsi mana yang merupakan fungsi pengujian.
Contoh body fungsi ini memakai macro assert_eq! untuk menegaskan kalau
result, yang menampung hasil pemanggilan add dengan angka 2 dan 2, itu
sama dengan 4. Penegasan ini berfungsi sebagai contoh format buat pengujian yang
umum. Mari kita jalankan untuk melihat kalau pengujian ini sukses (passes).
Perintah cargo test menjalankan semua pengujian di dalam project kita, seperti
yang ditunjukkan di Listing 11-2.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.57s
Running unittests src/lib.rs (target/debug/deps/adder-01ad14159ff659ab)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Cargo men-compile dan menjalankan pengujiannya. Kita melihat baris
running 1 test. Baris berikutnya menunjukkan nama fungsi pengujian yang
di-generate, bernama tests::it_works, dan hasil dari pengujian itu adalah ok.
Ringkasan keseluruhan test result: ok. berarti semua pengujian sukses, dan
bagian yang tertulis 1 passed; 0 failed menjumlahkan banyaknya pengujian yang
sukses atau gagal.
Kita bisa menandai sebuah pengujian untuk diabaikan (ignored) supaya tidak
dijalankan pada waktu tertentu; kita bakal membahas ini di bagian “Mengabaikan
Beberapa Pengujian Kecuali Diminta Secara Spesifik” nanti di bab ini.
Karena kita belum melakukannya di sini, ringkasannya menunjukkan 0 ignored. Kita
juga bisa mengirimkan argumen ke perintah cargo test untuk menjalankan hanya
pengujian yang namanya cocok dengan string tertentu; ini disebut filtering
(penyaringan) dan kita bakal membahasnya di bagian “Menjalankan Sebagian
Pengujian Berdasarkan Nama”. Di sini kita tidak menyaring pengujiannya,
jadi akhir dari ringkasan menunjukkan 0 filtered out.
Statistik 0 measured adalah untuk pengujian benchmark yang mengukur performa.
Pengujian benchmark, saat tulisan ini dibuat, baru tersedia di versi Rust
nightly. Cek dokumentasi soal pengujian benchmark buat info lebih
lanjut.
Bagian selanjutnya dari output pengujian yang dimulai dengan Doc-tests adder
adalah hasil dari documentation tests (pengujian dokumentasi). Kita belum
punya documentation tests apa pun, tapi Rust bisa men-compile contoh kode apa
pun yang ada di dokumentasi API kita. Fitur ini membantu menjaga supaya
dokumentasi dan kode kita tetap sinkron! Kita bakal membahas cara menulis
documentation tests di bagian “Komentar Dokumentasi Sebagai
Pengujian” di Bab 14. Buat sekarang, kita abaikan saja output
Doc-tests ini.
Mari kita mulai mengubah pengujian ini sesuai kebutuhan kita sendiri. Pertama,
ubah nama fungsi it_works jadi nama yang beda, misalnya exploration, kayak
gini:
Nama file: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn exploration() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}Kemudian jalankan cargo test lagi. Outputnya sekarang bakal menunjukkan
exploration bukannya it_works:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.59s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::exploration ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Sekarang kita bakal nambahin pengujian satu lagi, tapi kali ini kita bakal bikin
pengujian yang gagal! Pengujian bakal gagal kalau ada sesuatu di dalam fungsi
pengujian tersebut yang menyebabkan panic. Tiap pengujian dijalankan di dalam
thread baru, dan saat main thread melihat ada test thread yang mati,
pengujian itu bakal ditandai sebagai gagal. Di Bab 9, kita membahas gimana cara
paling sederhana untuk membuat panic adalah dengan memanggil macro panic!.
Masukkan pengujian baru ini sebagai fungsi bernama another, sehingga file
src/lib.rs kita kelihatan seperti Listing 11-3.
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn exploration() {
let result = add(2, 2);
assert_eq!(result, 4);
}
#[test]
fn another() {
panic!("Make this test fail");
}
}panic!Jalankan pengujiannya lagi memakai cargo test. Output-nya seharusnya kelihatan
kayak Listing 11-4, yang menunjukkan kalau pengujian exploration kita sukses
tapi pengujian another kita gagal.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.72s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::another ... FAILED
test tests::exploration ... ok
failures:
---- tests::another stdout ----
thread 'tests::another' panicked at src/lib.rs:17:9:
Make this test fail
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::another
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Bukannya ok, baris test tests::another menunjukkan FAILED. Ada dua bagian
baru yang muncul di antara hasil masing-masing pengujian dan ringkasan akhir:
bagian pertama menampilkan detail alasan setiap pengujian yang gagal. Di kasus
ini, kita mendapat detail bahwa tests::another gagal karena terjadi panic
dengan pesan Make this test fail di baris 17 pada file src/lib.rs. Bagian
berikutnya mendaftarkan cuma nama-nama dari semua pengujian yang gagal, yang
mana sangat berguna saat ada banyak pengujian dan sangat banyak output dari
pengujian yang gagal. Kita bisa memakai nama pengujian yang gagal itu untuk
menjalankan hanya pengujian tersebut agar lebih gampang men-debug-nya; kita
bakal membahas lebih lanjut soal cara-cara menjalankan pengujian di bagian
“Mengontrol Bagaimana Pengujian Dijalankan”.
Baris ringkasan ditampilkan di bagian paling akhir: secara keseluruhan, hasil
pengujian kita adalah FAILED. Kita punya satu pengujian yang sukses dan satu
yang gagal.
Sekarang karena kita sudah melihat seperti apa hasil pengujian di berbagai
skenario, mari kita lihat beberapa macro selain panic! yang berguna buat
pengujian.
Memeriksa Hasil dengan Macro assert!
Macro assert!, yang disediakan oleh standard library, berguna saat kita
mau memastikan bahwa suatu kondisi di pengujian dievaluasi menjadi true. Kita
memberikan sebuah argumen ke macro assert! yang bakal dievaluasi jadi sebuah
Boolean. Kalau nilainya true, tidak ada yang terjadi dan pengujiannya bakal
sukses. Kalau nilainya false, macro assert! memanggil panic! sehingga
pengujiannya gagal. Memakai macro assert! sangat membantu buat mengecek apakah
kode kita berfungsi seperti yang kita mau.
Di Bab 5, Listing 5-15, kita memakai struct Rectangle dan method can_hold,
yang mana diulangi lagi di sini di Listing 11-5. Mari kita masukkan kode ini
ke dalam file src/lib.rs, lalu kita tulis beberapa pengujian buat kode tersebut
menggunakan macro assert!.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}Rectangle dan method can_hold-nya dari Bab 5Method can_hold mengembalikan Boolean, yang artinya ini adalah use case
yang sangat pas buat macro assert!. Di Listing 11-6, kita nulis pengujian
yang mencoba method can_hold dengan bikin instance Rectangle yang punya
lebar 8 dan tinggi 7, lalu menegaskan kalau ia bisa menampung instance Rectangle
lain yang punya lebar 5 dan tinggi 1.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
}can_hold yang mengecek apakah persegi panjang yang lebih besar benar-benar bisa menampung persegi panjang yang lebih kecilPerhatikan baris use super::*; di dalam modul tests. Modul tests adalah
modul biasa yang mengikuti aturan visibilitas standar yang sudah kita bahas
di Bab 7 di bagian “Paths untuk Merujuk ke sebuah Item di Pohon Modul”.
Karena modul tests adalah inner module (modul di dalam modul lain), kita
perlu membawa kode yang mau diuji di modul luar ke dalam scope modul
tests ini. Kita memakai glob (*) di sini, jadi semua hal yang kita
definisikan di modul luar bakal tersedia di modul tests ini.
Kita menamakan pengujian kita larger_can_hold_smaller, dan kita membuat dua
instance Rectangle yang kita butuhkan. Kemudian kita memanggil macro assert!
dan memasukkan hasil pemanggilan larger.can_hold(&smaller) kepadanya.
Ekspresi ini seharusnya mengembalikan true, jadi pengujian kita seharusnya
sukses. Mari kita buktikan!
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 1 test
test tests::larger_can_hold_smaller ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Sukses kan! Mari tambahkan pengujian satu lagi, kali ini menegaskan bahwa persegi panjang yang lebih kecil tidak bisa menampung persegi panjang yang lebih besar:
Nama file: src/lib.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
// --snip--
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}Karena hasil yang benar dari fungsi can_hold di kasus ini adalah false,
kita perlu men-negasikan hasil tersebut sebelum memasukkannya ke macro assert!.
Sebagai hasilnya, pengujian kita bakal sukses kalau can_hold mengembalikan
false:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... ok
test tests::smaller_cannot_hold_larger ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Dua pengujian yang sukses! Sekarang mari kita lihat apa yang terjadi pada hasil
pengujian kalau kita memunculkan bug di kode kita. Kita bakal mengubah
implementasi dari method can_hold dengan mengganti tanda lebih-dari menjadi
tanda kurang-dari saat dia membandingkan lebar (widths):
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
// --snip--
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width < other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}Menjalankan pengujiannya sekarang bakal menghasilkan output ini:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... FAILED
test tests::smaller_cannot_hold_larger ... ok
failures:
---- tests::larger_can_hold_smaller stdout ----
thread 'tests::larger_can_hold_smaller' panicked at src/lib.rs:28:9:
assertion failed: larger.can_hold(&smaller)
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::larger_can_hold_smaller
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Pengujian kita berhasil menangkap bug tersebut! Karena larger.width adalah
8 dan smaller.width adalah 5, perbandingan lebar-lebar ini di can_hold
sekarang mengembalikan false: 8 itu tidak kurang dari 5.
Menguji Kesamaan dengan Macro assert_eq! dan assert_ne!
Cara yang sangat umum buat memverifikasi fungsionalitas adalah dengan menguji
kesamaan antara hasil dari kode yang diuji dengan nilai yang kita harapkan bakal
dikembalikan oleh kode tersebut. Kita bisa saja melakukannya memakai macro
assert! dengan memasukkan ekspresi yang memakai operator ==. Tapi, karena
ini adalah bentuk pengujian yang sering sekali dipakai, standard library
menyediakan dua macro—assert_eq! dan assert_ne!—buat melakukan pengujian
ini dengan lebih praktis. Kedua macro ini membandingkan dua argumen buat melihat
apakah mereka sama (equality) atau tidak sama (inequality). Mereka juga bakal
mencetak kedua nilai tersebut kalau penegasannya gagal, yang mana bikin kita lebih
gampang melihat kenapa pengujian itu gagal; sebaliknya, macro assert! cuma
menunjukkan kalau dia dapat nilai false dari ekspresi ==, tanpa mencetak
nilai-nilai apa saja yang membuat hasil tersebut jadi false.
Di Listing 11-7, kita menulis sebuah fungsi bernama add_two yang menambahkan
2 ke parameternya, lalu kita menguji fungsi ini menggunakan macro assert_eq!.
pub fn add_two(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
}add_two memakai macro assert_eq!Mari cek apakah pengujiannya sukses!
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Kita membuat sebuah variabel bernama result yang menampung hasil pemanggilan
add_two(2). Kemudian kita memasukkan result dan 4 sebagai argumen buat
macro assert_eq!. Baris output buat pengujian ini adalah test tests::it_adds_two ... ok, dan teks ok menunjukkan bahwa pengujian kita sukses!
Mari kita masukkan sebuah bug ke dalam kode kita buat melihat seperti apa
assert_eq! kalau dia gagal. Ubah implementasi fungsi add_two biar dia malah
menambahkan 3:
pub fn add_two(a: u64) -> u64 {
a + 3
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
}Jalankan pengujiannya lagi:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... FAILED
failures:
---- tests::it_adds_two stdout ----
thread 'tests::it_adds_two' panicked at src/lib.rs:12:9:
assertion `left == right` failed
left: 5
right: 4
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_adds_two
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Pengujian kita berhasil menangkap bug tersebut! Pengujian tests::it_adds_two
gagal, dan pesannya memberi tahu kita kalau penegasan yang gagal adalah
left == right beserta apa nilai left dan right yang didapatkan. Pesan ini
ngebantu kita buat mulai melakukan debugging: argumen left, di mana kita
menaruh hasil pemanggilan add_two(2), itu ternyata 5, padahal argumen
right adalah 4. Kita bisa bayangin kalau informasi ini bakal kepake sekali
terutama kalau ada banyak pengujian yang lagi jalan.
Perhatikan bahwa di beberapa bahasa dan test frameworks (kerangka pengujian),
parameter untuk fungsi penegasan kesamaan biasanya dinamakan expected (harapan)
dan actual (asli), dan urutan kita memasukkan argumen-argumennya itu penting.
Tapi di Rust, mereka disebut left (kiri) dan right (kanan), dan urutan
kita meletakkan nilai ekspektasi kita sama nilai hasil dari kodenya itu sama
sekali tidak masalah. Kita bisa saja menulis penegasan di pengujian ini sebagai
assert_eq!(4, result), dan ini bakal menghasilkan pesan gagal yang sama yang
menampilkan assertion `left == right` failed.
Macro assert_ne! bakal sukses (pass) kalau dua nilai yang kita masukkan
tidak sama, dan bakal gagal kalau mereka sama. Macro ini paling berguna buat
kasus di mana kita tidak yakin nilai tersebut bakal jadi apa, tapi kita tahu
pasti nilai tersebut tidak boleh jadi apa. Misalnya, kalau kita menguji fungsi
yang dijamin mengubah inputnya dengan cara tertentu, tapi perubahan itu
tergantung sama hari dalam seminggu saat kita menjalankan pengujiannya, maka hal
terbaik yang bisa ditegaskan (assert) mungkin adalah bahwa output fungsinya
tidak sama dengan inputnya.
Di balik layar, macro assert_eq! dan assert_ne! masing-masing memakai operator
== dan !=. Saat penegasan gagal, macro ini mencetak argumen mereka memakai
debug formatting, yang berarti nilai-nilai yang dibandingkan harus
mengimplementasikan trait PartialEq dan Debug. Semua tipe primitif dan
sebagian besar tipe di standard library sudah mengimplementasikan traits
ini. Buat structs dan enums yang kita definisikan sendiri, kita harus
mengimplementasikan PartialEq buat menegaskan kesamaan tipe tersebut. Kita juga
harus mengimplementasikan Debug buat mencetak nilainya saat penegasan gagal.
Karena kedua traits ini adalah derivable traits, seperti yang disebutkan di
Listing 5-12 di Bab 5, hal ini biasanya semudah menambahkan anotasi
#[derive(PartialEq, Debug)] ke dalam definisi struct atau enum kita.
Lihat Lampiran C, “Derivable Traits,” buat detail lebih
lanjut soal ini dan derivable traits lainnya.
Menambahkan Pesan Kegagalan Kustom
Kita juga bisa menambahkan pesan kustom buat dicetak bersama pesan kegagalan
sebagai argumen opsional di macro assert!, assert_eq!, dan assert_ne!.
Argumen apa pun yang ditaruh setelah argumen wajib bakal diteruskan langsung ke
macro format! (dibahas di “Penggabungan dengan Operator + atau
Macro format!” di Bab 8),
jadi kita bisa memasukkan format string yang mengandung placeholder {}
serta nilai-nilai buat mengisi placeholder tersebut. Pesan kustom ini berguna
buat mendokumentasikan apa maksud dari sebuah penegasan; saat sebuah pengujian
gagal, kita jadi punya gambaran yang lebih baik soal masalah apa yang sedang
terjadi dengan kodenya.
Misalnya, katakanlah kita punya fungsi yang menyapa orang dengan namanya dan kita mau menguji apakah nama yang kita berikan ke fungsi tersebut muncul di dalam outputnya:
Nama file: src/lib.rs
pub fn greeting(name: &str) -> String {
format!("Hello {name}!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}Persyaratan buat program ini belum sepenuhnya disepakati, dan kita cukup yakin
kalau teks Hello di awal sapaan bakal berubah. Kita udah mutusin kalau kita
tidak mau terus-terusan meng-update pengujiannya tiap kali persyaratan ini
berubah, jadi alih-alih mengecek kesamaan yang sama persis dengan nilai kembalian
dari fungsi greeting, kita hanya menegaskan kalau outputnya mengandung teks
dari parameter inputnya.
Sekarang mari kita masukkan sebuah bug ke dalam kode ini dengan mengubah
greeting sehingga dia tidak menyertakan name dan kita bisa lihat seperti apa
kegagalan pengujian standarnya:
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}Menjalankan pengujian ini bakal menghasilkan output berikut:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at src/lib.rs:12:9:
assertion failed: result.contains("Carol")
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Hasil ini cuma ngasih tahu kalau penegasannya gagal dan di baris mana penegasan
itu berada. Pesan kegagalan yang lebih membantu seharusnya mencetak nilai dari
fungsi greeting. Mari tambahkan pesan kegagalan kustom yang disusun dari
format string dan placeholder yang diisi dengan nilai yang kita dapat
dari fungsi greeting:
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(
result.contains("Carol"),
"Greeting did not contain name, value was `{result}`"
);
}
}Sekarang ketika kita menjalankan pengujiannya, kita bakal dapat pesan error yang lebih informatif:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.93s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at src/lib.rs:12:9:
Greeting did not contain name, value was `Hello!`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Kita bisa melihat nilai asli yang kita dapat di dalam output pengujiannya, yang mana sangat membantu kita buat debug apa yang sedang terjadi bukannya cuma apa yang kita harapkan terjadi.
Mengecek Panics dengan should_panic
Selain mengecek nilai kembalian, penting juga buat memastikan kalau kode kita
menangani kondisi error sesuai yang diharapkan. Contohnya, mari perhatikan
tipe Guess yang kita bikin di Bab 9, Listing 9-13. Kode lain yang memakai
Guess bergantung pada jaminan bahwa instance Guess hanya bakal berisi
angka antara 1 dan 100. Kita bisa nulis pengujian buat memastikan kalau
mencoba membuat instance Guess dengan nilai di luar batas itu bakal
mengakibatkan panic.
Kita melakukan ini dengan menambahkan atribut should_panic ke dalam fungsi
pengujian kita. Pengujian ini bakal sukses jika kode di dalam fungsi tersebut
mengalami panic; dan pengujian ini gagal jika kode di dalam fungsinya tidak
panic.
Listing 11-8 menunjukkan pengujian yang mengecek bahwa kondisi error dari
Guess::new memang terjadi pada waktu yang diharapkan.
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}panic!Kita menaruh atribut #[should_panic] setelah atribut #[test] dan sebelum
fungsi pengujian yang ia kenai. Mari lihat hasilnya ketika pengujian ini sukses:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests guessing_game
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Terlihat bagus! Sekarang mari masukkan sebuah bug di kode kita dengan menghapus
kondisi yang membuat fungsi new panic kalau nilainya lebih besar dari 100:
pub struct Guess {
value: i32,
}
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}Saat kita menjalankan pengujian di Listing 11-8, dia bakal gagal:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
note: test did not panic as expected at src/lib.rs:21:8
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Kita tidak dapat pesan yang cukup membantu di kasus ini, tapi pas kita melihat
fungsi pengujiannya, kita ingat kalau ia dianotasi dengan #[should_panic].
Kegagalan yang kita dapat berarti kode di dalam fungsi pengujian ini tidak
menyebabkan panic.
Pengujian yang memakai should_panic bisa kurang presisi. Sebuah pengujian
should_panic bakal tetap sukses meskipun terjadi panic dengan alasan yang
berbeda dari apa yang kita harapkan. Biar pengujian should_panic jadi lebih
presisi, kita bisa menambahkan parameter opsional expected ke dalam atribut
should_panic. Test harness bakal memastikan kalau pesan kegagalan tersebut
mengandung teks yang diberikan. Sebagai contoh, pertimbangkan kode yang
dimodifikasi untuk Guess di Listing 11-9 di mana fungsi new bakal panic
dengan pesan yang berbeda-beda tergantung apakah nilainya terlalu kecil atau
terlalu besar.
pub struct Guess {
value: i32,
}
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be greater than or equal to 1, got {value}."
);
} else if value > 100 {
panic!(
"Guess value must be less than or equal to 100, got {value}."
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}panic! di mana pesan panic-nya harus mengandung potongan teks tertentu (substring)Pengujian ini bakal sukses karena teks yang kita tulis di parameter expected
dari atribut should_panic adalah substring (bagian string) dari pesan panic
yang muncul di fungsi Guess::new. Kita bisa juga memberikan pesan panic
utuh yang kita harapkan, yang mana di kasus ini adalah Guess value must be less than or equal to 100, got 200. Apa yang kita pilih buat ditulis tergantung dari
seberapa unik atau seberapa dinamis pesan panic-nya dan seberapa presisi
kita mau pengujian ini. Di kasus ini, satu potongan teks saja dari pesan panic-nya
sudah cukup buat memastikan kalau fungsi pengujian ini menjalankan kasus blok
else if value > 100.
Untuk melihat apa yang terjadi saat sebuah pengujian should_panic dengan pesan
expected itu gagal, mari kembali masukkan bug ke dalam kode kita dengan menukar
body dari blok if value < 1 dan blok else if value > 100:
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be less than or equal to 100, got {value}."
);
} else if value > 100 {
panic!(
"Guess value must be greater than or equal to 1, got {value}."
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}Kali ini pas kita jalanin pengujian should_panic ini, dia bakal gagal:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
thread 'tests::greater_than_100' panicked at src/lib.rs:12:13:
Guess value must be greater than or equal to 1, got 200.
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
note: panic did not contain expected string
panic message: "Guess value must be greater than or equal to 1, got 200."
expected substring: "less than or equal to 100"
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Pesan kegagalannya menunjukkan kalau pengujian ini memang panic seperti yang
kita harapkan, tapi pesan panic-nya tidak mengandung string yang diharapkan
yaitu less than or equal to 100. Pesan panic yang justru kita dapatkan di
kasus ini adalah Guess value must be greater than or equal to 1, got 200.
Nah, dengan info ini, kita bisa mulai menelusuri di mana letak bug kita!
Menggunakan Result<T, E> di Pengujian
Semua pengujian yang kita bikin sejauh ini bakal panic saat gagal. Kita juga
bisa menulis pengujian yang menggunakan Result<T, E>! Berikut adalah
pengujian dari Listing 11-1, tapi ditulis ulang untuk memakai Result<T, E>
dan mengembalikan Err daripada panic:
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() -> Result<(), String> {
let result = add(2, 2);
if result == 4 {
Ok(())
} else {
Err(String::from("two plus two does not equal four"))
}
}
}Fungsi it_works sekarang punya tipe kembalian Result<(), String>. Di dalam
body fungsi, alih-alih memanggil macro assert_eq!, kita mengembalikan Ok(())
ketika pengujiannya sukses dan mengembalikan Err yang menampung String ketika
pengujiannya gagal.
Menulis pengujian biar mereka mengembalikan Result<T, E> memungkinkan kita
menggunakan question mark operator (?) di dalam body pengujiannya, yang bisa
jadi cara sangat nyaman untuk menulis pengujian yang seharusnya gagal jika ada
operasi di dalamnya yang mengembalikan varian Err.
Kita tidak bisa memakai anotasi #[should_panic] di pengujian yang memakai
Result<T, E>. Buat menegaskan kalau suatu operasi mengembalikan varian Err,
jangan pakai question mark operator pada nilai Result<T, E> itu. Sebaliknya,
pakai assert!(value.is_err()).
Sekarang setelah kita paham beberapa cara untuk menulis pengujian, mari kita
lihat apa yang terjadi di balik layar saat kita menjalankan pengujian dan mulai
mengeksplorasi berbagai opsi yang bisa kita pakai dengan cargo test.
Mengontrol Gimana Tests Dijalankan
Mengontrol Bagaimana Pengujian Dijalankan
Sama halnya dengan cargo run yang men-compile kode kita lalu menjalankan binary hasilnya, cargo test men-compile kode kita dalam mode pengujian (test mode) lalu menjalankan test binary hasilnya. Perilaku default dari binary yang dihasilkan oleh cargo test adalah menjalankan semua pengujian secara paralel dan menangkap (capture) output yang dihasilkan selama pengujian berjalan, yang mana mencegah output tersebut ditampilkan sehingga kita lebih gampang membaca output yang berkaitan dengan hasil pengujian. Akan tetapi, kita bisa menentukan opsi baris perintah (command line options) untuk mengubah perilaku default ini.
Beberapa opsi baris perintah diteruskan ke cargo test, dan beberapa diteruskan ke test binary yang dihasilkan. Untuk memisahkan dua jenis argumen ini, kita mendaftarkan argumen yang diteruskan ke cargo test, diikuti dengan pemisah -- (dua tanda hubung), lalu argumen yang diteruskan ke test binary. Menjalankan cargo test --help menampilkan opsi-opsi yang bisa kita pakai bareng cargo test, dan menjalankan cargo test -- --help menampilkan opsi-opsi yang bisa kita pakai setelah pemisah. Opsi-opsi tersebut juga didokumentasikan di bagian “Tests” di buku rustc.
Menjalankan Pengujian secara Paralel atau Berurutan
Saat kita menjalankan banyak pengujian, secara default mereka berjalan secara paralel menggunakan threads (utas), yang berarti mereka selesai dijalankan lebih cepat dan kita bisa dapat feedback lebih cepat. Karena pengujian-pengujian ini berjalan di saat yang bersamaan, kita harus memastikan kalau pengujian kita tidak saling bergantung satu sama lain atau bergantung pada shared state (state/keadaan yang dibagikan) apa pun, termasuk lingkungan (environment) yang dibagikan, seperti direktori kerja saat ini (current working directory) atau variabel lingkungan (environment variables).
Misalnya, katakanlah setiap pengujian kita menjalankan beberapa kode yang membuat file di diska bernama test-output.txt lalu menulis beberapa data ke file tersebut. Kemudian tiap pengujian membaca data di file itu dan menegaskan (asserts) kalau file tersebut mengandung nilai tertentu, yang mana nilainya beda-beda di tiap pengujian. Karena pengujian berjalan di saat yang bersamaan, satu pengujian mungkin bakal menimpa (overwrite) file itu di antara waktu pengujian lain sedang menulis dan membaca file tersebut. Pengujian kedua bakal gagal, bukan karena kodenya salah tapi karena pengujian-pengujian itu saling mengintervensi satu sama lain saat dijalankan secara paralel. Salah satu solusinya adalah memastikan tiap pengujian menulis ke file yang berbeda-beda; solusi lainnya adalah menjalankan pengujian satu per satu.
Kalau kita tidak mau menjalankan pengujian secara paralel atau kalau kita mau kontrol yang lebih mendetail terhadap jumlah threads yang dipakai, kita bisa mengirim flag --test-threads beserta jumlah threads yang mau kita pakai ke test binary. Coba lihat contoh berikut:
$ cargo test -- --test-threads=1
Kita nge-set jumlah test threads jadi 1, memberi tahu program untuk tidak menggunakan paralelisme apa pun. Menjalankan pengujian pakai satu thread bakal makan waktu lebih lama ketimbang menjalankannya secara paralel, tapi pengujiannya tidak bakal saling mengintervensi kalau mereka membagikan state.
Menampilkan Output Fungsi
Secara default, kalau sebuah pengujian sukses, library pengujian Rust menangkap (captures) apa pun yang dicetak ke standard output. Misalnya, kalau kita memanggil println! di sebuah pengujian dan pengujian itu sukses, kita tidak bakal melihat output println! di terminal; kita cuma bakal melihat baris yang menandakan kalau pengujiannya sukses. Kalau pengujiannya gagal, barulah kita bakal melihat apa pun yang tadi dicetak ke standard output beserta sisa pesan kegagalannya.
Sebagai contoh, Listing 11-10 punya fungsi konyol yang mencetak nilai dari parameternya lalu mengembalikan nilai 10, serta punya sebuah pengujian yang sukses dan satu lagi pengujian yang gagal.
fn prints_and_returns_10(a: i32) -> i32 {
println!("I got the value {a}");
10
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn this_test_will_pass() {
let value = prints_and_returns_10(4);
assert_eq!(value, 10);
}
#[test]
fn this_test_will_fail() {
let value = prints_and_returns_10(8);
assert_eq!(value, 5);
}
}println!Saat kita menjalankan pengujian ini pakai cargo test, kita bakal melihat output berikut:
$ cargo test
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'tests::this_test_will_fail' panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Perhatikan bahwa di dalam output ini kita tidak melihat I got the value 4, yang dicetak saat pengujian yang sukses itu berjalan. Output tersebut sudah ditangkap (captured). Output dari pengujian yang gagal, I got the value 8, muncul di bagian ringkasan output pengujian, yang juga menunjukkan penyebab dari kegagalan pengujiannya.
Kalau kita mau melihat nilai yang dicetak dari pengujian yang sukses juga, kita bisa memberi tahu Rust buat juga menampilkan output dari pengujian yang sukses dengan --show-output:
$ cargo test -- --show-output
Saat kita menjalankan pengujian di Listing 11-10 lagi pakai flag --show-output, kita melihat output berikut:
$ cargo test -- --show-output
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
successes:
---- tests::this_test_will_pass stdout ----
I got the value 4
successes:
tests::this_test_will_pass
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'tests::this_test_will_fail' panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Menjalankan Sebagian Pengujian Berdasarkan Nama
Kadang-kadang, menjalankan test suite yang lengkap itu bisa makan waktu lama. Kalau kita lagi mengerjakan kode di area tertentu, kita mungkin mau menjalankan hanya pengujian yang berkaitan dengan kode tersebut aja. Kita bisa memilih pengujian mana yang mau dijalankan dengan mengirimkan nama atau nama-nama dari pengujian yang mau dijalankan sebagai argumen ke cargo test.
Buat mendemonstrasikan gimana cara menjalankan sebagian pengujian, pertama-tama kita bakal bikin tiga pengujian buat fungsi add_two kita, seperti yang ditunjukkan di Listing 11-11, lalu kita pilih mana yang mau dijalankan.
pub fn add_two(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn add_two_and_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
#[test]
fn add_three_and_two() {
let result = add_two(3);
assert_eq!(result, 5);
}
#[test]
fn one_hundred() {
let result = add_two(100);
assert_eq!(result, 102);
}
}Kalau kita menjalankan pengujian tanpa mengirim argumen apa pun, seperti yang kita lihat sebelumnya, semua pengujian bakal berjalan secara paralel:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 3 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test tests::one_hundred ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Menjalankan Pengujian Tunggal
Kita bisa mengirimkan nama dari fungsi pengujian mana pun ke cargo test untuk menjalankan cuma pengujian itu saja:
$ cargo test one_hundred
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.69s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::one_hundred ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 2 filtered out; finished in 0.00s
Hanya pengujian dengan nama one_hundred yang jalan; dua pengujian lainnya tidak cocok sama nama itu. Output pengujian memberi tahu kita kalau kita punya lebih banyak pengujian yang tidak dijalankan dengan menampilkan 2 filtered out di akhir.
Kita tidak bisa menentukan nama dari beberapa pengujian pakai cara ini; cuma nilai pertama yang diberikan ke cargo test aja yang bakal dipakai. Tapi ada cara buat menjalankan beberapa pengujian.
Menyaring untuk Menjalankan Beberapa Pengujian
Kita bisa menentukan sebagian dari nama pengujian, dan pengujian apa pun yang namanya cocok sama nilai tersebut bakal dijalankan. Misalnya, karena dua dari nama pengujian kita mengandung kata add, kita bisa menjalankan kedua pengujian itu dengan menjalankan cargo test add:
$ cargo test add
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Perintah ini menjalankan semua pengujian yang punya add di namanya dan menyaring (filtered out) pengujian bernama one_hundred. Perhatikan juga bahwa modul tempat pengujian itu berada menjadi bagian dari nama pengujian tersebut, jadi kita bisa menjalankan semua pengujian di dalam sebuah modul dengan menyaringnya berdasarkan nama modul.
Mengabaikan Beberapa Pengujian Kecuali Diminta Secara Spesifik
Kadang-kadang ada beberapa pengujian spesifik yang sangat memakan waktu untuk dieksekusi, jadi kita mungkin mau mengecualikan pengujian-pengujian itu selama sebagian besar sesi cargo test. Ketimbang mendaftarkan semua pengujian yang ingin kita jalankan sebagai argumen, kita bisa menganotasi pengujian yang makan waktu tersebut dengan atribut ignore buat mengecualikannya, seperti yang ditunjukkan di sini:
Nama file: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
#[test]
#[ignore]
fn expensive_test() {
// code that takes an hour to run
}
}Setelah #[test], kita menambahkan baris #[ignore] ke pengujian yang mau kita kecualikan. Sekarang pas kita menjalankan pengujian kita, it_works bakal jalan, tapi expensive_test tidak:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::expensive_test ... ignored
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 1 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Fungsi expensive_test didaftarkan sebagai ignored (diabaikan). Kalau kita mau menjalankan hanya pengujian yang diabaikan, kita bisa memakai cargo test -- --ignored:
$ cargo test -- --ignored
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::expensive_test ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Dengan mengontrol pengujian mana aja yang dijalankan, kita bisa memastikan hasil cargo test kita bakal keluar dengan cepat. Saat kita berada di titik di mana rasanya masuk akal untuk mengecek hasil dari pengujian yang ignored dan kita punya waktu buat menunggu hasilnya, kita bisa menjalankan cargo test -- --ignored alih-alih perintah biasa. Kalau kita mau menjalankan semua pengujian baik itu diabaikan atau tidak, kita bisa menjalankan cargo test -- --include-ignored.
Organisasi Test
Organisasi Pengujian
Seperti yang disebutkan di awal bab, pengujian adalah disiplin yang kompleks, dan orang-orang yang berbeda memakai istilah dan organisasi yang beda-beda juga. Komunitas Rust memikirkan pengujian dalam dua kategori utama: unit tests (pengujian unit) dan integration tests (pengujian integrasi). Unit tests itu kecil dan lebih fokus, menguji satu modul secara terisolasi pada satu waktu, dan bisa menguji antarmuka (interface) private. Integration tests itu sepenuhnya eksternal terhadap library kita dan memakai kode kita dengan cara yang sama persis seperti kode eksternal lainnya, hanya memakai antarmuka public dan berpotensi melibatkan beberapa modul per pengujian.
Menulis kedua jenis pengujian ini penting buat memastikan kalau bagian-bagian dari library kita melakukan apa yang kita harapkan, baik secara terpisah maupun bersama-sama.
Unit Tests
Tujuan dari unit tests adalah buat menguji setiap unit kode secara terisolasi
dari sisa kode lainnya buat dengan cepat mencari tahu di mana kode kita berjalan
sesuai harapan atau tidak. Kita bakal menaruh unit tests di dalam direktori
src di setiap file bersama dengan kode yang lagi mereka uji. Konvensinya adalah
membuat modul bernama tests di setiap file buat menampung fungsi-fungsi
pengujian dan menganotasi modul itu dengan cfg(test).
Modul Tests dan #[cfg(test)]
Anotasi #[cfg(test)] pada modul tests memberi tahu Rust buat men-compile dan
menjalankan kode pengujian hanya ketika kita menjalankan cargo test, dan tidak
saat kita menjalankan cargo build. Ini menghemat waktu kompilasi (compile time)
saat kita cuma mau mem-build library-nya dan menghemat ruang di dalam artefak
hasil kompilasi (compiled artifact) karena pengujian-pengujiannya tidak
dimasukkan. Nanti kita bakal lihat kalau integration tests itu berada di
direktori yang berbeda, jadi mereka tidak butuh anotasi #[cfg(test)]. Tapi,
karena unit tests berada di file yang sama dengan kodenya, kita bakal pakai
#[cfg(test)] buat menentukan kalau mereka seharusnya tidak dimasukkan di
hasil kompilasinya.
Ingat kembali waktu kita men-generate project adder baru di bagian pertama
bab ini, Cargo men-generate kode ini buat kita:
Nama file: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}Pada modul tests yang di-generate otomatis, atribut cfg singkatan dari
configuration (konfigurasi) dan ngasih tahu Rust kalau item berikutnya hanya
boleh dimasukkan jika ada opsi konfigurasi tertentu. Di kasus ini, opsi
konfigurasinya adalah test, yang disediakan oleh Rust buat men-compile dan
menjalankan pengujian. Dengan memakai atribut cfg, Cargo men-compile kode
pengujian kita cuma kalau kita secara aktif menjalankan pengujiannya dengan
cargo test. Ini termasuk fungsi bantuan (helper functions) apa pun yang
mungkin ada di dalam modul ini, selain fungsi-fungsi yang dianotasi dengan
#[test].
Menguji Fungsi Private
Ada perdebatan di komunitas pengujian tentang apakah fungsi private (privat)
sebaiknya diuji secara langsung atau tidak, dan bahasa pemrograman lain membuat
pengujian fungsi private jadi hal yang susah atau mustahil. Terlepas dari
ideologi pengujian mana yang kita anut, aturan privasi Rust memang
memperbolehkan kita untuk menguji fungsi private. Coba perhatikan kode di
Listing 11-12 yang punya fungsi private internal_adder.
pub fn add_two(a: u64) -> u64 {
internal_adder(a, 2)
}
fn internal_adder(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn internal() {
let result = internal_adder(2, 2);
assert_eq!(result, 4);
}
}Perhatikan bahwa fungsi internal_adder tidak ditandai sebagai pub.
Pengujian itu pada dasarnya cuma kode Rust biasa, dan modul tests itu cuma
modul biasa juga. Seperti yang kita bahas di “Paths untuk Merujuk ke sebuah
Item di Pohon Modul”, items di dalam modul anak (child modules)
bisa memakai items di dalam modul leluhurnya (ancestor modules). Di pengujian
ini, kita membawa semua items dari induk modul tests ke dalam scope
dengan use super::*, lalu pengujian ini bisa memanggil internal_adder.
Kalau kita ngerasa fungsi private itu tidak perlu diuji, tidak ada hal di
Rust yang bakal memaksa kita buat ngelakuin itu.
Integration Tests
Di Rust, integration tests (pengujian integrasi) itu sepenuhnya eksternal terhadap library kita. Mereka memakai library kita dengan cara yang persis sama seperti kode eksternal lainnya, yang artinya mereka cuma bisa memanggil fungsi-fungsi yang merupakan bagian dari API public library kita. Tujuannya adalah buat menguji apakah banyak bagian dari library kita bekerja sama dengan benar. Unit-unit kode yang berjalan dengan benar saat sendirian bisa saja punya masalah pas digabungkan (integrated), jadi cakupan pengujian (test coverage) pada kode yang tergabung itu juga penting. Buat bikin integration tests, kita pertama-tama harus punya direktori tests.
Direktori tests
Kita membuat direktori tests di tingkat teratas (top level) direktori project kita, bersebelahan dengan src. Cargo tahu dia harus mencari file-file integration test di direktori ini. Kita kemudian bisa membuat sebanyak apa pun file pengujian yang kita mau, dan Cargo bakal men-compile tiap file tersebut sebagai sebuah crate individu.
Mari kita bikin sebuah integration test. Dengan kode di Listing 11-12 yang masih ada di file src/lib.rs, buat sebuah direktori tests, dan bikin file baru bernama tests/integration_test.rs. Struktur direktori kita seharusnya jadi seperti ini:
adder
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
└── integration_test.rs
Masukkan kode di Listing 11-13 ke dalam file tests/integration_test.rs.
use adder::add_two;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}adderTiap file di dalam direktori tests itu adalah sebuah crate terpisah,
jadi kita perlu membawa library kita ke dalam scope masing-masing test crate.
Oleh karena itu kita menambahkan use adder::add_two; di paling atas kode
kita, yang mana tidak kita perlukan di unit tests.
Kita tidak perlu menganotasi kode apa pun di tests/integration_test.rs dengan
#[cfg(test)]. Cargo memperlakukan direktori tests secara spesial dan
men-compile file-file di direktori ini cuma kalau kita menjalankan cargo test.
Jalankan cargo test sekarang:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.31s
Running unittests src/lib.rs (target/debug/deps/adder-1082c4b063a8fbe6)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-1082c4b063a8fbe6)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Tiga bagian dari output ini mencakup unit tests, integration test, dan doc tests. Perhatikan bahwa kalau ada pengujian di sebuah bagian yang gagal, bagian-bagian selanjutnya tidak bakal dijalankan. Misalnya, kalau ada unit test yang gagal, tidak bakal ada output buat integration tests atau doc tests karena pengujian-pengujian itu baru bakal jalan kalau semua unit tests sukses.
Bagian pertama untuk unit tests itu sama dengan yang selama ini kita lihat:
satu baris buat setiap unit test (satu bernama internal yang kita tambahkan
di Listing 11-12) dan kemudian satu baris ringkasan buat unit tests tersebut.
Bagian integration tests dimulai dengan baris Running tests/integration_test.rs. Setelah itu, ada satu baris buat setiap fungsi
pengujian di dalam integration test itu dan satu baris ringkasan buat
hasil dari integration test tepat sebelum bagian Doc-tests adder dimulai.
Tiap file integration test punya bagiannya masing-masing, jadi kalau kita nambahin lebih banyak file di direktori tests, bakal ada lebih banyak bagian integration test.
Kita masih bisa menjalankan fungsi integration test tertentu dengan
menentukan nama fungsi pengujian itu sebagai argumen di cargo test. Buat
menjalankan semua pengujian di dalam file integration test tertentu, kita
bisa memakai argumen --test di cargo test diikuti dengan nama filenya:
$ cargo test --test integration_test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.64s
Running tests/integration_test.rs (target/debug/deps/integration_test-82e7799c1bc62298)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Perintah ini hanya menjalankan pengujian-pengujian yang ada di file tests/integration_test.rs.
Submodul dalam Integration Tests
Saat kita menambahkan lebih banyak integration tests, kita mungkin mau membuat lebih banyak file di dalam direktori tests untuk membantu mengaturnya; misalnya, kita bisa mengelompokkan fungsi-fungsi pengujian berdasarkan fungsionalitas yang lagi mereka uji. Seperti yang disebutkan sebelumnya, setiap file di direktori tests di-compile sebagai crate-nya sendiri-sendiri secara terpisah, yang mana sangat berguna buat membuat scopes yang terpisah demi meniru dengan lebih dekat gimana para end users bakal memakai crate kita. Namun, ini artinya file-file di direktori tests tidak berbagi perilaku yang sama dengan file-file di direktori src, seperti yang kita pelajari di Bab 7 soal gimana memisahkan kode jadi berbagai modul dan file.
Perbedaan perilaku dari file-file di direktori tests ini paling terlihat saat
kita punya sekumpulan fungsi bantuan (helper functions) buat dipakai di berbagai
file integration test lalu kita mencoba mengikuti langkah-langkah di bagian
“Memisahkan Modul ke dalam Berbagai File”
di Bab 7 buat mengekstrak fungsi-fungsi itu ke modul bersama (common module).
Misalnya, kalau kita membuat tests/common.rs dan menaruh fungsi bernama
setup di dalamnya, kita bisa menambahkan beberapa kode ke setup yang mau
kita panggil dari beberapa fungsi pengujian yang ada di file-file pengujian
yang berbeda:
Nama file: tests/common.rs
pub fn setup() {
// setup code specific to your library's tests would go here
}Saat kita menjalankan pengujiannya lagi, kita bakal melihat bagian baru di
output pengujiannya buat file common.rs, meskipun file ini sama sekali tidak
mengandung fungsi pengujian maupun kita memanggil fungsi setup dari mana
pun:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.89s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/common.rs (target/debug/deps/common-92948b65e88960b4)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-92948b65e88960b4)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Munculnya common di hasil pengujian dengan pesan running 0 tests yang
ditampilkan buat modul itu bukanlah apa yang kita mau. Kita cuma mau membagikan
sedikit kode dengan file-file integration test yang lain. Buat mencegah
common muncul di output pengujian, alih-alih membuat tests/common.rs, kita
bakal membuat tests/common/mod.rs. Direktori project-nya sekarang bakal
kelihatan seperti ini:
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
├── common
│ └── mod.rs
└── integration_test.rs
Ini adalah konvensi penamaan versi lama yang juga dipahami oleh Rust yang
sudah kita sebutkan di bagian “Alternate File Paths” di Bab 7.
Menamai file dengan cara ini memberi tahu Rust untuk tidak memperlakukan modul
common sebagai file integration test. Saat kita memindahkan kode fungsi
setup ke dalam tests/common/mod.rs dan menghapus file tests/common.rs,
bagian khusus buat modul ini di output pengujian tidak akan muncul lagi. File-file
yang ada di dalam subdirektori dari direktori tests tidak akan di-compile
sebagai crate yang terpisah maupun mendapatkan bagian khususnya sendiri di
output pengujian.
Setelah kita membuat tests/common/mod.rs, kita bisa memakainya dari file
integration test mana pun layaknya sebuah modul. Berikut ini contoh memanggil
fungsi setup dari pengujian it_adds_two yang ada di
tests/integration_test.rs:
Nama file: tests/integration_test.rs
use adder::add_two;
mod common;
#[test]
fn it_adds_two() {
common::setup();
let result = add_two(2);
assert_eq!(result, 4);
}Perhatikan bahwa deklarasi mod common; itu sama dengan deklarasi modul yang
sudah kita demonstrasikan di Listing 7-21. Kemudian, di dalam fungsi
pengujiannya, kita bisa memanggil fungsi common::setup().
Integration Tests buat Binary Crates
Kalau project kita adalah sebuah binary crate yang hanya mengandung satu file
src/main.rs dan tidak punya file src/lib.rs, kita tidak bisa bikin
integration tests di direktori tests yang mencoba membawa fungsi-fungsi
yang didefinisikan di src/main.rs ke dalam scope dengan memakai statement
use. Cuma library crates yang mengekspos fungsi-fungsi buat bisa dipakai
oleh crates lain; binary crates itu dimaksudkan untuk berjalan sendiri.
Inilah salah satu alasan kenapa project-project Rust yang menyediakan sebuah
binary biasanya punya file src/main.rs yang lumayan simpel dan langsung
memanggil logika yang berada di dalam file src/lib.rs. Dengan struktur itu,
integration tests bisa menguji library crate dengan perintah use buat
membuat fungsionalitas utamanya jadi tersedia buat dites. Kalau fungsionalitas
utamanya bekerja dengan baik, sebagian kecil kode yang ada di file src/main.rs
itu bakal ikut bekerja dengan baik juga, dan bagian kecil kode itu tidak perlu
diuji lagi secara terpisah.
Ringkasan
Fitur pengujian Rust ngasih kita cara buat menentukan dengan spesifik gimana kode kita seharusnya berfungsi untuk memastikan kode itu terus berjalan sesuai yang kita harapkan, bahkan ketika kita membuat berbagai perubahan nanti. Unit tests mencoba bagian-bagian yang berbeda dari sebuah library secara terpisah dan bisa menguji detail implementasi private. Integration tests mengecek apakah banyak bagian dari library itu bekerja sama dengan benar, dan mereka memakai API public dari library itu buat menguji kodenya dengan cara yang persis sama dengan bagaimana kode eksternal bakal memakainya. Walaupun sistem tipe (type system) Rust dan aturan ownership ngebantu mencegah beberapa jenis bugs, pengujian tetaplah penting buat ngurangin logic bugs (kutu logika) yang berkaitan dengan bagaimana kode kita seharusnya berperilaku.
Mari kita gabungin ilmu yang udah kita pelajarin di bab ini dan di bab-bab sebelumnya buat ngerjain sebuah project bareng!
Project I/O: Bikin Program Command Line
Bab ini adalah rangkuman dari banyak skill yang udah kita pelajari sejauh ini dan sebuah eksplorasi ke beberapa fitur standard library lainnya. Kita bakal bikin alat (tool) command line yang berinteraksi sama file dan input/output dari command line buat melatih beberapa konsep Rust yang sekarang udah kita kuasai.
Kecepatan, keamanan, output binary tunggal, dan dukungan lintas platform
bikin Rust jadi bahasa yang ideal buat bikin alat command line, jadi buat
project kita ini, kita bakal bikin versi kita sendiri dari alat pencarian
command line klasik grep (globally search a regular expression
and print). Di skenario penggunaan paling sederhana, grep mencari string
tertentu di dalam file yang ditentukan. Buat ngelakuin itu, grep menerima
path (jalur) file dan sebuah string sebagai argumennya. Lalu dia ngebaca
file tersebut, nyari baris-baris di file itu yang mengandung argumen string
tadi, terus mencetak baris-baris itu.
Di sepanjang jalan, kita bakal nunjukin gimana cara bikin alat command line
kita memakai fitur terminal yang dipakai sama banyak alat command line
lainnya. Kita bakal ngebaca nilai dari environment variable buat ngebolehin
user mengonfigurasi perilaku alat kita. Kita juga bakal mencetak pesan error
ke stream konsol standard error (stderr) bukannya standard output
(stdout) sehingga, misalnya, user bisa me-redirect (mengalihkan) output
yang sukses ke sebuah file tapi tetap bisa melihat pesan error di layar.
Salah satu anggota komunitas Rust, Andrew Gallant, udah bikin versi grep yang
berfitur lengkap dan kenceng sekali, namanya ripgrep. Sebagai perbandingan,
versi kita bakal lumayan sederhana, tapi bab ini bakal ngasih kita beberapa
pengetahuan dasar yang kita butuhin buat paham project dunia nyata kayak
ripgrep.
Project grep kita bakal nggabungin sejumlah konsep yang udah kita pelajari
sejauh ini:
- Mengorganisasi kode (Bab 7)
- Memakai vectors dan strings (Bab 8)
- Menangani errors (Bab 9)
- Memakai traits dan lifetimes di tempat yang tepat (Bab 10)
- Nulis pengujian (tests) (Bab 11)
Kita juga bakal ngenalin secara singkat closures, iterators, dan trait objects, yang bakal dibahas lebih detail di Bab 13 dan Bab 18.
Menerima Argumen Command Line
Menerima Argumen Command Line
Mari kita bikin project baru dengan cargo new, seperti biasa. Kita bakal
menamakan project kita minigrep buat ngebedain dari alat grep yang mungkin
udah ada di sistem kita.
$ cargo new minigrep
Created binary (application) `minigrep` project
$ cd minigrep
Tugas pertama adalah bikin minigrep menerima dua argumen command line-nya:
path file dan sebuah string yang mau dicari. Yakni, kita mau bisa menjalankan
program kita pakai cargo run, dengan dua tanda hubung (hyphens) buat
menandakan argumen berikutnya itu buat program kita bukannya buat cargo, sebuah
string buat dicari, dan path ke file tempat nyarinya, kayak gini:
$ cargo run -- searchstring example-filename.txt
Saat ini, program yang di-generate sama cargo new belum bisa memproses
argumen yang kita berikan. Beberapa libraries yang udah ada di
crates.io bisa bantu nulis program yang menerima argumen
command line, tapi karena kita baru aja belajar konsep ini, mari kita
mengimplementasikan kemampuan ini sendiri.
Membaca Nilai Argumen
Biar minigrep bisa ngebaca nilai argumen command line yang kita masukkan
ke dalamnya, kita butuh fungsi std::env::args yang disediakan di standard
library Rust. Fungsi ini mengembalikan sebuah iterator dari argumen-argumen
command line yang diberikan ke minigrep. Kita bakal membahas iterators secara
lengkap di Bab 13. Buat sekarang, kita cuma perlu tahu dua detail soal
iterators: iterators menghasilkan serangkaian nilai, dan kita bisa memanggil
method collect pada sebuah iterator buat mengubahnya jadi sebuah collection
(koleksi), kayak vector misalnya, yang berisi semua elemen yang dihasilkan
sama iterator tersebut.
Kode di Listing 12-1 memungkinkan program minigrep kita ngebaca argumen
command line apa pun yang diberikan ke dia, terus mengumpulkan nilai-nilainya
ke dalam sebuah vector.
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
dbg!(args);
}Pertama kita bawa modul std::env ke dalam scope pakai statement use
biar kita bisa memakai fungsi args-nya. Perhatikan kalau fungsi
std::env::args ini bersarang (nested) di dua level modul. Kayak yang udah
kita bahas di Bab 7, di kasus di mana fungsi yang mau kita
pakai bersarang di lebih dari satu modul, kita memilih buat membawa induk
modulnya ke dalam scope ketimbang fungsinya langsung. Dengan melakukan hal itu,
kita bisa dengan gampang memakai fungsi lain dari std::env. Hal ini juga
mengurangi kebingungan (ambiguity) dibandingkan menambahkan use std::env::args
lalu memanggil fungsinya dengan args doang, karena args gampang sekali
disangka fungsi yang didefinisikan di modul saat ini.
Fungsi args dan Unicode Tidak Valid
Perhatikan bahwa std::env::args bakal panic kalau ada argumen yang
mengandung karakter Unicode yang tidak valid. Kalau program kita perlu menerima
argumen yang mengandung Unicode tidak valid, pakai std::env::args_os sebagai
gantinya. Fungsi tersebut mengembalikan iterator yang menghasilkan nilai
OsString bukannya nilai String. Kita memilih memakai std::env::args
di sini biar simpel karena nilai OsString itu beda-beda di setiap platform
dan lebih rumit buat dikerjain dibanding nilai String.
Di baris pertama dari main, kita memanggil env::args, lalu kita langsung
memakai collect buat mengubah iterator itu jadi vector yang berisi semua nilai
yang dihasilkan sama iterator-nya. Kita bisa memakai fungsi collect buat bikin
berbagai jenis koleksi, jadi kita harus secara eksplisit menganotasi tipe dari
args buat menentukan kalau kita mau sebuah vector berisi strings. Walaupun
kita jarang sekali perlu menganotasi tipe di Rust, collect adalah salah satu
fungsi yang sering sekali butuh anotasi karena Rust tidak bisa menebak jenis
koleksi apa yang kita mau.
Terakhir, kita mencetak vector-nya pakai debug macro. Mari kita coba jalankan kodenya dulu tanpa argumen lalu dengan dua argumen:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/minigrep`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
]
$ cargo run -- needle haystack
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.57s
Running `target/debug/minigrep needle haystack`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
"needle",
"haystack",
]
Perhatikan kalau nilai pertama di vector itu adalah "target/debug/minigrep",
yaitu nama dari binary kita. Ini sesuai sama perilaku daftar argumen di
bahasa C, membiarkan program memakai nama yang digunakan saat mereka dipanggil
dalam eksekusinya. Sering kali praktis punya akses ke nama program kalau
kita mau mencetaknya di dalam pesan atau ngubah perilaku program berdasarkan
alias command line apa yang dipakai buat memanggil programnya. Tapi buat
tujuan bab ini, kita abaikan saja itu dan cuma nyimpen dua argumen yang kita
butuhin.
Menyimpan Nilai Argumen di dalam Variabel
Program kita saat ini sudah bisa mengakses nilai yang ditentukan sebagai argumen command line. Sekarang kita perlu menyimpan nilai dari kedua argumen itu di dalam variabel supaya kita bisa memakai nilainya di seluruh bagian program. Kita lakuin itu di Listing 12-2.
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {query}");
println!("In file {file_path}");
}Seperti yang kita lihat saat kita mencetak vector tadi, nama program menempati
nilai pertama di vector pada args[0], jadi kita mulai ngambil argumennya di
indeks 1. Argumen pertama yang diterima minigrep adalah string yang lagi
kita cari, jadi kita menaruh referensi ke argumen pertama tersebut di variabel
query. Argumen kedua bakal jadi path file, jadi kita menaruh referensi ke
argumen kedua tersebut di variabel file_path.
Kita sementara mencetak nilai dari variabel-variabel ini buat membuktikan
kalau kodenya berjalan sesuai keinginan kita. Mari kita jalankan program ini lagi
dengan argumen test dan sample.txt:
$ cargo run -- test sample.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep test sample.txt`
Searching for test
In file sample.txt
Mantap, programnya jalan! Nilai-nilai argumen yang kita butuhkan sudah disimpan ke dalam variabel yang tepat. Nanti kita bakal menambahkan sedikit error handling (penanganan error) buat menangani beberapa potensi situasi yang keliru, misalnya saat user tidak memberikan argumen apa pun; buat sekarang, kita abaikan dulu situasi itu dan lanjut bekerja menambahkan kemampuan membaca file.
Membaca sebuah File
Membaca File
Sekarang kita bakal menambahkan fungsionalitas untuk membaca file yang ditentukan di argumen file_path. Pertama kita butuh sebuah file contoh buat mengujinya: kita bakal memakai file dengan sedikit teks yang membentang di beberapa baris dan punya beberapa kata yang diulang. Listing 12-3 punya puisi Emily Dickinson yang bakal pas sekali! Buat sebuah file bernama poem.txt di tingkat root project kita, lalu masukkan puisi “I’m Nobody! Who are you?”
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Dengan teks yang sudah siap, edit src/main.rs dan tambahkan kode buat membaca file tersebut, seperti yang ditunjukkan di Listing 12-4.
use std::env;
use std::fs;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {query}");
println!("In file {file_path}");
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}Pertama kita membawa bagian yang relevan dari standard library dengan statement use: kita butuh std::fs buat menangani file.
Di main, statement baru fs::read_to_string menerima file_path, membuka file tersebut, dan mengembalikan nilai bertipe std::io::Result<String> yang berisi konten filenya.
Setelah itu, kita kembali menambahkan statement println! sementara yang mencetak nilai dari contents setelah file dibaca, jadi kita bisa mengecek kalau programnya berfungsi dengan baik sejauh ini.
Mari kita jalankan kode ini dengan sembarang string sebagai argumen command line pertama (karena kita belum mengimplementasikan bagian pencariannya) dan file poem.txt sebagai argumen kedua:
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Mantap! Kodenya berhasil membaca dan kemudian mencetak isi dari filenya. Tapi kodenya punya beberapa kelemahan. Saat ini, fungsi main punya banyak tanggung jawab: umumnya, fungsi bakal lebih jelas dan gampang dipelihara (maintain) kalau tiap fungsi bertanggung jawab untuk satu ide saja. Masalah lainnya adalah kita belum menangani error sebaik yang kita bisa. Programnya masih kecil, jadi kelemahan-kelemahan ini belum jadi masalah besar, tapi seiring programnya makin besar, bakal lebih susah untuk memperbaikinya dengan rapi. Praktik yang bagus adalah mulai me-refactor sejak awal saat mengembangkan program karena bakal jauh lebih mudah untuk me-refactor jumlah kode yang lebih sedikit. Kita bakal melakukan itu selanjutnya.
Refactoring buat Meningkatkan Modularitas dan Error Handling
Refactoring untuk Meningkatkan Modularitas dan Penanganan Error
Untuk meningkatkan program kita, kita bakal memperbaiki empat masalah yang berkaitan dengan struktur program dan gimana program menangani potensi error. Pertama, fungsi main kita sekarang melakukan dua tugas: mengurai (parsing) argumen dan membaca file. Seiring berkembangnya program kita, jumlah tugas terpisah yang ditangani oleh fungsi main juga bakal meningkat. Saat sebuah fungsi mendapat lebih banyak tanggung jawab, fungsi itu jadi lebih sulit buat dipahami, lebih susah buat diuji, dan lebih susah buat diubah tanpa merusak salah satu bagiannya. Hal terbaik adalah memisahkan fungsionalitas sehingga tiap fungsi bertanggung jawab atas satu tugas saja.
Isu ini juga terikat ke masalah kedua: walaupun query dan file_path adalah variabel konfigurasi untuk program kita, variabel seperti contents dipakai buat menjalankan logika programnya. Semakin panjang main, semakin banyak variabel yang harus kita bawa ke dalam scope; semakin banyak variabel yang ada di scope, semakin susah untuk mengingat tujuan dari masing-masing variabel tersebut. Praktik terbaiknya adalah mengelompokkan variabel-variabel konfigurasi ke dalam satu struktur buat memperjelas tujuan mereka.
Masalah ketiga adalah kita memakai expect buat mencetak pesan error saat membaca file gagal, tapi pesan error-nya cuma mencetak Should have been able to read the file. Membaca file bisa gagal karena berbagai alasan: contohnya, file tersebut bisa saja tidak ada, atau kita mungkin tidak punya izin buat membukanya. Saat ini, apa pun situasinya, kita bakal mencetak pesan error yang sama persis buat semuanya, yang mana tidak ngasih informasi apa pun ke user!
Keempat, kita memakai expect buat menangani error secara berulang kali, dan kalau user menjalankan program kita tanpa memberikan argumen yang cukup, mereka bakal dapat error index out of bounds dari Rust yang tidak menjelaskan masalahnya dengan jelas. Bakal lebih baik kalau semua kode penanganan error (error-handling code) ada di satu tempat sehingga para maintainer di masa depan cuma punya satu tempat buat dicek kalau logika penanganan error-nya perlu diubah. Mengumpulkan semua kode penanganan error di satu tempat juga bakal memastikan kalau kita mencetak pesan yang bermakna bagi end users (pengguna akhir) kita.
Mari kita atasi empat masalah ini dengan me-refactor project kita.
Separation of Concerns (Pemisahan Kepentingan) untuk Binary Projects
Masalah organisasi dari mengalokasikan tanggung jawab untuk beberapa tugas ke dalam fungsi main itu umum terjadi di banyak binary projects. Sebagai hasilnya, banyak programmer Rust merasa berguna untuk memisahkan berbagai kepentingan dari sebuah program binary saat fungsi main mulai menjadi besar. Proses ini punya langkah-langkah berikut:
- Pisahkan program kita jadi file main.rs dan file lib.rs, lalu pindahkan logika program kita ke lib.rs.
- Selama logika penguraian (parsing) command line masih kecil, ia bisa tetap berada di dalam fungsi
main. - Ketika logika penguraian command line mulai menjadi rumit, ekstrak logika itu dari fungsi
mainke dalam fungsi atau tipe lain.
Tanggung jawab yang tersisa di fungsi main setelah proses ini seharusnya dibatasi hanya pada hal-hal berikut:
- Memanggil logika penguraian command line beserta nilai-nilai argumennya
- Menyiapkan konfigurasi apa pun lainnya
- Memanggil fungsi
runyang ada di lib.rs - Menangani error kalau fungsi
runmengembalikan error
Pola ini adalah soal pemisahan kepentingan (separating concerns): main.rs menangani jalannya program dan lib.rs menangani semua logika dari tugas yang ada. Karena kita tidak bisa menguji fungsi main secara langsung, struktur ini memungkinkan kita untuk menguji semua logika program dengan memindahkannya ke luar dari fungsi main. Kode yang tersisa di fungsi main bakal cukup kecil untuk bisa diverifikasi kebenarannya hanya dengan membacanya. Mari kita rombak program kita dengan mengikuti proses ini.
Mengekstrak Parser Argumen
Kita bakal mengekstrak fungsionalitas untuk mengurai argumen ke dalam fungsi yang bakal dipanggil oleh main. Listing 12-5 menunjukkan permulaan baru dari fungsi main yang memanggil fungsi baru parse_config, yang bakal kita definisikan di src/main.rs.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let (query, file_path) = parse_config(&args);
// --snip--
println!("Searching for {query}");
println!("In file {file_path}");
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
fn parse_config(args: &[String]) -> (&str, &str) {
let query = &args[1];
let file_path = &args[2];
(query, file_path)
}parse_config dari mainKita masih mengumpulkan argumen command line ke dalam sebuah vector, tapi alih-alih me-assign nilai argumen di indeks 1 ke variabel query dan nilai argumen di indeks 2 ke variabel file_path di dalam fungsi main, kita memberikan keseluruhan vector-nya ke fungsi parse_config. Fungsi parse_config ini kemudian menampung logika yang menentukan argumen mana yang masuk ke variabel mana dan mengembalikan nilai-nilainya kembali ke main. Kita tetap membuat variabel query dan file_path di main, tapi main tidak lagi punya tanggung jawab buat menentukan gimana korelasi antara argumen command line dan variabel-variabel tersebut.
Perombakan ini mungkin kelihatan agak berlebihan buat program kita yang masih kecil, tapi kita melakukan refactoring dalam langkah-langkah kecil yang bertahap. Setelah membuat perubahan ini, jalankan programnya lagi buat memverifikasi kalau penguraian argumennya masih berfungsi. Mengecek progres kita secara rutin itu hal yang baik, untuk membantu mengidentifikasi penyebab masalah ketika masalah itu muncul.
Mengelompokkan Nilai-nilai Konfigurasi
Kita bisa mengambil langkah kecil lainnya buat meningkatkan fungsi parse_config lebih jauh lagi. Saat ini, kita mengembalikan sebuah tuple, tapi kemudian kita langsung memecah tuple itu menjadi bagian-bagian individual lagi. Ini adalah tanda kalau kita mungkin belum punya abstraksi yang tepat.
Indikator lain yang menunjukkan ada ruang buat peningkatan adalah bagian config dari nama parse_config, yang menyiratkan kalau dua nilai yang kita kembalikan itu saling berhubungan dan keduanya adalah bagian dari satu nilai konfigurasi. Saat ini kita belum menyampaikan makna tersebut di dalam struktur datanya selain dengan mengelompokkan kedua nilai itu ke dalam tuple; kita bakal lebih baik menaruh kedua nilai itu ke dalam satu struct dan memberikan nama yang bermakna buat tiap field dari struct tersebut. Melakukan hal ini bakal mempermudah para maintainer kode ini di masa depan buat paham gimana berbagai nilai tersebut saling berhubungan dan apa tujuannya.
Listing 12-6 menunjukkan peningkatan buat fungsi parse_config.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = parse_config(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
// --snip--
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
fn parse_config(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}parse_config agar mengembalikan sebuah instance dari struct ConfigKita sudah menambahkan sebuah struct bernama Config yang didefinisikan punya field bernama query dan file_path. Signature dari parse_config sekarang menunjukkan kalau dia mengembalikan nilai Config. Di dalam body parse_config, di mana kita tadinya mengembalikan string slices yang merujuk pada nilai String di args, kita sekarang mendefinisikan Config agar menampung nilai String yang owned (dimiliki). Variabel args di main adalah pemilik dari nilai-nilai argumen tersebut dan dia hanya membiarkan fungsi parse_config meminjamnya (borrow), yang berarti kita bakal melanggar aturan borrowing Rust kalau Config mencoba mengambil ownership (kepemilikan) dari nilai-nilai yang ada di args.
Ada banyak cara yang bisa kita pakai buat mengelola data String ini; yang paling gampang, meskipun agak kurang efisien, adalah dengan memanggil method clone pada nilai-nilai tersebut. Ini bakal membuat salinan penuh dari datanya supaya instance Config tersebut bisa memilikinya, yang mana makan lebih banyak waktu dan memori dibandingkan cuma menyimpan referensi ke data string-nya. Tapi, meng-clone datanya juga bikin kode kita jadi sangat simpel karena kita tidak perlu pusing mengelola lifetimes dari referensi-referensinya; di situasi ini, mengorbankan sedikit performa buat mendapatkan kesederhanaan adalah sebuah trade-off (pertukaran) yang sepadan.
Pertukaran (Trade-Offs) dari Pemakaian clone
Ada kecenderungan di antara banyak programmer Rust buat menghindari pemakaian clone demi memperbaiki masalah ownership karena biaya runtime-nya. Di Bab 13, kita bakal belajar gimana cara memakai methods yang lebih efisien di tipe situasi seperti ini. Tapi buat sekarang, tidak masalah menyalin beberapa string demi bisa terus maju karena kita cuma bakal membuat salinan ini sekali saja dan path file serta string pencarian kita itu sangat kecil. Jauh lebih baik punya program yang bekerja walau sedikit tidak efisien daripada mencoba melakukan hyperoptimize (optimasi berlebihan) di kode pada percobaan pertama kita. Seiring kita jadi makin berpengalaman dengan Rust, bakal lebih gampang buat mulai dari solusi yang paling efisien, tapi buat sekarang, memanggil clone itu masih sangat bisa diterima.
Kita sudah meng-update main agar dia menaruh instance dari Config yang dikembalikan oleh parse_config ke dalam variabel bernama config, dan kita juga meng-update kode yang sebelumnya memakai variabel query dan file_path secara terpisah sehingga kini ia memakai field yang ada di struct Config.
Sekarang kode kita dengan lebih jelas menyampaikan kalau query dan file_path itu berhubungan dan tujuannya adalah buat mengkonfigurasi gimana program kita bakal berjalan. Kode apa pun yang memakai nilai-nilai ini tahu untuk mencari mereka di instance config di dalam field yang dinamai sesuai tujuannya.
Membuat Constructor buat Config
Sejauh ini, kita sudah mengekstrak logika yang bertanggung jawab buat mengurai argumen command line dari main dan menaruhnya di fungsi parse_config. Melakukan hal ini membantu kita melihat kalau nilai query dan file_path itu berhubungan, dan hubungan itu harus disampaikan di kode kita. Kita kemudian menambahkan struct Config untuk menamai tujuan terkait dari query dan file_path serta untuk bisa mengembalikan nama-nama dari nilai tersebut sebagai nama field struct dari fungsi parse_config.
Jadi sekarang karena tujuan dari fungsi parse_config adalah untuk membuat sebuah instance Config, kita bisa mengubah parse_config dari fungsi biasa menjadi sebuah fungsi bernama new yang dikaitkan (associated) dengan struct Config. Membuat perubahan ini bakal bikin kodenya jadi lebih idiomatik. Kita bisa membuat instance dari berbagai tipe di standard library, seperti String, dengan memanggil String::new. Mirip dengan itu, dengan mengubah parse_config menjadi sebuah fungsi new yang dikaitkan dengan Config, kita bakal bisa membuat instance dari Config dengan memanggil Config::new. Listing 12-7 menunjukkan perubahan yang perlu kita buat.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
// --snip--
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn new(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}parse_config menjadi Config::newKita sudah meng-update main di tempat kita memanggil parse_config untuk memanggil Config::new sebagai gantinya. Kita sudah mengubah nama parse_config jadi new dan memindahkannya ke dalam blok impl, yang mengaitkan fungsi new ini dengan Config. Coba compile kode ini lagi buat memastikan kalau ini berfungsi.
Memperbaiki Penanganan Error
Sekarang kita bakal bekerja buat memperbaiki penanganan error (error handling) kita. Ingat kembali kalau mencoba mengakses nilai di dalam vector args di indeks 1 atau indeks 2 bakal bikin program mengalami panic kalau vector-nya berisi kurang dari tiga item. Coba jalankan programnya tanpa argumen apa pun; outputnya bakal kayak gini:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:27:21:
index out of bounds: the len is 1 but the index is 1
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Baris index out of bounds: the len is 1 but the index is 1 adalah pesan error yang ditujukan buat para programmer. Ini tidak bakal ngebantu end users (pengguna akhir) kita buat paham apa yang seharusnya mereka lakuin. Mari kita perbaiki itu sekarang.
Memperbaiki Pesan Error
Di Listing 12-8, kita menambahkan pengecekan di fungsi new yang bakal memverifikasi apakah panjang slice-nya cukup sebelum mengakses indeks 1 dan indeks 2. Kalau slice-nya tidak cukup panjang, programnya bakal mengalami panic dan menampilkan pesan error yang lebih bagus.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
// --snip--
fn new(args: &[String]) -> Config {
if args.len() < 3 {
panic!("not enough arguments");
}
// --snip--
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}Kode ini mirip sama fungsi Guess::new yang kita tulis di Listing 9-13, di mana kita memanggil panic! saat argumen value berada di luar rentang nilai yang valid. Alih-alih mengecek sebuah rentang nilai di sini, kita mengecek apakah panjang dari args minimal adalah 3 dan sisa dari fungsi ini bisa beroperasi di bawah asumsi kalau kondisi ini sudah terpenuhi. Kalau args punya kurang dari tiga item, kondisi ini bakal bernilai true, dan kita memanggil macro panic! buat mengakhiri program seketika.
Dengan sedikit baris tambahan ini di new, mari kita jalankan programnya tanpa argumen lagi buat melihat seperti apa pesan error-nya sekarang:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:26:13:
not enough arguments
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Output ini lebih mendingan: kita sekarang punya pesan error yang masuk akal. Namun, kita juga punya informasi ekstra yang tidak mau kita kasih ke user kita. Mungkin teknik yang kita pakai di Listing 9-13 bukanlah teknik yang terbaik buat dipakai di sini: sebuah pemanggilan panic! lebih cocok buat mengatasi masalah pemrograman dibanding masalah pemakaian, seperti yang dibahas di Bab 9. Sebagai gantinya, kita bakal memakai teknik lain yang sudah kita pelajari di Bab 9—mengembalikan sebuah Result yang menandakan sukses atau error.
Mengembalikan Result Alih-Alih Memanggil panic!
Kita bisa mengembalikan sebuah nilai Result yang bakal mengandung sebuah instance Config kalau sukses dan bakal mendeskripsikan masalahnya kalau terjadi error. Kita juga bakal mengubah nama fungsinya dari new jadi build karena banyak programmer berharap kalau fungsi bernama new itu tidak bakal pernah gagal. Saat Config::build sedang berkomunikasi dengan main, kita bisa memakai tipe Result buat ngasih tahu kalau ada masalah. Kemudian kita bisa mengubah main agar dia mengubah varian Err jadi error yang lebih praktis buat user kita, tanpa teks-teks tambahan soal thread 'main' dan RUST_BACKTRACE yang disebabkan oleh pemanggilan panic!.
Listing 12-9 menunjukkan perubahan yang perlu kita buat pada nilai kembalian dari fungsi yang sekarang kita namakan Config::build ini beserta isi (body) fungsinya yang dibutuhkan buat mengembalikan Result. Perhatikan bahwa kode ini tidak bakal bisa di-compile sampai kita meng-update main juga, yang mana bakal kita lakukan di listing berikutnya.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Result dari Config::buildFungsi build kita mengembalikan sebuah Result dengan instance Config di kasus yang sukses dan string literal di kasus yang gagal. Nilai error kita bakal selalu berupa string literal yang punya lifetime 'static.
Kita sudah membuat dua perubahan di body fungsi tersebut: alih-alih memanggil panic! saat user tidak memberikan argumen yang cukup, kita sekarang mengembalikan sebuah nilai Err, dan kita sudah membungkus nilai kembalian Config di dalam sebuah Ok. Perubahan ini membuat fungsinya sesuai dengan signature tipe barunya.
Mengembalikan nilai Err dari Config::build memungkinkan fungsi main untuk menangani nilai Result yang dikembalikan dari fungsi build tersebut dan keluar dari proses dengan lebih rapi saat terjadi error.
Memanggil Config::build dan Menangani Error
Buat menangani kasus yang gagal (error) dan mencetak pesan yang user-friendly, kita perlu meng-update main untuk menangani Result yang dikembalikan oleh Config::build, seperti yang ditunjukkan di Listing 12-10. Kita juga bakal mengambil tanggung jawab untuk keluar dari alat command line dengan kode error bukan nol (nonzero error code) menjauh dari panic! dan malah mengimplementasikannya secara manual. Status keluar (exit status) bukan nol adalah sebuah konvensi untuk memberi tanda kepada proses yang memanggil program kita bahwa program kita telah keluar dengan state error.
use std::env;
use std::fs;
use std::process;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Config gagalDi listing ini, kita sudah memakai method yang belum pernah kita bahas secara mendetail: unwrap_or_else, yang didefinisikan pada Result<T, E> oleh standard library. Pemakaian unwrap_or_else memungkinkan kita buat mendefinisikan penanganan error kustom yang tidak menggunakan panic!. Kalau Result-nya adalah nilai Ok, method ini bakal berperilaku mirip seperti unwrap: ia mengembalikan nilai di dalam yang sedang dibungkus oleh Ok. Namun, kalau nilainya adalah sebuah nilai Err, method ini memanggil kode yang ada di dalam sebuah closure, yakni sebuah fungsi anonim yang kita definisikan dan kita kirimkan sebagai argumen ke unwrap_or_else. Kita bakal membahas closures lebih dalam di Bab 13. Buat sekarang, kita cuma perlu tahu kalau unwrap_or_else bakal meneruskan nilai yang ada di dalam Err, yang mana di kasus ini adalah string statis "not enough arguments" yang kita tambahkan di Listing 12-9, ke closure kita di dalam argumen err yang muncul di antara tanda garis vertikal (|). Kode di dalam closure tersebut kemudian bisa memakai nilai err itu saat dia berjalan.
Kita sudah menambahkan satu baris use baru buat membawa process dari standard library ke dalam scope. Kode di dalam closure yang bakal berjalan di kasus error ini cuma terdiri dari dua baris: kita mencetak nilai err lalu memanggil process::exit. Fungsi process::exit bakal menghentikan programnya secara instan dan mengembalikan angka yang diteruskan sebagai kode exit status. Hal ini mirip seperti penanganan berbasis panic! yang kita pakai di Listing 12-8, tapi kita tidak lagi dapat semua output ekstra. Mari kita coba:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/minigrep`
Problem parsing arguments: not enough arguments
Bagus! Output ini jauh lebih friendly (ramah) buat para user kita.
Mengekstrak Logika dari Fungsi main
Sekarang setelah kita selesai me-refactor penguraian (parsing) konfigurasi, mari kita beralih ke logika programnya. Seperti yang kita nyatakan di “Separation of Concerns (Pemisahan Kepentingan) untuk Binary Projects”, kita bakal mengekstrak sebuah fungsi bernama run yang bakal menampung semua logika yang saat ini ada di fungsi main yang tidak berkaitan dengan menyiapkan konfigurasi atau menangani error. Setelah kita selesai, fungsi main bakal ringkas dan gampang diverifikasi hanya dengan melihatnya, dan kita bakal bisa menulis pengujian untuk semua logika lainnya.
Listing 12-11 menunjukkan peningkatan kecil dan bertahap berupa mengekstrak sebuah fungsi run.
use std::env;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) {
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}run yang mengandung sisa dari logika programFungsi run sekarang mengandung semua sisa logika dari main, mulai dari bagian membaca file. Fungsi run menerima instance Config sebagai argumennya.
Mengembalikan Error dari Fungsi run
Dengan sisa logika program yang sudah dipisahkan ke fungsi run, kita bisa meningkatkan penanganan error-nya, sama seperti yang kita lakukan dengan Config::build di Listing 12-9. Bukannya ngebiarin program kita mengalami panic dengan memanggil expect, fungsi run bakal mengembalikan Result<T, E> pas terjadi sesuatu yang salah. Hal ini bakal membiarkan kita buat mengonsolidasi (menyatukan) logika seputar penanganan error ke dalam main lebih jauh lagi dengan cara yang ramah buat user. Listing 12-12 menunjukkan perubahan yang perlu kita buat pada signature dan body dari run.
use std::env;
use std::fs;
use std::process;
use std::error::Error;
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}run agar mengembalikan ResultKita sudah membuat tiga perubahan yang signifikan di sini. Pertama, kita mengubah tipe kembalian (return type) dari fungsi run jadi Result<(), Box<dyn Error>>. Fungsi ini sebelumnya mengembalikan tipe unit, (), dan kita mempertahankan itu sebagai nilai yang dikembalikan pada kasus yang sukses (Ok).
Buat tipe error-nya, kita memakai trait object Box<dyn Error> (dan kita juga sudah membawa std::error::Error ke dalam scope dengan statement use di paling atas). Kita bakal membahas trait objects di Bab 18. Buat sekarang, cukup ketahui kalau Box<dyn Error> berarti fungsinya bakal mengembalikan sebuah tipe yang mengimplementasikan trait Error, tapi kita tidak usah menentukan dengan spesifik tipe apa nilai kembaliannya. Ini ngasih kita fleksibilitas buat mengembalikan nilai-nilai error yang mungkin bertipe beda-beda di kasus error yang berbeda-beda. Keyword dyn itu singkatan dari dynamic (dinamis).
Kedua, kita telah menghapus pemanggilan expect dan menggantinya dengan operator ?, seperti yang kita bicarakan di Bab 9. Bukannya melakukan panic! pas ada error, ? bakal mengembalikan nilai error dari fungsi saat ini agar si pemanggil fungsi yang menangani error-nya.
Ketiga, fungsi run kini mengembalikan nilai Ok pada kasus yang sukses. Kita sudah mendeklarasikan kalau tipe sukses dari fungsi run adalah () pada signature-nya, yang artinya kita perlu membungkus nilai tipe unit tersebut di dalam sebuah nilai Ok. Sintaks Ok(()) ini mungkin kelihatannya agak aneh pas awal-awal, tapi memakai () kayak gini adalah cara yang idiomatik buat menunjukkan kalau kita memanggil run murni hanya karena side effects (efek samping)-nya aja; ia tidak mengembalikan nilai yang kita perlukan.
Saat kita menjalankan kode ini, kode ini bakal berhasil di-compile tapi bakal menampilkan sebuah warning (peringatan):
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
warning: unused `Result` that must be used
--> src/main.rs:19:5
|
19 | run(config);
| ^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
19 | let _ = run(config);
| +++++++
warning: `minigrep` (bin "minigrep") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.71s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Rust ngasih tahu kita kalau kode kita mengabaikan nilai Result, padahal nilai Result itu mungkin menunjukkan kalau terjadi sebuah error. Tapi kita tidak mengecek apakah memang terjadi error atau tidak, dan compiler mengingatkan kita kalau kita mungkin lupa menaruh kode penanganan error di sini! Mari kita bereskan masalah itu sekarang.
Menangani Error yang Dikembalikan oleh run di main
Kita bakal mengecek error dan menangani mereka memakai teknik yang mirip dengan yang kita pakai bersama Config::build di Listing 12-10, tapi dengan sedikit perbedaan:
Nama file: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Kita memakai if let bukannya unwrap_or_else buat mengecek apakah run mengembalikan nilai Err dan memanggil process::exit(1) jika iya. Fungsi run tidak mengembalikan sebuah nilai yang mau kita unwrap seperti Config::build yang mengembalikan instance Config. Karena run mengembalikan () pada kasus yang sukses, kita cuma peduli pada mendeteksi terjadinya error, jadi kita tidak perlu unwrap_or_else untuk mengembalikan nilai yang tidak terbungkus, yang mana hasilnya cuma bakal ().
Body dari if let dan fungsi di unwrap_or_else itu sama persis di kedua kasus: kita mencetak error-nya lalu kita keluar dari program.
Memisahkan Kode ke dalam sebuah Library Crate
Project minigrep kita sudah kelihatan bagus sejauh ini! Sekarang kita bakal memisahkan file src/main.rs dan menaruh sebagian kode ke dalam file src/lib.rs. Dengan begitu, kita bisa menguji kodenya dan bisa punya file src/main.rs dengan lebih sedikit tanggung jawab.
Mari kita definisikan kode yang bertanggung jawab untuk pencarian teks di dalam src/lib.rs ketimbang di src/main.rs, yang mana hal ini bakal membiarkan kita (atau siapa pun yang memakai library minigrep kita) untuk memanggil fungsi pencarian dari lebih banyak konteks dibanding hanya lewat binary minigrep kita.
Pertama, mari definisikan signature fungsi search di src/lib.rs seperti yang ditunjukkan di Listing 12-13, dengan isi (body) fungsi yang memanggil macro unimplemented!. Kita bakal menjelaskan signature-nya lebih detail pas kita mengisi implementasinya.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
unimplemented!();
}search di src/lib.rsKita sudah memakai keyword pub di definisi fungsinya untuk menunjuk search sebagai bagian dari API public dari library crate kita. Sekarang kita sudah punya sebuah library crate yang bisa kita pakai dari binary crate kita dan yang bisa kita tes!
Sekarang kita perlu membawa kode yang didefinisikan di src/lib.rs ke dalam scope dari binary crate di src/main.rs lalu memanggilnya, seperti yang ditunjukkan di Listing 12-14.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
// --snip--
use minigrep::search;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
for line in search(&config.query, &contents) {
println!("{line}");
}
Ok(())
}search dari library crate minigrep di dalam src/main.rsKita menambahkan baris use minigrep::search untuk membawa fungsi search dari library crate ke dalam scope dari binary crate. Lalu, di dalam fungsi run, alih-alih mencetak konten dari file tersebut, kita memanggil fungsi search dan meneruskan nilai config.query dan contents sebagai argumennya. Setelah itu, run bakal memakai for loop buat mencetak setiap baris yang dikembalikan oleh search yang cocok dengan kueri (query) pencariannya. Ini juga waktu yang tepat buat menghapus pemanggilan println! di dalam fungsi main yang tadi menampilkan kueri dan path file sehingga program kita cuma mencetak hasil pencariannya aja (kalau tidak ada error yang terjadi).
Perhatikan bahwa fungsi pencarian bakal mengumpulkan semua hasil ke dalam sebuah vector yang dikembalikannya sebelum terjadi pencetakan ke layar. Implementasi ini bisa jadi agak lambat untuk menampilkan hasil ketika mencari di file yang berukuran sangat besar karena hasilnya tidak langsung dicetak saat ditemukan; kita bakal mendiskusikan kemungkinan untuk memperbaiki ini dengan memakai iterators di Bab 13.
Huft! Kerjaan yang lumayan banyak ya, tapi kita udah nyiapin diri buat kesuksesan di masa depan. Sekarang jauh lebih gampang buat menangani error, dan kita sudah membuat kodenya jadi lebih modular. Mulai dari sini, hampir semua pekerjaan kita bakal dilakukan di src/lib.rs.
Mari kita manfaatkan modularitas yang baru kita dapatkan ini dengan melakukan sesuatu yang bakal susah sekali dilakuin sama kode kita yang lama tapi sangat gampang dengan kode yang baru: kita bakal nulis beberapa tests (pengujian)!
Menambah Fungsionalitas dengan Test Driven Development
Mengembangkan Fungsionalitas Library dengan Test-Driven Development
Sekarang setelah logika pencarian kita terpisah di src/lib.rs dari fungsi
main, jauh lebih mudah untuk menulis pengujian buat fungsionalitas inti dari
kode kita. Kita bisa memanggil fungsi secara langsung dengan berbagai argumen
dan mengecek nilai kembaliannya tanpa perlu menjalankan binary kita dari
command line.
Di bagian ini, kita bakal menambahkan logika pencarian ke program minigrep
memakai proses test-driven development (TDD) dengan langkah-langkah berikut:
- Tulis sebuah pengujian yang gagal lalu jalankan buat memastikan kalau pengujian itu gagal dengan alasan yang kita harapkan.
- Tulis atau ubah kode secukupnya saja buat bikin pengujian baru itu sukses.
- Refactor (rombak) kode yang baru saja ditambahkan atau diubah dan pastikan pengujiannya tetap sukses.
- Ulangi lagi dari langkah 1!
Meskipun ini cuma salah satu dari sekian banyak cara buat nulis software, TDD bisa membantu mengarahkan desain kode. Menulis pengujian sebelum kita menulis kode yang bakal membuat pengujian itu sukses membantu mempertahankan test coverage (cakupan pengujian) yang tinggi di sepanjang proses.
Kita bakal menguji-kembangkan (test-drive) implementasi fungsionalitas yang
nantinya bakal benar-benar melakukan pencarian string kueri di dalam isi file
lalu menghasilkan daftar baris yang cocok dengan kueri tersebut. Kita bakal
menambahkan fungsionalitas ini ke dalam sebuah fungsi bernama search.
Menulis Pengujian yang Gagal
Di src/lib.rs, kita bakal menambahkan modul tests dengan fungsi pengujiannya,
seperti yang kita lakukan di Bab 11. Fungsi pengujian ini
menentukan perilaku yang kita inginkan dari fungsi search: fungsi ini bakal
menerima sebuah kueri dan teks tempat kita mencari, lalu ia cuma bakal
mengembalikan baris-baris dari teks tersebut yang mengandung kuerinya. Listing
12-15 menunjukkan pengujian ini.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
unimplemented!();
}
// --snip--
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}search untuk fungsionalitas yang kita harapkan adaPengujian ini mencari string "duct". Teks yang lagi kita cari ada tiga baris,
dan cuma satu yang mengandung "duct" (perhatikan bahwa tanda backslash
setelah tanda kutip ganda pembuka memberi tahu Rust buat tidak menambahkan
karakter newline alias baris baru di awal konten string literal ini). Kita
menegaskan bahwa nilai yang dikembalikan oleh fungsi search cuma berisi
baris yang kita harapkan.
Kalau kita menjalankan pengujian ini sekarang, ia bakal gagal karena macro
unimplemented! mengalami panic dengan pesan “not implemented”. Mengikuti
prinsip-prinsip TDD, kita bakal mengambil langkah kecil dengan menambahkan kode
secukupnya agar pengujian ini tidak panic saat memanggil fungsi tersebut; kita
lakukan dengan mendefinisikan fungsi search agar selalu mengembalikan vector
kosong, seperti yang ditunjukkan di Listing 12-16. Kemudian pengujian ini
seharusnya berhasil di-compile dan lalu gagal karena vector kosong tidak cocok
dengan vector yang isinya baris "safe, fast, productive."
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
vec![]
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}search secukupnya saja sehingga ia tidak panic saat dipanggilSekarang mari kita bahas kenapa kita perlu mendefinisikan lifetime 'a secara
eksplisit di signature fungsi search dan memakai lifetime itu bersama
argumen contents dan nilai kembaliannya. Ingat kembali di Bab 10
bahwa parameter lifetime menentukan lifetime argumen mana yang terhubung
dengan lifetime nilai kembaliannya. Di kasus ini, kita mengindikasikan kalau
vector yang dikembalikan seharusnya berisi string slices yang merujuk pada
slices dari argumen contents (bukannya dari argumen query).
Dengan kata lain, kita memberi tahu Rust kalau data yang dikembalikan oleh fungsi
search bakal hidup (live) selama data yang diteruskan ke dalam fungsi search
lewat argumen contents. Ini penting! Data yang dirujuk oleh sebuah slice
harus tetap valid agar referensinya juga ikut valid; kalau compiler
mengasumsikan kalau kita lagi bikin string slices dari query bukannya
contents, pengecekan keamanannya bakal dilakukan dengan tidak tepat.
Kalau kita kelupaan menganotasi lifetime dan mencoba men-compile fungsi ini, kita bakal dapat error ini:
$ cargo build
Compiling minigrep v0.1.0 (file:///projects/minigrep)
error[E0106]: missing lifetime specifier
--> src/lib.rs:1:51
|
1 | pub fn search(query: &str, contents: &str) -> Vec<&str> {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `query` or `contents`
help: consider introducing a named lifetime parameter
|
1 | pub fn search<'a>(query: &'a str, contents: &'a str) -> Vec<&'a str> {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `minigrep` (lib) due to 1 previous error
Rust tidak bisa tahu pasti dari kedua parameter ini mana yang kita butuhkan buat
outputnya, jadi kita harus memberitahukannya secara eksplisit. Perhatikan bahwa
teks bantuannya menyarankan buat menentukan parameter lifetime yang sama buat
semua parameter beserta tipe outputnya, yang mana itu salah! Karena contents
adalah parameter yang berisi semua teks kita dan kita mau mengembalikan
bagian-bagian dari teks itu yang cocok, kita jadi tahu kalau cuma parameter
contents yang seharusnya dihubungkan dengan nilai kembaliannya menggunakan
sintaks lifetime.
Bahasa pemrograman lain biasanya tidak mengharuskan kita buat menghubungkan argumen dengan nilai kembalian di signature-nya, tapi praktik ini bakal terasa lebih mudah seiring berjalannya waktu. Kita mungkin mau membandingkan contoh ini dengan contoh-contoh di bagian “Memvalidasi Referensi dengan Lifetimes” di Bab 10.
Menulis Kode Agar Pengujian Sukses
Saat ini, pengujian kita gagal karena kita selalu mengembalikan vector kosong.
Buat memperbaikinya dan mengimplementasikan search, program kita harus mengikuti
langkah-langkah berikut:
- Iterasi melewati setiap baris dari konten.
- Mengecek apakah baris tersebut mengandung string kueri kita.
- Jika iya, tambahkan baris itu ke daftar nilai yang bakal kita kembalikan.
- Jika tidak, jangan lakukan apa-apa.
- Kembalikan daftar hasil yang cocok.
Mari kerjakan satu per satu setiap langkahnya, dimulai dari iterasi melewati baris-baris.
Iterasi Melewati Baris dengan Method lines
Rust punya method yang membantu sekali buat menangani iterasi baris per baris
dari strings, dinamai dengan nama yang nyaman yaitu lines, yang bekerja seperti
yang ditunjukkan di Listing 12-17. Perhatikan kalau kode ini belum bisa di-compile.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
// do something with line
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}contentsMethod lines mengembalikan sebuah iterator. Kita bakal membahas iterator lebih
mendalam di Bab 13, tapi ingat kembali bahwa kita pernah
melihat cara memakai iterator seperti ini di Listing 3-5, di mana
kita memakai for loop dengan sebuah iterator buat menjalankan beberapa kode
pada setiap item di dalam sebuah collection (koleksi).
Mencari Kueri di Setiap Baris
Berikutnya, kita bakal mengecek apakah baris saat ini mengandung string kueri
kita. Untungnya, tipe string punya method pembantu (helper) bernama contains
yang ngelakuin persis apa yang kita butuhkan! Tambahkan pemanggilan ke method
contains di dalam fungsi search, seperti yang ditunjukkan di Listing 12-18.
Perhatikan kalau kode ini masih belum bisa di-compile.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
if line.contains(query) {
// do something with line
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}querySaat ini, kita baru membangun fungsionalitasnya. Supaya kodenya bisa di-compile, kita perlu mengembalikan sebuah nilai dari body fungsi sesuai indikasi yang kita berikan di signature fungsi.
Menyimpan Baris yang Cocok
Buat menyelesaikan fungsi ini, kita butuh cara buat menyimpan baris-baris yang
cocok yang mau kita kembalikan. Buat melakukan itu, kita bisa membuat vector
mutable sebelum for loop lalu memanggil method push buat menyimpan line
ke dalam vector tersebut. Setelah for loop selesai, kita mengembalikan
vector-nya, seperti yang ditunjukkan di Listing 12-19.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Sekarang fungsi search seharusnya hanya mengembalikan baris-baris yang
mengandung query, dan pengujian kita seharusnya sukses. Mari kita jalankan
pengujiannya:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.22s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 1 test
test tests::one_result ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Pengujian kita sukses, jadi kita tahu kalau ini berfungsi!
Di titik ini, kita bisa mempertimbangkan peluang buat me-refactor implementasi dari fungsi pencarian sambil menjaga agar pengujiannya tetap sukses demi mempertahankan fungsionalitas yang sama. Kode di fungsi pencariannya tidak terlalu jelek sih, tapi dia tidak memanfaatkan beberapa fitur iterator yang sangat berguna. Kita bakal kembali lagi ke contoh ini di Bab 13, di mana kita bakal mengeksplorasi iterator lebih dalam, dan melihat gimana cara meningkatkannya.
Sekarang keseluruhan programnya seharusnya sudah bisa jalan! Mari kita coba, pertama dengan kata yang seharusnya cuma mengembalikan satu baris persis dari puisi Emily Dickinson: frog.
$ cargo run -- frog poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.38s
Running `target/debug/minigrep frog poem.txt`
How public, like a frog
Keren! Sekarang mari kita coba pakai kata yang bakal cocok dengan beberapa baris sekaligus, misalnya body:
$ cargo run -- body poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep body poem.txt`
I'm nobody! Who are you?
Are you nobody, too?
How dreary to be somebody!
Dan terakhir, mari kita pastikan kalau kita tidak dapat baris apa pun ketika kita mencari kata yang sama sekali tidak ada di dalam puisinya, misalnya monomorphization:
$ cargo run -- monomorphization poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep monomorphization poem.txt`
Luar biasa! Kita sudah membangun versi mini kita sendiri dari alat klasik dan belajar banyak hal soal cara menata aplikasi. Kita juga belajar sedikit tentang input dan output file, lifetimes, pengujian, dan penguraian command line.
Buat melengkapi project ini, kita bakal mendemonstrasikan secara singkat gimana cara berurusan dengan environment variables (variabel lingkungan) dan gimana cara mencetak pesan ke standard error, yang mana keduanya sangat berguna pas kita lagi nulis program command line.
Bekerja dengan Variabel Lingkungan (Environment Variables)
Berurusan dengan Environment Variables
Kita bakal meningkatkan binary minigrep dengan menambahkan fitur tambahan:
opsi pencarian case-insensitive (tidak membedakan huruf besar/kecil) yang
bisa dinyalakan oleh user via environment variable (variabel lingkungan).
Kita bisa saja bikin fitur ini jadi opsi di command line dan mewajibkan
user buat memasukkannya setiap kali mereka mau fitur itu aktif, tapi dengan
menjadikannya environment variable, kita membiarkan para user untuk menge-set
environment variable-nya sekali saja dan semua pencarian mereka bakal jadi
case-insensitive selama sesi terminal (terminal session) tersebut.
Menulis Pengujian yang Gagal buat Fungsi search yang Case-Insensitive
Pertama-tama kita menambahkan fungsi search_case_insensitive baru ke library
minigrep yang bakal dipanggil pas environment variable-nya punya nilai. Kita
bakal terus ngikutin proses TDD, jadi langkah pertamanya adalah kembali menulis
pengujian yang gagal. Kita bakal menambahkan pengujian baru buat fungsi baru
search_case_insensitive ini lalu me-rename pengujian lama kita dari
one_result jadi case_sensitive buat memperjelas perbedaan di antara kedua
pengujian ini, seperti yang ditunjukkan di Listing 12-20.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Perhatikan bahwa kita juga sudah ngedit contents di pengujian lama. Kita
menambahkan satu baris baru dengan teks "Duct tape." yang memakai huruf D
kapital yang tidak boleh cocok dengan kueri "duct" ketika kita lagi mencari
dengan metode pencarian yang case-sensitive. Ngubah pengujian lama dengan
cara ini ngebantu kita memastikan kalau kita tidak bakal tidak sengaja merusak
fungsionalitas pencarian case-sensitive yang sudah kita implementasikan.
Pengujian ini seharusnya sukses sekarang dan bakal terus sukses saat kita
ngerjain fungsi pencarian yang case-insensitive.
Pengujian baru buat pencarian yang case-insensitive ini memakai "rUsT"
sebagai kuerinya. Di dalam fungsi search_case_insensitive yang bakal kita
tambahkan nanti, kueri "rUsT" ini seharusnya cocok sama baris yang
mengandung "Rust:" dengan huruf R kapital, dan juga cocok sama baris
"Trust me." biarpun casing (huruf besar/kecil)-nya berbeda dari kueri aslinya.
Ini adalah pengujian kita yang gagal, dan pengujian ini bakal gagal di-compile
karena kita belum mendefinisikan fungsi search_case_insensitive. Kalau mau,
silakan tambahkan implementasi kerangkanya yang selalu mengembalikan vector
kosong, mirip kayak yang kita lakukan buat fungsi search di Listing 12-16 buat
melihat pengujiannya berhasil di-compile lalu gagal.
Mengimplementasikan Fungsi search_case_insensitive
Fungsi search_case_insensitive, yang ditunjukkan di Listing 12-21, bakal
mirip sekali sama fungsi search. Satu-satunya perbedaan adalah kita bakal
mengubah query dan setiap line jadi huruf kecil (lowercase) agar tidak peduli
apa casing dari argumen inputnya, mereka bakal punya casing yang sama pas
kita mengecek apakah baris tersebut mengandung kuerinya.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}search_case_insensitive agar mengubah kueri dan baris teks jadi huruf kecil sebelum membandingkan keduanyaPertama kita ngubah string query jadi huruf kecil lalu menyimpannya ke dalam
variabel baru dengan nama yang sama, menimpa (shadowing) variabel query aslinya.
Memanggil to_lowercase pada kueri ini diperlukan supaya tidak peduli apakah
kueri dari user itu "rust", "RUST", "Rust", atau "rUsT", kita bakal
memperlakukan kueri tersebut seolah-olah itu "rust" dan tidak mempedulikan
casing-nya. Meskipun to_lowercase bakal menangani Unicode dasar, fungsi ini
tidak 100 persen akurat. Kalau kita lagi bikin aplikasi sungguhan, kita bakal
mau bekerja sedikit lebih jauh di sini, tapi bagian ini membahas tentang
environment variables, bukan Unicode, jadi kita biarkan saja seperti ini buat
sekarang.
Perhatikan bahwa query sekarang adalah tipe String bukannya string slice
karena pemanggilan to_lowercase itu membikin data baru alih-alih merujuk ke
data yang sudah ada. Katakanlah kuerinya itu "rUsT", sebagai contoh: string
slice tersebut tidak mengandung karakter u atau t kecil yang bisa kita
pakai, jadi kita harus mengalokasikan memori buat String baru yang mengandung
"rust". Saat kita meneruskan query sebagai argumen ke method contains
sekarang, kita perlu menambahkan ampersand (&) karena signature dari
contains didefinisikan buat nerima string slice.
Selanjutnya, kita nambahin panggilan ke to_lowercase di setiap line buat
mengubah semua karakternya jadi huruf kecil. Sekarang karena kita udah mengonversi
baik line maupun query jadi huruf kecil, kita bakal menemukan baris yang
cocok tidak peduli apa casing kuerinya.
Mari kita lihat apakah implementasi ini berhasil melewati pengujian:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.33s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 2 tests
test tests::case_insensitive ... ok
test tests::case_sensitive ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Mantap! Mereka sukses. Sekarang, mari kita panggil fungsi
search_case_insensitive baru ini dari dalam fungsi run. Pertama kita bakal
menambahkan opsi konfigurasi ke struct Config buat beralih antara metode
pencarian case-sensitive dan case-insensitive. Nambahin field ini bakal
menghasilkan error compiler karena kita belum menginisialisasi field ini di
mana pun:
Nama file: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Kita nambahin field ignore_case yang menampung sebuah Boolean. Selanjutnya,
kita butuh fungsi run buat mengecek nilai dari field ignore_case lalu
memakai nilai itu buat menentukan apakah harus memanggil fungsi search atau
fungsi search_case_insensitive, seperti yang ditunjukkan di Listing 12-22.
Ini masih belum bisa di-compile.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}search atau search_case_insensitive berdasarkan nilai dari config.ignore_caseTerakhir, kita perlu mengecek apakah environment variable-nya diset.
Fungsi-fungsi buat berinteraksi dengan environment variables berada di
dalam modul env di standard library, yang mana sudah berada di dalam
scope di bagian paling atas src/main.rs. Kita bakal memakai fungsi var
dari modul env buat mengecek dan melihat apakah ada nilai yang sudah diset
buat environment variable bernama IGNORE_CASE, seperti yang ditunjukkan
di Listing 12-23.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}IGNORE_CASEDi sini, kita membuat variabel baru, ignore_case. Buat menge-set nilainya,
kita memanggil fungsi env::var dan meneruskan nama dari environment
variable IGNORE_CASE kepadanya. Fungsi env::var mengembalikan sebuah
Result yang bakal jadi varian sukses Ok yang berisi nilai dari
environment variable tersebut jika ia telah diset dengan nilai apa pun. Ia
bakal mengembalikan varian Err kalau environment variable-nya tidak diset.
Kita memakai method is_ok pada Result tersebut buat mengecek apakah
environment variable-nya diset, yang berarti programnya seharusnya melakukan
pencarian secara case-insensitive. Kalau environment variable IGNORE_CASE
tidak diset sama sekali, is_ok bakal mengembalikan false dan programnya
bakal melakukan pencarian case-sensitive. Kita tidak peduli dengan nilai
dari environment variable-nya, yang penting dia diset atau tidak aja,
makanya kita memakai is_ok dan tidak memakai unwrap, expect, atau
method lain dari Result yang sudah kita lihat sebelumnya.
Kita meneruskan nilai di variabel ignore_case ke instance Config agar
fungsi run bisa ngebaca nilai itu dan memutuskan apakah bakal memanggil
search_case_insensitive atau search, seperti yang sudah kita implementasikan
di Listing 12-22.
Mari kita coba! Pertama kita bakal jalankan program kita tanpa menge-set
environment variable apa pun dan memakai kueri to, yang mana seharusnya
cocok dengan baris mana pun yang mengandung kata to dalam huruf kecil semua:
$ cargo run -- to poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep to poem.txt`
Are you nobody, too?
How dreary to be somebody!
Sepertinya masih jalan dengan baik! Sekarang mari kita jalankan programnya
dengan IGNORE_CASE diset ke 1 tapi dengan kueri to yang sama:
$ IGNORE_CASE=1 cargo run -- to poem.txt
Kalau kita pakai PowerShell, kita perlu menge-set environment variable-nya lalu menjalankan programnya sebagai dua command yang terpisah:
PS> $Env:IGNORE_CASE=1; cargo run -- to poem.txt
Ini bakal membikin IGNORE_CASE bertahan (persist) sepanjang sisa sesi shell
kita. Ia bisa di-unset pakai cmdlet Remove-Item:
PS> Remove-Item Env:IGNORE_CASE
Kita seharusnya mendapatkan baris-baris yang mengandung to yang mungkin huruf-hurufnya kapital:
Are you nobody, too?
How dreary to be somebody!
To tell your name the livelong day
To an admiring bog!
Hebat, kita juga dapat baris yang mengandung To! Program minigrep kita
sekarang bisa melakukan pencarian case-insensitive yang dikendalikan oleh
sebuah environment variable. Sekarang kita tahu gimana caranya mengatur opsi
yang diset melalui argumen command line maupun environment variables.
Beberapa program mengizinkan pemakaian argumen dan environment variables buat tujuan konfigurasi yang sama. Di kasus seperti itu, program-program tersebut harus memutuskan mana yang harus didahulukan (precedence). Sebagai latihan, cobalah mengatur opsi case sensitivity (kepekaan huruf besar/kecil) melalui argumen command line atau environment variable. Putuskan apakah argumen command line atau environment variable yang seharusnya lebih didahulukan kalau ternyata programnya dijalankan dengan salah satu opsi dijadikan case-sensitive sementara opsi lainnya diset untuk mengabaikan casing.
Modul std::env berisi banyak lagi fitur yang berguna buat berurusan dengan
environment variables: cek dokumentasinya buat melihat fitur apa saja yang
tersedia.
Mengarahkan Error ke Standard Error
Menulis Pesan Error ke Standard Error Bukannya Standard Output
Saat ini, kita menulis semua output ke terminal memakai macro println!. Di
sebagian besar terminal, ada dua jenis output: standard output (stdout)
buat informasi umum dan standard error (stderr) buat pesan-pesan error.
Pemisahan ini memungkinkan para user untuk memilih buat mengarahkan
(redirect) output yang sukses dari suatu program ke sebuah file, tapi tetap
bisa mencetak pesan-pesan error ke layar.
Macro println! cuma bisa mencetak ke standard output, jadi kita harus
pakai sesuatu yang lain buat bisa mencetak ke standard error.
Mengecek Ke Mana Error Ditulis
Pertama-tama mari kita amati gimana konten yang dicetak oleh minigrep saat
ini ditulis ke standard output, termasuk pesan-pesan error apa pun yang
sebenarnya mau kita tulis ke standard error. Kita bakal ngelakuin itu dengan
mengarahkan stream standard output ke sebuah file sementara kita sengaja
membikin sebuah error. Kita tidak akan mengarahkan stream standard error,
jadi konten apa pun yang dikirim ke standard error bakal tetap ditampilkan
di layar.
Program-program command line umumnya diharapkan bakal mengirim pesan error ke stream standard error supaya kita masih bisa melihat pesan-pesan error di layar bahkan kalau kita mengarahkan stream standard output ke sebuah file. Program kita saat ini belum berperilaku dengan baik: kita bakal segera melihat kalau dia malah menyimpan output pesan error-nya ke sebuah file!
Buat mendemonstrasikan perilaku ini, kita bakal menjalankan programnya dengan
> dan path file, output.txt, ke mana kita mau mengarahkan stream standard
output. Kita tidak akan memasukkan argumen apa pun, yang mana seharusnya bakal
menyebabkan error:
$ cargo run > output.txt
Sintaks > memberi tahu shell (terminal) buat menulis konten dari standard
output ke output.txt ketimbang menampilkannya ke layar. Kita ternyata tidak
melihat pesan error yang kita harapkan tercetak di layar, jadi itu artinya pesan
tersebut pasti berujung di dalam file itu. Inilah apa yang terkandung di dalam
output.txt:
Problem parsing arguments: not enough arguments
Yup, pesan error kita benar-benar dicetak ke standard output. Bakal jauh lebih berguna kalau pesan-pesan error semacam ini dicetak ke standard error sehingga hanya data dari proses yang berjalan dengan sukses saja yang bakal berakhir di dalam file tersebut. Kita bakal mengubah hal itu.
Mencetak Error ke Standard Error
Kita bakal memakai kode di Listing 12-24 buat mengubah gimana pesan-pesan error
dicetak. Karena perombakan (refactoring) yang kita lakuin sebelumnya di bab ini,
semua kode yang mencetak pesan error ada di satu fungsi aja, yaitu main.
Standard library menyediakan macro eprintln! yang bisa mencetak ke stream
standard error, jadi mari ubah dua tempat di mana kita memakai println! buat
mencetak error agar memakai eprintln! sebagai gantinya.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}eprintln!Sekarang mari kita coba jalankan lagi programnya pakai cara yang sama, tanpa
argumen apa pun dan mengarahkan standard output pakai >:
$ cargo run > output.txt
Problem parsing arguments: not enough arguments
Sekarang kita bisa melihat pesan error-nya di layar dan output.txt isinya kosong, yang mana ini persis seperti perilaku yang kita harapkan dari program-program command line.
Mari kita jalankan programnya sekali lagi, kali ini dengan argumen-argumen yang tidak bakal menyebabkan error tapi kita tetap mengarahkan standard output ke sebuah file, kayak gini:
$ cargo run -- to poem.txt > output.txt
Kita tidak akan melihat output apa pun di terminal, dan output.txt bakal berisi hasil-hasil pencarian kita:
Nama file: output.txt
Are you nobody, too?
How dreary to be somebody!
Ini mendemonstrasikan kalau sekarang kita sudah memakai standard output buat output yang sukses dan memakai standard error buat output yang berupa error sebagaimana mestinya.
Ringkasan
Bab ini merangkum (recap) beberapa konsep besar yang udah kita pelajarin sejauh
ini dan membahas soal gimana caranya ngejalanin operasi I/O (Input/Output)
umum di Rust. Dengan memakai argumen command line, file, environment variables,
dan macro eprintln! buat mencetak error, kita sekarang sudah siap buat nulis
berbagai aplikasi command line. Digabungkan dengan konsep-konsep dari bab-bab
sebelumnya, kode kita bakal terorganisir dengan rapi, menyimpan data secara efektif
di struktur data yang tepat, menangani error dengan apik, dan telah teruji dengan
baik.
Berikutnya, kita bakal mengeksplorasi beberapa fitur di Rust yang dipengaruhi oleh bahasa pemrograman fungsional: closures dan iterators.
Fitur Bahasa Fungsional: Iterators dan Closures
Desain Rust mengambil inspirasi dari banyak bahasa dan teknik pemrograman yang sudah ada, dan salah satu pengaruh yang signifikan adalah functional programming (pemrograman fungsional). Pemrograman dengan gaya fungsional sering kali mencakup penggunaan fungsi sebagai nilai, yaitu dengan memasukkan fungsi sebagai argumen, mengembalikannya dari fungsi lain, menaruhnya ke variabel untuk dieksekusi nanti, dan seterusnya.
Di bab ini, kita tidak akan berdebat soal apa itu pemrograman fungsional atau apa yang bukan, tapi kita bakal membahas beberapa fitur Rust yang mirip dengan fitur-fitur di banyak bahasa pemrograman yang sering disebut sebagai bahasa fungsional.
Secara lebih spesifik, kita bakal membahas:
- Closures, sebuah struktur mirip fungsi yang bisa kita simpan di dalam sebuah variabel
- Iterators, sebuah cara buat memproses serangkaian elemen
- Gimana cara memakai closures dan iterators buat meningkatkan project I/O yang kita buat di Bab 12
- Performa dari closures dan iterators (bocoran: performa mereka lebih cepat dari yang mungkin kita bayangkan!)
Kita sebenarnya sudah membahas beberapa fitur Rust lainnya, seperti pattern matching dan enums, yang juga terpengaruh oleh gaya fungsional. Karena menguasai closures dan iterators adalah bagian penting dari menulis kode Rust yang idiomatik dan kencang, kita bakal mendedikasikan seluruh bab ini buat membahas mereka.
Closures
Closures: Fungsi Anonim yang Bisa Menangkap Lingkungannya
Closures di Rust adalah fungsi anonim (tanpa nama) yang bisa kita simpan di dalam sebuah variabel atau diteruskan sebagai argumen ke fungsi lain. Kita bisa membuat sebuah closure di satu tempat lalu memanggil closure tersebut di tempat lain untuk dievaluasi dalam konteks yang berbeda. Tidak seperti fungsi biasa, closures bisa menangkap (capture) nilai-nilai dari scope tempat mereka didefinisikan. Kita bakal mendemonstrasikan gimana fitur-fitur closure ini memungkinkan penggunaan ulang kode dan kustomisasi perilaku.
Menangkap Lingkungan Menggunakan Closures
Pertama-tama kita bakal meneliti gimana kita bisa memakai closures buat menangkap nilai dari lingkungan tempat mereka didefinisikan untuk dipakai nanti. Berikut skenarionya: sesekali, perusahaan kaos kita membagikan kaos edisi terbatas eksklusif kepada seseorang di mailing list kita sebagai bentuk promosi. Orang-orang di mailing list bisa secara opsional menambahkan warna favorit mereka ke profilnya. Kalau orang yang terpilih untuk dapat kaos gratis itu sudah menge-set warna favoritnya, dia bakal dapat kaos dengan warna itu. Tapi kalau orang tersebut belum menentukan warna favorit, dia bakal dapat warna apa pun yang saat itu stoknya paling banyak di perusahaan.
Ada banyak cara buat mengimplementasikan ini. Buat contoh ini, kita bakal
memakai sebuah enum bernama ShirtColor yang punya varian Red (merah) dan
Blue (biru) (kita membatasi jumlah warna yang ada biar simpel). Kita mewakili
stok barang milik perusahaan dengan sebuah struct Inventory yang punya field
bernama shirts yang berisi sebuah Vec<ShirtColor> yang merepresentasikan
warna-warna kaos yang saat ini ada di stok. Method giveaway yang didefinisikan
pada Inventory menerima preferensi warna kaos opsional dari pemenang kaos
gratis, lalu mengembalikan warna kaos yang bakal didapat oleh orang tersebut.
Persiapan ini ditunjukkan di Listing 13-1.
#[derive(Debug, PartialEq, Copy, Clone)]
enum ShirtColor {
Red,
Blue,
}
struct Inventory {
shirts: Vec<ShirtColor>,
}
impl Inventory {
fn giveaway(&self, user_preference: Option<ShirtColor>) -> ShirtColor {
user_preference.unwrap_or_else(|| self.most_stocked())
}
fn most_stocked(&self) -> ShirtColor {
let mut num_red = 0;
let mut num_blue = 0;
for color in &self.shirts {
match color {
ShirtColor::Red => num_red += 1,
ShirtColor::Blue => num_blue += 1,
}
}
if num_red > num_blue {
ShirtColor::Red
} else {
ShirtColor::Blue
}
}
}
fn main() {
let store = Inventory {
shirts: vec![ShirtColor::Blue, ShirtColor::Red, ShirtColor::Blue],
};
let user_pref1 = Some(ShirtColor::Red);
let giveaway1 = store.giveaway(user_pref1);
println!(
"The user with preference {:?} gets {:?}",
user_pref1, giveaway1
);
let user_pref2 = None;
let giveaway2 = store.giveaway(user_pref2);
println!(
"The user with preference {:?} gets {:?}",
user_pref2, giveaway2
);
}Toko (store) yang didefinisikan di fungsi main punya dua kaos biru dan satu
kaos merah yang tersisa untuk dibagikan dalam promosi edisi terbatas ini. Kita
memanggil method giveaway untuk seorang user dengan preferensi kaos merah
dan seorang user tanpa preferensi sama sekali.
Sekali lagi, kode ini bisa saja diimplementasikan dengan banyak cara, dan di
sini, untuk fokus ke closures, kita cuma memakai konsep-konsep yang sudah
kita pelajari, kecuali buat body dari method giveaway yang memakai sebuah
closure. Di method giveaway, kita menerima preferensi user sebagai sebuah
parameter bertipe Option<ShirtColor> lalu memanggil method unwrap_or_else
pada user_preference. Method unwrap_or_else pada Option<T>
didefinisikan oleh standard library. Method ini menerima satu argumen: sebuah
closure tanpa argumen apa pun yang mengembalikan sebuah nilai bertipe T
(tipe yang sama dengan yang disimpan di varian Some dari Option<T>, yang
mana di kasus ini adalah ShirtColor). Kalau Option<T> itu adalah varian
Some, unwrap_or_else bakal mengembalikan nilai dari dalam Some tersebut.
Tapi kalau Option<T> adalah varian None, unwrap_or_else bakal memanggil
closure-nya dan mengembalikan nilai yang dikembalikan oleh closure tersebut.
Kita menentukan ekspresi closure || self.most_stocked() sebagai argumen
untuk unwrap_or_else. Ini adalah sebuah closure yang tidak menerima parameter
apa pun (kalau closure-nya punya parameter, parameternya bakal muncul di antara
dua garis vertikal). Body dari closure ini memanggil self.most_stocked().
Kita mendefinisikan closure-nya di sini, dan implementasi dari unwrap_or_else
nanti bakal mengevaluasi closure ini kalau hasilnya memang dibutuhkan.
Menjalankan kode ini bakal mencetak output berikut:
$ cargo run
Compiling shirt-company v0.1.0 (file:///projects/shirt-company)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/shirt-company`
The user with preference Some(Red) gets Red
The user with preference None gets Blue
Satu aspek yang menarik di sini adalah kita sudah meneruskan sebuah closure
yang memanggil self.most_stocked() pada instance Inventory saat ini.
Standard library tidak perlu tahu apa-apa tentang tipe Inventory atau
ShirtColor yang kita definisikan, ataupun logika yang mau kita pakai di
skenario ini. Closure ini menangkap sebuah referensi immutable ke instance
Inventory self dan meneruskannya bersama kode yang kita tentukan ke method
unwrap_or_else. Di sisi lain, fungsi biasa tidak bisa menangkap lingkungan
mereka dengan cara seperti ini.
Inference dan Anotasi Tipe untuk Closure
Ada lebih banyak perbedaan antara fungsi biasa dan closures. Closures
biasanya tidak mengharuskan kita untuk menganotasi tipe dari parameter atau nilai
kembalian seperti yang diwajibkan oleh fungsi fn. Anotasi tipe diwajibkan
pada fungsi karena tipe-tipe tersebut adalah bagian dari antarmuka eksplisit yang
diekspos ke para pengguna fungsi tersebut. Mendefinisikan antarmuka ini secara
kaku penting untuk memastikan bahwa semua orang sepakat mengenai tipe-tipe nilai
yang dipakai dan dikembalikan oleh sebuah fungsi. Sebaliknya, closures tidak
dipakai dalam antarmuka yang terekspos seperti itu: mereka disimpan di dalam
variabel dan dipakai tanpa menamai mereka atau mengeksposnya ke pengguna library
kita.
Closures biasanya berukuran pendek dan hanya relevan di dalam konteks yang sempit, bukan di sembarang skenario acak. Di dalam batasan konteks ini, compiler bisa menebak (infer) tipe-tipe parameternya dan tipe kembaliannya, mirip dengan bagaimana ia bisa menebak tipe dari sebagian besar variabel (walaupun ada kasus-kasus langka di mana compiler juga membutuhkan anotasi tipe untuk closure).
Sama halnya dengan variabel, kita bisa menambahkan anotasi tipe kalau kita mau meningkatkan kejelasan secara eksplisit walau akibatnya kode kita bakal sedikit lebih bertele-tele (verbose) dari yang sebenarnya diperlukan. Menganotasi tipe buat sebuah closure bakal kelihatan seperti definisi yang ditunjukkan di Listing 13-2. Di contoh ini, kita mendefinisikan sebuah closure dan menyimpannya di dalam sebuah variabel, bukannya mendefinisikan closure tersebut tepat di tempat kita meneruskannya sebagai argumen seperti yang kita lakukan di Listing 13-1.
use std::thread;
use std::time::Duration;
fn generate_workout(intensity: u32, random_number: u32) {
let expensive_closure = |num: u32| -> u32 {
println!("calculating slowly...");
thread::sleep(Duration::from_secs(2));
num
};
if intensity < 25 {
println!("Today, do {} pushups!", expensive_closure(intensity));
println!("Next, do {} situps!", expensive_closure(intensity));
} else {
if random_number == 3 {
println!("Take a break today! Remember to stay hydrated!");
} else {
println!(
"Today, run for {} minutes!",
expensive_closure(intensity)
);
}
}
}
fn main() {
let simulated_user_specified_value = 10;
let simulated_random_number = 7;
generate_workout(simulated_user_specified_value, simulated_random_number);
}Dengan menambahkan anotasi tipe, sintaks closures jadi kelihatan lebih mirip
dengan sintaks fungsi biasa. Di sini, kita mendefinisikan sebuah fungsi yang
menambahkan 1 ke parameternya dan sebuah closure yang punya perilaku yang sama,
sebagai perbandingan. Kita sudah menambahkan sedikit spasi supaya bagian-bagian
yang relevan sejajar. Ini mengilustrasikan gimana sintaks closure itu mirip
dengan sintaks fungsi, kecuali di penggunaan garis vertikal (|) dan seberapa
banyak sintaks yang sifatnya opsional:
fn add_one_v1 (x: u32) -> u32 { x + 1 }
let add_one_v2 = |x: u32| -> u32 { x + 1 };
let add_one_v3 = |x| { x + 1 };
let add_one_v4 = |x| x + 1 ;Baris pertama menunjukkan sebuah definisi fungsi dan baris kedua menunjukkan
definisi closure yang dianotasi secara penuh. Di baris ketiga, kita membuang
anotasi tipe dari definisi closure. Di baris keempat, kita membuang kurung
kurawal, yang mana jadi opsional karena body dari closure ini hanya punya
satu ekspresi. Ini semua adalah definisi yang valid dan bakal menghasilkan
perilaku yang sama saat mereka dipanggil. Baris add_one_v3 dan add_one_v4
mewajibkan closures tersebut untuk dievaluasi agar kodenya bisa di-compile,
karena tipe-tipenya bakal ditebak berdasarkan gimana closures tersebut dipakai.
Ini mirip dengan bagaimana let v = Vec::new(); membutuhkan entah anotasi tipe
atau adanya nilai dengan tipe tertentu yang dimasukkan ke dalam Vec agar Rust
bisa menebak tipenya.
Buat definisi closure, compiler bakal menebak satu tipe konkret untuk masing-
masing parameternya dan juga untuk nilai kembaliannya. Misalnya, Listing 13-3
menunjukkan definisi closure singkat yang cuma mengembalikan nilai yang dia
terima sebagai parameter. Closure ini sebenarnya tidak terlalu berguna kecuali
buat tujuan contoh ini. Perhatikan bahwa kita tidak menambahkan anotasi tipe apa
pun di definisinya. Karena tidak ada anotasi tipe, kita bisa memanggil closure
ini dengan tipe apa pun, yang mana kita lakukan di sini dengan tipe String
untuk panggilan pertama. Kalau kita kemudian mencoba memanggil example_closure
dengan sebuah integer, kita bakal dapat error.
fn main() {
let example_closure = |x| x;
let s = example_closure(String::from("hello"));
let n = example_closure(5);
}Compiler ngasih kita error ini:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
error[E0308]: mismatched types
--> src/main.rs:5:29
|
5 | let n = example_closure(5);
| --------------- ^ expected `String`, found integer
| |
| arguments to this function are incorrect
|
note: expected because the closure was earlier called with an argument of type `String`
--> src/main.rs:4:29
|
4 | let s = example_closure(String::from("hello"));
| --------------- ^^^^^^^^^^^^^^^^^^^^^ expected because this argument is of type `String`
| |
| in this closure call
note: closure parameter defined here
--> src/main.rs:2:28
|
2 | let example_closure = |x| x;
| ^
help: try using a conversion method
|
5 | let n = example_closure(5.to_string());
| ++++++++++++
For more information about this error, try `rustc --explain E0308`.
error: could not compile `closure-example` (bin "closure-example") due to 1 previous error
Saat pertama kali kita memanggil example_closure memakai nilai String,
compiler menebak kalau tipe dari x dan tipe kembalian dari closure itu
adalah String. Tipe-tipe itu kemudian “terkunci” ke dalam closure di
example_closure, dan kita bakal dapat type error (error tipe) saat kita
mencoba memakai tipe yang berbeda dengan closure yang sama.
Menangkap Referensi atau Memindahkan Kepemilikan (Ownership)
Closures bisa menangkap nilai dari lingkungannya memakai tiga cara, yang mana berkorelasi langsung dengan tiga cara sebuah fungsi bisa menerima parameter: meminjam secara immutable, meminjam secara mutable, dan mengambil kepemilikan (taking ownership). Closure bakal memutuskan cara mana yang mau dipakai berdasarkan apa yang dilakukan oleh isi fungsinya terhadap nilai-nilai yang ditangkapnya.
Di Listing 13-4, kita mendefinisikan sebuah closure yang menangkap referensi
immutable ke vector bernama list karena closure itu cuma butuh referensi
immutable buat mencetak nilainya.
fn main() {
let list = vec![1, 2, 3];
println!("Before defining closure: {list:?}");
let only_borrows = || println!("From closure: {list:?}");
println!("Before calling closure: {list:?}");
only_borrows();
println!("After calling closure: {list:?}");
}Contoh ini juga mengilustrasikan kalau sebuah variabel bisa diikat ke definisi sebuah closure, dan nanti kita bisa memanggil closure tersebut memakai nama variabel dan tanda kurung, seolah-olah nama variabel itu adalah nama sebuah fungsi.
Karena kita bisa punya banyak referensi immutable ke list di waktu yang
bersamaan, list masih bisa diakses dari kode sebelum definisi closure, di
antara definisi closure namun sebelum closure-nya dipanggil, dan setelah
closure-nya dipanggil. Kode ini berhasil di-compile, jalan, dan mencetak:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Before defining closure: [1, 2, 3]
Before calling closure: [1, 2, 3]
From closure: [1, 2, 3]
After calling closure: [1, 2, 3]
Selanjutnya, di Listing 13-5, kita ngubah body closure-nya biar dia nambahin
sebuah elemen ke vector list. Closure ini sekarang menangkap referensi
mutable.
fn main() {
let mut list = vec![1, 2, 3];
println!("Before defining closure: {list:?}");
let mut borrows_mutably = || list.push(7);
borrows_mutably();
println!("After calling closure: {list:?}");
}Kode ini berhasil di-compile, jalan, dan mencetak:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Before defining closure: [1, 2, 3]
After calling closure: [1, 2, 3, 7]
Perhatikan bahwa sekarang tidak ada lagi println! di antara definisi dan
pemanggilan closure borrows_mutably: ketika borrows_mutably didefinisikan,
ia menangkap referensi mutable ke list. Kita tidak lagi menggunakan closure
ini setelah ia dipanggil, jadi peminjaman mutable itu pun berakhir. Di antara
definisi closure dan pemanggilannya, kita tidak diizinkan buat melakukan
peminjaman immutable untuk mencetaknya karena peminjaman lain tidak
diperbolehkan selama masih ada peminjaman mutable. Coba tambahkan println!
di situ buat melihat pesan error apa yang bakal kita dapatkan!
Kalau kita mau memaksa closure buat mengambil ownership dari nilai yang dia
pakai dari lingkungannya, biarpun isi closure-nya sebenarnya tidak
mewajibkan ownership, kita bisa menambahkan keyword move sebelum daftar
parameternya.
Teknik ini biasanya sangat berguna pas kita mau meneruskan sebuah closure ke
thread baru untuk memindahkan datanya supaya ia dimiliki oleh thread baru
tersebut. Kita bakal bahas threads dan kenapa kita mau menggunakannya secara
mendetail di Bab 16 saat kita ngomongin soal konkurensi (concurrency), tapi buat
sekarang, mari kita eksplor secara singkat cara bikin thread baru yang memakai
sebuah closure yang membutuhkan keyword move. Listing 13-6 menampilkan kode
dari Listing 13-4 yang diubah buat mencetak isi vector di sebuah thread baru,
bukannya di thread utama (main thread).
use std::thread;
fn main() {
let list = vec![1, 2, 3];
println!("Before defining closure: {list:?}");
thread::spawn(move || println!("From thread: {list:?}"))
.join()
.unwrap();
}move buat memaksa closure di thread baru untuk mengambil kepemilikan dari listKita membuat thread baru, sambil memberikan sebuah closure buat dijalankan
sebagai argumen untuk thread tersebut. Isi closure-nya mencetak daftar list.
Di Listing 13-4, closure tersebut cuma menangkap list dengan memakai
referensi immutable karena itulah hak akses minimal yang dibutuhkan ke list
buat mencetaknya. Di contoh ini, meskipun isi closure-nya masih cuma butuh
referensi immutable, kita harus menentukan secara spesifik bahwa list
seharusnya dipindahkan (moved) ke dalam closure dengan menaruh keyword move
di awal definisi closure-nya. Kalau thread utamanya melakukan lebih banyak
operasi sebelum memanggil join pada thread barunya, thread baru tersebut
bisa saja selesai sebelum thread utamanya selesai, atau sebaliknya thread
utama bisa saja selesai lebih dulu. Kalau thread utama masih mempertahankan
ownership dari list tapi dia berakhir lebih dulu sebelum thread barunya
dan men-drop (membuang) list tersebut, referensi immutable di thread baru
bakal jadi tidak valid. Maka dari itu, compiler mewajibkan list untuk
dipindahkan ke dalam closure yang diberikan ke thread baru supaya
referensinya bakal dipastikan valid. Coba hapus keyword move-nya atau
coba pakai variabel list di thread utama setelah closure itu didefinisikan
buat melihat error compiler apa yang bakal muncul!
Memindahkan Nilai yang Ditangkap ke Luar Closures dan Traits Fn
Begitu sebuah closure sudah menangkap referensi atau mengambil kepemilikan dari sebuah nilai dari lingkungan tempat closure itu didefinisikan (yang artinya, hal itu memengaruhi apa yang dipindahkan ke dalam closure-nya), kode di dalam isi closure-nya bakal menentukan apa yang terjadi sama referensi atau nilai tersebut pas closure-nya dievaluasi nantinya (yang artinya, hal ini memengaruhi apa yang dipindahkan ke luar dari closure-nya).
Isi dari sebuah closure bisa ngelakuin mana aja dari hal-hal berikut: memindahkan nilai yang ditangkap ke luar dari closure, memutasi (mengubah) nilai yang ditangkap, tidak memindahkan atau memutasi nilainya, atau dari awal emang tidak menangkap apa pun dari lingkungannya.
Cara sebuah closure menangkap dan menangani nilai dari lingkungannya
memengaruhi trait mana yang diimplementasikan oleh closure tersebut, dan
traits adalah cara bagaimana fungsi dan struct bisa menentukan jenis closures
apa yang bisa mereka terima. Closures bakal secara otomatis mengimplementasikan
satu, dua, atau ketiga traits Fn ini secara aditif, tergantung dari gimana isi
closure-nya menangani nilai-nilai tersebut:
FnOnceberlaku untuk closures yang bisa dipanggil sekali saja. Semua closures minimal mengimplementasikan trait ini karena semua closures itu bisa dipanggil. Closure yang memindahkan nilai yang ditangkap keluar dari isi kodenya cuma bakal mengimplementasikanFnOncedan bukan traitFnlainnya karena ia cuma bisa dipanggil satu kali.FnMutberlaku untuk closures yang tidak memindahkan nilai yang ditangkap keluar dari isinya, tapi yang mungkin memutasi nilai-nilai tersebut. Closures jenis ini bisa dipanggil lebih dari sekali.Fnberlaku untuk closures yang tidak memindahkan nilai yang ditangkap keluar dari isinya dan tidak memutasi nilai-nilai tersebut, serta berlaku juga buat closures yang memang tidak menangkap apa pun dari lingkungannya. Closures seperti ini bisa dipanggil lebih dari sekali tanpa memutasi lingkungannya, yang mana ini penting buat kasus-kasus seperti saat kita memanggil sebuah closure berkali-kali secara konruen (bersamaan).
Mari kita lihat definisi dari method unwrap_or_else pada Option<T> yang
kita pakai di Listing 13-1:
impl<T> Option<T> {
pub fn unwrap_or_else<F>(self, f: F) -> T
where
F: FnOnce() -> T
{
match self {
Some(x) => x,
None => f(),
}
}
}Ingat kembali bahwa T adalah tipe generik yang merepresentasikan tipe dari
nilai di dalam varian Some milik sebuah Option. Tipe T itu juga adalah
tipe kembalian (return type) dari fungsi unwrap_or_else: kode yang memanggil
unwrap_or_else pada sebuah Option<String>, misalnya, bakal mendapatkan sebuah
String.
Selanjutnya, perhatikan bahwa fungsi unwrap_or_else juga punya parameter tipe
generik tambahan F. Tipe F adalah tipe dari parameter bernama f, yang
mana itu adalah closure yang kita kasih saat memanggil unwrap_or_else.
Trait bound yang ditentukan pada tipe generik F adalah FnOnce() -> T, yang
berarti F harus bisa dipanggil sekali, tidak menerima argumen apa pun, dan
mengembalikan sebuah T. Memakai FnOnce di trait bound ini mengekspresikan
batasan bahwa unwrap_or_else cuma bakal memanggil f maksimal satu kali saja.
Di dalam isi unwrap_or_else, kita bisa melihat kalau Option-nya itu Some,
f tidak bakal dipanggil. Kalau Option-nya itu None, f bakal dipanggil
sekali. Karena semua closures mengimplementasikan FnOnce, unwrap_or_else
bisa menerima ketiga jenis closures dan dia fleksibel sekali.
Catatan: Kalau hal yang mau kita lakukan tidak mewajibkan kita menangkap nilai dari lingkungannya, kita bisa aja memakai nama sebuah fungsi sebagai ganti dari closure di tempat kita butuh sesuatu yang mengimplementasikan salah satu dari trait
Fn. Contohnya, pada nilaiOption<Vec<T>>, kita bisa manggilunwrap_or_else(Vec::new)buat mendapatkan vector baru yang kosong kalau nilainya adalahNone. Compiler bakal secara otomatis mengimplementasikan traitFnyang paling pas buat definisi fungsi tersebut.
Sekarang mari kita lihat method standard library sort_by_key, yang
didefinisikan pada slices, buat melihat bedanya dari unwrap_or_else dan
kenapa sort_by_key memakai FnMut dan bukannya FnOnce buat trait bound-nya.
Closure ini menerima satu argumen berupa referensi ke item saat ini yang ada
di slice yang lagi diperiksa, lalu mengembalikan nilai bertipe K yang bisa
diurutkan (ordered). Fungsi ini berguna pas kita mau mengurutkan sebuah slice
berdasarkan atribut spesifik dari setiap itemnya. Di Listing 13-7, kita punya
daftar berisi instance Rectangle dan kita memakai sort_by_key buat mengurutkan
mereka berdasarkan atribut width (lebar) mereka dari yang terkecil sampai
terbesar.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
list.sort_by_key(|r| r.width);
println!("{list:#?}");
}sort_by_key buat mengurutkan persegi panjang berdasarkan lebarnyaKode ini mencetak:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/rectangles`
[
Rectangle {
width: 3,
height: 5,
},
Rectangle {
width: 7,
height: 12,
},
Rectangle {
width: 10,
height: 1,
},
]
Alasan kenapa sort_by_key didefinisikan buat menerima closure FnMut adalah
karena method itu memanggil closure-nya berkali-kali: satu kali untuk setiap
item di slice-nya. Closure |r| r.width tidak menangkap, memutasi, atau
memindahkan apa pun keluar dari lingkungannya, jadi ia memenuhi syarat trait
bound-nya.
Sebaliknya, Listing 13-8 menunjukkan contoh closure yang cuma mengimplementasikan
trait FnOnce, karena dia memindahkan sebuah nilai ke luar dari lingkungannya.
Compiler tidak bakal ngebiarin kita pakai closure ini dengan sort_by_key.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
let mut sort_operations = vec![];
let value = String::from("closure called");
list.sort_by_key(|r| {
sort_operations.push(value);
r.width
});
println!("{list:#?}");
}FnOnce bersama sort_by_keyIni adalah cara aneh yang dibikin-bikin (dan tidak bisa jalan) buat mencoba
menghitung berapa kali sort_by_key memanggil closure-nya saat ia mengurutkan
list. Kode ini mencoba melakukan penghitungan ini dengan memasukkan (pushing)
value—sebuah String dari lingkungan closure-nya—ke dalam vector
sort_operations. Closure ini menangkap value lalu memindahkan value
tersebut keluar dari closure dengan mentransfer kepemilikan (ownership)
value ke vector sort_operations. Closure ini bisa dipanggil satu kali;
mencoba memanggilnya untuk kedua kalinya tidak bakal berhasil karena value
sudah tidak ada lagi di lingkungan closure-nya buat dimasukkan ke dalam
sort_operations! Maka dari itu, closure ini cuma mengimplementasikan
FnOnce. Pas kita mencoba men-compile kode ini, kita bakal dapat error yang
bilang kalau value tidak bisa dipindahkan keluar dari closure karena
closure-nya harus mengimplementasikan FnMut:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
error[E0507]: cannot move out of `value`, a captured variable in an `FnMut` closure
--> src/main.rs:18:30
|
15 | let value = String::from("closure called");
| ----- ------------------------------ move occurs because `value` has type `String`, which does not implement the `Copy` trait
| |
| captured outer variable
16 |
17 | list.sort_by_key(|r| {
| --- captured by this `FnMut` closure
18 | sort_operations.push(value);
| ^^^^^ `value` is moved here
|
help: consider cloning the value if the performance cost is acceptable
|
18 | sort_operations.push(value.clone());
| ++++++++
For more information about this error, try `rustc --explain E0507`.
error: could not compile `rectangles` (bin "rectangles") due to 1 previous error
Error ini menunjuk ke baris di dalam isi closure yang memindahkan value
keluar dari lingkungannya. Buat memperbaikinya, kita harus mengubah isi closure
agar ia tidak memindahkan nilai-nilai keluar dari lingkungannya. Menyimpan sebuah
variabel counter di lingkungan dan menambah nilainya dari dalam closure adalah
cara yang jauh lebih masuk akal buat menghitung berapa kali closure tersebut
dipanggil. Closure di Listing 13-9 berhasil jalan dengan sort_by_key karena
ia cuma menangkap referensi mutable ke counter num_sort_operations dan
makanya bisa dipanggil lebih dari sekali:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
let mut num_sort_operations = 0;
list.sort_by_key(|r| {
num_sort_operations += 1;
r.width
});
println!("{list:#?}, sorted in {num_sort_operations} operations");
}FnMut bersama sort_by_key diperbolehkanTraits Fn penting pas kita mendefinisikan atau memakai fungsi atau tipe yang
memakai closures. Di bagian selanjutnya, kita bakal membahas iterators. Banyak
method iterator yang menerima argumen closure, jadi tetap ingat detail-detail
tentang closures ini ya saat kita lanjut belajar!
Memproses Serangkaian Item Memakai Iterator
Memproses Serangkaian Item dengan Iterators
Pola (pattern) iterator memungkinkan kita buat melakukan suatu tugas secara berurutan pada serangkaian item. Sebuah iterator bertanggung jawab atas logika untuk melakukan iterasi melewati setiap item dan menentukan kapan rangkaian tersebut sudah selesai. Saat kita memakai iterator, kita tidak perlu repot-repot mengimplementasikan ulang logika tersebut sendiri.
Di Rust, iterators itu lazy (malas), yang artinya mereka tidak punya efek
apa-apa sampai kita memanggil method-method yang bakal mengonsumsi (consume)
iterator itu untuk memakainya sampai habis. Sebagai contoh, kode di Listing
13-10 membuat sebuah iterator atas item-item di dalam vector v1 dengan
memanggil method iter yang didefinisikan pada Vec<T>. Kode ini kalau
berdiri sendiri tidak melakukan hal berguna apa pun.
fn main() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
}Iterator ini disimpan di dalam variabel v1_iter. Setelah kita membuat sebuah
iterator, kita bisa memakainya dalam berbagai cara. Di Listing 3-5, kita
beriterasi melewati sebuah array memakai for loop untuk mengeksekusi
beberapa kode pada masing-masing itemnya. Di balik layar, hal ini secara
implisit membuat lalu mengonsumsi sebuah iterator, tapi kita melewatkan detail
tentang gimana sebenarnya itu bekerja sampai saat ini.
Di contoh pada Listing 13-11, kita memisahkan proses pembuatan iterator dari
penggunaan iterator tersebut di dalam for loop. Saat for loop ini dipanggil
memakai iterator di v1_iter, setiap elemen di iterator tersebut dipakai
dalam satu putaran (iteration) loop, yang mana mencetak setiap nilainya.
fn main() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
for val in v1_iter {
println!("Got: {val}");
}
}Di bahasa pemrograman yang tidak menyediakan iterator dari standard library-nya, kita kemungkinan bakal menulis fungsionalitas yang sama ini dengan memulai sebuah variabel di indeks 0, memakai variabel tersebut buat mengindeks ke dalam vector untuk mendapatkan nilai, lalu menambah nilai variabel itu di dalam loop sampai jumlahnya mencapai total item yang ada di vector.
Iterators menangani semua logika tersebut buat kita, mengurangi kode yang berulang-ulang (repetitive code) yang mana bisa saja kita bikin salah. Iterators ngasih kita fleksibilitas lebih buat memakai logika yang sama dengan berbagai jenis urutan data, bukan cuma struktur data yang bisa kita indeks aja, kayak vector. Mari kita teliti gimana cara iterators melakukan itu.
Trait Iterator dan Method next
Semua iterators mengimplementasikan sebuah trait bernama Iterator yang
didefinisikan di standard library. Definisi dari trait ini kelihatan kayak gini:
#![allow(unused)]
fn main() {
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
// methods dengan implementasi default dihilangkan
}
}Perhatikan bahwa definisi ini memakai beberapa sintaks baru: type Item dan
Self::Item, yang mendefinisikan sebuah associated type dengan trait ini.
Kita bakal membahas associated types lebih mendalam di Bab 20. Buat sekarang,
yang perlu kita tahu adalah bahwa kode ini bilang kalau buat mengimplementasikan
trait Iterator, kita juga harus mendefinisikan tipe Item, dan tipe Item
ini dipakai di tipe kembalian (return type) dari method next. Dengan kata
lain, tipe Item bakal jadi tipe yang dikembalikan dari iterator tersebut.
Trait Iterator cuma mewajibkan para peng-implementasi (implementors) buat
mendefinisikan satu method saja: yaitu method next, yang mengembalikan satu
item dari iterator pada satu waktu, dibungkus di dalam Some, dan, ketika
iterasi selesai, mengembalikan None.
Kita bisa memanggil method next pada iterators secara langsung; Listing 13-12
mendemonstrasikan nilai-nilai apa aja yang dikembalikan dari pemanggilan
berulang ke next pada iterator yang dibikin dari vector.
#[cfg(test)]
mod tests {
#[test]
fn iterator_demonstration() {
let v1 = vec![1, 2, 3];
let mut v1_iter = v1.iter();
assert_eq!(v1_iter.next(), Some(&1));
assert_eq!(v1_iter.next(), Some(&2));
assert_eq!(v1_iter.next(), Some(&3));
assert_eq!(v1_iter.next(), None);
}
}next pada sebuah iteratorPerhatikan bahwa kita harus membikin v1_iter jadi mutable: memanggil
method next pada sebuah iterator bakal mengubah state (keadaan) internal
yang dipakai sama iterator tersebut untuk melacak (keep track of) ada di mana
dia saat ini di urutan tersebut. Dengan kata lain, kode ini mengonsumsi
(consumes), atau menghabiskan, iterator-nya. Setiap pemanggilan ke next
bakal “memakan” satu item dari iterator-nya. Kita tidak perlu membikin
v1_iter jadi mutable saat kita memakai for loop karena loop tersebut
mengambil kepemilikan (ownership) dari v1_iter dan membikinnya mutable di
balik layar.
Perhatikan juga bahwa nilai yang kita dapat dari pemanggilan next adalah
referensi immutable ke nilai-nilai yang ada di vector-nya. Method iter
menghasilkan sebuah iterator yang berisi referensi immutable. Kalau kita
mau membuat iterator yang mengambil kepemilikan dari v1 lalu mengembalikan
nilai yang owned (dimiliki), kita bisa memanggil into_iter alih-alih iter.
Sama juga halnya, kalau kita mau beriterasi melewati referensi mutable, kita
bisa memanggil iter_mut alih-alih iter.
Method-method yang Mengonsumsi Iterator
Trait Iterator punya sejumlah method berbeda dengan implementasi default
yang disediakan oleh standard library; kita bisa tahu soal method-method
ini dengan melihat dokumentasi API standard library untuk trait Iterator.
Beberapa dari method ini memanggil method next di dalam definisi mereka,
dan inilah alasannya kenapa kita diwajibkan buat mengimplementasikan method
next saat kita mau mengimplementasikan trait Iterator.
Method-method yang memanggil next ini disebut consuming adapters, karena
memanggil mereka bakal menghabiskan iterator-nya. Salah satu contohnya adalah
method sum, yang mengambil kepemilikan dari iterator lalu beriterasi melewati
item-itemnya dengan memanggil next secara berulang, yang mana ini bakal
mengonsumsi iterator tersebut. Selama ia beriterasi, method ini menambahkan
tiap item ke dalam sebuah total berjalan (running total) lalu mengembalikan
totalnya saat iterasi selesai. Listing 13-13 punya contoh tes yang
mengilustrasikan pemakaian method sum.
#[cfg(test)]
mod tests {
#[test]
fn iterator_sum() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
let total: i32 = v1_iter.sum();
assert_eq!(total, 6);
}
}sum buat mendapatkan total dari semua item di dalam iteratorKita tidak diizinkan buat memakai v1_iter lagi setelah memanggil sum karena
sum mengambil kepemilikan dari iterator tempat dia dipanggil.
Method-method yang Menghasilkan Iterator Lain
Iterator adapters adalah method-method yang didefinisikan pada trait Iterator
yang tidak mengonsumsi iterator-nya. Alih-alih mengonsumsi, mereka malah
menghasilkan iterator-iterator yang berbeda dengan cara mengubah beberapa aspek
dari iterator aslinya.
Listing 13-14 menunjukkan contoh dari pemanggilan method iterator adapter map,
yang menerima sebuah closure buat dipanggil pada setiap item saat item-item
tersebut dilewati dalam proses iterasi. Method map mengembalikan sebuah
iterator baru yang menghasilkan item-item yang sudah dimodifikasi tersebut.
Closure di sini membuat iterator baru di mana tiap item dari vector bakal
ditambahkan 1.
fn main() {
let v1: Vec<i32> = vec![1, 2, 3];
v1.iter().map(|x| x + 1);
}map buat membuat iterator baruNamun, kode ini menghasilkan sebuah peringatan (warning):
$ cargo run
Compiling iterators v0.1.0 (file:///projects/iterators)
warning: unused `Map` that must be used
--> src/main.rs:4:5
|
4 | v1.iter().map(|x| x + 1);
| ^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: iterators are lazy and do nothing unless consumed
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
4 | let _ = v1.iter().map(|x| x + 1);
| +++++++
warning: `iterators` (bin "iterators") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.47s
Running `target/debug/iterators`
Kode di Listing 13-14 tidak melakukan apa-apa; closure yang sudah kita tentukan itu tidak akan pernah dipanggil. Peringatannya mengingatkan kita soal alasannya kenapa: iterator adapters itu lazy (malas), dan kita harus mengonsumsi iterator-nya di sini.
Untuk membereskan peringatan ini dan mengonsumsi iterator-nya, kita bakal
memakai method collect, yang sudah kita pakai bersama env::args di Listing
12-1. Method ini mengonsumsi iterator-nya lalu mengumpulkan (collects) nilai-
nilai yang dihasilkan ke dalam sebuah tipe data koleksi.
Di Listing 13-15, kita mengumpulkan hasil dari iterasi iterator yang dikembalikan
oleh panggilan ke map menjadi sebuah vector. Vector ini nantinya bakal berisi
setiap item dari vector aslinya, masing-masing ditambah 1.
fn main() {
let v1: Vec<i32> = vec![1, 2, 3];
let v2: Vec<_> = v1.iter().map(|x| x + 1).collect();
assert_eq!(v2, vec![2, 3, 4]);
}map buat membuat iterator baru, lalu memanggil method collect buat mengonsumsi iterator baru itu dan membuat sebuah vectorKarena map menerima sebuah closure, kita bisa menentukan operasi apa pun yang
mau kita lakukan pada tiap itemnya. Ini adalah contoh yang bagus tentang gimana
closures memungkinkan kita buat mengkustomisasi beberapa perilaku tertentu
sambil menggunakan kembali perilaku iterasi yang disediakan sama trait Iterator.
Kita bisa menyambung (chain) beberapa panggilan ke berbagai iterator adapters buat melakukan tindakan yang rumit pakai cara yang tetap enak dibaca. Tapi karena semua iterator itu lazy, kita harus memanggil salah satu dari method consuming adapter buat mendapatkan hasil dari rentetan panggilan ke iterator adapters tersebut.
Menggunakan Closures yang Menangkap Lingkungannya
Banyak iterator adapters menerima closures sebagai argumen, dan biasanya closures yang bakal kita berikan sebagai argumen ke iterator adapters itu adalah closures yang bakal menangkap lingkungan (environment) mereka.
Untuk contoh ini, kita bakal memakai method filter yang menerima sebuah
closure. Closure ini mengambil item dari iterator lalu mengembalikan sebuah
bool. Kalau closure-nya mengembalikan true, nilainya bakal diikutsertakan
dalam iterasi yang dihasilkan oleh filter. Kalau closure-nya mengembalikan
false, nilainya tidak bakal diikutsertakan.
Di Listing 13-16, kita memakai filter bersama sebuah closure yang menangkap
variabel shoe_size dari lingkungannya untuk beriterasi melewati sekumpulan
instance struct Shoe. Ini cuma bakal mengembalikan sepatu-sepatu yang punya
ukuran sama dengan yang ditentukan.
#[derive(PartialEq, Debug)]
struct Shoe {
size: u32,
style: String,
}
fn shoes_in_size(shoes: Vec<Shoe>, shoe_size: u32) -> Vec<Shoe> {
shoes.into_iter().filter(|s| s.size == shoe_size).collect()
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn filters_by_size() {
let shoes = vec![
Shoe {
size: 10,
style: String::from("sneaker"),
},
Shoe {
size: 13,
style: String::from("sandal"),
},
Shoe {
size: 10,
style: String::from("boot"),
},
];
let in_my_size = shoes_in_size(shoes, 10);
assert_eq!(
in_my_size,
vec![
Shoe {
size: 10,
style: String::from("sneaker")
},
Shoe {
size: 10,
style: String::from("boot")
},
]
);
}
}filter bersama sebuah closure yang menangkap shoe_sizeFungsi shoes_in_size mengambil kepemilikan dari sebuah vector sepatu (shoes)
dan ukuran sepatu sebagai parameternya. Ia mengembalikan vector yang hanya
berisi sepatu-sepatu dengan ukuran yang ditentukan tersebut.
Di dalam body dari shoes_in_size, kita memanggil into_iter buat membuat
sebuah iterator yang mengambil kepemilikan dari vector-nya. Kemudian kita
memanggil filter buat mengadaptasi iterator itu menjadi iterator baru yang
hanya mengandung elemen-elemen yang bikin closure-nya mengembalikan true.
Closure-nya menangkap parameter shoe_size dari lingkungan di sekitarnya dan
membandingkan nilai itu dengan setiap ukuran dari sepatunya, mempertahankan
hanya sepatu-sepatu dengan ukuran yang sesuai. Terakhir, memanggil collect
bakal mengumpulkan (gathers) nilai-nilai yang dikembalikan oleh iterator yang
diadaptasi ini ke dalam sebuah vector yang kemudian dikembalikan oleh fungsi
tersebut.
Pengujian ini menunjukkan bahwa saat kita memanggil shoes_in_size, kita cuma
bakal dapat balik sepatu-sepatu yang punya ukuran yang sama dengan nilai yang
kita tentukan.
Meningkatkan Project I/O Kita
Meningkatkan Project I/O Kita
Dengan pengetahuan baru tentang iterators ini, kita bisa meningkatkan project I/O
di Bab 12 dengan memakai iterators buat bikin beberapa bagian kodenya jadi lebih
jelas dan lebih ringkas. Mari kita lihat gimana iterators bisa meningkatkan
implementasi dari fungsi Config::build dan fungsi search kita.
Menghilangkan clone Menggunakan Iterator
Di Listing 12-6, kita menambahkan kode yang mengambil slice berisi nilai
String lalu membuat instance dari struct Config dengan mengindeks ke dalam
slice tersebut dan meng-clone (menyalin) nilai-nilainya, yang memungkinkan
struct Config buat memiliki (own) nilai-nilai itu. Di Listing 13-17, kita
menampilkan ulang implementasi dari fungsi Config::build persis seperti yang
ada di Listing 12-23.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Config::build dari Listing 12-23Waktu itu, kita bilang buat tidak mengkhawatirkan panggilan clone yang kurang
efisien karena kita bakal menghapusnya di masa depan. Nah, sekaranglah saatnya!
Kita membutuhkan clone di sini karena kita punya sebuah slice berisi
elemen-elemen String di parameter args, tapi fungsi build tidak mengambil
kepemilikan (ownership) atas args. Buat mengembalikan kepemilikan dari instance
Config, kita harus meng-clone nilai-nilai dari field query dan file_path
milik Config supaya instance Config tersebut bisa memiliki nilai-nilainya.
Dengan pengetahuan baru kita tentang iterators, kita bisa mengubah fungsi build
agar mengambil kepemilikan dari sebuah iterator sebagai argumennya, ketimbang
meminjam (borrow) sebuah slice. Kita bakal memakai fungsionalitas iterator
alih-alih kode yang mengecek panjang dari slice dan mengindeks ke lokasi
spesifik. Ini bakal memperjelas apa yang sedang dilakukan oleh fungsi
Config::build karena iterator-lah yang bakal mengakses nilai-nilainya.
Begitu Config::build mengambil kepemilikan atas iterator dan berhenti memakai
operasi indexing yang sifatnya meminjam, kita bisa memindahkan (move)
nilai-nilai String dari iterator tersebut ke dalam Config alih-alih memanggil
clone dan membuat alokasi baru.
Memakai Iterator yang Dikembalikan secara Langsung
Buka file src/main.rs dari project I/O kita, yang seharusnya kelihatan seperti ini:
Nama file: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Pertama-tama kita bakal mengubah bagian awal dari fungsi main yang kita punya
di Listing 12-24 jadi kode yang ada di Listing 13-18, yang mana kali ini memakai
iterator. Ini belum bisa di-compile sampai kita meng-update Config::build juga.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}env::args ke Config::buildFungsi env::args mengembalikan sebuah iterator! Alih-alih mengumpulkan nilai-nilai
iterator itu ke dalam sebuah vector terus meneruskan sebuah slice ke
Config::build, sekarang kita meneruskan kepemilikan dari iterator yang
dikembalikan dari env::args ke Config::build secara langsung.
Berikutnya, kita harus meng-update definisi dari Config::build. Mari kita ubah
signature (tanda tangan) dari Config::build agar kelihatan seperti Listing
13-19. Ini masih belum bisa di-compile, karena kita harus meng-update isi (body)
fungsinya.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
// --snip--
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Config::build buat mengharapkan sebuah iteratorDokumentasi standard library untuk fungsi env::args menunjukkan bahwa tipe
dari iterator yang dikembalikannya adalah std::env::Args, dan tipe tersebut
mengimplementasikan trait Iterator serta mengembalikan nilai String.
Kita sudah meng-update signature dari fungsi Config::build jadi parameter
args punya tipe generik dengan trait bounds impl Iterator<Item = String>
bukannya &[String]. Penggunaan sintaks impl Trait yang kita bahas di
bagian “Traits sebagai Parameter” di Bab 10 ini berarti args
bisa berupa tipe apa pun yang mengimplementasikan trait Iterator dan
mengembalikan item berupa String.
Karena kita mengambil kepemilikan atas args dan kita bakal memutasi (mengubah)
args saat kita beriterasi melewatinya, kita bisa menambahkan keyword mut
ke dalam spesifikasi parameter args buat membikinnya jadi mutable.
Memakai Method Trait Iterator Alih-Alih Indexing
Berikutnya, kita bakal memperbaiki isi dari Config::build. Karena args
mengimplementasikan trait Iterator, kita tahu kalau kita bisa memanggil method
next padanya! Listing 13-20 meng-update kode dari Listing 12-23 buat memakai
method next.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
args.next();
let query = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a query string"),
};
let file_path = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a file path"),
};
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Config::build buat memakai method iteratorIngat kembali bahwa nilai pertama di dalam nilai yang dikembalikan oleh
env::args adalah nama dari programnya. Kita mau mengabaikan itu dan lanjut ke
nilai berikutnya, jadi pertama kita memanggil next dan tidak ngelakuin apa-apa
dengan nilai yang dikembalikannya. Terus kita panggil next lagi buat dapet
nilai yang mau kita masukin ke field query dari Config. Kalau next
mengembalikan Some, kita pakai match buat mengekstrak nilainya. Kalau dia
mengembalikan None, itu berarti argumen yang diberikan tidak cukup dan kita
bisa keluar lebih awal dengan nilai Err. Kita ngelakuin hal yang sama buat
nilai file_path.
Membikin Kode Lebih Jelas dengan Iterator Adapters
Kita juga bisa memanfaatkan iterators di fungsi search dari project I/O kita,
yang ditampilkan ulang di Listing 13-21 persis seperti yang ada di Listing 12-19.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}search dari Listing 12-19Kita bisa nulis kode ini dengan cara yang lebih ringkas memakai method iterator
adapter. Dengan begitu, kita juga terhindar dari kewajiban punya vector
results menengah (intermediate) yang mutable. Gaya pemrograman fungsional
lebih suka meminimalisir mutable state (keadaan yang bisa berubah) demi
bikin kodenya jadi lebih jelas. Membuang mutable state ini mungkin bisa
memungkinkan adanya peningkatan di masa depan yang bakal bikin pencarian terjadi
secara paralel karena kita tidak perlu pusing mengelola akses konruen
(concurrent access) ke vector results tersebut. Listing 13-22 menunjukkan
perubahan ini.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
contents
.lines()
.filter(|line| line.contains(query))
.collect()
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}searchIngat kembali bahwa tujuan dari fungsi search adalah mengembalikan semua baris
di dalam contents yang mengandung query. Mirip seperti contoh filter di
Listing 13-16, kode ini memakai adapter filter buat menyimpan cuma
baris-baris di mana line.contains(query) mengembalikan true. Kita kemudian
mengumpulkan baris-baris yang cocok itu ke dalam sebuah vector lain menggunakan
collect. Jauh lebih simpel kan! Jangan ragu buat ngelakuin perubahan yang sama
buat memakai method iterator di fungsi search_case_insensitive juga.
Sebagai peningkatan lanjutan, coba kembalikan sebuah iterator dari fungsi
search dengan menghapus panggilan ke collect dan mengubah tipe kembaliannya
jadi impl Iterator<Item = &'a str> supaya fungsi ini menjadi sebuah iterator
adapter. Perhatikan bahwa kita juga bakal harus meng-update pengujiannya! Coba
cari di dalam sebuah file berukuran besar menggunakan alat minigrep kita sebelum
dan sesudah membikin perubahan ini untuk melihat perbedaan perilakunya. Sebelum
perubahan ini, program tidak bakal mencetak hasil apa pun sampai ia selesai
mengumpulkan semua hasilnya, tapi setelah perubahan itu, hasil bakal dicetak
satu per satu setiap kali ada baris yang cocok karena for loop di fungsi run
bisa memanfaatkan sifat lazy (malas) dari iterator-nya.
Memilih antara Loops dan Iterators
Pertanyaan masuk akal berikutnya adalah gaya mana yang sebaiknya kita pilih di kode kita sendiri dan kenapa: implementasi awal di Listing 13-21 atau versi yang memakai iterators di Listing 13-22 (dengan asumsi kita mengumpulkan semua hasilnya sebelum mengembalikannya bukannya mengembalikan iteratornya). Sebagian besar programmer Rust lebih suka memakai gaya iterator. Mungkin agak sedikit susah buat memahaminya di awal, tapi begitu kita sudah mulai merasakan (get a feel for) berbagai iterator adapters dan apa yang mereka lakukan, iterators bisa jadi lebih gampang buat dipahami. Ketimbang ribet ngurusin detail soal looping (perulangan) dan membikin vector baru, kode kita jadi bisa lebih fokus ke tujuan tingkat tinggi (high-level objective) dari loop tersebut. Ini mengabstraksi kode-kode umum (commonplace code) sehingga konsep-konsep yang unik buat kode ini jadi lebih mudah dilihat, seperti contohnya kondisi penyaringan (filtering condition) yang harus dilewati sama setiap elemen di dalam iterator.
Tapi apakah kedua implementasi ini benar-benar ekuivalen (sama)? Asumsi yang mungkin muncul secara intuitif adalah loop tingkat rendah (lower-level loop) bakal lebih cepat. Mari kita bahas soal performa.
Performa: Loops vs. Iterator
Membandingkan Performa: Loops vs. Iterators
Buat menentukan apakah kita sebaiknya memakai loops atau iterators, kita
perlu tahu implementasi mana yang lebih cepat: versi fungsi search yang
memakai for loop eksplisit atau versi yang memakai iterators.
Kita menjalankan sebuah benchmark (pengujian performa) dengan memuat seluruh isi
buku The Adventures of Sherlock Holmes karya Sir Arthur Conan Doyle ke dalam
sebuah String dan mencari kata the di dalam isinya. Berikut adalah hasil dari
benchmark pada fungsi search versi for loop dan versi iterators:
test bench_search_for ... bench: 19,620,300 ns/iter (+/- 915,700)
test bench_search_iter ... bench: 19,234,900 ns/iter (+/- 657,200)
Kedua implementasi ini punya performa yang mirip! Kita tidak bakal menjelaskan kode benchmark-nya di sini karena tujuannya bukanlah buat membuktikan kalau kedua versi itu persis ekuivalen, tapi buat ngasih gambaran umum soal gimana perbandingan performa kedua implementasi ini.
Untuk benchmark yang lebih komprehensif, kita sebaiknya menguji dengan memakai
berbagai teks dari berbagai ukuran sebagai contents, kata yang berbeda-beda dan
kata dengan panjang yang beda-beda sebagai query, dan berbagai jenis variasi
lainnya. Poin utamanya adalah ini: iterators, meskipun merupakan sebuah
abstraksi tingkat tinggi (high-level abstraction), bakal di-compile menjadi kode
yang kurang lebih sama seperti kalau kita menulis sendiri kode tingkat rendah
(lower-level code)-nya secara manual. Iterators adalah salah satu dari
zero-cost abstractions (abstraksi tanpa biaya) di Rust, yang maksudnya adalah
penggunaan abstraksi tersebut tidak menambahkan beban (overhead) apa pun pas
runtime. Ini analog dengan gimana Bjarne Stroustrup, perancang dan
pengimplementasi asli dari C++, mendefinisikan zero-overhead di
“Foundations of C++” (2012):
Secara umum, implementasi C++ mematuhi prinsip zero-overhead: Apa yang tidak kita pakai, kita tidak perlu membayarnya. Dan lebih jauh lagi: Apa yang kita pakai, kita tidak bakal bisa nulis kodenya secara manual dengan lebih baik lagi.
Di banyak kasus, kode Rust yang memakai iterators di-compile menjadi kode assembly (bahasa rakitan) yang sama persis kayak yang bakal kita tulis pakai tangan sendiri. Berbagai optimasi kayak loop unrolling dan menghilangkan pengecekan batas (bounds checking) pada akses array bakal diterapkan dan membikin kode akhirnya jadi sangat efisien. Sekarang karena kita sudah tahu hal ini, kita bisa memakai iterators dan closures tanpa rasa takut! Mereka bikin kode kelihatan seperti di tingkat yang lebih tinggi (higher level) tapi tidak mengenakan hukuman performa (performance penalty) pas runtime karena ngelakuin hal tersebut.
Ringkasan
Closures dan iterators adalah fitur-fitur Rust yang terinspirasi dari ide-ide bahasa pemrograman fungsional. Mereka berkontribusi pada kemampuan Rust buat mengekspresikan ide-ide tingkat tinggi (high-level ideas) dengan jelas sembari mempertahankan performa tingkat rendah (low-level performance). Implementasi dari closures dan iterators dirancang sedemikian rupa sehingga performa pas runtime tidak terpengaruh. Ini adalah bagian dari tujuan Rust buat berjuang menyediakan zero-cost abstractions.
Sekarang setelah kita meningkatkan kemampuan ekspresi dari project I/O kita,
mari kita lihat beberapa fitur cargo lainnya yang bakal membantu kita membagikan
project kita dengan dunia.
Lebih Lanjut soal Cargo dan Crates.io
Sejauh ini, kita baru memakai fitur-fitur paling dasar dari Cargo buat mem-build, menjalankan, dan menguji kode kita, tapi dia bisa melakukan jauh lebih banyak lagi. Di bab ini, kita bakal membahas beberapa fitur Cargo lainnya yang lebih mahir (advanced) buat menunjukkan ke kita gimana cara ngelakuin hal-hal berikut:
- Mengkustomisasi build kita melalui release profiles (profil rilis)
- Memublikasikan (publish) libraries di crates.io
- Mengatur project yang besar dengan workspaces
- Menginstal binaries dari crates.io
- Memperluas kemampuan Cargo memakai perintah kustom (custom commands)
Cargo bisa melakukan lebih dari fungsionalitas yang kita bahas di bab ini, jadi buat penjelasan selengkapnya tentang semua fiturnya, cek dokumentasinya.
Kustomisasi Build Memakai Profil Rilis
Mengkustomisasi Build dengan Release Profiles
Di Rust, release profiles (profil rilis) adalah profil yang sudah didefinisikan sebelumnya (predefined) dan bisa dikustomisasi dengan berbagai konfigurasi yang memungkinkan programmer buat punya lebih banyak kontrol atas berbagai opsi saat men-compile kode. Setiap profil dikonfigurasi secara independen satu sama lain.
Cargo punya dua profil utama: profil dev yang dipakai Cargo saat kita
menjalankan cargo build, dan profil release yang dipakai Cargo saat kita
menjalankan cargo build --release. Profil dev didefinisikan dengan
default yang bagus buat fase development (pengembangan), dan profil
release punya default yang bagus buat release builds (build versi rilis).
Nama-nama profil ini mungkin terasa familier dari output build yang pernah kita jalankan:
$ cargo build
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
$ cargo build --release
Finished `release` profile [optimized] target(s) in 0.32s
dev dan release adalah profil-profil berbeda yang dipakai sama compiler.
Cargo punya pengaturan default buat setiap profil yang berlaku kalau kita
belum menambahkan bagian [profile.*] secara eksplisit di file Cargo.toml
milik project kita. Dengan menambahkan bagian [profile.*] buat profil mana
pun yang mau kita kustomisasi, kita bisa menimpa (override) sebagian dari
pengaturan default-nya. Misalnya, ini adalah nilai default buat pengaturan
opt-level di profil dev dan release:
Nama file: Cargo.toml
[profile.dev]
opt-level = 0
[profile.release]
opt-level = 3
Pengaturan opt-level mengontrol seberapa banyak optimasi yang bakal
diterapkan Rust ke kode kita, dengan rentang nilai dari 0 sampai 3. Menerapkan
lebih banyak optimasi bakal memperpanjang waktu kompilasi, jadi kalau kita
sedang dalam fase pengembangan dan sering men-compile kode kita, kita bakal
mau lebih sedikit optimasi agar kodenya bisa di-compile lebih cepat meskipun
kode akhirnya nanti berjalan lebih lambat. Oleh karena itu, nilai opt-level
default buat dev adalah 0. Saat kita sudah siap merilis kode kita, hal
terbaik adalah menghabiskan lebih banyak waktu buat kompilasi. Kita cuma
bakal men-compile dalam mode release sesekali saja, tapi kita bakal
menjalankan program yang sudah di-compile itu berkali-kali, jadi mode
release menukar waktu kompilasi yang lebih lama demi mendapatkan kode yang
berjalan lebih cepat. Itulah kenapa nilai opt-level default buat profil
release adalah 3.
Kita bisa menimpa pengaturan default dengan menambahkan nilai yang berbeda untuknya di Cargo.toml. Misalnya, kalau kita mau memakai tingkat optimasi 1 di profil development, kita bisa menambahkan dua baris ini ke file Cargo.toml project kita:
Nama file: Cargo.toml
[profile.dev]
opt-level = 1
Kode ini menimpa pengaturan default yaitu 0. Sekarang pas kita menjalankan
cargo build, Cargo bakal memakai nilai-nilai default buat profil dev
ditambah dengan kustomisasi kita pada opt-level. Karena kita menge-set
opt-level jadi 1, Cargo bakal menerapkan lebih banyak optimasi daripada
nilai default-nya, tapi tidak sebanyak di versi release build.
Buat melihat daftar lengkap dari opsi konfigurasi dan nilai default dari setiap profil, silakan cek dokumentasi Cargo.
Mempublikasikan sebuah Crate ke Crates.io
Mempublikasikan Crate ke Crates.io
Kita sudah memakai packages dari crates.io sebagai dependencies buat project kita, tapi kita juga bisa nge-share kode kita sama orang lain dengan mempublikasikan packages milik kita sendiri. Registry crate di crates.io mendistribusikan source code dari packages kita, jadi ia pada dasarnya meng-host kode yang open source (sumber terbuka).
Rust dan Cargo punya berbagai fitur yang bikin package yang kita publikasikan jadi lebih gampang dicari dan dipakai orang. Kita bakal membahas beberapa fitur ini lalu menjelaskan gimana caranya mempublikasikan sebuah package.
Menulis Komentar Dokumentasi yang Berguna
Mendokumentasikan packages kita secara akurat bakal membantu para user
lain tahu gimana dan kapan mereka bisa memakainya, jadi sangat sepadan
menghabiskan waktu buat nulis dokumentasi. Di Bab 3, kita sudah membahas gimana
cara memberi komentar di kode Rust menggunakan dua garis miring, //. Rust
juga punya jenis komentar khusus buat dokumentasi, yang lebih enak disebut
documentation comment (komentar dokumentasi), yang bakal men-generate
dokumentasi dalam format HTML. HTML ini menampilkan isi dari komentar dokumentasi
buat item-item API public yang ditujukan buat para programmer yang tertarik
buat tahu gimana cara memakai crate kita, bukannya gimana crate kita itu
diimplementasikan.
Komentar dokumentasi memakai tiga garis miring, ///, bukannya dua dan
mendukung notasi Markdown buat memformat teksnya. Taruh komentar dokumentasi
persis sebelum item yang lagi mereka dokumentasikan. Listing 14-1 menunjukkan
komentar dokumentasi buat sebuah fungsi add_one di dalam sebuah crate
bernama my_crate.
/// Adds one to the number given.
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}Di sini, kita memberikan deskripsi tentang apa yang dilakukan sama fungsi add_one,
memulai sebuah bagian (section) dengan judul Examples (Contoh), dan kemudian
menyediakan kode yang mendemonstrasikan gimana cara memakai fungsi add_one. Kita
bisa men-generate dokumentasi HTML dari komentar dokumentasi ini dengan
menjalankan cargo doc. Perintah ini menjalankan tool rustdoc yang
didistribusikan bersama Rust dan menaruh dokumentasi HTML hasilnya ke dalam
direktori target/doc.
Biar lebih praktis, menjalankan cargo doc --open bakal mem-build HTML buat
dokumentasi dari crate kita saat ini (beserta dokumentasi buat semua
dependencies crate kita) lalu membuka hasilnya di web browser. Arahkan
navigasi ke fungsi add_one dan kita bakal melihat gimana teks di komentar
dokumentasi tersebut dirender, seperti yang ditunjukkan di Gambar 14-1.
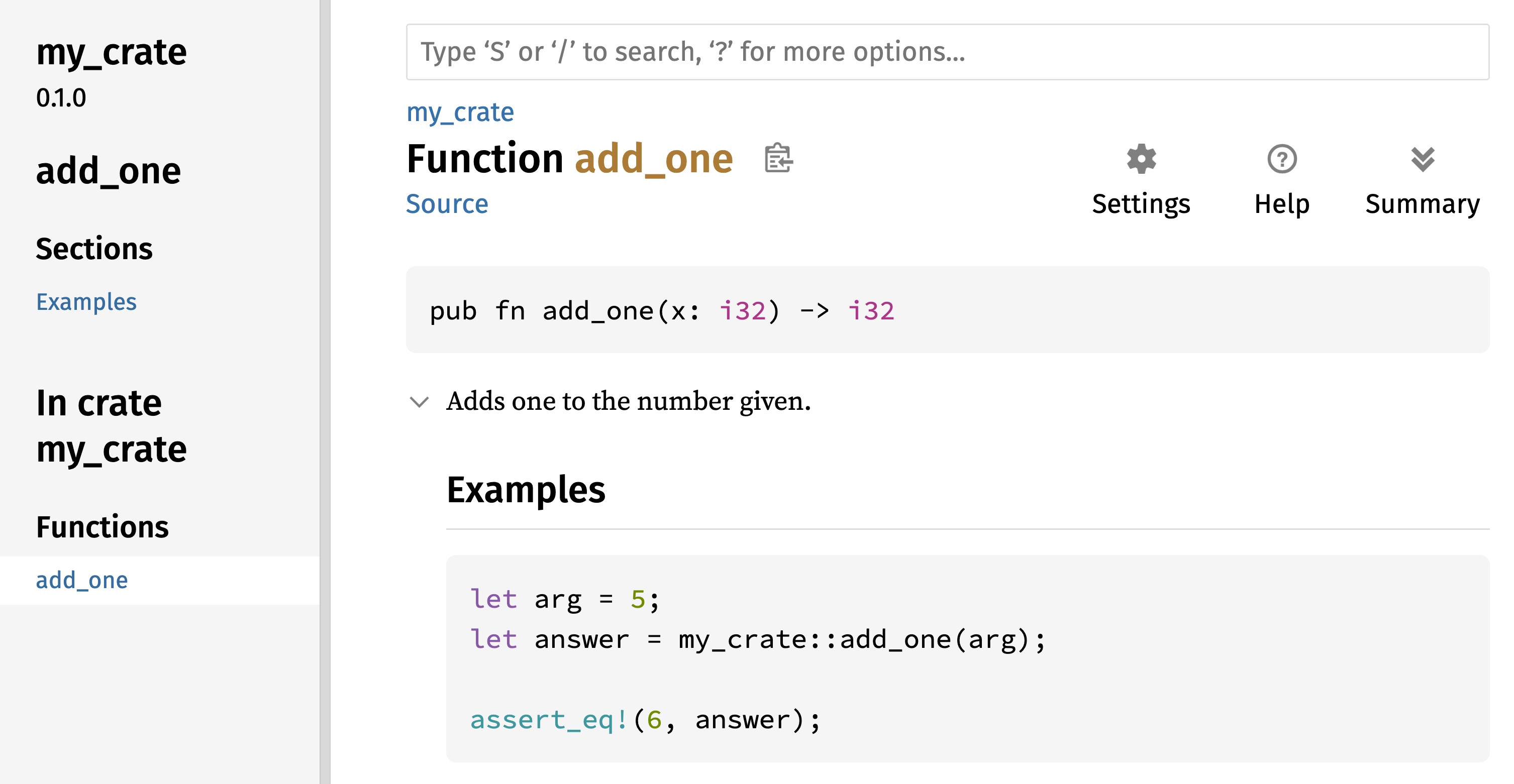
Gambar 14-1: Dokumentasi HTML untuk fungsi add_one
Bagian-bagian yang Sering Dipakai
Kita memakai heading Markdown # Examples di Listing 14-1 buat membikin
sebuah bagian di HTML-nya dengan judul “Examples.” Berikut ini beberapa bagian
lain yang sering sekali dipakai oleh para pembuat crate di dokumentasi mereka:
- Panics: Skenario-skenario di mana fungsi yang didokumentasikan ini bisa mengalami panic. Kode pemanggil fungsi ini yang tidak mau programnya mengalami panic harus memastikan kalau mereka tidak memanggil fungsi ini di situasi-situasi tersebut.
- Errors: Kalau fungsinya mengembalikan sebuah
Result, mendeskripsikan jenis-jenis error apa aja yang mungkin terjadi dan kondisi apa yang mungkin menyebabkan error-error itu dikembalikan bisa sangat ngebantu pemanggil agar mereka bisa nulis kode buat menangani berbagai jenis error dengan cara yang berbeda-beda. - Safety: Kalau fungsinya itu
unsafe(tidak aman) buat dipanggil (kita membahas soal unsafety di Bab 20), harusnya ada bagian yang menjelaskan kenapa fungsi itu tidak aman dan mencakup invariants (batasan) apa yang diharapkan oleh fungsi tersebut buat dipatuhi sama pemanggilnya.
Kebanyakan komentar dokumentasi tidak perlu punya semua bagian ini, tapi ini adalah checklist yang bagus buat ngingetin kita soal aspek-aspek kode kita yang bakal bikin user tertarik buat tahu.
Komentar Dokumentasi Sebagai Tests (Pengujian)
Menambahkan blok-blok contoh kode di dalam komentar dokumentasi kita bisa
membantu mendemonstrasikan gimana cara memakai library kita, dan
melakukannya punya keuntungan ekstra: menjalankan cargo test bakal
menjalankan contoh kode di dokumentasi kita tersebut sebagai pengujian!
Tidak ada yang lebih baik dari dokumentasi yang disertai contoh. Tapi tidak
ada yang lebih parah dari contoh yang tidak jalan gara-gara kodenya udah
diubah sejak dokumentasinya ditulis. Kalau kita menjalankan cargo test
dengan dokumentasi buat fungsi add_one dari Listing 14-1, kita bakal melihat
sebuah bagian di hasil pengujian yang kelihatan kayak gini:
Doc-tests my_crate
running 1 test
test src/lib.rs - add_one (line 5) ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.27s
Sekarang, kalau kita mengubah fungsinya atau contohnya sehingga assert_eq!
di contoh tersebut mengalami panic, lalu menjalankan cargo test lagi, kita
bakal melihat kalau doc tests bakal menangkap bahwa contoh dan kodenya
sudah tidak sinkron lagi!
Mengomentari Item Penampungnya (Contained Items)
Gaya komentar dokumentasi //! menambahkan dokumentasi ke item yang menampung
komentar tersebut, bukannya ke item-item yang mengikuti komentarnya. Kita
biasanya memakai jenis komentar dokumentasi ini di dalam file crate root
(src/lib.rs secara konvensi) atau di dalam sebuah modul buat mendokumentasikan
crate atau modulnya secara keseluruhan.
Misalnya, buat menambahkan dokumentasi yang mendeskripsikan tujuan dari
crate my_crate yang mengandung fungsi add_one, kita bisa menambahkan
komentar dokumentasi yang dimulai dengan //! ke bagian paling awal dari
file src/lib.rs, seperti yang ditunjukkan di Listing 14-2.
//! # My Crate
//!
//! `my_crate` is a collection of utilities to make performing certain
//! calculations more convenient.
/// Adds one to the number given.
// --snip--
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}my_crate secara keseluruhanPerhatikan bahwa tidak ada kode apa pun setelah baris terakhir yang dimulai
dengan //!. Karena kita memulai komentarnya dengan //! bukannya ///,
kita mendokumentasikan item yang menampung komentar ini, bukannya item yang
ada setelah komentar ini. Di kasus ini, item tersebut adalah file
src/lib.rs, yang mana itu adalah crate root. Komentar-komentar ini
mendeskripsikan crate-nya secara keseluruhan.
Pas kita menjalankan cargo doc --open, komentar-komentar ini bakal tampil
di halaman depan dokumentasi untuk my_crate tepat di atas daftar item-item
public di crate tersebut, seperti yang ditunjukkan di Gambar 14-2.
Gambar 14-2: Dokumentasi yang dirender buat my_crate, termasuk komentar yang mendeskripsikan crate secara keseluruhan
Komentar dokumentasi yang ditaruh di dalam item sangat berguna buat mendeskripsikan crates dan juga modules (modul). Pakailah mereka buat menjelaskan tujuan keseluruhan dari wadah (container)-nya demi membantu para user kita memahami organisasi crate tersebut.
Mengekspor API Public yang Nyaman dengan pub use
Struktur dari API public kita adalah pertimbangan besar saat mempublikasikan sebuah crate. Orang-orang yang memakai crate kita itu kurang familier dengan strukturnya dibandingkan kita dan mungkin bakal kesusahan mencari bagian-bagian yang mau mereka pakai kalau crate kita punya hierarki modul yang besar.
Di Bab 7, kita sudah membahas gimana cara membikin item jadi public memakai
keyword pub, dan gimana cara membawa item ke dalam scope memakai keyword
use. Namun, struktur yang menurut kita masuk akal saat kita lagi ngembangin
sebuah crate mungkin aja tidak terlalu nyaman buat para user kita. Kita
mungkin mau mengatur structs kita di dalam sebuah hierarki yang terdiri dari
beberapa tingkat, tapi nanti orang yang mau memakai tipe yang sudah kita
definisikan jauh di kedalaman hierarki itu mungkin bakal kesulitan buat tahu kalau
tipe tersebut ada. Mereka juga mungkin bakal jengkel karena harus mengetikkan
use my_crate::some_module::another_module::UsefulType; bukannya sekadar
use my_crate::UsefulType;.
Kabar baiknya adalah kalau struktur yang kita buat tidak nyaman buat orang lain
pakai dari library mereka, kita tidak harus menata ulang organisasi
internalnya: sebagai gantinya, kita bisa me-re-export (mengekspor ulang)
item-item buat bikin sebuah struktur public yang beda dari struktur private
kita dengan menggunakan pub use. Re-exporting mengambil sebuah item public
di satu lokasi lalu membikinnya jadi public di lokasi lain, seolah-olah
item tersebut didefinisikan di lokasi yang lain itu.
Misalnya, katakanlah kita bikin sebuah library bernama art untuk memodelkan
konsep-konsep kesenian. Di dalam library ini ada dua modul: modul kinds yang
berisi dua enum bernama PrimaryColor dan SecondaryColor, serta modul
utils yang berisi fungsi bernama mix, seperti yang ditunjukkan di Listing 14-3.
//! # Art
//!
//! A library for modeling artistic concepts.
pub mod kinds {
/// The primary colors according to the RYB color model.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// The secondary colors according to the RYB color model.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
use crate::kinds::*;
/// Combines two primary colors in equal amounts to create
/// a secondary color.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
// --snip--
unimplemented!();
}
}art yang punya item-item yang diatur ke dalam modul kinds dan utilsGambar 14-3 menunjukkan seperti apa jadinya halaman depan dokumentasi untuk
crate ini yang di-generate oleh cargo doc.
Gambar 14-3: Halaman depan dokumentasi untuk art yang mendaftarkan modul kinds dan utils
Perhatikan bahwa tipe PrimaryColor dan SecondaryColor tidak terdaftar di
halaman depan, fungsi mix juga tidak ada. Kita harus mengklik kinds dan
utils buat melihat mereka.
Crate lain yang bergantung pada library ini bakal butuh statements
use yang membawa item-item dari art ke dalam scope, dengan menentukan
struktur modul yang saat ini didefinisikan. Listing 14-4 menunjukkan contoh
sebuah crate yang memakai item PrimaryColor dan mix dari crate art.
use art::kinds::PrimaryColor;
use art::utils::mix;
fn main() {
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}art dengan struktur internalnya yang tereksporPembuat kode di Listing 14-4, yang memakai crate art, harus mencari tahu
kalau PrimaryColor ada di dalam modul kinds dan mix ada di dalam
modul utils. Struktur modul dari crate art ini lebih relevan buat para
developer yang mengerjakan crate art tersebut dibanding buat orang yang
memakainya. Struktur internalnya tidak memberikan informasi yang berguna buat
seseorang yang lagi mencoba buat paham gimana cara memakai crate art
tersebut, melainkan malah bikin bingung karena developer yang memakainya harus
nyari tahu di mana harus mencari, dan harus mengetikkan nama-nama modulnya
di statement use.
Buat menghilangkan organisasi internalnya dari API public, kita bisa
memodifikasi kode crate art di Listing 14-3 dengan menambahkan statements
pub use buat me-re-export item-item itu di tingkat paling atas, seperti
yang ditunjukkan di Listing 14-5.
//! # Art
//!
//! A library for modeling artistic concepts.
pub use self::kinds::PrimaryColor;
pub use self::kinds::SecondaryColor;
pub use self::utils::mix;
pub mod kinds {
// --snip--
/// The primary colors according to the RYB color model.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// The secondary colors according to the RYB color model.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
// --snip--
use crate::kinds::*;
/// Combines two primary colors in equal amounts to create
/// a secondary color.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
SecondaryColor::Orange
}
}pub use buat me-re-export itemDokumentasi API yang di-generate sama cargo doc buat crate ini sekarang
bakal mendaftarkan dan menaruh tautan ke re-exports tersebut di halaman depan,
seperti yang ditunjukkan di Gambar 14-4, sehingga bikin tipe PrimaryColor dan
SecondaryColor serta fungsi mix jadi lebih gampang dicari.
Gambar 14-4: Halaman depan dokumentasi buat art yang mendaftarkan hasil re-exports
Para pengguna crate art masih bisa melihat dan memakai struktur internalnya
dari Listing 14-3 seperti yang didemonstrasikan di Listing 14-4, atau mereka
bisa memakai struktur yang lebih nyaman dari Listing 14-5, seperti yang
ditunjukkan di Listing 14-6.
use art::PrimaryColor;
use art::mix;
fn main() {
// --snip--
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}artDi kasus di mana ada banyak modul yang bersarang (nested modules), me-re-export
tipe di level teratas dengan pub use bisa bikin perbedaan yang sangat besar
dalam pengalaman (experience) orang-orang yang memakai crate tersebut.
Kegunaan umum lain dari pub use adalah buat me-re-export definisi dari
sebuah dependency (dependensi) di crate saat ini buat bikin definisi
crate itu jadi bagian dari API public crate kita.
Membikin struktur API public yang berguna itu lebih ke arah seni ketimbang sains
eksak, dan kita bisa melakukan iterasi buat nemuin API apa yang bekerja paling
baik buat para user kita. Memilih buat pakai pub use ngasih kita fleksibilitas
dalam mengatur gimana struktur internal crate kita dan melepaskan kaitan
(decouples) antara struktur internal itu dari apa yang kita tampilkan ke para user
kita. Coba deh lihat beberapa kode dari crates yang udah kita instal buat melihat
apakah struktur internal mereka berbeda dari API public mereka.
Menyiapkan Akun Crates.io
Sebelum kita bisa mempublikasikan crates apa pun, kita harus bikin akun dulu
di crates.io dan dapetin API token. Buat melakukannya,
kunjungi halaman depan di crates.io lalu login pakai akun
GitHub. (Akun GitHub saat ini adalah syarat wajibnya, tapi situsnya mungkin bakal
mendukung cara lain buat bikin akun di masa depan.) Setelah kita login, kunjungi
pengaturan akun kita di https://crates.io/me/ lalu ambil
kunci (key) API kita. Kemudian jalankan perintah cargo login dan paste
kunci API kita pas diminta, kayak gini:
$ cargo login
abcdefghijklmnopqrstuvwxyz012345
Perintah ini bakal ngasih tahu Cargo soal token API kita lalu menyimpannya secara lokal di ~/.cargo/credentials.toml. Perhatikan bahwa token ini adalah sebuah rahasia (secret): jangan bagikan ke orang lain. Kalau kita membagikannya ke orang lain dengan alasan apa pun, kita harus menariknya (revoke) dan membuat token baru di crates.io.
Menambahkan Metadata ke Crate Baru
Katakanlah kita punya sebuah crate yang mau kita publikasikan. Sebelum dipublish,
kita harus menambahkan beberapa metadata di bagian [package] dari file Cargo.toml
milik crate tersebut.
Crate kita bakal butuh nama yang unik. Selama kita mengerjakan crate secara
lokal, kita bisa menamai crate sesuka kita. Namun, nama crate di
crates.io itu dialokasikan berdasarkan siapa cepat dia
dapat (first-come, first-served). Begitu sebuah nama crate sudah diambil,
tidak ada orang lain yang bisa mempublikasikan crate dengan nama tersebut.
Sebelum mencoba buat mempublikasikan sebuah crate, carilah nama yang pengen kita
pakai. Kalau nama tersebut sudah terpakai, kita harus mencari nama lain lalu
mengedit field name di dalam file Cargo.toml di bawah bagian [package] buat
memakai nama baru tersebut untuk publikasi, kayak gini:
Nama file: Cargo.toml
[package]
name = "guessing_game"
Meskipun kita sudah milih nama yang unik, saat kita menjalankan cargo publish
buat mempublikasikan crate di titik ini, kita bakal dapat peringatan dan lalu
sebuah error:
$ cargo publish
Updating crates.io index
warning: manifest has no description, license, license-file, documentation, homepage or repository.
See https://doc.rust-lang.org/cargo/reference/manifest.html#package-metadata for more info.
--snip--
error: failed to publish to registry at https://crates.io
Caused by:
the remote server responded with an error (status 400 Bad Request): missing or empty metadata fields: description, license. Please see https://doc.rust-lang.org/cargo/reference/manifest.html for more information on configuring these fields
Ini menghasilkan error karena kita kelupaan beberapa informasi yang krusial:
sebuah deskripsi (description) dan lisensi (license) diwajibkan supaya
orang-orang bisa tahu apa yang dilakukan sama crate kita dan di bawah
ketentuan (terms) apa mereka bisa memakainya. Di Cargo.toml, tambahkan sebuah
deskripsi yang hanya terdiri dari satu atau dua kalimat aja, karena itu bakal
muncul bareng crate kita di hasil pencarian. Buat field license, kita harus
memberikan nilai pengenal lisensi (license identifier value).
Software Package Data Exchange (SPDX) milik Linux Foundation
mendaftarkan pengenal yang bisa kita pakai buat nilai ini. Misalnya, buat
menentukan kalau kita melisensikan crate kita memakai Lisensi MIT, tambahkan
pengenal MIT:
Nama file: Cargo.toml
[package]
name = "guessing_game"
license = "MIT"
Kalau kita mau memakai lisensi yang tidak muncul di SPDX, kita perlu menaruh teks
dari lisensi tersebut di sebuah file, memasukkan file itu di project kita, lalu
memakai license-file buat menentukan nama dari file tersebut sebagai ganti dari
memakai key license.
Panduan soal lisensi mana yang pas buat project kita ada di luar cakupan buku ini.
Banyak orang di komunitas Rust melisensikan project mereka pakai cara yang sama
kayak Rust dengan memakai dual license (lisensi ganda) MIT OR Apache-2.0.
Praktik ini menunjukkan kalau kita juga bisa menentukan lebih dari satu
pengenal lisensi yang dipisahkan oleh OR buat punya banyak lisensi di
project kita.
Dengan nama yang unik, versi, deskripsi kita, dan lisensi yang sudah ditambahkan, file Cargo.toml untuk project yang siap dipublish mungkin bakal kelihatan kayak gini:
Nama file: Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2024"
description = "A fun game where you guess what number the computer has chosen."
license = "MIT OR Apache-2.0"
[dependencies]
Dokumentasi Cargo mendeskripsikan metadata lain yang bisa kita tentukan buat memastikan orang lain bisa lebih gampang menemukan dan memakai crate kita.
Mempublikasikan ke Crates.io
Sekarang karena kita udah bikin akun, nyimpan token API kita, memilih nama buat crate kita, dan menentukan metadata yang dibutuhin, kita sudah siap buat melakukan publikasi! Mempublikasikan sebuah crate mengunggah versi spesifiknya ke crates.io biar orang lain bisa pakai.
Hati-hati ya, karena mempublikasikan itu sifatnya permanen. Versi itu tidak akan pernah bisa ditimpa (overwritten), dan kodenya tidak bisa dihapus kecuali di situasi-situasi tertentu. Salah satu tujuan utama dari Crates.io adalah bertindak sebagai arsip kode yang permanen sehingga proses build dari semua project yang bergantung pada crates dari crates.io bakal terus berfungsi. Mengizinkan penghapusan versi bakal bikin pemenuhan tujuan tersebut jadi mustahil. Namun, tidak ada batas buat seberapa banyak versi crate yang bisa kita publikasikan.
Jalankan perintah cargo publish lagi. Kali ini harusnya udah berhasil:
$ cargo publish
Updating crates.io index
Packaging guessing_game v0.1.0 (file:///projects/guessing_game)
Packaged 6 files, 1.2KiB (895.0B compressed)
Verifying guessing_game v0.1.0 (file:///projects/guessing_game)
Compiling guessing_game v0.1.0
(file:///projects/guessing_game/target/package/guessing_game-0.1.0)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.19s
Uploading guessing_game v0.1.0 (file:///projects/guessing_game)
Uploaded guessing_game v0.1.0 to registry `crates-io`
note: waiting for `guessing_game v0.1.0` to be available at registry
`crates-io`.
You may press ctrl-c to skip waiting; the crate should be available shortly.
Published guessing_game v0.1.0 at registry `crates-io`
Selamat! Kita sekarang sudah nge-share kode kita sama komunitas Rust, dan siapa pun bisa dengan gampang nambahin crate kita sebagai dependency di project mereka.
Mempublikasikan Versi Baru dari Crate yang Sudah Ada
Saat kita bikin perubahan di crate kita dan udah siap buat ngerilis versi
baru, kita cukup ganti nilai version yang ditentukan di file Cargo.toml
kita dan publish ulang (republish). Pakai aturan Semantic Versioning
buat nentuin apa nomor versi selanjutnya yang paling pas, berdasarkan
jenis perubahan yang sudah kita buat. Terus jalankan cargo publish buat
mengunggah versi barunya.
Melarang Penggunaan Versi Lama dari Crates.io dengan cargo yank
Meskipun kita tidak bisa menghapus versi lama dari sebuah crate, kita bisa mencegah project-project di masa depan buat menambahkan versi tersebut sebagai dependency baru. Hal ini berguna pas sebuah versi crate ternyata rusak (broken) karena suatu alasan tertentu. Di situasi semacam itu, Cargo mendukung aksi “menyentak” (yanking) sebuah versi crate.
Yanking sebuah versi mencegah project baru untuk bisa bergantung pada versi tersebut sekaligus tetap membiarkan semua project yang sudah ada yang bergantung pada versi itu buat terus berjalan. Pada dasarnya, aksi yank berarti bahwa semua project yang sudah punya file Cargo.lock tidak akan rusak, dan file Cargo.lock apa pun yang di-generate di masa depan tidak bakal memakai versi yang di-yank tersebut.
Buat menge-yank sebuah versi crate, dari dalam direktori crate yang
tadinya sudah kita publikasikan, jalankan cargo yank dan tentukan versi mana
yang mau kita yank. Misalnya, kalau kita sudah mempublikasikan sebuah crate
bernama guessing_game versi 1.0.1 dan kita mau menge-yank-nya, di dalam
direktori project buat guessing_game kita bakal menjalankan:
$ cargo yank --vers 1.0.1
Updating crates.io index
Yank guessing_game@1.0.1
Dengan menambahkan --undo ke dalam command-nya, kita juga bisa
membatalkan aksi yank (meng-unyank) lalu mengizinkan project-project buat
mulai bergantung lagi pada sebuah versi:
$ cargo yank --vers 1.0.1 --undo
Updating crates.io index
Unyank guessing_game@1.0.1
Aksi yank sama sekali tidak menghapus kode apa pun. Ia tidak bisa, misalnya, menghapus data rahasia (secrets) yang tidak sengaja terunggah. Kalau hal seperti itu terjadi, kita harus langsung nge-reset rahasia tersebut.
Cargo Workspaces
Cargo Workspaces
Di Bab 12, kita udah bikin sebuah package yang isinya satu binary crate sama satu library crate. Seiring berkembangnya project kita, kita mungkin menemukan bahwa library crate kita terus jadi makin besar dan kita mau membagi package kita lebih jauh lagi jadi beberapa library crates. Cargo menawarkan fitur bernama workspaces (ruang kerja) yang bisa membantu mengelola beberapa packages yang saling terkait yang dikembangkan secara beriringan (in tandem).
Membuat Workspace
Sebuah workspace adalah sekumpulan packages yang berbagi Cargo.lock dan
direktori output yang sama. Mari kita bikin project yang memakai
workspace—kita bakal pakai kode yang sepele biar kita bisa fokus ke
struktur dari workspace tersebut. Ada banyak cara buat menata struktur
sebuah workspace, jadi kita cuma bakal nunjukin satu cara yang umum.
Kita bakal punya sebuah workspace yang berisi satu binary dan dua
libraries. Si binary, yang bakal menyediakan fungsionalitas utama,
bakal bergantung pada (depend on) kedua libraries itu. Satu library
bakal menyediakan fungsi add_one dan library yang satunya lagi
menyediakan fungsi add_two. Ketiga crates ini bakal jadi bagian dari
workspace yang sama. Kita bakal memulainya dengan membuat direktori baru
buat workspace tersebut:
$ mkdir add
$ cd add
Berikutnya, di dalam direktori add, kita bikin file Cargo.toml yang
bakal mengkonfigurasi seluruh workspace. File ini tidak bakal punya
bagian [package]. Sebaliknya, file ini bakal diawali dengan bagian
[workspace] yang bakal memungkinkan kita buat menambahkan anggota
(members) ke dalam workspace. Kita juga sengaja menentukan buat memakai
algoritma resolver (pemecah) Cargo versi yang paling baru dan paling
bagus di workspace kita dengan menge-set nilai resolver ke "3".
Nama file: Cargo.toml
[workspace]
resolver = "3"
Selanjutnya, kita bakal membikin binary crate adder dengan menjalankan
cargo new di dalam direktori add:
$ cargo new adder
Created binary (application) `adder` package
Adding `adder` as member of workspace at `file:///projects/add`
Menjalankan cargo new di dalam sebuah workspace juga secara otomatis
menambahkan package yang baru dibuat itu ke dalam key members di
definisi [workspace] yang ada di Cargo.toml tingkat workspace, kayak gini:
[workspace]
resolver = "3"
members = ["adder"]
Pada titik ini, kita bisa mem-build workspace ini dengan menjalankan
cargo build. File-file di direktori add kita seharusnya kelihatan
seperti ini:
├── Cargo.lock
├── Cargo.toml
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
Workspace ini cuma punya satu direktori target di tingkat teratas
(top level) tempat artefak hasil kompilasi bakal ditaruh; package
adder tidak punya direktori target-nya sendiri. Bahkan kalau pun kita
menjalankan cargo build dari dalam direktori adder, artefak
hasil kompilasinya bakal tetap berujung di add/target bukannya di
add/adder/target. Cargo menata struktur direktori target di sebuah
workspace seperti ini karena crates di dalam sebuah workspace itu
memang ditujukan buat bergantung satu sama lain. Kalau setiap crate punya
direktori target-nya sendiri, setiap crate harus men-compile ulang
setiap crate lainnya di dalam workspace itu buat menaruh artefaknya di
direktori target-nya sendiri-sendiri. Dengan berbagi satu direktori
target, crates bisa menghindari kompilasi ulang yang tidak diperlukan.
Membuat Package Kedua di dalam Workspace
Berikutnya, mari kita buat member package (paket anggota) lain di dalam
workspace ini dan namakan dia add_one. Generate sebuah library crate
baru bernama add_one:
$ cargo new add_one --lib
Created library `add_one` package
Adding `add_one` as member of workspace at `file:///projects/add`
File Cargo.toml tingkat teratas sekarang bakal menyertakan path add_one
ke dalam daftar members:
Nama file: Cargo.toml
[workspace]
resolver = "3"
members = ["adder", "add_one"]
Direktori add kita seharusnya sekarang punya direktori dan file berikut ini:
├── Cargo.lock
├── Cargo.toml
├── add_one
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
Di dalam file add_one/src/lib.rs, mari kita tambahkan sebuah fungsi add_one:
Nama file: add_one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}Sekarang kita bisa bikin package adder dengan binary kita bergantung pada
package add_one yang punya library kita. Pertama-tama, kita harus
menambahkan path dependency pada add_one ke dalam adder/Cargo.toml.
Nama file: adder/Cargo.toml
[dependencies]
add_one = { path = "../add_one" }
Cargo tidak mengasumsikan kalau crates di dalam sebuah workspace bakal bergantung satu sama lain, jadi kita harus secara eksplisit mendefinisikan hubungan dependensi (ketergantungan) mereka.
Selanjutnya, mari kita pakai fungsi add_one (dari crate add_one) di dalam
crate adder. Buka file adder/src/main.rs dan ubah fungsi main buat
memanggil fungsi add_one, seperti di Listing 14-7.
fn main() {
let num = 10;
println!("Hello, world! {num} plus one is {}!", add_one::add_one(num));
}add_one dari dalam crate adderMari kita build workspace ini dengan menjalankan cargo build di direktori
tingkat teratas add!
$ cargo build
Compiling add_one v0.1.0 (file:///projects/add/add_one)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.22s
Buat menjalankan binary crate tersebut dari direktori add, kita bisa
menentukan package mana di dalam workspace yang mau kita jalankan dengan
memakai argumen -p beserta nama package-nya dengan cargo run:
$ cargo run -p adder
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/adder`
Hello, world! 10 plus one is 11!
Ini bakal menjalankan kode di adder/src/main.rs, yang mana bergantung pada
crate add_one.
Bergantung pada Package Eksternal di dalam Workspace
Perhatikan bahwa workspace ini cuma punya satu file Cargo.lock di tingkat
teratas, bukannya punya file Cargo.lock di setiap direktori crate. Ini
memastikan kalau semua crates memakai versi yang persis sama buat semua
dependensinya. Kalau kita menambahkan package rand ke dalam file
adder/Cargo.toml dan add_one/Cargo.toml, Cargo bakal me-resolve keduanya
ke satu versi dari rand dan mencatat hal itu di dalam satu file Cargo.lock
tersebut. Membuat semua crates di workspace memakai dependensi yang sama
berarti semua crates tersebut bakal selalu kompatibel satu sama lain.
Mari kita tambahkan crate rand ke bagian [dependencies] di file
add_one/Cargo.toml supaya kita bisa memakai crate rand di dalam crate
add_one:
Nama file: add_one/Cargo.toml
[dependencies]
rand = "0.8.5"
Sekarang kita bisa menambahkan use rand; ke dalam file add_one/src/lib.rs,
dan saat mem-build seluruh workspace dengan menjalankan cargo build di
direktori add bakal ikut membawa dan men-compile crate rand. Kita bakal
dapat satu peringatan (warning) karena kita belum memakai rand yang sudah kita
bawa ke dalam scope tersebut:
$ cargo build
Updating crates.io index
Downloaded rand v0.8.5
--snip--
Compiling rand v0.8.5
Compiling add_one v0.1.0 (file:///projects/add/add_one)
warning: unused import: `rand`
--> add_one/src/lib.rs:1:5
|
1 | use rand;
| ^^^^
|
= note: `#[warn(unused_imports)]` on by default
warning: `add_one` (lib) generated 1 warning (run `cargo fix --lib -p add_one` to apply 1 suggestion)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.95s
File Cargo.lock di tingkat teratas sekarang berisi informasi mengenai
dependensi dari add_one terhadap rand. Namun, meskipun rand sudah dipakai
di suatu tempat di dalam workspace, kita tidak bisa memakainya di crates
lainnya di workspace ini kecuali kita menambahkan rand ke dalam file
Cargo.toml mereka juga. Misalnya, kalau kita menambahkan use rand; ke dalam
file adder/src/main.rs untuk package adder, kita bakal dapat error:
$ cargo build
--snip--
Compiling adder v0.1.0 (file:///projects/add/adder)
error[E0432]: unresolved import `rand`
--> adder/src/main.rs:2:5
|
2 | use rand;
| ^^^^ no external crate `rand`
Buat memperbaikinya, edit file Cargo.toml untuk package adder dan
indikasikan kalau rand juga adalah sebuah dependensi buatnya. Mem-build
package adder bakal menambahkan rand ke dalam daftar dependensi untuk
adder di dalam Cargo.lock, tapi tidak akan ada salinan tambahan dari
rand yang bakal di-download. Cargo bakal memastikan kalau setiap crate di
setiap package di dalam workspace yang memakai package rand bakal
memakai versi yang persis sama selama mereka menentukan versi dari rand yang
kompatibel, hal ini menghemat kapasitas penyimpanan kita dan memastikan kalau
semua crates di workspace ini bakal kompatibel satu sama lain.
Kalau crates di workspace menentukan versi yang tidak kompatibel dari dependensi yang sama, Cargo bakal mencoba me-resolve masing-masing dari mereka, tapi tetap bakal berusaha me-resolve ke sesedikit mungkin versi.
Menambahkan Pengujian ke Workspace
Untuk peningkatan selanjutnya, mari kita tambahkan sebuah pengujian buat fungsi
add_one::add_one di dalam crate add_one:
Nama file: add_one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
assert_eq!(3, add_one(2));
}
}Sekarang jalankan cargo test di dalam direktori add di tingkat teratas.
Menjalankan cargo test di sebuah workspace yang ditata seperti ini bakal
menjalankan pengujian untuk semua crates di dalam workspace tersebut:
$ cargo test
Compiling add_one v0.1.0 (file:///projects/add/add_one)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.20s
Running unittests src/lib.rs (target/debug/deps/add_one-93c49ee75dc46543)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/adder-3a47283c568d2b6a)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Bagian pertama dari outputnya menunjukkan kalau pengujian it_works di dalam
crate add_one itu sukses (passed). Bagian selanjutnya menunjukkan kalau ada
nol pengujian yang ditemukan di dalam crate adder, dan lalu bagian terakhir
menunjukkan kalau ada nol pengujian dokumentasi yang ditemukan di dalam crate
add_one.
Kita juga bisa menjalankan pengujian buat satu crate tertentu di dalam
sebuah workspace dari direktori tingkat teratas dengan memakai flag -p
dan menentukan nama dari crate yang mau kita uji:
$ cargo test -p add_one
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.00s
Running unittests src/lib.rs (target/debug/deps/add_one-93c49ee75dc46543)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Output ini menunjukkan kalau cargo test cuma menjalankan pengujian untuk
crate add_one dan tidak menjalankan pengujian untuk crate adder.
Kalau kita mempublikasikan crates yang ada di dalam workspace ke
crates.io, setiap crate di dalam workspace itu
harus dipublikasikan secara terpisah. Sama seperti cargo test, kita bisa
mempublikasikan satu crate tertentu di dalam workspace kita dengan memakai
flag -p dan menentukan nama dari crate yang mau kita publikasikan.
Sebagai latihan tambahan, coba tambahkan crate add_two ke dalam workspace
ini dengan cara yang sama seperti crate add_one!
Seiring project kita bertambah besar, pertimbangkanlah buat memakai sebuah workspace: ini memungkinkan kita buat bekerja dengan komponen-komponen yang lebih kecil dan lebih gampang dipahami ketimbang bekerja dengan satu gumpalan kode (blob of code) yang super besar. Selain itu, menyimpan crates di dalam sebuah workspace bisa bikin koordinasi antar crates jadi lebih mudah kalau mereka sering diubah secara bersamaan.
Menginstal Binari Memakai cargo install
Menginstal Binaries dengan cargo install
Perintah cargo install memungkinkan kita buat menginstal dan memakai binary
crates secara lokal. Ini tidak ditujukan buat menggantikan sistem packages;
ini ditujukan sebagai cara yang praktis buat para developer Rust untuk
menginstal tools yang udah di-share sama orang lain di
crates.io. Perhatikan bahwa kita cuma bisa menginstal
packages yang punya binary targets. Sebuah binary target adalah program
yang bisa dijalankan (runnable) yang dibikin kalau crate tersebut punya
file src/main.rs atau file lain yang ditentukan sebagai binary, kebalikan
dari library target yang tidak bisa dijalankan secara mandiri melainkan cocok
buat dimasukkan ke dalam program lain. Biasanya, crates punya informasi di
dalam file README soal apakah sebuah crate itu library, punya binary
target, atau dua-duanya.
Semua binaries yang diinstal pakai cargo install disimpan di dalam folder
bin di direktori root instalasi. Kalau kita menginstal Rust pakai
rustup.rs dan tidak punya konfigurasi kustom apa pun, direktori ini bakal ada
di $HOME/.cargo/bin. Pastikan direktori tersebut ada di dalam $PATH kita
biar kita bisa menjalankan program-program yang udah kita instal pakai
cargo install.
Misalnya, di Bab 12 kita sempat menyinggung kalau ada implementasi Rust dari
tool grep yang bernama ripgrep buat nyari-nyari file. Buat menginstal
ripgrep, kita bisa menjalankan yang berikut ini:
$ cargo install ripgrep
Updating crates.io index
Downloaded ripgrep v14.1.1
Downloaded 1 crate (213.6 KB) in 0.40s
Installing ripgrep v14.1.1
--snip--
Compiling grep v0.3.2
Finished `release` profile [optimized + debuginfo] target(s) in 6.73s
Installing ~/.cargo/bin/rg
Installed package `ripgrep v14.1.1` (executable `rg`)
Dua baris terakhir dari output-nya menunjukkan lokasi dan nama dari binary
yang udah diinstal, yang mana di kasus ripgrep namanya adalah rg. Selama
direktori instalasinya ada di dalam $PATH kita, seperti yang udah disebutkan
sebelumnya, kita kemudian bisa menjalankan rg --help dan mulai memakai tool
yang lebih kencang dan lebih bergaya Rust buat nyari file!
Memperluas Cargo Memakai Command Kustom
Memperluas Kemampuan Cargo dengan Custom Commands (Perintah Kustom)
Cargo didesain biar kita bisa memperluas kemampuannya dengan subcommands baru
tanpa harus memodifikasi Cargo itu sendiri. Kalau sebuah binary di dalam
$PATH kita bernama cargo-sesuatu, kita bisa menjalankannya seolah-olah itu
adalah subcommand Cargo dengan menjalankan cargo sesuatu. Custom commands
kayak gini juga terdaftar saat kita menjalankan cargo --list. Kemampuan buat
memakai cargo install untuk menginstal ekstensi-ekstensi lalu menjalankannya
persis seperti tools bawaan Cargo adalah salah satu keuntungan super-nyaman
dari desain Cargo!
Ringkasan
Menge-share kode pakai Cargo dan crates.io adalah bagian dari hal yang bikin ekosistem Rust jadi berguna buat berbagai macam tugas. Standard library Rust itu kecil dan stabil, tapi crates itu gampang sekali buat di-share, dipakai, dan ditingkatkan di timeline (garis waktu) yang beda dari timeline bahasa Rust itu sendiri. Jangan malu-malu buat nge-share kode yang berguna buat kita di crates.io; kemungkinan besar kode itu bakal berguna buat orang lain juga!
Smart Pointers
Pointer (penunjuk) adalah sebuah konsep umum buat sebuah variabel yang
mengandung sebuah alamat di memori. Alamat ini merujuk ke, atau “menunjuk
ke,” data lain. Jenis pointer yang paling umum di Rust adalah sebuah
referensi, yang udah kita pelajari di Bab 4. Referensi ditandai oleh
simbol & dan meminjam (borrow) nilai yang mereka tunjuk. Mereka tidak
punya kemampuan spesial apa-apa selain cuma merujuk ke data, dan mereka
tidak punya biaya overhead.
Smart pointers (penunjuk pintar), di sisi lain, adalah struktur data yang bertindak seperti sebuah pointer tapi juga punya metadata dan kemampuan tambahan. Konsep smart pointers ini bukan cuma ada di Rust: smart pointers asalnya dari C++ dan ada di bahasa pemrograman lain juga. Rust punya berbagai macam smart pointers yang didefinisikan di standard library yang menyediakan fungsionalitas lebih dari sekadar apa yang disediakan oleh referensi biasa. Buat mengeksplorasi konsep umumnya, kita bakal melihat beberapa contoh smart pointers yang berbeda, termasuk tipe smart pointer reference counting (penghitungan referensi). Pointer ini memungkinkan kita buat membiarkan sebuah data punya banyak pemilik (owners) dengan melacak (keeping track of) jumlah pemilik yang ada dan, saat tidak ada pemilik yang tersisa, membersihkan (cleaning up) datanya.
Rust, dengan konsep ownership dan borrowing-nya, punya perbedaan tambahan antara referensi dan smart pointers: walaupun referensi cuma meminjam data, di banyak kasus smart pointers memiliki (own) data yang mereka tunjuk.
Smart pointers biasanya diimplementasikan memakai structs. Tidak seperti
struct biasa, smart pointers mengimplementasikan trait Deref dan Drop.
Trait Deref memungkinkan sebuah instance dari struct smart pointer
berperilaku seperti sebuah referensi sehingga kita bisa menulis kode yang
bisa bekerja buat referensi maupun buat smart pointers. Trait Drop
memungkinkan kita buat mengkustomisasi kode yang bakal dijalankan saat
sebuah instance dari smart pointer keluar dari scope. Di bab ini, kita
bakal membahas kedua trait tersebut dan mendemonstrasikan kenapa mereka
itu penting buat smart pointers.
Mengingat kalau smart pointer itu adalah sebuah desain pola yang umum dan sering sekali dipakai di Rust, bab ini tidak akan membahas setiap smart pointer yang pernah ada. Banyak libraries punya smart pointers mereka sendiri, dan kita bahkan bisa bikin smart pointer kita sendiri. Kita bakal membahas smart pointers yang paling umum di standard library:
Box<T>, buat mengalokasikan nilai di heapRc<T>, sebuah tipe reference counting yang memungkinkan kepemilikan ganda (multiple ownership)Ref<T>danRefMut<T>, yang diakses melaluiRefCell<T>, sebuah tipe yang menerapkan (enforces) aturan borrowing saat runtime ketimbang pas compile time
Selain itu, kita bakal ngebahas desain pola interior mutability (mutabilitas interior) di mana sebuah tipe yang immutable (tidak bisa diubah) mengekspos sebuah API buat memutasi nilai internalnya. Kita juga bakal ngebahas siklus referensi (reference cycles): gimana mereka bisa membocorkan memori (leak memory) dan gimana cara mencegahnya.
Mari kita selami!
Memakai Box<T> buat Menunjuk ke Data di Heap
Memakai Box<T> buat Menunjuk ke Data di Heap
Smart pointer yang paling sederhana adalah box (kotak), yang tipenya
ditulis Box<T>. Boxes memungkinkan kita buat nyimpan data di heap
ketimbang di stack. Apa yang tersisa di stack adalah si pointer yang
menunjuk ke data di heap tersebut. Silakan merujuk lagi ke Bab 4 buat
me-review perbedaan antara stack dan heap.
Boxes tidak punya overhead performa, selain harus menyimpan data mereka di heap alih-alih di stack. Tapi mereka juga tidak punya banyak kemampuan ekstra. Kita bakal paling sering memakainya di situasi-situasi berikut:
- Saat kita punya sebuah tipe yang ukurannya tidak bisa diketahui secara pasti pas compile time dan kita mau memakai sebuah nilai dari tipe itu di konteks yang membutuhkan ukuran yang persis
- Saat kita punya jumlah data yang besar dan kita mau mentransfer kepemilikannya (ownership) tapi tetap pengen memastikan kalau datanya tidak bakal disalin (copied) saat kita melakukannya
- Saat kita pengen memiliki sebuah nilai dan kita cuma peduli kalau nilai itu adalah tipe yang mengimplementasikan trait tertentu, bukannya merupakan suatu tipe spesifik
Kita bakal mendemonstrasikan situasi pertama di “Memungkinkan Tipe Rekursif dengan Boxes”. Di kasus kedua, mentransfer kepemilikan dari data yang sangat besar bisa memakan waktu lama karena datanya bakal disalin mondar-mandir di stack. Buat meningkatkan performa di situasi ini, kita bisa menyimpan jumlah data yang besar itu di heap di dalam sebuah box. Dengan begitu, cuma data pointer yang kecil itu doang yang bakal disalin mondar-mandir di stack, sementara data yang ditunjuknya tetap diam di satu tempat di heap. Kasus ketiga dikenal sebagai trait object, dan “Memakai Trait Objects yang Mengizinkan Nilai Dari Tipe yang Berbeda-beda” di Bab 18 memang dikhususkan untuk membahas topik tersebut. Jadi, apa yang kita pelajari di sini bakal kita terapkan lagi di bagian itu!
Memakai Box<T> buat Menyimpan Data di Heap
Sebelum kita membahas kegunaan penyimpanan di heap untuk Box<T>, kita
bakal membahas sintaksnya dan gimana cara berinteraksi sama nilai yang
disimpan di dalam Box<T>.
Listing 15-1 menunjukkan gimana cara memakai box buat menyimpan nilai i32
di heap.
fn main() {
let b = Box::new(5);
println!("b = {b}");
}i32 di heap menggunakan sebuah boxKita mendefinisikan variabel b buat punya nilai berupa sebuah Box yang
menunjuk ke nilai 5, yang mana nilainya itu dialokasikan di heap. Program
ini bakal mencetak b = 5; di kasus ini, kita bisa mengakses data yang
ada di dalam box ini mirip kayak kalau datanya ada di stack. Sama
kayak nilai (owned value) lainnya, pas sebuah box keluar dari scope,
sebagaimana yang terjadi pada b di akhir dari main, dia bakal di-deallocate
(dihapus dari memori). Proses dealokasi ini terjadi baik untuk box-nya
(yang disimpan di stack) maupun untuk data yang ditunjuknya (yang
disimpan di heap).
Menaruh satu nilai tunggal di heap itu tidak terlalu berguna, jadi kita
tidak akan terlalu sering memakai boxes sendirian kayak gini. Membiarkan
nilai-like satu i32 tunggal ada di stack, di mana memang di situlah
mereka disimpan secara default, itu lebih tepat buat mayoritas situasi. Mari
kita lihat sebuah kasus di mana boxes memungkinkan kita buat mendefinisikan
tipe yang tidak bakal diizinkan untuk didefinisikan kalau kita tidak punya boxes.
Memungkinkan Tipe Rekursif dengan Boxes
Nilai dari sebuah tipe rekursif (recursive type) bisa punya nilai lain dari tipe yang sama sebagai bagian dari dirinya sendiri. Tipe rekursif ini menimbulkan masalah karena Rust perlu tahu saat compile time seberapa banyak ruang (space) yang dipakai sama sebuah tipe. Namun, nilai yang bersarang (nesting) di tipe rekursif ini secara teoritis bisa terus berlanjut tanpa batas, jadi Rust tidak bisa tahu berapa banyak ruang yang dibutuhkan sama nilai tersebut. Karena boxes punya ukuran yang sudah pasti diketahui, kita bisa memungkinkan tipe rekursif ini dengan menyelipkan (inserting) sebuah box ke dalam definisi tipe rekursifnya.
Sebagai contoh tipe rekursif, mari kita eksplorasi cons list. Ini adalah tipe data yang sering sekali dijumpai di bahasa pemrograman fungsional. Tipe cons list yang bakal kita definisikan itu mudah dipahami kecuali pada bagian rekursinya; maka dari itu, konsep-konsep di dalam contoh yang bakal kita kerjakan ini bakal berguna kapan pun kita masuk ke situasi yang lebih kompleks yang melibatkan tipe rekursif.
Info Lebih Lanjut soal Cons List
Sebuah cons list adalah struktur data yang berasal dari bahasa pemrograman
Lisp dan dialek-dialeknya, yang disusun dari pasangan (pairs) yang bersarang,
dan ini adalah versi Lisp dari linked list. Namanya datang dari fungsi
cons (kependekan dari fungsi construct) di Lisp yang mengonstruksi sebuah
pasangan baru dari dua argumennya. Dengan memanggil cons pada sebuah pasangan
yang terdiri dari sebuah nilai dan pasangan lain, kita bisa mengonstruksi
cons lists yang terbuat dari pasangan yang rekursif.
Misalnya, ini adalah representasi pseudocode (kode semu) dari sebuah cons list
yang berisi list 1, 2, 3 dengan setiap pasangan ditaruh di dalam tanda kurung:
(1, (2, (3, Nil)))
Tiap item di dalam cons list terdiri dari dua elemen: nilai dari item saat ini
dan item selanjutnya. Item terakhir di dalam list hanya terdiri dari sebuah
nilai bernama Nil tanpa ada item berikutnya. Sebuah cons list diproduksi dengan
memanggil fungsi cons secara rekursif. Nama standar (canonical name) untuk
menyebut kasus dasar (base case) dari rekursi ini adalah Nil. Perhatikan
bahwa ini tidak sama dengan konsep “null” atau “nil” yang dibahas di Bab 6, yang
mana itu artinya nilai yang tidak valid atau absen.
Cons list bukanlah struktur data yang sering dipakai di Rust. Kebanyakan
waktunya saat kita punya sebuah list yang berisi item-item di Rust, Vec<T>
adalah pilihan yang lebih baik buat dipakai. Namun, tipe data rekursif lainnya
yang lebih kompleks memang berguna di berbagai situasi, tapi dengan memulai
pakai cons list di bab ini, kita bisa mengeksplorasi gimana boxes memungkinkan
kita buat mendefinisikan tipe data rekursif tanpa banyak gangguan.
Listing 15-2 mengandung sebuah definisi enum untuk sebuah cons list.
Perhatikan kalau kode ini belum bisa di-compile karena tipe List tidak punya
ukuran yang pasti, yang mana bakal kita demonstrasikan.
enum List {
Cons(i32, List),
Nil,
}
fn main() {}i32Catatan: Kita mengimplementasikan sebuah cons list yang menampung cuma nilai
i32aja demi tujuan contoh ini. Kita bisa saja mengimplementasikannya memakai generik (generics), seperti yang sudah kita bahas di Bab 10, buat mendefinisikan tipe cons list yang bisa menyimpan nilai dari tipe apa pun.
Memakai tipe List buat menyimpan list 1, 2, 3 bakal kelihatan seperti kode
di Listing 15-3.
enum List {
Cons(i32, List),
Nil,
}
// --snip--
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Cons(2, Cons(3, Nil)));
}List buat menyimpan list 1, 2, 3Nilai Cons pertama menampung 1 dan nilai List lain. Nilai List ini
adalah nilai Cons lain yang menampung 2 dan sebuah nilai List lainnya.
Nilai List ini adalah satu lagi nilai Cons yang menampung 3 dan sebuah
nilai List, yang mana pada akhirnya adalah Nil, yaitu varian non-rekursif yang
menandakan akhir dari list tersebut.
Kalau kita nyoba men-compile kode di Listing 15-3, kita dapat error yang ditunjukkan di Listing 15-4.
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0072]: recursive type `List` has infinite size
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
2 | Cons(i32, List),
| ---- recursive without indirection
|
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
error[E0391]: cycle detected when computing when `List` needs drop
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
|
= note: ...which immediately requires computing when `List` needs drop again
= note: cycle used when computing whether `List` needs drop
= note: see https://rustc-dev-guide.rust-lang.org/overview.html#queries and https://rustc-dev-guide.rust-lang.org/query.html for more information
Some errors have detailed explanations: E0072, E0391.
For more information about an error, try `rustc --explain E0072`.
error: could not compile `cons-list` (bin "cons-list") due to 2 previous errors
Error-nya bilang kalau tipe ini “punya ukuran tak terbatas” (has infinite size).
Alasannya adalah karena kita mendefinisikan List dengan sebuah varian yang
rekursif: ia memegang nilai lain dari dirinya sendiri secara langsung. Sebagai
hasilnya, Rust tidak bisa menghitung seberapa banyak ruang yang ia butuhkan buat
menyimpan sebuah nilai List. Mari kita pecahkan masalah kenapa kita dapat
error ini. Pertama kita bakal melihat gimana cara Rust memutuskan berapa banyak
ruang yang ia butuhkan buat menyimpan nilai dari tipe non-rekursif.
Menghitung Ukuran dari Tipe Non-Rekursif
Ingat kembali enum Message yang kita definisikan di Listing 6-2 saat kita
membahas definisi enum di Bab 6:
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {}Buat menentukan seberapa banyak ruang yang harus dialokasikan untuk nilai
Message, Rust menelusuri setiap varian yang ada buat melihat varian mana yang
butuh ruang paling banyak. Rust melihat kalau Message::Quit tidak butuh ruang
sama sekali, Message::Move butuh ruang yang cukup buat menyimpan dua nilai i32,
dan seterusnya. Karena cuma satu varian saja yang bakal dipakai dalam satu waktu,
ruang maksimal yang bakal dibutuhkan oleh sebuah nilai Message adalah ruang yang
dibutuhkan buat menyimpan varian terbesarnya.
Bandingkan ini sama apa yang terjadi saat Rust mencoba menentukan seberapa banyak
ruang yang dibutuhkan oleh sebuah tipe rekursif kayak enum List di Listing 15-2.
Compiler mulai dengan melihat varian Cons, yang mana memegang sebuah nilai
tipe i32 dan sebuah nilai tipe List. Maka dari itu, Cons butuh jumlah ruang
yang setara dengan ukuran dari i32 ditambah sama ukuran dari List. Buat
menghitung seberapa besar memori yang dibutuhkan oleh tipe List, compiler
melihat variannya, yang dimulai dengan varian Cons. Varian Cons memegang nilai
bertipe i32 dan sebuah nilai bertipe List, dan proses ini terus berlanjut tanpa
batas, seperti yang ditunjukkan di Gambar 15-1.

Gambar 15-1: Sebuah List yang tidak terhingga yang terdiri
dari varian Cons yang tidak terhingga juga
Memakai Box<T> buat Mendapatkan Tipe Rekursif dengan Ukuran Pasti
Karena Rust tidak bisa mencari tahu seberapa banyak ruang yang harus dialokasikan buat tipe-tipe yang definisinya rekursif, compiler mengeluarkan error dengan saran yang ngebantu ini:
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
Di saran ini, indirection berarti bahwa ketimbang menyimpan nilainya secara langsung, kita sebaiknya mengubah struktur datanya buat menyimpan nilai itu secara tidak langsung dengan menyimpan pointer yang merujuk ke nilai tersebut.
Karena sebuah Box<T> itu adalah sebuah pointer, Rust bakal selalu tahu
seberapa banyak ruang yang dibutuhkan oleh sebuah Box<T>: ukuran dari sebuah
pointer tidak bakal berubah tidak peduli seberapa banyak data yang dia tunjuk.
Ini artinya kita bisa menaruh sebuah Box<T> di dalam varian Cons ketimbang
menaruh nilai List lain secara langsung. Box<T> tersebut bakal menunjuk ke
nilai List berikutnya yang mana bakal berada di heap dan bukannya berada di
dalam varian Cons. Secara konsep, kita masih punya sebuah list, yang dibikin
dari list yang memegang list lainnya, tapi implementasi yang ini sekarang lebih
mirip dengan menaruh item-item tersebut bersebelahan satu sama lain ketimbang
di dalam satu sama lain.
Kita bisa mengubah definisi dari enum List di Listing 15-2 dan pemakaian dari
List di Listing 15-3 menjadi kode di Listing 15-5, yang mana sekarang bakal
bisa di-compile.
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil))))));
}List yang memakai Box<T> biar bisa punya ukuran yang pasti diketahuiVarian Cons butuh ukuran sebesar sebuah i32 ditambah sama ruang buat
menyimpan data pointer dari box tersebut. Varian Nil tidak menyimpan nilai
apa pun, jadi ia butuh lebih sedikit ruang di stack dibandingkan varian Cons.
Kita sekarang tahu kalau nilai List apa pun cuma bakal memakan ruang sebesar i32
ditambah dengan ukuran dari data pointer di box-nya. Dengan memakai sebuah box,
kita sudah memutuskan (broken) rantai yang tidak terhingga dan rekursif tadi,
jadi compiler sekarang bisa menghitung ukuran yang dia butuhkan buat menyimpan
nilai List. Gambar 15-2 menunjukkan seperti apa rupa dari varian Cons itu
sekarang.

Gambar 15-2: Sebuah List yang ukurannya tidak lagi tidak
terhingga karena Cons sekarang memegang sebuah Box
Boxes hanya menyediakan proses penyimpanan tidak langsung (indirection) beserta alokasi di heap; mereka tidak punya kapabilitas spesial lainnya, seperti yang bakal kita lihat di tipe-tipe smart pointer lainnya. Mereka juga tidak punya overhead performa dari kapabilitas spesial tersebut, jadi mereka bakal berguna di kasus-cases seperti cons list di mana indirection itu adalah satu-satunya fitur yang kita butuhin. Kita bakal melihat lebih banyak contoh pemakaian buat boxes di Bab 18.
Tipe Box<T> adalah sebuah smart pointer karena ia mengimplementasikan trait
Deref, yang memungkinkan nilai Box<T> buat diperlakukan seperti layaknya
sebuah referensi biasa. Pas sebuah nilai Box<T> keluar dari scope, data
di heap yang ditunjuk sama box tersebut juga bakal dibersihkan karena adanya
implementasi trait Drop. Dua trait ini bakal jadi lebih penting lagi dalam
memahami fungsionalitas yang disediakan oleh tipe-tipe smart pointer lain
yang bakal kita bahas di sisa bab ini. Mari kita eksplorasi dua trait ini secara
lebih detail.
Memperlakukan Smart Pointers kayak Referensi Biasa
Memperlakukan Smart Pointers seperti Referensi Biasa dengan Deref
Mengimplementasikan trait Deref memungkinkan kita buat mengkustomisasi
perilaku dari dereference operator (operator dereferensi) * (jangan
tertukar sama operator perkalian atau operator glob). Dengan
mengimplementasikan Deref sedemikian rupa sehingga sebuah smart pointer
bisa diperlakukan seperti referensi biasa, kita bisa menulis kode yang
beroperasi pada referensi dan memakai kode tersebut buat smart pointers
juga.
Mari kita lihat dulu gimana cara kerja operator dereferensi pada referensi
biasa. Kemudian kita bakal mencoba mendefinisikan sebuah tipe kustom yang
berperilaku mirip Box<T>, dan melihat kenapa operator dereferensi tidak
bekerja seperti referensi pada tipe yang baru kita definisikan itu. Kita
bakal mengeksplorasi gimana mengimplementasikan trait Deref membikin
smart pointers mungkin buat bekerja dengan cara yang mirip seperti
referensi. Kemudian kita bakal melihat fitur deref coercion di Rust dan
gimana ia membiarkan kita bekerja entah itu pakai referensi maupun pakai
smart pointers.
Mengikuti Referensi ke Nilainya
Sebuah referensi biasa adalah salah satu jenis pointer, dan salah satu
cara buat membayangkan sebuah pointer adalah sebagai tanda panah yang
menunjuk ke sebuah nilai yang disimpan di tempat lain. Di Listing 15-6,
kita membuat sebuah referensi ke nilai i32 lalu memakai operator
dereferensi buat mengikuti referensi tersebut ke nilainya.
fn main() {
let x = 5;
let y = &x;
assert_eq!(5, x);
assert_eq!(5, *y);
}i32Variabel x memegang sebuah nilai i32 yaitu 5. Kita menge-set y agar
sama dengan sebuah referensi ke x. Kita bisa menegaskan (assert) kalau
x itu sama dengan 5. Namun, kalau kita mau bikin penegasan soal nilai
di dalam y, kita harus memakai *y buat mengikuti referensi tersebut ke
nilai yang lagi dia tunjuk (karenanya disebut dereference) supaya
compiler bisa membandingkan nilai aslinya. Begitu kita men-dereferensi y,
kita punya akses ke nilai integer yang ditunjuk sama y yang bisa kita
bandingkan dengan 5.
Kalau kita malah mencoba nulis assert_eq!(5, y);, kita bakal dapat error
kompilasi ini:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:6:5
|
6 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}`
|
= help: the trait `PartialEq<&{integer}>` is not implemented for `{integer}`
= note: this error originates in the macro `assert_eq` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0277`.
error: could not compile `deref-example` (bin "deref-example") due to 1 previous error
Membandingkan sebuah angka dan sebuah referensi ke angka itu tidak diperbolehkan karena mereka adalah tipe yang berbeda. Kita harus memakai operator dereferensi buat mengikuti referensi tersebut ke nilai yang ditunjuknya.
Memakai Box<T> Layaknya Sebuah Referensi
Kita bisa menulis ulang kode di Listing 15-6 buat memakai sebuah Box<T>
bukannya referensi; operator dereferensi yang dipakai pada Box<T> di
Listing 15-7 berfungsi dengan cara yang sama kayak operator dereferensi
yang dipakai pada referensi di Listing 15-6.
fn main() {
let x = 5;
let y = Box::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}Box<i32>Perbedaan utama antara Listing 15-7 dan Listing 15-6 adalah di sini kita
menge-set y agar menjadi sebuah instance dari sebuah box yang menunjuk
ke salinan nilai dari x ketimbang sebuah referensi yang menunjuk ke
nilai dari x. Di penegasan terakhir, kita bisa memakai operator
dereferensi buat mengikuti pointer box tersebut dengan cara yang sama
seperti saat y tadinya adalah sebuah referensi. Selanjutnya, kita bakal
mengeksplorasi apa yang spesial dari Box<T> yang memungkinkan kita buat
memakai operator dereferensi dengan mendefinisikan tipe box kita sendiri.
Mendefinisikan Smart Pointer Kita Sendiri
Mari kita bikin sebuah tipe pembungkus (wrapper type) yang mirip sama tipe
Box<T> yang disediakan sama standard library buat merasakan gimana
tipe smart pointer berperilaku secara berbeda dari referensi secara
default. Kemudian kita bakal melihat gimana cara menambahkan kemampuan
buat memakai operator dereferensi.
Catatan: Ada satu perbedaan besar antara tipe
MyBox<T>yang mau kita bikin ini denganBox<T>yang asli: versi kita ini tidak bakal menyimpan datanya di heap. Kita memfokuskan contoh ini padaDeref, jadi di mana datanya sebenarnya disimpan itu kurang penting dibanding perilaku yang mirip pointer-nya.
Tipe Box<T> pada akhirnya didefinisikan sebagai sebuah tuple struct dengan
satu elemen, jadi Listing 15-8 mendefinisikan sebuah tipe MyBox<T> dengan
cara yang sama. Kita juga bakal mendefinisikan sebuah fungsi new agar
cocok sama fungsi new yang didefinisikan pada Box<T>.
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {}MyBox<T>Kita mendefinisikan sebuah struct bernama MyBox dan mendeklarasikan sebuah
parameter generik T karena kita mau tipe kita bisa memegang nilai dari
tipe apa pun. Tipe MyBox adalah sebuah tuple struct dengan satu elemen
bertipe T. Fungsi MyBox::new menerima satu parameter bertipe T dan
mengembalikan sebuah instance MyBox yang memegang nilai yang dimasukkan.
Mari coba tambahkan fungsi main di Listing 15-7 ke Listing 15-8 lalu
ubah kodenya biar memakai tipe MyBox<T> yang sudah kita definisikan
bukannya Box<T>. Kode di Listing 15-9 tidak bakal bisa di-compile karena
Rust tidak tahu gimana cara men-dereferensi MyBox.
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}MyBox<T> dengan cara yang sama seperti kita memakai referensi dan Box<T>Berikut adalah error kompilasi yang dihasilkan:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0614]: type `MyBox<{integer}>` cannot be dereferenced
--> src/main.rs:14:19
|
14 | assert_eq!(5, *y);
| ^^ can't be dereferenced
For more information about this error, try `rustc --explain E0614`.
error: could not compile `deref-example` (bin "deref-example") due to 1 previous error
Tipe MyBox<T> kita tidak bisa di-dereferensi karena kita belum
mengimplementasikan kemampuan tersebut pada tipe kita. Untuk memungkinkan
proses dereferensi dengan operator *, kita harus mengimplementasikan
trait Deref.
Mengimplementasikan Trait Deref
Seperti yang sudah dibahas di “Mengimplementasikan sebuah Trait pada suatu
Tipe” di Bab 10, untuk mengimplementasikan sebuah trait kita
perlu menyediakan implementasi buat method-method yang diwajibkan oleh
trait tersebut. Trait Deref, yang disediakan oleh standard library,
mewajibkan kita buat mengimplementasikan satu method bernama deref yang
meminjam self lalu mengembalikan sebuah referensi ke data internalnya.
Listing 15-10 mengandung implementasi Deref buat ditambahkan ke definisi
MyBox<T>.
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &Self::Target {
&self.0
}
}
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}Deref pada MyBox<T>Sintaks type Target = T; mendefinisikan sebuah associated type buat
dipakai oleh trait Deref. Associated types adalah cara yang sedikit
berbeda dalam mendeklarasikan sebuah parameter generik, tapi kita tidak usah
pusing dulu soal itu buat sekarang; kita bakal membahasnya lebih detail
di Bab 20.
Kita mengisi body dari method deref dengan &self.0 supaya deref
mengembalikan referensi ke nilai yang mau kita akses dengan operator *;
ingat kembali dari “Memakai Tuple Structs tanpa Field Bernama buat Bikin
Tipe yang Beda” di Bab 5 kalau .0 mengakses nilai pertama
di dalam sebuah tuple struct. Fungsi main di Listing 15-9 yang
memanggil * pada nilai MyBox<T> sekarang sudah bisa di-compile, dan
penegasannya sukses!
Tanpa trait Deref, compiler cuma bisa men-dereferensi referensi &.
Method deref memberi compiler kemampuan buat mengambil sebuah nilai dari
tipe apa pun yang mengimplementasikan Deref lalu memanggil method deref
buat mendapatkan sebuah referensi & yang dia tahu gimana cara
men-dereferensinya.
Saat kita memasukkan *y di Listing 15-9, di balik layar Rust sebenarnya
menjalankan kode ini:
*(y.deref())Rust mengganti operator * dengan pemanggilan ke method deref dan lalu
sebuah dereferensi biasa sehingga kita tidak perlu repot mikirin apakah
kita butuh memanggil method deref atau tidak. Fitur Rust ini membiarkan
kita menulis kode yang fungsinya identik baik saat kita punya referensi
biasa maupun tipe yang mengimplementasikan Deref.
Alasan kenapa method deref mengembalikan sebuah referensi ke sebuah nilai,
dan kenapa dereferensi biasa di luar tanda kurung di *(y.deref()) itu
tetap diperlukan, ada hubungannya sama sistem ownership. Kalau method
deref mengembalikan nilainya secara langsung bukannya referensi ke
nilainya, nilainya bakal di-move keluar dari self. Kita tidak mau
mengambil kepemilikan (ownership) dari nilai internal di dalam MyBox<T>
di kasus ini maupun di kebanyakan kasus di mana kita memakai operator
dereferensi.
Perhatikan bahwa operator * digantikan dengan pemanggilan ke method
deref dan kemudian pemanggilan ke operator * cuma satu kali saja, setiap
kali kita memakai tanda * di kode kita. Karena penggantian operator *
tersebut tidak berulang secara rekursif tanpa henti, kita akhirnya mendapatkan
data bertipe i32, yang cocok dengan angka 5 di assert_eq! di
Listing 15-9.
Deref Coercion Implisit dengan Fungsi dan Method
Deref coercion mengubah sebuah referensi ke sebuah tipe yang
mengimplementasikan trait Deref menjadi sebuah referensi ke tipe lainnya.
Misalnya, deref coercion bisa mengubah &String menjadi &str karena
String mengimplementasikan trait Deref sedemikian rupa sehingga ia
mengembalikan &str. Deref coercion adalah sebuah kemudahan yang
dilakukan Rust pada argumen buat fungsi dan method, dan cuma bekerja pada
tipe yang mengimplementasikan trait Deref. Hal ini terjadi secara
otomatis saat kita meneruskan sebuah referensi ke nilai dari tipe tertentu
sebagai argumen ke sebuah fungsi atau method yang tipenya tidak cocok dengan
tipe parameter di definisi fungsi atau method tersebut. Serangkaian
pemanggilan ke method deref mengubah tipe yang kita berikan menjadi tipe
yang dibutuhkan sama parameternya.
Deref coercion ditambahkan ke Rust supaya para programmer yang menulis
pemanggilan fungsi dan method tidak perlu menambahkan terlalu banyak
referensi dan dereferensi eksplisit dengan & dan *. Fitur deref coercion
juga membiarkan kita menulis lebih banyak kode yang bisa bekerja baik
buat referensi maupun buat smart pointers.
Buat melihat deref coercion beraksi, mari kita gunakan tipe MyBox<T> yang
kita definisikan di Listing 15-8 beserta implementasi Deref yang kita
tambahkan di Listing 15-10. Listing 15-11 menunjukkan definisi dari sebuah
fungsi yang punya parameter berupa string slice.
fn hello(name: &str) {
println!("Hello, {name}!");
}
fn main() {}hello yang punya parameter name bertipe &strKita bisa memanggil fungsi hello dengan sebuah string slice sebagai
argumennya, misalnya hello("Rust");. Deref coercion memungkinkan kita
buat memanggil hello dengan sebuah referensi ke sebuah nilai bertipe
MyBox<String>, seperti yang ditunjukkan di Listing 15-12.
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn hello(name: &str) {
println!("Hello, {name}!");
}
fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&m);
}hello dengan referensi ke nilai MyBox<String>, yang mana berhasil berkat deref coercionDi sini kita memanggil fungsi hello dengan argumen &m, yang mana adalah
sebuah referensi ke sebuah nilai MyBox<String>. Karena kita
mengimplementasikan trait Deref pada MyBox<T> di Listing 15-10, Rust
bisa mengubah &MyBox<String> menjadi &String dengan memanggil deref.
Standard library menyediakan sebuah implementasi Deref pada String
yang mengembalikan sebuah string slice, dan ini ada di dokumentasi API
buat Deref. Rust memanggil deref sekali lagi buat mengubah &String
menjadi &str, yang mana cocok sama definisi fungsi hello.
Kalau Rust tidak mengimplementasikan deref coercion, kita harus menulis
kode di Listing 15-13 bukannya kode di Listing 15-12 buat memanggil hello
dengan sebuah nilai bertipe &MyBox<String>.
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn hello(name: &str) {
println!("Hello, {name}!");
}
fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&(*m)[..]);
}Tanda (*m) men-dereferensi MyBox<String> menjadi sebuah String.
Kemudian tanda & dan [..] mengambil sebuah string slice dari String
tersebut yang setara dengan keseluruhan string-nya agar cocok sama signature
dari hello. Kode tanpa deref coercions ini lebih susah buat dibaca, ditulis,
dan dipahami dengan semua simbol yang terlibat ini. Deref coercion membiarkan
Rust menangani konversi-konversi ini buat kita secara otomatis.
Saat trait Deref didefinisikan buat tipe-tipe yang terlibat, Rust bakal
menganalisis tipe-tipenya dan memakai Deref::deref sebanyak yang
dibutuhkan buat mendapatkan sebuah referensi yang cocok sama tipe
parameternya. Berapa kali Deref::deref perlu disisipkan itu sudah
diselesaikan (resolved) pas compile time, jadi tidak ada hukuman performa
saat runtime karena memanfaatkan deref coercion!
Gimana Deref Coercion Berinteraksi sama Mutabilitas
Sama seperti gimana kita memakai trait Deref buat menimpa operator * pada
referensi immutable, kita juga bisa memakai trait DerefMut buat menimpa
operator * pada referensi mutable.
Rust melakukan deref coercion saat ia menemukan tipe-tipe dan implementasi trait di tiga kasus ini:
- Dari
&Tke&UsaatT: Deref<Target=U> - Dari
&mut Tke&mut UsaatT: DerefMut<Target=U> - Dari
&mut Tke&UsaatT: Deref<Target=U>
Dua kasus pertama itu sama saja kecuali kalau yang kedua mengimplementasikan
mutabilitas. Kasus pertama menyatakan kalau kita punya sebuah &T, dan T
mengimplementasikan Deref ke suatu tipe U, kita bisa mendapatkan sebuah
&U secara transparan. Kasus kedua menyatakan kalau deref coercion yang
sama terjadi buat referensi mutable.
Kasus ketiga itu sedikit lebih tricky: Rust juga bakal me-coerce sebuah referensi mutable menjadi referensi immutable. Tapi kebalikannya itu tidak mungkin: referensi immutable tidak bakal pernah bisa di-coerce menjadi referensi mutable. Karena aturan borrowing, kalau kita punya sebuah referensi mutable, referensi mutable tersebut haruslah menjadi satu-satunya referensi ke data tersebut (kalau tidak, programnya tidak bakal bisa di-compile). Mengonversi satu referensi mutable menjadi satu referensi immutable tidak bakal pernah melanggar aturan borrowing. Mengonversi sebuah referensi immutable menjadi referensi mutable bakal mewajibkan kalau referensi immutable awalnya adalah satu-satunya referensi immutable ke data tersebut, tapi aturan borrowing tidak menjamin hal itu. Oleh karena itu, Rust tidak bisa membuat asumsi kalau mengonversi sebuah referensi immutable menjadi referensi mutable itu mungkin dilakukan.
Menjalankan Kode saat Bersih-bersih Memakai Trait Drop
Menjalankan Kode saat Proses Pembersihan (Cleanup) dengan Trait Drop
Trait kedua yang penting buat pola smart pointer adalah Drop, yang
membiarkan kita mengkustomisasi apa yang terjadi saat sebuah nilai bakal
keluar dari scope. Kita bisa menyediakan sebuah implementasi buat trait
Drop di tipe apa pun, dan kode tersebut bisa dipakai buat melepaskan
(release) resources kayak file atau koneksi jaringan.
Kita ngenalin Drop di konteks smart pointers karena fungsionalitas dari
trait Drop hampir selalu dipakai pas kita mengimplementasikan sebuah smart
pointer. Misalnya, saat sebuah Box<T> di-drop, dia bakal men-deallocate
(melepaskan) ruang di heap yang ditunjuk sama box tersebut.
Di beberapa bahasa, buat tipe-tipe tertentu, si programmer harus memanggil kode buat membebaskan memori atau resources setiap kali mereka kelar memakai sebuah instance dari tipe-tipe tersebut. Contohnya termasuk file handles (pegangan file), sockets, sama locks. Kalau mereka lupa, sistem bisa jadi overloaded dan crash. Di Rust, kita bisa menentukan bahwa sekumpulan kode tertentu bakal dijalankan setiap kali sebuah nilai keluar dari scope, dan compiler bakal menyisipkan (insert) kode ini secara otomatis. Hasilnya, kita tidak perlu repot-repot menaruh kode cleanup (pembersihan) di mana-mana di dalam program setiap kali sebuah instance dari suatu tipe sudah selesai dipakai—dan kita tetap tidak bakal membocorkan (leak) resources!
Kita menentukan kode yang bakal jalan saat sebuah nilai keluar dari scope
dengan mengimplementasikan trait Drop. Trait Drop mewajibkan kita buat
mengimplementasikan satu method bernama drop yang menerima referensi
mutable ke self. Buat melihat kapan Rust memanggil drop, mari kita
mengimplementasikan drop dengan statements println! dulu buat sekarang.
Listing 15-14 menunjukkan sebuah struct CustomSmartPointer yang satu-satunya
fungsionalitas kustom yang dia punya adalah dia bakal mencetak Dropping CustomSmartPointer! saat instance-nya keluar dari scope, buat menunjukkan
kapan Rust menjalankan method drop.
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("my stuff"),
};
let d = CustomSmartPointer {
data: String::from("other stuff"),
};
println!("CustomSmartPointers created");
}CustomSmartPointer yang mengimplementasikan trait Drop di mana kita bakal menaruh kode cleanup kitaTrait Drop sudah dimasukkan ke dalam prelude, jadi kita tidak perlu membawa
trait itu ke dalam scope. Kita mengimplementasikan trait Drop pada
CustomSmartPointer dan menyediakan sebuah implementasi buat method drop yang
memanggil println!. Body dari method drop adalah tempat di mana kita
bakal menaruh logika apa pun yang mau kita jalankan pas sebuah instance dari
tipe kita keluar dari scope. Kita mencetak sedikit teks di sini buat
mendemonstrasikan secara visual kapan Rust bakal memanggil drop.
Di main, kita bikin dua instance dari CustomSmartPointer lalu mencetak
CustomSmartPointers created. Di akhir main, instance-instance dari
CustomSmartPointer kita bakal keluar dari scope, dan Rust bakal memanggil
kode yang kita taruh di method drop, yang mana mencetak pesan terakhir kita.
Perhatikan bahwa kita tidak perlu memanggil method drop secara eksplisit.
Pas kita menjalankan program ini, kita bakal melihat output berikut:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.60s
Running `target/debug/drop-example`
CustomSmartPointers created
Dropping CustomSmartPointer with data `other stuff`!
Dropping CustomSmartPointer with data `my stuff`!
Rust secara otomatis memanggil drop buat kita pas instance-instance kita keluar
dari scope, dan menjalankan kode yang sudah kita tentukan. Variabel-variabel
di-drop dalam urutan yang berlawanan dari pembuatannya, jadi d di-drop
sebelum c. Contoh ini tujuannya adalah buat ngasih kita panduan visual soal
gimana method drop itu bekerja; biasanya kita bakal menentukan kode cleanup
yang dibutuhkan sama tipe kita, ketimbang cuma pesan print biasa.
Sayangnya, menonaktifkan fungsionalitas drop otomatis ini tidak
gampang. Menonaktifkan drop biasanya juga tidak diperlukan; keseluruhan
poin dari trait Drop adalah supaya hal itu diurus secara otomatis. Tapi,
terkadang, kita mungkin pengen membersihkan (clean up) sebuah nilai lebih
awal. Salah satu contohnya adalah pas lagi memakai smart pointers yang
mengelola locks: kita mungkin pengen memaksa method drop yang bakal
melepaskan lock itu agar kode lain di scope yang sama bisa mendapatkan
lock tersebut. Rust tidak membiarkan kita buat memanggil method drop
dari trait Drop secara manual; sebaliknya, kita harus memanggil fungsi
std::mem::drop yang disediakan sama standard library kalau kita mau
memaksa sebuah nilai buat di-drop sebelum akhir dari scope-nya.
Kalau kita mencoba memanggil method drop dari trait Drop secara manual
dengan memodifikasi fungsi main dari Listing 15-14, seperti yang ditunjukkan
di Listing 15-15, kita bakal dapat error compiler.
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created");
c.drop();
println!("CustomSmartPointer dropped before the end of main");
}drop dari trait Drop secara manual untuk cleanup lebih awalPas kita nyoba men-compile kode ini, kita bakal dapat error ini:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
error[E0040]: explicit use of destructor method
--> src/main.rs:16:7
|
16 | c.drop();
| ^^^^ explicit destructor calls not allowed
|
help: consider using `drop` function
|
16 - c.drop();
16 + drop(c);
|
For more information about this error, try `rustc --explain E0040`.
error: could not compile `drop-example` (bin "drop-example") due to 1 previous error
Pesan error ini menyatakan kalau kita tidak diizinkan buat memanggil drop
secara eksplisit. Pesan error ini memakai istilah destructor (destruktor),
yang mana adalah istilah pemrograman umum buat sebuah fungsi yang membersihkan
sebuah instance. Sebuah destructor analog (mirip) dengan sebuah constructor
(konstruktor), yang membikin sebuah instance. Fungsi drop di Rust adalah
salah satu destruktor tertentu.
Rust tidak membiarkan kita memanggil drop secara eksplisit karena Rust tetap
bakal secara otomatis memanggil drop pada nilainya di akhir dari main. Hal
ini bakal menyebabkan error double free karena Rust bakal mencoba membersihkan
nilai yang sama dua kali.
Kita tidak bisa menonaktifkan penyisipan drop secara otomatis pas sebuah nilai
keluar dari scope, dan kita tidak bisa memanggil method drop secara eksplisit.
Jadi, kalau kita butuh memaksa sebuah nilai buat dibersihkan lebih awal, kita
memakai fungsi std::mem::drop.
Fungsi std::mem::drop berbeda dari method drop yang ada di trait Drop.
Kita memanggilnya dengan meneruskan nilai yang mau kita paksa untuk di-drop
sebagai argumennya. Fungsi ini ada di dalam prelude, jadi kita bisa memodifikasi
main di Listing 15-15 buat memanggil fungsi drop tersebut, seperti yang
ditunjukkan di Listing 15-16.
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created");
drop(c);
println!("CustomSmartPointer dropped before the end of main");
}std::mem::drop buat me-drop secara eksplisit sebuah nilai sebelum dia keluar dari scopeMenjalankan kode ini bakal mencetak yang berikut ini:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/drop-example`
CustomSmartPointer created
Dropping CustomSmartPointer with data `some data`!
CustomSmartPointer dropped before the end of main
Teks Dropping CustomSmartPointer with data `some data`! dicetak di antara
teks CustomSmartPointer created. dan CustomSmartPointer dropped before the end of main., menunjukkan kalau kode method drop dipanggil
buat me-drop c pada titik tersebut.
Kita bisa memakai kode yang ditentukan di dalam implementasi trait Drop
pakai berbagai cara buat membikin cleanup jadi nyaman dan aman: misalnya,
kita bisa memakainya buat membikin memory allocator kita sendiri! Dengan trait
Drop dan sistem ownership di Rust, kita tidak perlu repot nginget-nginget
buat cleanup karena Rust ngelakuin itu secara otomatis.
Kita juga tidak perlu khawatir soal masalah-masalah yang timbul dari secara
tidak sengaja membersihkan nilai yang masih dipakai: sistem ownership yang
memastikan kalau referensi bakal selalu valid juga memastikan kalau drop
cuma bakal dipanggil satu kali pas nilainya memang sudah tidak dipakai lagi.
Sekarang setelah kita meneliti Box<T> dan beberapa karakteristik dari
smart pointers, mari kita lihat beberapa smart pointers lain yang didefinisikan
di standard library.
Rc<T>, si Smart Pointer yang Punya Reference Counting
Rc<T>, Smart Pointer Reference Counted
Di mayoritas kasus, kepemilikan (ownership) itu jelas: kita tahu persis variabel mana yang memiliki suatu nilai. Namun, ada kasus di mana sebuah nilai bisa punya banyak pemilik. Misalnya, di struktur data graf (graph), banyak edges (sisi) mungkin menunjuk ke node (simpul) yang sama, dan node tersebut secara konsep dimiliki oleh semua edges yang menunjuk kepadanya. Sebuah node tidak boleh dibersihkan kecuali jika dia sudah tidak punya edges yang menunjuk kepadanya, yang artinya dia tidak punya pemilik lagi.
Kita harus mengaktifkan kepemilikan ganda (multiple ownership) secara eksplisit
dengan memakai tipe Rust Rc<T>, yang merupakan singkatan dari
reference counting (penghitungan referensi). Tipe Rc<T> melacak
(keeps track of) jumlah referensi ke sebuah nilai buat menentukan apakah
nilai tersebut masih dipakai atau tidak. Kalau ada nol referensi ke sebuah nilai,
nilai tersebut bisa dibersihkan tanpa membuat referensi apa pun jadi tidak valid.
Bayangkan Rc<T> itu seperti TV di ruang keluarga. Saat ada satu orang yang
masuk buat nonton TV, dia menyalakannya. Orang-orang lain bisa ikut masuk
dan menonton TV. Saat orang terakhir keluar ruangan, dia bakal mematikan TV
tersebut karena sudah tidak dipakai lagi. Kalau ada orang yang mematikan TV
padahal orang lain masih pada nonton, pasti bakal ada keributan dari
penonton-penonton yang tersisa itu!
Kita memakai tipe Rc<T> saat kita mau mengalokasikan beberapa data di heap
biar bisa dibaca sama beberapa bagian dari program kita, dan saat kita
tidak bisa menentukan di compile time bagian mana yang bakal paling
terakhir selesai memakai datanya. Kalau kita tahu bagian mana yang bakal
selesai terakhir, kita bisa aja bikin bagian itu jadi pemilik (owner) dari
datanya, dan aturan ownership normal yang ditegakkan saat compile time
bakal berlaku.
Perhatikan bahwa Rc<T> cuma buat dipakai di skenario single-threaded (satu
thread). Saat kita ngebahas konkurensi di Bab 16, kita bakal menutupi gimana
cara melakukan reference counting di program multithreaded.
Memakai Rc<T> buat Berbagi Data
Mari kembali ke contoh cons list kita di Listing 15-5. Ingat kembali kalau kita
mendefinisikannya memakai Box<T>. Kali ini, kita bakal membikin dua list
yang dua-duanya berbagi kepemilikan atas sebuah list ketiga. Secara konsep,
ini kelihatannya mirip seperti Gambar 15-3.

Gambar 15-3: Dua list, b dan c, berbagi kepemilikan
atas sebuah list ketiga, a
Kita bakal membikin list a yang berisi 5 lalu 10. Terus kita bakal
membikin dua list lagi: b yang dimulai dengan 3 dan c yang dimulai
dengan 4. Baik list b maupun c nantinya bakal berlanjut ke list a
pertama yang berisi 5 dan 10. Dengan kata lain, kedua list ini bakal
berbagi list pertama yang berisi 5 dan 10.
Mencoba mengimplementasikan skenario ini memakai definisi dari List dengan
Box<T> tidak bakal berhasil, seperti yang ditunjukkan di Listing 15-17.
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
let b = Cons(3, Box::new(a));
let c = Cons(4, Box::new(a));
}Box<T> yang mencoba berbagi kepemilikan atas list ketigaPas kita men-compile kode ini, kita bakal dapat error ini:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0382]: use of moved value: `a`
--> src/main.rs:11:30
|
9 | let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
| - move occurs because `a` has type `List`, which does not implement the `Copy` trait
10 | let b = Cons(3, Box::new(a));
| - value moved here
11 | let c = Cons(4, Box::new(a));
| ^ value used here after move
|
note: if `List` implemented `Clone`, you could clone the value
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^ consider implementing `Clone` for this type
...
10 | let b = Cons(3, Box::new(a));
| - you could clone this value
For more information about this error, try `rustc --explain E0382`.
error: could not compile `cons-list` (bin "cons-list") due to 1 previous error
Varian-varian Cons memiliki data yang mereka pegang, jadi saat kita
membikin list b, a di-move ke dalam b dan b memiliki a.
Kemudian, saat kita nyoba memakai a lagi pas lagi membikin c, kita
tidak diizinkan buat melakukannya karena a sudah dipindahkan.
Kita bisa saja mengubah definisi dari Cons agar memegang referensi
sebagai gantinya, tapi kalau begitu kita harus menentukan parameter
lifetime. Dengan menentukan parameter lifetime, kita bakal menentukan
kalau setiap elemen di dalam list tersebut bakal hidup setidaknya selama
keseluruhan list itu hidup. Ini sesuai buat elemen-elemen dan list-list
yang ada di Listing 15-17, tapi tidak sesuai di semua skenario.
Sebagai gantinya, kita bakal mengubah definisi dari List kita agar
memakai Rc<T> di tempat Box<T>, seperti yang ditunjukkan di Listing 15-18.
Setiap varian Cons sekarang bakal memegang sebuah nilai dan sebuah Rc<T>
yang menunjuk ke sebuah List. Saat kita membikin b, ketimbang mengambil
kepemilikan dari a, kita bakal meng-clone (menyalin) Rc<List> yang
lagi dipegang sama a, sehingga menaikkan jumlah referensinya dari satu
jadi dua dan membiarkan a serta b berbagi kepemilikan dari data di dalam
Rc<List> tersebut. Kita juga bakal meng-clone a pas membikin c,
yang mana menaikkan jumlah referensinya dari dua jadi tiga. Setiap kali
kita memanggil Rc::clone, reference count (jumlah referensi) ke data
di dalam Rc<List> bakal naik, dan datanya tidak bakal dibersihkan
kecuali ada nol referensi yang tersisa padanya.
enum List {
Cons(i32, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
let b = Cons(3, Rc::clone(&a));
let c = Cons(4, Rc::clone(&a));
}List yang memakai Rc<T>Kita harus menambahkan statement use buat membawa Rc<T> ke dalam
scope karena dia tidak ada di dalam prelude. Di main, kita membikin
list yang memegang 5 dan 10 lalu menyimpannya di dalam Rc<List>
baru di a. Terus, pas kita membikin b dan c, kita memanggil fungsi
Rc::clone dan memberikan referensi ke Rc<List> di a sebagai argumennya.
Kita bisa saja memanggil a.clone() ketimbang Rc::clone(&a), tapi
konvensi Rust adalah memakai Rc::clone di kasus ini. Implementasi dari
Rc::clone tidak membuat deep copy (salinan dalam/penuh) dari semua
datanya seperti yang dilakukan sama kebanyakan implementasi clone di
tipe lain. Pemanggilan ke Rc::clone cuma menaikkan jumlah referensinya aja,
yang mana tidak memakan banyak waktu. Deep copies dari data bisa memakan
waktu yang lama sekali. Dengan memakai Rc::clone buat reference
counting, kita bisa secara visual membedakan antara jenis clone yang
berupa deep-copy dan jenis clone yang cuma menaikkan jumlah referensi.
Saat lagi mencari masalah performa di kode, kita cuma perlu
mempertimbangkan clones yang deep-copy aja dan bisa mengabaikan pemanggilan
ke Rc::clone.
Meng-clone Rc<T> Menaikkan Reference Count
Mari kita ubah contoh pekerjaan kita di Listing 15-18 supaya kita bisa
melihat gimana jumlah referensinya berubah saat kita membikin dan men-drop
referensi ke Rc<List> di a.
Di Listing 15-19, kita bakal mengubah main supaya ia punya scope di dalam
(inner scope) yang mengelilingi list c; dengan begitu kita bisa melihat
gimana jumlah referensinya berubah saat c keluar dari scope.
enum List {
Cons(i32, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
// --snip--
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
println!("count after creating a = {}", Rc::strong_count(&a));
let b = Cons(3, Rc::clone(&a));
println!("count after creating b = {}", Rc::strong_count(&a));
{
let c = Cons(4, Rc::clone(&a));
println!("count after creating c = {}", Rc::strong_count(&a));
}
println!("count after c goes out of scope = {}", Rc::strong_count(&a));
}Di tiap titik di program di mana jumlah referensinya berubah, kita mencetak
jumlah referensinya, yang mana kita dapat dengan memanggil fungsi
Rc::strong_count. Fungsi ini dinamakan strong_count ketimbang count
karena tipe Rc<T> juga punya sebuah weak_count; kita bakal melihat
buat apa weak_count dipakai di “Mencegah Reference Cycles Memakai
Weak<T>”.
Kode ini mencetak yang berikut ini:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.45s
Running `target/debug/cons-list`
count after creating a = 1
count after creating b = 2
count after creating c = 3
count after c goes out of scope = 2
Kita bisa melihat kalau Rc<List> di a punya jumlah referensi awal
sebesar 1; lalu setiap kali kita memanggil clone, jumlahnya naik 1. Saat
c keluar dari scope, jumlahnya turun 1. Kita tidak perlu memanggil
sebuah fungsi buat menurunkan jumlah referensinya seperti kita harus memanggil
Rc::clone buat menaikkannya: implementasi dari trait Drop bakal menurunkan
jumlah referensinya secara otomatis pas sebuah nilai Rc<T> keluar dari
scope.
Apa yang tidak bisa kita lihat dari contoh ini adalah saat b dan kemudian
a keluar dari scope di akhir main, jumlahnya menjadi 0, dan Rc<List>
tersebut bakal dibersihkan seutuhnya. Memakai Rc<T> memungkinkan sebuah
nilai tunggal buat punya banyak pemilik, dan penghitungan ini memastikan
kalau nilainya bakal tetap valid selama salah satu dari para pemiliknya
masih eksis.
Lewat referensi immutable, Rc<T> memungkinkan kita buat berbagi data di
antara berbagai bagian program buat dibaca aja (reading only). Kalau Rc<T>
juga mengizinkan kita buat punya banyak referensi mutable, kita mungkin
bakal melanggar salah satu dari aturan borrowing yang dibahas di Bab 4:
banyak referensi mutable ke tempat yang sama bisa menyebabkan data races
(balapan data) dan inkonsistensi. Tapi bisa memutasi data itu kan berguna
sekali! Di bagian selanjutnya, kita bakal membahas desain pola interior
mutability dan tipe RefCell<T> yang bisa kita pakai bersamaan dengan sebuah
Rc<T> buat menangani larangan immutability ini.
RefCell<T> dan Pola Interior Mutability
RefCell<T> dan Desain Pola Interior Mutability
Interior mutability (mutabilitas interior) adalah sebuah desain pola di Rust
yang membiarkan kita memutasi (mengubah) data bahkan saat ada referensi
immutable ke data tersebut; normalnya, tindakan ini tidak diizinkan oleh
aturan borrowing. Buat memutasi data, pola ini memakai kode unsafe di dalam
sebuah struktur data untuk membengkokkan aturan-aturan normal Rust yang mengatur
mutasi dan borrowing. Kode unsafe mengindikasikan ke compiler bahwa kita
memeriksa aturan-aturan tersebut secara manual ketimbang mengandalkan
compiler buat mengeceknya untuk kita; kita bakal membahas kode unsafe
lebih banyak di Bab 20.
Kita bisa memakai tipe yang menggunakan desain pola interior mutability cuma
pas kita bisa memastikan kalau aturan borrowing bakal dipatuhi saat runtime,
meskipun compiler tidak bisa menjamin hal itu. Kode unsafe yang terlibat
kemudian dibungkus di dalam sebuah API yang aman (safe API), dan tipe yang ada
di luar bakal tetap immutable.
Mari kita eksplorasi konsep ini dengan melihat tipe RefCell<T> yang mengikuti
desain pola interior mutability ini.
Menegakkan Aturan Borrowing saat Runtime dengan RefCell<T>
Tidak seperti Rc<T>, tipe RefCell<T> merepresentasikan kepemilikan tunggal
(single ownership) atas data yang dipegangnya. Jadi apa yang membikin RefCell<T>
berbeda dari tipe seperti Box<T>? Ingat kembali aturan borrowing yang
kita pelajari di Bab 4:
- Pada waktu kapan pun, kita cuma boleh punya satu referensi mutable atau sejumlah referensi immutable (tapi tidak boleh dua-duanya sekaligus).
- Referensi harus selalu valid.
Dengan referensi biasa dan Box<T>, invarian (aturan mutlak) dari aturan
borrowing ini ditegakkan (enforced) saat compile time. Dengan RefCell<T>,
invarian ini ditegakkan saat runtime. Dengan referensi, kalau kita
melanggar aturan-aturan ini, kita bakal dapat error compiler. Dengan
RefCell<T>, kalau kita melanggar aturan-aturan ini, program kita bakal
mengalami panic dan keluar (exit).
Keuntungan dari mengecek aturan borrowing saat compile time adalah error bakal ditangkap lebih awal di proses development (pengembangan), dan tidak ada dampak pada performa runtime karena semua analisisnya udah diselesaikan sebelumnya. Karena alasan-alasan tersebut, mengecek aturan borrowing saat compile time adalah pilihan terbaik buat mayoritas kasus, yang mana itulah alasannya kenapa ini jadi default (bawaan) di Rust.
Keuntungan dari mengecek aturan borrowing saat runtime sebagai gantinya adalah ada beberapa skenario aman-memori (memory-safe) yang kemudian jadi diizinkan, di mana mereka tadinya tidak bakal diizinkan sama pengecekan compile time. Analisis statis, seperti compiler Rust, secara bawaan sifatnya konservatif. Beberapa properti (sifat) kode mustahil buat dideteksi dengan hanya menganalisis kodenya saja: contoh paling terkenal adalah Halting Problem, yang ada di luar cakupan buku ini tapi merupakan topik yang menarik buat diteliti.
Karena beberapa analisis itu mustahil, kalau compiler Rust tidak bisa yakin
kodenya mematuhi aturan ownership, ia mungkin bakal menolak sebuah program
yang sebenarnya benar; di sinilah letak sifat konservatifnya. Kalau Rust
menerima program yang salah, para user tidak bakal bisa mempercayai jaminan
yang diberikan Rust. Namun, kalau Rust menolak program yang benar, si
programmer bakal direpotkan, tapi tidak ada bencana besar yang bakal
terjadi. Tipe RefCell<T> ini berguna saat kita yakin kode kita mematuhi
aturan borrowing tapi compiler tidak mampu memahami dan menjamin hal
tersebut.
Sama halnya dengan Rc<T>, RefCell<T> cuma buat dipakai di skenario
single-threaded dan bakal ngasih kita error compile-time kalau kita
mencoba memakainya di konteks multithreaded. Kita bakal bahas gimana
cara mendapatkan fungsionalitas dari RefCell<T> di dalam program
multithreaded di Bab 16.
Berikut adalah rangkuman (recap) dari alasan memilih Box<T>, Rc<T>,
atau RefCell<T>:
Rc<T>memungkinkan banyak pemilik (multiple owners) dari data yang sama;Box<T>danRefCell<T>cuma punya pemilik tunggal (single owners).Box<T>mengizinkan borrows (peminjaman) immutable atau mutable yang dicek saat compile time;Rc<T>cuma mengizinkan borrows immutable yang dicek saat compile time;RefCell<T>mengizinkan borrows immutable atau mutable yang dicek saat runtime.- Karena
RefCell<T>mengizinkan borrows mutable yang dicek saat runtime, kita bisa memutasi nilai di dalamRefCell<T>bahkan saatRefCell<T>itu sendiri sifatnya immutable.
Memutasi nilai yang ada di dalam sebuah nilai yang immutable itulah yang disebut desain pola interior mutability. Mari kita lihat sebuah situasi di mana interior mutability itu berguna dan memeriksa gimana hal itu bisa dilakukan.
Interior Mutability: Peminjaman Mutable ke sebuah Nilai yang Immutable
Sebuah konsekuensi dari aturan borrowing adalah pas kita punya nilai yang immutable, kita tidak bisa meminjamnya secara mutable. Misalnya, kode ini tidak bakal bisa di-compile:
fn main() {
let x = 5;
let y = &mut x;
}Kalau kita mencoba men-compile kode ini, kita bakal dapat error berikut:
$ cargo run
Compiling borrowing v0.1.0 (file:///projects/borrowing)
error[E0596]: cannot borrow `x` as mutable, as it is not declared as mutable
--> src/main.rs:3:13
|
3 | let y = &mut x;
| ^^^^^^ cannot borrow as mutable
|
help: consider changing this to be mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `borrowing` (bin "borrowing") due to 1 previous error
Namun, ada beberapa situasi di mana bakal berguna buat sebuah nilai buat
bisa memutasi dirinya sendiri di dalam method-methodnya tapi terlihat
immutable bagi kode lain. Kode di luar method dari nilai tersebut tidak
bakal bisa memutasi nilai itu. Memakai RefCell<T> adalah salah satu
cara buat bisa mendapatkan kemampuan buat punya interior mutability, tapi
RefCell<T> tidak sepenuhnya menghindari aturan borrowing: borrow checker
di dalam compiler memang mengizinkan interior mutability ini, dan sebagai
gantinya aturan borrowing dicek saat runtime. Kalau kita melanggar
aturan-aturannya, kita bakal dapat panic! bukannya error compiler.
Mari kita kerjakan sebuah contoh praktis di mana kita bisa memakai
RefCell<T> buat memutasi nilai yang immutable dan melihat kenapa hal
itu berguna.
Use Case untuk Interior Mutability: Mock Objects
Kadang-kadang saat lagi testing (pengujian), seorang programmer bakal memakai sebuah tipe sebagai pengganti dari tipe lain, untuk mengobservasi perilaku tertentu dan menegaskan kalau perilakunya diimplementasikan dengan benar. Tipe placeholder ini disebut test double (pengganti tes). Bayangkan saja seperti pemeran pengganti (stunt double) di pembuatan film, di mana seseorang masuk dan menggantikan sang aktor buat melakukan adegan yang sangat berbahaya (tricky scene). Test doubles menggantikan tipe lain saat kita sedang menjalankan pengujian. Mock objects (objek pura-pura) adalah jenis test double spesifik yang merekam (records) apa yang terjadi selama pengujian berjalan sehingga kita bisa menegaskan kalau aksi yang benar telah terjadi.
Rust tidak punya objects (objek) dalam artian yang sama kayak bahasa lain punya objects, dan Rust tidak punya fungsionalitas mock object bawaan di standard library seperti yang ada di beberapa bahasa lain. Namun, kita tetap bisa membikin sebuah struct yang bakal melayani tujuan yang sama dengan sebuah mock object.
Ini skenario yang bakal kita uji: kita bakal bikin sebuah library yang melacak (tracks) sebuah nilai berdasarkan nilai maksimalnya dan mengirim pesan berdasarkan seberapa dekat nilai saat ini ke nilai maksimalnya. Library ini bisa dipakai buat melacak kuota user untuk jumlah pemanggilan API yang diizinkan buat mereka, contohnya.
Library kita cuma bakal menyediakan fungsionalitas buat melacak seberapa
dekat suatu nilai ke nilai maksimalnya dan apa pesan yang seharusnya muncul
di waktu kapan aja. Aplikasi-aplikasi yang memakai library kita bakal
diharapkan buat menyediakan mekanisme pengiriman pesannya: aplikasi itu bisa
aja menaruh pesannya di dalam aplikasinya, mengirim email, mengirim pesan
teks (SMS), atau melakukan hal lain. Library-nya tidak perlu tahu detail
tersebut. Yang ia butuhkan cuma sesuatu yang mengimplementasikan sebuah trait
yang bakal kita sediakan bernama Messenger. Listing 15-20 menunjukkan kode
dari library tersebut.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}Satu bagian penting dari kode ini adalah trait Messenger punya satu method
bernama send yang menerima sebuah referensi immutable ke self dan teks
pesannya. Trait ini adalah interface (antarmuka) yang perlu
diimplementasikan oleh mock object kita sehingga si mock (objek
pura-pura) ini bisa dipakai dengan cara yang sama kayak objek aslinya dipakai.
Bagian penting lainnya adalah kita mau menguji perilaku dari method
set_value di LimitTracker. Kita bisa mengubah nilai apa yang kita teruskan
ke dalam parameter value, tapi set_value tidak mengembalikan apa pun yang
bisa kita pakai buat membuat penegasan (assertions). Kita mau bisa bilang kalau
saat kita bikin sebuah LimitTracker dengan sesuatu yang mengimplementasikan
trait Messenger dan sebuah nilai spesifik buat max, pas kita meneruskan
angka-angka yang beda buat value maka si messenger (pengirim pesan) ini bakal
disuruh mengirim pesan-pesan yang sesuai.
Kita butuh sebuah mock object yang, alih-alih mengirim email atau SMS
saat kita memanggil send, dia cuma bakal mencatat pesan-pesan apa aja yang
disuruh untuk dikirim. Kita bisa membikin sebuah instance baru dari mock object
ini, membikin sebuah LimitTracker yang memakai mock object itu,
memanggil method set_value di LimitTracker, dan kemudian mengecek kalau
mock object itu memang punya pesan-pesan yang kita harapkan. Listing 15-21
menunjukkan sebuah usaha buat mengimplementasikan sebuah mock object buat
melakukan hal itu persis, tapi borrow checker tidak bakal mengizinkannya.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
struct MockMessenger {
sent_messages: Vec<String>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: vec![],
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.len(), 1);
}
}MockMessenger yang mana tidak diizinkan oleh borrow checkerKode pengujian ini mendefinisikan sebuah struct MockMessenger yang punya field
sent_messages berisi Vec dari nilai-nilai String buat melacak
pesan-pesan apa aja yang dia disuruh buat kirim. Kita juga mendefinisikan
fungsi associated (terkait) new buat bikin nyaman pas membikin nilai
MockMessenger baru yang dimulai dengan list pesan yang kosong. Kita
kemudian mengimplementasikan trait Messenger untuk MockMessenger supaya
kita bisa ngasih sebuah MockMessenger ke sebuah LimitTracker. Di dalam
definisi dari method send, kita mengambil pesan yang diberikan sebagai
parameter lalu menyimpannya di list sent_messages milik MockMessenger.
Di dalam pengujiannya, kita menguji apa yang terjadi saat LimitTracker
disuruh buat nge-set value ke sesuatu yang jumlahnya lebih dari 75 persen
dari nilai max. Pertama kita bikin sebuah MockMessenger baru, yang mana
bakal dimulai dengan list pesan yang kosong. Terus kita bikin sebuah
LimitTracker baru dan ngasih dia sebuah referensi ke MockMessenger yang
baru itu dan nilai max sebesar 100. Kita memanggil method set_value di
LimitTracker dengan nilai 80, yang mana itu lebih dari 75 persen dari 100.
Lalu kita menegaskan kalau list pesan yang dilacak sama MockMessenger itu
seharusnya sekarang punya satu pesan di dalamnya.
Namun, ada satu masalah dengan pengujian ini, seperti yang ditunjukkan di sini:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
error[E0596]: cannot borrow `self.sent_messages` as mutable, as it is behind a `&` reference
--> src/lib.rs:58:13
|
58 | self.sent_messages.push(String::from(message));
| ^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference in the `impl` method and the `trait` definition
|
2 ~ fn send(&mut self, msg: &str);
3 | }
...
56 | impl Messenger for MockMessenger {
57 ~ fn send(&mut self, message: &str) {
|
For more information about this error, try `rustc --explain E0596`.
error: could not compile `limit-tracker` (lib test) due to 1 previous error
Kita tidak bisa memodifikasi MockMessenger buat melacak pesan-pesannya
karena method send mengambil sebuah referensi immutable ke self.
Kita juga tidak bisa mengikuti saran dari teks error-nya buat memakai
&mut self di method impl dan juga di definisi trait-nya. Kita tidak
mau mengubah trait Messenger cuma demi bisa melakukan pengujian.
Sebaliknya, kita harus cari cara buat bikin kode pengujian kita bekerja
dengan benar dengan desain kita yang udah ada.
Ini adalah sebuah situasi di mana interior mutability bisa membantu!
Kita bakal menyimpan sent_messages di dalam sebuah RefCell<T>, dan kemudian
method send bakal bisa memodifikasi sent_messages buat menyimpan
pesan-pesan yang udah kita lihat. Listing 15-22 menunjukkan seperti apa rupa
dari perubahan tersebut.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.borrow_mut().push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
// --snip--
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}RefCell<T> buat memutasi nilai internal (inner value) sembari nilai luarnya (outer value) dianggap immutableField sent_messages sekarang bertipe RefCell<Vec<String>> bukannya
Vec<String>. Di dalam fungsi new, kita membikin sebuah instance
RefCell<Vec<String>> baru di sekeliling vector kosong.
Untuk implementasi method send-nya, parameter pertamanya tetap berupa
pinjaman (borrow) immutable dari self, yang mana cocok sama definisi
trait-nya. Kita memanggil borrow_mut pada RefCell<Vec<String>> di dalam
self.sent_messages buat dapet sebuah referensi mutable ke nilai yang
ada di dalam RefCell<Vec<String>>, yaitu vector-nya. Terus kita bisa
manggil push pada referensi mutable ke vector tersebut buat melacak
pesan-pesan yang dikirim selama pengujiannya.
Perubahan terakhir yang harus kita buat adalah di penegasannya (assertion):
buat melihat ada berapa banyak item yang ada di vector internalnya, kita
memanggil borrow pada RefCell<Vec<String>> buat dapet sebuah referensi
immutable ke vector-nya.
Sekarang karena kita sudah melihat gimana cara memakai RefCell<T>, mari kita
gali lebih dalam soal gimana cara kerjanya!
Melacak Borrows saat Runtime dengan RefCell<T>
Saat membikin referensi immutable dan mutable, kita masing-masing
memakai sintaks & dan &mut. Dengan RefCell<T>, kita memakai method
borrow dan borrow_mut, yang merupakan bagian dari API aman yang dimiliki
sama RefCell<T>. Method borrow mengembalikan tipe smart pointer
Ref<T>, dan borrow_mut mengembalikan tipe smart pointer RefMut<T>.
Kedua tipe ini mengimplementasikan Deref, jadi kita bisa memperlakukan
mereka kayak referensi biasa.
RefCell<T> melacak berapa banyak smart pointers Ref<T> dan
RefMut<T> yang saat ini lagi aktif. Setiap kali kita memanggil borrow,
RefCell<T> menaikkan hitungan (count) jumlah borrows immutable yang
lagi aktif. Saat sebuah nilai Ref<T> keluar dari scope, hitungan dari
borrows immutable itu turun sebanyak 1. Persis sama kayak aturan
borrowing di compile-time, RefCell<T> membiarkan kita punya banyak
borrows immutable atau satu borrow mutable pada suatu waktu
kapan pun.
Kalau kita mencoba melanggar aturan ini, bukannya dapat error compiler
kayak yang bakal kita dapat pas pakai referensi, implementasi dari
RefCell<T> malah bakal panic di saat runtime. Listing 15-23 menunjukkan
sebuah modifikasi dari implementasi send di Listing 15-22. Kita sengaja
mencoba membikin dua borrows mutable aktif di scope yang sama buat
mengilustrasikan kalau RefCell<T> mencegah kita dari melakukan hal ini saat
runtime.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
let mut one_borrow = self.sent_messages.borrow_mut();
let mut two_borrow = self.sent_messages.borrow_mut();
one_borrow.push(String::from(message));
two_borrow.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}RefCell<T> bakal mengalami panicKita membikin sebuah variabel one_borrow buat smart pointer RefMut<T>
yang dikembalikan dari borrow_mut. Terus kita membikin borrow mutable
lainnya dengan cara yang sama di dalam variabel two_borrow. Ini membikin dua
referensi mutable di dalam scope yang sama, yang mana tidak diizinkan.
Saat kita menjalankan pengujian buat library kita, kode di Listing 15-23
bakal berhasil di-compile tanpa error apa pun, tapi pengujiannya bakal gagal:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/limit_tracker-e599811fa246dbde)
running 1 test
test tests::it_sends_an_over_75_percent_warning_message ... FAILED
failures:
---- tests::it_sends_an_over_75_percent_warning_message stdout ----
thread 'tests::it_sends_an_over_75_percent_warning_message' panicked at src/lib.rs:60:53:
RefCell already borrowed
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_sends_an_over_75_percent_warning_message
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Perhatikan kalau kodenya mengalami panic dengan pesan already borrowed: BorrowMutError. Ini adalah gimana RefCell<T> menangani pelanggaran dari
aturan borrowing saat runtime.
Memilih buat menangkap error borrowing saat runtime ketimbang saat compile
time, seperti yang udah kita lakuin di sini, berarti kita punya kemungkinan
buat nemuin kesalahan di kode kita jauh belakangan di proses pengembangan:
bahkan mungkin tidak bakal ketemu sampai kode kita sudah di-deploy ke
production (produksi). Selain itu, kode kita bakal kena sedikit penalti
(hukuman) performa runtime akibat harus melacak borrows-nya pas
runtime ketimbang pas compile time. Namun, memakai RefCell<T> memungkinkan
kita buat menulis sebuah mock object yang bisa memodifikasi dirinya sendiri buat
melacak pesan-pesan yang udah dilihatnya sementara kita memakainya di dalam sebuah
konteks di mana cuma nilai immutable yang diizinkan. Kita bisa memakai
RefCell<T> meskipun ada trade-offs (kekurangannya) buat dapat fungsionalitas
lebih banyak ketimbang yang disediakan oleh referensi biasa.
Mengizinkan Kepemilikan Ganda (Multiple Owners) pada Data yang Mutable dengan Rc<T> dan RefCell<T>
Cara yang umum buat memakai RefCell<T> adalah dengan menggabungkannya bersama
Rc<T>. Ingat kembali kalau Rc<T> membiarkan kita punya banyak pemilik
dari suatu data, tapi ia cuma ngasih akses immutable ke data tersebut. Kalau
kita punya sebuah Rc<T> yang memegang sebuah RefCell<T>, kita bisa
dapat sebuah nilai yang bisa punya banyak pemilik dan juga bisa kita mutasi
(ubah)!
Sebagai contoh, ingat kembali contoh cons list di Listing 15-18 di mana kita
memakai Rc<T> agar beberapa lists bisa berbagi kepemilikan dari sebuah list
lain. Karena Rc<T> cuma menampung nilai immutable, kita tidak bisa mengubah
satu pun nilai di dalam list-nya setelah kita membuatnya. Mari kita
menambahkan RefCell<T> agar kita bisa mendapatkan kemampuan buat mengubah
nilai-nilai di dalam lists tersebut. Listing 15-24 menunjukkan kalau dengan
memakai sebuah RefCell<T> di dalam definisi Cons, kita bisa memodifikasi
nilai yang disimpan di semua lists.
#[derive(Debug)]
enum List {
Cons(Rc<RefCell<i32>>, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
fn main() {
let value = Rc::new(RefCell::new(5));
let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil)));
let b = Cons(Rc::new(RefCell::new(3)), Rc::clone(&a));
let c = Cons(Rc::new(RefCell::new(4)), Rc::clone(&a));
*value.borrow_mut() += 10;
println!("a after = {a:?}");
println!("b after = {b:?}");
println!("c after = {c:?}");
}Rc<RefCell<i32>> buat bikin sebuah List yang bisa kita mutasiKita membikin sebuah nilai yang merupakan sebuah instance dari
Rc<RefCell<i32>> lalu menyimpannya ke dalam sebuah variabel bernama value
supaya kita bisa mengaksesnya secara langsung nanti. Terus kita membikin
sebuah List di dalam a dengan sebuah varian Cons yang memegang value.
Kita perlu meng-clone value sehingga baik a dan value dua-duanya punya
kepemilikan dari nilai internal 5 tersebut ketimbang memindahkan (transferring)
kepemilikan dari value ke a atau bikin a meminjam dari value.
Kita membungkus list a di dalam sebuah Rc<T> sehingga saat kita membikin
lists b dan c, mereka berdua bisa merujuk ke a, persis kayak yang kita
lakuin di Listing 15-18.
Setelah kita membikin lists di a, b, dan c, kita mau menambahkan 10 ke
nilai di dalam value. Kita melakukan ini dengan memanggil borrow_mut pada
value, yang mana memakai fitur automatic dereferencing yang udah kita bahas
di “Ke Mana Perginya Operator ->?” di Bab 5 buat
men-dereferensi Rc<T> ke nilai RefCell<T> di dalamnya. Method borrow_mut
mengembalikan sebuah smart pointer RefMut<T>, lalu kita memakai operator
dereferensi padanya dan mengubah nilai internalnya.
Saat kita mencetak a, b, dan c, kita bisa melihat kalau mereka semua
sekarang punya nilai yang udah dimodifikasi menjadi 15 bukannya 5:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.63s
Running `target/debug/cons-list`
a after = Cons(RefCell { value: 15 }, Nil)
b after = Cons(RefCell { value: 3 }, Cons(RefCell { value: 15 }, Nil))
c after = Cons(RefCell { value: 4 }, Cons(RefCell { value: 15 }, Nil))
Teknik ini lumayan keren! Dengan memakai RefCell<T>, dari luar kita punya
sebuah nilai List yang terlihat immutable. Tapi kita bisa memakai
method-method di RefCell<T> yang menyediakan akses ke interior mutability-nya
sehingga kita bisa memodifikasi data kita saat kita butuhkan. Pengecekan aturan
borrowing saat runtime ngelindungin kita dari data races (balapan data),
dan kadang-kadang sepadan rasanya buat menukar sedikit kecepatan (speed) demi
fleksibilitas di dalam struktur data kita ini. Perhatikan bahwa RefCell<T>
tidak bakal bekerja buat kode yang multithreaded! Mutex<T> adalah versi
yang thread-safe (aman dari utas) dari RefCell<T>, dan kita bakal membahas
Mutex<T> di Bab 16.
Siklus Referensi Bisa Menyebabkan Kebocoran Memori
Reference Cycles Bisa Membocorkan Memori (Memory Leak)
Jaminan keamanan memori (memory safety guarantees) di Rust membikin hal itu
jadi sulit, tapi bukannya mustahil, buat secara tidak sengaja membikin memori
yang tidak akan pernah dibersihkan (dikenal sebagai memory leak atau
kebocoran memori). Mencegah memory leaks secara total bukanlah salah satu
jaminan yang diberikan Rust, yang berarti memory leaks itu sifatnya aman-memori
(memory safe) di Rust. Kita bisa melihat kalau Rust mengizinkan memory leaks
dengan memakai Rc<T> dan RefCell<T>: sangat mungkin buat membikin referensi
di mana item-itemnya merujuk satu sama lain dalam sebuah cycle (siklus).
Ini membikin memory leaks karena jumlah referensi (reference count) dari
setiap item di dalam cycle tidak akan pernah mencapai 0, dan nilainya
tidak akan pernah di-drop.
Membikin Sebuah Reference Cycle
Mari kita lihat gimana sebuah reference cycle bisa terjadi dan gimana cara
mencegahnya, dimulai dengan definisi dari enum List dan method tail
di Listing 15-25.
// ANCHOR: here
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
enum List {
Cons(i32, RefCell<Rc<List>>),
Nil,
}
impl List {
fn tail(&self) -> Option<&RefCell<Rc<List>>> {
match self {
Cons(_, item) => Some(item),
Nil => None,
}
}
}
// ANCHOR_END: here
fn main() {}RefCell<T> supaya kita bisa memodifikasi apa yang ditunjuk oleh varian ConsKita memakai variasi lain dari definisi List dari Listing 15-5. Elemen
kedua di varian Cons sekarang adalah RefCell<Rc<List>>, yang berarti
bahwa ketimbang cuma punya kemampuan buat memodifikasi nilai i32 seperti
yang kita lakuin di Listing 15-24, kita sekarang mau memodifikasi nilai List
yang ditunjuk oleh sebuah varian Cons. Kita juga menambahkan method tail
buat memudahkan kita mengakses item kedua kalau kita punya sebuah varian Cons.
Di Listing 15-26, kita menambahkan fungsi main yang memakai definisi di
Listing 15-25. Kode ini membikin sebuah list di a dan sebuah list di b
yang menunjuk ke list di a. Terus dia memodifikasi list di a buat menunjuk
ke b, sehingga membikin sebuah reference cycle. Ada statements println!
di sepanjang jalan buat menunjukkan berapa jumlah referensi (reference counts)
di berbagai titik dalam proses ini.
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
enum List {
Cons(i32, RefCell<Rc<List>>),
Nil,
}
impl List {
fn tail(&self) -> Option<&RefCell<Rc<List>>> {
match self {
Cons(_, item) => Some(item),
Nil => None,
}
}
}
fn main() {
let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil))));
println!("a initial rc count = {}", Rc::strong_count(&a));
println!("a next item = {:?}", a.tail());
let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a))));
println!("a rc count after b creation = {}", Rc::strong_count(&a));
println!("b initial rc count = {}", Rc::strong_count(&b));
println!("b next item = {:?}", b.tail());
if let Some(link) = a.tail() {
*link.borrow_mut() = Rc::clone(&b);
}
println!("b rc count after changing a = {}", Rc::strong_count(&b));
println!("a rc count after changing a = {}", Rc::strong_count(&a));
// Uncomment the next line to see that we have a cycle;
// it will overflow the stack.
// println!("a next item = {:?}", a.tail());
}List yang saling menunjuk satu sama lainKita membikin instance Rc<List> yang memegang sebuah nilai List di variabel
a dengan list awal berupa 5, Nil. Terus kita membikin instance Rc<List>
yang memegang nilai List lainnya di variabel b yang berisi nilai 10
dan menunjuk ke list di a.
Kita memodifikasi a agar dia menunjuk ke b ketimbang ke Nil, sehingga
membikin sebuah cycle. Kita melakukan itu dengan memakai method tail buat
mendapatkan sebuah referensi ke RefCell<Rc<List>> di a, yang kemudian kita
taruh di variabel link. Lalu kita memakai method borrow_mut pada
RefCell<Rc<List>> tersebut buat mengubah nilai internalnya dari sebuah
Rc<List> yang memegang nilai Nil menjadi Rc<List> yang ada di b.
Saat kita menjalankan kode ini, dengan membiarkan println! terakhir
tetap dikomentari (commented out) buat saat ini, kita bakal dapat output ini:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.53s
Running `target/debug/cons-list`
a initial rc count = 1
a next item = Some(RefCell { value: Nil })
a rc count after b creation = 2
b initial rc count = 1
b next item = Some(RefCell { value: Cons(5, RefCell { value: Nil }) })
b rc count after changing a = 2
a rc count after changing a = 2
Jumlah referensi (reference count) dari instance Rc<List> di a maupun b
adalah 2 setelah kita ngubah list di a agar menunjuk ke b. Di akhir dari
main, Rust men-drop variabel b, yang mana menurunkan jumlah referensi
dari instance Rc<List> si b dari 2 menjadi 1. Memori yang dimiliki Rc<List>
di heap tidak bakal di-drop di titik ini karena jumlah referensinya itu 1,
bukannya 0. Terus Rust men-drop a, yang mana menurunkan jumlah referensi dari
instance Rc<List> si a dari 2 menjadi 1 juga. Memori dari instance ini
juga tidak bisa di-drop, karena instance Rc<List> yang satunya lagi masih
merujuk ke dia. Memori yang dialokasikan ke list tersebut bakal terus tersisa
dan tidak dibersihkan selamanya. Buat memvisualisasikan reference cycle ini,
kita sudah membikin diagram di Gambar 15-4.

Gambar 15-4: Sebuah reference cycle dari list a dan
b yang saling menunjuk satu sama lain
Kalau kita menghilangkan komentar (uncomment) pada println! yang terakhir lalu
menjalankan programnya, Rust bakal mencoba mencetak cycle ini dengan a
menunjuk ke b menunjuk ke a dan seterusnya sampai dia mengalami stack overflow.
Dibandingkan dengan program di dunia nyata, konsekuensi dari membikin reference cycle di contoh ini tidak terlalu fatal: sesaat setelah kita membikin reference cycle tersebut, programnya berakhir. Namun, kalau sebuah program yang lebih kompleks mengalokasikan banyak memori di dalam sebuah cycle lalu memegangnya untuk waktu yang lama, program tersebut bakal memakai lebih banyak memori daripada yang dia butuhkan dan bisa bikin sistem kewalahan, yang berujung pada kehabisan memori (out of memory).
Membikin reference cycles itu memang tidak mudah dilakukan, tapi itu juga
bukanlah hal yang mustahil. Kalau kita punya nilai RefCell<T> yang
mengandung nilai Rc<T> atau kombinasi bersarang yang mirip dari tipe-tipe yang
punya interior mutability dan reference counting, kita harus memastikan
kalau kita tidak membikin cycles; kita tidak bisa ngandelin Rust buat
menangkap hal tersebut. Membikin sebuah reference cycle adalah sebuah logic
bug (kutu logika) di program kita yang harusnya diminimalisir dengan memakai
automated tests (pengujian otomatis), code reviews (tinjauan kode), dan
praktik pengembangan software lainnya.
Solusi lain buat menghindari reference cycles adalah dengan mengatur ulang
struktur data kita sedemikian rupa sehingga beberapa referensi mengekspresikan
kepemilikan (ownership) dan referensi lainnya tidak. Sebagai hasilnya, kita
bisa punya cycles yang dibikin dari beberapa hubungan kepemilikan dan beberapa
hubungan non-kepemilikan, dan cuma hubungan kepemilikan lah yang memengaruhi
apakah suatu nilai bisa di-drop atau tidak. Di Listing 15-25, kita selalu mau
varian Cons buat memiliki list mereka, jadi mengatur ulang struktur datanya
itu tidak memungkinkan. Mari kita lihat contoh yang memakai graphs (graf) yang
dibikin dari parent nodes (simpul induk) dan child nodes (simpul anak)
buat melihat kapan hubungan non-kepemilikan menjadi cara yang pas buat
mencegah reference cycles.
Mencegah Reference Cycles Memakai Weak<T>
Sejauh ini, kita sudah mendemonstrasikan kalau memanggil Rc::clone bakal
menaikkan nilai strong_count dari sebuah instance Rc<T>, dan sebuah instance
Rc<T> cuma bakal dibersihkan kalau nilai strong_count-nya 0. Kita juga bisa
membikin sebuah weak reference (referensi lemah) ke sebuah nilai yang ada
di dalam instance Rc<T> dengan memanggil Rc::downgrade dan meneruskan sebuah
referensi ke Rc<T> tersebut. Strong references (referensi kuat) adalah cara
gimana kita bisa berbagi kepemilikan dari sebuah instance Rc<T>. Weak references
tidak mengekspresikan hubungan kepemilikan, dan jumlah mereka (count) tidak
memengaruhi kapan sebuah instance Rc<T> dibersihkan. Mereka tidak bakal bikin
sebuah reference cycle karena cycle apa pun yang melibatkan beberapa weak
references bakal terputus begitu jumlah strong reference dari nilai-nilai yang
terlibat mencapai 0.
Pas kita memanggil Rc::downgrade, kita bakal dapat sebuah smart pointer
bertipe Weak<T>. Alih-alih menaikkan strong_count di instance Rc<T> sebanyak
1, memanggil Rc::downgrade menaikkan weak_count sebanyak 1. Tipe Rc<T> memakai
weak_count buat melacak berapa banyak referensi Weak<T> yang ada, mirip
kayak strong_count. Bedanya adalah weak_count tidak harus 0 supaya instance
Rc<T>-nya bisa dibersihkan.
Karena nilai yang ditunjuk sama Weak<T> mungkin sudah di-drop, untuk melakukan
apa pun dengan nilai yang ditunjuk sama Weak<T> kita harus memastikan kalau
nilainya masih eksis. Lakukan ini dengan memanggil method upgrade pada sebuah
instance Weak<T>, yang mana bakal mengembalikan sebuah Option<Rc<T>>. Kita
bakal dapat hasil Some kalau nilai Rc<T> tersebut belum di-drop dan hasil
None kalau nilai Rc<T> tersebut sudah di-drop. Karena upgrade mengembalikan
sebuah Option<Rc<T>>, Rust bakal memastikan kalau kasus Some maupun kasus None
udah ditangani, dan tidak bakal ada yang namanya pointer yang tidak valid.
Sebagai contoh, ketimbang memakai sebuah list yang item-itemnya cuma tahu soal item selanjutnya aja, kita bakal membikin sebuah struktur tree (pohon) yang item-itemnya tahu soal children items (item anak) mereka dan parent items (item induk) mereka.
Membikin Struktur Data Tree: Sebuah Node dengan Child Nodes
Sebagai awalan, kita bakal ngebangun sebuah tree yang terdiri dari nodes (simpul)
yang tahu soal child nodes mereka. Kita bakal membikin sebuah struct bernama Node
yang memegang nilai i32-nya sendiri dan juga referensi ke nilai-nilai Node dari
children-nya:
Nama file: src/main.rs
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Node {
value: i32,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
children: RefCell::new(vec![]),
});
let branch = Rc::new(Node {
value: 5,
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
}Kita pengen supaya sebuah Node memiliki children-nya, dan kita mau berbagi
kepemilikan tersebut dengan berbagai variabel sehingga kita bisa mengakses
setiap Node di tree tersebut secara langsung. Buat melakukannya, kita
mendefinisikan item-item Vec<T> agar berupa nilai-nilai bertipe Rc<Node>.
Kita juga mau mengubah nodes mana saja yang merupakan children dari node lain,
jadi kita membungkus Vec<Rc<Node>> tersebut di dalam sebuah RefCell<T> di
field children.
Selanjutnya, kita bakal memakai definisi struct kita buat membikin satu instance
Node bernama leaf (daun) dengan nilai 3 dan tanpa children, serta instance
lain bernama branch (cabang) dengan nilai 5 dan leaf sebagai salah satu
children-nya, seperti yang ditunjukkan di Listing 15-27.
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Node {
value: i32,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
children: RefCell::new(vec![]),
});
let branch = Rc::new(Node {
value: 5,
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
}Kita meng-clone Rc<Node> yang ada di leaf dan menyimpannya di dalam
branch, yang artinya Node di leaf sekarang punya dua pemilik: leaf
dan branch. Kita bisa pindah dari branch ke leaf melalui branch.children,
tapi tidak ada cara buat pindah dari leaf ke branch. Alasannya adalah karena
leaf tidak punya referensi ke branch dan tidak tahu kalau mereka itu
berhubungan. Kita pengen supaya leaf tahu kalau branch itu adalah parent-nya
(induknya). Kita bakal melakukan hal itu selanjutnya.
Menambahkan Referensi dari Child ke Parent-nya
Buat membikin si child node sadar akan parent-nya, kita perlu menambahkan
sebuah field parent ke definisi struct Node kita. Masalahnya adalah
menentukan apa seharusnya tipe dari parent ini. Kita tahu kalau dia tidak
boleh berisi Rc<T>, karena itu bakal membikin sebuah reference cycle dengan
leaf.parent yang menunjuk ke branch dan branch.children yang menunjuk ke
leaf, yang mana bakal membikin nilai strong_count mereka tidak akan
pernah mencapai 0.
Membayangkan hubungan ini dengan cara lain, sebuah parent node seharusnya memiliki children-nya: kalau sebuah parent node di-drop, child nodes-nya seharusnya ikut di-drop juga. Namun, sebuah child tidak seharusnya memiliki parent-nya: kalau kita men-drop sebuah child node, sang parent seharusnya tetap eksis. Ini adalah kasus yang tepat sekali buat memakai weak references!
Jadi ketimbang memakai Rc<T>, kita bakal membikin tipe dari parent tersebut
agar memakai Weak<T>, spesifiknya adalah RefCell<Weak<Node>>. Sekarang
definisi struct Node kita kelihatan kayak gini:
Nama file: src/main.rs
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
}Sebuah node sekarang bakal bisa merujuk ke parent node-nya tapi dia tidak
memiliki parent tersebut. Di Listing 15-28, kita meng-update main buat memakai
definisi baru ini sehingga node leaf bakal punya cara buat merujuk ke
parent-nya, yaitu branch.
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
}branchMembikin node leaf ini kelihatan mirip sama yang di Listing 15-27 dengan
pengecualian di field parent: leaf awalnya tidak punya parent, jadi kita
membikin sebuah instance referensi Weak<Node> baru yang kosong.
Pada titik ini, saat kita mencoba buat mendapatkan referensi ke parent dari
leaf dengan memakai method upgrade, kita bakal dapat sebuah nilai None.
Kita bisa melihat ini di dalam output dari statement println! yang pertama:
leaf parent = None
Saat kita membikin node branch, dia juga bakal punya sebuah referensi
Weak<Node> baru di field parent-nya karena branch tidak punya parent
node. Kita tetap punya leaf sebagai salah satu dari children si branch.
Setelah kita mendapatkan instance Node di dalam branch, kita bisa
memodifikasi leaf buat ngasih dia sebuah referensi Weak<Node> ke
parent-nya. Kita memakai method borrow_mut pada RefCell<Weak<Node>> di
dalam field parent si leaf, dan terus kita pakai fungsi Rc::downgrade buat
membikin sebuah referensi Weak<Node> ke branch dari Rc<Node> yang ada
di dalam branch.
Pas kita mencetak parent dari leaf lagi, kali ini kita bakal dapat
sebuah varian Some yang memegang branch: sekarang leaf bisa mengakses
parent-nya! Pas kita mencetak leaf, kita juga terhindar dari cycle yang
pada akhirnya berujung pada stack overflow kayak yang terjadi di Listing 15-26;
referensi Weak<Node> tersebut cuma dicetak sebagai (Weak):
leaf parent = Some(Node { value: 5, parent: RefCell { value: (Weak) },
children: RefCell { value: [Node { value: 3, parent: RefCell { value: (Weak) },
children: RefCell { value: [] } }] } })
Absennya (lack of) output yang tidak terhingga ini menandakan bahwa kode ini
tidak membikin sebuah reference cycle. Kita juga bisa mengetahuinya dengan melihat
ke nilai-nilai yang kita dapat dari memanggil Rc::strong_count dan
Rc::weak_count.
Memvisualisasikan Perubahan pada strong_count dan weak_count
Mari kita lihat gimana nilai strong_count dan weak_count dari instance-instance
Rc<Node> tersebut berubah dengan membikin sebuah inner scope (scope dalam) baru
lalu memindahkan pembuatan branch ke dalam scope tersebut. Dengan melakukan ini,
kita bisa melihat apa yang terjadi saat branch dibikin dan kemudian di-drop
pas dia keluar dari scope. Modifikasi ini ditunjukkan di Listing 15-29.
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
{
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!(
"branch strong = {}, weak = {}",
Rc::strong_count(&branch),
Rc::weak_count(&branch),
);
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
}
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
}branch di sebuah inner scope dan memeriksa jumlah (count) strong dan weak reference-nyaSetelah leaf dibikin, Rc<Node> miliknya punya strong count sebesar 1 dan
weak count sebesar 0. Di dalam inner scope, kita membikin branch dan
mengaitkannya (associate) dengan leaf, di mana pada titik ini kalau kita
mencetak jumlahnya, Rc<Node> di dalam branch bakal punya strong count 1
dan weak count 1 (karena leaf.parent menunjuk ke branch dengan
sebuah Weak<Node>). Pas kita mencetak jumlah (counts) yang ada di leaf,
kita bakal melihat kalau dia punya strong count sebesar 2 karena branch
sekarang punya clone dari Rc<Node> milik leaf yang disimpan di
branch.children, tapi dia tetap punya weak count sebesar 0.
Saat inner scope-nya berakhir, branch keluar dari scope dan strong count
dari Rc<Node>-nya turun menjadi 0, jadi Node-nya bakal di-drop. Weak count
sebesar 1 dari leaf.parent sama sekali tidak memengaruhi apakah si Node itu
bakal di-drop atau tidak, jadi kita tidak dapat memory leaks!
Kalau kita nyoba mengakses parent dari leaf setelah akhir dari scope itu,
kita bakal dapat None lagi. Di akhir dari program, Rc<Node> di dalam leaf
punya strong count sebesar 1 dan weak count sebesar 0 karena variabel leaf
sekarang menjadi satu-satunya referensi ke Rc<Node> tersebut lagi.
Semua logika yang mengelola jumlah referensi (counts) dan pen-drop-an nilai ini
dibangun langsung di dalam Rc<T> dan Weak<T> beserta implementasi mereka
pada trait Drop. Dengan secara spesifik menentukan kalau hubungan dari seorang
child ke parent-nya haruslah memakai referensi Weak<T> di dalam definisi
dari Node, kita bisa membikin parent nodes menunjuk ke child nodes dan
begitu juga sebaliknya tanpa membikin sebuah reference cycle dan memory leaks.
Ringkasan
Bab ini membahas gimana cara memakai smart pointers buat membikin berbagai jaminan
dan trade-offs (pertukaran) yang berbeda dari apa yang Rust lakukan secara
default dengan referensi biasa. Tipe Box<T> punya ukuran yang sudah pasti
diketahui dan menunjuk ke data yang dialokasikan di heap. Tipe Rc<T> melacak
jumlah referensi ke data yang ada di heap supaya data tersebut bisa punya
banyak pemilik. Tipe RefCell<T> dengan kemampuan interior mutability-nya
ngasih kita tipe yang bisa kita pakai pas kita butuh tipe yang immutable tapi
juga butuh buat ngubah nilai di dalamnya; ia juga menegakkan aturan borrowing
saat runtime bukannya saat compile time.
Kita juga udah ngebahas trait Deref dan Drop, yang memungkinkan berjalannya
banyak dari fungsionalitas smart pointers ini. Kita mengeksplorasi reference
cycles yang bisa menyebabkan memory leaks dan gimana cara mencegah mereka
memakai Weak<T>.
Kalau bab ini sudah membangkitkan rasa penasaran kita dan kita pengen mengimplementasikan smart pointers kita sendiri, silakan cek “The Rustonomicon” buat dapetin lebih banyak informasi yang berguna.
Berikutnya, kita bakal ngomongin soal konkurensi (concurrency) di Rust. Kita bahkan bakal mempelajari beberapa smart pointers baru lagi lho!
Konkurensi Tanpa Rasa Takut (Fearless Concurrency)
Menangani pemrograman konkuren secara aman dan efisien adalah salah satu tujuan utama Rust lainnya. Concurrent programming (pemrograman konkuren), di mana berbagai bagian dari sebuah program dieksekusi secara independen, dan parallel programming (pemrograman paralel), di mana berbagai bagian dari sebuah program dieksekusi di saat yang bersamaan, menjadi makin penting seiring makin banyaknya komputer yang memanfaatkan prosesor multi-inti (multiple processors). Secara historis, pemrograman di dalam konteks ini selalu sulit dan rawan error. Rust berharap bisa mengubah hal tersebut.
Awalnya, tim Rust berpikir bahwa memastikan keamanan memori (memory safety) dan mencegah masalah konkurensi adalah dua tantangan terpisah yang harus diselesaikan dengan metode yang berbeda. Seiring berjalannya waktu, tim menemukan bahwa sistem kepemilikan (ownership) dan sistem tipe adalah serangkaian alat yang sangat kuat buat membantu mengelola keamanan memori dan masalah konkurensi! Dengan memanfaatkan ownership dan pengecekan tipe (type checking), banyak error konkurensi di Rust bakal menjadi error compile-time (saat kompilasi) ketimbang error runtime. Oleh karena itu, ketimbang membiarkan kita menghabiskan banyak waktu mencoba mereka ulang kondisi persis di mana sebuah bug konkurensi runtime terjadi, kode yang salah bakal menolak untuk di-compile dan menyajikan error yang menjelaskan masalahnya. Sebagai hasilnya, kita bisa memperbaiki kode kita saat kita sedang mengerjakannya, bukannya nanti setelah kodenya dikirim ke tahap produksi. Kita menjuluki aspek dari Rust ini sebagai fearless concurrency (konkurensi tanpa rasa takut). Fearless concurrency memungkinkan kita buat menulis kode yang bebas dari bugs yang tersembunyi (subtle bugs) dan mudah buat di-refactor tanpa memunculkan bugs baru.
Catatan: Demi kesederhanaan, kita bakal menyebut banyak dari masalah-masalah ini sebagai konkuren ketimbang lebih presisi dengan bilang konkuren dan/atau paralel. Buat bab ini, tolong substitusikan dalam hati konkuren dan/atau paralel kapan pun kita memakai kata konkuren. Di bab selanjutnya, di mana perbedaannya lebih penting, kita bakal lebih spesifik.
Banyak bahasa pemrograman bersifat dogmatis soal solusi yang mereka tawarkan buat menangani masalah konkuren. Misalnya, Erlang punya fungsionalitas yang elegan buat konkurensi message-passing (pengiriman pesan) tapi cuma punya cara yang samar-samar (obscure) buat membagikan state (keadaan) di antara threads. Mendukung hanya sebagian dari solusi yang memungkinkan adalah strategi yang masuk akal buat bahasa tingkat tinggi (higher-level languages) karena bahasa tingkat tinggi menjanjikan manfaat dari mengorbankan sedikit kontrol buat mendapatkan abstraksi. Namun, bahasa tingkat rendah (lower-level languages) diharapkan bisa menyediakan solusi dengan performa terbaik di situasi apa pun dan punya lebih sedikit abstraksi di atas perangkat kerasnya. Oleh karena itu, Rust menawarkan berbagai alat buat memodelkan masalah dengan cara apa pun yang cocok buat situasi dan kebutuhan kita.
Berikut adalah topik-topik yang bakal kita bahas di bab ini:
- Cara membikin threads (utas) buat menjalankan beberapa potong kode di saat yang bersamaan
- Konkurensi message-passing, di mana saluran (channels) mengirim pesan antar threads
- Konkurensi shared-state, di mana banyak threads punya akses ke sekumpulan data
- Trait
SyncdanSend, yang memperluas jaminan konkurensi Rust ke tipe-tipe yang didefinisikan sama pengguna (user-defined types) serta tipe-tipe yang disediakan oleh standard library
Memakai Threads buat Menjalankan Kode Secara Beberangan
Memakai Threads buat Menjalankan Kode Secara Bersamaan
Di sebagian besar sistem operasi saat ini, kode dari sebuah program yang dieksekusi dijalankan di dalam sebuah process (proses), dan sistem operasi bakal mengelola banyak proses sekaligus. Di dalam sebuah program, kita juga bisa punya bagian-bagian independen yang berjalan secara bersamaan (simultaneously). Fitur yang menjalankan bagian-bagian independen ini disebut threads (utas). Misalnya, sebuah web server bisa punya banyak threads sehingga ia bisa merespons lebih dari satu request (permintaan) di saat yang bersamaan.
Memecah komputasi di program kita menjadi banyak threads buat menjalankan banyak tugas di saat yang bersamaan bisa meningkatkan performa, tapi ini juga menambahkan kerumitan (complexity). Karena threads bisa berjalan secara bersamaan, tidak ada jaminan bawaan (inherent guarantee) tentang urutan bagian kode mana di threads yang berbeda yang bakal jalan duluan. Ini bisa berujung pada masalah-masalah, seperti:
- Race conditions (balapan kondisi), di mana threads mengakses data atau sumber daya (resources) dalam urutan yang tidak konsisten
- Deadlocks (jalan buntu), di mana dua threads saling menunggu satu sama lain, mencegah kedua threads tersebut buat bisa lanjut
- Bugs yang cuma terjadi di situasi-situasi tertentu dan susah buat direka ulang (reproduce) dan diperbaiki secara andal
Rust berusaha memitigasi efek-efek negatif dari memakai threads, tapi memprogram di dalam konteks multithreaded tetap butuh pemikiran yang hati-hati dan membutuhkan struktur kode yang berbeda dari program yang berjalan di satu thread saja (single thread).
Bahasa pemrograman mengimplementasikan threads dengan beberapa cara yang berbeda-beda, dan banyak sistem operasi menyediakan sebuah API yang bisa dipanggil oleh bahasa pemrograman tersebut buat membikin threads baru. Standard library Rust memakai model implementasi thread 1:1, di mana sebuah program memakai satu thread sistem operasi untuk satu thread bahasa. Ada crates yang mengimplementasikan model threading lain yang membikin trade-offs (pertukaran) yang beda dari model 1:1. (Sistem async Rust, yang bakal kita lihat di bab selanjutnya, menyediakan pendekatan lain buat konkurensi.)
Membikin Thread Baru dengan spawn
Buat membikin thread baru, kita memanggil fungsi thread::spawn lalu
memberikan sebuah closure (kita sudah membahas closures di Bab 13) yang
mengandung kode yang mau kita jalankan di thread baru tersebut. Contoh
di Listing 16-1 mencetak sedikit teks dari main thread (thread utama) dan
teks lainnya dari thread yang baru dibikin.
use std::thread;
use std::time::Duration;
fn main() {
thread::spawn(|| {
for i in 1..10 {
println!("hi number {i} from the spawned thread!");
thread::sleep(Duration::from_millis(1));
}
});
for i in 1..5 {
println!("hi number {i} from the main thread!");
thread::sleep(Duration::from_millis(1));
}
}Perhatikan bahwa saat main thread dari program Rust selesai, semua threads yang baru dibikin (spawned threads) bakal dimatikan, tidak peduli apakah mereka sudah selesai berjalan atau belum. Output dari program ini mungkin bakal sedikit berbeda setiap kalinya, tapi bakal kelihatan mirip seperti berikut:
hi number 1 from the main thread!
hi number 1 from the spawned thread!
hi number 2 from the main thread!
hi number 2 from the spawned thread!
hi number 3 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the main thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
Pemanggilan ke thread::sleep memaksa sebuah thread buat menghentikan
eksekusinya untuk durasi yang singkat, memungkinkan thread lain buat berjalan.
Threads tersebut kemungkinan bakal berjalan bergantian, tapi itu tidak dijamin:
itu bergantung sama gimana sistem operasi kita menjadwalkan (schedules)
threads tersebut. Di jalannya (run) kali ini, main thread mencetak duluan,
meskipun statement print dari spawned thread muncul duluan di kodenya. Dan
walaupun kita menyuruh spawned thread buat mencetak sampai i itu 9, ia cuma
sampai ke 5 sebelum main thread dimatikan.
Kalau kita menjalankan kode ini dan cuma melihat output dari main thread, atau tidak melihat tumpang tindih (overlap) apa pun, coba naikkan angka di rentangnya (ranges) buat membikin lebih banyak kesempatan buat sistem operasi beralih di antara threads tersebut.
Menunggu Semua Threads buat Selesai Memakai join Handles
Kode di Listing 16-1 tidak cuma menghentikan spawned thread sebelum waktunya (prematurely) di sebagian besar waktu karena main thread yang berakhir duluan, tapi karena tidak ada jaminan di urutan mana threads itu berjalan, kita juga tidak bisa menjamin apakah spawned thread itu bakal dapat kesempatan buat berjalan sama sekali!
Kita bisa membereskan masalah spawned thread yang tidak berjalan atau
berakhir sebelum waktunya dengan menyimpan nilai kembalian (return value) dari
thread::spawn ke dalam sebuah variabel. Tipe kembalian dari thread::spawn
adalah JoinHandle<T>. Sebuah JoinHandle<T> adalah nilai yang dimiliki (owned
value) yang, saat kita memanggil method join padanya, bakal menunggu sampai
thread-nya selesai. Listing 16-2 menunjukkan gimana cara memakai
JoinHandle<T> dari thread yang kita bikin di Listing 16-1 dan gimana cara
memanggil join buat memastikan spawned thread tersebut selesai sebelum main
keluar (exits).
use std::thread;
use std::time::Duration;
fn main() {
let handle = thread::spawn(|| {
for i in 1..10 {
println!("hi number {i} from the spawned thread!");
thread::sleep(Duration::from_millis(1));
}
});
for i in 1..5 {
println!("hi number {i} from the main thread!");
thread::sleep(Duration::from_millis(1));
}
handle.join().unwrap();
}JoinHandle<T> dari thread::spawn buat menjamin thread-nya berjalan sampai selesaiMemanggil join pada handle bakal memblokir (blocks) thread yang saat ini
lagi jalan sampai thread yang diwakili oleh handle tersebut berhenti (terminates).
Memblokir sebuah thread berarti thread tersebut dicegah buat melakukan
pekerjaan atau keluar. Karena kita menaruh pemanggilan join setelah for loop
milik main thread, menjalankan Listing 16-2 seharusnya menghasilkan output
yang mirip kayak gini:
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 1 from the spawned thread!
hi number 3 from the main thread!
hi number 2 from the spawned thread!
hi number 4 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
Dua threads tersebut lanjut berjalan bergantian, tapi main thread menunggu
karena adanya pemanggilan handle.join() dan tidak berakhir sampai spawned
thread-nya selesai.
Tapi mari kita lihat apa yang terjadi kalau kita malah memindahkan handle.join()
sebelum for loop di main, kayak gini:
use std::thread;
use std::time::Duration;
fn main() {
let handle = thread::spawn(|| {
for i in 1..10 {
println!("hi number {i} from the spawned thread!");
thread::sleep(Duration::from_millis(1));
}
});
handle.join().unwrap();
for i in 1..5 {
println!("hi number {i} from the main thread!");
thread::sleep(Duration::from_millis(1));
}
}Main thread bakal menunggu spawned thread buat selesai baru kemudian dia menjalankan for loop-nya, jadi outputnya tidak bakal tumpang tindih lagi, seperti yang ditunjukkan di sini:
hi number 1 from the spawned thread!
hi number 2 from the spawned thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 3 from the main thread!
hi number 4 from the main thread!
Detail-detail kecil, kayak di mana join itu dipanggil, bisa memengaruhi apakah
threads kita berjalan secara bersamaan atau tidak.
Memakai Closures move bersama Threads
Kita bakal sering memakai keyword move bersama closures yang diteruskan
ke thread::spawn karena closure tersebut kemudian bakal mengambil
kepemilikan atas nilai-nilai yang dia pakai dari lingkungannya, sehingga
mentransfer kepemilikan dari nilai-nilai tersebut dari satu thread ke thread
lainnya. Di “Menangkap Referensi atau Memindahkan Kepemilikan” di
Bab 13, kita sudah membahas move di dalam konteks closures. Sekarang kita
bakal lebih konsentrasi pada interaksi antara move dan thread::spawn.
Perhatikan di Listing 16-1 bahwa closure yang kita teruskan ke
thread::spawn tidak menerima argumen apa pun: kita tidak memakai data apa
pun dari main thread di dalam kode milik spawned thread. Buat memakai
data dari main thread di dalam spawned thread, closure si spawned thread
harus menangkap (capture) nilai-nilai yang dia butuhkan. Listing 16-3
menunjukkan usaha buat membikin sebuah vector di main thread dan memakainya
di dalam spawned thread. Namun, ini belum bisa jalan, seperti yang bakal kita
lihat sebentar lagi.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {v:?}");
});
handle.join().unwrap();
}Closure ini memakai v, jadi dia bakal menangkap v dan menjadikannya bagian
dari lingkungan closure tersebut. Karena thread::spawn menjalankan closure
ini di sebuah thread baru, kita seharusnya bisa mengakses v di dalam thread
baru tersebut. Tapi pas kita men-compile contoh ini, kita dapat error berikut:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0373]: closure may outlive the current function, but it borrows `v`, which is owned by the current function
--> src/main.rs:6:32
|
6 | let handle = thread::spawn(|| {
| ^^ may outlive borrowed value `v`
7 | println!("Here's a vector: {v:?}");
| - `v` is borrowed here
|
note: function requires argument type to outlive `'static`
--> src/main.rs:6:18
|
6 | let handle = thread::spawn(|| {
| __________________^
7 | | println!("Here's a vector: {v:?}");
8 | | });
| |______^
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
For more information about this error, try `rustc --explain E0373`.
error: could not compile `threads` (bin "threads") due to 1 previous error
Rust menebak (infers) gimana cara menangkap v, dan karena println! cuma
butuh sebuah referensi ke v, closure tersebut mencoba meminjam (borrow) v.
Namun, ada sebuah masalah: Rust tidak bisa memberi tahu berapa lama spawned
thread tersebut bakal berjalan, jadi dia tidak tahu apakah referensi ke v
itu bakal selalu valid.
Listing 16-4 memberikan skenario yang punya kemungkinan lebih tinggi di mana
referensi ke v tidak bakal valid.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {v:?}");
});
drop(v); // oh no!
handle.join().unwrap();
}v dari sebuah main thread yang men-drop vKalau Rust mengizinkan kita menjalankan kode ini, ada kemungkinan kalau spawned
thread tersebut bakal langsung ditaruh di background (latar belakang) tanpa
sempat dijalankan sama sekali. Spawned thread itu punya referensi ke v di
dalamnya, tapi main thread langsung men-drop (membuang) v, memakai
fungsi drop yang sudah kita bahas di Bab 15. Lalu, saat spawned thread
mulai dieksekusi, v sudah tidak valid lagi, jadi referensi ke dia juga ikutan
tidak valid. Waduh!
Buat membenarkan error compiler di Listing 16-3, kita bisa memakai saran dari pesan error-nya:
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
Dengan menambahkan keyword move sebelum closure, kita memaksa closure
buat mengambil kepemilikan dari nilai-nilai yang dia pakai, ketimbang membiarkan
Rust menebak kalau dia seharusnya meminjam (borrow) nilai-nilai tersebut.
Modifikasi buat Listing 16-3 yang ditunjukkan di Listing 16-5 bakal bisa
di-compile dan berjalan sesuai keinginan kita.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(move || {
println!("Here's a vector: {v:?}");
});
handle.join().unwrap();
}move buat memaksa sebuah closure untuk mengambil kepemilikan dari nilai-nilai yang dia pakaiKita mungkin tergiur buat mencoba hal yang sama buat membenarkan kode di Listing
16-4 di mana main thread memanggil drop, dengan memakai closure move.
Namun, perbaikan ini tidak bakal bisa karena apa yang coba dilakukan oleh
Listing 16-4 itu tidak diizinkan buat alasan yang berbeda. Kalau kita menambahkan
move ke closure tersebut, kita bakal memindahkan v ke dalam lingkungan
closure-nya, dan kita tidak bisa lagi memanggil drop padanya di main thread.
Kita malah bakal dapat error compiler ini:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0382]: use of moved value: `v`
--> src/main.rs:10:10
|
4 | let v = vec![1, 2, 3];
| - move occurs because `v` has type `Vec<i32>`, which does not implement the `Copy` trait
5 |
6 | let handle = thread::spawn(move || {
| ------- value moved into closure here
7 | println!("Here's a vector: {v:?}");
| - variable moved due to use in closure
...
10 | drop(v); // oh no!
| ^ value used here after move
|
help: consider cloning the value before moving it into the closure
|
6 ~ let value = v.clone();
7 ~ let handle = thread::spawn(move || {
8 ~ println!("Here's a vector: {value:?}");
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `threads` (bin "threads") due to 1 previous error
Aturan ownership (kepemilikan) Rust sudah menyelamatkan kita lagi! Kita dapat
error dari kode di Listing 16-3 karena Rust bertindak konservatif dan cuma
meminjam v buat thread tersebut, yang mana berarti main thread secara
teoritis bisa membikin referensi si spawned thread jadi tidak valid. Dengan
memberi tahu Rust buat memindahkan kepemilikan dari v ke spawned thread,
kita menjamin ke Rust kalau main thread tidak bakal memakai v lagi. Kalau
kita mengubah Listing 16-4 dengan cara yang sama, kita malah melanggar aturan
kepemilikan saat kita mencoba memakai v di main thread. Keyword move
menimpa (overrides) aturan default konservatif Rust yang melakukan peminjaman
(borrowing); ia tidak mengizinkan kita buat melanggar aturan kepemilikannya.
Sekarang karena kita sudah membahas apa itu threads dan method-method yang disediakan oleh API thread, mari kita lihat beberapa situasi di mana kita bisa memakai threads.
Transfer Data antar Threads Memakai Message Passing
Memakai Message Passing buat Mentransfer Data Antar Threads
Satu pendekatan yang makin populer buat memastikan konkurensi yang aman adalah message passing (pengiriman pesan), di mana threads atau actors berkomunikasi dengan mengirimkan pesan berisi data ke satu sama lain. Ide ini digambarkan dalam sebuah slogan dari dokumentasi bahasa Go: “Jangan berkomunikasi dengan membagikan (sharing) memori; sebaliknya, bagikan memori dengan berkomunikasi.”
Buat mencapai konkurensi pengiriman pesan ini, standard library Rust menyediakan sebuah implementasi dari saluran (channels). Sebuah channel adalah konsep pemrograman umum di mana data dikirim dari satu thread ke thread lainnya.
Kita bisa membayangkan sebuah channel di dalam pemrograman itu kayak saluran air yang mengalir ke satu arah, seperti sungai atau selokan. Kalau kita menaruh sesuatu kayak bebek karet ke dalam sungai, dia bakal mengalir ke hilir (downstream) sampai ke ujung saluran air tersebut.
Sebuah channel punya dua paruh: sebuah transmitter (pemancar/pengirim) dan sebuah receiver (penerima). Paruh transmitter adalah lokasi hulu (upstream) tempat kita menaruh bebek karetnya ke dalam sungai, dan paruh receiver adalah hilir tempat si bebek karet pada akhirnya berlabuh. Satu bagian dari kode kita memanggil method-method di transmitter dengan data yang mau kita kirim, dan bagian lain mengecek ujung penerima (receiving end) buat melihat pesan yang datang. Sebuah channel dikatakan closed (tertutup) kalau entah paruh transmitter atau receiver-nya di-drop (dibuang).
Di sini, kita bakal perlahan ngebangun sebuah program yang punya satu thread buat nge-generate nilai dan mengirimkannya ke dalam sebuah channel, dan satu thread lain yang bakal menerima nilai-nilai tersebut lalu mencetaknya ke layar. Kita bakal mengirim nilai-nilai sederhana antar threads memakai sebuah channel buat mengilustrasikan fitur ini. Begitu kita udah terbiasa sama tekniknya, kita bisa memakai channels buat threads mana aja yang butuh berkomunikasi satu sama lain, kayak sistem chat atau sistem di mana banyak threads melakukan bagian-bagian dari sebuah perhitungan lalu mengirim bagian-bagian tersebut ke satu thread yang mengagregasikan (mengumpulkan) hasilnya.
Pertama, di Listing 16-6, kita bakal membikin sebuah channel tapi tidak melakukan apa-apa dengannya. Perhatikan bahwa ini belum bisa di-compile karena Rust tidak tahu tipe nilai apa yang mau kita kirim lewat channel ini.
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
}tx dan rxKita membikin sebuah channel baru memakai fungsi mpsc::channel; mpsc
adalah singkatan dari multiple producer, single consumer (banyak
penghasil, satu konsumen). Singkatnya, cara standard library Rust
mengimplementasikan channels berarti sebuah channel bisa punya banyak
ujung pengirim (sending ends) yang memproduksi nilai tapi cuma bisa punya
satu ujung penerima (receiving end) yang mengonsumsi nilai-nilai tersebut.
Bayangin ada banyak aliran sungai kecil yang ngalir bersatu jadi satu
sungai besar: apa pun yang dikirim ke salah satu sungai kecil itu bakal
berakhir di satu sungai besar tersebut di ujungnya. Kita bakal mulai dengan
satu produsen (producer) aja buat sekarang, tapi kita bakal nambahin banyak
produsen pas contoh ini udah bisa jalan.
Fungsi mpsc::channel mengembalikan sebuah tuple, yang elemen pertamanya
adalah ujung pengirim (the sending end)—yaitu si transmitter—dan elemen
keduanya adalah ujung penerima (the receiving end)—yaitu si receiver.
Singkatan tx dan rx secara tradisional sering dipakai di banyak bidang
untuk masing-masing transmitter dan receiver, jadi kita menamai variabel
kita dengan nama tersebut buat mengindikasikan setiap ujungnya. Kita
memakai statement let dengan sebuah pola (pattern) yang men-destructure
tuples tersebut; kita bakal membahas pemakaian pola di dalam statements
let dan destructuring di Bab 19. Buat sekarang, ketahui aja kalau
memakai statement let dengan cara ini adalah pendekatan yang nyaman buat
mengekstrak potongan-potongan dari tuple yang dikembalikan sama
mpsc::channel.
Mari kita pindahkan ujung pengirim (transmitting end) ke dalam spawned thread lalu suruh dia mengirim satu string supaya spawned thread tersebut berkomunikasi sama main thread, seperti yang ditunjukkan di Listing 16-7. Ini ibarat naruh bebek karet di bagian hulu sungai atau ngirim pesan chat dari satu thread ke thread lainnya.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
});
}tx ke dalam sebuah spawned thread dan mengirim "hi"Sekali lagi, kita memakai thread::spawn buat membikin thread baru lalu
memakai move buat memindahkan tx ke dalam closure supaya spawned
thread tersebut memiliki (owns) tx. Spawned thread perlu memiliki si
transmitter supaya bisa mengirim pesan lewat channel.
Transmitter punya sebuah method send yang menerima nilai yang mau kita
kirim. Method send mengembalikan sebuah tipe Result<T, E>, jadi kalau
receiver-nya ternyata sudah di-drop dan tidak ada tempat lagi buat ngirim
nilai, operasi pengirimannya (send) bakal mengembalikan sebuah error. Di
contoh ini, kita memanggil unwrap buat panic seandainya terjadi error. Tapi
di aplikasi betulan (real application), kita bakal menanganinya dengan benar:
silakan kembali ke Bab 9 buat me-review strategi-strategi buat penanganan
error yang tepat.
Di Listing 16-8, kita bakal mengambil nilainya dari receiver di dalam main thread. Ini ibarat memungut bebek karet dari air di ujung hilir sungai atau menerima sebuah pesan chat.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
});
let received = rx.recv().unwrap();
println!("Got: {received}");
}"hi" di dalam main thread dan mencetaknyaReceiver punya dua method yang berguna: recv dan try_recv. Kita
memakai recv, singkatan dari receive (menerima), yang bakal memblokir
eksekusi dari main thread dan menunggu sampai sebuah nilai dikirim lewat
channel tersebut. Begitu ada nilai yang dikirim, recv bakal
mengembalikannya di dalam sebuah Result<T, E>. Saat transmitter ditutup,
recv bakal mengembalikan sebuah error buat memberi sinyal bahwa tidak akan
ada lagi nilai yang bakal datang.
Method try_recv tidak melakukan pemblokiran (doesn’t block), tapi ia bakal
langsung mengembalikan sebuah Result<T, E>: nilai Ok yang memegang sebuah
pesan kalau pesannya lagi tersedia dan nilai Err kalau tidak ada pesan
sama sekali saat ini. Memakai try_recv berguna kalau thread ini punya
kerjaan lain yang harus dilakuin sambil nunggu pesan: kita bisa nulis
sebuah loop yang memanggil try_recv sesekali, menangani pesannya kalau
lagi tersedia, dan kalau enggak, ngerjain tugas lain dulu sebentar sampai
waktunya ngecek lagi.
Kita memakai recv di contoh ini buat kesederhanaan; kita tidak punya
kerjaan lain buat main thread selain menunggu pesan, jadi memblokir
main thread adalah pilihan yang tepat.
Pas kita menjalankan kode di Listing 16-8, kita bakal melihat nilai yang dicetak dari main thread:
Got: hi
Sempurna!
Channels dan Transfer Kepemilikan (Ownership Transference)
Aturan-aturan ownership (kepemilikan) memainkan peran vital dalam
pengiriman pesan karena mereka ngebantu kita nulis kode konkuren yang aman.
Mencegah error di pemrograman konkuren adalah keuntungan (advantage) dari
memikirkan tentang ownership di sepanjang program Rust kita. Mari kita
lakukan sebuah eksperimen buat nunjukin gimana channels dan ownership
bekerja bersama-sama mencegah timbulnya masalah: kita bakal nyoba memakai
sebuah nilai val di dalam spawned thread setelah kita ngirim nilai itu
lewat channel. Coba compile kode di Listing 16-9 buat melihat kenapa kode
ini tidak diizinkan.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
println!("val is {val}");
});
let received = rx.recv().unwrap();
println!("Got: {received}");
}val setelah kita mengirimnya lewat channelDi sini, kita mencoba buat mencetak val setelah kita mengirimnya lewat
channel via tx.send. Mengizinkan ini adalah ide yang buruk: begitu nilainya
sudah dikirim ke thread lain, thread tersebut bisa aja memodifikasi atau
men-drop-nya sebelum kita nyoba memakai nilai itu lagi. Secara potensial,
modifikasi yang dilakukan sama thread lain bisa menyebabkan error atau hasil
yang tidak disangka-sangka akibat adanya data yang tidak konsisten atau sudah
tidak eksis lagi. Namun, Rust ngasih kita error kalau kita mencoba men-compile
kode di Listing 16-9:
$ cargo run
Compiling message-passing v0.1.0 (file:///projects/message-passing)
error[E0382]: borrow of moved value: `val`
--> src/main.rs:10:27
|
8 | let val = String::from("hi");
| --- move occurs because `val` has type `String`, which does not implement the `Copy` trait
9 | tx.send(val).unwrap();
| --- value moved here
10 | println!("val is {val}");
| ^^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0382`.
error: could not compile `message-passing` (bin "message-passing") due to 1 previous error
Kesalahan konkurensi (concurrency mistake) kita ini sudah membikin sebuah error
compile-time. Fungsi send mengambil kepemilikan atas parameternya, dan
saat nilainya dipindahkan (moved), receiver bakal mengambil kepemilikannya.
Hal ini menghentikan kita dari memakai nilai itu secara tidak sengaja lagi
setelah mengirimnya; sistem ownership memastikan kalau semuanya aman terkendali.
Mengirim Banyak Nilai dan Melihat Receiver Menunggu
Kode di Listing 16-8 berhasil di-compile dan jalan, tapi dia tidak secara jelas menunjukkan ke kita kalau ada dua threads terpisah yang lagi ngobrol satu sama lain lewat channel.
Di Listing 16-10 kita sudah membuat beberapa modifikasi yang bakal membuktikan kalau kode di Listing 16-8 itu berjalan secara konkuren: spawned thread sekarang bakal mengirim banyak pesan dan ngasih jeda sebentar (pause) satu detik di antara setiap pesannya.
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {received}");
}
}Kali ini, spawned thread punya sebuah vector berisi string yang mau kita
kirim ke main thread. Kita iterasi ngelewatin mereka, ngirim setiap string-nya
satu-satu, dan ngasih jeda di antara setiap pengiriman dengan memanggil
fungsi thread::sleep beserta sebuah nilai Duration satu detik.
Di dalam main thread, kita tidak memanggil fungsi recv secara eksplisit
lagi: sebaliknya, kita memperlakukan rx sebagai sebuah iterator. Buat setiap
nilai yang diterima, kita bakal mencetaknya. Saat channel-nya ditutup,
iterasinya bakal berakhir.
Pas kita menjalankan kode di Listing 16-10, kita seharusnya melihat output berikut dengan jeda satu detik di antara setiap barisnya:
Got: hi
Got: from
Got: the
Got: thread
Karena kita tidak punya kode yang melakukan jeda atau penundaan (delays) di dalam for loop di main thread, kita bisa tahu kalau main thread tersebut lagi nunggu buat nerima nilai-nilai dari spawned thread.
Membikin Banyak Producers dengan Meng-clone si Transmitter
Tadi kita sempat menyebutkan kalau mpsc adalah singkatan dari multiple producer,
single consumer (banyak penghasil, satu konsumen). Mari kita manfaatin
mpsc ini lalu ekspansi kode di Listing 16-10 buat membikin beberapa threads
yang semuanya mengirim nilai ke satu receiver yang sama. Kita bisa melakukan
itu dengan meng-clone transmitter-nya, seperti yang ditunjukkan di Listing 16-11.
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
// --snip--
let (tx, rx) = mpsc::channel();
let tx1 = tx.clone();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx1.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
thread::spawn(move || {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {received}");
}
// --snip--
}Kali ini, sebelum kita membikin spawned thread yang pertama, kita memanggil
clone pada transmitter-nya. Ini bakal ngasih kita sebuah transmitter baru
yang bisa kita teruskan ke spawned thread yang pertama. Kita meneruskan
transmitter aslinya ke sebuah spawned thread yang kedua. Hal ini ngasih
kita dua threads, di mana masing-masing mengirim pesan yang berbeda ke
satu receiver yang sama.
Pas kita menjalankan kodenya, output kita harusnya bakal kelihatan kurang lebih kayak gini:
Got: hi
Got: more
Got: from
Got: messages
Got: for
Got: the
Got: thread
Got: you
kita mungkin bakal melihat nilai-nilainya dalam urutan yang berbeda,
tergantung dari sistem yang kita pakai. Inilah yang membikin konkurensi
jadi hal yang menarik sekaligus sulit. Kalau kita eksperimen sama
thread::sleep, ngasih dia nilai yang beda-beda di berbagai threads
tersebut, masing-masing jalan (run) bakal jadi makin tidak deterministik
dan menghasilkan output yang berbeda-beda setiap kalinya.
Sekarang setelah kita melihat gimana channels itu bekerja, mari kita lihat metode konkurensi yang berbeda.
Konkurensi dengan Shared-State (Status Bersama)
Konkurensi Shared-State (Keadaan Berbagi)
Pengiriman pesan (message passing) adalah cara yang bagus buat menangani konkurensi, tapi itu bukan satu-satunya cara. Metode lain adalah dengan membiarkan banyak threads buat mengakses data bersama (shared data) yang sama. Ingat kembali slogan dari dokumentasi bahasa Go ini: “Jangan berkomunikasi dengan membagikan (sharing) memori.”
Kira-kira gimana sih bentuknya berkomunikasi dengan membagikan memori itu? Selain itu, kenapa para penggemar message-passing mewanti-wanti buat tidak memakai berbagi memori (memory sharing)?
Di satu sisi, channels (saluran) di bahasa pemrograman mana pun itu mirip dengan kepemilikan tunggal (single ownership) karena begitu kita mentransfer sebuah nilai lewat channel, kita tidak seharusnya memakai nilai itu lagi. Konkurensi memori bersama (shared-memory concurrency) itu kayak kepemilikan ganda (multiple ownership): banyak threads bisa mengakses lokasi memori yang sama di saat yang bersamaan. Seperti yang udah kita lihat di Bab 15, di mana smart pointers memungkinkan kepemilikan ganda, kepemilikan ganda bisa nambahin kerumitan (complexity) karena pemilik-pemilik yang berbeda ini butuh dikelola (managed). Sistem tipe (type system) dan aturan ownership Rust ngebantu sekali buat bikin pengelolaan ini jadi benar. Sebagai contoh, mari kita lihat mutexes, salah satu dari struktur data konkurensi (concurrency primitives) yang paling umum dipakai buat memori bersama.
Memakai Mutexes buat Mengizinkan Akses ke Data dari Satu Thread dalam Satu Waktu
Mutex adalah singkatan dari mutual exclusion (pengecualian timbal balik), yang artinya sebuah mutex cuma mengizinkan satu thread aja buat mengakses beberapa data di satu waktu tertentu. Buat mengakses data di dalam sebuah mutex, sebuah thread pertama-tama harus ngasih sinyal kalau dia mau akses dengan meminta buat ngambil (acquire) lock (kunci) milik mutex tersebut. Lock adalah struktur data yang jadi bagian dari mutex yang melacak siapa yang saat ini punya akses eksklusif ke datanya. Oleh karena itu, mutex digambarkan sebagai penjaga (guarding) data yang dia pegang melalui sistem locking ini.
Mutexes terkenal susah dipakai karena kita harus ingat dua aturan ini:
- Kita harus mencoba mengambil (acquire) lock-nya sebelum memakai datanya.
- Pas kita kelar sama data yang dijaga sama mutex tersebut, kita harus membuka kunci (unlock) datanya supaya threads lain bisa mengambil lock itu.
Sebagai metafora dunia nyata buat sebuah mutex, bayangin sebuah panel diskusi di sebuah konferensi yang cuma punya satu mikrofon. Sebelum seorang panelis bisa ngomong, dia harus minta atau ngasih sinyal kalau dia mau memakai mikrofonnya. Saat dia dapat mikrofonnya, dia bisa ngomong selama yang dia mau lalu memberikan mikrofonnya ke panelis berikutnya yang meminta buat ngomong. Kalau ada panelis yang lupa ngasih mikrofonnya ke orang lain pas udah selesai, tidak bakal ada orang lain yang bisa ngomong. Kalau pengelolaan mikrofon bersama ini jadi berantakan, panelnya tidak bakal berjalan sesuai rencana!
Pengelolaan mutex bisa jadi susah sekali buat dibikin benar, itulah kenapa banyak orang jadi antusias sekali sama channels. Namun, berkat sistem tipe dan aturan ownership di Rust, kita tidak mungkin salah mengunci dan membuka kunci.
API dari Mutex<T>
Sebagai contoh gimana cara memakai mutex, mari mulai dengan memakai sebuah mutex di dalam konteks satu thread (single-threaded), seperti yang ditunjukkan di Listing 16-12.
use std::sync::Mutex;
fn main() {
let m = Mutex::new(5);
{
let mut num = m.lock().unwrap();
*num = 6;
}
println!("m = {m:?}");
}Mutex<T> di dalam konteks single-threaded buat kesederhanaanSama kayak banyak tipe lainnya, kita membikin sebuah Mutex<T> dengan memakai
fungsi associated new. Buat mengakses data di dalam mutex-nya, kita memakai
method lock buat ngambil lock-nya. Pemanggilan ini bakal memblokir (block)
thread yang saat ini lagi jalan sehingga ia tidak bisa melakukan kerjaan
apa-apa sampai giliran kita dapat lock-nya.
Pemanggilan ke lock bakal gagal kalau thread lain yang sedang memegang
lock tersebut mengalami panic. Di kasus itu, tidak bakal ada yang bisa
ngedapetin lock-nya lagi, jadi kita memilih buat unwrap dan membikin
thread ini panic kalau kita ada di situasi tersebut.
Setelah kita dapat lock-nya, kita bisa memperlakukan nilai kembaliannya,
yang kita namakan num di sini, sebagai referensi mutable ke data internalnya.
Sistem tipe memastikan kalau kita dapat lock-nya dulu sebelum memakai nilai di
dalam m. Tipe dari m adalah Mutex<i32>, bukannya i32, jadi kita harus
memanggil lock supaya bisa memakai nilai i32 tersebut. Kita tidak bisa lupa;
sistem tipenya tidak bakal ngebiarin kita mengakses i32 internal itu kalau kita
tidak melakukannya.
Pemanggilan ke lock mengembalikan sebuah tipe bernama MutexGuard, yang
dibungkus di dalam sebuah LockResult yang tadi kita tangani dengan panggilan ke
unwrap. Tipe MutexGuard mengimplementasikan Deref agar dia menunjuk ke data
internal kita; tipe ini juga punya implementasi Drop yang melepaskan lock-nya
secara otomatis saat sebuah MutexGuard keluar dari scope, yang mana terjadi di
akhir dari inner scope (scope dalam). Sebagai hasilnya, kita tidak bakal ambil
risiko lupa melepaskan lock-nya dan ngeblokir mutex tersebut dari dipakai sama
threads lain, karena pelepasan lock itu terjadi secara otomatis.
Setelah lock-nya di-drop, kita bisa mencetak nilai mutex tersebut dan melihat
kalau kita berhasil ngubah i32 internalnya jadi 6.
Berbagi Mutex<T> di Antara Beberapa Threads
Sekarang mari kita coba membagikan sebuah nilai di antara beberapa threads
memakai Mutex<T>. Kita bakal membikin (spin up) 10 threads dan menyuruh
masing-masing dari mereka buat menaikkan nilai penghitung (counter) sebanyak 1,
sehingga penghitungnya berjalan dari 0 sampai 10. Contoh di Listing 16-13
bakal mengalami error compiler, dan kita bakal memakai error itu buat belajar
lebih banyak soal memakai Mutex<T> dan gimana Rust ngebantu kita memakainya
dengan benar.
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Mutex::new(0);
let mut handles = vec![];
for _ in 0..10 {
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Mutex<T>Kita bikin sebuah variabel counter buat memegang sebuah i32 di dalam
sebuah Mutex<T>, kayak yang kita lakuin di Listing 16-12. Selanjutnya, kita
bikin 10 threads dengan iterasi melewati serangkaian angka. Kita memakai
thread::spawn dan ngasih closure yang sama ke semua threads itu: sebuah
closure yang memindahkan (moves) penghitung tersebut ke dalam thread,
mengambil lock pada Mutex<T> dengan memanggil method lock, lalu
menambahkan 1 ke nilai yang ada di dalam mutex tersebut. Pas sebuah thread
kelar ngejalanin closure-nya, num bakal keluar dari scope dan melepaskan
lock-nya supaya thread lain bisa mengambil lock itu.
Di main thread, kita mengumpulkan (collect) semua join handles. Terus,
sama kayak di Listing 16-2, kita memanggil join pada setiap handle buat
memastikan semua threads selesai. Di titik itu, main thread bakal ngambil
lock-nya dan mencetak hasil dari program ini.
Kita tadi udah ngebocorin kalau contoh ini tidak bakal bisa di-compile. Sekarang mari kita cari tahu alasannya kenapa!
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0382]: borrow of moved value: `counter`
--> src/main.rs:21:29
|
5 | let counter = Mutex::new(0);
| ------- move occurs because `counter` has type `std::sync::Mutex<i32>`, which does not implement the `Copy` trait
...
8 | for _ in 0..10 {
| -------------- inside of this loop
9 | let handle = thread::spawn(move || {
| ------- value moved into closure here, in previous iteration of loop
...
21 | println!("Result: {}", *counter.lock().unwrap());
| ^^^^^^^ value borrowed here after move
|
help: consider moving the expression out of the loop so it is only moved once
|
8 ~ let mut value = counter.lock();
9 ~ for _ in 0..10 {
10 | let handle = thread::spawn(move || {
11 ~ let mut num = value.unwrap();
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `shared-state` (bin "shared-state") due to 1 previous error
Pesan error-nya bilang kalau nilai counter itu udah dipindahkan (moved) di
iterasi loop sebelumnya. Rust ngasih tahu kita kalau kita tidak bisa
memindahkan kepemilikan lock counter ke dalam beberapa threads. Mari
kita perbaiki error compiler ini dengan metode kepemilikan ganda (multiple-
ownership method) yang udah kita bahas di Bab 15.
Multiple Ownership dengan Multiple Threads
Di Bab 15, kita ngasih sebuah nilai ke beberapa pemilik (multiple owners)
dengan memakai smart pointer Rc<T> buat membikin nilai yang jumlah
referensinya dilacak (reference counted value). Mari kita lakuin hal yang
sama di sini dan lihat apa yang terjadi. Kita bakal ngebungkus Mutex<T> ke
dalam Rc<T> di Listing 16-14 dan meng-clone Rc<T>-nya sebelum
memindahkan kepemilikannya ke dalam thread.
use std::rc::Rc;
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Rc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Rc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Rc<T> buat mengizinkan beberapa threads buat memiliki Mutex<T>Sekali lagi, kita compile dan… dapat error yang beda! Compiler-nya ngajarin kita banyak hal.
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0277]: `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ------------- ^------
| | |
| ______________________|_____________within this `{closure@src/main.rs:11:36: 11:43}`
| | |
| | required by a bound introduced by this call
12 | | let mut num = counter.lock().unwrap();
13 | |
14 | | *num += 1;
15 | | });
| |_________^ `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
|
= help: within `{closure@src/main.rs:11:36: 11:43}`, the trait `Send` is not implemented for `Rc<std::sync::Mutex<i32>>`
note: required because it's used within this closure
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ^^^^^^^
note: required by a bound in `spawn`
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/std/src/thread/mod.rs:723:1
For more information about this error, try `rustc --explain E0277`.
error: could not compile `shared-state` (bin "shared-state") due to 1 previous error
Wow, pesan error-nya panjang sekali ya! Ini bagian penting yang perlu jadi
fokus: `Rc<Mutex<i32>>` cannot be sent between threads safely. Compiler-nya
juga ngasih tahu kita apa alasannya: the trait `Send` is not implemented for `Rc<Mutex<i32>>`. Kita bakal ngomongin soal Send di bagian selanjutnya: dia
adalah salah satu trait yang memastikan tipe-tipe yang kita pakai bersama threads
emang ditujukan buat dipakai di situasi yang konkuren.
Sayangnya, Rc<T> tidak aman buat dibagikan antar threads. Saat Rc<T>
mengelola reference count, dia nambahin jumlahnya buat setiap panggilan ke
clone dan ngurangin jumlahnya saat setiap clone di-drop. Tapi dia tidak
memakai concurrency primitives apa pun buat memastikan kalau perubahan pada
jumlah itu tidak diinterupsi sama thread lain. Hal ini bisa menyebabkan
perhitungan (counts) yang salah—bugs halus (subtle bugs) yang pada akhirnya
bisa menyebabkan memory leaks (kebocoran memori) atau sebuah nilai di-drop
sebelum kita selesai memakainya. Apa yang kita butuhkan adalah sebuah tipe
yang persis kayak Rc<T>, tapi yang ngubah jumlah referensinya pakai cara yang
thread-safe (aman di lingkungan utas ganda).
Atomic Reference Counting dengan Arc<T>
Untungnya, Arc<T> adalah tipe yang mirip Rc<T> yang aman buat dipakai di
situasi yang konkuren. Huruf A-nya singkatan dari atomic, yang artinya
dia adalah tipe atomically reference-counted (penghitungan referensi secara
atomik). Atomics adalah jenis primitif konkurensi tambahan yang tidak bakal
kita bahas secara mendetail di sini: cek dokumentasi standard library buat
std::sync::atomic buat detail lebih lanjut. Di titik ini, kita
cuma perlu tahu kalau atomics bekerja kayak tipe primitif biasa tapi aman
buat dibagikan antar threads.
Terus kita mungkin penasaran kenapa tidak semua tipe primitif dibikin jadi
atomic dan kenapa tipe-tipe standard library tidak diimplementasikan buat
memakai Arc<T> secara default. Alasannya adalah keamanan thread (thread
safety) itu datang dengan penalti performa (performance penalty) yang mana
kita cuma mau membayarnya saat kita bener-bener butuh. Kalau kita cuma ngelakuin
operasi pada nilai di dalam satu thread, kode kita bisa berjalan lebih kencang
kalau dia tidak perlu memaksakan jaminan yang disediakan sama atomics.
Mari kembali ke contoh kita: Arc<T> dan Rc<T> punya API yang sama, jadi
kita memperbaiki program kita dengan mengubah baris use, panggilan ke new,
dan panggilan ke clone. Kode di Listing 16-15 akhirnya bakal bisa di-compile
dan jalan.
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
let counter = Arc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Arc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Arc<T> buat ngebungkus Mutex<T> supaya bisa membagikan kepemilikan di beberapa threadsKode ini bakal mencetak output berikut:
Result: 10
Kita berhasil! Kita menghitung dari 0 sampai 10, yang mungkin tidak kelihatan
terlalu mengesankan, tapi itu banyak ngajarin kita soal Mutex<T> dan keamanan
thread. Kita juga bisa memakai struktur program ini buat melakukan operasi
yang lebih rumit ketimbang cuma menaikkan nilai penghitung. Memakai strategi ini,
kita bisa membagi perhitungan jadi bagian-bagian independen, memecah bagian-
bagian itu ke berbagai threads, lalu memakai Mutex<T> agar masing-masing
thread bisa meng-update hasil akhirnya dengan bagian perhitungan mereka.
Perhatikan bahwa kalau kita ngelakuin operasi angka (numerical operations) yang
simpel, ada tipe yang lebih sederhana ketimbang tipe Mutex<T> yang disediakan
sama modul std::sync::atomic di standard library. Tipe-tipe ini
menyediakan akses yang aman, konkuren, dan atomik ke tipe-tipe primitif. Kita
memilih buat memakai Mutex<T> bersama sebuah tipe primitif buat contoh ini
supaya kita bisa berkonsentrasi pada gimana Mutex<T> itu bekerja.
Kesamaan Antara RefCell<T>/Rc<T> dan Mutex<T>/Arc<T>
kita mungkin nyadar kalau counter itu immutable tapi kita bisa dapat sebuah
referensi mutable ke nilai di dalamnya; ini artinya Mutex<T> menyediakan
interior mutability (mutabilitas interior), sama kayak keluarga Cell. Dengan
cara yang sama seperti kita memakai RefCell<T> di Bab 15 buat memungkinkan kita
memutasi isi di dalam sebuah Rc<T>, kita memakai Mutex<T> buat memutasi isi
di dalam sebuah Arc<T>.
Detail lain yang perlu diperhatikan adalah Rust tidak bisa melindungi kita dari
semua jenis logic errors (kutu logika) pas kita memakai Mutex<T>. Ingat
kembali dari Bab 15 kalau memakai Rc<T> punya risiko membikin reference cycles
(siklus referensi), di mana dua nilai Rc<T> merujuk ke satu sama lain, yang
menyebabkan memory leaks. Serupa dengan hal itu, Mutex<T> punya risiko
membikin deadlocks (jalan buntu). Hal ini terjadi pas suatu operasi butuh
mengambil dua locks dan dua threads masing-masing udah ngambil salah satu dari
locks tersebut, yang menyebabkan mereka saling menunggu satu sama lain
selamanya. Kalau kita tertarik sama deadlocks, coba bikin program Rust yang
punya sebuah deadlock; terus cari tahu soal strategi mitigasi deadlock buat
mutexes di bahasa pemrograman apa pun lalu cobalah mengimplementasikan strategi
itu di Rust. Dokumentasi API standard library buat Mutex<T> dan MutexGuard
nawarin informasi yang berguna.
Kita bakal menuntaskan bab ini dengan ngomongin soal trait Send dan Sync
dan gimana cara kita bisa memakainya bersama custom types (tipe kustom).
Konkurensi yang Bisa Diperluas Memakai Send dan Sync
Konkurensi yang Bisa Diperluas (Extensible) dengan Trait Send dan Sync
Yang menarik, hampir semua fitur konkurensi yang udah kita bahas sejauh ini di bab ini adalah bagian dari standard library, bukan bagian dari bahasa Rust itu sendiri. Pilihan kita buat menangani konkurensi tidak cuma terbatas pada apa yang disediakan oleh bahasa atau standard library; kita bisa nulis fitur konkurensi kita sendiri atau memakai yang udah ditulis sama orang lain.
Namun, di antara konsep-konsep konkurensi utama yang tertanam (embedded) di
dalam bahasanya ketimbang di standard library adalah marker traits (trait
penanda) std::marker yaitu Send dan Sync.
Mengizinkan Transfer Kepemilikan Antar Threads dengan Send
Marker trait Send mengindikasikan bahwa kepemilikan (ownership) dari nilai
dengan tipe yang mengimplementasikan Send itu bisa ditransfer antar threads.
Hampir setiap tipe di Rust mengimplementasikan Send, tapi ada beberapa
pengecualian, termasuk Rc<T>: tipe ini tidak bisa mengimplementasikan Send
karena kalau kita meng-clone sebuah nilai Rc<T> lalu mencoba buat mentransfer
kepemilikan dari clone tersebut ke thread lain, kedua threads bisa aja
meng-update reference count di waktu yang bersamaan. Atas alasan inilah,
Rc<T> diimplementasikan buat dipakai di situasi single-threaded di mana kita
tidak mau membayar penalti performa (performance penalty) demi keamanan thread.
Oleh karena itu, sistem tipe dan trait bounds Rust memastikan kalau kita tidak
bakal bisa secara tidak sengaja mengirim nilai Rc<T> melintasi threads
dengan cara yang tidak aman. Pas kita mencoba melakukan ini di Listing 16-14,
kita dapat error the trait `Send` is not implemented for `Rc<Mutex<i32>>`.
Pas kita ganti jadi pakai Arc<T>, yang mana emang mengimplementasikan Send,
kodenya berhasil di-compile.
Tipe apa pun yang secara utuh disusun (composed entirely) dari tipe-tipe yang
mengimplementasikan Send bakal secara otomatis ditandai sebagai Send juga.
Hampir semua tipe primitif itu Send, kecuali untuk raw pointers (pointer
mentah), yang bakal kita bahas di Bab 20.
Mengizinkan Akses dari Banyak Threads dengan Sync
Marker trait Sync mengindikasikan kalau aman buat sebuah tipe yang
mengimplementasikan Sync untuk dirujuk (referenced) dari banyak threads.
Dengan kata lain, tipe T apa pun mengimplementasikan Sync kalau &T
(referensi immutable ke T) mengimplementasikan Send, yang berarti
referensi tersebut bisa dikirim dengan aman ke thread lain. Sama kayak Send,
semua tipe primitif mengimplementasikan Sync, dan tipe-tipe yang secara utuh
disusun dari tipe-tipe yang mengimplementasikan Sync juga bakal mengimplementasikan
Sync.
Smart pointer Rc<T> juga tidak mengimplementasikan Sync dengan alasan yang
sama kayak kenapa dia tidak mengimplementasikan Send. Tipe RefCell<T>
(yang kita bahas di Bab 15) dan keluarga dari tipe Cell<T> yang terkait juga
tidak mengimplementasikan Sync. Implementasi dari borrow checking yang
dilakukan RefCell<T> saat runtime itu tidak thread-safe (tidak aman di
lingkungan banyak utas). Smart pointer Mutex<T> mengimplementasikan Sync
dan bisa dipakai buat berbagi akses dengan banyak threads, seperti yang kita
lihat di “Berbagi Mutex<T> di Antara Beberapa Threads”.
Mengimplementasikan Send dan Sync secara Manual Itu Unsafe (Tidak Aman)
Karena tipe yang secara utuh disusun dari tipe-tipe lain yang mengimplementasikan
trait Send dan Sync itu juga otomatis mengimplementasikan Send dan Sync,
kita tidak perlu mengimplementasikan trait-trait tersebut secara manual. Sebagai
marker traits, mereka bahkan tidak punya method apa pun buat diimplementasikan.
Mereka cuma berguna buat memaksakan (enforcing) aturan baku (invariants) yang
berkaitan dengan konkurensi.
Mengimplementasikan trait-trait ini secara manual melibatkan penulisan kode Rust
yang unsafe. Kita bakal ngomongin soal memakai kode Rust yang unsafe di
Bab 20; buat sekarang, informasi pentingnya adalah bahwa membangun tipe konkuren
baru yang tidak disusun dari bagian-bagian yang Send dan Sync membutuhkan
pemikiran yang ekstra hati-hati buat mempertahankan jaminan keamanannya (safety
guarantees). “The Rustonomicon” punya lebih banyak informasi soal
jaminan-jaminan ini dan gimana cara mempertahankannya.
Ringkasan
Ini bukan terakhir kalinya kita bakal melihat konkurensi di buku ini: bab berikutnya berfokus pada pemrograman async, dan project di Bab 21 bakal memakai konsep-konsep di bab ini di dalam situasi yang lebih realistis ketimbang contoh-contoh kecil yang dibahas di sini.
Seperti yang disebutkan sebelumnya, karena cuma sebagian kecil dari cara Rust menangani konkurensi itu yang menjadi bagian dari bahasanya, banyak solusi konkurensi diimplementasikan dalam bentuk crates. Crate-crate ini berevolusi lebih cepat daripada standard library, jadi pastikan kita mencari secara online buat crates yang paling mutakhir (state-of-the-art) buat dipakai di situasi- situasi multithreaded.
Standard library Rust menyediakan channels buat pengiriman pesan (message
passing) dan tipe-tipe smart pointer, seperti Mutex<T> dan Arc<T>, yang
aman buat dipakai di konteks konkuren. Sistem tipe dan borrow checker memastikan
kalau kode yang memakai solusi-solusi ini tidak bakal berujung pada data races
atau referensi yang tidak valid. Begitu kita berhasil membikin kode kita bisa
di-compile, kita bisa bernapas lega karena dia bakal jalan dengan bahagia di atas
banyak threads tanpa jenis bugs yang susah dilacak kayak yang biasa terjadi
di bahasa pemrograman lain. Pemrograman konkuren bukan lagi konsep yang perlu
ditakutkan: maju terus dan bikin program kita konkuren tanpa rasa takut!
Dasar-dasar Pemrograman Asinkron: Async, Await, Futures, dan Streams
Banyak operasi yang kita suruh komputer buat lakukan bisa memakan waktu agak lama buat selesai. Bakal menyenangkan sekali kalau kita bisa melakukan hal lain selagi kita nungguin proses-proses yang panjang itu buat kelar. Komputer modern menawarkan dua teknik buat mengerjakan lebih dari satu operasi pada satu waktu: paralelisme (parallelism) dan konkurensi (concurrency). Namun, logika program kita biasanya ditulis dengan gaya yang linear. Kita pengen bisa menentukan operasi apa aja yang harus dilakukan program dan titik-titik di mana sebuah fungsi bisa berhenti sejenak (pause) dan bagian lain dari program bisa berjalan sebagai gantinya, tanpa perlu menentukan di awal secara persis urutan dan cara tiap potongan kode itu berjalan. Pemrograman asinkron (asynchronous programming) adalah sebuah abstraksi yang memungkinkan kita mengekspresikan kode kita dalam bentuk titik-titik jeda potensial dan hasil akhirnya, yang mana bakal menangani detail koordinasinya buat kita.
Bab ini dibangun di atas penggunaan threads buat paralelisme dan konkurensi
di Bab 16 dengan memperkenalkan pendekatan alternatif buat nulis kode: futures,
streams, dan sintaks async dan await di Rust yang memungkinkan kita buat
mengekspresikan gimana operasi-operasi tersebut bisa bersifat asinkron, serta
crates pihak ketiga yang mengimplementasikan asynchronous runtimes: kode yang
mengelola dan mengoordinasi eksekusi dari operasi-operasi asinkron tersebut.
Mari kita pertimbangkan sebuah contoh. Katakanlah kita lagi ngekspor video perayaan keluarga yang sudah kita bikin, sebuah operasi yang bisa memakan waktu mulai dari beberapa menit sampai berjam-jam. Ekspor video bakal memakai sebanyak mungkin tenaga CPU dan GPU yang bisa dia dapatkan. Kalau kita cuma punya satu core (inti) CPU dan sistem operasi kita tidak nge-pause ekspor itu sampai ia selesai—yaitu, kalau ia mengeksekusi ekspornya secara sinkron (synchronously)—kita tidak bakal bisa ngelakuin hal lain di komputer kita saat tugas itu berjalan. Itu bakal jadi pengalaman yang cukup bikin frustrasi. Untungnya, sistem operasi di komputer kita bisa, dan emang ngelakuin itu, menginterupsi proses ekspor secara kasatmata cukup sering biar kita bisa mengerjakan tugas lain di saat yang bersamaan.
Sekarang katakanlah kita lagi men-download video yang di-share sama orang lain, yang juga bisa memakan waktu lumayan lama tapi tidak terlalu menyita banyak waktu CPU. Di kasus ini, CPU harus menunggu data dari jaringan buat tiba. Meskipun kita bisa mulai membaca data tersebut begitu dia mulai berdatangan, itu bisa memakan waktu beberapa saat sampai semuanya muncul. Bahkan setelah semua datanya ada, kalau videonya sangat besar, itu bisa memakan waktu setidaknya satu atau dua detik buat nge-load semuanya. Itu mungkin tidak kedengeran terlalu lama, tapi itu adalah waktu yang sangat lama buat prosesor modern, yang mana bisa melakukan miliaran operasi setiap detik. Sekali lagi, sistem operasi kita bakal menginterupsi program kita secara kasatmata buat membiarkan CPU mengerjakan tugas lain sembari nunggu pemanggilan jaringan selesai.
Ekspor video adalah contoh dari operasi CPU-bound atau compute-bound (bergantung pada prosesor). Dia dibatasi oleh potensi kecepatan pemrosesan data komputer di dalam CPU atau GPU, dan seberapa besar dari kecepatan itu yang bisa didedikasikan buat operasi tersebut. Download video adalah contoh dari operasi I/O-bound (bergantung pada input-output), karena dia dibatasi oleh kecepatan input dan output komputer; dia cuma bisa berjalan secepat data yang bisa dikirim lewat jaringan.
Di dua contoh ini, interupsi kasatmata dari sistem operasi ngasih suatu bentuk konkurensi. Namun, konkurensi itu cuma terjadi di tingkat keseluruhan program: sistem operasi menginterupsi satu program buat membiarkan program lain mengerjakan tugasnya. Di banyak kasus, karena kita paham program kita di tingkat yang jauh lebih spesifik (granular) ketimbang sistem operasi, kita bisa menemukan peluang-peluang buat konkurensi yang tidak bisa dilihat sama sistem operasi.
Misalnya, kalau kita lagi bikin tool buat mengelola download file, kita seharusnya bisa menulis program kita sedemikian rupa sehingga pas mulai nge-download satu file UI-nya tidak bakal macet (lock up), dan user seharusnya bisa memulai banyak download di saat yang bersamaan. Namun, banyak API sistem operasi buat berinteraksi dengan jaringan itu sifatnya blocking (memblokir); yakni, mereka memblokir progress program sampai data yang mereka proses itu benar-benar siap seutuhnya.
Catatan: Ini adalah cara kerja kebanyakan pemanggilan fungsi, kalau dipikir-pikir. Namun, istilah blocking biasanya dikhususkan buat pemanggilan fungsi yang berinteraksi dengan file, jaringan, atau sumber daya lain di komputer, karena itu adalah kasus-kasus di mana suatu program individu bakal dapat keuntungan kalau operasi tersebut non-blocking.
Kita bisa menghindari memblokir main thread kita dengan membikin sebuah thread khusus buat men-download tiap file. Namun, beban (overhead) dari sumber daya sistem yang dipakai sama threads itu pada akhirnya bakal jadi masalah. Bakal lebih oke kalau pemanggilan fungsinya dari awal emang tidak memblokir, dan sebaliknya kita bisa menentukan sejumlah tugas yang pengen diselesaikan program kita lalu membiarkan runtime memilih urutan dan cara terbaik buat menjalankannya.
Nah, itulah persisnya yang dikasih sama abstraksi asinkron (singkatan dari async) di Rust buat kita. Di bab ini, kita bakal belajar semua hal tentang asinkron selagi kita membahas topik-topik berikut:
- Gimana cara memakai sintaks
asyncdanawaitdi Rust dan mengeksekusi fungsi-fungsi asinkron dengan sebuah runtime - Gimana cara memakai model asinkron buat nyelesein beberapa tantangan yang sama seperti yang udah kita lihat di Bab 16
- Gimana multithreading dan asinkron menyediakan solusi yang saling melengkapi, yang bisa kita gabungkan di banyak kasus
Tapi, sebelum kita lihat gimana cara kerja asinkron di praktiknya, kita perlu sedikit belok sebentar buat ngebahas perbedaan antara paralelisme dan konkurensi.
Paralelisme dan Konkurensi
Sejauh ini kita memperlakukan paralelisme dan konkurensi seolah-olah maknanya bisa ditukar-tukar. Sekarang kita harus bisa membedakannya dengan lebih presisi, karena perbedaannya bakal kerasa pas kita udah mulai bekerja.
Bayangin aja cara-cara beda yang bisa dipakai sebuah tim buat ngebagi kerjaan di suatu proyek software. Kita bisa menugaskan satu orang beberapa tugas, menugaskan tiap anggota satu tugas, atau memakai campuran dari kedua pendekatan tersebut.
Saat satu orang individu mengerjakan beberapa tugas yang berbeda sebelum satupun dari tugas-tugas itu selesai, ini dinamakan konkurensi. Salah satu cara buat mengimplementasikan konkurensi adalah mirip kayak punya dua project berbeda yang lagi dibuka di komputer kita, dan pas kita bosan atau mentok di satu project, kita beralih ke project yang satu lagi. Kita cuma satu orang, jadi kita tidak bisa bikin progress di kedua tugas pada waktu yang sama persis, tapi kita bisa multitask, bikin progress pada satu tugas secara bergantian dengan beralih di antara mereka (lihat Gambar 17-1).

Saat sebuah tim membagi sekelompok tugas dengan nyuruh setiap anggota mengambil satu tugas lalu mengerjakannya sendirian, ini dinamakan paralelisme. Setiap orang di tim tersebut bisa membikin progress pada waktu yang sama persis (lihat Gambar 17-2).

Di kedua alur kerja (workflows) ini, kita mungkin harus mengoordinasikan antara tugas-tugas yang berbeda. Mungkin kita pikir tugas yang diberikan ke satu orang itu benar-benar independen dari pekerjaan orang lain, tapi ternyata dia butuh orang lain di tim itu buat nyelesein tugas mereka lebih dulu. Beberapa pekerjaan bisa dilakukan secara paralel, tapi sebagian darinya itu sebenarnya serial: dia cuma bisa terjadi dalam satu urutan, satu tugas setelah tugas lainnya, kayak di Gambar 17-3.

Sama halnya, kita mungkin sadar kalau salah satu tugas kita sendiri itu bergantung sama tugas kita yang lainnya. Sekarang pekerjaan konkuren kita juga udah jadi serial.
Paralelisme dan konkurensi juga bisa bersinggungan satu sama lain. Kalau kita tahu kalau rekan kerja kita lagi mentok sampai kita nyelesein salah satu tugas kita, kita mungkin bakal memusatkan seluruh usaha kita pada tugas itu buat “membuka jalan” (unblock) rekan kerja kita tersebut. Kita dan rekan kerja kita tidak lagi bisa bekerja secara paralel, dan kita juga tidak lagi bisa bekerja secara konkuren di tugas kita masing-masing.
Dinamika dasar yang sama mulai berlaku pada perangkat lunak dan perangkat keras. Di mesin yang punya satu core CPU, CPU cuma bisa melakukan satu operasi pada satu waktu, tapi dia tetap bisa bekerja secara konkuren. Memakai alat seperti threads, proses, dan asinkron, komputer bisa mem-pause satu aktivitas lalu beralih ke aktivitas lain sebelum akhirnya berputar kembali ke aktivitas pertama tadi. Di mesin dengan banyak core CPU, dia juga bisa mengerjakan tugas secara paralel. Satu core bisa ngerjain satu tugas sementara core lain ngerjain tugas yang sama sekali tidak ada hubungannya, dan operasi-operasi itu benar-benar terjadi pada waktu yang bersamaan.
Menjalankan kode asinkron di Rust biasanya terjadi secara konkuren. Tergantung pada perangkat keras, sistem operasi, dan async runtime yang lagi kita pakai (async runtimes bakal dibahas sebentar lagi), konkurensi itu mungkin juga memakai paralelisme di balik layar.
Sekarang, mari kita selami gimana cara kerja pemrograman asinkron di Rust sebenarnya.
Futures dan Sintaks Async
Futures dan Sintaks Async
Elemen kunci dari pemrograman asinkron di Rust adalah futures dan keyword
async dan await milik Rust.
Sebuah future adalah nilai yang mungkin belum siap sekarang tapi bakal jadi
siap di suatu waktu di masa depan. (Konsep yang sama ini juga muncul di banyak
bahasa lain, kadang-kadang pakai nama lain kayak task atau promise.) Rust
menyediakan trait Future sebagai blok penyusun supaya berbagai operasi asinkron
bisa diimplementasikan pakai struktur data yang berbeda-beda tapi dengan
antarmuka (interface) yang sama. Di Rust, futures adalah tipe-tipe yang
mengimplementasikan trait Future. Tiap future menyimpan informasinya sendiri
soal sejauh mana kemajuan yang sudah dibuat dan apa makna dari “siap” (“ready”).
Kita bisa menerapkan keyword async ke blok dan fungsi buat menentukan kalau
mereka bisa diinterupsi dan dilanjutkan lagi. Di dalam sebuah blok asinkron atau
fungsi asinkron, kita bisa memakai keyword await buat menunggu sebuah future
(yaitu, nunggu dia sampai jadi siap). Titik mana pun di mana kita me-await
sebuah future di dalam sebuah blok atau fungsi asinkron adalah titik potensial
buat blok atau fungsi asinkron itu buat berhenti sejenak (pause) dan dilanjutkan
lagi (resume). Proses pengecekan ke sebuah future buat melihat apakah nilainya
sudah tersedia atau belum ini disebut polling.
Beberapa bahasa pemrograman lain, kayak C# dan JavaScript, juga memakai keyword
async dan await buat pemrograman asinkron. Kalau kita sudah familier sama
bahasa-bahasa itu, kita mungkin bakal sadar ada beberapa perbedaan signifikan
dari cara Rust melakukan hal tersebut, termasuk cara nanganin sintaksnya. Itu ada
alasan bagusnya lho, kayak yang bakal kita lihat nanti!
Pas lagi nulis Rust asinkron, kita bakal memakai keyword async dan await
sebagian besar waktunya. Rust mengompilasi mereka jadi kode yang ekuivalen
menggunakan trait Future, mirip kayak gimana dia mengompilasi for loops jadi
kode yang ekuivalen memakai trait Iterator. Tapi karena Rust menyediakan trait
Future, kita juga bisa mengimplementasikannya buat tipe data kita sendiri
kalau kita butuh. Banyak fungsi yang bakal kita lihat di sepanjang bab ini
mengembalikan tipe yang punya implementasi Future-nya masing-masing. Kita bakal
balik lagi ke definisi trait-nya di akhir bab ini dan gali lebih dalam soal
gimana cara kerjanya, tapi detail segini sudah cukup buat kita lanjut jalan dulu.
Ini semua mungkin terasa agak abstrak, jadi mari kita tulis program asinkron pertama kita: sebuah web scraper mini. Kita bakal memasukkan dua URL dari command line, mengambil (fetch) kedua URL itu secara konkuren, terus mengembalikan hasil dari URL mana pun yang selesai duluan. Contoh ini bakal punya lumayan banyak sintaks baru, tapi jangan khawatir—kita bakal jelasin semua yang perlu kita tahu seiring kita berjalan.
Program Asinkron Pertama Kita
Biar fokus bab ini tetap pada belajar asinkron ketimbang sibuk ngerjain bagian-
bagian ekosistem, kita sudah ngebikin crate trpl (trpl itu singkatan dari
“The Rust Programming Language”). Crate ini mengekspor ulang (re-exports) semua
tipe, trait, dan fungsi yang bakal kita butuhkan, utamanya dari crate
futures dan tokio.
Crate futures adalah tempat resmi buat bereksperimen dengan kode asinkron di
Rust, dan sebenarnya di sanalah trait Future asal-muasalnya didesain. Tokio
adalah async runtime yang paling banyak dipakai di Rust saat ini, apalagi buat
aplikasi web. Ada banyak runtimes keren lainnya di luar sana, dan mereka
mungkin lebih cocok buat kebutuhan kita. Kita memakai crate tokio di balik
layarnya trpl karena dia sudah teruji dengan baik dan banyak dipakai.
Di beberapa kasus, trpl juga mengganti nama atau membungkus (wraps) API aslinya
biar kita tetap fokus sama detail-detail yang relevan buat bab ini. Kalau kita
mau paham apa yang dilakukan sama crate ini, kita menyarankan kita buat cek
source code-nya. Kita bakal bisa lihat dari crate mana asal
dari tiap fitur yang di-re-export, dan kita sudah ninggalin komentar yang
ekstensif yang menjelaskan apa aja yang dilakukan sama crate tersebut.
Bikin sebuah project binary baru bernama hello-async dan tambahkan crate
trpl sebagai dependensi:
$ cargo new hello-async
$ cd hello-async
$ cargo add trpl
Sekarang kita bisa pakai berbagai potongan yang disediakan sama trpl buat
nulis program asinkron pertama kita. Kita bakal bikin alat command line mini
yang mengambil dua halaman web, menarik elemen <title> dari masing-masing
halaman, terus mencetak judul dari halaman mana pun yang menyelesaikan seluruh
proses tersebut paling duluan.
Mendefinisikan Fungsi page_title
Mari mulai dengan nulis fungsi yang menerima satu URL halaman sebagai parameternya, melakukan request ke sana, dan mengembalikan teks dari elemen judulnya (lihat Listing 17-1).
extern crate trpl; // required for mdbook test
fn main() {
// TODO: we'll add this next!
}
use trpl::Html;
async fn page_title(url: &str) -> Option<String> {
let response = trpl::get(url).await;
let response_text = response.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}Pertama, kita mendefinisikan sebuah fungsi bernama page_title dan menandainya
pakai keyword async. Terus kita pakai fungsi trpl::get buat mengambil
URL apa pun yang dimasukkan dan menambahkan keyword await buat menunggu
responsnya. Buat dapat teks dari respons tersebut, kita memanggil method text-
nya, dan sekali lagi menunggunya dengan keyword await. Kedua langkah ini
sifatnya asinkron. Buat fungsi get, kita harus nunggu server buat mengirim
balik bagian pertama dari responsnya, yang mana bakal berisi HTTP headers,
cookies, dan lain-lain, dan bisa saja dikirim secara terpisah dari body
(isi utama) responsnya. Apalagi kalau body-nya itu besar sekali, itu bisa
memakan waktu yang lumayan lama buat semuanya sampai. Karena kita harus nunggu
buat keseluruhan responsnya sampai, method text itu juga asinkron.
Kita harus secara eksplisit menunggu kedua futures ini, karena futures di
Rust itu lazy (malas): mereka tidak bakal melakukan apa-apa sampai kita
menyuruh mereka dengan keyword await. (Faktanya, Rust bakal mengeluarkan
peringatan compiler kalau kita tidak menunggu sebuah future.) Ini mungkin
mengingatkan kita soal pembahasan iterator di Bab 13 di bagian “Memproses
Serangkaian Item dengan Iterator”. Iterator
tidak bakal melakukan apa-apa kecuali kalau kita memanggil method next-nya—baik
itu secara langsung atau dengan memakai for loops atau method-method kayak
map yang memakai next di balik layarnya. Demikian juga, futures tidak
bakal melakukan apa-apa kecuali kita menyuruh mereka secara eksplisit. Sifat
malas ini membolehkan Rust menghindari menjalankan kode asinkron sampai dia
bener-bener dibutuhkan.
Catatan: Ini berbeda dari perilaku yang kita lihat di Bab 16 saat memakai
thread::spawndi “Membikin Thread Baru dengan spawn”<!–ignore –>, di mana closure yang kita kasih ke thread lain itu langsung mulai berjalan. Ini juga beda dari cara banyak bahasa lain melakukan pendekatan ke asinkron. Tapi penting buat Rust buat bisa ngasih jaminan performanya, sama halnya dengan iterator.
Begitu kita dapet response_text, kita bisa menguraikan (parse) nilainya jadi
sebuah instance dari tipe Html menggunakan Html::parse. Daripada pakai
string mentah, sekarang kita punya sebuah tipe data yang bisa kita pakai buat
mengolah HTML tersebut sebagai struktur data yang lebih kaya. Secara spesifik,
kita bisa pakai method select_first buat menemukan instance pertama dari CSS
selector yang kita kasih. Dengan memasukkan string "title", kita bakal dapet
elemen <title> pertama di dokumen tersebut, kalau memang ada. Karena mungkin
saja nggak ada elemen yang cocok, select_first mengembalikan Option<ElementRef>.
Terakhir, kita memakai method Option::map, yang membolehkan kita beroperasi
pada item di dalam Option kalau itemnya ada, dan tidak melakukan apa-apa
kalau itemnya nggak ada. (Kita juga bisa saja pakai ekspresi match di sini,
tapi map itu lebih idiomatik.) Di dalam isi fungsi yang kita berikan ke map,
kita memanggil inner_html pada title buat mendapatkan kontennya, yang mana
adalah sebuah String. Pada akhirnya, kita punya sebuah Option<String>.
Perhatikan bahwa keyword await di Rust ditaruh setelah ekspresi yang lagi
kita tungguin, bukan di sebelumnya. Yakni, ia adalah sebuah keyword postfix
(akhiran). Ini mungkin beda dari apa yang biasa kita jumpai kalau kita pernah
memakai async di bahasa lain, tapi di Rust ini bikin chaining (rentetan)
pemanggilan method jadi jauh lebih enak buat dibuat. Hasilnya, kita bisa
mengubah isi dari page_title buat menyambung (chain) pemanggilan fungsi
trpl::get dan text sekaligus pakai await di antara mereka, kayak yang
ditunjukkan di Listing 17-2.
extern crate trpl; // required for mdbook test
use trpl::Html;
fn main() {
// TODO: we'll add this next!
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}awaitSelesai deh, kita sudah berhasil menulis fungsi asinkron pertama kita! Sebelum
kita nambahin beberapa kode di main buat manggil dia, mari kita ngomongin
lebih lanjut soal apa yang sudah kita tulis ini dan apa maknanya.
Pas Rust melihat ada blok yang ditandai pakai keyword async, dia
mengompilasinya jadi tipe data anonim unik yang mengimplementasikan trait
Future. Pas Rust melihat fungsi ditandai pakai async, dia mengompilasinya
jadi fungsi non-asinkron yang isinya merupakan sebuah blok asinkron. Tipe
kembalian fungsi asinkron adalah tipe dari tipe data anonim yang dibuat sama
compiler buat blok asinkron tersebut.
Jadi, menulis async fn itu ekuivalen (sama aja) kayak menulis fungsi yang
mengembalikan sebuah future dari tipe kembaliannya. Bagi compiler, definisi
fungsi kayak async fn page_title di Listing 17-1 itu kira-kira ekuivalen
sama fungsi non-asinkron yang didefinisikan kayak gini:
#![allow(unused)]
fn main() {
extern crate trpl; // required for mdbook test
use std::future::Future;
use trpl::Html;
fn page_title(url: &str) -> impl Future<Output = Option<String>> {
async move {
let text = trpl::get(url).await.text().await;
Html::parse(&text)
.select_first("title")
.map(|title| title.inner_html())
}
}
}Mari kita telusuri bagian demi bagian dari versi yang sudah diubah ini:
- Dia memakai sintaks
impl Traityang sudah kita bahas dulu di Bab 10 di bagian “Traits sebagai Parameter”. - Nilai yang dikembalikan mengimplementasikan trait
Futuredengan associated typeOutput. Perhatikan bahwa tipeOutput-nya adalahOption<String>, yang mana sama dengan tipe kembalian asli dari versiasync fnsipage_title. - Semua kode yang dipanggil di dalam isi dari fungsi aslinya dibungkus di dalam
sebuah blok
async move. Ingat kembali kalau blok itu adalah ekspresi. Keseluruhan blok ini adalah ekspresi yang dikembalikan dari fungsinya. - Blok asinkron ini menghasilkan nilai bertipe
Option<String>, seperti yang baru saja dijelaskan. Nilai tersebut cocok sama tipeOutputdi tipe kembaliannya. Ini sama persis kayak blok-blok lain yang pernah kita lihat. - Isi fungsi baru tersebut adalah sebuah blok
async movegara-gara gimana dia memakai parameterurl. (Kita bakal ngebahas lebih banyak lagi soalasyncversusasync movenanti di bab ini.)
Sekarang kita bisa memanggil page_title di main.
Mengeksekusi Fungsi Asinkron dengan sebuah Runtime
Sebagai awalan, kita cuma bakal mengambil judul buat satu halaman saja, yang ditunjukkan di Listing 17-3. Sayangnya, kode ini belum bisa di-compile.
extern crate trpl; // required for mdbook test
use trpl::Html;
async fn main() {
let args: Vec<String> = std::env::args().collect();
let url = &args[1];
match page_title(url).await {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}page_title dari main memakai argumen yang dikasih sama userKita mengikuti pola yang sama yang kita pakai buat dapat argumen command line
di Bab 12 di bagian “Menerima Argumen Command Line”.
Terus kita mengoper URL pertamanya ke page_title dan menunggu hasilnya.
Karena nilai yang dihasilkan oleh future tersebut adalah sebuah
Option<String>, kita memakai ekspresi match buat mencetak pesan yang beda-
beda dengan memperhitungkan apakah halamannya punya <title> atau tidak.
Satu-satunya tempat di mana kita bisa memakai keyword await adalah di dalam
fungsi atau blok asinkron, dan Rust tidak bakal membolehkan kita menandai
fungsi spesial main sebagai async.
error[E0752]: `main` function is not allowed to be `async`
--> src/main.rs:6:1
|
6 | async fn main() {
| ^^^^^^^^^^^^^^^ `main` function is not allowed to be `async`
Alasan main tidak bisa ditandai async adalah karena kode asinkron itu
butuh sebuah runtime: sebuah crate Rust yang mengelola detail eksekusi kode
asinkron. Fungsi main di sebuah program bisa menginisialisasi (initialize)
sebuah runtime, tapi fungsi main itu bukanlah sebuah runtime itu sendiri.
(Kita bakal lihat lebih lanjut soal kenapa ini terjadi sebentar lagi.) Setiap
program Rust yang mengeksekusi kode asinkron punya minimal satu tempat di mana
dia menyiapkan sebuah runtime yang mengeksekusi futures-nya.
Kebanyakan bahasa yang mendukung asinkron sudah membundel sebuah runtime bawaan, tapi Rust tidak begitu. Sebaliknya, ada banyak async runtimes berbeda yang tersedia, di mana masing-masing membikin tradeoffs (pertukaran) yang cocok buat kasus penggunaan yang jadi targetnya. Misalnya, web server yang high-throughput (kemampuan transmisi besar) dengan banyak core CPU dan RAM dalam jumlah besar punya kebutuhan yang sangat berbeda dari mikrokontroler dengan single core, jumlah RAM yang kecil, dan tidak punya kemampuan alokasi heap sama sekali. Crate yang menyediakan runtimes ini juga sering kali memberikan versi asinkron dari fungsionalitas umum kayak I/O file atau jaringan.
Di sini, dan di sepanjang sisa bab ini, kita bakal memakai fungsi block_on
dari crate trpl, yang mana menerima sebuah future sebagai argumen dan
memblokir thread saat ini sampai future tersebut berjalan hingga selesai.
Di balik layar, memanggil block_on menyiapkan sebuah runtime menggunakan
crate tokio yang dipakai buat menjalankan future yang diberikan (perilaku
block_on dari crate trpl ini mirip dengan fungsi block_on milik crate
runtime lainnya). Setelah future tersebut selesai, block_on bakal
mengembalikan nilai apa pun yang dihasilkan oleh future itu.
Kita bisa saja meneruskan future yang dikembalikan sama page_title langsung
ke block_on dan, begitu selesai, kita bisa melakukan match pada
Option<String> hasilnya, kayak yang sudah kita coba lakukan di Listing 17-3.
Tapi, buat mayoritas contoh di bab ini (dan mayoritas kode asinkron di dunia
nyata), kita bakal melakukan lebih dari sekadar satu pemanggilan fungsi
asinkron saja, jadi alih-alih begitu kita bakal meneruskan sebuah blok async
lalu secara eksplisit menunggu hasil dari panggilan page_title, seperti di
Listing 17-4.
extern crate trpl; // required for mdbook test
use trpl::Html;
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::block_on(async {
let url = &args[1];
match page_title(url).await {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
})
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}trpl::block_onPas kita jalankan kode ini, kita dapet perilaku kayak yang kita harapkan di awal:
$ cargo run -- "https://www.rust-lang.org"
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.05s
Running `target/debug/async_await 'https://www.rust-lang.org'`
The title for https://www.rust-lang.org was
Rust Programming Language
Fiuh—akhirnya kita punya kode asinkron yang jalan! Tapi sebelum kita nambahin kode buat mengadu (race) kedua situs web itu satu sama lain, mari kita alihkan sejenak perhatian kita kembali ke gimana futures itu bekerja.
Setiap await point (titik penantian)—yakni, setiap tempat di mana kodenya
memakai keyword await—merepresentasikan sebuah tempat di mana kontrol
dikembalikan ke runtime. Biar itu bisa terjadi, Rust perlu melacak (keep
track of) state (keadaan) yang terlibat di dalam blok asinkron tersebut
sehingga runtime bisa memulai beberapa pekerjaan lain lalu balik lagi nanti
kalau dia sudah siap buat mencoba melanjutkan pekerjaan pertama tadi. Ini
adalah sebuah state machine (mesin keadaan) kasatmata, seolah-olah kita
menulis sebuah enum kayak gini buat menyimpan state saat ini di tiap titik
await:
#![allow(unused)]
fn main() {
extern crate trpl; // required for mdbook test
enum PageTitleFuture<'a> {
Initial { url: &'a str },
GetAwaitPoint { url: &'a str },
TextAwaitPoint { response: trpl::Response },
}
}Menulis kode buat bertransisi di antara setiap state ini secara manual bakal melelahkan dan gampang rawan error, apalagi kalau nanti kita harus menambahkan fungsionalitas dan lebih banyak states lagi ke kode tersebut. Untungnya, compiler Rust otomatis membikin dan mengelola struktur data state machine buat kode asinkron. Aturan-aturan borrowing dan ownership normal seputar struktur data itu tetap berlaku semua, dan syukurnya, compiler juga menangani pengecekan itu buat kita dan menyediakan pesan error yang berguna. Kita bakal membedah beberapa kasus kayak gitu nanti di bab ini.
Pada akhirnya, sesuatu harus mengeksekusi state machine ini, dan “sesuatu” itu adalah sebuah runtime. (Inilah kenapa kita mungkin pernah ketemu istilah executors (pengeksekusi) pas lagi nyari tahu soal runtimes: sebuah executor adalah bagian dari sebuah runtime yang bertugas mengeksekusi kode asinkron tersebut.)
Sekarang kita bisa tahu kenapa compiler melarang kita membikin main itu
sendiri jadi fungsi asinkron balik di Listing 17-3 tadi. Kalau main itu fungsi
asinkron, sesuatu yang lain bakal harus mengelola state machine buat future
apa pun yang dikembalikan sama main, tapi padahal main adalah titik awal
buat programnya! Sebaliknya, kita memanggil fungsi trpl::block_on di main
buat menyiapkan sebuah runtime dan menjalankan future yang dikembalikan
sama blok async sampai dia selesai.
Catatan: Beberapa runtimes menyediakan macros sehingga kita bisa menulis fungsi
mainyang asinkron. Macros itu menulis ulangasync fn main() { ... }jadifn mainnormal, yang melakukan persis hal yang sama kayak yang kita lakukan secara manual di Listing 17-4: memanggil fungsi yang mengeksekusi sebuah future sampai selesai kayak yang dilakukan samatrpl::block_on.
Sekarang mari kita gabungkan bagian-bagian ini dan lihat gimana kita bisa menulis kode konkuren.
Menandingkan (Racing) Dua URL Secara Konkuren
Di Listing 17-5, kita memanggil page_title dengan dua URL berbeda yang
dimasukkan dari command line lalu mengadu (race) mereka berdua dengan
memilih future mana pun yang selesai duluan.
extern crate trpl; // required for mdbook test
use trpl::{Either, Html};
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::block_on(async {
let title_fut_1 = page_title(&args[1]);
let title_fut_2 = page_title(&args[2]);
let (url, maybe_title) =
match trpl::select(title_fut_1, title_fut_2).await {
Either::Left(left) => left,
Either::Right(right) => right,
};
println!("{url} returned first");
match maybe_title {
Some(title) => println!("Its page title was: '{title}'"),
None => println!("It had no title."),
}
})
}
async fn page_title(url: &str) -> (&str, Option<String>) {
let response_text = trpl::get(url).await.text().await;
let title = Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html());
(url, title)
}page_title buat dua URL untuk melihat mana yang kembali duluanKita mulai dengan memanggil page_title buat tiap URL yang dikasih sama user.
Kita simpan futures hasilnya sebagai title_fut_1 dan title_fut_2. Ingat,
mereka ini belum melakukan apa-apa, karena futures itu sifatnya malas dan
kita belum menunggunya. Terus kita mengoper futures tersebut ke
trpl::select, yang mengembalikan sebuah nilai buat mengindikasikan future
mana yang selesai duluan di antara yang dioper kepadanya.
Catatan: Di balik layar,
trpl::selectdibangun di atas fungsiselectyang lebih umum yang didefinisikan di cratefutures. Fungsiselectmilik cratefuturesbisa melakukan banyak hal yang fungsitrpl::selecttidak bisa, tapi dia juga punya kerumitan ekstra yang bisa kita lewati dulu buat sekarang.
Masing-masing future bisa saja “menang,” jadi tidak masuk akal kalau kita
mengembalikan Result. Alih-alih begitu, trpl::select mengembalikan sebuah
tipe yang belum pernah kita lihat sebelumnya, yaitu trpl::Either. Tipe
Either itu agak mirip sama Result dalam hal dia punya dua kasus. Bedanya
sama Result, tidak ada konsep “sukses” atau “gagal” yang tertanam di dalam
Either. Alih-alih begitu, dia memakai Left (kiri) dan Right (kanan) buat
mengindikasikan “yang satu atau yang lainnya”:
#![allow(unused)]
fn main() {
enum Either<A, B> {
Left(A),
Right(B),
}
}Fungsi select mengembalikan Left yang berisi output dari future tersebut
kalau argumen pertama menang, dan Right yang berisi output future kedua
kalau yang itu yang menang. Ini cocok dengan urutan munculnya argumen-argumen
tersebut saat memanggil fungsinya: argumen pertama ada di kiri argumen kedua.
Kita juga memperbarui page_title buat mengembalikan URL yang sama dengan yang
dimasukkan. Dengan begitu, kalau halaman yang kembali duluan tidak punya
<title> yang bisa kita uraikan, kita masih bisa mencetak pesan yang bermakna.
Dengan informasi yang sudah tersedia itu, kita selesaikan ini semua dengan
mengubah output println! kita buat mengindikasikan baik URL mana yang selesai
duluan, dan apa, kalau memang ada, <title> buat halaman web di URL tersebut.
Kita sudah ngebikin web scraper mini yang bisa jalan sekarang! Silakan pilih beberapa URL lalu jalankan alat command line kita. Kita mungkin mendapati kalau beberapa situs secara konsisten memang lebih kencang dibanding yang lain, sementara di kasus lain situs yang kencang itu berubah-ubah di tiap jalan. Yang lebih penting, kita sudah belajar dasar-dasar dari bekerja dengan futures, jadi sekarang kita bisa gali lebih dalam soal apa yang bisa kita lakukan dengan asinkron.
Menerapkan Konkurensi dengan Async
Menerapkan Konkurensi dengan Async
Di bagian ini, kita bakal menerapkan asinkron ke beberapa tantangan konkurensi yang sama dengan yang sudah kita tangani memakai threads di Bab 16. Karena kita sudah banyak ngomongin ide-ide kuncinya di sana, di bagian ini kita bakal fokus sama apa aja yang berbeda antara threads dan futures.
Di banyak kasus, API buat bekerja bareng konkurensi memakai asinkron itu mirip sekali sama yang dipakai buat threads. Di kasus lain, mereka jadinya lumayan berbeda. Bahkan kalau API-nya kelihatan mirip antara threads dan asinkron, mereka sering kali punya perilaku yang berbeda—dan mereka hampir selalu punya karakteristik performa yang berbeda.
Membikin Task (Tugas) Baru dengan spawn_task
Operasi pertama yang kita tangani di bagian “Membikin Thread Baru dengan
spawn” di Bab 16 adalah menghitung angka di dua
threads terpisah. Mari kita lakukan hal yang sama memakai asinkron. Crate
trpl menyediakan fungsi spawn_task yang kelihatannya mirip sekali sama API
thread::spawn, dan fungsi sleep yang merupakan versi asinkron dari API
thread::sleep. Kita bisa memakai keduanya bersama-sama buat
mengimplementasikan contoh penghitungan angka tersebut, kayak yang ditunjukkan
di Listing 17-6.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
trpl::spawn_task(async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
}Sebagai titik awal, kita menyiapkan fungsi main kita pakai trpl::block_on
supaya fungsi tingkat teratas kita bisa bersifat asinkron.
Catatan: Mulai dari titik ini di bab ini, setiap contoh bakal menyertakan kode pembungkus yang sama persis pakai
trpl::block_ondimain, jadi kita bakal sering mengabaikannya (skip) sama seperti kita mengabaikanmain. Jangan lupa buat menyertakannya di dalam kode kita ya!
Terus kita menulis dua loops di dalam blok tersebut, masing-masing mengandung
pemanggilan trpl::sleep, yang bakal nunggu selama setengah detik (500
milidetik) sebelum mengirim pesan berikutnya. Kita menaruh satu loop di dalam
isi dari trpl::spawn_task dan satu lagi di dalam loop for tingkat teratas.
Kita juga nambahin await setelah pemanggilan sleep.
Kode ini berperilaku mirip sama implementasi berbasis thread—termasuk fakta bahwa kita mungkin bakal melihat pesan-pesannya muncul dalam urutan yang berbeda di terminal kita pas kita menjalankannya:
hi number 1 from the second task!
hi number 1 from the first task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
Versi ini bakal berhenti begitu loop for di dalam isi blok asinkron utamanya
selesai, karena task yang ditelurkan sama spawn_task bakal dimatikan pas
fungsi main berakhir. Kalau kita pengen task tersebut jalan sampai kelar,
kita perlu memakai join handle buat nungguin task pertamanya selesai. Pas
pakai threads, kita memakai method join buat “memblokir” sampai thread-nya
selesai jalan. Di Listing 17-7, kita bisa memakai await buat ngelakuin hal yang
sama, karena task handle itu sendiri adalah sebuah future. Tipe Output-nya
adalah sebuah Result, jadi kita juga meng-unwrap-nya setelah me-await-nya.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let handle = trpl::spawn_task(async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
handle.await.unwrap();
});
}await bersama join handle buat menjalankan task sampai selesaiVersi yang sudah di-update ini bakal jalan sampai kedua loops selesai:
hi number 1 from the second task!
hi number 1 from the first task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
hi number 6 from the first task!
hi number 7 from the first task!
hi number 8 from the first task!
hi number 9 from the first task!
Sejauh ini, kelihatannya asinkron dan threads ngasih kita hasil yang mirip,
cuma beda di sintaksnya aja: memakai await ketimbang memanggil join pada
join handle, dan me-await pemanggilan sleep.
Perbedaan besarnya adalah kita tidak perlu menelurkan (spawn) thread sistem
operasi lainnya buat melakukan hal ini. Faktanya, kita bahkan tidak perlu
menelurkan sebuah task di sini. Karena blok asinkron dikompilasi jadi
futures anonim, kita bisa menaruh tiap loop di dalam blok asinkron lalu
menyuruh runtime menjalankan keduanya sampai selesai memakai fungsi
trpl::join.
Di bagian “Menunggu Semua Thread sampai Selesai”
di Bab 16, kita menunjukkan gimana cara memakai method join pada tipe
JoinHandle yang dikembalikan pas kita memanggil std::thread::spawn. Fungsi
trpl::join itu mirip, tapi buat futures. Pas kita ngasih dia dua futures,
dia bakal memproduksi satu future baru yang output-nya adalah sebuah tuple
berisi output dari tiap future yang kita masukkan tadi begitu keduanya
selesai. Jadi, di Listing 17-8, kita memakai trpl::join buat nungguin baik
fut1 maupun fut2 sampai selesai. Kita tidak me-await fut1 dan fut2
melainkan me-await future baru yang dihasilkan sama trpl::join. Kita
ngabaiin output-nya, karena dia cuma sebuah tuple berisi dua nilai unit.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let fut1 = async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
};
let fut2 = async {
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
};
trpl::join(fut1, fut2).await;
});
}trpl::join buat menunggu dua futures anonimPas kita jalankan ini, kita melihat kedua futures jalan sampai selesai:
hi number 1 from the first task!
hi number 1 from the second task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
hi number 6 from the first task!
hi number 7 from the first task!
hi number 8 from the first task!
hi number 9 from the first task!
Nah, kita bakal melihat urutan yang sama persis di tiap jalannya, yang mana
berbeda sekali sama apa yang kita lihat di threads dan di trpl::spawn_task
di Listing 17-7. Itu gara-gara fungsi trpl::join ini sifatnya adil (fair),
yang artinya dia mengecek tiap future dengan frekuensi yang sama, ganti-
gantian di antara mereka, dan tidak pernah membiarkan satu pun balapan (race)
mendahului yang lain kalau yang lainnya juga sudah siap. Kalau pakai threads,
sistem operasilah yang menentukan thread mana yang mau dicek dan seberapa
lama dia dibiarkan jalan. Kalau di Rust asinkron, runtime-lah yang menentukan
task mana yang mau dicek. (Di praktiknya, detail-detailnya jadi rumit karena
sebuah async runtime mungkin memakai threads sistem operasi di balik layar
sebagai bagian dari caranya mengelola konkurensi, jadi menjamin keadilan bisa
jadi kerjaan ekstra buat sebuah runtime—tapi tetap mungkin kok!) Runtimes
tidak diwajibkan buat menjamin keadilan buat sembarang operasi, dan mereka
sering kali menawarkan API yang berbeda-beda biar kita bisa milih mau yang adil
atau nggak.
Cobain deh beberapa variasi me-await futures ini dan lihat apa yang mereka lakukan:
- Hapus blok asinkron dari salah satu atau kedua loops tersebut.
- Await tiap blok asinkron seketika setelah mendefinisikannya.
- Bungkus cuma loop pertama saja di dalam blok asinkron, dan await future hasilnya setelah isi dari loop kedua.
Buat tantangan ekstra, coba deh tebak bakal kayak apa output-nya di tiap kasus sebelum kita menjalankan kodenya!
Mengirim Data di Antara Dua Task Memakai Message Passing
Berbagi data antar futures juga bakal terasa familier: kita bakal memakai message passing lagi, tapi kali ini pakai versi asinkron dari tipe-tipe dan fungsi-fungsinya. Kita bakal ngambil jalan yang agak beda dibanding waktu di bagian “Transfer Data antar Threads Memakai Message Passing” di Bab 16 buat mengilustrasikan beberapa perbedaan kunci antara konkurensi berbasis thread dan berbasis futures. Di Listing 17-9, kita bakal mulai dengan cuma satu blok asinkron saja—tidak menelurkan sebuah task terpisah sebagaimana dulu kita menelurkan sebuah thread terpisah.
extern crate trpl; // required for mdbook test
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let val = String::from("hi");
tx.send(val).unwrap();
let received = rx.recv().await.unwrap();
println!("received '{received}'");
});
}tx dan rxDi sini, kita memakai trpl::channel, sebuah versi asinkron dari API multiple-
producer, single-consumer channel yang kita pakai bareng threads dulu di Bab
16. Versi asinkron dari API-nya cuma beda sedikit dari versi berbasis thread:
ia memakai receiver rx yang bersifat mutable bukannya immutable, dan
method recv-nya menghasilkan sebuah future yang perlu kita await bukannya
menghasilkan nilainya secara langsung. Sekarang kita bisa mengirim pesan dari
sisi pengirim ke sisi penerima. Perhatikan bahwa kita tidak harus menelurkan
sebuah thread terpisah atau bahkan sebuah task; kita cuma butuh me-await
pemanggilan rx.recv.
Method Receiver::recv yang sinkron di std::mpsc::channel memblokir sampai
ia menerima pesan. Method trpl::Receiver::recv tidak memblokir, karena ia
sifatnya asinkron. Alih-alih memblokir, ia menyerahkan kontrol kembali ke
runtime sampai entah ada pesan yang diterima atau sisi pengirim (send side)
dari channel tersebut ditutup. Sebaliknya, kita tidak me-await pemanggilan
send, karena ia tidak memblokir. Dia tidak perlu memblokir karena channel
yang kita pakai buat mengirim ini sifatnya unbounded (tidak dibatasi).
Catatan: Karena semua kode asinkron ini jalan di dalam blok asinkron di dalam pemanggilan
trpl::block_on, semua hal di dalamnya bisa menghindari memblokir. Namun, kode di luar blok tersebut bakal memblokir pada saat fungsiblock_ondikembalikan. Itulah poin utama dari fungsitrpl::block_on: ia membiarkan kita memilih di mana harus memblokir pada sekumpulan kode inkron, dan dengan begitu bisa bertransisi antara kode sinkron dan asinkron.
Perhatikan dua hal soal contoh ini. Pertama, pesannya bakal tiba seketika itu juga. Kedua, meskipun kita memakai sebuah future di sini, belum ada konkurensi sama sekali. Semua hal di dalam listing tersebut terjadi secara berurutan (sequence), persis kayak yang bakal terjadi kalau seandainya tidak ada futures yang dilibatkan.
Mari kita beresin bagian pertamanya dengan mengirim serangkaian pesan dan tidur di antara mereka, kayak yang ditunjukkan di Listing 17-10.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
});
}await di antara tiap pesanSelain mengirim pesannya, kita juga perlu menerimanya. Di kasus ini, karena kita
tahu ada berapa banyak pesan yang masuk, kita bisa melakukan itu secara manual
dengan memanggil rx.recv().await sebanyak empat kali. Tapi di dunia nyata,
kita umumnya bakal nungguin pesan yang jumlahnya tidak diketahui, jadi kita
butuh terus menunggu sampai kita yakin sudah tidak ada pesan lagi.
Di Listing 16-10, kita memakai loop for buat memproses semua item yang
diterima dari sebuah channel yang sinkron. Namun, Rust belum punya cara buat
memakai loop for dengan serangkaian item yang diproduksi secara asinkron,
jadi kita perlu memakai jenis loop yang belum pernah kita lihat sebelumnya:
yaitu perulangan bersyarat while let. Ini adalah versi loop dari konstruk
if let yang sudah kita lihat di Bab 6 di bagian “Control Flow Singkat Memakai
if let dan let...else”. Loop ini bakal terus
dijalankan selama pattern yang ditentukannya terus cocok sama nilainya.
Pemanggilan rx.recv menghasilkan sebuah future, yang kemudian kita await.
Runtime bakal me-pause future tersebut sampai dia siap. Begitu sebuah
pesan tiba, future tersebut bakal selesai (resolve) jadi Some(message)
sebanyak jumlah pesan yang tiba. Saat channel-nya ditutup, terlepas dari
apakah ada pesan yang tiba atau nggak, future tersebut bakal selesai jadi
None buat mengindikasikan kalau sudah tidak ada lagi nilainya dan oleh karena
itu kita harus berhenti melakukan polling—yakni, berhenti me-await.
Loop while let menggabungkan ini semua. Kalau hasil dari pemanggilan
rx.recv().await adalah Some(message), kita dapet akses ke pesannya dan kita
bisa memakainya di dalam isi loop, persis kayak pas pakai if let. Kalau
hasilnya None, loop-nya berakhir. Setiap kali loop-nya selesai, dia kena
await point lagi, jadi runtime me-pause-nya lagi sampai ada pesan lain
yang tiba.
Kodenya sekarang berhasil mengirim dan menerima semua pesan tersebut. Sayangnya, masih ada beberapa masalah. Salah satunya, pesan-pesannya tidak tiba dalam interval setengah detik. Mereka tiba semuanya sekaligus, 2 detik (2.000 milidetik) setelah kita menyalakan programnya. Terus, program ini juga tidak pernah berakhir! Sebaliknya, ia menunggu selamanya buat pesan baru. Kita bakal perlu mematikannya memakai ctrl-C.
Kode di Dalam Satu Blok Asinkron Dieksekusi secara Linear
Mari kita mulai dengan menyelidiki kenapa pesan-pesannya datang sekaligus
setelah penundaan penuh (full delay), bukannya datang dengan jeda di tiap
pesannya. Di dalam sebuah blok asinkron tertentu, urutan munculnya keyword
await di dalam kode juga merupakan urutan saat mereka dieksekusi pas programnya
jalan.
Cuma ada satu blok asinkron di Listing 17-10, jadi semua hal di dalamnya jalan
secara linear. Masih belum ada konkurensi. Semua pemanggilan tx.send terjadi,
diselingi sama semua pemanggilan trpl::sleep dan await points terkaitnya.
Baru setelah itu loop while let dapat giliran buat melewati titik await
apa pun pada pemanggilan recv.
Buat mendapatkan perilaku yang kita mau, di mana jeda tidurnya (sleep delay)
terjadi di antara tiap pesan, kita perlu menaruh operasi tx dan rx di dalam
blok asinkronnya masing-masing, kayak yang ditunjukkan di Listing 17-11. Terus
si runtime bisa mengeksekusi masing-masing blok secara terpisah memakai
trpl::join, persis kayak di Listing 17-8. Sekali lagi, kita me-await hasil
pemanggilan trpl::join, bukannya me-await futures individunya. Kalau kita
me-await futures individunya secara berurutan, kita ujung-ujungnya cuma
bakal balik lagi ke alur sekuensial—persis kayak apa yang mau kita hindari.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx_fut = async {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
trpl::join(tx_fut, rx_fut).await;
});
}send dan recv ke dalam blok asinkronnya masing-masing dan menunggu futures dari blok-blok tersebutDengan kode yang sudah di-update di Listing 17-11, pesan-pesannya dicetak dalam interval 500 milidetik, bukannya buru-buru sekaligus setelah 2 detik.
Memindahkan Kepemilikan (Ownership) ke dalam Blok Asinkron
Meskipun begitu, programnya tetap tidak pernah berakhir, karena cara loop
while let berinteraksi sama trpl::join:
- Future yang dikembalikan dari
trpl::joincuma selesai begitu kedua futures yang diberikan ke dia sudah selesai. - Future
tx_futselesai begitu dia kelar tidur setelah mengirim pesan terakhir di dalamvals. - Future
rx_futtidak bakal selesai sampai loopwhile letberakhir. - Loop
while lettidak bakal berakhir sampai me-awaitrx.recvmenghasilkanNone. - Me-await
rx.recvbakal mengembalikanNonecuma kalau sisi lain dari channel-nya sudah ditutup. - Channel-nya bakal tutup cuma kalau kita memanggil
rx.closeatau pas sisi pengirimnya,tx, di-drop. - Kita tidak memanggil
rx.closedi mana pun, dantxtidak bakal di-drop sampai blok asinkron terluar yang diberikan ketrpl::block_onberakhir. - Blok tersebut tidak bisa berakhir karena dia terhambat (blocked) menunggu
trpl::joinselesai, yang mana membawa kita balik lagi ke urutan paling atas dari daftar ini.
Saat ini, blok asinkron tempat kita mengirim pesannya cuma meminjam tx
karena mengirim pesan tidak mewajibkan adanya kepemilikan, tapi kalau seandainya
kita bisa memindahkan (move) tx ke dalam blok asinkron tersebut, dia bakal
di-drop begitu blok itu berakhir. Di Bab 13 di bagian “Menangkap Referensi
atau Memindahkan Kepemilikan”, kita sudah
mempelajari cara memakai keyword move bersama closures, dan, seperti yang
dibahas di bagian “Memakai move Closures bersama Threads” di Bab 16, kita sering kali perlu memindahkan data ke dalam
closures saat bekerja dengan threads. Dinamika dasar yang sama ini juga
berlaku buat blok asinkron, jadi keyword move juga bekerja di blok asinkron
sama seperti di closures.
Di Listing 17-12, kita mengubah blok yang dipakai buat mengirim pesan dari
async jadi async move.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx_fut = async move {
// --snip--
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
trpl::join(tx_fut, rx_fut).await;
});
}Pas kita menjalankan versi kode yang ini, dia bakal berhenti secara anggun begitu pesan terakhir sudah dikirim dan diterima. Berikutnya, mari kita lihat apa yang butuh diubah buat mengirim data dari lebih dari satu future.
Menggabungkan (Joining) Sejumlah Futures dengan Macro join!
Async channel ini juga merupakan multiple-producer channel, jadi kita bisa
memanggil clone pada tx kalau kita mau mengirim pesan dari banyak futures,
kayak yang ditunjukkan di Listing 17-13.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = async move {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
let tx_fut = async move {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(1500)).await;
}
};
trpl::join!(tx1_fut, tx_fut, rx_fut);
});
}Pertama, kita meng-clone tx, membikin tx1 di luar blok asinkron pertama.
Kita memindahkan tx1 ke dalam blok tersebut sama kayak yang kita lakukan
sebelumnya sama tx. Terus, belakangan, kita memindahkan tx asli ke dalam
blok asinkron baru, di mana kita mengirim lebih banyak pesan dengan jeda yang
sedikit lebih lambat. Kebetulan kita menaruh blok asinkron baru ini setelah blok
asinkron buat menerima pesan, tapi kita juga bisa kok menaruhnya sebelumnya.
Kuncinya adalah urutan pas futures-nya di-await, bukan urutan pas mereka
dibikin.
Kedua blok asinkron buat mengirim pesannya wajib berupa blok async move supaya
baik tx maupun tx1 di-drop pas blok-blok tersebut selesai. Kalau tidak,
kita bakal balik lagi ke perulangan tiada henti yang sama kayak di awal tadi.
Terakhir, kita beralih dari trpl::join ke trpl::join! buat menangani
future tambahannya: macro join! me-await jumlah futures yang sembarang
asalkan kita sudah tahu jumlah futures-nya pas masa kompilasi. Kita bakal
ngebahas soal menunggu sekumpulan futures yang jumlahnya tidak diketahui nanti
di bab ini.
Sekarang kita bisa melihat semua pesan dari kedua futures pengirimnya, dan karena futures pengirimnya memakai jeda yang sedikit berbeda setelah mengirim, pesan-pesannya juga diterima dalam interval yang berbeda tersebut:
received 'hi'
received 'more'
received 'from'
received 'the'
received 'messages'
received 'future'
received 'for'
received 'you'
Kita sudah mengeksplorasi cara memakai message passing buat mengirim data antar futures, gimana kode di dalam blok asinkron jalan secara sekuensial, gimana cara memindahkan kepemilikan ke dalam blok asinkron, dan gimana cara menggabungkan banyak futures. Berikutnya, mari kita bahas gimana dan kenapa harus kasih tahu runtime kalau dia bisa beralih ke tugas lain.
Bekerja dengan Jumlah Futures yang Sembarang
Menyerahkan Kontrol (Yielding) ke Runtime
Ingat kembali dari bagian “Program Asinkron Pertama Kita” kalau di tiap titik await, Rust ngasih kesempatan ke sebuah runtime buat me-pause task dan beralih ke task lain kalau future yang lagi di-await ternyata belum siap. Kebalikannya juga benar: Rust hanya me-pause blok asinkron dan menyerahkan kontrol kembali ke runtime pada saat titik await. Semua hal di antara titik-titik await itu sifatnya sinkron.
Itu artinya kalau kita melakukan banyak pekerjaan di dalam sebuah blok asinkron tanpa adanya titik await, future tersebut bakal memblokir futures lainnya supaya tidak bisa bikin progress. Kita mungkin kadang-kadang mendengar hal ini disebut sebagai satu future yang me-starving (membuat lapar/menghambat) futures lainnya. Di beberapa kasus, itu mungkin bukan masalah besar. Tapi, kalau kita lagi melakukan semacam setup yang berat atau pekerjaan yang makan waktu lama, atau kalau kita punya sebuah future yang bakal terus-menerus melakukan suatu tugas tertentu selamanya, kita perlu memikirkan kapan dan di mana harus menyerahkan kontrol kembali ke runtime.
Mari kita simulasikan sebuah operasi yang memakan waktu lama buat
mengilustrasikan masalah starvation ini, lalu mengeksplorasi gimana cara
menyelesaikannya. Listing 17-14 memperkenalkan sebuah fungsi slow.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
// We will call `slow` here later
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}thread::sleep buat menyimulasikan operasi yang lambatKode ini memakai std::thread::sleep bukannya trpl::sleep supaya pemanggilan
slow bakal memblokir thread saat ini selama beberapa milidetik. Kita bisa
memakai slow sebagai pengganti buat operasi di dunia nyata yang sifatnya makan
waktu lama sekaligus memblokir.
Di Listing 17-15, kita memakai slow buat meniru pengerjaan tugas semacam
CPU-bound ini di dalam sepasang futures.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let a = async {
println!("'a' started.");
slow("a", 30);
slow("a", 10);
slow("a", 20);
trpl::sleep(Duration::from_millis(50)).await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
slow("b", 10);
slow("b", 15);
slow("b", 350);
trpl::sleep(Duration::from_millis(50)).await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}slow buat menyimulasikan operasi yang lambatTiap future menyerahkan kontrol kembali ke runtime cuma setelah melaksanakan serangkaian operasi lambat. Kalau kita menjalankan kode ini, kita bakal melihat output ini:
'a' started.
'a' ran for 30ms
'a' ran for 10ms
'a' ran for 20ms
'b' started.
'b' ran for 75ms
'b' ran for 10ms
'b' ran for 15ms
'b' ran for 350ms
'a' finished.
Sama kayak di Listing 17-5 di mana kita memakai trpl::select buat mengadu
futures yang mengambil dua URL, select tetap selesai begitu a beres. Tapi
nggak ada proses selang-seling (interleaving) di antara pemanggilan ke slow di
kedua futures tersebut. Future a melakukan semua pekerjaannya sampai
pemanggilan trpl::sleep di-await, baru setelah itu future b melakukan
semua pekerjaannya sampai pemanggilan trpl::sleep-nya sendiri di-await, dan
akhirnya future a selesai. Buat membolehkan kedua futures membikin
progress di sela-sela tugas lambat mereka, kita butuh titik await supaya
kita bisa menyerahkan kontrol kembali ke runtime. Itu artinya kita butuh
sesuatu yang bisa kita await!
Kita sudah bisa melihat penyerahan kontrol semacam ini terjadi di Listing 17-15:
kalau seandainya kita menghapus trpl::sleep di akhir future a, dia bakal
selesai tanpa future b sempat berjalan sama sekali. Mari kita coba memakai
fungsi trpl::sleep sebagai titik awal buat membiarkan operasi-operasinya
bergantian membikin progress, kayak yang ditunjukkan di Listing 17-16.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let one_ms = Duration::from_millis(1);
let a = async {
println!("'a' started.");
slow("a", 30);
trpl::sleep(one_ms).await;
slow("a", 10);
trpl::sleep(one_ms).await;
slow("a", 20);
trpl::sleep(one_ms).await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
trpl::sleep(one_ms).await;
slow("b", 10);
trpl::sleep(one_ms).await;
slow("b", 15);
trpl::sleep(one_ms).await;
slow("b", 350);
trpl::sleep(one_ms).await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}trpl::sleep buat membiarkan operasi-operasi bergantian membuat progressKita sudah nambahin pemanggilan trpl::sleep dengan titik-titik await di tiap
sela pemanggilan ke slow. Sekarang pekerjaan kedua futures tersebut sudah
diselang-seling:
'a' started.
'a' ran for 30ms
'b' started.
'b' ran for 75ms
'a' ran for 10ms
'b' ran for 10ms
'a' ran for 20ms
'b' ran for 15ms
'a' finished.
Future a tetap jalan sebentar sebelum menyerahkan kontrol ke b, karena
dia memanggil slow sebelum pernah memanggil trpl::sleep, tapi setelah itu
futures-nya bertukar peran bolak-balik setiap kali salah satu dari mereka
mencapai titik await. Di kasus ini, kita sudah melakukan itu setelah tiap
pemanggilan ke slow, tapi kita bisa membagi-bagi pekerjaannya pakai cara apa
pun yang paling masuk akal buat kita.
Tapi sebenarnya kita nggak mau bener-bener “tidur” (sleep) di sini: kita mau
bikin progress secepat yang kita bisa. Kita cuma perlu menyerahkan kembali
kontrol ke runtime. Kita bisa melakukan itu secara langsung, menggunakan
fungsi trpl::yield_now. Di Listing 17-17, kita mengganti semua pemanggilan
trpl::sleep tadi dengan trpl::yield_now.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let a = async {
println!("'a' started.");
slow("a", 30);
trpl::yield_now().await;
slow("a", 10);
trpl::yield_now().await;
slow("a", 20);
trpl::yield_now().await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
trpl::yield_now().await;
slow("b", 10);
trpl::yield_now().await;
slow("b", 15);
trpl::yield_now().await;
slow("b", 350);
trpl::yield_now().await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}yield_now buat membiarkan operasi bergantian membuat progressKode ini terasa lebih jelas soal niat aslinya dan bisa jadi jauh lebih kencang
ketimbang memakai sleep, karena timers kayak yang dipakai sama sleep
sering kali punya batas seberapa spesifik (granular) mereka bisa bekerja. Versi
sleep yang kita pakai, misalnya, bakal selalu tidur setidaknya selama satu
milidetik, biarpun kita memberinya Duration sebesar satu nanodetik. Sekali
lagi, komputer modern itu cepat: mereka bisa melakukan banyak hal dalam satu
milidetik!
Ini artinya asinkron bisa berguna bahkan buat tugas-tugas compute-bound, tergantung dari apa lagi yang lagi dilakukan sama program kita, karena dia menyediakan alat yang berguna buat menstrukturkan hubungan antara berbagai bagian program yang berbeda (tapi dengan biaya beban dari state machine asinkron tersebut). Ini adalah suatu bentuk cooperative multitasking, di mana tiap future punya kuasa buat menentukan kapan dia menyerahkan kontrol lewat titik-titik await. Oleh karena itu, tiap future juga punya tanggung jawab buat menghindari memblokir terlalu lama. Di beberapa sistem operasi embedded berbasis Rust, ini adalah satu-satunya jenis multitasking yang ada!
Di kode dunia nyata, tentu saja kita tidak bakal biasanya menyelingi pemanggilan fungsi dengan titik-titik await di tiap baris kodenya. Meskipun menyerahkan kontrol pakai cara ini terhitung murah biayanya, tetap saja ia tidak gratis. Di banyak kasus, mencoba memecah-mecah tugas compute-bound bisa jadi malah bikin dia jauh lebih lambat, jadi kadang-kadang lebih baik buat performa keseluruhan kalau kita membiarkan sebuah operasi memblokir sebentar. Selalu lakukan pengukuran (measure) buat melihat di mana sebenarnya letak bottlenecks performa kode kita. Dinamika dasarnya tetap penting buat diingat, terutama kalau kita melihat banyak pekerjaan yang terjadi secara serial padahal kita mengharapnya terjadi secara konkuren!
Membikin Abstraksi Asinkron Kita Sendiri
Kita juga bisa menggabungkan (compose) futures bersama-sama buat membikin pola
baru. Misalnya, kita bisa membangun fungsi timeout dengan blok penyusun
asinkron yang sudah kita punya. Pas kita sudah selesai, hasilnya bakal jadi
blok penyusun lainnya yang bisa kita pakai buat membikin abstraksi asinkron
yang lebih banyak lagi.
Listing 17-18 menunjukkan gimana ekspektasi kita soal cara kerja timeout ini
bersama sebuah future yang lambat.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}timeout kita buat menjalankan operasi lambat dengan batas waktuMari kita implementasikan ini! Sebagai permulaan, mari pikirkan soal API buat
timeout:
- Ia sendiri harus berupa fungsi asinkron supaya kita bisa me-await-nya.
- Parameter pertamanya haruslah berupa sebuah future buat dijalankan. Kita bisa membikinnya generik biar dia bisa bekerja buat future apa saja.
- Parameter keduanya adalah waktu maksimal buat menunggu. Kalau kita memakai
Duration, itu bakal gampang diteruskan ketrpl::sleep. - Ia harus mengembalikan sebuah
Result. Kalau future-nya sukses selesai,Result-nya bakal berupaOkdengan nilai yang dihasilkan sama future tersebut. Kalau batas waktunya keburu habis duluan,Result-nya bakal berupaErrdengan durasi yang sudah dilewati sama si timeout.
Listing 17-19 menunjukkan deklarasi ini.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}
async fn timeout<F: Future>(
future_to_try: F,
max_time: Duration,
) -> Result<F::Output, Duration> {
// Here is where our implementation will go!
}timeoutItu sudah memenuhi tujuan kita buat tipe-tipenya. Sekarang mari kita pikirkan
soal perilaku yang kita butuhkan: kita mau mengadu (race) future yang
dimasukkan tadi melawan durasinya. Kita bisa memakai trpl::sleep buat membikin
timer future dari durasinya, lalu memakai trpl::select buat menjalankan
timer tersebut barengan sama future yang diberikan sama si pemanggil.
Di Listing 17-20, kita mengimplementasikan timeout dengan melakukan match
pada hasil dari me-await trpl::select.
extern crate trpl; // required for mdbook test
use std::time::Duration;
use trpl::Either;
// --snip--
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}
async fn timeout<F: Future>(
future_to_try: F,
max_time: Duration,
) -> Result<F::Output, Duration> {
match trpl::select(future_to_try, trpl::sleep(max_time)).await {
Either::Left(output) => Ok(output),
Either::Right(_) => Err(max_time),
}
}timeout dengan select dan sleepImplementasi dari trpl::select itu tidak adil (not fair): ia selalu melakukan
polling pada argumen-argumennya sesuai urutan saat mereka dioper (implementasi
select lainnya biasanya bakal memilih argumen mana yang mau di-poll duluan
secara acak). Maka dari itu, kita mengoper future_to_try ke select duluan
biar dia dapet kesempatan buat selesai biarpun max_time itu durasinya sangat
singkat. Kalau future_to_try beres duluan, select bakal mengembalikan
Left yang isinya output dari future_to_try. Kalau timer beres duluan,
select bakal mengembalikan Right berisi output dari timernya yaitu ().
Kalau future_to_try sukses dan kita dapet Left(output), kita mengembalikan
Ok(output). Kalau sebaliknya si sleep timer yang habis waktunya dan kita
dapet Right(()), kita mengabaikan () tersebut pakai _ lalu mengembalikan
Err(max_time) sebagai gantinya.
Selesai deh, kita sudah punya fungsi timeout yang bisa jalan yang dibangun
dari dua buah pembantu asinkron lainnya. Kalau kita jalankan kodenya, dia bakal
mencetak mode kegagalan setelah timeout terjadi:
Failed after 2 seconds
Karena futures bisa digabung-gabungin bareng futures lain, kita bisa membangun alat-alat yang sangat kuat memakai blok penyusun asinkron yang kecil- kecil. Misalnya, kita bisa memakai pendekatan yang sama ini buat menggabungkan timeouts dengan retries, dan sebaliknya memakai itu semua bersama operasi lain kayak pemanggilan jaringan (seperti contoh yang ada di Listing 17-5).
Di praktiknya, biasanya kita bakal bekerja secara langsung dengan async dan
await, dan secara sekunder memakai fungsi-fungsi kayak select dan macros
kayak macro join! buat mengontrol gimana futures paling luarnya dieksekusi.
Kita sekarang sudah melihat sejumlah cara buat bekerja bareng banyak futures di saat yang bersamaan. Selanjutnya, kita bakal melihat gimana cara kita bekerja dengan banyak futures di dalam sebuah urutan seiring berjalannya waktu menggunakan streams.
Streams: Serangkaian Futures Berurutan
Streams: Futures dalam Urutan
Ingat kembali gimana cara kita memakai receiver buat asinkron channel kita di
awal bab ini di bagian “Message Passing”.
Method asinkron recv memproduksi serangkaian item seiring berjalannya waktu.
Ini adalah salah satu bentuk dari pola yang jauh lebih umum yang dikenal sebagai
stream. Banyak konsep yang secara alami bisa direpresentasikan sebagai
streams: item-item yang mulai tersedia di dalam antrean (queue), potongan data
yang ditarik secara bertahap dari sistem file pas set datanya terlalu besar buat
memori komputer, atau data yang tiba melalui jaringan seiring waktu. Karena
streams adalah futures, kita bisa memakainya bareng jenis future lainnya
dan menggabungkannya dengan cara-cara yang menarik. Misalnya, kita bisa
mengumpulkan (batch up) kejadian-kejadian (events) buat menghindari terlalu
banyak pemanggilan jaringan, mengatur batas waktu (timeouts) pada urutan
operasi yang berjalan lama, atau membatasi (throttle) kejadian-kejadian UI
buat menghindari melakukan pekerjaan yang sia-sia.
Kita sudah pernah melihat serangkaian item di Bab 13, pas kita melihat trait
Iterator di bagian “Trait Iterator dan Method next”, tapi ada dua perbedaan antara iterator dan asinkron channel
receiver. Perbedaan pertama adalah waktu: iterator itu sinkron, sedangkan
channel receiver itu asinkron. Perbedaan kedua adalah API-nya. Pas bekerja
langsung dengan Iterator, kita memanggil method next-nya yang sinkron.
Khusus buat stream trpl::Receiver, kita memanggil method recv yang
asinkron sebagai gantinya. Di luar itu, API-API ini terasa sangat mirip, dan
kemiripan itu bukan kebetulan kok. Sebuah stream itu kayak bentuk asinkron
dari iterasi. Meskipun trpl::Receiver secara spesifik menunggu buat menerima
pesan, tapi API stream yang buat tujuan umum itu jauh lebih luas: dia
menyediakan item berikutnya sama kayak yang dilakukan Iterator, tapi secara
asinkron.
Kemiripan antara iterator dan streams di Rust artinya kita sebenarnya bisa
membikin sebuah stream dari iterator apa saja. Sama kayak iterator, kita bisa
bekerja bareng sebuah stream dengan memanggil method next-nya lalu me-await
output-nya, kayak di Listing 17-21, yang mana kode ini belum bisa di-compile.
extern crate trpl; // required for mdbook test
fn main() {
trpl::block_on(async {
let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let iter = values.iter().map(|n| n * 2);
let mut stream = trpl::stream_from_iter(iter);
while let Some(value) = stream.next().await {
println!("The value was: {value}");
}
});
}Kita mulai dengan sebuah array angka, yang kemudian kita ubah jadi sebuah
iterator lalu memanggil map buat melipatgandakan semua nilainya. Terus kita
mengubah iterator tersebut jadi sebuah stream menggunakan fungsi
trpl::stream_from_iter. Berikutnya, kita melakukan loop melewati item-item
di dalam stream tersebut pas mereka tiba memakai loop while let.
Sayangnya, pas kita coba menjalankan kodenya, ia tidak bisa di-compile
melainkan malah melaporkan kalau tidak ada method next yang tersedia:
error[E0599]: no method named `next` found for struct `tokio_stream::iter::Iter` in the current scope
--> src/main.rs:10:40
|
10 | while let Some(value) = stream.next().await {
| ^^^^
|
= help: items from traits can only be used if the trait is in scope
help: the following traits which provide `next` are implemented but not in scope; perhaps you want to import one of them
|
1 + use crate::trpl::StreamExt;
|
1 + use futures_util::stream::stream::StreamExt;
|
1 + use std::iter::Iterator;
|
1 + use std::str::pattern::Searcher;
|
help: there is a method `try_next` with a similar name
|
10 | while let Some(value) = stream.try_next().await {
| ~~~~~~~~
Sesuai penjelasan output ini, alasan error compiler-nya adalah karena kita
butuh trait yang tepat berada di dalam scope supaya bisa memakai method
next. Mengingat pembahasan kita sejauh ini, kita mungkin secara wajar
berekspektasi kalau trait tersebut adalah Stream, tapi sebenarnya ia adalah
StreamExt. Singkatan dari extension (ekstensi), Ext adalah pola yang umum
di komunitas Rust buat memperluas satu trait dengan trait lainnya.
Trait Stream mendefinisikan sebuah low-level interface yang secara efektif
menggabungkan trait Iterator dan Future. StreamExt menyuplai sekumpulan
API tingkat lebih tinggi di atas Stream, termasuk method next sekaligus
method pembantu lainnya yang mirip sama yang disediakan oleh trait Iterator.
Stream dan StreamExt belum menjadi bagian dari standard library milik
Rust, tapi mayoritas crates di ekosistem memakai definisi yang serupa.
Solusi buat error compiler tadi adalah dengan menambahkan statement use buat
trpl::StreamExt, kayak yang ditunjukkan di Listing 17-22.
extern crate trpl; // required for mdbook test
use trpl::StreamExt;
fn main() {
trpl::block_on(async {
let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
// --snip--
let iter = values.iter().map(|n| n * 2);
let mut stream = trpl::stream_from_iter(iter);
while let Some(value) = stream.next().await {
println!("The value was: {value}");
}
});
}Dengan semua bagian itu disatukan, kode ini berjalan sesuai yang kita mau!
Bahkan, sekarang karena kita punya StreamExt di dalam scope, kita bisa
memakai semua method pembantunya, persis kayak iterator.
Ngelihat Lebih Dekat pada Traits buat Async
Ngelihat Lebih Dekat pada Traits buat Async
Di sepanjang bab ini, kita sudah memakai trait Future, Stream, dan
StreamExt dengan berbagai cara. Sejauh ini, kita memang sengaja menghindari
membahas terlalu dalam soal gimana detail cara kerja mereka atau gimana mereka
saling berhubungan, yang mana sebenarnya sah-sah saja buat pekerjaan Rust kita
sehari-hari. Tapi kadang-kadang, kita bakal menjumpai situasi di mana kita butuh
memahami lebih banyak detail soal trait-trait ini, bersamaan dengan tipe Pin
dan trait Unpin. Di bagian ini, kita bakal menggalinya secukupnya saja buat
membantu kita di skenario-skenario tersebut, sembari tetap membiarkan pembahasan
yang bener-bener mendalam buat dokumentasi lainnya.
Trait Future
Mari kita mulai dengan melihat lebih dekat gimana cara kerja trait Future.
Beginilah cara Rust mendefinisikannya:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
}Definisi trait tersebut menyertakan sejumlah tipe baru dan juga beberapa sintaks yang belum pernah kita lihat sebelumnya, jadi mari kita bedah definisinya satu per satu.
Pertama, associated type Output milik Future menyatakan hasil akhir yang
dihasilkan sama future tersebut. Ini serupa dengan associated type Item
pada trait Iterator. Kedua, Future punya method poll, yang menerima sebuah
referensi Pin spesial buat parameter self-nya dan sebuah referensi mutable
ke tipe Context, serta mengembalikan sebuah Poll<Self::Output>. Kita bakal
ngomongin soal Pin dan Context sebentar lagi. Buat sekarang, mari fokus sama
apa yang dikembalikan sama method-nya, yaitu tipe Poll:
#![allow(unused)]
fn main() {
pub enum Poll<T> {
Ready(T),
Pending,
}
}Tipe Poll ini mirip sama Option. Ia punya satu varian yang punya nilai,
Ready(T), dan satu lagi yang nggak punya, Pending. Tapi makna Poll itu
jauh beda lho sama Option! Varian Pending mengindikasikan kalau future-nya
masih punya pekerjaan buat dilakukan, jadi si pemanggil perlu mengeceknya lagi
nanti. Varian Ready mengindikasikan kalau Future-nya sudah selesai
mengerjakan tugasnya dan nilai T sudah tersedia.
Catatan: Jarang sekali ada kebutuhan buat memanggil
pollsecara langsung, tapi kalau kita memang butuh melakukannya, ingatlah kalau pada kebanyakan futures, si pemanggil tidak seharusnya memanggilpolllagi setelah future-nya mengembalikanReady. Banyak futures yang bakal panic kalau di-poll lagi setelah mereka jadi siap. Futures yang aman buat di-poll lagi bakal menyatakannya secara eksplisit di dalam dokumentasinya. Perilaku ini mirip sama gimanaIterator::nextbekerja.
Pas kita melihat kode yang memakai await, Rust sebenarnya mengompilasi kode
tersebut di balik layar menjadi kode yang memanggil poll. Kalau kita melihat
balik ke Listing 17-4, di mana kita mencetak judul halaman buat satu URL begitu
dia selesai, Rust mengompilasinya jadi sesuatu yang kira-kira (biarpun nggak
persis sama) kayak gini:
match page_title(url).poll() {
Ready(page_title) => match page_title {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
},
Pending => {
// Terus apa yang ditaruh di sini?
}
}Apa yang harus kita lakukan pas future-nya masih Pending? Kita butuh suatu
cara buat mencoba lagi, lagi, dan lagi, sampai future-nya akhirnya siap.
Dengan kata lain, kita butuh sebuah loop:
let mut page_title_fut = page_title(url);
loop {
match page_title_fut.poll() {
Ready(value) => match page_title {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
Pending => {
// lanjut
}
}
}Tapi kalau seandainya Rust benar-benar mengompilasi kode yang persis kayak gitu,
tiap await jadinya bakal memblokir—persis kebalikan dari apa yang mau kita
capai! Sebaliknya, Rust memastikan kalau perulangannya bisa menyerahkan kontrol
ke sesuatu yang bisa me-pause pekerjaan pada future ini buat mengerjakan
futures lainnya dan baru kemudian mengecek yang satu ini lagi nanti. Kayak
yang sudah kita lihat, “sesuatu” itu adalah sebuah async runtime, dan
pekerjaan penjadwalan dan koordinasi ini adalah salah satu tugas utamanya.
Di bagian “Mengirim Data di Antara Dua Task Memakai Message Passing”, kita mendeskripsikan proses menunggu di rx.recv. Pemanggilan
recv mengembalikan sebuah future, dan me-await future tersebut bakal me-
poll-nya. Kita sudah mencatat kalau sebuah runtime bakal me-pause
future-nya sampai dia siap dengan entah Some(message) atau None pas
channel-nya tutup. Dengan pemahaman kita yang lebih dalam soal trait
Future, dan secara spesifik Future::poll, kita bisa melihat gimana cara
kerjanya. Runtime tahu kalau future-nya belum siap pas dia mengembalikan
Poll::Pending. Kebalikannya, runtime tahu kalau future-nya sudah siap
dan melanjutkannya pas poll mengembalikan Poll::Ready(Some(message)) atau
Poll::Ready(None).
Detail persis soal gimana cara runtime melakukan hal tersebut ada di luar cakupan buku ini, tapi kuncinya adalah melihat mekanisme dasar dari futures: sebuah runtime me-poll tiap future yang jadi tanggung jawabnya, lalu menidurkan kembali future tersebut pas dia belum siap.
Tipe Pin dan Trait Unpin
Dulu di Listing 17-13, kita memakai macro trpl::join! buat menunggu tiga
buah futures. Tapi, sudah jadi hal yang umum kalau kita punya sebuah koleksi
seperti vector yang berisi sejumlah futures yang jumlahnya baru bakal
diketahui pas runtime. Mari kita ubah Listing 17-13 jadi kode di Listing 17-
23 yang menaruh ketiga futures tersebut ke dalam sebuah vector lalu memanggil
fungsi trpl::join_all sebagai gantinya, yang mana kode ini belum bisa di-
compile.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = async move {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
let tx_fut = async move {
// --snip--
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let futures: Vec<Box<dyn Future<Output = ()>>> =
vec![Box::new(tx1_fut), Box::new(rx_fut), Box::new(tx_fut)];
trpl::join_all(futures).await;
});
}Kita menaruh tiap future di dalam sebuah Box buat menjadikannya sebagai
trait objects, persis kayak yang kita lakukan di bagian “Mengembalikan Error
dari run” di Bab 12. (Kita bakal membahas trait objects secara detail di
Bab 18.) Memakai trait objects membiarkan kita memperlakukan tiap futures
anonim yang dihasilkan sama tipe-tipe ini sebagai tipe yang sama, karena mereka
semua mengimplementasikan trait Future.
Ini mungkin mengejutkan. Lagian, tidak ada satu pun dari blok asinkron tersebut
yang mengembalikan apa-apa, jadi masing-masing memproduksi sebuah
Future<Output = ()>. Tapi ingat kalau Future itu adalah sebuah trait, dan
compiler membikin sebuah enum yang unik buat tiap blok asinkron, biarpun tipe
output mereka identik. Sama halnya kayak kita tidak bisa menaruh dua buah
struct tulisan tangan yang berbeda ke dalam sebuah Vec, kita juga tidak bisa
mencampur aduk enum-enum buatan compiler tersebut.
Terus kita mengoper koleksi futures tersebut ke fungsi trpl::join_all lalu
me-await hasilnya. Tapi, kode ini tidak bisa di-compile; ini dia bagian yang
relevan dari pesan errornya.
error[E0277]: `dyn Future<Output = ()>` cannot be unpinned
--> src/main.rs:48:33
|
48 | trpl::join_all(futures).await;
| ^^^^^ the trait `Unpin` is not implemented for `dyn Future<Output = ()>`
|
= note: consider using the `pin!` macro
consider using `Box::pin` if you need to access the pinned value outside of the current scope
= note: required for `Box<dyn Future<Output = ()>>` to implement `Future`
note: required by a bound in `futures_util::future::join_all::JoinAll`
--> file:///home/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/futures-util-0.3.30/src/future/join_all.rs:29:8
|
27 | pub struct JoinAll<F>
| ------- required by a bound in this struct
28 | where
29 | F: Future,
| ^^^^^^ required by this bound in `JoinAll`
Catatan di pesan error ini ngasih tahu kita kalau kita seharusnya memakai macro
pin! buat me-pin (mematok) nilai-nilainya, yang artinya menaruh mereka di
dalam tipe Pin yang menjamin kalau nilai-nilainya tidak bakal dipindah-pindah
di dalam memori. Pesan error-nya bilang kalau proses pinning itu diwajibkan
karena dyn Future<Output = ()> perlu mengimplementasikan trait Unpin dan
untuk sekarang dia belum melakukannya.
Fungsi trpl::join_all mengembalikan sebuah struct bernama JoinAll. Struct
tersebut sifatnya generik terhadap tipe F, yang dibatasi (constrained) buat
mengimplementasikan trait Future. Menunggu sebuah future secara langsung
dengan await bakal me-pin future-nya secara implisit. Itulah alasan
kenapa kita tidak perlu memakai pin! di semua tempat di mana kita mau me-
await futures.
Tapi, kita ini sedang tidak menunggu sebuah future secara langsung di sini.
Sebaliknya, kita sedang membangun sebuah future baru, JoinAll, dengan cara
meneruskan sekumpulan futures ke fungsi join_all. Signature buat
join_all mewajibkan tipe-tipe dari item di dalam koleksinya buat semuanya
mengimplementasikan trait Future, dan Box<T> mengimplementasikan Future
cuma kalau T yang ia bungkus itu adalah sebuah future yang
mengimplementasikan trait Unpin.
Duh, sangat banyak yang harus diserap ya! Biar benar-benar paham, mari kita gali
sedikit lebih jauh soal gimana cara trait Future sebenarnya bekerja, terutama
seputar urusan pinning. Mari kita lihat lagi definisi dari trait Future:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
pub trait Future {
type Output;
// Method yang wajib ada
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
}Parameter cx dan tipe Context-nya adalah kunci gimana sebuah runtime bisa
benar-benar tahu kapan harus mengecek sembarang future yang diberikan sambil
tetap bersifat malas. Sekali lagi, detail gimana itu bekerja ada di luar
cakupan bab ini, dan kita umumnya cuma perlu memikirkan hal ini pas lagi
menulis implementasi Future kustom. Kita bakal fokus saja ke tipe buat
self, karena ini adalah pertama kalinya kita melihat sebuah method di mana
self punya anotasi tipe. Sebuah anotasi tipe buat self bekerja kayak
anotasi tipe buat parameter fungsi lainnya tapi dengan dua perbedaan kunci:
- Ia memberi tahu Rust tipe
selfapa yang harus dimiliki supaya method-nya bisa dipanggil. - Ia nggak boleh sembarang tipe. Ia dibatasi cuma buat tipe tempat method-nya
diimplementasikan, sebuah referensi atau smart pointer ke tipe tersebut,
atau sebuah
Pinyang membungkus referensi ke tipe tersebut.
Kita bakal melihat lebih banyak lagi soal sintaks ini di Bab 18. Buat sekarang, cukup tahu saja kalau kita mau me-poll sebuah
future buat mengecek apakah dia itu Pending atau Ready(Output), kita
butuh referensi mutable yang dibungkus Pin ke tipe tersebut.
Pin adalah sebuah pembungkus (wrapper) buat tipe-tipe yang mirip pointer kayak
&, &mut, Box, dan Rc. (Secara teknis, Pin bekerja dengan tipe-tipe
yang mengimplementasikan trait Deref atau DerefMut, tapi ini secara efektif
ekuivalen dengan bekerja cuma bareng referensi dan smart pointers.) Pin
bukanlah sebuah pointer itu sendiri dan ia tidak punya perilaku miliknya
sendiri kayak Rc dan Arc yang punya fitur reference counting; ia murni
hanyalah alat yang bisa dipakai compiler buat menegakkan batasan (constraints)
pada penggunaan pointer.
Mengingat kembali kalau await itu diimplementasikan lewat pemanggilan-
pemanggilan ke poll mulai bisa menjelaskan pesan error yang kita lihat tadi,
tapi kan tadi itu dalam konteks Unpin, bukan Pin. Jadi apa sebenarnya
hubungan Pin dengan Unpin, dan kenapa Future butuh self buat berada di
dalam tipe Pin supaya bisa memanggil poll?
Ingat dari bagian awal bab ini kalau serangkaian titik await di dalam sebuah future bakal dikompilasi jadi sebuah state machine, dan compiler mastiin kalau state machine tersebut mengikuti semua aturan normal Rust seputar keamanan, termasuk borrowing dan ownership. Biar itu bisa jalan, Rust melihat data apa saja yang dibutuhkan di antara satu titik await dengan titik await berikutnya atau sampai akhir dari blok asinkronnya. Terus dia membikin varian yang korespondensi di dalam state machine hasil kompilasinya. Tiap varian dapet akses yang dibutuhkannya ke data yang bakal dipakai di bagian kode sumber tersebut, entah dengan mengambil kepemilikan dari data tersebut atau dengan mendapatkan referensi mutable atau immutable kepadanya.
Sejauh ini aman: kalau kita bikin kesalahan soal ownership atau referensi di
sebuah blok asinkron tertentu, si borrow checker bakal kasih tahu kita. Tapi
pas kita mau memindah-mindahkan future yang berkaitan sama blok tersebut—kayak
memindahkannya ke dalam sebuah Vec buat dioper ke join_all—urusannya jadi
makin rumit.
Pas kita memindahkan sebuah future—entah itu dengan memasukkannya ke struktur
data buat dipakai sebagai iterator bersama join_all atau dengan
mengembalikannya dari sebuah fungsi—itu sebenarnya bermakna memindahkan state
machine yang Rust bikin buat kita. Dan beda sama mayoritas tipe lain di Rust,
futures yang Rust bikin buat blok asinkron bisa berakhir punya referensi ke
dirinya sendiri di dalam field dari varian yang manapun, kayak yang ditunjukkan
di ilustrasi yang disederhanakan di Gambar 17-4.

Tapi secara bawaan, objek apa saja yang punya referensi ke dirinya sendiri itu sifatnya tidak aman buat dipindahkan, karena referensi itu selalu menunjuk ke alamat memori asli dari apa pun yang dirujuknya (lihat Gambar 17-5). Kalau kita memindahkan struktur datanya itu sendiri, referensi internal tadi bakal ditinggalkan dalam posisi menunjuk ke lokasi yang lama. Padahal, lokasi memori tersebut sekarang sudah tidak valid. Di satu sisi, nilainya tidak bakal di- update pas kita melakukan perubahan ke struktur datanya. Di sisi lain—yang lebih penting—komputernya sekarang bebas buat memakai ulang memori tersebut buat keperluan lain! Kita bisa berakhir membaca data yang sama sekali tidak ada hubungannya nanti.

Secara teori, compiler Rust bisa saja mencoba buat meng-update tiap referensi ke suatu objek setiap kali objek tersebut dipindahkan, tapi itu bisa menambah banyak beban performa, apalagi kalau ada jaring-jaring referensi utuh yang perlu di-update. Kalau kita sebaliknya bisa memastikan struktur data yang dimaksud itu tidak pindah-pindah di memori, kita tidak perlu repot-repot meng- update referensi apa pun. Nah, itulah gunanya borrow checker milik Rust: di dalam kode yang aman, ia mencegah kita dari memindahkan item apa saja yang punya referensi aktif yang menunjuk kepadanya.
Pin dibangun di atas hal tersebut buat memberikan jaminan persis yang kita
butuhkan. Pas kita me-pin sebuah nilai dengan membungkus sebuah pointer ke
nilai tersebut di dalam Pin, dia sudah tidak bisa pindah lagi. Jadi, kalau
kita punya Pin<Box<SuatuTipe>>, kita sebenarnya sedang me-pin nilai
SuatuTipe tersebut, bukan pointer Box-nya. Gambar 17-6 mengilustrasikan
proses ini.

Kenyataannya, pointer Box-nya tetap bisa pindah-pindah dengan bebas. Ingat:
kita peduli buat memastikan kalau data yang ujung-ujungnya sedang direferensikan
itu tetap diam di tempat. Kalau sebuah pointer pindah-pindah, tapi data yang
ditunjuknya tetap ada di tempat yang sama, kayak di Gambar 17-7, nggak bakal
ada masalah potensial. (Sebagai latihan mandiri, coba lihat dokumentasi buat
tipe-tipe tersebut sekaligus modul std::pin dan coba cari tahu gimana cara
kita melakukan ini pakai Pin yang membungkus sebuah Box.) Kuncinya adalah
tipe self-referential-nya itu sendiri nggak bisa pindah, karena ia tetap di-
pin.

Meskipun begitu, mayoritas tipe itu benar-benar aman buat dipindah-pindahkan,
biarpun mereka kebetulan ada di balik sebuah pointer Pin. Kita cuma perlu
mikirin soal pinning pas item-itemnya punya referensi internal. Nilai-nilai
primitif kayak angka dan Boolean itu aman karena mereka jelas nggak punya
referensi internal apa-apa. Begitu juga sama mayoritas tipe yang biasa kita
pakai di Rust. Kita bisa memindah-mindahkan sebuah Vec, misalnya, tanpa perlu
khawatir. Mengingat apa yang sudah kita lihat sejauh ini, kalau kita punya
Pin<Vec<String>>, kita bakal dipaksa melakukan segalanya lewat API milik Pin
yang aman tapi membatasi, padahal sebuah Vec<String> itu selalu aman buat
dipindahkan kalau tidak ada referensi lain kepadanya. Kita butuh sebuah cara
buat memberi tahu compiler kalau tidak apa-apa buat memindah-mindahkan item di
kasus-kasus kayak gini—dan di situlah Unpin beraksi.
Unpin adalah sebuah marker trait, mirip sama trait Send dan Sync yang
kita lihat di Bab 16, dan oleh karenanya tidak punya fungsionalitas miliknya
sendiri. Marker traits eksis cuma buat memberi tahu compiler kalau tipe yang
mengimplementasikan trait tersebut aman buat dipakai di suatu konteks tertentu.
Unpin menginformasikan ke compiler kalau suatu tipe tertentu tidak perlu
menjunjung tinggi jaminan apa pun soal apakah nilai yang dimaksud bisa
dipindahkan dengan aman atau tidak.
Sama kayak Send dan Sync, compiler mengimplementasikan Unpin secara
otomatis buat semua tipe di mana dia bisa membuktikan keamanannya. Kasus
spesialnya, sekali lagi mirip kayak Send dan Sync, adalah pas Unpin
tidak diimplementasikan buat suatu tipe. Notasi buat hal ini adalah
impl !Unpin for SuatuTipe, di mana SuatuTipe adalah nama dari tipe yang
memang perlu menjunjung tinggi jaminan-jaminan tersebut supaya aman kapan pun
sebuah pointer ke tipe tersebut dipakai di dalam sebuah Pin.
Dengan kata lain, ada dua hal yang harus diingat soal hubungan antara Pin dan
Unpin. Pertama, Unpin adalah kasus yang “normal”, dan !Unpin adalah kasus
yang spesial. Kedua, apakah suatu tipe mengimplementasikan Unpin atau
!Unpin itu hanya berpengaruh pas kita lagi memakai pointer yang di-pin ke
tipe tersebut kayak Pin<&mut SuatuTipe>.
Buat menjadikannya konkret, coba pikirkan soal sebuah String: ia punya sebuah
panjang (length) dan karakter-karakter Unicode yang menyusunnya. Kita bisa
membungkus sebuah String di dalam Pin, kayak yang terlihat di Gambar 17-8.
Tapi, String secara otomatis mengimplementasikan Unpin, sama halnya kayak
mayoritas tipe lain di Rust.

Hasilnya, kita bisa melakukan hal-hal yang tadinya ilegal kalau seandainya
String mengimplementasikan !Unpin, kayak misalnya mengganti satu string
dengan yang lain di lokasi memori yang sama persis kayak di Gambar 17-9. Ini
tidak melanggar kontrak dari Pin, karena String nggak punya referensi
internal yang bikin dia jadi nggak aman buat dipindah-pindahkan. Itulah
persisnya kenapa ia mengimplementasikan Unpin bukannya !Unpin.

Nah sekarang kita sudah tahu cukup banyak buat memahami error-error yang
dilaporkan buat pemanggilan join_all tadi balik di Listing 17-23. Kita
awalnya mencoba memindahkan futures hasil produksi blok asinkron ke dalam
sebuah Vec<Box<dyn Future<Output = ()>>>, tapi kayak yang sudah kita lihat,
futures tersebut mungkin saja punya referensi internal, jadi mereka tidak
secara otomatis mengimplementasikan Unpin. Begitu kita me-pin mereka, kita
bisa meneruskan tipe Pin hasilnya ke dalam Vec, dengan rasa percaya diri
kalau data yang mendasari futures tersebut tidak bakal dipindahkan.
Listing 17-24 menunjukkan cara membetulkan kodenya dengan memanggil macro
pin! di tiap tempat di mana ketiga futures tadi didefinisikan dan
menyesuaikan tipe dari trait object-nya.
extern crate trpl; // required for mdbook test
use std::pin::{Pin, pin};
// --snip--
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = pin!(async move {
// --snip--
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
});
let rx_fut = pin!(async {
// --snip--
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
});
let tx_fut = pin!(async move {
// --snip--
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
});
let futures: Vec<Pin<&mut dyn Future<Output = ()>>> =
vec![tx1_fut, rx_fut, tx_fut];
trpl::join_all(futures).await;
});
}Contoh ini sekarang sudah bisa di-compile dan dijalankan, dan kita bisa menambah atau menghapus futures dari vector-nya pas runtime lalu menggabungkan mereka semua.
Pin dan Unpin itu paling banyak kepake pas lagi membangun lower-level
libraries, atau pas kita lagi membangun sebuah runtime itu sendiri, bukannya
buat kode Rust sehari-hari. Tapi pas kita melihat trait-trait ini muncul di
dalam pesan error, setidaknya sekarang kita punya gambaran yang lebih oke soal
gimana cara membetulkan kode kita!
Catatan: Kombinasi antara
PindanUnpinini memungkinkan implementasi aman dari keseluruhan kelas tipe-tipe kompleks di Rust yang tadinya bakal terbukti menantang gara-gara mereka bersifat self-referential. Tipe-tipe yang mewajibkanPinpaling sering muncul di Rust asinkron saat ini, tapi sekali-sekali, kita mungkin juga bakal menjumpai mereka di konteks lain.Detail spesifik soal gimana
PindanUnpinbekerja, dan aturan apa saja yang wajib mereka junjung tinggi, sudah dibahas secara ekstensif di dalam dokumentasi API buatstd::pin, jadi kalau kita tertarik buat belajar lebih lanjut, itu adalah tempat yang bagus buat memulai.Kalau kita mau memahami gimana cara kerja di balik layarnya secara lebih detail lagi, silakan baca Bab 2 dan 4 dari buku Asynchronous Programming in Rust.
Trait Stream
Sekarang setelah kita punya pemahaman yang lebih dalam soal trait Future,
Pin, dan Unpin, kita bisa mengalihkan perhatian kita ke trait Stream.
Kayak yang sudah kita pelajari sebelumnya di bab ini, streams itu mirip kayak
iterator asinkron. Tapi beda sama Iterator dan Future, Stream itu tidak
punya definisi di dalam standard library pada saat tulisan ini dibuat, tapi
emang ada definisi yang sangat umum dari crate futures yang dipakai di
seluruh ekosistem.
Mari kita ulas balik definisi dari trait Iterator dan Future sebelum
melihat gimana sebuah trait Stream mungkin bakal menggabungkan keduanya. Dari
Iterator, kita dapet ide soal urutan (sequence): method next-nya
menyediakan sebuah Option<Self::Item>. Dari Future, kita dapet ide soal
kesiapan seiring berjalannya waktu: method poll-nya menyediakan sebuah
Poll<Self::Output>. Buat merepresentasikan serangkaian item yang mulai siap
seiring waktu, kita mendefinisikan sebuah trait Stream yang menggabungkan
fitur-fitur tersebut:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
trait Stream {
type Item;
fn poll_next(
self: Pin<&mut Self>,
cx: &mut Context<'_>
) -> Poll<Option<Self::Item>>;
}
}Trait Stream mendefinisikan sebuah associated type bernama Item buat tipe
dari item-item yang diproduksi sama stream-nya. Ini mirip sama Iterator, di
mana itemnya bisa berjumlah nol sampai banyak, dan beda sama Future, yang
mana output-nya selalu satu, biarpun itu cuma tipe unit ().
Stream juga mendefinisikan sebuah method buat mendapatkan item-item tersebut.
Kita menamainya poll_next, buat memperjelas kalau dia me-poll pakai cara
yang sama kayak yang dilakukan Future::poll dan memproduksi serangkaian item
pakai cara yang sama kayak yang dilakukan Iterator::next. Tipe kembaliannya
menggabungkan Poll dengan Option. Tipe luarnya adalah Poll, karena dia
wajib dicek kesiapannya, persis kayak sebuah future. Tipe dalamnya adalah
Option, karena dia butuh memberi tanda apakah masih ada pesan lagi, persis
kayak sebuah iterator.
Sesuatu yang sangat mirip dengan definisi ini kemungkinan besar bakal berakhir menjadi bagian dari standard library milik Rust. Sembari menunggu, ia adalah bagian dari peralatan milik mayoritas runtimes, jadi kita bisa mengandalkannya, dan segala hal yang kita bahas selanjutnya secara umum bakal tetap berlaku!
Tapi di contoh-contoh yang kita lihat di bagian “Streams: Futures dalam
Urutan” tadi, kita tidak memakai poll_next maupun
Stream, melainkan malah memakai next dan StreamExt. Tentu saja kita bisa
bekerja secara langsung mengikuti API poll_next dengan cara menulis tangan
state machine Stream kita sendiri, persis kayak kita juga bisa bekerja
bareng futures secara langsung lewat method poll-nya. Tapi memakai await
itu jauh lebih enak, dan trait StreamExt menyuplai method next supaya kita
bisa melakukan hal itu:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
trait Stream {
type Item;
fn poll_next(
self: Pin<&mut Self>,
cx: &mut Context<'_>,
) -> Poll<Option<Self::Item>>;
}
trait StreamExt: Stream {
async fn next(&mut self) -> Option<Self::Item>
where
Self: Unpin;
// other methods...
}
}Catatan: Definisi asli yang kita pakai sebelumnya di bab ini kelihatan sedikit berbeda dari ini, karena ia mendukung versi Rust yang dulu belum mendukung penggunaan fungsi asinkron di dalam traits. Hasilnya, ia kelihatannya kayak gini:
fn next(&mut self) -> Next<'_, Self> where Self: Unpin;Tipe
Nexttersebut adalah sebuahstructyang mengimplementasikanFuturedan mengizinkan kita buat menamai lifetime dari referensi keselfdenganNext<'_, Self>, supayaawaitbisa bekerja bareng method ini.
Trait StreamExt juga merupakan rumah dari semua method menarik yang tersedia
buat dipakai bareng streams. StreamExt secara otomatis diimplementasikan
buat tiap tipe yang mengimplementasikan Stream, tapi trait-trait ini
didefinisikan secara terpisah supaya komunitas bisa beriterasi pada API-API
kemudahan tanpa mengganggu trait dasarnya.
Di versi StreamExt yang dipakai di crate trpl, trait-nya tidak cuma
mendefinisikan method next tapi juga menyuplai implementasi default dari
next yang secara benar menangani detail-detail pemanggilan
Stream::poll_next. Ini artinya bahkan pas kita perlu menulis tipe data streaming
kita sendiri, kita cuma harus mengimplementasikan Stream, dan nantinya
siapa saja yang memakai tipe data kita bisa memakai StreamExt beserta method-
methodnya secara otomatis.
Nah, segitu saja pembahasan kita soal detail-detail tingkat rendah pada trait- trait ini. Sebagai penutup, mari kita pertimbangkan gimana futures (termasuk streams), tasks, dan threads semuanya saling melengkapi!
Futures, Tasks, dan Threads
Menyatukan Semuanya: Futures, Tasks, dan Threads
Seperti yang sudah kita lihat di Bab 16, threads menyediakan salah satu pendekatan buat konkurensi. Kita juga sudah melihat pendekatan lainnya di bab ini: memakai asinkron dengan futures dan streams. Kalau kita bertanya-tanya kapan harus memilih salah satu metode di atas metode lainnya, jawabannya adalah: tergantung! Dan di banyak kasus, pilihannya bukan antara threads atau asinkron, melainkan threads dan asinkron.
Banyak sistem operasi sudah menyuplai model konkurensi berbasis threading selama puluhan tahun, dan banyak bahasa pemrograman yang jadi menyokongnya sebagai hasilnya. Namun, model-model ini bukannya tanpa pertukaran (tradeoffs). Di banyak sistem operasi, tiap thread memakan memori dalam jumlah yang cukup besar. Threads juga cuma jadi opsi pas sistem operasi dan perangkat keras kita memang menyokongnya. Beda sama komputer desktop dan ponsel arus utama, beberapa sistem embedded bahkan tidak punya sistem operasi sama sekali, jadinya mereka juga tidak punya threads.
Model asinkron menyediakan kumpulan tradeoffs yang berbeda—dan pada akhirnya
saling melengkapi. Di dalam model asinkron, operasi konkuren tidak mewajibkan
adanya thread masing-masing. Sebagai gantinya, mereka bisa berjalan di atas
tasks (tugas), kayak pas kita memakai trpl::spawn_task buat memulai
pekerjaan dari sebuah fungsi sinkron di bagian streams. Sebuah task itu
mirip sama thread, tapi bukannya dikelola oleh sistem operasi, ia dikelola
sama kode di tingkat library: yaitu runtime.
Ada alasannya kenapa API buat menelurkan threads dan menelurkan tasks itu sangat mirip. Threads bertindak sebagai batas (boundary) buat sekumpulan operasi sinkron; konkurensi dimungkinkan di antara threads. Tasks bertindak sebagai batas buat sekumpulan operasi asinkron; konkurensi dimungkinkan baik di antara maupun di dalam tasks, karena sebuah task bisa berganti-ganti di antara futures di dalam isinya. Terakhir, futures adalah unit konkurensi Rust yang paling spesifik (granular), dan tiap future bisa merepresentasikan sebuah pohon berisi futures lainnya. Runtime—lebih spesifiknya, executor-nya—mengelola tasks, dan tasks mengelola futures. Dalam hal tersebut, tasks itu mirip kayak threads yang ringan dan dikelola sama runtime dengan tambahan kapabilitas yang datang dari fakta bahwa ia dikelola sama runtime bukannya sama sistem operasi.
Ini tidak berarti kalau async tasks itu selalu lebih baik dibanding threads
(atau sebaliknya). Konkurensi memakai threads dalam beberapa hal merupakan
model pemrograman yang lebih simpel dibanding konkurensi memakai async. Itu
bisa jadi kekuatan atau kelemahan. Threads itu semacam “nyalakan dan lupakan”
(fire and forget); mereka nggak punya padanan asli terhadap future, jadi
mereka sekadar jalan sampai selesai tanpa bisa diinterupsi kecuali oleh sistem
operasinya sendiri.
Dan ternyata threads dan tasks itu sering kali bekerja barengan dengan
sangat baik, karena tasks (setidaknya di beberapa runtimes) bisa dipindah-
pindahkan antar threads. Bahkan, di balik layar, runtime yang sudah kita
pakai—termasuk fungsi spawn_blocking dan spawn_task—sifatnya adalah multi-
threaded secara bawaan! Banyak runtimes memakai pendekatan bernama work
stealing buat memindah-mindahkan tasks antar threads secara transparan,
berdasarkan gimana tiap thread tersebut sedang dimanfaatkan saat itu, demi
meningkatkan performa keseluruhan sistem. Pendekatan tersebut sebenarnya
mewajibkan adanya threads dan tasks, dan oleh karenanya juga futures.
Pas memikirkan metode mana yang mau dipakai kapan, coba pertimbangkan aturan praktis (rules of thumb) berikut:
- Kalau pekerjaannya sangat bisa diparalelkan (yaitu, CPU-bound), kayak memproses sekumpulan data di mana tiap bagiannya bisa diproses secara terpisah, threads adalah pilihan yang lebih oke.
- Kalau pekerjaannya sangat konkuren (yaitu, I/O-bound), kayak menangani pesan-pesan dari sekumpulan sumber berbeda yang mungkin datang di interval atau kecepatan yang berbeda-beda, asinkron adalah pilihan yang lebih oke.
Dan kalau kita butuh baik paralelisme maupun konkurensi, kita tidak harus memilih antara threads dan asinkron. Kita bisa memakai keduanya bersamaan dengan bebas, membiarkan masing-masing memainkan peran yang paling dikuasainya. Misalnya, Listing 17-25 menunjukkan contoh yang lumayan umum dari campuran kayak gini di kode Rust dunia nyata.
extern crate trpl; // for mdbook test
use std::{thread, time::Duration};
fn main() {
let (tx, mut rx) = trpl::channel();
thread::spawn(move || {
for i in 1..11 {
tx.send(i).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
trpl::block_on(async {
while let Some(message) = rx.recv().await {
println!("{message}");
}
});
}Kita mulai dengan membikin asinkron channel, terus menelurkan sebuah thread
yang mengambil kepemilikan dari sisi pengirim channel tersebut memakai keyword
move. Di dalam thread tersebut, kita mengirim angka 1 sampai 10, sambil
tidur selama satu detik di tiap angkanya. Terakhir, kita menjalankan sebuah
future yang dibuat pakai blok asinkron yang dioper ke trpl::block_on persis
kayak apa yang sudah kita lakukan di sepanjang bab ini. Di dalam future
tersebut, kita me-await pesan-pesan tadi, persis kayak di contoh-contoh
message-passing lainnya yang sudah kita lihat.
Buat balik lagi ke skenario yang kita buka di awal bab, bayangkan menjalankan sekumpulan tugas video encoding memakai thread khusus (karena video encoding itu sifatnya compute-bound) tapi memberikan notifikasi ke UI kalau operasi tersebut sudah selesai memakai asinkron channel. Ada banyak sekali contoh dari jenis kombinasi kayak gini di kasus penggunaan dunia nyata.
Ringkasan
Ini bukan kali terakhir kita melihat soal konkurensi di buku ini. Proyek di Bab 21 bakal menerapkan konsep-konsep ini di situasi yang lebih realistis dibanding contoh-contoh simpel yang dibahas di sini dan membandingkan penyelesaian masalah memakai threading versus tasks dan futures secara lebih langsung.
Metode mana pun yang kita pilih, Rust memberi kita alat-alat yang kita butuhkan buat menulis kode konkuren yang aman dan kencang—baik itu buat web server yang high-throughput maupun buat sistem operasi embedded.
Berikutnya, kita bakal ngomongin soal cara yang idiomatik buat memodelkan masalah dan menstrukturkan solusi seiring dengan semakin besarnya program Rust kita. Selain itu, kita bakal membahas gimana kaitan antara idiom milik Rust dengan idiom yang mungkin kita sudah familier di pemrograman berorientasi objek (object-oriented programming).
Fitur Pemrograman Berorientasi Objek
Pemrograman berorientasi objek (object-oriented programming, disingkat OOP) adalah sebuah cara buat memodelkan program. Objek (objects) sebagai sebuah konsep terprogram diperkenalkan pada bahasa pemrograman Simula di tahun 1960-an. Objek-objek tersebut memengaruhi arsitektur pemrograman buatan Alan Kay di mana objek-objek bisa saling melempar pesan satu sama lain. Buat mendeskripsikan arsitektur ini, dia mencetuskan istilah object-oriented programming di tahun 1967. Ada banyak definisi yang saling bersaing mengenai apa itu OOP, dan berdasarkan beberapa dari definisi-definisi tersebut Rust bisa dibilang berorientasi objek, tapi berdasarkan definisi lainnya dia bukan. Di bab ini, kita bakal mengeksplorasi ciri-ciri tertentu yang umumnya dianggap berorientasi objek dan gimana ciri-ciri itu diterjemahkan (translated) ke Rust yang idiomatik. Kita lalu bakal menunjukkan ke kita gimana cara mengimplementasikan sebuah desain pola (design pattern) berorientasi objek di Rust dan membahas trade-offs (kelebihan dan kekurangan) dari melakukannya dibandingkan dengan mengimplementasikan solusi yang memanfaatkan kekuatan- kekuatan dari Rust itu sendiri.
Ciri-ciri Bahasa Pemrograman Berorientasi Objek
Ciri-ciri Bahasa Pemrograman Berorientasi Objek
Tidak ada konsensus (kesepakatan umum) di komunitas pemrograman mengenai fitur- fitur apa aja yang wajib dimiliki oleh sebuah bahasa supaya bisa dianggap berorientasi objek. Rust dipengaruhi oleh banyak paradigma pemrograman, termasuk OOP; misalnya, kita sudah mengeksplorasi fitur-fitur yang datang dari pemrograman fungsional (functional programming) di Bab 13. Walaupun bisa diperdebatkan (arguably), bahasa pemrograman OOP biasanya berbagi ciri-ciri umum tertentu, yakni objek, encapsulation (enkapsulasi), dan inheritance (pewarisan). Mari kita lihat apa arti dari masing-masing ciri tersebut dan apakah Rust mendukungnya atau tidak.
Objek Mengandung Data dan Perilaku (Behavior)
Buku Design Patterns: Elements of Reusable Object-Oriented Software karangan Erich Gamma, Richard Helm, Ralph Johnson, dan John Vlissides (Addison-Wesley, 1994), yang secara santai sering disebut sebagai buku The Gang of Four, adalah sebuah katalog berisi desain pola berorientasi objek. Buku itu mendefinisikan OOP dengan cara ini:
Program berorientasi objek dibikin dari objek-objek. Sebuah objek membungkus (packages) baik data maupun prosedur-prosedur yang beroperasi pada data tersebut. Prosedur-prosedur tersebut biasanya disebut methods atau operations.
Memakai definisi ini, Rust itu berorientasi objek: structs dan enums punya
data, dan blok impl menyediakan methods pada structs dan enums tersebut.
Meskipun structs dan enums yang dilengkapi methods tidak disebut sebagai
objek, mereka menyediakan fungsionalitas yang sama, menurut definisi objek dari
the Gang of Four.
Encapsulation yang Menyembunyikan Detail Implementasi
Aspek lain yang umumnya dikaitkan dengan OOP adalah ide tentang encapsulation (enkapsulasi), yang berarti kalau detail implementasi dari sebuah objek itu tidak bisa diakses (accessible) oleh kode yang memakai objek tersebut. Oleh karena itu, satu-satunya cara buat berinteraksi dengan sebuah objek adalah melalui API public-nya; kode yang memakai objek itu tidak seharusnya bisa menjangkau bagian internal dari si objek lalu mengubah data atau perilakunya secara langsung. Hal ini memungkinkan programmer untuk mengubah dan me-refactor bagian internal dari sebuah objek tanpa perlu mengubah kode yang memakai objek tersebut.
Kita sudah membahas cara mengontrol encapsulation di Bab 7: kita bisa memakai
keyword pub buat menentukan modul, tipe, fungsi, dan method mana saja di kode
kita yang seharusnya bersifat public, sementara secara default segala hal
lainnya bersifat private. Misalnya, kita bisa mendefinisikan sebuah struct
AveragedCollection yang punya field yang berisi vector dari nilai i32.
Struct tersebut juga bisa punya sebuah field yang berisi nilai rata-rata
(average) dari nilai-nilai di vector tersebut, yang berarti nilai rata-ratanya
tidak harus dihitung seketika (on demand) kapan pun seseorang membutuhkannya.
Dengan kata lain, AveragedCollection bakal menge-cache nilai rata-rata
yang sudah dihitung tersebut buat kita. Listing 18-1 punya definisi dari struct
AveragedCollection.
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}AveragedCollection yang memelihara daftar (list) dari angka integer dan nilai rata-rata dari item-item di koleksi tersebutStruct ini ditandai sebagai pub supaya kode lain bisa memakainya, tapi field-
field di dalam struct tersebut tetap bersifat private. Hal ini penting di
kasus ini karena kita pengen memastikan bahwa kapan pun sebuah nilai
ditambahkan atau dihapus dari list, nilai average juga harus di-update.
Kita melakukan ini dengan mengimplementasikan method add, remove, dan
average pada struct tersebut, seperti yang ditunjukkan di Listing 18-2.
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}
impl AveragedCollection {
pub fn add(&mut self, value: i32) {
self.list.push(value);
self.update_average();
}
pub fn remove(&mut self) -> Option<i32> {
let result = self.list.pop();
match result {
Some(value) => {
self.update_average();
Some(value)
}
None => None,
}
}
pub fn average(&self) -> f64 {
self.average
}
fn update_average(&mut self) {
let total: i32 = self.list.iter().sum();
self.average = total as f64 / self.list.len() as f64;
}
}add, remove, dan average pada AveragedCollectionPublic methods add, remove, dan average adalah satu-satunya cara buat
mengakses atau memodifikasi data di dalam sebuah instance AveragedCollection.
Saat sebuah item ditambahkan ke list memakai method add atau dihapus
memakai method remove, implementasi dari kedua method ini bakal memanggil
method private update_average yang juga menangani pembaruan pada field
average.
Kita membiarkan field list dan average tetap private sehingga tidak ada
cara buat kode eksternal (external code) buat menambahkan atau menghapus item
ke atau dari field list secara langsung; karena jika dibiarkan, field average
bisa jadi tidak sinkron saat list berubah. Method average mengembalikan nilai
yang ada di dalam field average, yang memungkinkan kode eksternal buat membaca
nilai average tersebut tapi tidak bisa memodifikasinya.
Karena kita udah mengenkapsulasi (encapsulated) detail implementasi dari struct
AveragedCollection, kita bisa gampang mengubah berbagai aspeknya, kayak
struktur datanya, di masa depan. Misalnya, kita bisa aja memakai sebuah
HashSet<i32> ketimbang Vec<i32> buat field list. Asalkan signature
dari public methods add, remove, dan average itu tetap sama, kode
yang memakai AveragedCollection tidak perlu berubah. Tapi, kalau seandainya
kita membikin list jadi public, hal ini belum tentu benar: HashSet<i32>
dan Vec<i32> punya method yang berbeda buat menambahkan dan menghapus item,
jadi kode eksternalnya kemungkinan besar juga harus diubah kalau mereka
awalnya memodifikasi list secara langsung.
Kalau encapsulation adalah aspek yang wajib dipunyai sama sebuah bahasa agar
bisa dianggap berorientasi objek, maka Rust memenuhi syarat tersebut. Pilihan
buat memakai pub atau tidak pada berbagai bagian kode memungkinkan adanya
encapsulation terhadap detail-detail implementasi.
Inheritance sebagai Sistem Tipe (Type System) dan Pembagian Kode (Code Sharing)
Inheritance (pewarisan) adalah sebuah mekanisme di mana sebuah objek bisa mewarisi (inherit) elemen-elemen dari definisi objek lain, dengan begitu ia mendapatkan data dan perilaku dari objek induk (parent object) tanpa kita harus mendefinisikannya lagi.
Kalau sebuah bahasa wajib punya inheritance buat bisa disebut berorientasi objek, maka Rust tidak termasuk dalam bahasa tersebut. Tidak ada cara buat mendefinisikan sebuah struct yang mewarisi field-field dan implementasi method dari struct induk tanpa memakai macro.
Namun, kalau kita udah biasa (used to) punya inheritance di alat (toolbox) pemrograman kita, kita bisa memakai solusi lain di Rust, tergantung dari alasan kenapa kita mencari inheritance tersebut sejak awal.
Kita biasanya bakal milih buat memakai inheritance karena dua alasan utama.
Alasan pertama adalah buat pemakaian ulang kode (reuse of code): kita bisa
mengimplementasikan perilaku tertentu untuk satu tipe, dan inheritance
memungkinkan kita buat memakai ulang implementasi tersebut buat tipe yang berbeda.
Kita bisa melakukan hal ini secara terbatas di kode Rust dengan memakai
default trait method implementations (implementasi bawaan pada trait method),
yang udah kita lihat di Listing 10-14 pas kita menambahkan implementasi default
dari method summarize pada trait Summary. Tipe apa pun yang
mengimplementasikan trait Summary bakal langsung punya method summarize yang
bisa dipakai padanya tanpa perlu nulis kode tambahan lagi. Ini mirip dengan
sebuah parent class (kelas induk) yang punya implementasi dari suatu method
dan sebuah inheriting child class (kelas anak yang mewarisi) yang juga ikutan
punya implementasi dari method tersebut. Kita juga bisa menimpa (override)
implementasi default dari method summarize pas kita mengimplementasikan
trait Summary, yang mana mirip kayak saat sebuah child class menimpa
implementasi method yang diwarisinya dari sebuah parent class.
Alasan lain memakai inheritance berkaitan dengan sistem tipenya: yakni memungkinkan sebuah tipe child (anak) buat dipakai di tempat-tempat yang sama kayak tipe parent (induk)-nya. Ini juga disebut dengan polymorphism (polimorfisme), yang berarti kita bisa mensubstitusikan (menggantikan) berbagai objek untuk satu sama lain pas runtime asalkan mereka berbagi karakteristik tertentu.
Polimorfisme
Buat banyak orang, polimorfisme itu sinonim dengan inheritance. Tapi dia sebenarnya adalah konsep yang lebih umum yang mengacu ke kode yang bisa bekerja bareng data dari berbagai macam tipe. Buat inheritance, tipe-tipe itu umumnya adalah subclasses (subkelas).
Sebaliknya, Rust memakai generics (generik) buat mengabstraksi bermacam- macam kemungkinan tipe dan trait bounds buat memaksakan batasan-batasan (constraints) pada apa yang wajib disediakan sama tipe-tipe tersebut. Ini kadang-kadang disebut sebagai bounded parametric polymorphism (polimorfisme parametrik terbatas).
Rust memilih serangkaian tradeoffs yang berbeda dengan tidak menawarkan inheritance. Inheritance sering kali punya risiko buat nge-share lebih banyak kode daripada yang diperlukan. Subclasses tidak seharusnya selalu berbagi semua karakteristik dari parent class mereka, tapi mereka bakal melakukan itu kalau pakai inheritance. Hal ini bisa bikin desain dari sebuah program jadi kurang fleksibel. Ini juga memunculkan kemungkinan memanggil method-method pada subclasses yang sebenarnya tidak masuk akal atau menyebabkan error gara-gara method-method itu nyatanya tidak berlaku (apply) buat subclass tersebut. Selain itu, beberapa bahasa cuma mengizinkan single inheritance (berarti satu subclass cuma boleh mewarisi dari satu kelas saja), yang lebih lanjut membatasi fleksibilitas dari desain sebuah program.
Atas alasan-alasan ini, Rust mengambil pendekatan yang berbeda yaitu dengan memakai trait objects (objek trait) sebagai ganti inheritance buat memungkinkan adanya polimorfisme. Mari kita lihat gimana cara trait objects bekerja.
Memakai Trait Objects Buat Mengabstraksi Perilaku Bersama
Memakai Trait Objects Buat Mengabstraksi Perilaku Bersama
Di Bab 8, kita sempat nyebut kalau salah satu batasan dari vectors adalah
bahwa mereka cuma bisa nyimpan elemen dari satu tipe aja. Kita membikin sebuah
solusi buat ngakalin hal ini (workaround) di Listing 8-9 di mana kita
mendefinisikan enum SpreadsheetCell yang punya varian-varian buat menampung
integers, floats, dan teks. Ini berarti kita bisa nyimpan tipe data yang
berbeda-beda di setiap sel tapi tetap punya sebuah vector yang merepresentasikan
satu baris sel. Ini adalah solusi yang sangat bagus kalau item-item yang mau kita
tukar-tukar (interchangeable) itu merupakan serangkaian tipe tetap yang udah
kita tahu pas kode kita di-compile.
Namun, kadang-kadang kita pengen supaya user library kita bisa memperluas
serangkaian tipe yang valid di suatu situasi tertentu. Buat nunjukin gimana
kita bisa mencapai hal ini, kita bakal membikin contoh alat graphical user
interface (GUI) yang beriterasi ngelewatin sebuah daftar (list) item,
lalu memanggil method draw pada masing-masing item tersebut buat menggambarnya
ke layar—sebuah teknik yang umum buat alat-alat GUI. Kita bakal membikin sebuah
library crate bernama gui yang mengandung struktur dari library GUI
tersebut. Crate ini mungkin bakal nyertakan beberapa tipe buat dipakai
orang-orang, kayak Button atau TextField. Selain itu, para pengguna gui
bakal pengen bikin tipe-tipe mereka sendiri yang bisa digambar: contohnya,
satu programmer mungkin bakal nambahin Image dan yang lain mungkin bakal nambahin
SelectBox.
Pas lagi nulis library-nya, kita tidak bisa tahu dan tidak bisa mendefinisikan
semua tipe yang mungkin pengen dibikin sama programmer lain nantinya. Tapi kita
tahu kalau gui itu perlu melacak (keep track of) banyak nilai dari
tipe yang berbeda-beda, dan dia perlu manggil method draw pada setiap
nilai yang bertipe beda-beda ini. Dia tidak perlu tahu persis apa yang bakal
terjadi pas kita manggil method draw tersebut, dia cuma butuh tahu kalau nilai
itu punya method tersebut dan tersedia buat kita panggil.
Buat ngelakuin ini di bahasa pemrograman yang punya inheritance (pewarisan),
kita mungkin bakal mendefinisikan sebuah class bernama Component yang
punya sebuah method bernama draw padanya. Kelas-kelas lainnya, kayak Button,
Image, dan SelectBox, bakal mewarisi (inherit) dari Component dan dengan
gitu bakal mewarisi juga method draw-nya. Mereka masing-masing bisa menimpa
(override) method draw tersebut buat mendefinisikan perilaku kustom mereka
sendiri, tapi framework-nya bisa memperlakukan semua tipe-tipe tersebut
seolah-olah mereka adalah instance dari Component dan memanggil draw pada
mereka. Tapi karena Rust tidak punya inheritance, kita butuh cara lain buat
menstrukturkan library gui tersebut supaya user bisa bikin tipe-tipe
baru yang kompatibel sama library kita.
Mendefinisikan sebuah Trait untuk Perilaku Umum (Common Behavior)
Buat mengimplementasikan perilaku yang kita pengen ada di gui, kita bakal
mendefinisikan sebuah trait bernama Draw yang bakal punya satu method
bernama draw. Terus kita bisa mendefinisikan sebuah vector yang menerima
sebuah trait object (objek trait). Sebuah trait object menunjuk ke sebuah
instance dari suatu tipe yang mengimplementasikan trait yang sudah kita
tentukan, dan juga menunjuk ke sebuah tabel yang dipakai buat nyari trait methods
pada tipe tersebut saat runtime. Kita membikin trait object dengan
menentukan semacam pointer, kayak referensi & atau smart pointer
Box<T>, lalu keyword dyn, dan lalu menentukan trait yang relevan. (Kita
bakal ngomongin alasan kenapa trait objects harus memakai pointer di
“Tipe-tipe yang Berukuran Dinamis dan Trait Sized”
di Bab 20.) Kita bisa memakai trait objects buat menggantikan tipe generik
atau tipe konkret. Di mana pun kita memakai sebuah trait object, sistem tipe
Rust bakal memastikan saat compile time bahwa nilai apa pun yang dipakai di
konteks tersebut bakal mengimplementasikan trait dari trait object itu.
Akibatnya, kita tidak perlu tahu semua tipe yang mungkin ada saat compile time.
Kita udah sempat nyebut kalau di Rust, kita menahan diri buat tidak nyebut
structs dan enums sebagai “objek” buat ngebedain mereka dari objek di bahasa
pemrograman lain. Di sebuah struct atau enum, data di fields struct-nya
dan perilakunya di blok impl itu dipisahkan, sedangkan di bahasa pemrograman lain,
data dan perilaku yang digabungkan jadi satu konsep itu yang sering kali
dilabeli sebagai sebuah objek. Trait objects berbeda dari objek di bahasa
lain dalam hal kita tidak bisa menambahkan data ke sebuah trait object. Trait
objects tidak berguna secara umum (generally useful) layaknya objek di bahasa
lain: tujuan spesifik mereka adalah memungkinkan abstraksi melewati berbagai
perilaku umum (common behavior).
Listing 18-3 menunjukkan gimana cara mendefinisikan sebuah trait bernama Draw
dengan satu method bernama draw.
pub trait Draw {
fn draw(&self);
}DrawSintaks ini seharusnya udah kerasa familier dari pembahasan kita soal gimana
cara mendefinisikan traits di Bab 10. Berikutnya datang beberapa sintaks baru:
Listing 18-4 mendefinisikan sebuah struct bernama Screen yang memegang sebuah
vector bernama components. Vector ini bertipe Box<dyn Draw>, yang mana adalah
sebuah trait object; dia jadi pengganti (stand-in) buat tipe apa pun di dalam
sebuah Box yang mengimplementasikan trait Draw.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}Screen dengan sebuah field components yang memegang sebuah vector berisi trait objects yang mengimplementasikan trait DrawPada struct Screen, kita bakal mendefinisikan sebuah method bernama run
yang bakal memanggil method draw pada masing-masing komponen (components)-nya,
seperti yang ditunjukkan di Listing 18-5.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}run pada Screen yang memanggil method draw pada tiap komponenIni bekerja dengan cara yang beda dari pas kita mendefinisikan sebuah struct
yang memakai sebuah parameter tipe generik (generic type parameter) dengan
trait bounds. Sebuah parameter tipe generik cuma bisa digantikan (substituted)
oleh satu tipe konkret aja pada satu waktu, sedangkan trait objects memungkinkan
banyak tipe konkret buat ngisi posisi trait object tersebut saat runtime.
Misalnya, kita bisa saja mendefinisikan struct Screen memakai tipe generik
dan sebuah trait bound, seperti di Listing 18-6.
pub trait Draw {
fn draw(&self);
}
pub struct Screen<T: Draw> {
pub components: Vec<T>,
}
impl<T> Screen<T>
where
T: Draw,
{
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}Screen dan method run-nya memakai generik dan trait boundsCara ini membatasi kita pada satu instance Screen yang punya daftar komponen yang
semuanya bertipe Button atau semuanya bertipe TextField. Kalau kita emang
cuma bakal punya koleksi yang homogen (sama semua jenisnya), memakai generik
dan trait bounds lebih disarankan karena definisi-definisinya bakal
di-monomorphize (diubah ke tipe spesifik) saat compile time buat memakai
tipe-tipe konkret tersebut.
Di sisi lain, dengan memakai method yang menggunakan trait objects, satu
instance Screen bisa memegang sebuah Vec<T> yang berisi sebuah Box<Button>
sekaligus sebuah Box<TextField>. Mari kita lihat gimana cara kerja ini, dan
nanti kita bakal ngebahas soal implikasi performa runtime-nya.
Mengimplementasikan Trait-nya
Sekarang kita bakal menambahkan beberapa tipe yang mengimplementasikan trait
Draw. Kita bakal menyediakan tipe Button. Sekali lagi, sebenarnya
mengimplementasikan library GUI itu ada di luar cakupan buku ini, jadi method
draw di sini tidak bakal punya implementasi yang berguna di isi fungsinya. Buat
ngebayangin seperti apa rupa dari implementasinya, sebuah struct Button
mungkin punya fields buat width, height, dan label, seperti yang
ditunjukkan di Listing 18-7.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
pub struct Button {
pub width: u32,
pub height: u32,
pub label: String,
}
impl Draw for Button {
fn draw(&self) {
// code to actually draw a button
}
}Button yang mengimplementasikan trait DrawFields width, height, dan label pada Button bakal beda dari fields
pada komponen-komponen lain; misalnya, tipe TextField mungkin punya fields
yang sama ditambah sebuah field placeholder. Masing-masing dari tipe yang mau
kita gambar di layar bakal mengimplementasikan trait Draw tapi mereka bakal
memakai kode yang berbeda di dalam method draw buat mendefinisikan gimana cara
menggambar tipe khusus tersebut, seperti yang dimiliki Button di sini
(tanpa kode GUI aslinya, seperti yang disebutkan sebelumnya). Tipe Button,
misalnya, mungkin punya blok impl tambahan yang mengandung method-method yang
berkaitan dengan apa yang terjadi saat seorang user mengklik tombol (button) itu.
Method-method semacam ini tidak bakal berlaku buat tipe kayak TextField.
Kalau seseorang yang memakai library kita memutuskan buat mengimplementasikan
sebuah struct SelectBox yang punya fields width, height, dan options,
mereka bakal mengimplementasikan trait Draw pada tipe SelectBox tersebut juga,
seperti yang ditunjukkan di Listing 18-8.
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
fn main() {}gui dan mengimplementasikan trait Draw pada sebuah struct SelectBoxUser dari library kita sekarang bisa menulis fungsi main mereka buat bikin
sebuah instance Screen. Ke instance Screen ini, mereka bisa menambahkan
sebuah SelectBox dan sebuah Button dengan menaruh masing-masing tipe
tersebut di dalam sebuah Box<T> buat menjadikannya trait object. Terus
mereka bisa manggil method run pada instance Screen tersebut, yang mana
bakal manggil draw pada masing-masing komponen. Listing 18-9 menunjukkan
implementasi ini.
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
use gui::{Button, Screen};
fn main() {
let screen = Screen {
components: vec![
Box::new(SelectBox {
width: 75,
height: 10,
options: vec![
String::from("Yes"),
String::from("Maybe"),
String::from("No"),
],
}),
Box::new(Button {
width: 50,
height: 10,
label: String::from("OK"),
}),
],
};
screen.run();
}Pas kita nulis library-nya, kita tidak tahu kalau seseorang mungkin bakal
nambahin tipe SelectBox, tapi implementasi Screen kita nyatanya bisa
beroperasi pada tipe yang baru tersebut dan menggambarnya karena SelectBox
mengimplementasikan trait Draw, yang artinya dia mengimplementasikan method
draw.
Konsep ini—yaitu peduli hanya pada pesan apa yang direspon sama sebuah nilai
ketimbang peduli sama tipe konkret dari nilai tersebut—itu mirip sama konsep
duck typing (tipe bebek) di bahasa pemrograman dengan tipe dinamis (dynamically
typed languages): kalau dia jalan kayak bebek dan kwek kayak bebek, maka dia pasti
bebek! Di dalam implementasi dari run pada Screen di Listing 18-5, run tidak
perlu tahu apa tipe konkret dari masing-masing komponen tersebut. Dia tidak
ngecek apakah sebuah komponen itu adalah instance dari sebuah Button atau sebuah
SelectBox, dia cuma manggil method draw pada komponen tersebut. Dengan
menentukan Box<dyn Draw> sebagai tipe dari nilai-nilai di vector components,
kita udah mendefinisikan Screen buat butuh nilai-nilai yang bisa kita
panggil method draw-nya.
Keuntungan dari memakai trait objects dan sistem tipe Rust buat nulis kode yang mirip sama kode yang memakai duck typing adalah bahwa kita tidak perlu repot ngecek apakah sebuah nilai mengimplementasikan suatu method tertentu atau enggak saat runtime, atau khawatir dapat error kalau sebuah nilai ternyata tidak mengimplementasikan sebuah method tapi kita tetep memanggilnya. Rust tidak bakal mengompilasi kode kita kalau nilai-nilainya tidak mengimplementasikan traits yang dibutuhkan sama trait objects tersebut.
Misalnya, Listing 18-10 menunjukkan apa yang terjadi kalau kita mencoba bikin
sebuah Screen dengan sebuah String sebagai komponennya.
use gui::Screen;
fn main() {
let screen = Screen {
components: vec![Box::new(String::from("Hi"))],
};
screen.run();
}Kita bakal dapat error ini karena String tidak mengimplementasikan trait
Draw:
$ cargo run
Compiling gui v0.1.0 (file:///projects/gui)
error[E0277]: the trait bound `String: Draw` is not satisfied
--> src/main.rs:5:26
|
5 | components: vec![Box::new(String::from("Hi"))],
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `Draw` is not implemented for `String`
|
= help: the trait `Draw` is implemented for `Button`
= note: required for the cast from `Box<String>` to `Box<dyn Draw>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `gui` (bin "gui") due to 1 previous error
Error ini ngasih tahu kita kalau entah kita itu memberikan sesuatu ke Screen yang
sebenarnya tidak kita maksudkan untuk kita berikan dan oleh karena itu kita harusnya
memberikan tipe yang berbeda, atau kita harusnya mengimplementasikan Draw pada
String supaya Screen bisa memanggil draw pada String tersebut.
Trait Objects Melakukan Dynamic Dispatch
Ingat kembali di “Performa Kode yang Memakai Generik” di Bab 10 pembahasan kita soal proses monomorphization (monomorfisasi) yang dilakukan pada tipe generik oleh compiler: compiler membikin (generates) implementasi fungsi dan method yang non-generik (spesifik) buat setiap tipe konkret yang kita pakai buat gantiin parameter tipe generik tersebut. Kode hasil dari monomorphization ini melakukan static dispatch (pengiriman statis), yaitu ketika compiler sudah tahu method apa yang kita panggil saat compile time. Ini berlawanan dengan dynamic dispatch (pengiriman dinamis), yaitu ketika compiler tidak bisa tahu pasti pas compile time method mana yang kita panggil. Di kasus dynamic dispatch, compiler menghasilkan (emits) kode yang saat runtime baru bakal mencari tahu method mana yang harus dipanggil.
Saat kita memakai trait objects, Rust pasti memakai dynamic dispatch. Compiler tidak tahu semua tipe yang mungkin dipakai bersama kode yang lagi memakai trait objects tersebut, jadi dia tidak tahu method yang mana (yang diimplementasikan pada tipe yang mana) yang harus dipanggil. Alih-alih begitu, saat runtime, Rust memakai pointer yang ada di dalam trait object buat mencari tahu method mana yang harus dipanggil. Pencarian (lookup) ini menimbulkan beban runtime (runtime cost) yang tidak terjadi pada static dispatch. Dynamic dispatch juga mencegah compiler dari memilih buat meng-inline (menyisipkan kode secara langsung) kode dari sebuah method, yang mana berakibat mencegah (prevents) dilakukannya beberapa optimasi lain. Rust juga punya beberapa aturan soal di mana kita boleh dan tidak boleh memakai dynamic dispatch, yang disebut dyn compatibility (kompatibilitas dinamis). Aturan-aturan itu ada di luar cakupan pembahasan ini, tapi kita bisa baca lebih lanjut soal itu di referensinya. Namun, kita dapat kebebasan ekstra (extra flexibility) di dalam kode yang kita tulis di Listing 18-5 dan berhasil mendukung tipe baru di Listing 18-9, jadi ini adalah trade-off (pertukaran) yang patut dipertimbangkan.
Mengimplementasikan Desain Pola Object-Oriented
Mengimplementasikan Desain Pola Object-Oriented
State pattern (pola status) adalah sebuah desain pola object-oriented (berorientasi objek). Inti dari pola ini adalah kita mendefinisikan serangkaian states (status/keadaan) yang bisa dimiliki oleh suatu nilai di dalamnya (internally). States ini direpresentasikan oleh sekumpulan state objects, dan perilaku dari nilai tersebut berubah berdasarkan state yang dia miliki saat itu. Kita bakal mengerjakan contoh berupa struct postingan blog yang punya field buat menampung state-nya, yang mana bakal berupa state object dari serangkaian pilihan: “draft” (draf), “review” (tinjauan), atau “published” (dipublikasikan).
Objek-objek state ini saling berbagi fungsionalitas: di Rust, tentu saja, kita memakai struct dan traits bukannya objek dan pewarisan (inheritance). Setiap state object bertanggung jawab buat perilakunya sendiri dan mengatur kapan dia harus berubah jadi state lain. Nilai yang menampung state object tersebut sama sekali tidak tahu tentang perilaku yang berbeda dari setiap state atau kapan waktu yang tepat buat bertransisi (transition) antar states.
Keuntungan dari memakai state pattern ini adalah, saat ada perubahan persyaratan bisnis (business requirements) di program kita, kita tidak perlu mengubah kode dari nilai yang menampung state-nya atau kode yang memakai nilai tersebut. Kita cuma perlu meng-update kode di dalam salah satu state objects buat ngubah aturan-aturannya atau mungkin nambahin state objects baru.
Pertama-tama kita bakal mengimplementasikan state pattern pakai cara yang lebih tradisional ala object-oriented, terus kita bakal memakai pendekatan yang lebih natural di Rust. Mari kita gali pelan-pelan buat mengimplementasikan workflow (alur kerja) postingan blog pakai state pattern.
Fungsionalitas akhirnya bakal kelihatan kayak gini:
- Postingan blog bermula dari draft kosong.
- Saat draft-nya beres, sebuah review dari postingan itu diminta (requested).
- Saat postingannya disetujui (approved), dia bakal di-publish (dipublikasikan).
- Cuma postingan blog yang udah di-publish yang mengembalikan konten buat dicetak, jadi postingan yang belum disetujui tidak bakal bisa tidak sengaja ke-publish.
Perubahan lain yang dicoba dilakukan pada postingan tersebut seharusnya tidak bisa mengubah apa pun. Misalnya, kalau kita mencoba men-approve sebuah postingan draft sebelum kita me-request review, postingan itu seharusnya tetap berupa draft yang belum di-publish.
Percobaan Object-Oriented yang Tradisional
Ada sangat banyak cara buat menata struktur kode buat menyelesaikan masalah yang sama, masing-masing dengan trade-offs (kekurangan/kelebihan) yang beda. Implementasi di bagian ini memakai gaya object-oriented yang lebih tradisional, yang mana bisa ditulis di Rust, tapi tidak memanfaatkan beberapa dari kekuatan unggulan yang dimiliki Rust. Nanti, kita bakal mendemonstrasikan solusi lain yang tetap memakai desain pola object-oriented tapi disusun sedemikian rupa hingga mungkin kelihatan kurang familier buat programmer yang punya pengalaman object-oriented. Kita bakal membandingkan kedua solusi ini buat ngalamin langsung trade-offs dari mendesain kode di Rust dengan cara yang beda daripada nulis kode di bahasa lain.
Listing 18-11 menunjukkan workflow ini dalam bentuk kode: ini adalah contoh
pemakaian dari API yang bakal kita implementasikan di sebuah library crate
bernama blog. Ini masih belum bisa di-compile karena kita belum
mengimplementasikan crate blog-nya.
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}blog kitaKita mau ngebolehin user bikin postingan blog draft baru pakai Post::new. Kita
mau ngebolehin teks buat ditambahin ke postingan blog itu. Kalau kita nyoba ngambil
konten (content) dari postingan itu langsung, sebelum adanya approval, kita tidak
seharusnya dapat teks apa pun karena postingannya masih berupa draft. Kita udah
nambahin assert_eq! di kode ini buat tujuan demonstrasi aja. Pengujian unit test
yang cakep sekali buat ini adalah dengan menegaskan (assert) kalau postingan blog
draft mengembalikan string kosong dari method content, tapi kita tidak bakal
nulis tests buat contoh ini.
Berikutnya, kita mau memungkinkan adanya permintaan (request) buat me-review
postingan tersebut, dan kita pengen method content tetap mengembalikan string
kosong selama masih nungguin review. Pas postingannya udah dapat approval,
dia harusnya langsung ke-publish, yang berarti teks dari postingan tersebut bakal
dikembalikan saat method content dipanggil.
Perhatikan bahwa satu-satunya tipe yang kita pakai buat berinteraksi dari crate ini
adalah tipe Post. Tipe ini bakal memakai state pattern dan bakal menampung
sebuah nilai yang merupakan salah satu dari tiga state objects yang mewakili
berbagai macam state yang mungkin ada pada suatu postingan—draft, review,
atau published. Perubahan dari satu state ke state lainnya bakal dikelola
secara internal di dalam tipe Post. States-nya berubah sebagai respons
terhadap method-method yang dipanggil sama para pengguna library kita pada
instance Post tersebut, tapi mereka sendiri tidak perlu ngurusin (manage)
perubahan state-nya secara langsung. Selain itu, user juga tidak bisa ngelakuin
kesalahan pada states-nya, kayak nge-publish sebuah postingan sebelum dia
di-review.
Mendefinisikan Post dan Membikin Instance Baru di State Draft
Mari kita mulai ngimplementasiin library-nya! Kita tahu kita butuh sebuah
struct public Post yang menampung beberapa konten, jadi kita bakal mulai dengan
definisi dari struct tersebut dan fungsi associated public bernama new buat
bikin sebuah instance dari Post, seperti yang ditunjukkan di Listing 18-12. Kita
juga bakal bikin trait private bernama State yang bakal mendefinisikan
perilaku yang wajib dimiliki sama semua state objects buat Post.
Terus, Post bakal menampung sebuah trait object berupa Box<dyn State> di dalam
sebuah Option<T> di sebuah field private bernama state buat naruh si
state object. Kita bakal ngelihat kenapa Option<T> ini dibutuhkan sebentar lagi.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
}
trait State {}
struct Draft {}
impl State for Draft {}Post dan fungsi new yang ngebikin instance Post baru, trait State, dan struct DraftTrait State mendefinisikan perilaku yang di-share (dibagi) oleh states dari
postingan yang beda-beda. State objects-nya adalah Draft, PendingReview,
dan Published, dan mereka semua bakal mengimplementasikan trait State. Buat
sekarang, trait-nya belum punya method apa-apa, dan kita bakal mulai dengan cuma
mendefinisikan state Draft aja karena itu adalah state awal (start) yang kita
pengen ada di sebuah postingan.
Pas kita membikin Post baru, kita nge-set field state-nya jadi sebuah nilai
Some yang nampung sebuah Box. Box ini menunjuk ke sebuah instance baru dari
struct Draft. Hal ini memastikan bahwa kapan pun kita membikin instance baru
dari Post, dia bakal selalu mulai sebagai draft. Karena field state pada
Post itu private, tidak ada cara buat membikin sebuah Post di state
selain draft! Di fungsi Post::new, kita menge-set field content jadi String
baru yang masih kosong.
Menyimpan Teks dari Konten Postingan
Kita udah lihat di Listing 18-11 kalau kita pengen bisa memanggil method bernama
add_text lalu ngasih dia sebuah &str yang kemudian ditambahkan sebagai teks
konten dari postingan blog tersebut. Kita mengimplementasikan ini sebagai sebuah
method, bukannya ngekspos field content sebagai pub, supaya nanti kita bisa
mengimplementasikan sebuah method yang bakal ngontrol gimana data di field content
ini bisa dibaca. Method add_text ini lumayan straightforward (sederhana), jadi
mari kita tambahin implementasinya di Listing 18-13 ke dalam blok impl Post.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}
trait State {}
struct Draft {}
impl State for Draft {}add_text buat nambahin teks ke content di sebuah postinganMethod add_text menerima referensi mutable ke self karena kita mau mengubah
instance Post tempat kita manggil add_text. Kemudian kita memanggil push_str
pada String di content dan masukin argumen text buat ditambahin ke content
yang udah tersimpan. Perilaku ini tidak bergantung pada state yang lagi
dimiliki postingan, jadi ini bukanlah bagian dari state pattern. Method
add_text tidak berinteraksi dengan field state sama sekali, tapi dia adalah
bagian dari perilaku yang mau kita dukung (support).
Memastikan Konten dari Postingan Draft Itu Kosong
Bahkan setelah kita manggil add_text dan nambahin beberapa konten ke postingan
kita, kita tetap pengen method content buat mengembalikan string slice kosong
karena postingannya masih ada di state draft, kayak yang ditunjukin di baris 7
di Listing 18-11. Buat sekarang, mari kita implementasikan method content dengan
cara paling simpel yang bisa menuhi persyaratan ini: selalu mengembalikan string
slice kosong. Kita bakal mengubah ini nanti pas kita udah ngimplementasiin
kemampuan buat mengubah state postingan jadi bisa di-publish. Sejauh ini,
postingan cuma bisa ada di state draft, jadi konten postingan harus selalu
kosong. Listing 18-14 menunjukkan implementasi placeholder (sementara) ini.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
}
trait State {}
struct Draft {}
impl State for Draft {}content pada Post yang selalu ngembaliin string slice kosongDengan method content yang ditambahkan ini, semua yang ada di Listing 18-11
sampai baris 7 bakal jalan sesuai rencana.
Meminta Review Bakal Mengubah State dari Postingan
Berikutnya, kita perlu nambahin fungsionalitas buat meminta sebuah review dari
sebuah postingan, yang mana bakal mengubah state-nya dari Draft jadi
PendingReview. Listing 18-15 nunjukin kodenya.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
}request_review pada Post dan trait StateKita ngasih Post sebuah method public bernama request_review yang bakal
menerima referensi mutable ke self. Terus kita memanggil method internal
request_review pada state saat ini dari Post, dan method request_review
yang kedua ini bakal mengonsumsi state saat ini dan mengembalikan state yang
baru.
Kita nambahin method request_review ke trait State; semua tipe yang
mengimplementasikan trait tersebut sekarang juga harus mengimplementasikan method
request_review. Perhatikan bahwa ketimbang pakai self, &self, atau &mut self
sebagai parameter pertama di method ini, kita malah pakai self: Box<Self>.
Sintaks ini berarti method tersebut cuma valid pas dipanggil pada sebuah Box
yang nampung tipe tersebut. Sintaks ini ngambil kepemilikan (ownership) atas
Box<Self>, yang bakal membikin state yang lama jadi tidak valid sehingga
nilai state dari Post bisa berubah jadi state yang baru.
Buat mengonsumsi state yang lama, method request_review butuh mengambil
kepemilikan dari nilai state-nya. Di sinilah Option yang ada di field state
milik Post kepake: kita memanggil method take buat mengambil (take out)
nilai Some dari field state dan ninggalin nilai None di tempatnya karena
Rust tidak ngebolehin kita punya field yang tidak berisi apa-apa (unpopulated
fields) di dalam struct. Ini memungkinkan kita mindahin nilai state keluar dari
Post ketimbang meminjamnya (borrowing). Terus kita bakal menge-set nilai
state dari postingannya ke hasil dari operasi ini.
Kita perlu nge-set state ke None untuk sementara waktu ketimbang menge-setnya
secara langsung pakai kode seperti self.state = self.state.request_review();
supaya kita bisa dapat kepemilikan atas nilai state-nya. Ini memastikan Post
tidak bisa memakai nilai state yang lama setelah kita udah ngubah dia jadi
state yang baru.
Method request_review pada Draft mengembalikan sebuah instance baru yang
dibungkus Box dari sebuah struct baru bernama PendingReview, yang mana
merepresentasikan state saat sebuah postingan lagi nunggu review. Struct
PendingReview juga mengimplementasikan method request_review tapi dia tidak
melakukan perubahan (transformations) apa pun. Sebaliknya, dia ngembaliin dirinya
sendiri (returns itself) karena kalau kita meminta review pada postingan yang
emang udah ada di state PendingReview, dia seharusnya tetap berada di state
PendingReview.
Sekarang kita bisa mulai ngelihat keuntungan dari state pattern: method
request_review pada Post itu sama persis terlepas dari apa nilai state-nya.
Setiap state bertanggung jawab atas aturannya sendiri.
Kita bakal biarin method content pada Post apa adanya, yang mana bakal
ngembaliin string slice kosong. Kita sekarang bisa punya Post di state
PendingReview maupun di state Draft, tapi kita pengen perilaku yang sama di
state PendingReview. Listing 18-11 sekarang udah bisa jalan sampai baris ke-10!
Menambahkan approve buat Mengubah Perilaku dari content
Method approve bakal mirip sama method request_review: dia bakal menge-set
state ke nilai yang dibilang sama state saat ini sebagai nilai yang harusnya
dia miliki saat state itu di-approve, seperti yang ditunjukin di Listing 18-16.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}approve pada Post dan trait StateKita nambahin method approve ke trait State dan nambahin struct baru yang
mengimplementasikan State, yaitu state Published.
Mirip sama cara kerja request_review di PendingReview, kalau kita memanggil
method approve pada sebuah Draft, hal itu tidak bakal punya efek apa-apa karena
approve bakal mengembalikan self. Saat kita memanggil approve pada
PendingReview, dia mengembalikan instance baru yang dibungkus Box dari struct
Published. Struct Published mengimplementasikan trait State, dan baik untuk
method request_review maupun method approve, dia mengembalikan dirinya sendiri
karena postingan seharusnya tetap berada di state Published dalam kasus-kasus
tersebut.
Sekarang kita perlu meng-update method content pada Post. Kita mau supaya nilai
yang dikembalikan dari content itu bergantung sama state saat ini dari si Post,
jadi kita bakal membikin si Post mendelegasikan (delegate) panggilan ini ke method
content yang didefinisikan pada state-nya, seperti yang ditunjukin di Listing
18-17.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
// --snip--
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}content pada Post buat mendelegasikan panggilan ke method content pada StateKarena tujuan utamanya adalah buat menyimpan semua aturan ini di dalam struct-struct
yang mengimplementasikan State, kita memanggil sebuah method content pada nilai
yang ada di dalam state dan memasukkan instance dari postingan tersebut (yaitu,
self) sebagai argumen. Terus kita mengembalikan nilai yang dikembalikan dari
pemakaian method content pada nilai state tadi.
Kita memanggil method as_ref pada Option tersebut karena kita cuma pengen referensi
ke nilai yang ada di dalam Option, bukannya ngambil kepemilikan dari nilai itu
sendiri. Karena state adalah Option<Box<dyn State>>, pas kita manggil as_ref,
yang dikembalikan adalah Option<&Box<dyn State>>. Kalau kita tidak memanggil
as_ref, kita bakal dapat error karena kita tidak bisa mindahin state ke luar
dari referensi pinjaman (borrowed reference) &self dari parameter fungsinya.
Terus kita memanggil method unwrap, yang mana kita tahu pasti tidak bakal pernah
menyebabkan panic karena kita tahu method-method pada Post memastikan kalau state
bakal selalu berisi nilai Some saat method-method itu selesai dijalankan. Ini
adalah salah satu kasus yang kita obrolin di “Kasus Di Mana kita Punya Lebih
Banyak Informasi Daripada Compiler” di Bab 9, di mana kita
tahu pasti kalau nilai None itu mustahil, meskipun compiler tidak mampu buat
memahami hal itu.
Pada titik ini, pas kita memanggil content pada &Box<dyn State>, fitur deref
coercion (paksaan dereferensi) bakal bekerja pada tanda & dan Box tersebut,
sehingga pada akhirnya method content bakal dipanggil pada tipe yang
mengimplementasikan trait State. Itu artinya kita perlu nambahin content ke
definisi trait State, dan di sanalah kita bakal menaruh logika soal konten mana
yang harus dikembalikan tergantung di state mana kita berada sekarang, kayak
yang ditunjukin di Listing 18-18.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
fn content<'a>(&self, post: &'a Post) -> &'a str {
""
}
}
// --snip--
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
fn content<'a>(&self, post: &'a Post) -> &'a str {
&post.content
}
}content ke trait StateKita nambahin sebuah implementasi default (bawaan) buat method content yang
mengembalikan string slice kosong. Itu artinya kita tidak perlu repot-repot
mengimplementasikan content di struct Draft dan PendingReview. Nah, buat struct
Published, kita bakal menimpa (override) method content ini lalu mengembalikan
nilai yang ada di post.content. Walaupun praktis, membiarkan method content di
State yang menentukan apa isi dari content milik Post itu agak mengaburkan garis
batas antara apa yang jadi tanggung jawab State dan apa yang jadi tanggung
jawab Post.
Perhatikan bahwa kita juga butuh anotasi lifetime (waktu hidup) di method ini,
seperti yang kita bahas di Bab 10. Kita menerima referensi ke sebuah post sebagai
argumen dan mengembalikan sebuah referensi ke bagian dari post itu, jadi lifetime
dari referensi yang dikembalikan itu berkaitan erat sama lifetime dari argumen
post tersebut.
Dan kita udah selesai—semua kode di Listing 18-11 sekarang berjalan sesuai rencana!
Kita sudah berhasil mengimplementasikan state pattern dengan aturan-aturan dari
workflow postingan blog. Logika yang berkaitan sama aturan-aturannya kini hidup di
dalam state objects ketimbang bertebaran (scattered) ke mana-mana di dalam Post.
Kenapa Tidak Pake Enum Aja?
kita mungkin bingung dan nanya-nanya kenapa kita tidak pakai sebuah enum aja buat
berbagai macam kemungkinan state postingan tersebut sebagai varian-variannya.
Itu emang salah satu solusi yang mungkin; cobain aja terus bandingin hasil akhirnya
buat ngelihat mana yang lebih kita suka! Satu kekurangan dari memakai enum adalah
di setiap tempat yang ngecek nilai dari enum itu, kita bakal butuh ekspresi match
atau sejenisnya buat menangani setiap kemungkinan varian yang ada. Ini bisa jadi
jauh lebih berulang-ulang (repetitive) ketimbang solusi yang memakai trait
object ini.
Trade-offs dari State Pattern
Kita udah nunjukin kalau Rust itu mampu buat mengimplementasikan state pattern
ala object-oriented buat mengenkapsulasi (encapsulate) berbagai jenis perilaku yang
seharusnya dimiliki sama sebuah postingan di tiap state-nya. Method-method pada Post
sama sekali tidak tahu soal perilaku yang bermacam-macam itu. Dengan cara kita menata
kode ini, kita cuma perlu ngecek di satu tempat buat tahu bermacam-macam cara
gimana sebuah postingan yang di-publish bisa berperilaku: yaitu di implementasi
trait State pada struct Published.
Seandainya kita membikin implementasi alternatif yang tidak pakai state pattern,
kita mungkin bakal milih buat pakai ekspresi match di dalam method-method pada
Post atau bahkan di dalam kode main yang ngecek state dari postingannya dan
mengubah perilaku di tempat-tempat itu. Itu artinya kita harus ngecek di beberapa tempat
buat bisa paham semua implikasi dari sebuah postingan saat ia berada di state
published.
Dengan state pattern, method-method di Post dan tempat-tempat di mana kita memakai
Post tidak butuh ekspresi match, dan buat nambahin sebuah state baru, kita cuma
perlu nambahin satu struct baru lalu mengimplementasikan trait methods pada struct
baru itu di satu tempat aja.
Implementasi yang memakai state pattern ini gampang sekali buat diperluas buat nambahin lebih banyak fungsionalitas. Buat ngelihat sendiri seberapa simpelnya memelihara (maintaining) kode yang pakai state pattern, coba deh beberapa saran ini:
- Tambahin method
reject(tolak) yang ngubah state postingan dariPendingReviewbalik lagi keDraft. - Wajibkan (require) dua panggilan ke
approvesebelum state-nya bisa berubah jadiPublished. - Izinkan (allow) user buat nambahin teks konten cuma pas postingan lagi ada
di state
Draft. Petunjuk: biarin state object yang bertanggung jawab soal apa yang mungkin berubah terkait konten, tapi jangan biarin dia bertanggung jawab buat memodifikasiPostsecara langsung.
Satu kelemahan dari state pattern ini adalah karena states-nya sendirilah yang
mengimplementasikan proses transisi (perpindahan) ke state lain, beberapa states
jadi terikat (coupled) satu sama lain. Kalau kita nambahin state lain di antara
PendingReview dan Published, seperti Scheduled (dijadwalkan), kita harus mengubah
kode di PendingReview buat bertransisi ke Scheduled sebagai gantinya. Bakal lebih
sedikit kerjaannya kalau seandainya PendingReview tidak perlu diubah pas kita
nambahin state baru, tapi itu berarti kita harus beralih ke desain pola yang beda
(another design pattern).
Kelemahan lainnya adalah kita jadi menduplikasi beberapa logika. Buat menghilangkan
sebagian dari duplikasi ini, kita mungkin nyoba buat bikin implementasi default buat
method request_review dan approve di trait State yang selalu mengembalikan
self. Namun, ini tidak bakal jalan: pas kita pakai State sebagai trait object,
trait itu tidak tahu apa tipe konkret yang bakal jadi self-nya nanti, jadi
tipe kembalian (return type) itu tidak bisa diketahui saat compile time. (Ini
adalah salah satu dari aturan dyn compatibility yang udah disebutin sebelumnya.)
Duplikasi lainnya termasuk implementasi method request_review dan approve
yang mirip-mirip di Post. Kedua method itu memakai Option::take dengan field
state milik Post, dan kalau state itu isinya Some, mereka mendelegasikannya
ke implementasi nilai yang dibungkus tersebut buat method yang sama lalu menge-set
nilai baru dari field state dengan hasil panggilannya. Kalau kita punya
sangat banyak method di Post yang ngikutin pola ini, kita mungkin bakal
pertimbangin buat mendefinisikan sebuah macro buat ngebuang pengulangan ini
(lihat “Macros” di Bab 20).
Dengan mengimplementasikan state pattern persis kayak yang didefinisikan buat bahasa
pemrograman object-oriented, kita nyatanya tidak memanfaatkan kekuatan unggulan Rust
semaksimal mungkin. Mari kita lihat beberapa perubahan yang bisa kita lakukan pada
crate blog yang bisa ngebikin invalid states (state yang tidak valid) dan
transisi yang salah menjadi error saat compile-time (compile-time errors).
Menge-encode States dan Perilaku (Behavior) ke dalam Types (Tipe)
Kita bakal nunjukin gimana cara memikirkan ulang (rethink) state pattern buat dapat kumpulan trade-offs yang berbeda. Ketimbang mengenkapsulasi states dan transisi secara keseluruhan supaya kode luar tidak tahu apa-apa soal mereka, kita bakal menge-encode (menyandikan) states ke dalam tipe-tipe yang berbeda-beda. Konsekuensinya, sistem pengecekan tipe Rust (type checking system) bakal mencegah usaha (attempts) buat memakai postingan draft di tempat-tempat yang mana cuma postingan yang udah published (dipublikasikan) yang boleh dipakai, dengan ngeluarin error compiler.
Mari kita perhatikan bagian awal dari main di Listing 18-11:
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}Kita tetep mau ngasih kemampuan buat bikin postingan baru di state draft memakai
Post::new dan kemampuan buat nambahin teks ke dalam konten postingannya. Tapi
ketimbang punya sebuah method content pada postingan draft yang cuma ngembaliin
string kosong, kita malah bakal membikin supaya postingan draft itu sama sekali
tidak punya method content. Dengan begitu, kalau kita nyoba ngambil konten
dari postingan draft, kita bakal dapat error compiler yang ngasih tahu kita
kalau method itu tidak eksis. Sebagai hasilnya, bakal jadi mustahil bagi kita
buat secara tidak sengaja menampilkan konten dari postingan draft pas udah masuk
production (produksi), karena kodenya aja tidak bakal bisa di-compile.
Listing 18-19 nunjukin definisi struct Post dan struct DraftPost, beserta method
yang ada pada keduanya.
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}Post yang punya method content dan DraftPost yang tidak punya method contentBaik struct Post maupun DraftPost punya field private bernama content yang
nyimpen teks dari postingan blog tersebut. Struct-struct ini tidak lagi punya
field state karena kita udah mindahin encoding dari state-nya ke dalam tipe
dari struct-struct itu. Struct Post bakal merepresentasikan sebuah postingan yang
udah di-publish, dan dia punya method content yang bakal ngembaliin nilai dari
content.
Kita tetap punya fungsi Post::new, tapi ketimbang mengembalikan sebuah instance dari
Post, dia sekarang mengembalikan sebuah instance dari DraftPost. Karena content
itu sifatnya private dan tidak ada fungsi lain yang ngembaliin Post, maka mustahil
buat membikin sebuah instance dari Post saat ini.
Struct DraftPost punya sebuah method add_text, jadi kita bisa nambahin teks ke
dalam content sama kayak sebelumnya, tapi perhatikan kalau DraftPost tidak
punya method content yang didefinisikan! Jadi sekarang programnya memastikan
kalau semua postingan selalu bermula sebagai postingan draft, dan postingan
draft ini belum punya konten yang bisa ditampilkan. Usaha apa pun buat ngakalin
atau ngelewatin batasan-batasan ini bakal ngasilin error compiler.
Lalu gimana dong caranya kita dapet postingan yang udah ke-publish? Kita mau
menegakkan aturan bahwa sebuah postingan draft itu wajib di-review dan
di-approve (disetujui) sebelum bisa di-publish. Postingan yang lagi ada di
state pending review (nunggu review) juga seharusnya masih belum bisa nampilin
konten apa pun. Mari kita implementasikan batasan-batasan ini dengan menambahkan struct
baru, PendingReviewPost, lalu mendefinisikan method request_review pada
DraftPost yang bakal mengembalikan PendingReviewPost dan mendefinisikan method
approve pada PendingReviewPost yang bakal mengembalikan Post, seperti yang
ditunjukin di Listing 18-20.
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
// --snip--
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn request_review(self) -> PendingReviewPost {
PendingReviewPost {
content: self.content,
}
}
}
pub struct PendingReviewPost {
content: String,
}
impl PendingReviewPost {
pub fn approve(self) -> Post {
Post {
content: self.content,
}
}
}PendingReviewPost yang dibikin lewat manggil request_review pada DraftPost dan method approve yang mengubah PendingReviewPost jadi sebuah Post yang ke-publishMethod request_review dan approve mengambil kepemilikan (ownership) dari self,
dengan begitu mengonsumsi instance DraftPost dan PendingReviewPost lalu mengubah
(transforming) mereka secara berurutan menjadi PendingReviewPost dan Post yang
ke-publish. Dengan cara ini, kita tidak bakal punya sisa-sisa (lingering) instance
dari DraftPost setelah kita memanggil request_review pada mereka, dan seterusnya.
Struct PendingReviewPost tidak punya method content padanya, jadi usaha buat
ngebaca kontennya bakal menghasilkan error compiler, persis kayak DraftPost. Karena
satu-satunya cara buat dapetin instance Post yang udah ke-publish (yang mana emang
punya method content padanya) adalah dengan manggil method approve pada sebuah
PendingReviewPost, dan satu-satunya cara buat dapetin PendingReviewPost adalah
dengan manggil method request_review pada sebuah DraftPost, kita sekarang
telah berhasil menge-encode workflow dari postingan blog ini ke dalam sistem tipe
(type system) di Rust.
Tapi kita juga harus membikin beberapa perubahan kecil di main. Method
request_review dan approve mengembalikan instance baru alih-alih memodifikasi
struct tempat mereka dipanggil, jadi kita perlu nambahin assignment shadowing
let post = lagi buat nyimpen instance-instance baru yang dikembalikan itu. Kita
juga tidak bisa lagi punya penegasan (assertions) soal postingan draft maupun
postingan yang nunggu review punya konten string kosong, tapi kita juga tidak butuh
penegasan itu lagi kok: kita emang udah tidak bisa lagi nge-compile kode yang mencoba
buat memakai konten dari postingan yang ada di states tersebut. Kode yang udah
di-update di main ini ditunjukin di Listing 18-21.
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
let post = post.request_review();
let post = post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}main buat memakai implementasi yang baru dari workflow postingan blog kitaPerubahan-perubahan yang perlu kita lakuin di main buat me-reassign nilai ke
post berarti kalau implementasi ini udah tidak bener-bener ngikutin state pattern
ala object-oriented lagi: transisi-transisi antara states tersebut udah tidak lagi
dienkapsulasi sepenuhnya di dalam implementasi Post. Namun, keuntungan yang kita
dapat adalah bahwa invalid states sekarang jadi mustahil terjadi berkat sistem
tipe dan type checking (pengecekan tipe) yang terjadi saat compile time! Ini
memastikan kalau beberapa jenis bugs tertentu, seperti nge-display (nampilin) konten
dari postingan yang belum di-publish, bakal ketahuan jauh-jauh sebelum kodenya
berhasil masuk ke production.
Cobalah beberapa tugas yang disarankan di awal bagian ini pada crate blog
setelah memakai desain yang ada di Listing 18-21 buat melihat apa pendapat kita
soal desain dari versi kode yang ini. Perhatikan kalau beberapa dari tugas
tersebut mungkin emang udah terselesaikan secara natural di desain yang ini.
Kita udah melihat kalau walaupun Rust itu mampu mengimplementasikan desain pola object-oriented, pola-pola lain, kayak nge-encode state ke dalam sistem tipe, juga tersedia dan bisa diimplementasikan di Rust. Pola-pola ini punya kumpulan trade-offs yang beda-beda. Walaupun kita mungkin udah familier sekali sama pola-pola object-oriented, memikirkan kembali (rethinking) masalahnya buat memanfaatkan fitur-fitur dari Rust bisa ngasih banyak keuntungan, seperti mencegah munculnya bugs tertentu saat compile time. Pola-pola object-oriented tidak bakal selalu jadi solusi yang terbaik di Rust karena adanya fitur-fitur tertentu, seperti ownership, yang mana memang tidak dipunyai oleh bahasa-bahasa pemrograman object-oriented lainnya.
Ringkasan
Terlepas dari apakah kita mikir kalau Rust itu adalah sebuah bahasa yang object-oriented atau bukan setelah baca bab ini, kita sekarang udah tahu kalau kita bisa memakai trait objects buat dapetin beberapa fitur ala object-oriented di Rust. Dynamic dispatch bisa ngasih kode kita sedikit keluwesan (flexibility) yang harus dibayar dengan sedikit pinalti di performa runtime. Kita bisa memakai keluwesan ini buat mengimplementasikan pola-pola object-oriented yang bisa ngebantu kode kita supaya lebih gampang dipelihara (maintainability). Rust juga punya fitur lain, kayak ownership, yang tidak dipunyai sama bahasa-bahasa object-oriented pada umumnya. Sebuah pola object-oriented tidak bakal selalu jadi cara yang paling oke buat memanfaatkan kekuatan dari Rust, tapi dia jelas adalah salah satu pilihan yang tersedia.
Berikutnya, kita bakal melihat patterns (pola), yang mana merupakan fitur Rust lainnya yang juga ngasih keluwesan tingkat tinggi. Kita udah ngelihat sedikit soal pola-pola ini di sepanjang buku, tapi kita belum ngelihat potensi penuh dari kemampuan mereka. Ayo gas!
Pola (Patterns) dan Pencocokan (Matching)
Patterns (pola) adalah sebuah sintaks spesial di Rust buat mencocokkan (matching)
struktur dari berbagai tipe, baik yang kompleks maupun yang sederhana. Memakai
patterns bersamaan dengan ekspresi match dan konstruk-konstruk lainnya
ngasih kita kontrol yang lebih banyak terhadap control flow (alur kontrol)
dari sebuah program. Sebuah pattern terdiri dari beberapa kombinasi dari
hal-hal berikut ini:
- Literals (nilai harfiah)
- Array, enum, struct, atau tuple yang di-destructure (dipecah-pecah)
- Variabel
- Wildcards (kartu liar)
- Placeholders (tempat pengganti)
Beberapa contoh patterns meliputi x, (a, 3), dan Some(Color::Red). Di
dalam konteks di mana patterns itu valid, komponen-komponen ini mendeskripsikan
bentuk (shape) dari suatu data. Program kita kemudian mencocokkan nilai
dengan patterns tersebut buat menentukan apakah nilai tersebut punya bentuk
data yang tepat buat melanjutkan eksekusi potongan kode tertentu.
Buat memakai sebuah pattern, kita membandingkannya dengan suatu nilai.
Kalau pattern tersebut cocok dengan nilainya, kita memakai bagian-bagian dari
nilai itu di dalam kode kita. Ingat kembali ekspresi match di Bab 6 yang
memakai patterns, kayak di contoh mesin penyortir koin. Kalau nilainya cocok
sama bentuk dari pattern-nya, kita bisa memakai potongan-potongan yang udah
dikasih nama. Kalau tidak cocok, kode yang terkait sama pattern tersebut tidak
bakal dijalankan.
Bab ini adalah sebuah referensi tentang semua hal yang berkaitan dengan patterns. Kita bakal membahas tempat-tempat valid di mana kita bisa memakai patterns, perbedaan antara refutable (bisa dibantah/bisa gagal) dan irrefutable (tidak bisa dibantah/pasti sukses) patterns, serta berbagai macam sintaks pattern yang mungkin bakal kita temui. Di akhir bab ini, kita bakal tahu gimana cara memakai patterns buat mengekspresikan banyak konsep dengan cara yang jelas.
Semua Tempat di Mana Patterns Bisa Dipakai
Semua Tempat di Mana Patterns Bisa Dipakai
Patterns muncul di berbagai tempat di Rust, dan kita sebenarnya udah sering sekali memakai mereka tanpa menyadarinya! Bagian ini membahas semua tempat di mana patterns itu valid untuk dipakai.
Lengan (Arms) dari match
Seperti yang sudah dibahas di Bab 6, kita memakai patterns di arms
(lengan) dari ekspresi match. Secara formal, ekspresi match didefinisikan
sebagai keyword match, sebuah nilai yang mau dicocokkan, dan satu atau
lebih match arms yang terdiri dari sebuah pattern dan sebuah ekspresi
buat dijalankan kalau nilainya cocok dengan pattern di arm tersebut,
kayak gini:
match NILAI {
PATTERN => EKSPRESI,
PATTERN => EKSPRESI,
PATTERN => EKSPRESI,
}Misalnya, ini adalah ekspresi match dari Listing 6-5 yang mencocokkan sebuah
nilai Option<i32> di dalam variabel x:
match x {
None => None,
Some(i) => Some(i + 1),
}Patterns di ekspresi match ini adalah None dan Some(i) yang ada di
sebelah kiri dari setiap tanda panah.
Satu persyaratan untuk ekspresi match adalah mereka harus bersifat
exhaustive (menyeluruh/tuntas) yang berarti semua kemungkinan nilai buat
ekspresi match tersebut harus ditangani (accounted for). Salah satu cara
buat memastikan kita udah mencakup semua kemungkinannya adalah dengan memakai
catch-all pattern (pola penangkap-semua) buat arm terakhirnya: misalnya,
memakai nama variabel yang bakal cocok dengan nilai apa pun itu tidak bakal
pernah gagal dan karena itu mencakup semua kasus yang tersisa.
Pattern spesifik _ bakal cocok dengan apa pun, tapi ia tidak pernah
mengikat (bind) nilainya ke dalam sebuah variabel, jadi ia sering kali
dipakai di match arm yang paling akhir. Pattern _ ini bisa berguna pas
kita mau mengabaikan nilai apa pun yang tidak ditentukan (unspecified),
sebagai contoh. Kita bakal membahas pattern _ lebih detail di “Mengabaikan
Nilai di dalam sebuah Pattern” nanti di bab ini.
Statement let
Sebelum bab ini, kita cuma secara eksplisit ngebahas pemakaian patterns bersama
match dan if let, tapi pada kenyataannya, kita udah memakai patterns di
tempat lain juga, termasuk di dalam statement let. Misalnya, coba lihat
pemberian nilai (variable assignment) langsung pakai let ini:
#![allow(unused)]
fn main() {
let x = 5;
}Setiap kali kita memakai statement let kayak gini, kita sebenernya udah
memakai patterns, biarpun kita mungkin tidak menyadarinya! Lebih
formalnya, sebuah statement let itu kelihatannya kayak gini:
let PATTERN = EKSPRESI;
Di statement seperti let x = 5; di mana nama variabel ada di posisi PATTERN,
nama variabel itu hanyalah bentuk yang paling sederhana dari sebuah pattern.
Rust membandingkan ekspresi tersebut dengan pattern-nya lalu memberikan
nilai (assigns) ke nama-nama yang ia temukan. Jadi, di contoh let x = 5;, x
adalah sebuah pattern yang artinya “ikat (bind) apa pun yang cocok di
sini ke variabel x.” Karena nama x adalah keseluruhan pattern-nya, pattern
ini pada praktiknya berarti “ikat semuanya ke variabel x, apa pun nilainya.”
Buat ngelihat aspek pattern-matching (pencocokan pola) dari let dengan
lebih jelas, coba lihat Listing 19-1, yang memakai sebuah pattern bareng
let buat men-destructure (memecah) sebuah tuple.
fn main() {
let (x, y, z) = (1, 2, 3);
}Di sini, kita mencocokkan sebuah tuple terhadap sebuah pattern. Rust
membandingkan nilai (1, 2, 3) dengan pattern (x, y, z) dan melihat kalau
nilainya cocok dengan pattern tersebut, dalam arti dia melihat kalau jumlah
elemennya sama di kedua sisinya, jadi Rust mengikat 1 ke x, 2 ke y,
dan 3 ke z. Kita bisa membayangkan tuple pattern ini seolah-olah menyarangkan
(nesting) tiga variable patterns individu di dalamnya.
Kalau jumlah elemen di dalam pattern-nya tidak cocok dengan jumlah elemen di dalam tuple-nya, tipe keseluruhannya tidak bakal cocok dan kita bakal dapat error compiler. Misalnya, Listing 19-2 menunjukkan sebuah percobaan buat men-destructure sebuah tuple yang berisi tiga elemen ke dalam dua variabel, yang mana tidak bakal jalan.
fn main() {
let (x, y) = (1, 2, 3);
}Mencoba men-compile kode ini bakal menghasilkan type error (error tipe) ini:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0308]: mismatched types
--> src/main.rs:2:9
|
2 | let (x, y) = (1, 2, 3);
| ^^^^^^ --------- this expression has type `({integer}, {integer}, {integer})`
| |
| expected a tuple with 3 elements, found one with 2 elements
|
= note: expected tuple `({integer}, {integer}, {integer})`
found tuple `(_, _)`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Buat memperbaiki error-nya, kita bisa mengabaikan satu atau lebih nilai di
dalam tuple tersebut memakai _ atau .., kayak yang bakal kita lihat
di bagian “Mengabaikan Nilai di dalam sebuah Pattern”.
Kalau masalahnya adalah kita punya terlalu banyak variabel di dalam pattern-nya,
solusinya adalah mencocokkan (match) tipe-tipenya dengan membuang variabel-variabel
tersebut sehingga jumlah variabelnya sama dengan jumlah elemen di tuple-nya.
Ekspresi Bersyarat (Conditional) if let
Di Bab 6, kita ngebahas gimana cara memakai ekspresi if let yang mana
utamanya dipakai sebagai cara yang lebih singkat buat menulis bentuk ekuivalen
(setara) dari sebuah match yang cuma mencocokkan satu kasus aja. Secara
opsional, if let bisa dipasangkan dengan else yang berisi kode buat
dijalankan kalau pattern di dalam if let tersebut tidak cocok.
Listing 19-3 menunjukkan kalau kita juga bisa mencampur dan mencocokkan
(mix and match) ekspresi if let, else if, dan else if let. Ngelakuin hal
ini ngasih kita fleksibilitas yang lebih besar ketimbang ekspresi match
di mana kita cuma bisa mengekspresikan satu nilai aja buat dibandingkan dengan
semua patterns-nya. Selain itu, Rust tidak mewajibkan agar kondisi-kondisi
di dalam rangkaian lengan (arms) if let, else if, dan else if let itu
saling berhubungan satu sama lain.
Kode di Listing 19-3 menentukan warna apa yang bakal dijadikan warna background (latar belakang) berdasarkan serangkaian pengecekan pada beberapa kondisi. Untuk contoh ini, kita sudah membikin variabel-variabel dengan nilai yang di-hardcode (ditulis langsung) yang mana di program sungguhan mungkin aja nilai-nilai ini didapat dari input user.
fn main() {
let favorite_color: Option<&str> = None;
let is_tuesday = false;
let age: Result<u8, _> = "34".parse();
if let Some(color) = favorite_color {
println!("Using your favorite color, {color}, as the background");
} else if is_tuesday {
println!("Tuesday is green day!");
} else if let Ok(age) = age {
if age > 30 {
println!("Using purple as the background color");
} else {
println!("Using orange as the background color");
}
} else {
println!("Using blue as the background color");
}
}if let, else if, else if let, dan elseKalau user menentukan sebuah warna favorit, warna itu bakal dipakai sebagai background. Kalau tidak ada warna favorit yang ditentukan dan hari ini adalah hari Selasa (Tuesday), warna background-nya adalah hijau (green). Selain itu, kalau user menentukan umurnya sebagai sebuah string dan kita bisa mem-parse-nya jadi sebuah angka dengan sukses, warnanya bakal jadi ungu (purple) atau oranye (orange) tergantung dari nilai angkanya. Kalau tidak ada satu pun dari kondisi ini yang berlaku, warna background-nya adalah biru (blue).
Struktur kondisional (bersyarat) ini membiarkan kita mendukung persyaratan yang
kompleks. Dengan nilai-nilai hardcoded yang kita punya di sini, contoh ini bakal
mencetak Using purple as the background color.
Kita bisa melihat kalau if let juga bisa memperkenalkan variabel baru yang
menimpa (shadow) variabel yang sudah ada dengan cara yang sama kayak yang
dilakukan sama match arms: baris if let Ok(age) = age memperkenalkan
sebuah variabel age baru yang berisi nilai di dalam varian Ok-nya, menimpa
variabel age yang sudah ada sebelumnya. Ini artinya kita harus menaruh kondisi
if age > 30 di dalam blok tersebut: kita tidak bisa menggabungkan kedua
kondisi ini jadi if let Ok(age) = age && age > 30. Nilai age baru yang mau
kita bandingkan dengan 30 belum valid sampai scope (ruang lingkup) barunya
dimulai bersamaan dengan tanda kurung kurawal pembuka.
Kelemahan dari memakai ekspresi if let adalah kalau compiler tidak bakal
mengecek kelengkapannya (exhaustiveness), sedangkan dengan ekspresi match
compiler bakal mengeceknya. Kalau kita kelupaan menaruh blok else terakhir dan
oleh karenanya kelewatan (missed) buat menangani beberapa kasus, compiler
tidak bakal memperingatkan kita soal kemungkinan adanya logic bug (kutu logika)
tersebut.
Perulangan Bersyarat while let
Mirip dengan konstruksi if let, perulangan (loop) bersyarat while let
memungkinkan sebuah loop while buat terus berjalan selama sebuah pattern
masih terus cocok. Di Listing 19-4 kita menunjukkan sebuah loop while let
yang menunggu pesan-pesan yang dikirim antar threads, tapi di kasus ini
dia mengecek sebuah Result ketimbang sebuah Option.
fn main() {
let (tx, rx) = std::sync::mpsc::channel();
std::thread::spawn(move || {
for val in [1, 2, 3] {
tx.send(val).unwrap();
}
});
while let Ok(value) = rx.recv() {
println!("{value}");
}
}while let buat mencetak nilai-nilai selama rx.recv() mengembalikan OkContoh ini mencetak 1, 2, dan kemudian 3. Method recv mengambil
pesan pertama dari sisi penerima (receiver side) saluran (channel) tersebut dan
mengembalikan sebuah Ok(value). Saat pertama kali kita melihat recv
di Bab 16, kita langsung meng-unwrap error-nya, atau berinteraksi dengannya
layaknya sebuah iterator memakai sebuah loop for. Namun, seperti yang
ditunjukkan Listing 19-4, kita juga bisa memakai while let, karena method
recv mengembalikan sebuah Ok setiap kali ada pesan yang datang, selama si
pengirimnya (sender) masih eksis, lalu mengembalikan sebuah Err begitu
sisi pengirimnya memutuskan koneksi (disconnects).
Perulangan for
Di dalam loop for, nilai yang langsung mengikuti keyword for itu adalah
sebuah pattern. Misalnya, di dalam for x in y, x itu adalah pattern-nya.
Listing 19-5 mendemonstrasikan gimana cara memakai sebuah pattern di dalam loop
for buat men-destructure (memecah belah) sebuah tuple sebagai bagian dari
loop for tersebut.
fn main() {
let v = vec!['a', 'b', 'c'];
for (index, value) in v.iter().enumerate() {
println!("{value} is at index {index}");
}
}for buat men-destructure sebuah tupleKode di Listing 19-5 bakal mencetak yang berikut ini:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.52s
Running `target/debug/patterns`
a is at index 0
b is at index 1
c is at index 2
Kita mengadaptasi sebuah iterator memakai method enumerate sehingga ia
menghasilkan sebuah nilai beserta indeks buat nilai tersebut, yang ditaruh
di dalam sebuah tuple. Nilai pertama yang dihasilkan adalah tuple
(0, 'a'). Saat nilai ini dicocokkan dengan pattern (index, value),
index bakal jadi 0 dan value bakal jadi 'a', lalu mencetak
baris pertama dari outputnya.
Parameter Fungsi
Parameter dari sebuah fungsi juga bisa berupa patterns. Kode di Listing 19-6,
yang mendeklarasikan fungsi bernama foo yang menerima satu parameter bernama
x bertipe i32, harusnya sekarang udah terasa familier.
fn foo(x: i32) {
// code goes here
}
fn main() {}Bagian x itu adalah sebuah pattern lho! Sama kayak yang kita lakuin dengan
let, kita bisa mencocokkan sebuah tuple di dalam argumen sebuah fungsi
terhadap suatu pattern. Listing 19-7 memecah nilai-nilai di dalam sebuah
tuple saat kita meneruskannya ke sebuah fungsi.
fn print_coordinates(&(x, y): &(i32, i32)) {
println!("Current location: ({x}, {y})");
}
fn main() {
let point = (3, 5);
print_coordinates(&point);
}Kode ini mencetak Current location: (3, 5). Nilai-nilai &(3, 5) itu cocok
dengan pattern &(x, y), jadi x adalah nilai 3 dan y adalah nilai 5.
Kita juga bisa memakai patterns di dalam daftar parameter closure dengan cara yang sama seperti di dalam daftar parameter fungsi, karena closures itu mirip dengan fungsi, kayak yang udah dibahas di Bab 13.
Pada titik ini, kita udah melihat beberapa cara buat memakai patterns, tapi patterns tidak bekerja dengan cara yang sama persis di setiap tempat di mana kita bisa memakai mereka. Di beberapa tempat, patterns itu wajib bersifat irrefutable (tidak bisa dibantah/pasti sukses); di situasi lain, mereka bisa bersifat refutable (bisa dibantah/bisa gagal). Kita bakal ngebahas kedua konsep ini selanjutnya.
Refutability (Keterbantahan): Apakah sebuah Pattern Bisa Gagal Cocok?
Refutability (Keterbantahan): Apakah sebuah Pattern Bisa Gagal Cocok?
Patterns datang dalam dua bentuk: refutable (bisa dibantah/bisa gagal) dan
irrefutable (tidak bisa dibantah/pasti sukses). Patterns yang bakal selalu
cocok dengan kemungkinan nilai apa pun yang diberikan ke dia itu disebut
irrefutable. Contohnya adalah x di dalam statement let x = 5; karena x
cocok dengan apa aja dan oleh karena itu tidak mungkin gagal buat cocok.
Patterns yang bisa aja gagal buat cocok dengan beberapa kemungkinan nilai itu
disebut refutable. Contohnya adalah Some(x) di dalam ekspresi
if let Some(x) = a_value karena kalau nilai di variabel a_value ternyata
adalah None bukannya Some, maka pattern Some(x) itu tidak bakal cocok.
Parameter fungsi, statement let, dan loop for cuma bisa nerima patterns
yang irrefutable karena programnya tidak bisa ngelakuin hal berguna apa pun
kalau nilainya ternyata tidak cocok. Ekspresi if let dan while let serta
statement let...else bisa nerima patterns yang refutable maupun
irrefutable, tapi compiler bakal ngasih peringatan (warning) kalau kita
memakai patterns yang irrefutable di sana. Hal ini karena, secara definisi,
konstruk-konstruk tersebut memang ditujukan buat menangani kemungkinan gagal:
fungsionalitas dari sebuah kondisional ada pada kemampuannya buat melakukan
hal yang berbeda-beda tergantung pada apakah dia sukses atau gagal.
Secara umum, kita tidak perlu pusing mikirin perbedaan antara patterns yang refutable dan irrefutable; namun, kita tetap harus familier dengan konsep refutability ini supaya kita tahu apa yang harus dilakukan pas kita ngelihat istilah ini di dalam sebuah pesan error. Di kasus-kasus seperti itu, kita perlu mengubah entah pattern-nya atau konstruk tempat kita memakai pattern tersebut, tergantung dari perilaku yang kita inginkan buat kodenya.
Mari kita lihat sebuah contoh tentang apa yang terjadi pas kita nyoba memakai
sebuah pattern yang refutable di tempat di mana Rust mewajibkan pattern yang
irrefutable, dan sebaliknya. Listing 19-8 menunjukkan sebuah statement let,
tapi buat pattern-nya, kita menentukan Some(x), yang mana adalah sebuah
pattern yang refutable. Seperti yang mungkin kita tebak, kode ini tidak bakal
bisa di-compile.
fn main() {
let some_option_value: Option<i32> = None;
let Some(x) = some_option_value;
}letKalau some_option_value kebetulan bernilai None, maka dia bakal gagal buat
cocok sama pattern Some(x), yang artinya pattern tersebut adalah
refutable. Namun, statement let cuma bisa nerima pattern yang irrefutable
karena tidak ada aksi valid yang bisa dilakuin sama kodenya dengan sebuah nilai
None. Saat compile time, Rust bakal komplain kalau kita udah nyoba memakai
sebuah pattern refutable di tempat di mana sebuah pattern irrefutable
diwajibkan:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0005]: refutable pattern in local binding
--> src/main.rs:3:9
|
3 | let Some(x) = some_option_value;
| ^^^^^^^ pattern `None` not covered
|
= note: `let` bindings require an "irrefutable pattern", like a `struct` or an `enum` with only one variant
= note: for more information, visit https://doc.rust-lang.org/book/ch19-02-refutability.html
= note: the matched value is of type `Option<i32>`
help: you might want to use `let else` to handle the variant that isn't matched
|
3 | let Some(x) = some_option_value else { todo!() };
| ++++++++++++++++
For more information about this error, try `rustc --explain E0005`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Karena kita tidak mencakup (dan memang tidak bisa mencakup!) setiap kemungkinan
nilai yang valid dengan pattern Some(x), Rust dengan tepat menghasilkan error
compiler.
Kalau kita punya sebuah pattern refutable di tempat di mana pattern
irrefutable dibutuhkan, kita bisa memperbaikinya dengan mengubah kode yang
memakai pattern tersebut: ketimbang memakai let, kita bisa memakai
let else. Dengan begitu, kalau pattern-nya tidak cocok, kodenya bakal sekadar
melewati (skip) kode yang ada di dalam kurung kurawal, ngasih jalan (way out)
buat dia lanjut dengan cara yang valid. Listing 19-9 menunjukkan cara
memperbaiki kode di Listing 19-8.
fn main() {
let some_option_value: Option<i32> = None;
let Some(x) = some_option_value else {
return;
};
}let...else dan sebuah blok dengan patterns refutable bukannya letKita udah ngasih jalan keluar buat kodenya! Kode ini benar-benar valid sekarang,
meskipun ini berarti kita tidak bisa memakai sebuah pattern irrefutable tanpa
menerima sebuah peringatan. Kalau kita ngasih let...else sebuah pattern yang
bakal selalu cocok, kayak x, seperti yang ditunjukkan di Listing 19-10,
compiler bakal ngasih sebuah peringatan.
fn main() {
let x = 5 else {
return;
};
}let...elseRust komplain kalau tidak masuk akal buat memakai let...else dengan sebuah
pattern yang irrefutable:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
warning: irrefutable `let...else` pattern
--> src/main.rs:2:5
|
2 | let x = 5 else {
| ^^^^^^^^^
|
= note: this pattern will always match, so the `else` clause is useless
= help: consider removing the `else` clause
= note: `#[warn(irrefutable_let_patterns)]` on by default
warning: `patterns` (bin "patterns") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.39s
Running `target/debug/patterns`
Atas alasan ini, match arms wajib memakai patterns yang refutable, kecuali buat
arm yang paling terakhir, yang seharusnya mencocokkan sisa nilai apa pun yang belum
ditangani dengan sebuah pattern yang irrefutable. Rust mengizinkan kita buat
memakai sebuah pattern irrefutable di dalam sebuah match yang cuma punya satu
arm, tapi sintaks ini tidak terlalu berguna dan bisa aja diganti pakai sebuah
statement let yang lebih sederhana.
Sekarang karena kita udah tahu di mana aja bisa memakai patterns dan perbedaan antara patterns refutable dan irrefutable, mari kita bahas semua sintaks yang bisa kita pakai buat bikin patterns.
Sintaks Pattern
Sintaks Pattern
Di bagian ini, kita mengumpulkan semua sintaks yang valid buat dipakai di dalam patterns dan ngebahas kenapa dan kapan kita mungkin mau memakai masing-masing dari sintaks tersebut.
Mencocokkan Literals (Nilai Harfiah)
Seperti yang udah kita lihat di Bab 6, kita bisa mencocokkan patterns secara langsung dengan literals. Kode berikut ini ngasih beberapa contoh:
fn main() {
let x = 1;
match x {
1 => println!("one"),
2 => println!("two"),
3 => println!("three"),
_ => println!("anything"),
}
}Kode ini mencetak one karena nilai di dalam x adalah 1. Sintaks ini berguna
pas kita pengen kode kita mengambil suatu tindakan tertentu kalau dia dapat sebuah
nilai konkret yang spesifik.
Mencocokkan Variabel Bernama (Named Variables)
Variabel bernama adalah patterns irrefutable yang bakal cocok dengan nilai apa
pun, dan kita udah memakainya berkali-kali di buku ini. Namun, ada sedikit kerumitan
pas kita memakai variabel bernama di dalam ekspresi match, if let, atau
while let. Karena setiap jenis ekspresi ini memulai sebuah scope (ruang lingkup)
baru, variabel yang dideklarasikan sebagai bagian dari sebuah pattern di dalam
ekspresi ini bakal menimpa (shadow) variabel dengan nama yang sama yang ada di
luar konstruk tersebut, sama halnya kayak yang terjadi pada semua variabel di Rust.
Di Listing 19-11, kita mendeklarasikan sebuah variabel bernama x dengan nilai
Some(5) dan sebuah variabel y dengan nilai 10. Terus kita membikin ekspresi
match pada nilai x. Coba perhatikan patterns di dalam match arms-nya dan
println! di akhir, dan cobalah buat menebak apa yang bakal dicetak oleh kode ini
sebelum menjalankannya atau membaca lebih lanjut.
fn main() {
let x = Some(5);
let y = 10;
match x {
Some(50) => println!("Got 50"),
Some(y) => println!("Matched, y = {y}"),
_ => println!("Default case, x = {x:?}"),
}
println!("at the end: x = {x:?}, y = {y}");
}match dengan sebuah arm yang memperkenalkan variabel baru yang menimpa variabel y yang sudah adaMari kita telusuri apa yang terjadi pas ekspresi match ini dijalankan. Pattern
di arm pertama tidak cocok dengan nilai yang udah didefinisikan buat x, jadi kodenya
lanjut.
Pattern di arm kedua memperkenalkan sebuah variabel baru bernama y yang bakal cocok
dengan nilai apa pun yang ada di dalam sebuah nilai Some. Karena kita sekarang ada di
dalam scope baru di dalam ekspresi match ini, ini adalah variabel y yang baru,
bukannya y yang kita deklarasikan di awal tadi yang nilainya 10. Binding y
yang baru ini bakal cocok dengan nilai apa pun di dalam sebuah Some, yang mana
itulah yang kita punya di dalam x. Oleh karena itu, si y baru ini mengikat
(binds) dirinya ke nilai internal yang ada di dalam Some yang dimiliki x. Nilai
itu adalah 5, jadi ekspresi buat arm tersebut dieksekusi dan mencetak
Matched, y = 5.
Seandainya x tadi adalah sebuah nilai None bukannya Some(5), patterns di dua
arm pertama tidak bakal ada yang cocok, jadi nilainya bakal cocok sama si garis
bawah (underscore). Kita tidak memperkenalkan variabel x di dalam pattern buat
arm garis bawah ini, jadi si x di ekspresi tersebut tetap merujuk pada x yang
ada di luar yang belum tertimpa (unshadowed). Di kasus hipotetis (seandainya) ini,
si match bakal mencetak Default case, x = None.
Begitu ekspresi match ini selesai, scope-nya berakhir, dan scope buat si
y internal tadi juga berakhir. println! terakhir menghasilkan
at the end: x = Some(5), y = 10.
Buat membikin ekspresi match yang bisa membandingkan nilai-nilai dari x dan y
yang ada di luar, ketimbang memperkenalkan variabel baru yang malah menimpa variabel
y yang sudah ada, kita wajib memakai kondisional match guard sebagai gantinya.
Kita bakal ngebahas soal match guards nanti di “Kondisional Tambahan Memakai
Match Guards”.
Multiple Patterns (Banyak Pola Sekaligus)
Di dalam ekspresi match, kita bisa mencocokkan banyak patterns sekaligus dengan
memakai sintaks |, yang mana merupakan operator or (atau) buat pattern.
Misalnya, di kode berikut ini kita mencocokkan nilai x terhadap match arms-nya,
yang mana arm pertamanya punya sebuah opsi or, yang berarti kalau nilai dari x
itu cocok sama salah satu dari nilai yang ada di arm itu, kode milik arm itu bakal
dijalankan:
fn main() {
let x = 1;
match x {
1 | 2 => println!("one or two"),
3 => println!("three"),
_ => println!("anything"),
}
}Kode ini mencetak one or two.
Mencocokkan Rentang (Ranges) Nilai Memakai ..=
Sintaks ..= memungkinkan kita buat mencocokkan dengan sebuah rentang nilai yang
inklusif (inclusive range). Di kode berikut, saat sebuah pattern cocok sama
nilai apa pun yang ada di dalam rentang yang ditentukan, arm tersebut bakal dieksekusi:
fn main() {
let x = 5;
match x {
1..=5 => println!("one through five"),
_ => println!("something else"),
}
}Kalau x itu adalah 1, 2, 3, 4, atau 5, arm pertama bakal cocok. Sintaks
ini jauh lebih nyaman dipakai pas kita punya banyak nilai buat dicocokkan ketimbang
memakai operator | buat mengekspresikan ide yang sama; kalau kita memakai |,
kita harus menentukan 1 | 2 | 3 | 4 | 5. Menentukan sebuah rentang (range) itu jauh
lebih singkat, apalagi kalau kita mau mencocokkan, katakanlah, angka apa aja antara 1
dan 1.000!
Compiler mengecek kalau rentang tersebut tidak kosong pas compile time, dan
karena tipe-tipe yang mana Rust bisa tahu apakah sebuah rentang itu kosong atau
tidak itu cuma char dan nilai-nilai numerik aja, maka dari itu rentang (ranges)
cuma diizinkan buat nilai numerik atau char.
Berikut ini adalah contoh yang memakai rentang buat nilai char:
fn main() {
let x = 'c';
match x {
'a'..='j' => println!("early ASCII letter"),
'k'..='z' => println!("late ASCII letter"),
_ => println!("something else"),
}
}Rust bisa tahu kalau 'c' berada di dalam rentang pattern pertama dan lalu mencetak
early ASCII letter.
Destructuring (Membongkar) buat Memecah Nilai
Kita juga bisa memakai patterns buat men-destructure (membongkar/memecah belah) structs, enums, dan tuples supaya kita bisa memakai berbagai bagian-bagian yang berbeda dari nilai-nilai tersebut. Mari kita telusuri masing-masing dari mereka.
Destructuring Structs
Listing 19-12 menunjukkan sebuah struct Point yang punya dua fields (bidang),
x dan y, yang bisa kita pecah memakai sebuah pattern dengan statement let.
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
let Point { x: a, y: b } = p;
assert_eq!(0, a);
assert_eq!(7, b);
}Kode ini membikin variabel a dan b yang masing-masing cocok dengan nilai dari
field x dan y pada struct p. Contoh ini nunjukin kalau nama variabel-variabel
di dalam pattern-nya tidak harus sama dengan nama-nama field di dalam struct-nya.
Namun, sudah menjadi hal yang umum buat menyamakan nama variabelnya dengan nama
field-nya supaya lebih gampang buat diingat variabel mana yang berasal dari field mana.
Karena penggunaan umum ini, dan karena nulis let Point { x: x, y: y } = p; itu berisi
sangat banyak duplikasi, Rust punya bentuk singkat (shorthand) buat patterns yang
mencocokkan field struct: kita cuma perlu menyebutkan nama field struct-nya aja, dan
variabel yang dibikin dari pattern tersebut bakal punya nama yang sama. Listing
19-13 berperilaku persis sama kayak kode di Listing 19-12, tapi variabel yang dibikin
di pattern let-nya itu bernama x dan y bukannya a dan b.
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
let Point { x, y } = p;
assert_eq!(0, x);
assert_eq!(7, y);
}Kode ini membikin variabel x dan y yang cocok dengan field x dan y dari
variabel p. Hasilnya adalah variabel x dan y itu sekarang berisi nilai-nilai yang
ada dari struct p tersebut.
Kita juga bisa melakukan destructure memakai nilai literal (literal values) sebagai bagian dari pattern struct tersebut ketimbang membikin variabel buat semua field-nya. Melakukan hal ini memungkinkan kita buat ngetes (test) beberapa dari field tersebut terhadap suatu nilai tertentu sekaligus membikin variabel buat men-destructure field-field yang lain.
Di Listing 19-14, kita punya sebuah ekspresi match yang memisahkan nilai-nilai
Point ke dalam tiga kasus: titik yang terletak persis di sumbu x (yang mana
itu benar kalau y = 0), di sumbu y (x = 0), atau tidak di sumbu mana pun.
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
match p {
Point { x, y: 0 } => println!("On the x axis at {x}"),
Point { x: 0, y } => println!("On the y axis at {y}"),
Point { x, y } => {
println!("On neither axis: ({x}, {y})");
}
}
}Arm pertama bakal cocok sama titik apa pun yang terletak di sumbu x dengan menentukan
bahwa field y itu bakal dianggap cocok kalau nilainya cocok dengan literal 0.
Pattern-nya tetap membikin variabel x yang mana bisa kita pakai di kode buat
arm ini.
Serupa dengan itu, arm kedua mencocokkan titik apa pun yang ada di sumbu y dengan
menentukan bahwa field x itu bakal dianggap cocok kalau nilainya 0 dan
membikin sebuah variabel y buat nilai dari field y tersebut. Arm ketiga
sama sekali tidak menentukan literal apa pun, jadi ia cocok buat Point yang mana aja
dan membikin variabel buat kedua field x dan y.
Di contoh ini, nilai p itu cocok dengan arm kedua berkat fakta kalau x berisi
nilai 0, jadi kode ini bakal mencetak On the y axis at 7.
Ingat bahwa sebuah ekspresi match bakal berhenti ngecek lengan-lengan (arms) lain
begitu dia nemuin pattern pertama yang cocok, jadi biarpun Point { x: 0, y: 0}
itu ada di sumbu x sekaligus ada di sumbu y, kode ini cuma bakal mencetak
On the x axis at 0.
Destructuring Enums
Kita udah sering membongkar (destructured) enums di buku ini (misalnya, di Listing
6-5 di Bab 6), tapi kita belum pernah secara eksplisit ngebahas kalau pattern yang
dipakai buat membongkar sebuah enum itu berhubungan erat dengan gimana cara data
yang tersimpan di dalam enum tersebut didefinisikan. Sebagai contoh, di Listing
19-15 kita memakai enum Message dari Listing 6-2 lalu kita menulis sebuah match
yang punya patterns buat membongkar setiap nilai internalnya.
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {
let msg = Message::ChangeColor(0, 160, 255);
match msg {
Message::Quit => {
println!("The Quit variant has no data to destructure.");
}
Message::Move { x, y } => {
println!("Move in the x direction {x} and in the y direction {y}");
}
Message::Write(text) => {
println!("Text message: {text}");
}
Message::ChangeColor(r, g, b) => {
println!("Change color to red {r}, green {g}, and blue {b}");
}
}
}Kode ini bakal mencetak Change color to red 0, green 160, and blue 255. Cobalah
buat mengubah nilai dari msg buat melihat kode dari lengan-lengan yang lain itu
jalan.
Buat varian enum yang tidak punya data apa pun, kayak Message::Quit, kita tidak bisa
membongkar nilainya lebih jauh lagi. Kita cuma bisa mencocokkan terhadap literal nilai
Message::Quit secara langsung, dan tidak ada variabel sama sekali di dalam
pattern tersebut.
Buat varian enum yang bentuknya kayak struct (struct-like enum variants), seperti
Message::Move, kita bisa memakai sebuah pattern yang mirip sama pattern yang kita
tentukan buat mencocokkan structs. Setelah nama variannya, kita taruh kurung kurawal
lalu kita sebutkan field-fieldnya beserta variabelnya supaya kita bisa memecah-mecah
bagian-bagian itu buat dipakai di dalam kode untuk arm ini. Di sini kita memakai
bentuk singkat (shorthand) sama seperti yang kita lakuin di Listing 19-13.
Buat varian enum yang bentuknya kayak tuple (tuple-like enum variants), kayak
Message::Write yang menampung sebuah tuple dengan satu elemen dan
Message::ChangeColor yang menampung sebuah tuple dengan tiga elemen, pattern-nya
itu mirip sama pattern yang kita tentukan buat mencocokkan tuples. Jumlah variabel
di dalam pattern-nya itu harus cocok dengan jumlah elemen di dalam varian yang
lagi kita cocokkan tersebut.
Destructuring Structs dan Enums yang Bersarang (Nested)
Sejauh ini, contoh-contoh kita semuanya cuma mencocokkan structs atau enums dengan
kedalaman satu level aja (one level deep), tapi pencocokan itu bisa juga lho dipakai
buat item-item yang bersarang (nested items)! Misalnya, kita bisa merombak (refactor)
kode yang ada di Listing 19-15 buat ngedukung warna RGB maupun HSV di dalam pesan
ChangeColor, kayak yang ditunjukin di Listing 19-16.
enum Color {
Rgb(i32, i32, i32),
Hsv(i32, i32, i32),
}
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(Color),
}
fn main() {
let msg = Message::ChangeColor(Color::Hsv(0, 160, 255));
match msg {
Message::ChangeColor(Color::Rgb(r, g, b)) => {
println!("Change color to red {r}, green {g}, and blue {b}");
}
Message::ChangeColor(Color::Hsv(h, s, v)) => {
println!("Change color to hue {h}, saturation {s}, value {v}");
}
_ => (),
}
}Pattern dari arm pertama di ekspresi match itu cocok dengan varian enum
Message::ChangeColor yang mengandung varian Color::Rgb; dan kemudian pattern
itu bakal mengikat dirinya (binds) ke ketiga nilai i32 internal tersebut.
Pattern di arm kedua juga cocok dengan varian enum Message::ChangeColor, tapi
enum internalnya itu cocok dengan Color::Hsv sebagai gantinya. Kita bisa menentukan
kondisi-kondisi kompleks (complex conditions) ini semuanya di dalam satu ekspresi
match tunggal, meskipun ada dua enum yang dilibatkan.
Destructuring Structs dan Tuples Bersamaan
Kita bisa nyampur (mix), mencocokkan (match), dan menyarangkan (nest) destructuring patterns dengan cara yang bahkan lebih kompleks lagi. Contoh berikut nunjukin proses destructure yang lumayan rumit di mana kita menyarangkan structs dan tuples di dalam sebuah tuple lalu kita mengekstrak (destructure) semua nilai primitifnya sampai keluar (out):
fn main() {
struct Point {
x: i32,
y: i32,
}
let ((feet, inches), Point { x, y }) = ((3, 10), Point { x: 3, y: -10 });
}Kode ini membiarkan kita memecah tipe-tipe yang kompleks menjadi bagian-bagian komponen dasarnya (component parts) supaya kita bisa memakai nilai-nilai yang kita butuhkan secara terpisah.
Destructuring memakai patterns ini adalah cara yang nyaman sekali buat memakai potongan-potongan dari sebuah nilai, kayak misalnya nilai yang ada dari masing- masing field di dalam sebuah struct, secara terpisah dari satu sama lain.
Mengabaikan Nilai di dalam sebuah Pattern
kita udah melihat kalau kadang-kadang itu sangat berguna buat mengabaikan nilai-
nilai di dalam sebuah pattern, kayak misalnya di arm terakhir dari sebuah match,
buat ngedapetin catch-all yang tidak benar-benar ngelakuin apa-apa tapi tetep
mempertimbangkan (account for) semua kemungkinan nilai yang tersisa. Ada beberapa
cara buat mengabaikan seluruh nilai atau sebagian aja dari suatu nilai di dalam
sebuah pattern: dengan memakai pattern _ (yang udah kita lihat), dengan memakai
pattern _ di dalam pattern lainnya, dengan memakai nama yang diawali dengan
garis bawah (underscore), atau dengan memakai .. buat mengabaikan semua sisa bagian
dari sebuah nilai. Mari kita eksplorasi gimana dan kapan alasan yang tepat buat
memakai masing-masing patterns ini.
Mengabaikan Seluruh Nilai Memakai _
Kita udah memakai garis bawah (underscore) sebagai wildcard pattern (pola yang bisa
jadi apa saja) yang bakal cocok dengan nilai apa pun tapi tidak bakal mengikat
dirinya (bind) ke nilai tersebut. Ini sangat berguna dipakai sebagai arm terakhir di
dalam ekspresi match, tapi kita juga bisa memakainya di pattern mana aja lho,
termasuk di parameter fungsi, kayak yang ditunjukin di Listing 19-17.
fn foo(_: i32, y: i32) {
println!("This code only uses the y parameter: {y}");
}
fn main() {
foo(3, 4);
}_ di dalam signature sebuah fungsiKode ini bakal bener-bener mengabaikan nilai 3 yang dioper sebagai argumen
pertama, dan dia bakal mencetak This code only uses the y parameter: 4.
Di mayoritas kasus saat kita udah tidak butuh suatu parameter fungsi tertentu lagi, seharusnya kita sekalian aja ngubah signature-nya supaya dia tidak nyertain parameter yang tidak terpakai itu. Mengabaikan sebuah parameter fungsi bisa sangat sangat berguna di kasus-kasus di mana, misalnya, kita lagi mengimplementasikan sebuah trait saat kita diwajibkan buat punya type signature yang spesifik tapi isi fungsinya (function body) di implementasi kita sama sekali tidak butuh salah satu parameternya. Dengan melakukan itu kita bisa terhindar dari dapat peringatan (warning) compiler tentang parameter fungsi yang tidak terpakai (unused function parameters), yang mana peringatan itu bakal muncul kalau seandainya kita malah memakai sebuah nama.
Mengabaikan Bagian-bagian dari Sebuah Nilai Memakai _ yang Bersarang (Nested)
Kita juga bisa memakai _ di dalam pattern lain buat cuma ngabaiin sebagian
dari sebuah nilai, misalnya, pas kita cuma pengen ngetes sebagian dari sebuah
nilai tapi tidak punya alasan apa pun buat memakai bagian-bagian lainnya di dalam
kode korespondensinya yang mau kita jalanin. Listing 19-18 nunjukin kode yang
bertanggung jawab buat mengelola nilai dari suatu pengaturan (setting). Persyaratan
bisnisnya adalah user tidak boleh ngubah (overwrite) penyesuaian (customization)
yang udah ada pada suatu setting, tapi user boleh aja menghapus (unset)
setting tersebut lalu ngasih dia nilai baru kalau setting tersebut saat itu
lagi kosong (unset).
fn main() {
let mut setting_value = Some(5);
let new_setting_value = Some(10);
match (setting_value, new_setting_value) {
(Some(_), Some(_)) => {
println!("Can't overwrite an existing customized value");
}
_ => {
setting_value = new_setting_value;
}
}
println!("setting is {setting_value:?}");
}Some pas kita tidak perlu buat memakai nilai di dalam Some tersebutKode ini bakal mencetak Can't overwrite an existing customized value dan terus
setting is Some(5). Di match arm yang pertama, kita tidak perlu mencocokkan atau
memakai nilai-nilai yang ada di dalam masing-masing varian Some, tapi kita benar-benar
perlu buat ngetes kasus di mana setting_value dan new_setting_value dua-duanya
adalah varian Some. Di kasus itu, kita mencetak alasan kenapa kita tidak
mengubah setting_value, dan nilainya emang tidak jadi diubah.
Di semua kasus lainnya (kalau entah setting_value atau new_setting_value itu None)
yang diekspresikan sama pattern _ di arm yang kedua, kita pengen ngebolehin
new_setting_value buat ngegantiin (become) setting_value.
Kita juga bisa memakai garis bawah di banyak tempat di dalam satu pattern tunggal buat ngabaiin beberapa nilai tertentu. Listing 19-19 nunjukin sebuah contoh gimana caranya ngabaiin nilai kedua dan keempat di dalam sebuah tuple yang isinya ada lima item.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(first, _, third, _, fifth) => {
println!("Some numbers: {first}, {third}, {fifth}");
}
}
}Kode ini bakal mencetak Some numbers: 2, 8, 32, dan nilai 4 dan 16 bakal
diabaikan.
Mengabaikan Variabel yang Tidak Terpakai dengan Mengawali Namanya Memakai _
Kalau kita membikin sebuah variabel tapi tidak pernah memakannya di mana pun, Rust biasanya bakal mengeluarkan peringatan (warning) karena variabel yang tidak terpakai itu bisa aja merupakan sebuah bug. Namun, kadang-kadang itu kepake sekali buat bisa bikin sebuah variabel yang belum mau kita pakai sekarang, kayak pas kita lagi nge-prototipe (prototyping) atau pas lagi memulai sebuah project. Di situasi ini, kita bisa ngasih tahu Rust supaya tidak ngasih peringatan ke kita soal variabel yang tidak terpakai dengan ngawalin nama variabelnya pakai sebuah garis bawah (underscore). Di Listing 19-20, kita bikin dua variabel yang tidak dipakai, tapi pas kita mengompilasi kode ini, kita harusnya cuma bakal dapat satu peringatan aja tentang salah satunya.
fn main() {
let _x = 5;
let y = 10;
}Di sini, kita dapat satu peringatan karena tidak memakai variabel y, tapi kita
tidak dapat peringatan apa pun soal tidak memakai _x.
Perhatikan bahwa ada sedikit perbedaan yang halus (subtle difference) antara memakai
_ sendirian dan memakai nama yang diawali dengan sebuah garis bawah. Sintaks
_x itu tetap mengikat (binds) nilainya ke variabel tersebut, sementara _
tidak mengikat nilai itu sama sekali. Buat nunjukin di mana letak kasus yang mana
perbedaan ini jadi penting, Listing 19-21 bakal ngasih kita sebuah error.
fn main() {
let s = Some(String::from("Hello!"));
if let Some(_s) = s {
println!("found a string");
}
println!("{s:?}");
}Kita bakal nerima sebuah error karena nilai s tersebut bakal tetep aja di-move
(dipindahkan) ke dalam _s, yang mana mencegah kita dari memakai s lagi
setelah itu. Namun, memakai garis bawah itu sendiri aja tidak pernah mengikat (bind)
ke nilainya. Listing 19-22 bakal berhasil di-compile tanpa error apa pun karena s
tidak dipindahkan (moved) ke dalam _.
fn main() {
let s = Some(String::from("Hello!"));
if let Some(_) = s {
println!("found a string");
}
println!("{s:?}");
}Kode ini bisa jalan dengan lancar karena kita bener-bener tidak pernah mengikat
s ke mana pun; dia tidak dipindahkan.
Mengabaikan Sisa Bagian dari Sebuah Nilai Memakai ..
Buat nilai-nilai yang punya banyak bagian, kita bisa memakai sintaks .. buat
cuma memakai bagian-bagian yang spesifik aja lalu ngabaiin sisanya, sehingga
kita bisa menghindari nulisin garis bawah buat setiap nilai yang mau kita
abaikan. Pattern .. mengabaikan bagian mana pun dari sebuah nilai yang belum
kita cocokkan (matched) secara eksplisit di sisa pattern tersebut. Di Listing 19-23,
kita punya struct Point yang memegang titik koordinat di ruang tiga dimensi
(three-dimensional space). Di dalam ekspresi match, kita cuma mau beroperasi pada
koordinat x doang dan ngabaiin nilai-nilai yang ada di field y dan z.
fn main() {
struct Point {
x: i32,
y: i32,
z: i32,
}
let origin = Point { x: 0, y: 0, z: 0 };
match origin {
Point { x, .. } => println!("x is {x}"),
}
}Point kecuali buat x dengan memakai ..Kita nyebutin nilai x lalu setelah itu kita cuma masukin pattern .. aja.
Ini jauh lebih cepet daripada kita harus nulisin y: _ dan z: _, terutama
pas kita lagi ngerjain structs yang punya sangat banyak field di mana cuma ada satu
atau dua field doang yang relevan buat kita.
Sintaks .. ini bakal melebar (expand) ke seberapa banyak pun nilai yang dibutuhin.
Listing 19-24 nunjukin gimana cara memakai .. bareng sebuah tuple.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(first, .., last) => {
println!("Some numbers: {first}, {last}");
}
}
}Di kode ini, nilai yang pertama dan yang terakhir bakal dicocokkan dengan first
dan last. .. itu bakal nyocokin dan lalu ngabaiin semua hal yang ada di
tengah-tengah mereka berdua.
Namun, pemakaian .. itu harus tidak ambigu (unambiguous). Kalau sampai tidak
jelas nilai-nilai yang mana aja yang ditujukan buat dicocokin dan nilai yang
mana yang seharusnya diabaikan, Rust bakal ngasih kita sebuah error. Listing
19-25 nunjukin sebuah contoh dari pemakaian .. secara ambigu, jadi dia tidak
bakal bisa di-compile.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(.., second, ..) => {
println!("Some numbers: {second}")
},
}
}.. dengan cara yang ambiguPas kita men-compile contoh ini, kita dapet error ini:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error: `..` can only be used once per tuple pattern
--> src/main.rs:5:22
|
5 | (.., second, ..) => {
| -- ^^ can only be used once per tuple pattern
| |
| previously used here
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Mustahil bagi Rust buat nentuin seberapa banyak nilai di dalam tuple tersebut
yang harus diabaikan sebelum dia mencocokkan sebuah nilai dengan second lalu
berapa banyak lagi nilai selanjutnya yang harus diabaikan setelahnya. Kode ini bisa
aja berarti kalau kita mau ngabaiin 2, mengikat second ke 4, dan terus
ngabaiin 8, 16, dan 32; atau bisa juga berarti kalau kita mau ngabaiin 2 dan
4, mengikat second ke 8, dan lalu ngabaiin 16 dan 32; dan seterusnya
(and so forth). Nama variabel second itu tidak punya arti khusus apa-apa buat Rust,
jadi kita dapet error compiler karena memakai .. di dua tempat kayak gini itu
ambigu.
Kondisional Tambahan Memakai Match Guards
Sebuah match guard adalah tambahan kondisi if, yang ditentukan setelah pattern
di dalam sebuah lengan (arm) match, yang wajib dicocokkan juga supaya arm tersebut
bisa dipilih. Match guards ini berguna buat mengekspresikan ide-ide yang lebih
kompleks daripada apa yang bisa diizinkan sama sebuah pattern sendirian. Namun,
perhatikan bahwa mereka itu cuma tersedia di dalam ekspresi match, bukan di
ekspresi if let atau while let.
Kondisi tersebut bisa memakai variabel yang dibikin di dalam pattern-nya. Listing
19-26 nunjukin sebuah match di mana arm pertamanya punya pattern Some(x)
dan juga punya sebuah match guard if x % 2 == 0 (yang bakal jadi true kalau
angkanya itu bilangan genap).
fn main() {
let num = Some(4);
match num {
Some(x) if x % 2 == 0 => println!("The number {x} is even"),
Some(x) => println!("The number {x} is odd"),
None => (),
}
}Contoh ini bakal mencetak The number 4 is even. Pas num dibandingkan dengan
pattern di arm yang pertama, dia cocok karena Some(4) cocok dengan Some(x).
Terus si match guard mengecek apakah sisa dari ngebagi x dengan 2 itu sama
dengan 0, dan karena emang bener, arm yang pertama itu pun dipilih.
Kalau seandainya num tadi adalah Some(5), si match guard di arm pertama
bakal jadi false karena sisa pembagian 5 dengan 2 itu adalah 1, yang mana tidak
sama dengan 0. Rust terus bakal lanjut ke arm yang kedua, yang mana bakal cocok
karena arm yang kedua itu tidak punya match guard dan makanya dia cocok buat varian
Some yang mana aja.
Tidak ada cara buat mengekspresikan kondisi if x % 2 == 0 di dalam sebuah
pattern secara langsung, jadi match guard ngasih kita kemampuan buat bisa
mengekspresikan logika ini. Kekurangan dari penambahan fungsionalitas ekspresi
(expressiveness) ekstra ini adalah kalau compiler tidak bakal mencoba buat
mengecek kelengkapannya (exhaustiveness) saat ada ekspresi-ekspresi match guard yang
dilibatkan.
Di Listing 19-11, kita sempat menyebutkan kalau kita bisa memakai match guards
buat nyelesein masalah tertimpanya variabel (pattern-shadowing problem) yang
kita alami. Ingat kembali kalau waktu itu kita membikin sebuah variabel baru di
dalam pattern di ekspresi match-nya ketimbang memakai variabel yang udah ada di
luar match. Variabel yang baru itu berarti kalau kita tidak bisa lagi melakukan
pengetesan terhadap (test against) nilai dari variabel yang ada di luar itu.
Listing 19-27 nunjukin gimana caranya kita bisa memakai sebuah match guard buat
memperbaiki masalah ini.
fn main() {
let x = Some(5);
let y = 10;
match x {
Some(50) => println!("Got 50"),
Some(n) if n == y => println!("Matched, n = {n}"),
_ => println!("Default case, x = {x:?}"),
}
println!("at the end: x = {x:?}, y = {y}");
}Kode ini sekarang bakal mencetak Default case, x = Some(5). Pattern di arm
match yang kedua tidak memperkenalkan sebuah variabel baru y yang mana bakal
menimpa y yang ada di luar, yang berarti kita bisa memakai y luar tersebut di
dalam match guard-nya. Ketimbang menentukan pattern-nya sebagai Some(y), yang mana
bakal menimpa y luar, kita menentukannya sebagai Some(n). Ini membikin
sebuah variabel baru n yang tidak menimpa apa pun karena tidak ada variabel
n di luar match.
Match guard if n == y itu bukanlah sebuah pattern dan makanya dia tidak
memperkenalkan variabel baru apa pun. y ini adalah si y luar ketimbang
sebuah y baru yang menimpanya, dan kita bisa nyari-nyari sebuah nilai yang punya
nilai yang sama kayak si y luar tersebut dengan membandingkan n ke y.
Kita juga bisa memakai operator or | di dalam sebuah match guard buat
menentukan lebih dari satu patterns; di mana kondisi dari match guard tersebut
bakal berlaku buat kesemua patterns-nya. Listing 19-28 nunjukin hierarki (precedence)
saat ngegabungin sebuah pattern yang memakai | dengan sebuah match guard. Bagian
yang penting dari contoh ini adalah bahwa si match guard if y ini berlaku buat
4, 5, dan 6, biarpun dia mungkin kelihatannya kayak si if y ini cuma
berlaku buat 6 doang.
fn main() {
let x = 4;
let y = false;
match x {
4 | 5 | 6 if y => println!("yes"),
_ => println!("no"),
}
}Kondisi match itu menyatakan kalau arm tersebut cuma cocok kalau nilainya x
itu sama dengan 4, 5, atau 6 dan kalau y itu true. Pas kode ini jalan,
pattern dari arm pertama cocok karena x adalah 4, tapi si match guard if y
itu false, jadi arm pertama tersebut tidak dipilih. Kodenya lanjut ke arm yang
kedua, yang mana emang cocok, dan program ini mencetak no. Alasannya adalah
karena kondisi if tersebut berlaku buat keseluruhan pattern 4 | 5 | 6, bukan
cuma buat nilai terakhir 6 aja. Dengan kata lain, hierarki dari sebuah match
guard sehubungan dengan (in relation to) sebuah pattern itu berperilaku kayak gini:
(4 | 5 | 6) if y => ...
bukannya kayak gini:
4 | 5 | (6 if y) => ...
Setelah menjalankan kodenya, perilaku hierarki ini terlihat dengan jelas: kalau
match guard tersebut cuma diterapin ke nilai terakhir di daftar nilai yang ditentukan
memakai operator |, arm tersebut pasti udah cocok dan programnya pasti bakal
mencetak yes.
Binding Memakai @
Operator at @ membiarkan kita membikin sebuah variabel yang nampung sebuah nilai
di waktu yang bersamaan dengan kita melakukan tes apakah nilai tersebut cocok sama
suatu pattern (pattern match) atau tidak. Di Listing 19-29, kita mau ngetes apakah
field id di sebuah Message::Hello itu ada di dalam rentang 3..=7. Kita juga mau
mengikat (bind) nilai tersebut ke variabel id supaya kita bisa memakainya di
dalam kode yang diasosiasikan (associated) sama arm tersebut.
fn main() {
enum Message {
Hello { id: i32 },
}
let msg = Message::Hello { id: 5 };
match msg {
Message::Hello { id: id @ 3..=7 } => {
println!("Found an id in range: {id}")
}
Message::Hello { id: 10..=12 } => {
println!("Found an id in another range")
}
Message::Hello { id } => println!("Found some other id: {id}"),
}
}@ buat nge-bind ke suatu nilai di dalam sebuah pattern sembari juga ngetes (testing) nilai tersebutContoh ini bakal mencetak Found an id in range: 5. Dengan menspesifikasikan id @
sebelum rentang 3..=7, kita lagi menangkap nilai apa pun yang sekiranya cocok sama
rentang itu lalu menaruhnya ke dalam sebuah variabel bernama id, dan sembari ngelakuin
itu kita juga ngetes kalau nilai tersebut cocok sama pattern rentang (range
pattern) tersebut.
Di arm yang kedua, di mana kita cuma menentukan sebuah rentang doang di dalam
pattern-nya, kode yang terkait sama arm tersebut tidak punya variabel yang berisi
nilai asli dari field id itu. Nilai dari field id itu bisa jadi adalah 10, 11,
atau 12, tapi kode yang ada di arm pattern tersebut sama sekali tidak tahu nilainya yang
mana. Kode di pattern tersebut tidak mampu buat memakai nilai dari field id, karena
kita belum nyimpan nilai id tersebut di sebuah variabel.
Di arm terakhir, di mana kita udah menyebutkan sebuah variabel tanpa adanya rentang,
kita bener-bener punya akses ke nilai yang bisa kita pakai di dalam kode untuk arm
tersebut di sebuah variabel bernama id. Alasannya adalah karena kita udah memakai
sintaks shorthand field struct. Tapi kita belum menerapkan tes (test) apa-apa ke
dalam nilai di field id ini buat arm yang ini, seperti yang udah kita lakuin di dua
arm pertama: nilai apa pun bakal cocok dengan pattern ini.
Memakai @ ngasih kita kemampuan buat ngetes sebuah nilai dan kemudian menyimpannya
ke dalam sebuah variabel dalam satu pattern tunggal.
Ringkasan
Patterns di Rust itu sangat sangat berguna dalam membedakan (distinguishing) berbagai
macam jenis data yang berbeda. Pas mereka dipakai di dalam ekspresi match, Rust
memastikan kalau patterns kita udah mencakup semua kemungkinan nilai yang ada,
karena kalau tidak program kita tidak bakal bisa di-compile. Patterns yang ada di
dalam statement let dan parameter fungsi ngebikin konstruk-konstruk tersebut jadi
jauh lebih berguna, memungkinkan proses memecah (destructuring) sebuah nilai jadi
bagian-bagian yang lebih kecil dan meng-assign (ngasih nilai ke) bagian-bagian itu
ke dalam berbagai variabel. Kita bisa bikin patterns yang simpel maupun yang
kompleks buat menyesuaikan dengan apa yang kita butuhkan.
Berikutnya, untuk bab kedua dari akhir buku ini, kita bakal melihat beberapa aspek tingkat mahir (advanced aspects) dari berbagai macam fitur yang ada di Rust.
Fitur-fitur Tingkat Lanjut (Advanced Features)
Sekarang, kita udah mempelajari bagian-bagian yang paling sering dipakai di bahasa pemrograman Rust. Sebelum kita mengerjakan satu project lagi di Bab 21, kita bakal melihat beberapa aspek dari bahasa ini yang mungkin bakal kita temui sekali-sekali, biarpun kita mungkin tidak memakainya setiap hari. Kita bisa memakai bab ini sebagai referensi saat kita ketemu hal-hal yang belum kita ketahui. Fitur-fitur yang dibahas di sini sangat berguna buat situasi-situasi yang sangat spesifik. Walaupun kita mungkin jarang memakainya, kita pengen memastikan kita punya pemahaman soal semua fitur yang ditawarkan oleh Rust.
Di bab ini, kita bakal membahas:
- Unsafe Rust: gimana cara keluar (opt out) dari beberapa jaminan yang dikasih Rust dan mengambil tanggung jawab buat menjunjung tinggi jaminan-jaminan itu secara manual
- Advanced traits: associated types, default type parameters, fully qualified syntax, supertraits, dan newtype pattern (pola tipe baru) sehubungan dengan traits
- Advanced types: lebih banyak lagi soal newtype pattern, type aliases
(alias tipe), tipe
never(tipe tak pernah), dan dynamically sized types (tipe-tipe yang berukuran dinamis) - Advanced functions dan closures: function pointers (pointer fungsi) dan mengembalikan closures
- Macros: berbagai cara buat mendefinisikan kode yang membikin lebih banyak kode lagi saat compile time
Ini adalah sekumpulan fitur Rust yang punya sesuatu buat semua orang! Mari kita selami!
Unsafe Rust
Unsafe Rust
Semua kode yang udah kita bahas sejauh ini punya jaminan keamanan memori (memory safety guarantees) yang ditegakkan oleh Rust saat compile time. Namun, Rust punya sebuah bahasa kedua yang tersembunyi di dalamnya yang tidak menegakkan jaminan keamanan memori ini: namanya unsafe Rust dan dia bekerja persis kayak Rust biasa, tapi ngasih kita kekuatan super (superpowers) tambahan.
Unsafe Rust eksis karena, secara natur, analisis statis itu sifatnya konservatif. Saat compiler mencoba buat menentukan apakah sebuah kode mematuhi jaminan keamanannya atau tidak, jauh lebih baik baginya buat menolak beberapa program yang sebenarnya valid ketimbang menerima beberapa program yang ternyata tidak valid. Walaupun kodenya mungkin baik-baik aja, kalau compiler Rust tidak punya informasi yang cukup buat merasa yakin, dia bakal menolak kode tersebut. Di kasus-kasus seperti ini, kita bisa memakai kode unsafe buat ngasih tahu compiler, “Percaya deh, aku tahu apa yang lagi aku lakuin.” Namun, peringatan: kita memakai unsafe Rust dengan risiko kita sendiri: kalau kita memakai kode unsafe dengan tidak benar, masalah-masalah bisa bermunculan akibat tidak amannya memori, seperti proses dereferencing pada null pointer.
Alasan lain kenapa Rust punya sebuah alter ego yang unsafe adalah karena hardware komputer yang mendasarinya (underlying computer hardware) itu sifatnya memang tidak aman (inherently unsafe). Kalau Rust tidak membiarkan kita melakukan operasi-operasi yang tidak aman, kita tidak bakal bisa mengerjakan tugas-tugas tertentu. Rust perlu mengizinkan kita melakukan pemrograman sistem tingkat rendah (low-level systems programming), kayak berinteraksi secara langsung sama sistem operasi atau bahkan menulis sistem operasi kita sendiri. Bekerja dengan pemrograman sistem tingkat rendah adalah salah satu tujuan dari bahasa ini. Mari kita eksplorasi apa aja yang bisa kita lakukan dengan unsafe Rust dan gimana cara melakukannya.
Unsafe Superpowers
Buat beralih ke unsafe Rust, gunakan keyword unsafe lalu mulai sebuah blok baru
buat menampung kode unsafe tersebut. Ada lima hal yang bisa kita lakukan di
unsafe Rust yang tidak bisa kita lakukan di Rust biasa (safe Rust), yang mana
kita sebut sebagai unsafe superpowers. Kekuatan super tersebut meliputi kemampuan
buat:
- Men-dereferensi sebuah raw pointer (pointer mentah)
- Memanggil fungsi atau method unsafe
- Mengakses atau memodifikasi variabel static yang mutable
- Mengimplementasikan trait unsafe
- Mengakses field dari sebuah
union
Penting sekali buat dipahami kalau unsafe tidak mematikan borrow checker atau
menonaktifkan (disable) pengecekan keamanan Rust lainnya: kalau kita memakai
sebuah referensi di dalam kode unsafe, dia bakal tetap dicek. Keyword unsafe
cuma ngasih kita akses ke lima fitur ini yang kemudian tidak bakal dicek sama
compiler buat keamanan memori. Kita bakal tetap dapat tingkat keamanan
tertentu di dalam sebuah blok unsafe.
Selain itu, unsafe tidak berarti kalau kode di dalam blok tersebut pasti berbahaya
atau bahwa dia pasti bakal punya masalah keamanan memori: maksud utamanya adalah
sebagai programmer, Andalah yang bakal memastikan kalau kode di dalam blok
unsafe tersebut bakal mengakses memori dengan cara yang valid.
Manusia itu bisa aja salah dan kesalahan (mistakes) emang bakal terjadi, tapi dengan
mewajibkan kelima operasi unsafe ini buat berada di dalam blok-blok yang dianotasi
dengan unsafe, kita bakal tahu kalau error apa pun yang berkaitan dengan keamanan
memori itu pasti ada di dalam sebuah blok unsafe. Usahakan supaya blok unsafe
itu kecil; kita bakal bersyukur nanti pas kita lagi nyelidikin bugs memori.
Buat mengisolasi kode unsafe sebanyak mungkin, praktik terbaiknya adalah membungkus
(enclose) kode semacam itu di dalam sebuah abstraksi yang aman (safe abstraction)
lalu menyediakan API yang aman, yang mana bakal kita bahas nanti di bab ini pas
kita meneliti fungsi dan method unsafe. Beberapa bagian dari standard library
diimplementasikan sebagai abstraksi yang aman di atas kode unsafe yang udah diaudit.
Membungkus kode unsafe di dalam sebuah abstraksi yang aman bakal mencegah
penggunaan unsafe agar tidak bocor (leaking out) ke semua tempat di mana kita
atau user kita mungkin pengen memakai fungsionalitas yang diimplementasikan dengan
kode unsafe tersebut, karena memakai sebuah abstraksi yang aman itu sifatnya aman.
Mari kita bahas masing-masing dari lima unsafe superpowers tersebut satu per satu. Kita juga bakal melihat beberapa abstraksi yang nyediain interface (antarmuka) yang aman buat mengakses kode unsafe.
Men-dereferensi sebuah Raw Pointer
Di Bab 4, di bagian “Dangling References”, kita menyebutkan
kalau compiler selalu memastikan kalau referensi itu selalu valid. Unsafe Rust
punya dua tipe baru bernama raw pointers yang mirip sama referensi. Sama kayak
referensi, raw pointers bisa bersifat immutable atau mutable dan masing-masing
ditulis sebagai *const T dan *mut T. Tanda bintang (*) di sini bukanlah operator
dereferensi; dia adalah bagian dari nama tipenya. Di dalam konteks raw pointers,
immutable berarti kalau pointer tersebut tidak bisa secara langsung di-assign (diisi
nilai baru) setelah ia di-dereferensi.
Berbeda dari referensi dan smart pointers, raw pointers:
- Diizinkan buat ngabaikan aturan borrowing dengan membiarkan kita punya baik pointer immutable maupun mutable, atau banyak pointer mutable yang menunjuk ke lokasi yang sama
- Tidak dijamin bakal menunjuk ke memori yang valid
- Diizinkan buat bernilai null
- Tidak mengimplementasikan pembersihan otomatis (automatic cleanup) apa pun
Dengan memilih keluar (opting out) dari ditegakkannya jaminan-jaminan ini oleh Rust, kita bisa mengorbankan (give up) keamanan yang dijamin demi mendapatkan performa yang lebih besar atau kemampuan buat berinteraksi sama bahasa pemrograman lain atau hardware yang mana jaminan Rust tidak berlaku di situ.
Listing 20-1 menunjukkan gimana cara membikin sebuah raw pointer yang immutable dan yang mutable.
fn main() {
let mut num = 5;
let r1 = &raw const num;
let r2 = &raw mut num;
}Perhatikan bahwa kita tidak memasukkan keyword unsafe di kode ini. Kita bisa membikin
raw pointers di dalam safe code (kode yang aman); kita cuma tidak bisa
men-dereferensi raw pointers di luar sebuah blok unsafe, kayak yang bakal kita
lihat sebentar lagi.
Kita udah membikin raw pointers dengan memakai operator raw borrow: &raw const num
membikin sebuah raw pointer immutable *const i32, dan &raw mut num membikin
sebuah raw pointer mutable *mut i32. Karena kita membikin mereka secara
langsung dari sebuah variabel lokal, kita tahu pasti kalau raw pointers spesifik ini
itu valid, tapi kita tidak bisa bikin asumsi kayak gitu buat sembarang raw pointer
yang mana aja.
Buat mendemonstrasikan hal ini, selanjutnya kita bakal membikin sebuah raw pointer yang
mana validitasnya tidak bisa kita pastikan, dengan memakai keyword as buat meng-cast
(mengubah tipe) sebuah nilai ketimbang memakai operator raw borrow. Listing 20-2
menunjukkan gimana cara membikin sebuah raw pointer ke sebuah lokasi sembarang
(arbitrary location) di memori. Mencoba buat memakai memori sembarang itu adalah
perilaku yang tidak terdefinisi (undefined behavior): mungkin ada data di alamat
tersebut atau mungkin tidak ada, compiler mungkin bakal mengoptimasi kodenya
sehingga tidak ada akses memori yang terjadi, atau programnya mungkin bakal berhenti
(terminate) karena segmentation fault. Biasanya, tidak ada alasan yang bagus buat
menulis kode kayak gini, apalagi di kasus-kasus di mana kita bisa memakai operator
raw borrow sebagai gantinya, tapi hal ini tetap memungkinkan buat dilakukan.
fn main() {
let address = 0x012345usize;
let r = address as *const i32;
}Ingat kembali kalau kita bisa membikin raw pointers di safe code, tapi kita tidak
bisa men-dereferensi raw pointers dan membaca data yang ditunjuknya. Di Listing 20-3,
kita memakai operator dereferensi * pada sebuah raw pointer yang mana mewajibkan
sebuah blok unsafe.
fn main() {
let mut num = 5;
let r1 = &raw const num;
let r2 = &raw mut num;
unsafe {
println!("r1 is: {}", *r1);
println!("r2 is: {}", *r2);
}
}unsafeMembikin sebuah pointer itu tidak membahayakan apa-apa; cuma pas kita mencoba buat mengakses nilai yang ditunjuknya barulah kita berisiko berurusan dengan sebuah nilai yang tidak valid.
Perhatikan juga kalau di Listing 20-1 dan 20-3, kita membikin raw pointers *const i32
dan *mut i32 yang dua-duanya menunjuk ke lokasi memori yang sama, tempat di mana
num disimpan. Kalau kita nyoba buat membikin referensi immutable dan mutable
ke num sebagai gantinya, kodenya tidak bakal bisa di-compile karena aturan ownership
Rust tidak mengizinkan adanya referensi mutable di saat yang bersamaan dengan
referensi immutable apa pun. Dengan raw pointers, kita bisa membikin pointer
mutable dan pointer immutable ke lokasi yang sama dan mengubah datanya lewat
pointer mutable tersebut, yang secara potensial bisa ngebikin sebuah data race.
Hati-hati ya!
Dengan semua bahaya ini, kenapa kita mau repot-repot memakai raw pointers? Salah satu skenario penggunaan (use case) utamanya adalah saat berinteraksi sama kode C, kayak yang bakal kita lihat di bagian selanjutnya. Skenario lainnya adalah pas kita lagi ngebangun abstraksi yang aman yang mana si borrow checker tidak bisa pahami. Kita bakal mengenalkan fungsi-fungsi unsafe lalu melihat sebuah contoh abstraksi aman yang memakai kode unsafe.
Memanggil Fungsi atau Method Unsafe
Jenis operasi kedua yang bisa kita lakukan di dalam blok unsafe adalah memanggil
fungsi-fungsi unsafe. Fungsi dan method unsafe kelihatannya persis kayak
fungsi dan method biasa, tapi mereka punya tambahan unsafe sebelum sisa
definisinya. Keyword unsafe di konteks ini mengindikasikan bahwa fungsi
tersebut punya persyaratan yang harus kita junjung tinggi pas kita manggil fungsi
ini, karena Rust tidak bisa ngejamin kalau kita udah menuhi persyaratan
tersebut. Dengan memanggil fungsi unsafe di dalam blok unsafe, kita menyatakan
kalau kita udah ngebaca dokumentasi fungsi ini dan kita mengambil tanggung jawab
buat mematuhi kontrak dari fungsi tersebut.
Berikut ini adalah fungsi unsafe bernama dangerous yang tidak melakukan apa-apa
di dalam isinya (body):
fn main() {
unsafe fn dangerous() {}
unsafe {
dangerous();
}
}Kita wajib memanggil fungsi dangerous di dalam sebuah blok unsafe yang terpisah.
Kalau kita mencoba buat memanggil dangerous tanpa blok unsafe, kita bakal dapat error:
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0133]: call to unsafe function `dangerous` is unsafe and requires unsafe block
--> src/main.rs:4:5
|
4 | dangerous();
| ^^^^^^^^^^^ call to unsafe function
|
= note: consult the function's documentation for information on how to avoid undefined behavior
For more information about this error, try `rustc --explain E0133`.
error: could not compile `unsafe-example` (bin "unsafe-example") due to 1 previous error
Dengan blok unsafe, kita lagi menegaskan ke Rust kalau kita udah membaca dokumentasi
dari fungsinya, kita ngerti gimana cara memakainya dengan benar, dan kita udah
memverifikasi kalau kita mematuhi kontrak dari fungsi tersebut.
Buat melakukan operasi unsafe di dalam isi dari sebuah fungsi unsafe, kita tetap
butuh memakai sebuah blok unsafe, sama seperti di dalam fungsi biasa, dan compiler
bakal ngingetin (warn) kita kalau kita lupa. Ini ngebantu kita ngejaga supaya blok
unsafe itu sekecil mungkin, karena operasi unsafe mungkin tidak diperlukan
di seluruh isi fungsi tersebut.
Membikin Abstraksi yang Aman di atas Kode Unsafe
Cuma karena sebuah fungsi mengandung kode unsafe tidak berarti kita harus menandai
keseluruhan fungsinya sebagai unsafe. Faktanya, membungkus kode unsafe di dalam
sebuah fungsi yang aman adalah sebuah abstraksi yang sangat umum. Sebagai contoh, mari
kita pelajari fungsi split_at_mut dari standard library, yang mana mewajibkan
beberapa kode unsafe. Kita bakal mengeksplorasi gimana kita mungkin
mengimplementasikannya. Method aman ini didefinisikan pada slices mutable: dia
mengambil satu slice lalu membikinnya jadi dua dengan membelah slice tersebut di
indeks yang diberikan sebagai argumen. Listing 20-4 menunjukkan gimana cara
memakai split_at_mut.
fn main() {
let mut v = vec![1, 2, 3, 4, 5, 6];
let r = &mut v[..];
let (a, b) = r.split_at_mut(3);
assert_eq!(a, &mut [1, 2, 3]);
assert_eq!(b, &mut [4, 5, 6]);
}split_at_mutKita tidak bisa mengimplementasikan fungsi ini kalau cuma memakai Rust yang aman
saja. Percobaannya mungkin bakal kelihatan kayak yang ada di Listing 20-5,
yang mana tidak bakal bisa di-compile. Demi kesederhanaan, kita bakal
mengimplementasikan split_at_mut sebagai sebuah fungsi bukannya method
dan cuma buat slices yang berisi nilai i32 bukannya buat sebuah tipe generik T.
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
assert!(mid <= len);
(&mut values[..mid], &mut values[mid..])
}
fn main() {
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
}split_at_mut yang cuma memakai Rust yang amanFungsi ini pertama-tama mengambil panjang (length) total dari slice tersebut. Terus dia menegaskan (asserts) kalau indeks yang diberikan sebagai parameter itu ada di dalam batas-batas slice dengan mengecek apakah indeks tersebut kurang dari atau sama dengan panjangnya. Penegasan ini berarti kalau kita ngasih indeks yang lebih besar dari panjang slice tersebut buat ngebelah si slice, fungsinya bakal panic sebelum dia mencoba buat memakai indeks tersebut.
Lalu kita mengembalikan dua slices mutable di dalam sebuah tuple: yang satu
dari awal (start) slice aslinya sampai ke indeks mid, dan satu lagi dari mid
sampai ke akhir dari slice tersebut.
Pas kita mencoba buat men-compile kode di Listing 20-5, kita bakal dapat sebuah error:
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0499]: cannot borrow `*values` as mutable more than once at a time
--> src/main.rs:6:31
|
1 | fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
| - let's call the lifetime of this reference `'1`
...
6 | (&mut values[..mid], &mut values[mid..])
| --------------------------^^^^^^--------
| | | |
| | | second mutable borrow occurs here
| | first mutable borrow occurs here
| returning this value requires that `*values` is borrowed for `'1`
|
= help: use `.split_at_mut(position)` to obtain two mutable non-overlapping sub-slices
For more information about this error, try `rustc --explain E0499`.
error: could not compile `unsafe-example` (bin "unsafe-example") due to 1 previous error
Borrow checker Rust tidak bisa ngerti kalau kita lagi meminjam (borrowing) bagian yang berbeda dari slice tersebut; dia cuma tahu kalau kita lagi meminjam dari slice yang sama sebanyak dua kali. Meminjam bagian yang berbeda dari sebuah slice itu secara fundamental baik-baik aja karena kedua slices tersebut tidak saling tumpang tindih (overlapping), tapi Rust tidak cukup pintar buat tahu hal ini. Pas kita tahu kalau kodenya itu aman, tapi Rust tidak tahu, inilah saatnya buat ngambil kode unsafe.
Listing 20-6 nunjukin gimana caranya memakai sebuah blok unsafe, sebuah raw pointer,
dan beberapa pemanggilan ke fungsi unsafe buat ngebikin implementasi dari
split_at_mut ini jalan.
use std::slice;
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
let ptr = values.as_mut_ptr();
assert!(mid <= len);
unsafe {
(
slice::from_raw_parts_mut(ptr, mid),
slice::from_raw_parts_mut(ptr.add(mid), len - mid),
)
}
}
fn main() {
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
}split_at_mutIngat kembali dari “Tipe Slice” di Bab 4 kalau sebuah slice itu
adalah pointer ke suatu data beserta panjang dari slice tersebut. Kita memakai
method len buat dapat panjang dari sebuah slice dan method as_mut_ptr buat ngakses
raw pointer dari sebuah slice. Di kasus ini, karena kita punya slice mutable ke
nilai i32, as_mut_ptr mengembalikan sebuah raw pointer dengan tipe *mut i32,
yang udah kita simpan di dalam variabel ptr.
Kita tetap naruh penegasan kalau indeks mid itu ada di dalam slice. Terus kita
masuk ke kode unsafe-nya: fungsi slice::from_raw_parts_mut menerima sebuah
raw pointer dan sebuah panjang, terus dia ngebikin sebuah slice. Kita
memakai fungsi ini buat ngebikin sebuah slice yang dimulai dari ptr dan
panjangnya sebesar mid item. Terus kita panggil method add pada ptr dengan
mid sebagai argumen buat dapetin raw pointer yang mulai di posisi mid,
dan kita ngebikin sebuah slice memakai pointer itu dan sisa jumlah item setelah
mid sebagai panjangnya.
Fungsi slice::from_raw_parts_mut itu sifatnya unsafe karena dia menerima sebuah
raw pointer dan harus percaya kalau pointer ini benar-benar valid. Method add
pada raw pointers juga sifatnya unsafe karena dia harus percaya kalau lokasi
offset-nya itu juga merupakan pointer yang valid. Oleh karena itu, kita harus menaruh
blok unsafe di sekeliling pemanggilan ke slice::from_raw_parts_mut dan add
supaya kita bisa memanggil mereka. Dengan ngelihat kodenya dan dengan menambahkan
penegasan kalau mid itu harus kurang dari atau sama dengan len, kita bisa
tahu pasti kalau semua raw pointers yang dipakai di dalam blok unsafe tersebut
bakal jadi pointers yang valid yang menunjuk ke data di dalam slice tersebut. Ini
adalah penggunaan dari unsafe yang bisa diterima dan sangat tepat.
Perhatikan bahwa kita tidak perlu menandai fungsi split_at_mut hasilnya sebagai
unsafe, dan kita bisa memanggil fungsi ini dari safe code. Kita udah ngebikin
sebuah abstraksi yang aman ke dalam kode unsafe tersebut dengan sebuah implementasi
fungsi yang memakai kode unsafe dengan cara yang aman, karena dia cuma
membikin pointers yang valid dari data yang emang bisa diakses sama fungsi ini.
Sebaliknya, pemakaian slice::from_raw_parts_mut di Listing 20-7 kemungkinan
besar bakal crash (rusak) pas slice-nya dipakai. Kode ini mengambil sebuah lokasi
memori sembarang lalu membikin sebuah slice yang panjangnya 10.000 item.
fn main() {
use std::slice;
let address = 0x01234usize;
let r = address as *mut i32;
let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) };
}Kita tidak memiliki memori di lokasi sembarang ini, dan tidak ada jaminan kalau
slice yang dibikin sama kode ini benar-benar berisi nilai i32 yang valid. Mencoba buat
memakai values seolah-olah dia adalah slice yang valid bakal menghasilkan perilaku
yang tidak terdefinisi (undefined behavior).
Memakai Fungsi extern Buat Memanggil Kode Eksternal
Kadang-kadang kode Rust kita mungkin perlu berinteraksi sama kode yang ditulis di bahasa
pemrograman lain. Buat keperluan ini, Rust punya keyword extern yang memfasilitasi
pembuatan dan penggunaan Foreign Function Interface (FFI), yang mana adalah sebuah
cara bagi sebuah bahasa pemrograman buat mendefinisikan fungsi lalu memungkinkan
bahasa pemrograman (asing) lain buat memanggil fungsi-fungsi tersebut.
Listing 20-8 mendemonstrasikan gimana caranya nge-setup sebuah integrasi dengan fungsi
abs dari standard library C. Fungsi-fungsi yang dideklarasikan di dalam
blok extern itu umumnya tidak aman (unsafe) buat dipanggil dari kode Rust, jadi blok
extern tersebut juga harus ditandai sebagai unsafe. Alasannya adalah karena bahasa-
bahasa lain tidak menerapkan (enforce) aturan-aturan dan jaminan-jaminan yang dipunyai Rust,
dan Rust tidak bisa ngecek mereka, jadi tanggung jawabnya jatuh ke tangan si programmer buat
memastikan keamanan kodenya.
unsafe extern "C" {
fn abs(input: i32) -> i32;
}
fn main() {
unsafe {
println!("Absolute value of -3 according to C: {}", abs(-3));
}
}extern yang didefinisikan di bahasa pemrograman lainDi dalam blok unsafe extern "C", kita mendaftarkan (list) nama-nama dan signatures
dari fungsi-fungsi eksternal dari bahasa lain yang mau kita panggil. Bagian "C" itu
mendefinisikan application binary interface (ABI) mana yang dipakai sama fungsi eksternal
tersebut: ABI ini mendefinisikan gimana caranya memanggil fungsinya pada tingkat bahasa rakitan
(assembly level). ABI "C" adalah yang paling umum dipakai dan mengikuti standar
ABI dari bahasa pemrograman C. Informasi tentang semua ABI yang didukung oleh Rust ada
di Rust Reference.
Semua item yang dideklarasikan di dalam blok unsafe extern itu secara implisit sifatnya
unsafe. Namun, beberapa fungsi FFI memang aman buat dipanggil. Contohnya, fungsi
abs dari standard library C itu tidak punya pertimbangan apa pun soal keamanan memori dan
kita tahu dia bisa dipanggil pakai sembarang i32. Di kasus-kasus kayak gini, kita bisa
memakai keyword safe buat ngasih tahu kalau fungsi yang spesifik ini itu aman buat
dipanggil biarpun dia ada di dalam sebuah blok unsafe extern. Begitu kita bikin perubahan
tersebut, manggil fungsinya udah tidak perlu blok unsafe lagi, kayak yang ditunjukin
di Listing 20-9.
unsafe extern "C" {
safe fn abs(input: i32) -> i32;
}
fn main() {
println!("Absolute value of -3 according to C: {}", abs(-3));
}safe di dalam sebuah blok unsafe extern dan memanggilnya dengan amanMenandai sebuah fungsi sebagai safe tidak secara otomatis (inherently) membikin fungsinya
jadi aman ya! Sebaliknya, ini ibarat janji yang kita buat ke Rust kalau dia itu aman.
Itu tetap jadi tanggung jawab kita buat mastiin kalau janji itu ditepati!
Memanggil Fungsi Rust dari Bahasa Lain
Kita juga bisa memakai extern buat membikin interface yang memungkinkan bahasa
pemrograman lain buat memanggil fungsi Rust. Ketimbang membikin satu blok extern utuh, kita
menambahkan keyword extern dan menentukan ABI apa yang mau dipakai tepat sebelum
keyword fn buat fungsi yang relevan. Kita juga perlu nambahin anotasi
#[unsafe(no_mangle)] buat ngasih tahu compiler Rust supaya tidak nge-mangle nama dari
fungsi ini. Mangling adalah pas compiler ngubah nama yang udah kita kasih ke sebuah
fungsi jadi nama lain yang mengandung lebih banyak informasi biar bisa dikonsumsi sama
bagian-bagian lain dari proses kompilasi tapi jadinya kurang enak dibaca sama manusia.
Setiap compiler bahasa pemrograman nge-mangle nama dengan cara yang agak berbeda-beda,
jadi supaya sebuah fungsi Rust bisa dipanggil namanya sama bahasa lain, kita harus
mematikan fitur name mangling dari compiler Rust. Hal ini sifatnya unsafe karena bisa
aja terjadi bentrok nama (name collisions) antar libraries kalau mangling bawaan ini
dimatiin, jadi ini adalah tanggung jawab kita buat mastiin kalau nama yang kita pilih
itu aman buat diekspor tanpa di-mangle.
Di contoh berikut ini, kita membikin fungsi call_from_c supaya bisa diakses dari
kode C, setelah dia di-compile jadi shared library dan di-link dari C:
#[unsafe(no_mangle)]
pub extern "C" fn call_from_c() {
println!("Just called a Rust function from C!");
}
Penggunaan extern ini cuma mewajibkan adanya unsafe di dalam atributnya aja, bukan
di blok extern-nya.
Mengakses atau Memodifikasi Variabel Static yang Mutable
Di buku ini, kita belum pernah ngebahas soal variabel global (global variables), yang mana memang didukung oleh Rust tapi bisa jadi bermasalah kalau digabungkan sama aturan ownership Rust. Kalau ada dua threads yang lagi mengakses variabel global yang mutable yang sama, hal itu bisa nyebabin sebuah data race.
Di Rust, variabel global itu disebut sebagai variabel static (statis). Listing 20-10 menunjukkan contoh deklarasi dan penggunaan dari sebuah variabel statis dengan nilai berupa sebuah string slice.
static HELLO_WORLD: &str = "Hello, world!";
fn main() {
println!("value is: {HELLO_WORLD}");
}Variabel static itu mirip sama konstanta (constants), yang mana udah kita bahas di
“Konstanta” di Bab 3. Nama-nama buat
variabel statis itu ditulis pakai gaya SCREAMING_SNAKE_CASE secara konvensi. Variabel
statis cuma bisa menyimpan referensi dengan lifetime 'static, yang berarti compiler
Rust udah tahu soal lifetime-nya dan kita tidak diwajibkan buat menganotasinya
secara eksplisit. Mengakses sebuah variabel statis yang immutable itu aman.
Satu perbedaan yang cukup halus (subtle) antara konstanta dan variabel statis immutable
adalah nilai-nilai yang ada di dalam sebuah variabel statis punya alamat yang tetap di
memori. Memakai nilai tersebut bakal selalu mengakses data yang sama. Konstanta, di sisi lain,
diizinkan buat menduplikasi data mereka kapan pun mereka dipakai. Perbedaan lainnya adalah
variabel statis itu bisa bersifat mutable (bisa diubah). Mengakses dan memodifikasi
variabel statis mutable itu sifatnya unsafe. Listing 20-11 menunjukkan gimana
caranya mendeklarasikan, mengakses, dan memodifikasi sebuah variabel statis mutable
bernama COUNTER.
static mut COUNTER: u32 = 0;
/// SAFETY: Calling this from more than a single thread at a time is undefined
/// behavior, so you *must* guarantee you only call it from a single thread at
/// a time.
unsafe fn add_to_count(inc: u32) {
unsafe {
COUNTER += inc;
}
}
fn main() {
unsafe {
// SAFETY: This is only called from a single thread in `main`.
add_to_count(3);
println!("COUNTER: {}", *(&raw const COUNTER));
}
}Sama kayak variabel biasa, kita menentukan mutabilitasnya dengan memakai keyword mut.
Kode apa pun yang membaca atau menulis dari COUNTER wajib berada di dalam sebuah
blok unsafe. Kode di Listing 20-11 berhasil di-compile dan mencetak COUNTER: 3 kayak
yang kita harapkan karena ini adalah program single-threaded (utas tunggal). Kalau
sampai ada banyak threads yang mengakses COUNTER, itu kemungkinan besar bakal nyebabin
data races, jadi itu dianggap sebagai perilaku yang tidak terdefinisi. Oleh karena itu,
kita perlu menandai keseluruhan fungsinya sebagai unsafe dan mendokumentasikan batasan
keamanannya, supaya siapa pun yang memanggil fungsi ini tahu apa aja yang boleh dan tidak
boleh mereka lakuin dengan aman.
Kapan pun kita nulis sebuah fungsi yang unsafe, sangatlah idiomatik buat nulis sebuah
komentar yang diawali dengan kata SAFETY dan ngejelasin apa aja yang perlu dilakuin
sama si pemanggil fungsi buat memanggil fungsi tersebut dengan aman. Sama halnya, kapan pun
kita ngelakuin operasi unsafe, juga sangat idiomatik buat nulis sebuah komentar yang
diawali dengan SAFETY buat ngejelasin gimana aturan-aturan keamanan tersebut dijunjung
tinggi.
Selain itu, compiler secara default bakal melarang usaha apa pun buat ngebikin referensi ke
sebuah variabel statis yang mutable lewat mekanisme lint (peringatan kode) compiler.
Kita wajib secara eksplisit keluar (opt-out) dari perlindungan lint tersebut dengan
nambahin anotasi #[allow(static_mut_refs)] atau ngakses variabel statis mutable tersebut
lewat sebuah raw pointer yang dibikin pakai salah satu dari operator raw borrow. Hal ini
termasuk juga kasus-kasus di mana referensi tersebut dibikin secara kasatmata, kayak pas dia
dipakai di println! di dalam kode ini. Mewajibkan supaya referensi ke variabel statis
yang mutable harus dibikin lewat raw pointers ngebantu ngebikin persyaratan
keamanannya jadi lebih terlihat jelas saat kita memakai mereka.
Dengan data mutable yang bisa diakses secara global, itu susah sekali buat memastikan kalau tidak bakal ada data races, yang mana inilah alasan kenapa Rust menganggap variabel statis mutable itu sebagai unsafe. Kalau memungkinkan, jauh lebih baik buat memakai teknik-teknik konkurensi dan smart pointers yang thread-safe yang udah kita bahas di Bab 16 supaya compiler bisa ngecek kalau akses data dari berbagai threads yang berbeda dilakukan dengan aman.
Mengimplementasikan Sebuah Unsafe Trait
Kita bisa memakai unsafe buat mengimplementasikan sebuah trait unsafe. Sebuah trait
itu dianggap unsafe saat minimal salah satu dari method-methodnya punya aturan mutlak
(invariant) yang mana tidak bisa diverifikasi sama compiler. Kita mendeklarasikan kalau
sebuah trait itu unsafe dengan menambahkan keyword unsafe sebelum keyword trait dan
menandai implementasi dari trait tersebut sebagai unsafe juga, seperti yang ditunjukin
di Listing 20-12.
unsafe trait Foo {
// methods go here
}
unsafe impl Foo for i32 {
// method implementations go here
}
fn main() {}Dengan memakai unsafe impl, kita lagi berjanji kalau kita bakal menjunjung tinggi
aturan-aturan mutlak (invariants) yang tidak bisa diverifikasi sama compiler.
Sebagai contoh, ingat kembali marker traits Send dan Sync yang kita bahas di
“Konkurensi yang Bisa Diperluas dengan Trait Send dan Sync”
di Bab 16: compiler mengimplementasikan trait-trait ini secara otomatis kalau tipe-tipe
kita sepenuhnya disusun dari tipe-tipe lain yang udah mengimplementasikan Send dan
Sync. Kalau kita ngimplementasiin sebuah tipe yang mengandung sebuah tipe yang tidak
mengimplementasikan Send atau Sync, contohnya raw pointers, dan kita mau menandai
tipe tersebut sebagai Send atau Sync, kita wajib memakai unsafe. Rust tidak bisa
memverifikasi kalau tipe kita itu mematuhi jaminan bahwa dia bisa dikirim ke thread
lain dengan aman atau diakses dari banyak threads dengan aman; makanya, kita perlu
ngelakuin pengecekan itu sendiri secara manual dan ngasih tahu hal itu lewat keyword unsafe.
Mengakses Field dari Union
Tindakan (action) terakhir yang cuma bisa bekerja dengan keyword unsafe adalah
mengakses field (bidang) dari sebuah union. Sebuah union (gabungan) itu mirip sama
sebuah struct, tapi cuma satu aja dari field yang dideklarasikan yang bisa dipakai
di dalam sebuah instance pada satu waktu tertentu. Unions biasanya dipakai buat
berinteraksi dengan unions yang ada di dalam kode C. Mengakses field dari union
itu unsafe karena Rust tidak bisa ngejamin tipe dari data yang saat itu lagi
disimpan di dalam instance union tersebut. Kita bisa belajar lebih banyak soal unions
di Rust Reference.
Memakai Miri Buat Mengecek Kode Unsafe
Pas kita lagi nulis kode unsafe, kita mungkin pengen ngecek apakah kode yang udah kita tulis itu benar-benar aman dan udah betul (correct) atau tidak. Salah satu cara terbaik buat ngebuktiin itu adalah dengan memakai Miri, sebuah tool resmi Rust buat mendeteksi perilaku yang tidak terdefinisi (undefined behavior). Kalau borrow checker itu adalah sebuah tool yang statis (static) yang bekerja pas compile time, Miri itu adalah tool yang dinamis (dynamic) yang bekerja pas runtime. Miri mengecek kode kita dengan cara menjalankan program kita, atau seperangkat pengujiannya (test suite), lalu mendeteksi kapan kita melanggar aturan-aturan yang Miri pahami tentang gimana seharusnya Rust bekerja.
Memakai Miri mewajibkan kita punya instalasi Rust versi nightly (yang mana kita obrolin
lebih banyak di Lampiran G: Gimana Rust Dibuat dan “Nightly Rust”). Kita bisa
menginstal baik Rust versi nightly sekaligus tool Miri dengan mengetikkan perintah
rustup +nightly component add miri. Hal ini tidak bakal ngubah versi Rust apa yang
lagi dipakai sama project kita; dia cuma nambahin tool tersebut ke sistem kita biar
kita bisa memakainya pas kita mau aja. Kita bisa menjalankan Miri di sebuah project dengan
ngetik cargo +nightly miri run atau cargo +nightly miri test.
Sebagai contoh betapa bergunanya ini, bayangin apa yang terjadi pas kita menjalankan Miri buat nge-tes kode di Listing 20-7.
$ cargo +nightly miri run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.01s
Running `file:///home/.rustup/toolchains/nightly/bin/cargo-miri runner target/miri/debug/unsafe-example`
warning: integer-to-pointer cast
--> src/main.rs:5:13
|
5 | let r = address as *mut i32;
| ^^^^^^^^^^^^^^^^^^^ integer-to-pointer cast
|
= help: this program is using integer-to-pointer casts or (equivalently) `ptr::with_exposed_provenance`, which means that Miri might miss pointer bugs in this program
= help: see https://doc.rust-lang.org/nightly/std/ptr/fn.with_exposed_provenance.html for more details on that operation
= help: to ensure that Miri does not miss bugs in your program, use Strict Provenance APIs (https://doc.rust-lang.org/nightly/std/ptr/index.html#strict-provenance, https://crates.io/crates/sptr) instead
= help: you can then set `MIRIFLAGS=-Zmiri-strict-provenance` to ensure you are not relying on `with_exposed_provenance` semantics
= help: alternatively, `MIRIFLAGS=-Zmiri-permissive-provenance` disables this warning
= note: BACKTRACE:
= note: inside `main` at src/main.rs:5:13: 5:32
error: Undefined Behavior: pointer not dereferenceable: pointer must be dereferenceable for 40000 bytes, but got 0x1234[noalloc] which is a dangling pointer (it has no provenance)
--> src/main.rs:7:35
|
7 | let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) };
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ Undefined Behavior occurred here
|
= help: this indicates a bug in the program: it performed an invalid operation, and caused Undefined Behavior
= help: see https://doc.rust-lang.org/nightly/reference/behavior-considered-undefined.html for further information
= note: BACKTRACE:
= note: inside `main` at src/main.rs:7:35: 7:70
note: some details are omitted, run with `MIRIFLAGS=-Zmiri-backtrace=full` for a verbose backtrace
error: aborting due to 1 previous error; 1 warning emitted
Miri ngingetin kita dengan tepat kalau kita lagi nge-cast (mengubah tipe) sebuah integer jadi sebuah pointer, yang mana mungkin aja jadi masalah tapi Miri tidak bisa mendeteksi apakah emang ada masalah atau tidak karena Miri tidak tahu dari mana asal-usul si pointer tersebut. Terus, Miri ngembaliin sebuah error di mana Listing 20-7 punya perilaku yang tidak terdefinisi (undefined behavior) karena kita punya sebuah dangling pointer. Berkat Miri, sekarang kita jadi tahu kalau ada risiko terjadinya perilaku yang tidak terdefinisi, dan kita bisa mikirin gimana caranya ngebikin kodenya jadi aman. Di beberapa kasus, Miri bahkan bisa ngasih saran gimana cara buat ngeberesin error-error tersebut.
Miri tidak bisa menangkap semua hal yang mungkin keliru pas kita nulis kode unsafe. Miri itu adalah sebuah tool analisis yang dinamis, jadi dia cuma bisa nangkap masalah pada kode yang emang benar-benar dijalankan. Itu artinya kita perlu memakainya barengan sama teknik-teknik pengujian (testing techniques) yang oke buat ningkatin rasa percaya diri kita terhadap kode unsafe yang udah kita tulis. Miri juga tidak mencakup setiap kemungkinan yang ada yang bikin kode kita jadi cacat (unsound).
Dengan kata lain: Kalau Miri emang nangkap sebuah masalah, kita jadi tahu kalau ada sebuah bug, tapi cuma karena Miri tidak nangkap sebuah bug itu tidak berarti kalau tidak ada masalah di situ. Walaupun begitu, dia bisa nangkap sangat banyak lho. Cobain deh ngejalanin Miri di contoh-contoh kode unsafe lain di bab ini dan lihat apa aja yang dia bilang!
Kita bisa belajar lebih lanjut soal Miri di repositori GitHub-nya.
Kapan Harus Memakai Kode Unsafe
Memakai unsafe buat melakukan salah satu dari lima superpowers yang baru aja kita bahas
itu bukanlah hal yang salah atau yang dilarang keras, tapi emang lebih tricky (susah) buat
bikin kode unsafe itu jadi benar (correct) karena compiler tidak bisa ngebantu buat
menjunjung tinggi keamanan memori. Pas kita punya alasan buat memakai kode unsafe,
kita bebas aja buat melakukannya, dan dengan adanya anotasi unsafe yang eksplisit itu malah
ngebikin kita lebih gampang buat ngelacak sumber dari suatu masalah kalau sampai
masalah itu muncul nanti. Kapan pun kita nulis kode unsafe, kita bisa memakai Miri buat
ngebantu kita jadi lebih yakin kalau kode yang udah kita tulis itu benar-benar mematuhi
aturan-aturan Rust.
Buat penjelajahan yang jauh lebih dalam soal gimana cara kerja efektif dengan unsafe Rust, silakan baca panduan resmi dari Rust soal subjek ini, yaitu Rustonomicon.
Advanced Traits (Traits Tingkat Lanjut)
Advanced Traits (Traits Tingkat Lanjut)
Kita pertama kali ngebahas soal traits di “Traits: Mendefinisikan Perilaku Bersama” di Bab 10, tapi kita tidak ngebahas detail-detail yang lebih mahirnya. Sekarang setelah kita tahu lebih banyak soal Rust, kita bisa masuk ke seluk beluk (nitty-gritty) dari traits ini.
Associated Types
Associated types (tipe terkait) menghubungkan sebuah placeholder (tempat pengganti) tipe dengan sebuah trait sedemikian rupa sehingga definisi method dari trait tersebut bisa memakai tipe placeholder ini di dalam signatures-nya. Si peng-implementasi (implementor) dari trait tersebut bakal menentukan tipe konkret yang bakal dipakai buat menggantikan tipe placeholder itu buat implementasi khususnya. Dengan begitu, kita bisa mendefinisikan sebuah trait yang memakai tipe-tipe tertentu tanpa perlu tahu persis apa tipe-tipe tersebut sampai trait-nya benar-benar diimplementasikan.
Kita udah mendeskripsikan sebagian besar fitur-fitur tingkat lanjut di bab ini sebagai hal-hal yang jarang dibutuhkan. Associated types ini letaknya ada di tengah-tengah: mereka dipakai lebih jarang ketimbang fitur-fitur yang dijelaskan di bagian lain buku ini tapi lebih sering dipakai ketimbang banyak fitur lain yang dibahas di bab ini.
Salah satu contoh dari trait yang punya associated type adalah trait Iterator
yang disediakan oleh standard library. Associated type-nya dinamakan Item
dan dia bertindak sebagai pengganti buat tipe dari nilai-nilai yang lagi
diiterasi sama tipe yang mengimplementasikan trait Iterator tersebut.
Definisi dari trait Iterator ini ditunjukkan di Listing 20-13.
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}Iterator yang punya sebuah associated type ItemTipe Item itu adalah sebuah placeholder, dan definisi method next nunjukin
kalau dia bakal mengembalikan nilai-nilai bertipe Option<Self::Item>.
Peng-implementasi dari trait Iterator bakal menentukan tipe konkret buat Item,
dan method next bakal mengembalikan sebuah Option yang berisi sebuah nilai
dari tipe konkret tersebut.
Associated types mungkin kelihatannya mirip kayak konsep generik (generics),
di mana generik itu memungkinkan kita buat mendefinisikan sebuah fungsi tanpa
menentukan tipe-tipe apa yang bisa ditanganinya. Buat memeriksa perbedaan
antara kedua konsep ini, kita bakal melihat sebuah implementasi dari trait
Iterator pada sebuah tipe bernama Counter yang menentukan kalau tipe Item-nya
adalah u32:
struct Counter {
count: u32,
}
impl Counter {
fn new() -> Counter {
Counter { count: 0 }
}
}
impl Iterator for Counter {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
// --snip--
if self.count < 5 {
self.count += 1;
Some(self.count)
} else {
None
}
}
}Sintaks ini kelihatannya bisa disamain sama sintaksnya generik. Terus kenapa
tidak sekalian aja mendefinisikan trait Iterator pakai generik, seperti yang
ditunjukkan di Listing 20-14?
pub trait Iterator<T> {
fn next(&mut self) -> Option<T>;
}Iterator yang memakai generikPerbedaannya adalah saat memakai generik, seperti di Listing 20-14, kita
wajib menganotasi tipe-tipenya di setiap implementasinya; karena kita juga
bisa mengimplementasikan Iterator<String> for Counter atau tipe apa pun
lainnya, kita jadinya bisa punya banyak implementasi dari Iterator buat
Counter. Dengan kata lain, saat sebuah trait punya parameter generik,
dia bisa diimplementasikan buat satu tipe berkali-kali, asalkan tipe konkret
dari parameter tipe generiknya selalu berbeda setiap kalinya. Saat kita memakai
method next pada Counter, kita harus ngasih anotasi tipe buat nunjukin
implementasi dari Iterator yang mana yang mau kita pakai.
Dengan associated types, kita tidak perlu menganotasi tipe-tipe karena kita
tidak bisa mengimplementasikan sebuah trait pada satu tipe berkali-kali. Di
Listing 20-13 yang mana definisinya memakai associated types, kita cuma bisa
memilih tipe apa yang bakal jadi Item itu satu kali aja karena cuma boleh
ada satu impl Iterator for Counter. Kita tidak perlu menyebutkan kalau kita
mau sebuah iterator dari nilai-nilai u32 di mana-mana di kode pas kita
manggil next pada Counter.
Associated types juga menjadi bagian dari kontrak si trait tersebut: para peng-implementasi dari trait tersebut wajib menyediakan sebuah tipe buat menggantikan placeholder associated type-nya. Associated types sering kali punya nama yang mendeskripsikan gimana tipe tersebut bakal dipakai, dan mendokumentasikan associated type di dalam dokumentasi API adalah sebuah praktik yang baik.
Parameter Tipe Generik Default (Bawaan) dan Operator Overloading
Saat kita memakai parameter tipe generik, kita bisa menentukan tipe konkret default
(bawaan) buat tipe generik tersebut. Ini ngehapus kebutuhan bagi para peng-implementasi
dari trait tersebut buat menentukan tipe konkret kalau tipe default-nya emang udah pas.
Kita menentukan sebuah tipe default saat mendeklarasikan sebuah tipe generik dengan
sintaks <PlaceholderType=ConcreteType>.
Satu contoh keren dari situasi di mana teknik ini sangat berguna adalah pada
operator overloading (penumpukan fungsi operator), di mana kita mengkustomisasi
perilaku dari sebuah operator (seperti +) di situasi-situasi tertentu.
Rust tidak mengizinkan kita buat membikin operator kita sendiri atau melakukan
overload pada sembarang operator. Tapi kita bisa melakukan overload pada operasi-
operasi dan trait-trait korespondennya yang terdaftar di std::ops dengan
mengimplementasikan trait-trait yang berkaitan sama operator tersebut. Misalnya,
di Listing 20-15 kita melakukan overload pada operator + buat menjumlahkan
dua instance Point bersama-sama. Kita ngelakuin ini dengan mengimplementasikan
trait Add pada struct Point.
use std::ops::Add;
#[derive(Debug, Copy, Clone, PartialEq)]
struct Point {
x: i32,
y: i32,
}
impl Add for Point {
type Output = Point;
fn add(self, other: Point) -> Point {
Point {
x: self.x + other.x,
y: self.y + other.y,
}
}
}
fn main() {
assert_eq!(
Point { x: 1, y: 0 } + Point { x: 2, y: 3 },
Point { x: 3, y: 3 }
);
}Add buat nge-overload operator + untuk instance-instance PointMethod add ngejumlahin nilai x dari dua instance Point dan nilai y dari dua
instance Point buat membikin sebuah Point baru. Trait Add punya sebuah
associated type bernama Output yang menentukan tipe yang dikembalikan dari
method add.
Tipe generik default di kode ini ada di dalam trait Add. Ini adalah definisinya:
#![allow(unused)]
fn main() {
trait Add<Rhs=Self> {
type Output;
fn add(self, rhs: Rhs) -> Self::Output;
}
}Kode ini harusnya kelihatan familier pada umumnya: sebuah trait dengan satu method
dan satu associated type. Bagian yang baru adalah Rhs=Self: sintaks ini disebut
default type parameters (parameter tipe default). Parameter tipe generik Rhs
(singkatan dari “right-hand side” atau sisi kanan) mendefinisikan tipe dari
parameter rhs di dalam method add. Kalau kita tidak menentukan sebuah tipe konkret
buat Rhs saat kita mengimplementasikan trait Add, tipe dari Rhs bakal secara default
menjadi Self, yang mana merupakan tipe di mana kita lagi mengimplementasikan trait
Add tersebut.
Saat kita mengimplementasikan Add buat Point, kita memakai nilai default buat
Rhs karena kita mau menjumlahkan dua instance Point. Mari kita lihat sebuah
contoh pengimplementasian trait Add di mana kita mau mengkustomisasi tipe Rhs
ketimbang memakai nilai default-nya.
Kita punya dua struct, Millimeters dan Meters, yang menampung nilai-nilai dalam
satuan (units) yang berbeda. Pembungkusan tipis (thin wrapping) dari sebuah tipe
yang udah ada ke dalam struct lain ini dikenal sebagai newtype pattern, yang mana bakal
kita jelasin lebih detail di bagian “Memakai Newtype Pattern Buat Mengimplementasikan
External Traits”. Kita pengen bisa menjumlahkan nilai-nilai dalam millimeter
dengan nilai-nilai dalam meter lalu punya implementasi dari Add yang melakukan
konversinya dengan benar. Kita bisa mengimplementasikan Add buat Millimeters
dengan Meters sebagai si Rhs, seperti yang ditunjukkan di Listing 20-16.
use std::ops::Add;
struct Millimeters(u32);
struct Meters(u32);
impl Add<Meters> for Millimeters {
type Output = Millimeters;
fn add(self, other: Meters) -> Millimeters {
Millimeters(self.0 + (other.0 * 1000))
}
}Add pada Millimeters buat menjumlahkan Millimeters dan MetersBuat menjumlahkan Millimeters dan Meters, kita menentukan impl Add<Meters>
buat menge-set nilai dari parameter tipe Rhs ketimbang memakai nilai default Self.
Kita bakal memakai parameter tipe default dalam dua cara utama:
- Buat memperluas sebuah tipe tanpa merusak kode yang udah ada (existing code)
- Buat memungkinkan adanya kustomisasi di kasus-kasus spesifik yang mana mayoritas user tidak bakal membutuhkannya
Trait Add di standard library adalah contoh dari tujuan yang kedua: biasanya,
kita bakal menjumlahkan dua tipe yang sama, tapi trait Add menyediakan kemampuan
buat melakukan kustomisasi lebih dari itu. Memakai sebuah parameter tipe default di
dalam definisi trait Add berarti kita tidak perlu menyebutkan parameter tambahan itu
di sebagian besar waktunya. Dengan kata lain, sedikit boilerplate code (kode
berulang-ulang) tidak lagi diperlukan, ngebikin penggunaan trait-nya jadi lebih
gampang.
Tujuan pertama itu mirip sama tujuan kedua tapi kebalikannya: kalau kita mau nambahin sebuah parameter tipe ke sebuah trait yang udah ada, kita bisa ngasih dia sebuah nilai default biar ekstensi fungsionalitas dari trait tersebut tidak merusak kode implementasi yang udah ada.
Menghilangkan Ambiguitas (Disambiguating) di Antara Method-method yang Punya Nama yang Sama
Tidak ada aturan di Rust yang mencegah sebuah trait dari punya method dengan nama yang sama dengan method dari trait lain, dan Rust juga tidak mencegah kita buat mengimplementasikan kedua trait tersebut pada satu tipe. Sangat mungkin juga buat mengimplementasikan sebuah method secara langsung pada tipe tersebut dengan nama yang sama kayak nama-nama method dari trait-trait tadi.
Pas kita memanggil method-method yang punya nama yang sama ini, kita harus ngasih
tahu Rust mana yang mau kita pakai. Coba perhatikan kode di Listing 20-17 di mana
kita udah mendefinisikan dua trait, Pilot dan Wizard, yang mana dua-duanya punya
sebuah method bernama fly. Kita lalu mengimplementasikan kedua trait tersebut pada
sebuah tipe Human yang ternyata juga udah punya sebuah method bernama fly yang
diimplementasikan langsung padanya. Masing-masing method fly ini ngelakuin hal yang
berbeda.
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {}fly dan diimplementasikan pada tipe Human, dan sebuah method fly juga diimplementasikan langsung pada Human.Saat kita memanggil fly pada sebuah instance dari Human, compiler secara default
bakal memanggil method yang diimplementasikan secara langsung pada tipe tersebut,
seperti yang ditunjukkan di Listing 20-18.
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {
let person = Human;
person.fly();
}fly pada sebuah instance dari HumanMenjalankan kode ini bakal mencetak *waving arms furiously* (melambaikan tangan
dengan geram), nunjukin kalau Rust memanggil method fly yang diimplementasikan pada
Human secara langsung.
Buat memanggil method fly dari trait Pilot atau trait Wizard, kita harus
memakai sintaks yang lebih eksplisit buat menyebutkan method fly yang mana yang kita
maksud. Listing 20-19 mendemonstrasikan sintaks ini.
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {
let person = Human;
Pilot::fly(&person);
Wizard::fly(&person);
person.fly();
}fly dari trait mana yang mau kita panggilMenyebutkan nama trait sebelum nama method-nya memperjelas bagi Rust implementasi
dari fly yang mana yang mau kita panggil. Kita juga bisa menuliskan Human::fly(&person),
yang mana ini ekuivalen (sama) dengan person.fly() yang kita pakai di Listing
20-19, tapi cara ini sedikit lebih panjang buat ditulis padahal kita tidak perlu
menghilangkan ambiguitas apa pun di sana.
Menjalankan kode ini bakal mencetak yang berikut ini:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.46s
Running `target/debug/traits-example`
This is your captain speaking.
Up!
*waving arms furiously*
Karena method fly punya parameter self, kalau kita punya dua tipe yang dua-
duanya mengimplementasikan satu trait, Rust bisa nyari tahu implementasi dari trait
mana yang harus dipakai berdasarkan tipe dari self.
Namun, associated functions (fungsi terkait) yang bukan methods tidak punya parameter
self. Saat ada beberapa tipe atau trait yang mendefinisikan fungsi-fungsi non-method
dengan nama fungsi yang sama, Rust tidak selalu tahu tipe mana yang kita maksud
kecuali kalau kita memakai fully qualified syntax (sintaks yang dikualifikasikan secara
penuh). Misalnya, di Listing 20-20 kita membikin sebuah trait buat penampungan hewan
(animal shelter) yang mau menamai semua anjing bayi (baby dogs) dengan nama Spot.
Kita membikin sebuah trait Animal dengan sebuah fungsi associated non-method
bernama baby_name. Trait Animal ini diimplementasikan buat struct Dog, yang
mana padanya kita juga menyediakan sebuah fungsi associated non-method baby_name
secara langsung.
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", Dog::baby_name());
}Kita mengimplementasikan kode buat menamai semua anak anjing dengan Spot di dalam
fungsi associated baby_name yang didefinisikan pada Dog. Tipe Dog juga
mengimplementasikan trait Animal, yang mendeskripsikan karakteristik yang
dimiliki semua hewan. Anjing bayi dipanggil puppies (anak anjing), dan itu
diekspresikan di dalam implementasi trait Animal pada Dog di dalam fungsi
baby_name yang diasosiasikan dengan trait Animal.
Di main, kita memanggil fungsi Dog::baby_name, yang mana memanggil fungsi
associated yang didefinisikan pada Dog secara langsung. Kode ini mencetak
yang berikut ini:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.54s
Running `target/debug/traits-example`
A baby dog is called a Spot
Output ini bukanlah apa yang kita inginkan. Kita pengen memanggil fungsi baby_name
yang merupakan bagian dari trait Animal yang kita implementasikan pada Dog
supaya kodenya mencetak A baby dog is called a puppy. Teknik menyebutkan nama
trait yang kita pakai di Listing 20-19 tidak bisa membantu di sini; kalau kita ngubah
main menjadi kode yang ada di Listing 20-21, kita bakal dapat error kompilasi.
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", Animal::baby_name());
}baby_name dari trait Animal, tapi Rust tidak tahu implementasi mana yang harus dipakaiKarena Animal::baby_name tidak punya parameter self, dan bisa aja ada
tipe-tipe lain yang mengimplementasikan trait Animal, Rust tidak bisa nyari tahu
implementasi dari Animal::baby_name yang mana yang kita pengen. Kita bakal dapat
error compiler ini:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0790]: cannot call associated function on trait without specifying the corresponding `impl` type
--> src/main.rs:20:43
|
2 | fn baby_name() -> String;
| ------------------------- `Animal::baby_name` defined here
...
20 | println!("A baby dog is called a {}", Animal::baby_name());
| ^^^^^^^^^^^^^^^^^^^ cannot call associated function of trait
|
help: use the fully-qualified path to the only available implementation
|
20 | println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
| +++++++ +
For more information about this error, try `rustc --explain E0790`.
error: could not compile `traits-example` (bin "traits-example") due to 1 previous error
Buat menghilangkan ambiguitas ini dan ngasih tahu Rust kalau kita mau memakai
implementasi Animal buat Dog ketimbang implementasi Animal buat tipe
lain, kita perlu memakai fully qualified syntax. Listing 20-22 mendemonstrasikan
gimana cara memakai fully qualified syntax.
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
}baby_name dari trait Animal seperti yang diimplementasikan pada DogKita menyediakan Rust dengan sebuah anotasi tipe di dalam kurung sudut, yang
mana mengindikasikan kalau kita mau memanggil method baby_name dari trait
Animal seperti yang diimplementasikan pada Dog dengan mengatakan bahwa
kita mau memperlakukan tipe Dog sebagai sebuah Animal buat pemanggilan fungsi
ini. Kode ini sekarang bakal mencetak apa yang kita mau:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/traits-example`
A baby dog is called a puppy
Secara umum, fully qualified syntax didefinisikan kayak gini:
<Type as Trait>::function(receiver_if_method, next_arg, ...);Buat associated functions yang bukan method, tidak bakal ada yang namanya
receiver (penerima): yang ada cuma daftar dari argumen-argumen lainnya aja.
Kita bisa aja memakai fully qualified syntax di mana-mana setiap kali kita manggil
fungsi atau method. Namun, kita dibolehin buat ngilangin (omit) bagian apa pun dari
sintaks ini yang mana Rust bisa cari tahu sendiri dari informasi lain di programnya.
Kita cuma perlu memakai sintaks yang lebih panjang (verbose) ini di kasus-kasus di
mana ada banyak implementasi yang memakai nama yang sama dan Rust butuh bantuan buat
mengidentifikasi implementasi mana yang mau kita panggil.
Memakai Supertraits
Terkadang kita mungkin menulis sebuah definisi trait yang bergantung sama trait lain: supaya sebuah tipe bisa mengimplementasikan trait yang pertama, kita mau mewajibkan agar tipe tersebut juga mengimplementasikan trait yang kedua. Kita bakal melakukan ini supaya definisi trait kita bisa memanfaatkan item-item associated (terkait) dari trait yang kedua tersebut. Trait yang diandalkan (relied on) oleh definisi trait kita itu disebut sebagai sebuah supertrait dari trait kita.
Misalnya, katakanlah kita mau membikin sebuah trait OutlinePrint dengan sebuah
method outline_print yang bakal mencetak sebuah nilai yang udah diformat sehingga
dia dibingkai pakai tanda bintang (asterisks). Yakni, misalkan ada sebuah struct
Point yang mengimplementasikan trait Display dari standard library sehingga
hasilnya (x, y), maka saat kita memanggil outline_print pada instance Point
yang punya nilai 1 buat x dan 3 buat y, dia seharusnya mencetak yang
berikut ini:
**********
* *
* (1, 3) *
* *
**********
Di dalam implementasi dari method outline_print, kita pengen memakai fungsionalitas
dari trait Display. Oleh karena itu, kita perlu menentukan kalau trait
OutlinePrint ini cuma bakal bekerja buat tipe-tipe yang juga mengimplementasikan
Display dan menyediakan fungsionalitas yang dibutuhin sama OutlinePrint. Kita bisa
melakukan itu di definisi trait-nya dengan menentukan OutlinePrint: Display.
Teknik ini mirip sama menambahkan sebuah trait bound ke dalam sebuah trait.
Listing 20-23 menunjukkan sebuah implementasi dari trait OutlinePrint.
use std::fmt;
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
fn main() {}OutlinePrint yang mewajibkan fungsionalitas dari DisplayKarena kita udah menentukan kalau OutlinePrint mewajibkan adanya trait Display,
kita jadi bisa memakai fungsi to_string yang mana otomatis diimplementasikan
buat tipe apa pun yang mengimplementasikan Display. Kalau kita mencoba memakai
to_string tanpa menambahkan titik dua dan menentukan trait Display setelah
nama trait-nya, kita bakal dapat error yang bilang kalau tidak ada method bernama
to_string yang ditemukan buat tipe &Self di dalam scope saat ini.
Mari kita lihat apa yang terjadi saat kita mencoba mengimplementasikan OutlinePrint
pada sebuah tipe yang tidak mengimplementasikan Display, kayak struct Point ini
misalnya:
use std::fmt;
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Point {
x: i32,
y: i32,
}
impl OutlinePrint for Point {}
fn main() {
let p = Point { x: 1, y: 3 };
p.outline_print();
}Kita dapat error yang bilang kalau Display itu diwajibkan tapi tidak
diimplementasikan:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:20:23
|
20 | impl OutlinePrint for Point {}
| ^^^^^ the trait `std::fmt::Display` is not implemented for `Point`
|
note: required by a bound in `OutlinePrint`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint`
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:24:7
|
24 | p.outline_print();
| ^^^^^^^^^^^^^ the trait `std::fmt::Display` is not implemented for `Point`
|
note: required by a bound in `OutlinePrint::outline_print`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint::outline_print`
4 | fn outline_print(&self) {
| ------------- required by a bound in this associated function
For more information about this error, try `rustc --explain E0277`.
error: could not compile `traits-example` (bin "traits-example") due to 2 previous errors
Buat memperbaiki ini, kita mengimplementasikan Display pada Point buat memenuhi
(satisfy) batasan yang diwajibkan sama OutlinePrint, kayak gini:
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Point {
x: i32,
y: i32,
}
impl OutlinePrint for Point {}
use std::fmt;
impl fmt::Display for Point {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "({}, {})", self.x, self.y)
}
}
fn main() {
let p = Point { x: 1, y: 3 };
p.outline_print();
}Lalu setelahnya, mengimplementasikan trait OutlinePrint pada Point bakal berhasil
di-compile dengan sukses, dan kita bisa memanggil outline_print pada sebuah instance
Point buat nampilin dia di dalam sebuah bingkai yang isinya tanda bintang.
Memakai Newtype Pattern Buat Mengimplementasikan External Traits
Di “Mengimplementasikan Trait pada Sebuah Tipe” di Bab 10, kita sempat nyebut soal orphan rule (aturan yatim piatu) yang menyatakan kalau kita cuma dibolehin buat mengimplementasikan sebuah trait pada sebuah tipe kalau entah trait tersebut atau tipe tersebut, atau bahkan keduanya, itu berada di (local to) crate kita sendiri. Kita mungkin aja ngakalin (get around) batasan ini memakai newtype pattern, yang melibatkan pembuatan sebuah tipe baru di dalam sebuah tuple struct. (Kita udah ngebahas tuple structs di “Memakai Tuple Structs Tanpa Field Bernama buat Bikin Tipe yang Beda” di Bab 5.) Tuple struct ini bakal punya satu field dan bertindak sebagai sebuah pembungkus tipis (thin wrapper) di sekitar tipe yang mana mau kita implementasikan trait padanya. Kemudian tipe pembungkus (wrapper type) itu jadinya sifatnya lokal buat crate kita, dan kita bisa mengimplementasikan trait tersebut pada si pembungkus ini. Newtype adalah sebuah istilah yang asalnya dari bahasa pemrograman Haskell. Tidak ada pinalti performa runtime akibat memakai pola ini, dan tipe pembungkus ini bakal dihilangkan (elided) saat compile time.
Sebagai contoh, katakanlah kita mau mengimplementasikan Display pada Vec<T>,
yang mana dilarang secara langsung sama si orphan rule karena baik trait Display
maupun tipe Vec<T> itu didefinisikan di luar crate kita. Kita bisa membikin sebuah
struct Wrapper yang menampung sebuah instance dari Vec<T>; terus kita bisa
mengimplementasikan Display pada Wrapper dan lalu memakai nilai Vec<T>
tersebut, seperti yang ditunjukkan di Listing 20-24.
use std::fmt;
struct Wrapper(Vec<String>);
impl fmt::Display for Wrapper {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "[{}]", self.0.join(", "))
}
}
fn main() {
let w = Wrapper(vec![String::from("hello"), String::from("world")]);
println!("w = {w}");
}Wrapper di sekitar Vec<String> buat mengimplementasikan DisplayImplementasi dari Display memakai self.0 buat ngakses nilai Vec<T> yang
ada di dalamnya karena Wrapper adalah sebuah tuple struct dan Vec<T> adalah
item yang ada di indeks 0 di dalam tuple tersebut. Terus kita bisa deh memakai
fungsionalitas dari trait Display ini pada Wrapper.
Kelemahan dari memakai teknik ini adalah bahwa Wrapper adalah sebuah tipe baru,
jadi dia tidak punya method-method dari nilai yang dia tampung di dalamnya.
Kita harus mengimplementasikan semua method-method dari Vec<T> secara langsung
pada Wrapper sedemikian rupa sehingga method-method itu mendelegasikan panggilannya
ke self.0, yang mana bakal memungkinkan kita buat memperlakukan Wrapper persis
kayak sebuah Vec<T>. Kalau kita pengen tipe baru ini buat punya setiap method yang
dipunyai sama tipe internalnya, mengimplementasikan trait Deref pada si Wrapper
buat mengembalikan tipe internalnya bisa jadi sebuah solusi (kita udah ngebahas
pengimplementasian trait Deref di “Memperlakukan Smart Pointers seperti Referensi
Biasa dengan Deref” di Bab 15). Kalau kita tidak pengen
tipe Wrapper ini buat punya semua method dari tipe internalnya—misalnya, buat
ngebatesin perilaku dari si tipe Wrapper tersebut—maka kita harus mengimplementasikan
hanya method-method yang emang kita mau aja secara manual.
Newtype pattern ini juga berguna bahkan ketika tidak ada trait yang terlibat. Mari kita alihkan fokus kita lalu ngelihat beberapa cara tingkat lanjut (advanced ways) buat berinteraksi dengan sistem tipe Rust.
Advanced Types (Tipe Tingkat Lanjut)
Advanced Types (Tipe Tingkat Lanjut)
Sistem tipe Rust punya beberapa fitur yang sejauh ini cuma kita sebut aja
tapi belum benar-benar kita bahas. Kita bakal mulai dengan membahas newtypes
secara umum sembari kita menyelidiki kenapa newtypes itu berguna sebagai tipe.
Terus kita bakal lanjut ke type aliases (alias tipe), sebuah fitur yang mirip sama
newtypes tapi punya semantik yang agak beda. Kita juga bakal ngebahas
tipe ! dan dynamically sized types (tipe-tipe yang berukuran dinamis).
Memakai Newtype Pattern Buat Keamanan Tipe dan Abstraksi
Bagian ini berasumsi kalau kita udah ngebaca bagian sebelumnya “Memakai
Newtype Pattern Buat Mengimplementasikan External Traits”.
Newtype pattern (pola tipe baru) ini juga berguna buat hal-hal di luar dari
apa yang udah kita bahas sejauh ini, termasuk secara statis menegakkan
aturan supaya nilai-nilai tidak pernah tertukar (confused) dan buat
mengindikasikan satuan (units) dari sebuah nilai. Kita udah lihat contoh
pemakaian newtypes buat mengindikasikan satuan di Listing 20-16: ingat
kembali kalau struct Millimeters dan Meters itu membungkus nilai u32
di dalam sebuah newtype. Kalau kita nulis sebuah fungsi dengan parameter
bertipe Millimeters, kita tidak bakal bisa men-compile program yang
secara tidak sengaja mencoba memanggil fungsi tersebut dengan nilai
bertipe Meters atau nilai u32 biasa.
Kita juga bisa memakai newtype pattern buat mengabstraksi beberapa detail implementasi dari sebuah tipe: si tipe baru tersebut bisa ngekspos API public yang mana berbeda dari API milik tipe private yang ada di dalamnya.
Newtypes juga bisa menyembunyikan (hide) implementasi internal. Misalnya, kita
bisa aja menyediakan tipe People buat ngebungkus sebuah HashMap<i32, String>
yang nyimpan ID seseorang yang diasosiasikan dengan nama mereka. Kode yang
memakai People cuma bakal berinteraksi sama API public yang kita sediakan,
kayak method buat nambahin string nama ke dalam koleksi People; kode tersebut
tidak perlu tahu kalau kita secara internal menaruh nilai ID i32 ke nama-nama
tersebut. Newtype pattern adalah cara yang ringan (lightweight) buat mendapatkan
enkapsulasi (encapsulation) guna menyembunyikan detail implementasi, yang mana
udah kita bahas di “Encapsulation (Enkapsulasi) yang Menyembunyikan Detail
Implementasi” di Bab 18.
Membikin Sinonim Tipe dengan Type Aliases
Rust menyediakan kemampuan buat mendeklarasikan type alias (alias tipe) buat
ngasih nama lain ke tipe yang udah ada. Buat hal ini kita memakai keyword
type. Misalnya, kita bisa membikin alias Kilometers buat i32 kayak gini:
fn main() {
type Kilometers = i32;
let x: i32 = 5;
let y: Kilometers = 5;
println!("x + y = {}", x + y);
}Sekarang si alias Kilometers adalah sebuah sinonim buat i32; beda sama tipe
Millimeters dan Meters yang kita bikin di Listing 20-16, Kilometers
bukanlah sebuah tipe baru yang terpisah. Nilai-nilai yang punya tipe Kilometers
bakal diperlakukan persis sama kayak nilai-nilai bertipe i32:
fn main() {
type Kilometers = i32;
let x: i32 = 5;
let y: Kilometers = 5;
println!("x + y = {}", x + y);
}Karena Kilometers dan i32 adalah tipe yang sama, kita bisa menjumlahkan nilai
dari kedua tipe tersebut dan kita bisa ngoper nilai Kilometers ke fungsi-fungsi
yang menerima parameter i32. Namun, dengan memakai cara ini, kita tidak
dapetin keuntungan pengecekan tipe (type-checking benefits) yang kita dapat
dari pemakaian newtype pattern yang dibahas sebelumnya. Dengan kata lain, kalau kita
nyampur aduk (mix up) nilai Kilometers dan i32 di suatu tempat, compiler
tidak bakal ngasih kita error.
Kegunaan utama (main use case) dari sinonim tipe adalah buat ngurangin pengulangan (repetition). Misalnya, kita mungkin punya tipe yang panjang sekali kayak gini:
Box<dyn Fn() + Send + 'static>Nulisin tipe sepanjang ini di signatures fungsi dan sebagai anotasi tipe di semua tempat di kode kita bisa jadi melelahkan dan rentan kena error (error prone). Bayangin aja kalau punya sebuah project yang penuh dengan kode kayak yang ada di Listing 20-25.
fn main() {
let f: Box<dyn Fn() + Send + 'static> = Box::new(|| println!("hi"));
fn takes_long_type(f: Box<dyn Fn() + Send + 'static>) {
// --snip--
}
fn returns_long_type() -> Box<dyn Fn() + Send + 'static> {
// --snip--
Box::new(|| ())
}
}Sebuah type alias ngebikin kode ini jadi lebih gampang dikelola dengan cara
ngurangin pengulangan tersebut. Di Listing 20-26, kita memperkenalkan sebuah
alias bernama Thunk buat tipe yang panjang (verbose) tadi dan bisa mengganti
semua penggunaan dari tipe tersebut dengan si alias Thunk yang lebih pendek.
fn main() {
type Thunk = Box<dyn Fn() + Send + 'static>;
let f: Thunk = Box::new(|| println!("hi"));
fn takes_long_type(f: Thunk) {
// --snip--
}
fn returns_long_type() -> Thunk {
// --snip--
Box::new(|| ())
}
}Thunk, buat ngurangin pengulanganKode ini jadinya jauh lebih gampang buat dibaca dan ditulis! Milih nama yang punya makna (meaningful) buat type alias juga bisa ngebantu ngomunikasiin niat (intent) kita (thunk adalah kata yang artinya kode yang bakal dievaluasi nanti, jadi ini adalah nama yang tepat buat sebuah closure yang lagi disimpen).
Type aliases juga umumnya dipakai bareng sama tipe Result<T, E> buat ngurangin
pengulangan. Coba perhatikan modul std::io di standard library. Operasi
I/O (input/output) itu sering sekali mengembalikan Result<T, E> buat menangani
situasi-situasi pas operasinya gagal jalan. Library ini punya struct
std::io::Error yang merepresentasikan semua kemungkinan error I/O. Banyak
dari fungsi-fungsi di std::io bakal mengembalikan Result<T, E> di mana si
E itu adalah std::io::Error, kayak misalnya fungsi-fungsi di dalam trait
Write ini:
use std::fmt;
use std::io::Error;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize, Error>;
fn flush(&mut self) -> Result<(), Error>;
fn write_all(&mut self, buf: &[u8]) -> Result<(), Error>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<(), Error>;
}Bagian Result<..., Error> itu diulang berkali-kali. Karena hal itu, std::io
punya deklarasi type alias berikut ini:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}Karena deklarasi ini ada di dalam modul std::io, kita bisa memakai alias
fully qualified std::io::Result<T>; yakni, sebuah Result<T, E> dengan si
E udah diisi sebagai std::io::Error. Alhasil, signatures dari fungsi-fungsi di
trait Write kelihatannya jadi kayak gini deh:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}Type alias ini sangat ngebantu dalam dua hal: dia ngebikin kodenya jadi
lebih gampang ditulis dan dia ngasih kita sebuah antarmuka (interface) yang
konsisten di seluruh std::io. Karena dia cuma sebuah alias, dia sebenernya
cuma Result<T, E> biasa aja, yang berarti kita bisa memakai method apa pun yang
berlaku buat Result<T, E> dengannya, sekaligus juga sintaks-sintaks spesial
kayak operator ?.
Tipe Never (Tak Pernah) yang Tidak Pernah Mengembalikan Apa-apa
Rust punya tipe spesial bernama ! yang mana dikenal di bahasa gaulnya
teori tipe sebagai empty type (tipe kosong) karena dia tidak punya nilai
sama sekali. Kita lebih milih menyebutnya never type (tipe tak pernah)
karena dia berdiri menempati posisi dari tipe kembalian saat sebuah fungsi tidak
bakal pernah mengembalikan (never return) apa-apa. Ini adalah contohnya:
fn bar() -> ! {
// --snip--
panic!();
}Kode ini dibaca sebagai “fungsi bar mengembalikan never.” Fungsi-fungsi yang
mengembalikan never disebut diverging functions (fungsi divergen). Kita
tidak bisa membikin nilai dari tipe !, jadi si bar itu emang tidak mungkin bisa
mengembalikan apa-apa.
Tapi apa gunanya coba sebuah tipe yang kita tidak bisa bikin nilai buatnya sama sekali? Ingat kembali kode dari Listing 2-5, bagian dari game tebak angka; kita udah menaruh sedikit dari bagian kode itu di sini di Listing 20-27.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
// --snip--
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}match dengan arm yang berakhir dengan continueWaktu itu, kita mengabaikan (skipped over) beberapa detail di kode ini. Di
“Konstruk Control Flow match” di Bab 6, kita ngebahas
kalau match arms itu semuanya wajib mengembalikan tipe yang sama. Jadi, misalnya,
kode berikut ini tidak bakal jalan:
fn main() {
let guess = "3";
let guess = match guess.trim().parse() {
Ok(_) => 5,
Err(_) => "hello",
};
}Tipe dari guess di kode ini wajib jadi integer sekaligus string, padahal
Rust mewajibkan guess buat cuma punya satu tipe aja. Terus si continue itu
ngembaliin apa dong? Gimana ceritanya kita dibolehin buat mengembalikan nilai
u32 dari satu arm padahal punya arm lain yang berakhir dengan continue di
Listing 20-27?
Seperti yang mungkin udah kita tebak, continue itu punya nilai !. Yaitu, saat
Rust menghitung tipe dari guess, dia ngelihat ke kedua match arms tersebut,
yang pertama bernilai u32 dan yang terakhir (latter) bernilai !. Karena !
itu tidak bakal pernah bisa punya nilai, Rust memutuskan kalau tipe dari guess
adalah u32.
Cara formal buat mendeskripsikan perilaku ini adalah bahwa ekspresi-ekspresi dari
tipe ! itu bisa dipaksa (coerced) menjadi tipe apa aja yang lain. Kita
dibolehin buat mengakhiri match arm ini dengan continue karena continue
tidak mengembalikan nilai; sebagai gantinya, dia memindahkan kontrol kembali ke
atas perulangannya (loop), jadi di kasus Err, kita tidak pernah memberikan
sebuah nilai ke guess.
Tipe never ini berguna bareng macro panic! juga. Ingat kembali fungsi
unwrap yang kita panggil pada nilai-nilai Option<T> buat menghasilkan nilai atau
jadi panic dengan definisi seperti ini:
enum Option<T> {
Some(T),
None,
}
use crate::Option::*;
impl<T> Option<T> {
pub fn unwrap(self) -> T {
match self {
Some(val) => val,
None => panic!("called `Option::unwrap()` on a `None` value"),
}
}
}Di kode ini, hal yang sama juga terjadi kayak yang ada di match di Listing
20-27: Rust ngelihat kalau val punya tipe T dan panic! punya tipe !, jadi
hasil dari keseluruhan ekspresi match tersebut adalah T. Kode ini bisa jalan
karena panic! tidak memproduksi sebuah nilai; dia sekadar memberhentikan programnya.
Di kasus None, kita tidak bakal mengembalikan nilai dari unwrap, jadi kode ini
itu valid.
Satu ekspresi terakhir yang punya tipe ! adalah sebuah loop:
fn main() {
print!("forever ");
loop {
print!("and ever ");
}
}Di sini, loop tersebut tidak pernah berakhir, jadi nilai dari ekspresinya
adalah !. Namun, ini tidak bakal benar kalau seandainya kita memasukkan
break, karena perulangan tersebut bakal dihentikan pas dia mencapai break.
Tipe yang Berukuran Dinamis (Dynamically Sized Types) dan Trait Sized
Rust perlu tahu detail-detail tertentu tentang tipe-tipenya, seperti seberapa banyak ruang yang harus dialokasikan buat menyimpan sebuah nilai dari suatu tipe tertentu. Hal ini ngebikin satu sudut dari sistem tipenya jadi agak membingungkan pada awalnya: yakni konsep tentang dynamically sized types (tipe-tipe yang berukuran dinamis). Terkadang disebut juga sebagai DSTs atau unsized types (tipe tanpa ukuran tetap), tipe-tipe ini membiarkan kita nulis kode yang memakai nilai-nilai yang mana ukurannya cuma bisa kita ketahui saat runtime.
Mari kita gali detail-detail dari sebuah tipe berukuran dinamis yang bernama
str, yang mana udah sering kita pakai di sepanjang buku ini. Yap benar, bukan
&str, melainkan si str itu sendiri sendirian, dia itu adalah sebuah DST. Di
banyak kasus, kayak misalnya pas lagi nyimpan teks yang dimasukkan (entered) oleh
user, kita tidak bisa tahu seberapa panjang string-nya tersebut sampai runtime
datang. Itu artinya kita tidak bisa membikin variabel dengan tipe str, dan
kita juga tidak bisa memakai argumen bertipe str. Coba perhatikan kode berikut,
yang mana tidak bisa jalan:
fn main() {
let s1: str = "Hello there!";
let s2: str = "How's it going?";
}Rust butuh tahu seberapa besar memori yang harus dialokasikan buat nilai apa pun
dari suatu tipe tertentu, dan semua nilai dari sebuah tipe itu diwajibkan buat
memakai jumlah ruang memori yang sama. Kalau seandainya Rust ngebolehin kita buat
nulis kode ini, kedua nilai str ini pasti dituntut buat menempati jumlah ruang
yang sama besarnya. Tapi kenyataannya panjang mereka itu berbeda: s1 butuh
penyimpanan memori 12 bytes dan s2 butuh 15 bytes. Inilah alasan kenapa mustahil
buat ngebikin variabel yang menampung sebuah tipe berukuran dinamis secara langsung.
Terus apa yang harus kita lakuin? Di kasus ini, kita sebenarnya udah tahu jawabannya:
kita harus membikin tipe dari s1 dan s2 menjadi &str ketimbang str.
Ingat kembali dari “String Slices” di Bab 4 kalau struktur data slice
itu cuma sekadar menyimpan posisi awal (starting position) dan panjang (length)
dari slice tersebut. Jadi, meskipun &T itu merupakan sebuah nilai tunggal
yang menyimpan alamat memori di mana si T tersebut berada, sebuah &str itu
terdiri dari dua nilai: alamat dari si str dan juga panjangnya. Alhasil, kita bisa
tahu pasti ukuran dari nilai sebuah &str saat compile time: ukurannya adalah dua
kali panjang dari sebuah usize. Yaitu, kita selalu tahu ukuran dari sebuah &str,
tidak peduli sepanjang apa pun string yang ia tunjuk tersebut. Secara umum, beginilah
cara gimana tipe berukuran dinamis itu dipakai di Rust: mereka punya ekstra sedikit
metadata yang menyimpan besaran ukuran dari informasi yang dinamis tersebut. Aturan
emas (golden rule) dari tipe yang berukuran dinamis adalah kita harus selalu menaruh
nilai-nilai dari tipe berukuran dinamis tersebut di balik (behind) semacam pointer.
Kita bisa menggabungkan str dengan berbagai macam pointer lainnya: misalnya,
Box<str> atau Rc<str>. Faktanya, kita udah ngelihat hal ini sebelumnya tapi dengan
tipe berukuran dinamis yang berbeda: yakni, traits. Setiap trait itu adalah sebuah
tipe berukuran dinamis yang bisa kita rujuk (refer to) dengan memakai nama dari
trait tersebut. Di “Memakai Trait Objects Buat Mengabstraksi Perilaku Bersama”
di Bab 18, kita nyebutin kalau buat memakai traits sebagai trait objects, kita wajib
menaruh mereka di balik sebuah pointer, seperti &dyn Trait atau Box<dyn Trait>
(Rc<dyn Trait> juga bisa jalan kok).
Buat bekerja sama DSTs, Rust menyediakan trait Sized buat menentukan apakah
ukuran dari suatu tipe itu bisa diketahui saat compile time atau tidak. Trait ini
secara otomatis diimplementasikan buat semua hal yang ukurannya bisa diketahui
saat compile time. Selain itu, Rust juga secara implisit menambahkan batasan (bound)
pada Sized ke semua fungsi generik (generic function). Yakni, definisi fungsi
generik kayak gini:
fn generic<T>(t: T) {
// --snip--
}itu sebenernya bakal diperlakukan seolah-olah kita udah nulis kayak gini:
fn generic<T: Sized>(t: T) {
// --snip--
}Secara bawaan (by default), fungsi-fungsi generik cuma bakal bekerja buat tipe-tipe yang ukurannya itu diketahui pas compile time. Namun, kita bisa memakai sintaks spesial berikut ini buat mengendurkan (relax) pembatasan tersebut:
fn generic<T: ?Sized>(t: &T) {
// --snip--
}Batasan trait bound pada ?Sized itu artinya “T mungkin Sized atau mungkin juga
tidak Sized” dan notasi ini menimpa (overrides) sifat bawaan yang mewajibkan
tipe generik buat harus punya ukuran yang udah diketahui pas compile time.
Sintaks ?Trait yang punya arti (meaning) kayak gini cuma tersedia buat trait
Sized doang ya, tidak bisa dipakai buat traits yang lain.
Perhatikan juga kalau kita juga mengubah tipe dari parameter t dari asalnya T
menjadi &T. Karena tipe tersebut bisa aja tidak Sized, kita wajib memakai dia di
balik semacam pointer. Di kasus ini, kita milih buat memakai reference (referensi).
Berikutnya, kita bakal membahas tentang fungsi dan closures!
Advanced Functions (Fungsi Tingkat Lanjut) dan Closures
Advanced Functions (Fungsi Tingkat Lanjut) dan Closures
Bagian ini mengeksplorasi beberapa fitur tingkat lanjut yang berkaitan dengan fungsi dan closures, termasuk function pointers (pointer fungsi) dan mengembalikan closures.
Function Pointers
Kita udah ngebahas gimana caranya mengoper closures ke fungsi-fungsi; kita juga
bisa mengoper fungsi biasa ke fungsi-fungsi lho! Teknik ini sangat berguna pas
kita mau ngoper fungsi yang emang udah kita definisikan sebelumnya ketimbang
harus ngebikin closure baru. Fungsi itu bisa dipaksa (coerce) menjadi
tipe fn (dengan huruf f kecil), yang mana jangan sampai tertukar sama trait
closure Fn. Tipe fn ini disebut sebagai function pointer. Mengoper fungsi
memakai function pointers bakal memungkinkan kita buat memakai fungsi sebagai
argumen buat fungsi yang lainnya.
Sintaks buat menentukan kalau sebuah parameter itu adalah function pointer itu
mirip sama sintaks closures, kayak yang ditunjukin di Listing 20-28, di mana kita
udah mendefinisikan sebuah fungsi add_one yang menjumlahkan 1 ke parameternya.
Fungsi do_twice menerima dua parameter: sebuah function pointer ke fungsi mana aja
yang nerima parameter i32 dan ngembaliin sebuah i32, dan satu nilai i32.
Fungsi do_twice ini memanggil fungsi f sebanyak dua kali, mengoper nilai arg ke
dalamnya, lalu menjumlahkan kedua hasil pemanggilan fungsi tersebut bersama-sama.
Fungsi main lalu memanggil do_twice dengan argumen add_one dan 5.
fn add_one(x: i32) -> i32 {
x + 1
}
fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32 {
f(arg) + f(arg)
}
fn main() {
let answer = do_twice(add_one, 5);
println!("The answer is: {answer}");
}fn buat nerima function pointer sebagai argumenKode ini mencetak The answer is: 12. Kita menentukan kalau parameter f di
dalam do_twice itu adalah sebuah fn yang nerima satu parameter bertipe i32
dan mengembalikan sebuah i32. Terus kita bisa manggil f di dalam isi (body)
dari do_twice. Di main, kita bisa mengoper nama fungsi add_one sebagai
argumen pertama ke do_twice.
Beda sama closures, fn itu adalah sebuah tipe bukannya trait, jadi kita
menentukan fn sebagai tipe parameternya secara langsung ketimbang harus
mendeklarasikan sebuah parameter tipe generik yang mana trait bounds-nya
memakai salah satu dari trait Fn.
Function pointers mengimplementasikan ketiga trait closure sekaligus
(Fn, FnMut, dan FnOnce), yang berarti kita bakal selalu bisa mengoper sebuah
function pointer sebagai argumen buat fungsi yang membutuhkan sebuah closure.
Praktik terbaiknya adalah nulis fungsi memakai tipe generik dan salah satu dari
trait-trait closure tersebut supaya fungsi kita bisa nerima fungsi biasa maupun
closures.
Namun, ada satu contoh di mana kita mungkin cuma mau nerima tipe fn aja dan
tidak mau nerima closures, yaitu pas kita lagi berinteraksi (interfacing)
dengan kode eksternal yang emang tidak punya closures: Fungsi-fungsi C bisa
menerima fungsi biasa sebagai argumen, tapi C tidak punya fitur closures.
Sebagai contoh buat situasi di mana kita bisa memakai sebuah closure yang
didefinisikan secara langsung (inline) atau sebuah fungsi bernama, mari kita
lihat penggunaan method map yang disediain sama trait Iterator di standard
library. Buat memakai method map buat mengubah sebuah vector angka-angka
jadi vector string-string, kita bisa memakai closure, kayak di Listing 20-29.
fn main() {
let list_of_numbers = vec![1, 2, 3];
let list_of_strings: Vec<String> =
list_of_numbers.iter().map(|i| i.to_string()).collect();
}map buat mengubah angka jadi stringAtau kita juga bisa memakai fungsi bernama sebagai argumen buat method map
ketimbang memakai sebuah closure. Listing 20-30 nunjukin bakal seperti apa
kelihatannya kalau pakai cara ini.
fn main() {
let list_of_numbers = vec![1, 2, 3];
let list_of_strings: Vec<String> =
list_of_numbers.iter().map(ToString::to_string).collect();
}String::to_string bareng method map buat mengubah angka jadi stringPerhatikan bahwa kita wajib memakai fully qualified syntax (sintaks terkualifikasi
penuh) yang udah kita obrolin di “Advanced Traits” karena
ada banyak fungsi tersedia yang namanya sama-sama to_string.
Di sini, kita memakai fungsi to_string yang didefinisikan di dalam trait
ToString, yang mana udah diimplementasikan secara otomatis sama standard
library buat tipe apa aja yang mengimplementasikan trait Display.
Ingat kembali dari “Nilai Enum (Enum Values)” di Bab 6 kalau nama dari setiap varian enum yang kita definisikan itu juga bertindak sebagai sebuah fungsi inisialisasi (initializer function). Kita bisa memakai fungsi-fungsi inisialisasi ini sebagai function pointers yang mengimplementasikan trait-trait closure, yang berarti kita bisa mengoper fungsi inisialisasi tersebut sebagai argumen buat method-method yang nerima closures, kayak yang kelihatan di Listing 20-31.
fn main() {
enum Status {
Value(u32),
Stop,
}
let list_of_statuses: Vec<Status> = (0u32..20).map(Status::Value).collect();
}map buat ngebikin instance Status dari angka-angkaDi sini, kita ngebikin instance-instance Status::Value memakai setiap nilai u32
di dalam rentang yang mana dipanggil oleh method map dengan jalan memakai
fungsi inisialisasi dari varian Status::Value tersebut. Beberapa orang lebih
suka gaya penulisan kayak gini dan beberapa orang lainnya lebih milih buat pakai
closures. Mereka di-compile jadi hasil kode yang sama kok, jadi pakai aja gaya mana
yang lebih jelas dan enak dibaca buat kita.
Mengembalikan Closures
Closures direpresentasikan memakai traits, yang artinya kita tidak bisa ngembaliin
closures secara langsung. Di sebagian besar kasus di mana kita mungkin pengen
mengembalikan sebuah trait, kita bisa memakai tipe konkret yang emang
mengimplementasikan trait tersebut sebagai nilai kembalian fungsinya. Tapi,
biasanya kita tidak bisa ngelakuin itu buat closures karena mereka tidak punya
tipe konkret yang bisa di-return (dikembalikan); contohnya, kita tidak diizinkan
buat memakai function pointer fn sebagai tipe kembalian kalau closure-nya itu
menangkap (captures) nilai-nilai apa pun dari scope-nya.
Sebaliknya, kita biasanya bakal memakai sintaks impl Trait yang udah kita
pelajarin di Bab 10. Kita bisa ngembaliin tipe fungsi apa aja, dengan memakai
Fn, FnOnce dan FnMut. Contohnya, kode di Listing 20-32 bakal sukses
di-compile dengan baik.
#![allow(unused)]
fn main() {
fn returns_closure() -> impl Fn(i32) -> i32 {
|x| x + 1
}
}impl TraitNamun, kayak yang udah kita sebutin di “Inferensi Tipe dan Anotasi pada Closure” di Bab 13, masing-masing closure itu juga merupakan tipe mereka sendiri yang berbeda-beda. Kalau kita perlu beroperasi sama fungsi-fungsi yang punya signature yang sama tapi implementasi yang berbeda-beda, kita perlu memakai trait object buat mereka. Coba bayangin apa yang terjadi kalau kita nulis kode kayak yang ditunjukin di Listing 20-33.
fn main() {
let handlers = vec![returns_closure(), returns_initialized_closure(123)];
for handler in handlers {
let output = handler(5);
println!("{output}");
}
}
fn returns_closure() -> impl Fn(i32) -> i32 {
|x| x + 1
}
fn returns_initialized_closure(init: i32) -> impl Fn(i32) -> i32 {
move |x| x + init
}Vec<T> berisi closures yang didefinisikan sama fungsi-fungsi yang mengembalikan tipe impl FnDi sini kita punya dua fungsi, returns_closure dan returns_initialized_closure,
yang mana dua-duanya mengembalikan impl Fn(i32) -> i32. Perhatikan kalau
closures yang mereka kembalikan itu berbeda isinya, biarpun mereka
mengimplementasikan tipe yang sama. Kalau kita mencoba men-compile ini, Rust
bakal ngasih tahu kita kalau ini tidak bisa jalan:
$ cargo build
Compiling functions-example v0.1.0 (file:///projects/functions-example)
error[E0308]: mismatched types
--> src/main.rs:2:44
|
2 | let handlers = vec![returns_closure(), returns_initialized_closure(123)];
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ expected opaque type, found a different opaque type
...
9 | fn returns_closure() -> impl Fn(i32) -> i32 {
| ------------------- the expected opaque type
...
13 | fn returns_initialized_closure(init: i32) -> impl Fn(i32) -> i32 {
| ------------------- the found opaque type
|
= note: expected opaque type `impl Fn(i32) -> i32`
found opaque type `impl Fn(i32) -> i32`
= note: distinct uses of `impl Trait` result in different opaque types
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions-example` (bin "functions-example") due to 1 previous error
Pesan error ini ngasih tahu kita kalau kapan pun kita mengembalikan impl Trait,
Rust ngebikin tipe opaque (buram/tidak tembus pandang) yang unik, yaitu sebuah
tipe di mana kita tidak bisa melihat ke dalam detail dari apa yang dibangun sama
Rust buat kita, dan kita juga tidak bisa nebak-nebak tipe apa yang bakal dihasilkan
(generated) sama Rust supaya kita bisa nulisin tipenya sendiri secara manual. Jadi
meskipun fungsi-fungsi ini sama-sama ngembaliin closures yang mengimplementasikan
trait yang sama, yaitu Fn(i32) -> i32, tipe opaque yang dihasilkan oleh Rust
buat masing-masing fungsinya itu tetap berbeda. (Ini mirip dengan gimana cara
Rust memproduksi tipe konkret yang berbeda-beda untuk blok async yang berbeda
bahkan pas mereka punya tipe output yang sama, kayak yang kita lihat di
“Bekerja dengan Jumlah Futures yang Sembarang” di Bab 17.)
Kita udah pernah lihat solusi buat masalah ini beberapa kali sebelumnya: kita
bisa memakai sebuah trait object, kayak di Listing 20-34.
fn main() {
let handlers = vec![returns_closure(), returns_initialized_closure(123)];
for handler in handlers {
let output = handler(5);
println!("{output}");
}
}
fn returns_closure() -> Box<dyn Fn(i32) -> i32> {
Box::new(|x| x + 1)
}
fn returns_initialized_closure(init: i32) -> Box<dyn Fn(i32) -> i32> {
Box::new(move |x| x + init)
}Vec<T> berisi closures yang didefinisikan sama fungsi-fungsi yang mengembalikan Box<dyn Fn> supaya mereka punya tipe yang samaKode ini bakal sukses di-compile dengan mulus. Buat tahu lebih lanjut soal trait objects, silakan mengacu ke bagian “Memakai Trait Objects Buat Mengabstraksi Perilaku Bersama” di Bab 18.
Berikutnya, mari kita lihat tentang macro!
Macros
Macros
Kita udah sering memakai macros (makro) kayak println! di sepanjang buku ini,
tapi kita belum sepenuhnya mengeksplorasi apa itu macro dan gimana cara
kerjanya. Istilah macro mengacu ke sekumpulan fitur di Rust: macros declarative
(deklaratif) yang memakai macro_rules! dan tiga macam macros procedural
(prosedural):
- Macros
#[derive]kustom yang menentukan kode yang bakal ditambahin pakai atributderiveyang dipakai pada structs dan enums - Macros mirip atribut (attribute-like) yang mendefinisikan atribut kustom yang bisa dipakai pada item apa pun
- Macros mirip fungsi (function-like) yang kelihatannya kayak pemanggilan fungsi tapi beroperasi pada tokens yang ditentukan sebagai argumen mereka
Kita bakal ngebahas masing-masing dari ini secara bergantian, tapi pertama- tama, mari kita bahas kenapa kita butuh macros padahal kita udah punya fungsi biasa.
Perbedaan Antara Macros dan Fungsi
Secara fundamental, macros itu adalah sebuah cara buat nulis kode yang
nulisin kode lain, yang mana dikenal dengan istilah metaprogramming (metapemrograman).
Di Lampiran C, kita ngebahas soal atribut derive, yang menghasilkan
(generates) sebuah implementasi dari berbagai traits buat kita. Kita juga udah
memakai macro println! dan vec! di sepanjang buku ini. Semua macros
ini melebar (expand) buat menghasilkan lebih banyak kode ketimbang
kode yang secara manual kita tulis.
Metaprogramming itu sangat berguna buat ngurangin seberapa banyak kode yang harus kita tulis dan pelihara, yang mana juga merupakan salah satu dari peran fungsi biasa. Namun, macros punya beberapa kekuatan tambahan yang tidak dipunyai sama fungsi biasa.
Sebuah signature fungsi wajib mendeklarasikan jumlah dan tipe dari
parameter-parameter yang dipunyai fungsi tersebut. Macros, di sisi lain,
bisa menerima jumlah parameter yang bervariasi (variable number of parameters):
kita bisa memanggil println!("hello") dengan satu argumen atau
println!("hello {}", name) dengan dua argumen. Selain itu, macros itu
dijabarkan (expanded) sebelum compiler menginterpretasi (menafsirkan)
makna dari kode tersebut, jadi sebuah macro bisa, contohnya, mengimplementasikan
sebuah trait pada suatu tipe tertentu. Sebuah fungsi tidak bisa ngelakuin ini,
karena dia dipanggil pas runtime dan sebuah trait wajib diimplementasikan pas
compile time.
Kelemahan dari mengimplementasikan sebuah macro ketimbang sebuah fungsi adalah kalau definisi macro itu lebih kompleks daripada definisi fungsi karena kita lagi nulis kode Rust yang bertugas buat nulis kode Rust. Gara-gara ketidaklangsungan (indirection) ini, definisi macro itu umumnya lebih susah buat dibaca, dipahami, dan dipelihara ketimbang definisi fungsi.
Perbedaan penting lainnya antara macros dan fungsi adalah kita wajib mendefinisikan macros atau membawa mereka ke dalam scope (ruang lingkup) sebelum kita manggil mereka di dalam sebuah file, berlawanan dengan fungsi biasa yang bisa kita definisikan di mana aja dan panggil dari mana aja.
Macros Declarative dengan macro_rules! buat Metaprogramming Umum
Bentuk macros yang paling sering dipakai di Rust adalah declarative macro
(makro deklaratif). Ini kadang-kadang juga disebut sebagai “macros by example”
(makro lewat contoh), “macros macro_rules!”, atau sekadar “macros” doang. Pada
intinya, macros deklaratif membiarkan kita nulis sesuatu yang mirip sama ekspresi
match di Rust. Seperti yang udah dibahas di Bab 6, ekspresi match adalah
struktur kontrol yang mengambil sebuah ekspresi, ngebandingin nilai hasil dari ekspresi
tersebut dengan serangkaian patterns (pola), lalu menjalankan kode yang
berasosiasi sama pattern yang cocok tersebut. Macros juga membandingkan
sebuah nilai terhadap patterns yang diasosiasikan dengan kode tertentu: di situasi
ini, nilainya itu adalah kode sumber (source code) Rust literal yang dioper ke
dalam macro tersebut; lalu patterns tersebut dibandingkan dengan struktur
dari kode sumber tadi; dan kode yang terkait dengan setiap pattern itu, pas dia cocok,
bakal menggantikan kode yang dioper ke dalam macro tersebut. Ini semua terjadi pas
masa kompilasi.
Buat mendefinisikan sebuah macro, kita memakai konstruk macro_rules!.
Mari kita telusuri gimana cara memakai macro_rules! dengan melihat gimana si
macro vec! itu didefinisikan. Bab 8 mencakup gimana kita bisa memakai macro
vec! buat ngebikin sebuah vector baru dengan nilai-nilai tertentu. Misalnya,
macro berikut ini ngebikin sebuah vector baru yang berisi tiga buah integer:
#![allow(unused)]
fn main() {
let v: Vec<u32> = vec![1, 2, 3];
}Kita juga bisa memakai macro vec! buat ngebikin sebuah vector yang berisi dua
integer atau sebuah vector yang berisi lima string slices. Kita tidak bakal bisa
memakai fungsi biasa buat ngelakuin hal yang sama karena kita tidak bakal tahu
jumlah atau tipe nilai-nilainya secara pasti dari awal (up front).
Listing 20-35 nunjukin definisi yang sedikit disederhanakan dari macro vec!.
#[macro_export]
macro_rules! vec {
( $( $x:expr ),* ) => {
{
let mut temp_vec = Vec::new();
$(
temp_vec.push($x);
)*
temp_vec
}
};
}vec!Catatan: Definisi asli dari macro
vec!yang ada di standard library juga mengandung kode buat mengalokasikan (pre-allocate) jumlah memori yang tepat dari awal. Kode tersebut adalah sebuah optimasi (optimization) yang tidak kita sertakan di sini supaya contohnya lebih simpel.
Anotasi #[macro_export] mengindikasikan kalau macro ini seharusnya dibikin
tersedia di mana pun crate di mana macro ini didefinisikan dibawa ke dalam
scope. Tanpa anotasi ini, si macro tersebut tidak bisa dibawa masuk ke dalam
scope.
Terus kita memulai definisi macro-nya dengan macro_rules! dan nama dari macro
yang lagi kita definisikan ini tanpa pake tanda seru. Nama itu, di kasus ini
yakni vec, lalu diikuti dengan kurung kurawal yang menandakan isi (body) dari
definisi macro tersebut.
Struktur yang ada di dalam isi dari vec! ini mirip sekali sama struktur dari
ekspresi match. Di sini kita punya satu arm (lengan) dengan pattern
( $( $x:expr ),* ), lalu diikuti dengan => dan blok kode yang terkait sama
pattern ini. Kalau pattern ini cocok, blok kode yang terkait itu bakal dipancarkan
(emitted). Mengingat bahwa ini adalah satu-satunya pattern yang ada di dalam
macro ini, berarti cuma ada satu cara valid buat mencocokkan nilainya; pattern
lain apa pun bakal nyebabin error. Macros yang lebih kompleks bakal punya lebih dari
satu arm.
Sintaks pattern yang valid di dalam definisi macro itu berbeda dengan sintaks pattern yang udah kita bahas di Bab 19 karena patterns pada macro itu dicocokkan terhadap struktur dari kode Rust ketimbang terhadap nilai. Mari kita telusuri apa arti dari potongan-potongan pattern yang ada di Listing 20-29; buat ngelihat sintaks pattern macro yang seutuhnya, silakan lihat Rust Reference.
Pertama-tama kita memakai sepasang tanda kurung biasa (parentheses) buat ngebungkus
keseluruhan pattern tersebut. Kita memakai tanda dolar ($) buat mendeklarasikan
sebuah variabel di dalam sistem macro tersebut yang bakal menampung kode Rust
yang cocok dengan pattern-nya. Tanda dolar ini ngejelasin (makes it clear) kalau
ini adalah sebuah variabel macro bukannya variabel Rust biasa. Berikutnya ada
sepasang tanda kurung lagi yang menangkap nilai-nilai yang cocok sama pattern
yang ada di dalam tanda kurung tersebut buat dipakai di dalam kode penggantinya.
Di dalam $() ada $x:expr, yang mana bakal cocok sama sembarang ekspresi Rust
dan lalu ngasih nama $x ke ekspresi tersebut.
Koma yang ada di belakang $() mengindikasikan kalau sebuah karakter pemisah (separator)
berupa koma secara literal itu wajib muncul di antara setiap instance kode yang cocok
sama kode yang ada di dalam $(). Tanda bintang * menentukan kalau pattern
tersebut cocok nol atau sekian kali (zero or more) dari apa pun yang ngeduluin
(precedes) tanda * tersebut.
Saat kita memanggil macro ini pakai vec![1, 2, 3];, pattern $x bakal cocok
sebanyak tiga kali dengan tiga ekspresi 1, 2, dan 3.
Sekarang mari kita lihat pada pola (pattern) yang ada di dalam isi blok kode yang
terkait sama arm ini: temp_vec.push() yang ada di dalam $()* bakal dihasilkan
buat setiap bagian yang cocok sama $() di dalam pattern sebelumnya sebanyak
nol atau lebih kali (tergantung dari seberapa banyak pattern itu cocok). Si $x
bakal diganti dengan masing-masing ekspresi yang cocok tadi. Saat kita manggil
macro ini pakai vec![1, 2, 3];, kode yang dihasilkan yang bakal menggantikan
pemanggilan macro ini bakal jadi kayak gini:
{
let mut temp_vec = Vec::new();
temp_vec.push(1);
temp_vec.push(2);
temp_vec.push(3);
temp_vec
}Kita udah mendefinisikan sebuah macro yang bisa menerima jumlah argumen sebanyak apa pun yang bertipe apa pun dan bisa menghasilkan kode buat ngebikin sebuah vector yang berisi elemen-elemen yang udah kita tentukan.
Buat belajar lebih jauh soal gimana cara nulis macros, silakan konsultasi ke dokumentasi online atau sumber referensi lainnya, kayak misalnya “The Little Book of Rust Macros” yang dimulai sama Daniel Keep dan terus dilanjutin sama Lukas Wirth.
Macros Procedural Buat Menghasilkan Kode dari Atribut
Bentuk kedua dari macros adalah procedural macro (makro prosedural), yang mana
bekerjanya lebih mirip kayak sebuah fungsi (dan emang merupakan sebuah tipe prosedur).
Procedural macros nerima beberapa kode sebagai input, lalu beroperasi pada kode
tersebut, dan akhirnya memproduksi (menghasilkan) beberapa kode sebagai output,
bukannya mencocokkan patterns lalu nggantiin kode tersebut dengan kode lain
kayak yang dilakuin sama macros deklaratif. Tiga macam macros prosedural ini adalah
derive kustom, mirip atribut (attribute-like), dan mirip fungsi (function-like),
dan mereka semua bekerja pakai cara yang mirip-mirip.
Pas lagi membikin macros prosedural, definisi-definisi ini wajib berada di dalam
crate mereka sendiri (tersendiri) dengan sebuah tipe crate spesial. Ini terjadi
karena alasan-alasan teknis yang rumit yang mana kita harap bisa kita hilangkan di
masa depan. Di Listing 20-36, kita nunjukin gimana cara mendefinisikan sebuah
macro prosedural, di mana some_attribute itu adalah placeholder buat memakai
salah satu variasi spesifik dari macro tersebut.
use proc_macro;
#[some_attribute]
pub fn some_name(input: TokenStream) -> TokenStream {
}Fungsi yang mendefinisikan sebuah macro prosedural menerima sebuah TokenStream
sebagai input dan memproduksi sebuah TokenStream sebagai output. Tipe
TokenStream ini didefinisikan sama crate proc_macro yang mana emang disertakan
bareng Rust dan merepresentasikan sekumpulan dari tokens. Inilah inti (core) dari
macro tersebut: kode sumber (source code) yang lagi dioperasikan sama si macro itu
ngebentuk input TokenStream tersebut, dan kode yang dihasilkan sama si macro
itu adalah output TokenStream hasilnya. Fungsi ini juga punya atribut yang
nempel ke dirinya yang menentukan jenis macro prosedural apa yang lagi kita bikin.
Kita bisa punya berbagai jenis macros prosedural di dalam satu crate yang sama.
Mari kita ngelihat jenis-jenis dari macros prosedural tersebut. Kita bakal mulai
dengan macro derive kustom dan terus ngejelasin sedikit perbedaan kecil (small
dissimilarities) yang ngebikin bentuk-bentuk lainnya jadi beda.
Gimana Cara Menulis Sebuah Macro derive Kustom
Mari kita bikin sebuah crate bernama hello_macro yang mendefinisikan
sebuah trait bernama HelloMacro dengan satu fungsi associated bernama hello_macro.
Ketimbang harus maksa supaya user kita mengimplementasikan trait HelloMacro
secara manual buat setiap tipe mereka, kita bakal nyediain sebuah macro prosedural
sehingga para pengguna bisa menganotasi tipe mereka dengan #[derive(HelloMacro)]
buat dapetin implementasi default (bawaan) dari fungsi hello_macro ini. Implementasi
default ini bakal mencetak Hello, Macro! My name is TypeName! di mana TypeName
itu adalah nama dari tipe di mana trait ini baru aja didefinisikan. Dengan
kata lain, kita bakal nulis sebuah crate yang memungkinkan programmer lain
buat nulis kode kayak di Listing 20-37 dengan memakai crate kita.
use hello_macro::HelloMacro;
use hello_macro_derive::HelloMacro;
#[derive(HelloMacro)]
struct Pancakes;
fn main() {
Pancakes::hello_macro();
}Kode ini bakal mencetak Hello, Macro! My name is Pancakes! pas kita udah selesai.
Langkah pertamanya adalah membikin library crate baru, kayak gini:
$ cargo new hello_macro --lib
Berikutnya, di Listing 20-38, kita bakal mendefinisikan trait HelloMacro dan
fungsi associated-nya.
pub trait HelloMacro {
fn hello_macro();
}deriveKita udah punya trait dan fungsinya. Pada titik ini, user dari crate kita udah bisa mengimplementasikan trait ini buat dapetin fungsionalitas yang mereka inginkan, kayak di Listing 20-39.
use hello_macro::HelloMacro;
struct Pancakes;
impl HelloMacro for Pancakes {
fn hello_macro() {
println!("Hello, Macro! My name is Pancakes!");
}
}
fn main() {
Pancakes::hello_macro();
}HelloMacroNamun, mereka masih butuh buat nulis blok implementasi ini buat setiap tipe yang
pengen mereka pakai dengan hello_macro; kita mau nyelametin mereka dari keharusan
(having to do) ngelakuin kerjaan ini.
Selain itu, kita belum bisa nyediain fungsi hello_macro dengan implementasi
default yang mana bakal bisa nyetak nama dari tipe di mana trait itu diimplementasikan:
Rust tidak punya kapabilitas reflection (kemampuan buat meneliti tipe-tipe saat jalan),
jadi dia tidak bisa nyari tahu nama dari sebuah tipe pas runtime dateng. Kita
butuh macro buat bisa menghasilkan (generate) kode tersebut saat compile time.
Langkah selanjutnya adalah mendefinisikan macro prosedural tersebut. Saat tulisan ini
dibikin, macros prosedural wajib berada di dalam crate mereka sendiri (terpisah).
Suatu hari nanti, pembatasan ini mungkin bakal diangkat (lifted). Konvensi buat
menata struktur (structuring) crates dan crates macro itu kayak gini: buat sebuah
crate yang namanya foo, crate macro prosedural derive kustomnya itu dikasih nama
foo_derive. Mari kita mulai crate baru bernama hello_macro_derive di dalam
project hello_macro kita:
$ cargo new hello_macro_derive --lib
Dua crates kita ini itu saling berkaitan erat (tightly related), jadi kita ngebikin
crate macro prosedural ini di dalam directory dari crate hello_macro kita. Kalau
kita ngubah definisi trait yang ada di dalam hello_macro, kita juga bakal harus
mengubah implementasi macro prosedural di dalam hello_macro_derive. Kedua crates
ini harus dipublikasikan (published) secara terpisah, dan programmer-programmer yang
memakai crates ini harus menambahkan dua-duanya sebagai dependensi lalu membawa
keduanya masuk ke dalam scope. Sebagai gantinya, kita juga bisa sih bikin supaya
crate hello_macro itu memakai hello_macro_derive sebagai dependensi terus dia yang
mengekspor ulang (re-export) kode macro prosedural tersebut. Namun, cara kita menata
struktur project kita ini membiarkan programmer-programmer buat memakai hello_macro
bahkan kalau mereka sebenernya tidak butuh sama fungsionalitas derive-nya.
Kita perlu mendeklarasikan crate hello_macro_derive ini sebagai sebuah crate
macro prosedural. Kita juga bakal butuh fungsionalitas dari crates syn dan
quote, kayak yang bakal kita lihat sebentar lagi, jadi kita perlu nambahin mereka
sebagai dependensi. Tambahkan yang berikut ini ke dalam file Cargo.toml untuk
hello_macro_derive:
[lib]
proc-macro = true
[dependencies]
syn = "2.0"
quote = "1.0"
Buat mulai mendefinisikan macro prosedural ini, tempatin kode dari Listing 20-40
ke dalam file src/lib.rs kita buat crate hello_macro_derive. Perhatikan bahwa
kode ini belum bakal bisa di-compile sampai kita udah nambahin definisi buat fungsi
impl_hello_macro.
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate.
let ast = syn::parse(input).unwrap();
// Build the trait implementation.
impl_hello_macro(&ast)
}Coba perhatikan kalau kita udah membelah (split) kodenya ke dalam fungsi
hello_macro_derive, yang mana bertanggung jawab buat nge-parse (mengurai/menguraikan)
si TokenStream, dan fungsi impl_hello_macro, yang mana bertanggung jawab
buat mengubah (transforming) struktur pohon sintaksnya (syntax tree): ini
ngebikin penulisan sebuah macro prosedural jadi lebih nyaman (convenient). Kode di dalam
fungsi yang luar (hello_macro_derive di kasus ini) itu bakal sama aja bunyinya buat
hampir sebagian besar dari crates macro prosedural yang pernah kita lihat atau bikin.
Kode yang kita tentuin di dalam isi fungsi dalamnya (impl_hello_macro di kasus ini)
itu bakal berbeda-beda tergantung dari apa tujuan macro prosedural kita itu sebenernya.
Kita udah memperkenalkan tiga crates baru di sini: proc_macro, syn,
dan quote. Crate proc_macro itu emang udah dibawa bareng sama Rust,
jadi kita tidak perlu nambahin dia ke dalam dependensi di Cargo.toml kita. Crate
proc_macro ini adalah API dari compiler yang memungkinkan kita buat membaca dan
memanipulasi kode Rust dari dalam kode kita.
Crate syn itu mem-parse kode Rust yang asalnya dari string menjadi sebuah struktur
data yang mana bisa kita operasikan lebih lanjut. Crate quote kemudian mengubah si
struktur data syn tersebut kembali (turns back) menjadi kode Rust biasa.
Crates ini ngebikin gampang sekali buat mem-parse segala macam kode Rust apa pun yang
mungkin pengen kita tangani (handle): nulis parser yang sempurna (full parser)
buat bahasa pemrograman Rust bukanlah tugas yang gampang lho.
Fungsi hello_macro_derive bakal dipanggil pas ada user library kita yang
mencantumkan #[derive(HelloMacro)] pada sebuah tipe. Hal ini dimungkinkan
karena kita udah ngasih anotasi ke fungsi hello_macro_derive di sini pakai
proc_macro_derive dan nentuin nama HelloMacro, yang mana nama ini emang cocok
sama nama dari trait kita; ini adalah konvensi yang paling banyak diikuti sama macros
prosedural.
Fungsi hello_macro_derive pertama-tama mengkonversi input yang asalnya dari sebuah
TokenStream menjadi sebuah struktur data yang lalu bisa kita interpretasikan
dan kita operasikan lebih lanjut. Di sinilah si syn ikut campur. Fungsi parse
di dalam syn mengambil sebuah TokenStream lalu mengembalikan sebuah struct
DeriveInput yang merepresentasikan kode Rust yang udah selesai di-parse. Listing
20-41 nunjukin bagian-bagian yang relevan dari struct DeriveInput yang kita dapetin
sebagai hasil dari menge-parse string struct Pancakes;.
DeriveInput {
// --snip--
ident: Ident {
ident: "Pancakes",
span: #0 bytes(95..103)
},
data: Struct(
DataStruct {
struct_token: Struct,
fields: Unit,
semi_token: Some(
Semi
)
}
)
}DeriveInput yang kita dapetin pas kita mem-parse kode yang punya atribut macro tersebut di Listing 20-37Bidang (fields) dari struct ini nunjukin kalau kode Rust yang udah kita parse ini
adalah sebuah unit struct dengan ident (identifier/pengidentifikasi, yang artinya
nama) Pancakes. Ada lebih banyak bidang lagi pada struct ini buat
mendeskripsikan segala macam variasi kode Rust; silakan cek dokumentasi syn
untuk DeriveInput buat informasi lebih lengkap.
Bentar lagi kita bakal mendefinisikan fungsi impl_hello_macro, yang mana ini
bakal jadi tempat di mana kita ngebangun kode Rust baru yang pengen kita
masukkan (include) ke dalem programnya. Tapi sebelum kita melakukan itu, perhatikan
kalau output dari macro derive kita ini juga merupakan sebuah TokenStream. Si
TokenStream kembalian (returned) ini bakal ditambahin ke kode yang dibikin sama user
crate kita, jadi pas mereka mengompilasi (compile) crate mereka, mereka bakal
dapetin fungsi tambahan yang udah kita sediain di dalam TokenStream yang udah
dimodifikasi tadi.
Kita mungkin sempat merhatiin kalau kita tadi memanggil unwrap yang mana bakal
ngebikin fungsi hello_macro_derive jadi panic kalau pemanggilan ke fungsi
syn::parse tersebut ternyata gagal (fails) di sini. Sangat diwajibkan buat macro
prosedural kita supaya jadi panic pas ada error karena fungsi-fungsi proc_macro_derive
itu wajib ngembaliin tipe TokenStream ketimbang Result supaya dia bisa patuh (conform)
sama API macro prosedural tersebut. Kita udah menyederhanakan contoh ini dengan
memakai unwrap; kalau di dalem kode produksi sungguhan (production code), kita
harusnya menyediakan pesan error yang jauh lebih spesifik soal apa yang
sebenernya salah dengan memakai panic! atau expect.
Nah, sekarang karena kita udah punya kode buat ngubah kode Rust yang udah dianotasikan
(annotated Rust code) dari sebuah TokenStream menjadi sebuah instance DeriveInput,
mari kita hasilkan kode (generate the code) yang mengimplementasikan trait
HelloMacro pada tipe yang dianotasi tersebut, kayak yang ditunjukin di Listing 20-42.
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate
let ast = syn::parse(input).unwrap();
// Build the trait implementation
impl_hello_macro(&ast)
}
fn impl_hello_macro(ast: &syn::DeriveInput) -> TokenStream {
let name = &ast.ident;
let generated = quote! {
impl HelloMacro for #name {
fn hello_macro() {
println!("Hello, Macro! My name is {}!", stringify!(#name));
}
}
};
generated.into()
}HelloMacro memakai kode Rust yang udah diparseKita mendapatkan sebuah instance dari struct Ident yang mengandung nama (identifier) dari
tipe yang dianotasi tadi memakai ast.ident. Struct yang ada di Listing 20-41 tadi
nunjukin kalau pas kita ngejalanin fungsi impl_hello_macro pada kode yang ada di
Listing 20-37, si ident yang bakal kita dapet ini bakal punya field ident
dengan nilai "Pancakes". Oleh karenanya variabel name di dalam Listing 20-42
bakal berisi instance struct Ident yang mana, pas dicetak, dia bakal ngasih
string "Pancakes", nama dari struct di dalam Listing 20-37.
Macro quote! membiarkan kita mendefinisikan kode Rust yang mau kita kembalikan (return).
Compiler mengharapkan sesuatu yang agak beda dengan hasil eksekusi langsung dari
macro quote!, jadi kita perlu buat ngubahnya (convert it) menjadi sebuah
TokenStream. Kita melakukan hal ini dengan cara memanggil method into, yang mana
memakan (consumes) si representasi menengah (intermediate representation) ini lalu
mengembalikan sebuah nilai dengan tipe TokenStream yang diwajibkan tersebut.
Macro quote! ini juga nyediain mekanisme templat (templating) yang keren sekali lho: kita
bisa memasukkan #name, dan quote! bakal nggantiin itu dengan nilai yang ada di
dalam variabel name. Kita bahkan bisa ngelakuin pengulangan yang mirip sama cara
kerja macros yang biasa. Silakan cek dokumentasi crate quote
buat perkenalan yang komprehensif (thorough).
Kita pengen macro prosedural kita ini buat menghasilkan sebuah implementasi dari
trait HelloMacro kita buat tipe yang dianotasi sama si user, yang mana nama tipenya
itu bisa kita dapetin dengan memakai #name. Implementasi trait-nya ini punya
satu fungsi doang yaitu hello_macro, di mana isinya (body) mengandung
fungsionalitas yang pengen kita berikan: yaitu mencetak tulisan Hello, Macro! My name is lalu diikuti dengan nama dari tipe yang dianotasi tersebut.
Macro stringify! yang dipakai di sini emang udah tertanam (built into) di dalam Rust.
Dia mengambil (takes) sebuah ekspresi Rust, kayak misalnya 1 + 2, lalu pada
saat compile time dia bakal ngerubah ekspresi tersebut jadi string literal (string harfiah),
kayak misalnya "1 + 2". Ini beda sama format! atau println!, dua macro ini kan
mengevaluasi ekspresinya dan baru kemudian ngubah hasilnya jadi sebuah String.
Ada kemungkinan input #name ini bisa jadi adalah sebuah ekspresi yang mana harus
dicetak apa adanya secara harfiah (literally), jadi makanya kita memakai stringify!.
Memakai stringify! juga ngirit alokasi (saves an allocation) karena dia ngubah
#name jadi string literal saat compile time (saat kompilasi).
Pada titik ini, jalanin cargo build seharusnya udah bisa kelar tanpa masalah di
dalam hello_macro sekaligus hello_macro_derive. Mari kita pasangkan (hook up)
crates ini dengan kode yang ada di dalam Listing 20-37 tadi buat ngelihat gimana
macro prosedural kita ini beraksi! Bikin sebuah project binary baru
di dalam directory projects kita memakai cargo new pancakes. Kita perlu menambahkan
hello_macro dan hello_macro_derive sebagai dependensi (dependencies) di
dalam Cargo.toml milik crate pancakes ini. Kalau seandainya kita mempublikasikan
versi dari hello_macro dan hello_macro_derive punya kita ke
crates.io, mereka bakal jadi kayak dependensi biasa;
kalau belum dipublikasikan, kita bisa menspesifikasikan mereka sebagai dependensi bertipe path
(jalur ke folder) kayak gini:
[dependencies]
hello_macro = { path = "../hello_macro" }
hello_macro_derive = { path = "../hello_macro/hello_macro_derive" }
Masukin kode dari Listing 20-37 tadi ke dalam file src/main.rs, terus coba jalanin cargo run:
dia seharusnya mencetak Hello, Macro! My name is Pancakes! Implementasi dari
trait HelloMacro dari macro prosedural tersebut udah dimasukkan (included)
tanpa crate pancakes ini harus mengimplementasikannya sendiri; si atribut
#[derive(HelloMacro)] itulah yang udah nambahin implementasi trait tersebut secara
otomatis.
Selanjutnya, mari kita telusuri di mana letak perbedaan dari jenis-jenis macro
prosedural lain kalau dibandingin dengan macros derive kustom.
Macros Mirip Atribut (Attribute-Like Macros)
Macros yang mirip atribut itu serupa sama macros derive kustom, tapi
ketimbang menghasilkan (generating) kode buat atribut derive, macros ini ngebolehin
kita buat membikin atribut baru (new attributes). Mereka juga lebih fleksibel: derive
itu kan cuma bisa kerja buat structs dan enums doang; sedangkan atribut itu bisa aja
diterapkan ke item-item lain, kayak fungsi misalnya. Berikut ini adalah sebuah
contoh penggunaan macro yang mirip atribut. Katakanlah kita punya sebuah atribut
bernama route yang mana nganotasi fungsi-fungsi pas lagi makek framework aplikasi
web (web application framework):
#[route(GET, "/")]
fn index() {Atribut #[route] ini idealnya bakal didefinisikan sama framework tersebut sebagai
sebuah macro prosedural. Signature dari fungsi pendefinisi macro-nya (macro
definition function) mungkin bakal kelihatan kayak gini:
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {Di sini, kita punya dua parameter bertipe TokenStream. Yang pertama itu adalah
buat menampung konten dari atributnya: yaitu di bagian GET, "/". Terus yang
kedua itu adalah buat isinya (body) si item di mana atribut itu ditempelkan (attached
to): di contoh kasus ini, buat si fn index() {} beserta sisa isi dari fungsi
tersebut.
Selain perbedaan tadi, macros mirip atribut ini bekerja dengan cara yang sama persis
dengan macros derive kustom: kita membikin sebuah crate dengan tipe crate proc-macro
lalu kita mengimplementasikan fungsi yang tugasnya buat ngehasilin kode (generates the code)
yang pengen kita bikin!
Macros Mirip Fungsi (Function-Like Macros)
Macros mirip fungsi itu mendefinisikan macros yang kelihatannya kayak pemanggilan fungsi.
Sama kayak macros macro_rules!, macros ini itu lebih luwes (fleksibel) daripada
fungsi biasa; misalnya, mereka bisa nerima jumlah argumen yang bervariasi
(unknown number of arguments). Namun, macros macro_rules! itu cuma bisa didefinisikan
memakai sintaks yang mirip match (match-like syntax) yang udah kita obrolin di
“Macros Declarative dengan macro_rules! buat Metaprogramming Umum” tadi
sebelumnya. Macros yang mirip fungsi ini mengambil satu parameter TokenStream dan
kemudian di definisinya dia memanipulasi TokenStream tersebut memakai kode
Rust sama persis kayak apa yang dilakuin sama kedua tipe macros prosedural
sebelumnya. Sebuah contoh dari macro mirip fungsi adalah macro sql! yang mana mungkin
bakal dipanggil kayak gini:
let sql = sql!(SELECT * FROM posts WHERE id=1);Macro ini bakal mem-parse pernyataan (statement) SQL yang ada di dalamnya dan ngecek
apakah secara sintaks itu (syntactically) benar atau tidak, yang mana itu merupakan pemrosesan
yang jauh lebih ribet (complex processing) ketimbang apa yang sanggup dilakukan
sama macro tipe macro_rules!. Definisi macro sql! ini kelihatannya bakal kayak gini:
#[proc_macro]
pub fn sql(input: TokenStream) -> TokenStream {Definisi ini mirip sekali kan sama signature dari macro derive kustom tadi: kita
menerima tokens yang ada di dalam tanda kurung tersebut (parentheses) dan
terus kita ngembaliin (return) kode yang emang pengen kita hasilin (generate).
Ringkasan
Fiuh! (Whew!) Nah sekarang kita punya segelintir fitur Rust baru di sabuk perkakas (toolbox) kita yang mana kemungkinan besar kita tidak bakal sering memakainya, tapi seenggaknya kita bakal tahu kalau mereka itu tersedia di situasi-situasi tertentu yang amat spesifik. Kita udah memperkenalkan beberapa topik yang kompleks (complex topics) sehingga saat kita kebetulan menjumpainya di dalam saran-saran pesan error (error message suggestions) atau di dalam kode orang lain, kita bakal sanggup buat mengenali berbagai macam konsep dan sintaks ini. Gunakan bab ini sebagai sebuah pedoman referensi (reference guide) buat ngebimbing kita nemuin solusinya.
Berikutnya, kita bakal mempraktikkan (put into practice) segala macam hal yang udah kita bicarain di sepanjang buku ini dengan cara mengerjakan satu project lagi!
Project Akhir: Membikin Sebuah Multithreaded Web Server
Udah jadi perjalanan panjang ya, tapi akhirnya kita nyampe juga di akhir buku ini. Di bab ini, kita bakal ngebikin satu project lagi bareng-bareng buat mendemonstrasikan beberapa konsep yang udah kita bahas di bab-bab akhir, sekaligus juga ngeringkas (recap) pelajaran-pelajaran yang ada sebelumnya.
Buat project akhir kita, kita bakal membikin sebuah web server yang ngomong “hello” dan kelihatannya kayak Gambar 21-1 di web browser.
Berikut ini adalah rencana kita buat ngebangun web server-nya:
- Belajar sedikit soal TCP dan HTTP.
- Mendengarkan (listen) koneksi-koneksi TCP di dalam sebuah socket.
- Mem-parse sejumlah kecil requests (permintaan) HTTP.
- Membikin sebuah response (respons/balasan) HTTP yang layak.
- Ningkatin throughput (kemampuan ngelayanin banyak permintaan) dari server kita dengan sebuah thread pool.
Gambar 21-1: Project akhir yang kita buat bareng-bareng
Sebelum kita mulai, kita harus nyebutin dua hal detail. Pertama, metode yang bakal kita pakai ini bukanlah cara terbaik buat ngebangun sebuah web server pakai Rust. Anggota komunitas udah memublikasikan beberapa crates yang siap buat dipakai di production (production-ready) yang tersedia di crates.io yang mana menyediakan implementasi web server dan thread pool yang jauh lebih lengkap ketimbang apa yang bakal kita bikin ini. Namun, niat kita di bab ini adalah ngebantu kita buat belajar, bukannya ngambil jalan yang gampang. Karena Rust itu adalah bahasa pemrograman sistem (systems programming language), kita bisa milih tingkat abstraksi yang pengen kita kerjain dan kita bisa turun ke tingkat (level) yang lebih rendah ketimbang apa yang mungkin atau praktis buat dilakukan di bahasa pemrograman lainnya.
Kedua, kita tidak bakal memakai async dan await di sini. Ngebangun sebuah thread pool aja itu udah tantangan yang lumayan gede sendirian, jadi kita tidak perlu nambah-nambahin keruwetan dengan ngebangun sebuah runtime async sekalian! Walaupun begitu, kita bakal ngasih catetan gimana sih async dan await mungkin bisa diterapin ke beberapa permasalahan yang bakal kita temui di bab ini. Pada akhirnya, seperti yang udah kita sebutin balik di Bab 17, banyak runtimes async yang juga memakai thread pools buat mengelola kerjaan mereka kok.
Oleh karena itu, kita bakal menulis sebuah HTTP server dasar dan thread pool secara manual supaya kita bisa belajar ide-ide umum dan teknik-teknik di balik crates yang mana mungkin bakal kita pakai di masa depan.
Membikin Web Server yang Single-Threaded
Membikin Web Server yang Single-Threaded
Kita bakal mulai dengan ngebikin supaya sebuah web server single-threaded (satu utas/thread) bisa jalan. Sebelum kita mulai, mari kita lihat ikhtisar (overview) kilat soal protokol-protokol yang dilibatin di dalam pembuatan web servers. Detail-detail dari protokol ini emang ada di luar dari cakupan buku ini, tapi ikhtisar singkat ini bakal ngasih kita informasi yang kita butuhkan.
Dua protokol utama yang dilibatin di dalam web servers adalah Hypertext Transfer Protocol (HTTP) dan Transmission Control Protocol (TCP). Kedua protokol ini adalah protokol request-response (minta dan balas), yang artinya sebuah client (klien) ngirim requests dan sebuah server ngedengerin (listens to) requests tersebut lalu ngasih sebuah response (respons/balasan) ke si client tadi. Konten (isi) dari requests dan responses ini didefinisikan sama protokol-protokol tersebut.
TCP itu adalah protokol tingkat lebih rendah (lower-level protocol) yang mendeskripsikan detail-detail soal gimana informasi itu nyampe dari satu server ke server lainnya tapi dia tidak menentukan secara spesifik apa sebenarnya bentuk informasi itu. HTTP ngebangun di atas (builds on top of) TCP dengan cara mendefinisikan konten dari requests dan responses tersebut. Secara teknis itu mungkin aja buat memakai HTTP pakai protokol selain TCP, tapi di mayoritas kasus yang ada, HTTP ngirim datanya lewat TCP. Kita bakal kerja dengan barisan bytes mentah (raw bytes) dari requests dan responses TCP dan HTTP ini.
Mendengarkan Koneksi TCP
Web server kita perlu mendengarkan (listen to) sebuah koneksi TCP, jadi
itulah bagian pertama yang bakal kita kerjain. Standard library menawarkan
sebuah modul std::net yang membiarkan kita buat ngelakuin ini. Mari kita
bikin project baru pakai cara yang biasa:
$ cargo new hello
Created binary (application) `hello` project
$ cd hello
Sekarang masukin kode yang ada di Listing 21-1 ke dalam src/main.rs buat
memulai. Kode ini bakal dengerin di alamat lokal 127.0.0.1:7878 nyari streams
(aliran data) TCP yang lagi mau masuk (incoming). Pas dia dapat sebuah stream
yang masuk, dia bakal mencetak Connection established!.
use std::net::TcpListener;
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
println!("Connection established!");
}
}Memakai TcpListener, kita bisa ngedengerin nyari koneksi-koneksi TCP di
alamat 127.0.0.1:7878. Di alamat tersebut, bagian sebelum titik dua itu
adalah alamat IP yang merepresentasikan komputer kita (ini sama aja di setiap
komputer dan tidak merepresentasikan spesifik komputernya si penulis ya),
dan 7878 itu adalah port-nya. Kita udah milih port ini karena dua
alasan: HTTP itu umumnya tidak diterima di port ini, jadi server kita ini
punya kemungkinan kecil buat berkonflik sama web server lain yang mungkin
lagi jalan di mesin komputer kita, dan 7878 itu adalah kata rust yang diketik
di telepon jadul.
Fungsi bind (ikat) di dalam skenario ini bekerja kayak fungsi new di mana
dia bakal mengembalikan (return) sebuah instance TcpListener yang baru. Fungsi
ini dikasih nama bind karena, di dunia jaringan komputer (networking), nyambung
ke sebuah port buat mulai mendengarkan ke sana itu dikenal dengan istilah
“binding to a port” (ngikat ke sebuah port).
Fungsi bind ini mengembalikan sebuah Result<T, E>, yang mana mengindikasikan
kalau proses binding ini mungkin aja gagal (fail). Misalnya, kalau kita
ngejalanin dua instance dari program kita sehingga ada dua program yang dengerin
di port yang sama persis. Karena kita ini lagi nulis sebuah server super dasar
(basic) cuma buat tujuan pembelajaran aja, kita tidak bakal ambil pusing buat
menangani (handling) error-error semacam ini; sebaliknya, kita bakal memakai
unwrap buat ngehentiin programnya kalau error-error ini emang kejadian.
Method incoming pada TcpListener mengembalikan sebuah iterator yang ngasih
kita serangkaian streams (lebih spesifiknya, streams dari tipe TcpStream).
Sebuah stream tunggal itu merepresentasikan sebuah koneksi terbuka
(open connection) antara si client sama si server. Sebuah connection
(koneksi) itu adalah nama buat proses pemanggilan request dan response secara
utuh di mana si client nyambung ke server-nya, si server ngehasilin sebuah
response, lalu si server menutup koneksi tersebut. Makanya, kita bakal
membaca (read) dari TcpStream ini buat tahu apa yang dikirim sama si
client dan lalu menulis (write) response kita ke stream tersebut buat ngirim
datanya kembali ke si client. Secara umum, loop (perulangan) for ini bakal
memproses setiap koneksi secara bergantian dan menghasilkan serangkaian streams
buat kita tanganin.
Buat sekarang, cara penanganan kita terhadap stream ini adalah dengan memanggil
unwrap buat menghentikan (terminate) program kita kalau ternyata stream
tersebut punya error apa pun; kalau tidak ada error sama sekali, programnya bakal
mencetak sebuah pesan. Kita bakal nambahin fungsionalitas yang lebih buat kasus di
mana program sukses (success case) di listing berikutnya. Alasan kenapa kita mungkin
nerima error dari method incoming pas seorang client nyambung ke server adalah
karena kita itu sebenarnya bukan beriterasi melewati koneksi-koneksi (connections).
Sebaliknya, kita itu lagi beriterasi ngelewatin percobaan-percobaan koneksi (connection
attempts). Koneksinya bisa aja tidak sukses karena banyak alasan, yang mana kebanyakan
dari alasan itu spesifik sama sistem operasi (operating system specific) masing-masing.
Misalnya, banyak sistem operasi yang punya batas seberapa banyak jumlah koneksi
terbuka simultan (berbarengan) yang bisa mereka dukung; percobaan koneksi baru yang
ngelebihi jumlah tersebut bakal ngehasilin error sampai ada beberapa koneksi yang
udah kebuka tadi itu pada ditutupin dulu.
Mari kita cobain buat ngejalanin kode ini! Panggil cargo run di terminal dan lalu
buka (load) 127.0.0.1:7878 di sebuah web browser. Web browser-nya seharusnya
nampilin pesan error kayak “Connection reset” karena emang si server-nya saat ini
belum ngirim balik data apa pun. Tapi pas kita ngelihat ke terminal kita, kita
harusnya bisa ngelihat beberapa pesan yang tadi dicetak pas si browser ini nyambung
ke servernya!
Running `target/debug/hello`
Connection established!
Connection established!
Connection established!
Kadang-kadang kita bakal ngelihat banyak pesan yang dicetak cuma buat satu request dari browser; alasannya mungkin adalah karena si browser itu lagi ngebikin request buat halaman utamanya sekaligus ngebikin request juga buat resources (sumber daya) lainnya, kayak misalnya icon favicon.ico yang suka muncul di tab browser itu.
Bisa juga karena si browser ini lagi mencoba buat nyambung ke server berkali-kali
karena si server tidak ngasih respons data apa-apa. Saat stream keluar dari
scope dan di-drop (dibuang) di akhir perulangannya, koneksinya secara otomatis
ditutup (closed) sebagai bagian dari implementasi dari method drop tersebut. Browser
kadang-kadang nanganin koneksi yang ditutup ini dengan cara mencoba ulang (retrying),
karena ya mungkin masalahnya itu cuma sementara.
Browser juga kadang-kadang ngebuka koneksi yang banyak ke sebuah server tanpa ngirim permintaan apa-apa, jadi kalau nanti mereka memang ngirim request, request-nya itu bisa kejadian lebih cepet. Pas ini kejadian, server kita bakal bisa ngelihat koneksi tersebut, terlepas dari apakah ada request apa enggak yang dikirim liwat koneksi itu. Versi-versi dari browser berbasis Chrome misalnya banyak yang ngelakuin ini; kita bisa menonaktifkan optimasi ini dengan cara memakai mode private browsing (samaran) atau dengan memakai web browser yang beda.
Faktor yang penting adalah kita udah berhasil dapetin sebuah pegangan (handle) ke sebuah koneksi TCP!
Inget ya buat ngestop (stop) programnya dengan cara neken ctrl-C
pas kita udah selesai ngejalanin suatu versi kode tertentu. Terus nyalain ulang programnya
dengan cara manggil perintah cargo run setiap kali habis ngebikin rangkaian perubahan
kode (code changes) buat mastiin kalau kita emang ngejalanin kodenya yang paling baru.
Membaca Request (Permintaan)
Mari kita implementasikan fungsionalitas buat membaca request yang asalnya dari browser!
Buat misahin urusan (concerns) dari yang awalnya dapet koneksi terlebih dahulu lalu setelah itu
baru ngambil beberapa tindakan tertentu sama koneksi tersebut, kita bakal bikin sebuah
fungsi baru yang khusus buat memproses koneksi (processing connections). Di dalam fungsi
handle_connection yang baru ini, kita bakal membaca data yang asalnya dari TCP stream
tersebut dan lalu mencetaknya supaya kita bisa ngelihat data apa yang lagi dikirim
sama si browser. Ubah kodenya supaya kelihatan kayak yang ada di Listing 21-2.
use std::{
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
println!("Request: {http_request:#?}");
}TcpStream dan mencetak data tersebutKita ngebawa (bring) std::io::prelude dan std::io::BufReader ke dalam scope
buat dapetin akses ke trait-trait dan tipe-tipe yang membiarkan kita buat membaca
dari dan nulis ke stream tersebut. Di dalam loop for yang ada di fungsi
main, ketimbang kita sekadar nyetak pesan yang bilang kalau kita udah dapat koneksi,
sekarang kita memanggil fungsi handle_connection yang baru lalu mengoper
stream tersebut ke dalamnya.
Di dalam fungsi handle_connection, kita ngebikin sebuah instance BufReader
yang membungkus referensi ke si stream tersebut. BufReader ini nambahin fitur
buffering (penyangga) dengan cara mengatur (managing) pemanggilan-pemanggilan ke
method-method dari trait std::io::Read secara otomatis buat kita.
Kita ngebikin sebuah variabel bernama http_request buat ngumpulin (collect) baris-baris
dari request yang dikirim sama si browser ke server kita. Kita mengindikasikan kalau kita
mau ngumpulin baris-baris tersebut ke dalam sebuah vector dengan cara nambahin anotasi tipe
Vec<_>.
BufReader mengimplementasikan trait std::io::BufRead, yang mana menyediakan method
lines. Method lines ini mengembalikan sebuah iterator dari tipe
Result<String, std::io::Error> dengan cara ngebelah-belah (splitting) aliran datanya
(stream of data) setiap kali dia ngelihat sebuah byte newline (baris baru). Buat
bisa dapat tiap String-nya, kita memakai map dan unwrap pada masing-masing
Result. Tipe Result ini mungkin aja berisi sebuah error kalau datanya ternyata
bukan UTF-8 yang valid atau kalau sekiranya ada masalah pas membaca dari stream tersebut.
Sekali lagi, di program level production kita seharusnya nanganin error-error kayak
gini dengan jauh lebih cakep (gracefully), tapi kita lebih milih buat ngestop aja
programnya di kasus error ini demi menyederhanakan contoh.
Si browser nandain akhir (end) dari sebuah request HTTP dengan cara ngirimin dua karakter baris baru (newline) secara berurutan (in a row), jadi supaya kita bisa dapet satu request dari si stream, kita ngambil barisnya terus-terusan sampai kita dapet baris yang mana itu adalah string yang kosong. Setelah kita ngumpulin semua barisnya ke dalam vector, kita nyetak mereka pakai pretty debug formatting (format debug cantik yang gampang dibaca) supaya kita bisa lihat sendiri instruksi-instruksi apa aja yang lagi dikirim sama si web browser ke server kita.
Mari kita cobain kode ini! Jalanin programnya dan coba lakuin request (ngunjungin alamat) pakai web browser lagi. Perhatikan kalau kita bakal tetep dapet halaman error di web browsernya ya, tapi sekarang output dari program kita yang ada di dalam terminal bakal kelihatan kira-kira kayak gini:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished dev [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/hello`
Request: [
"GET / HTTP/1.1",
"Host: 127.0.0.1:7878",
"User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:99.0) Gecko/20100101 Firefox/99.0",
"Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language: en-US,en;q=0.5",
"Accept-Encoding: gzip, deflate, br",
"DNT: 1",
"Connection: keep-alive",
"Upgrade-Insecure-Requests: 1",
"Sec-Fetch-Dest: document",
"Sec-Fetch-Mode: navigate",
"Sec-Fetch-Site: none",
"Sec-Fetch-User: ?1",
"Cache-Control: max-age=0",
]
Tergantung dari browser apa yang kita pake, kita mungkin dapat output yang agak
sedikit beda. Sekarang setelah kita udah nyetak isi dari request datanya, kita
bisa paham kan alasan kenapa kita dapat koneksi berkali-kali dari satu request web
browser kalau kita ngelihat path (jalur) yang ada setelah kata GET di baris paling
pertama dari request tersebut. Kalau koneksi-koneksi yang berulang (repeated connections)
itu semuanya lagi nge-request /, kita jadi tahu kalau browser-nya itu lagi nyoba buat ngambil
(fetch) / berkali-kali karena dia tidak dapat respons apa-apa dari program kita.
Mari kita bedah dan perinci (break down) data request ini supaya kita benar-benar ngerti apa yang lagi diminta (asking of) sama si browser dari program kita ini.
Ngelihat Lebih Dekat pada Request HTTP
HTTP itu adalah protokol yang berbasis teks (text-based protocol), dan sebuah request (permintaan) itu ngebentuk format kayak gini:
Method Request-URI HTTP-Version CRLF
headers CRLF
message-body
Baris yang paling pertama itu disebut dengan request line (baris permintaan) yang
menampung informasi tentang apa yang lagi di-request sama si client. Bagian pertama
dari si request line ini mengindikasikan method (metode) apa yang lagi dipakai, kayak
misalnya GET atau POST, yang mana mendeskripsikan gimana caranya si client ini
melakukan request tersebut. Client kita (yakni si web browser tadi) itu memakai sebuah request GET, yang
berarti dia itu lagi minta dikasihin suatu informasi.
Bagian yang selanjutnya di request line tersebut adalah /, yang mana mengindikasikan uniform resource identifier (URI) yang lagi di-request sama client tersebut: sebuah URI itu tuh hampir sekali, tapi tidak sepenuhnya sama persis, dengan sebuah uniform resource locator (URL). Perbedaan antara URI dan URL ini tidaklah penting buat tujuan pembelajaran kita di bab ini, tapi spesifikasi HTTP (HTTP spec) memakai istilah URI, jadi kita bisa dalam hati aja men-substitusikan (menggantikan) URL jadi URI di sini.
Bagian terakhirnya adalah versi HTTP yang lagi dipakai sama si client, dan kemudian si
request line tersebut diakhiri pakai urutan CRLF (CRLF sequence). (CRLF singkatan dari
carriage return dan line feed, yang mana ini adalah istilah yang asalnya dari jaman
mesin tik lho!) Urutan CRLF ini juga bisa ditulis sebagai \r\n, di mana \r itu adalah
si carriage return dan \n itu adalah si line feed (baris baru). Urutan CRLF ini
memisahkan bagian request line dari sisa (rest) data request yang lainnya.
Perhatikan kalau pas CRLF ini dicetak, kita ngelihatnya kayak dimulainya baris baru kan ketimbang
tulisan \r\n.
Ngelihat ke data request line yang kita dapet dari hasil ngejalanin program kita sejauh
ini, kita ngelihat kalau GET itu adalah method-nya, / itu adalah request URI-nya,
dan HTTP/1.1 itu adalah versinya.
Setelah baris pertama (request line) tadi, baris-baris tersisa yang diawali dengan kata
Host: dan seterusnya itu semuanya adalah bagian headers. Requests tipe GET itu
sama sekali tidak punya body (badan/isi pesan).
Coba deh bikin sebuah request (permintaan) dari browser yang beda atau coba minta sebuah alamat yang berbeda, kayak misalnya 127.0.0.1:7878/test, dan perhatikan aja gimana isi dari data request-nya itu berubah.
Nah, sekarang karena kita udah paham apa yang sebenarnya lagi diminta sama si browser, mari kita coba buat ngirim balik beberapa data!
Nulis Sebuah Response (Respons)
Kita bakal mengimplementasikan cara mengirim data sebagai sebuah response (respons/balasan) terhadap request yang dibikin client (client request). Responses itu punya bentuk format kayak gini:
HTTP-Version Status-Code Reason-Phrase CRLF
headers CRLF
message-body
Baris pertama itu disebut status line (baris status) yang mengandung informasi versi HTTP yang dipakai di dalam response ini, sebuah kode status berupa angka (numeric status code) yang nge-ringkas (summarizes) apa hasil akhir dari request-nya, dan juga reason phrase (frasa alasan) yang menyediakan deskripsi teks dari kode status tersebut. Setelah urutan CRLF pertama adalah headers (kalau ada), dan diikuti oleh satu urutan CRLF lagi, dan barulah kemudian body (isi badan) dari si response tersebut.
Berikut ini adalah sebuah contoh response yang memakai versi HTTP 1.1, punya kode
status 200, beserta reason phrase OK, tidak punya headers, dan tidak punya
body:
HTTP/1.1 200 OK\r\n\r\n
Kode status 200 itu adalah respons standar buat bilang sukses (success response).
Teks barusan adalah sebuah response HTTP sukses yang ukurannya sekecil mungkin.
Mari kita tulis ini ke dalam stream (aliran data) kita sebagai response
ke request yang sukses! Dari dalam fungsi handle_connection tadi, silakan
hapus kode println! yang fungsinya buat nyetak data request tadi dan
terus ganti pakai kode yang ada di Listing 21-3.
use std::{
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
let response = "HTTP/1.1 200 OK\r\n\r\n";
stream.write_all(response.as_bytes()).unwrap();
}Baris baru yang pertama mendefinisikan variabel response yang bakal menyimpan
data pesan sukses kita. Terus kita panggil method as_bytes pada variabel
response kita ini buat mengkonversi data string tadi jadi kumpulan bytes.
Method write_all pada variabel stream itu menerima nilai tipe &[u8] (array
slice of bytes) dan dia bakal ngirim bytes tersebut secara langsung nyusurin
(down) koneksi tersebut. Karena operasi write_all ini berpotensi gagal, kita
memakai unwrap pada segala result error kayak sebelumnya. Sekali lagi ya,
di aplikasi yang rill (real application) kita seharusnya nambahin error
handling (penanganan error) di sini.
Dengan adanya perubahan-perubahan ini, mari kita jalanin kode kita lalu kita bikin sebuah request lewat browser. Kita udah tidak lagi mencetak data apa pun ke terminal ya, jadi kita tidak bakal ngelihat output apa-apa selain output dari Cargo. Pas kita memuat (load) alamat 127.0.0.1:7878 di sebuah web browser, kita seharusnya ngedapetin halaman putih (blank page) ketimbang halaman error. Kita baru aja melakukan hardcode (kode manual) buat menerima request HTTP lalu mengirimkan sebuah response secara utuh!
Mengembalikan HTML yang Asli (Real HTML)
Mari kita implementasikan fungsionalitas buat ngembaliin lebih dari sekadar halaman kosong (blank page). Silakan bikin sebuah file baru bernama hello.html di directory utama (root) dari project kita, inget ya bukan di dalem folder src. Kita bisa naruh (input) kode HTML apa aja yang kita mau kok; Listing 21-4 nunjukin salah satu kemungkinan isinya.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Hello!</h1>
<p>Hi from Rust</p>
</body>
</html>
Ini adalah sebuah dokumen HTML5 yang sangat minimal yang cuma ada heading (judul)
dan sedikit teks doang. Buat ngembaliin kode ini dari server saat ada request yang
diterima, kita bakal memodifikasi handle_connection seperti yang ditunjukin
di Listing 21-5 supaya dia ngebaca file HTML tersebut, menambahkannya ke dalam
response kita sebagai isi dari body, lalu mengirimkannya.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
// --snip--
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Kita udah menambahkan fs ke dalam statement use buat membawa filesystem
module (modul file sistem) kepunyaan standard library masuk ke dalam scope.
Kode buat membaca isi dari sebuah file ke dalam sebuah string seharusnya
udah kelihatan familier; kita sempat memakainya pas kita lagi membaca isi konten dari
sebuah file buat project I/O kita balik pas di Listing 12-4.
Selanjutnya, kita memakai format! buat menambahkan konten file tersebut
sebagai body dari response sukses kita tadi. Supaya pasti kalau ini
adalah response HTTP yang benar-benar valid, kita juga menambahkan header Content-Length
yang mana diatur isinya supaya ngepas sama ukuran (size) dari body dari
response kita, di kasus ini berarti ukurannya sama dengan ukuran file hello.html.
Coba jalanin kode ini pakai cargo run terus muat (load) 127.0.0.1:7878
di browser kita; kita harusnya bisa ngelihat HTML kita dimuat (rendered)!
Saat ini, kita emang lagi mengabaikan data request yang ada di http_request
dan kita cuma tanpa syarat (unconditionally) mengirimkan kembali isi (contents)
dari file HTML tersebut. Itu artinya kalau kita mencoba nge-request halaman
127.0.0.1:7878/something-else (apa-aja-lainnya) di browser kita, kita
bakal tetep dapet balasan response HTML yang ini-ini juga. Saat ini, server
kita ini sifatnya sangat terbatas (very limited) dan masih belum berbuat apa yang
mayoritas web server benar-benar lakuin. Kita mau mengkustomisasi responses kita
supaya bergantung pada si request tersebut lalu cuma mengirimkan balik file HTML
itu untuk request / yang formasinya bener (well-formed request).
Memvalidasi Request dan Merespons Secara Selektif
Sekarang ini, web server kita ini bakal selalu nge-return (ngembaliin) file HTML
kita ini tidak peduli apa pun yang diminta sama client-nya. Mari kita tambahin
fungsionalitas buat mengecek apakah browser ini benar-benar lagi nge-request rute /
sebelum nge-return si file HTML, dan terus dia bakal mengembalikan pesan error
kalau browser tersebut mencoba minta apa pun yang lainnya. Buat ngelakuin ini,
kita perlu memodifikasi fungsi handle_connection, kayak yang ditunjukin
di Listing 21-6. Kode yang baru ini bakal mengecek konten dari request yang
baru diterima tersebut dan membandingkannya (against) terhadap rupa dari
request GET buat path (rute) / yang kita ketahui (know), lalu nambahin
blok if dan else buat memperlakukan (treat) requests itu dengan cara
yang berbeda-beda.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
// --snip--
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
if request_line == "GET / HTTP/1.1" {
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
} else {
// some other request
}
}Kita emang cuma bakal ngelihat baris pertama (first line) doang dari request HTTP-nya,
jadi ketimbang baca keseluruhan request-nya dan dimasukin ke dalam sebuah vector,
kita cuma manggil method next buat dapat item paling pertama (first item) dari sang iterator.
Method unwrap yang pertama ngurusin nilai Option-nya dan langsung ngestop program
kalau si iterator tidak punya item apa-apa. Terus unwrap yang kedua menangani
nilai Result-nya yang mana efeknya persis sama kayak unwrap yang sempat
ada di dalam method map pas di Listing 21-2.
Berikutnya, kita ngecek nilai request_line buat ngebuktiin apakah dia itu sama
dengan request line milik sebuah request GET buat path /. Kalau emang
sama (it does), blok if tersebut bakal mengembalikan konten dari file HTML kita.
Kalau nilai request_line itu tidak sama (not equal) dengan GET request
ke path /, itu artinya kita udah nerima request untuk hal lain. Kita bakal
nambahin kode ke dalam blok else sebentar lagi buat membalas segala macam
requests lain yang masuk.
Silakan jalankan kode ini sekarang dan terus coba request alamat 127.0.0.1:7878;
kita seharusnya dapetin si HTML di dalam hello.html tersebut. Kalau kita bikin
request apa pun yang lainnya, kayak misalnya 127.0.0.1:7878/something-else,
kita bakal dapet error koneksi kayak yang kita temui pas ngejalanin kode di Listing
21-1 dan Listing 21-2.
Sekarang mari kita tambahin kode yang ada di Listing 21-7 ke dalam blok else
tersebut buat mengembalikan sebuah response (balasan) yang mana punya status
kode 404, yang mengindikasikan (signals) kalau konten buat request tersebut
tidak ditemukan (not found). Kita juga bakal mengembalikan (return) sebuah
file HTML buat halaman (page) yang bakal ditampilin (render) ke dalam browser yang
mana bakal mengindikasikan kepada sang end user (pengguna akhir) apa sebenarnya
response-nya.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
if request_line == "GET / HTTP/1.1" {
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
// --snip--
} else {
let status_line = "HTTP/1.1 404 NOT FOUND";
let contents = fs::read_to_string("404.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
}
}Di sini, response kita punya status line (baris status) dengan status kode
404 dan reason phrase NOT FOUND. Isi (body) dari response ini bakal
menjadi konten HTML dari sebuah file bernama 404.html. Kita perlu ngebikin file
404.html ini di sebelah (next to) file hello.html kita tadi buat halaman
error ini; sekali lagi ya, silakan pake HTML apa aja yang kita mau secara
bebas (feel free to use), atau kita juga bisa pakai HTML contoh (example HTML) yang ada
di Listing 21-8.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Oops!</h1>
<p>Sorry, I don't know what you're asking for.</p>
</body>
</html>
Dengan perubahan-perubahan ini, jalanin server kita lagi. Nge-request 127.0.0.1:7878 seharusnya mengembalikan isi konten dari hello.html, dan nyoba request apa pun yang lainnya, kayak 127.0.0.1:7878/foo, seharusnya nge-return halaman HTML error dari 404.html.
Sentuhan Kecil Refactoring (Merombak Kode)
Saat ini, di blok if dan else ada sangat banyak kode yang ngulang
(repetition): mereka berdua sama-sama lagi ngebaca file (reading files) lalu
sama-sama nulis (writing) isi konten file tersebut ke dalam stream. Satu-
satunya perbedaan ada di bagian status line dan nama filenya (filename).
Mari kita bikin kode ini jadi jauh lebih ringkas (concise) dengan menarik keluar
(pulling out) perbedaannya ke dalem baris-baris if dan else yang dipisah
yang mana bakal nge-assign (ngasih) nilai-nilai dari status line dan nama filenya
ke dalam variabel; kita lalu bisa memakai variabel-variabel tersebut secara mutlak
(unconditionally) di dalam kodenya buat membaca file dan nulis (write) balasannya.
Listing 21-9 nunjukin kode hasil (resultant code) sesudah kita nggantiin (replacing)
blok if dan else yang sangat besar (large) tadi.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
// --snip--
fn handle_connection(mut stream: TcpStream) {
// --snip--
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = if request_line == "GET / HTTP/1.1" {
("HTTP/1.1 200 OK", "hello.html")
} else {
("HTTP/1.1 404 NOT FOUND", "404.html")
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}if dan else supaya cuma berisi kode yang emang beda di antara kedua kasus tersebutSekarang blok if dan else tersebut cuma bakal nge-return nilai yang
paling pas buat status line dan nama file (filename) di dalam sebuah tuple;
terus kita memakai destructuring (pemecahan) buat nge-assign kedua nilai
ini ke variabel status_line dan filename memakai pattern (pola) di
dalam statement let, seperti yang udah di bahas di Bab 19.
Kode yang tadinya menduplikasi (duplicated) sekarang udah ditaruh di luar
(outside) blok if dan else lalu dia memakai variabel status_line dan
filename tadi. Hal ini ngebikin perbedaan di antara kedua kasus ini (two cases)
jadi jauh lebih gampang buat dilihat, dan ini juga berarti kita cuma perlu
ngubah kode (update the code) di satu tempat aja kalau kita pengen ngubah cara kerja
gimana si proses baca file (file reading) dan proses tulis balasan (response writing) ini
berjalan. Perilaku kode (behavior) di Listing 21-9 ini bakal tetap persis
sama kayak yang ada di Listing 21-7.
Keren sekali! (Awesome!) Nah sekarang kita udah punya sebuah web server sederhana cuma dalam waktu lebih kurang (approximately) 40 baris kode Rust yang mana merespons sebuah request tertentu dengan halaman berisi konten (page of content) dan membalas (responds to) semua requests lainnya pakai response 404.
Saat ini, server kita masih jalan di dalem single thread (satu utas/utas tunggal), yang artinya dia cuma bisa melayani (serve) satu request dalam satu waktu tertentu (at a time). Mari kita telusuri dan menguji (examine) gimana cara kerja kayak gini bisa mendatangkan sebuah masalah dengan menyimulasikan beberapa requests yang jalannya pelan (slow requests). Terus setelah itu kita bakal benerin itu supaya server kita bisa nanganin (handle) banyak requests secara sekaligus (at once).
Mengubah Server Single-Threaded Kita Menjadi Server Multithreaded
Mengubah Server Single-Threaded Kita Menjadi Server Multithreaded
Saat ini, server kita memproses setiap request secara bergantian (in turn), yang berarti dia tidak bakal memproses koneksi yang kedua sebelum proses untuk koneksi yang pertama selesai (finished processing). Kalau server ini nerima makin banyak requests, eksekusi secara berurutan (serial execution) kayak gini bakal jadi makin kurang optimal. Kalau server ini nerima sebuah request yang makan waktu lama sekali buat diproses, requests yang masuk berikutnya (subsequent requests) bakal terpaksa harus nungguin sampai request lama itu selesai, biarpun requests yang baru ini sebenernya bisa aja diproses dengan cepat. Kita perlu benerin ini nih, tapi pertama-tama mari kita ngelihat aksinya masalah ini secara langsung.
Menyimulasikan Sebuah Request yang Pelan (Slow Request)
Kita bakal ngelihat gimana sebuah request yang pemrosesannya lambat bisa berdampak sama requests lainnya yang dilakuin ke implementasi server kita saat ini. Listing 21-10 mengimplementasikan penanganan sebuah request ke path /sleep dengan menyimulasikan (simulated) sebuah balasan yang pelan yang mana bakal ngebikin server kita ini sleep (tidur/berhenti sejenak) selama lima detik sebelum dia ngasih balasan (responding).
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
// --snip--
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
// --snip--
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
// --snip--
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Kita beralih (switched) dari yang asalnya pakai if jadi match karena sekarang
kita punya tiga kemungkinan kasus (cases). Kita perlu secara eksplisit memakai
pencocokan (match) pada sebuah slice dari request_line buat mencocokkan pattern
(pattern-match) dengan nilai-nilai string literal tersebut; match itu tidak
secara otomatis ngelakuin referencing dan dereferencing kayak yang dilakuin sama
method equality (pemeriksaan kesamaan ==).
Arm (lengan) pertama ini bunyinya sama kayak isi dari blok if yang ada di Listing
21-9. Arm kedua cocok dengan sebuah request ke path /sleep. Pas request ini
diterima, server kita ini bakal tidur (sleep) selama lima detik sebelum dia nge-render
halaman HTML yang isinya sukses tersebut. Arm yang ketiga bunyinya sama persis kayak
blok else dari Listing 21-9.
Kita bisa ngelihat sendiri betapa primitifnya (primitive) server kita ini: libraries sungguhan (real libraries) itu biasanya nanganin proses rekognisi (pengenalan) banyak requests dengan cara yang jauh tidak lebih verbose (kepanjangan nulisnya) dari ini!
Jalanin servernya memakai cargo run. Terus buka dua jendela (windows) browser:
satu buat http://127.0.0.1:7878 dan satu lagi buat http://127.0.0.1:7878/sleep.
Kalau kita masukin URI / beberapa kali kayak sebelumnya, kita bakal ngelihat kalau dia
nge-responsnya cepet sekali. Tapi kalau kita masukin /sleep dan kemudian muat (load)
/ di tab lain, kita bakal ngelihat kalau / ini terpaksa harus nungguin (waits)
sampai si sleep tadi selesai tidur selama durasi penuh lima detiknya sebelum
halamannya bisa dimuat.
Ada banyak teknik yang bisa kita pakai buat ngehindarin situasi di mana requests
ini pada numpuk (backing up) di belakang sebuah request yang pelan, termasuk
salah satunya dengan memakai async kayak yang udah kita lakuin di Bab 17;
sementara yang bakal kita implementasikan di sini adalah sebuah thread pool
(kumpulan utas).
Meningkatkan Throughput dengan Sebuah Thread Pool
Sebuah thread pool itu adalah sekelompok threads yang udah ditelurkan (spawned) yang lagi bersiap-siap dan standby nungguin buat nanganin sebuah tugas (task). Saat program tersebut nerima tugas yang baru, dia bakal ngasih salah satu threads yang ada di dalam kolam (pool) ini buat ngerjain tugas tersebut, dan thread itulah yang bakal memprosesnya. Sisa threads lainnya yang ada di dalam pool ini tetep tersedia (available) buat nanganin tugas-tugas lain yang masuk saat thread yang pertama tadi lagi sibuk memproses. Pas thread pertama udah beres ngerjain tugasnya, dia dikembaliin (returned) lagi ke dalam pool yang isinya threads nganggur (idle threads), terus dia siap (ready) buat nanganin tugas baru lagi. Sebuah thread pool memungkinkan kita buat memproses banyak koneksi secara konkuren (bersamaan), ningkatin throughput (kemampuan nangani permintaan) dari server kita.
Kita bakal membatasi (limit) jumlah threads yang ada di dalam pool ini menjadi angka yang kecil buat melindungi (protect) kita dari serangan DoS (Denial of Service); kalau kita ngebikin program kita buat netasin (create) thread baru buat setiap kali ada request yang masuk, seseorang yang ngebikin 10 juta requests ke server kita bisa-bisa bikin kekacauan parah dengan cara ngabisin semua sumber daya (resources) server kita lalu bikin semua pemrosesan requests jadi mandek total (grinding to a halt).
Jadi ketimbang menelurkan threads tanpa batas (unlimited threads), kita bakal
punya jumlah threads yang tetap (fixed number) yang pada standby nungguin di
dalam pool tersebut. Requests yang masuk bakal dikirimin ke dalam pool ini
buat diproses. Pool ini bakal memelihara sebuah antrean (queue) yang isinya requests
yang baru masuk. Masing-masing dari threads yang ada di dalam pool ini bakal
mengambil (pop off) satu request dari antrean ini, menangani request tersebut,
dan lalu minta satu request lagi ke antrean tersebut. Pakai desain kayak gini,
kita bisa memproses maksimal N requests secara konkuren, di mana N itu
adalah jumlah threads yang ada. Kalau setiap thread itu lagi sibuk merespons ke
requests yang jalan lama sekali, requests yang masuk berikutnya emang masih
tetap bisa pada numpuk di dalem antreannya, tapi kita udah ningkatin seberapa banyak jumlah
requests yang jalannya lama sekali yang sanggup kita tangani sebelum kita nyampe ke titik
jenuh tersebut.
Teknik ini itu hanyalah salah satu dari sekian banyak cara yang ada buat ningkatin throughput dari sebuah web server. Opsi-opsi lain yang mungkin bisa kita eksplorasi adalah model fork/join, model single-threaded async I/O, sama model multithreaded async I/O. Kalau kita tertarik sama topik ini, kita bisa ngebaca lebih lanjut soal solusi-solusi lainnya dan nyobain mengimplementasikan mereka; dengan bahasa pemrograman tingkat rendah (low-level) kayak Rust ini, semua opsi ini sangat mungkin sekali buat dikerjain (possible).
Sebelum kita mulai mengimplementasikan sebuah thread pool, mari kita obrolin kayak gimana rupa dari memakai si pool ini nantinya (what using the pool should look like). Pas kita lagi mencoba mendesain (design) sebuah kode, menulis interface client-nya terlebih dahulu bisa ngebantu memandu jalannya desain kita. Tulis API dari kodenya sehingga strukturnya itu udah sesuai dengan cara kita manggil dia nantinya; baru deh setelah itu implementasikan fungsionalitasnya di dalam struktur tersebut ketimbang mikirin fungsionalitasnya duluan baru mikirin desain API public-nya belakangan.
Mirip dengan gimana kita memakai test-driven development (pengembangan berbasis pengujian) di dalam project kita pas Bab 12 kemarin, kita bakal memakai compiler-driven development (pengembangan berbasis compiler) di sini. Kita bakal nulis kode yang manggil fungsi-fungsi yang pengen kita panggil, lalu baru deh kita ngelihat ke error-error yang dikasih sama compiler buat nentuin apa yang harus kita ubah berikutnya supaya kodenya bisa benar-benar jalan. Tapi sebelum kita melakukan itu, kita bakal nyelidikin teknik yang tidak bakal kita pakai dulu sebagai titik mulai kita.
Menelurkan (Spawning) Sebuah Thread Buat Setiap Request
Pertama-tama, mari kita eksplorasi kira-kira kayak gimana kelihatannya kode kita ini kalau seandainya dia benar-benar ngebikin thread baru buat setiap koneksi yang masuk. Seperti yang udah kita sebutin sebelumnya, ini itu bukan rencana akhir kita gara-gara ada masalah yang mana kita berpotensi bakal netasin threads dalam jumlah yang tidak terbatas, tapi cara ini adalah titik pijak (starting point) yang oke buat ngebikin supaya server multithreaded kita ini bisa jalan dulu. Nanti barulah kita tambahin thread pool sebagai sebuah perbaikan (improvement), dan jadinya membandingkan (contrasting) kedua buah solusi ini bakal jadi lebih gampang.
Listing 21-11 nunjukin beberapa perubahan yang perlu dibikin di dalam fungsi main
supaya dia menelurkan (spawn) sebuah thread baru buat nanganin masing-masing
stream yang ada di dalam loop for tersebut.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
thread::spawn(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Kayak yang udah kita pelajarin di Bab 16, thread::spawn itu bakal ngebikin thread
baru lalu dia bakal ngejalanin kode yang ada di dalam closure tersebut di dalem si thread
yang baru ini. Kalau kita jalanin kode ini dan memuat /sleep di browser kita, lalu buka
/ di dua tab browser yang lain, kita benar-benar bakal ngelihat kalau requests ke / itu
tidak perlu lagi nungguin si /sleep sampai selesai beres (finish). Namun, seperti yang
tadi udah kita sebutin, cara ini pada akhirnya bakal bikin sistemnya kewalahan (overwhelm
the system) karena kita bakal terus-terusan ngebikin threads baru tanpa ada batas
sama sekali.
Kita juga mungkin masih inget dari Bab 17 kalau ini itu adalah tipe-tipe situasi persis yang mana async dan await bakal benar-benar bersinar! Simpan pikiran itu di kepala kita ya selagi kita ngebangun thread pool ini dan coba renungkan (think about) gimana situasinya bakal kelihatan berbeda atau malah sama aja kalau kita pakai async.
Ngebikin Sejumlah Threads dalam Jumlah Terbatas (Finite Number of Threads)
Kita mau supaya thread pool kita ini bekerja dengan cara yang mirip-mirip dan kerasa
familier supaya pindah (switching) dari threads biasa ke thread pool ini tidak butuh
perubahan gede-gedean pada kode-kode yang memakai API kita. Listing 21-12 nunjukin
antarmuka bayangan (hypothetical interface) buat sebuah struct ThreadPool yang pengen
kita pakai ketimbang thread::spawn.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}ThreadPool ideal milik kitaKita memakai ThreadPool::new buat ngebikin sebuah thread pool baru dengan jumlah
threads yang bisa dikonfigurasi, yang di kasus ini yaitu empat biji. Terus, di dalam
loop for, si pool.execute ini punya antarmuka (interface) yang mirip sekali
sama thread::spawn karena dia juga nerima sebuah closure yang mana seharusnya bakal
dijalanin sama si pool tersebut buat setiap stream yang masuk. Kita perlu mengimplementasikan
pool.execute ini sedemikian rupa sehingga dia bakal ngambil closure yang diterimanya
itu terus ngasihin itu ke salah satu thread yang ada di dalam pool buat dijalanin.
Kode ini jelas masih belum bisa di-compile, tapi kita bakal nyoba men-compile-nya
supaya si compiler bisa memandu (guide) kita soal gimana caranya ngeberesin ini.
Ngebangun ThreadPool Memakai Compiler-Driven Development (Pengembangan Berbasis Compiler)
Silakan bikin perubahan-perubahan yang ada di Listing 21-12 ke file src/main.rs kita,
dan lalu mari kita pakai pesan-pesan error compiler yang asalnya dari cargo check
buat mengarahkan jalan (drive) dari proses development kita. Ini dia error
pertama yang kita dapet:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0433]: failed to resolve: use of undeclared type `ThreadPool`
--> src/main.rs:11:16
|
11 | let pool = ThreadPool::new(4);
| ^^^^^^^^^^ use of undeclared type `ThreadPool`
For more information about this error, try `rustc --explain E0433`.
error: could not compile `hello` (bin "hello") due to 1 previous error
Sip sekali! (Great!) Error ini ngasih tahu kita kalau kita ini butuh punya tipe atau
modul ThreadPool, jadi kita bakal ngebangunnya sekarang juga. Implementasi ThreadPool
kita ini sifatnya bakal independen (independent) dan tidak peduli apa jenis kerjaan
yang lagi dilakuin sama web server kita ini. Jadi mari kita alihkan (switch)
crate hello kita ini dari yang tadinya sebuah binary crate menjadi sebuah
library crate buat nampung kode implementasi ThreadPool kita ini. Setelah kita ngubah
dia jadi library crate, kita juga jadi bisa lho memakai library thread pool yang
udah terpisah ini buat sekiranya ada pekerjaan apa pun lainnya yang mau kita lakuin pakai
sebuah thread pool, bukannya cuma khusus buat ngelayanin (serving) web requests doang.
Bikin sebuah file src/lib.rs yang isinya mengandung yang berikut ini, yang mana ini
adalah definisi paling simpel yang bisa kita punya buat sebuah struct ThreadPool buat
saat ini:
pub struct ThreadPool;Terus edit file main.rs kita buat ngebawa (bring) ThreadPool tersebut masuk ke
dalam scope yang asalnya dari library crate dengan nambahin kode berikut ke bagian
paling atas (top) dari src/main.rs:
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Kode ini tentu masih belum bisa jalan ya, tapi mari kita cek (check) kodenya lagi buat dapetin pesan error selanjutnya yang perlu kita beresin (address):
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no function or associated item named `new` found for struct `ThreadPool` in the current scope
--> src/main.rs:12:28
|
12 | let pool = ThreadPool::new(4);
| ^^^ function or associated item not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` (bin "hello") due to 1 previous error
Error ini mengindikasikan kalau langkah selanjutnya yang perlu kita lakuin adalah
ngebikin sebuah fungsi associated bernama new untuk si ThreadPool ini. Kita
juga tahu kalau new ini butuh satu parameter yang mana bisa menerima angka 4
sebagai argumen dan harus ngembaliin sebuah instance ThreadPool.
Mari kita implementasikan fungsi new yang paling simpel yang punya karakteristik
kayak gitu:
pub struct ThreadPool;
impl ThreadPool {
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
}Kita milih usize sebagai tipe buat parameter size karena kita tahu kalau ngebikin
threads dengan jumlah minus (negative number) itu emang kedengerannya
tidak masuk akal (doesn’t make sense). Kita juga tahu kalau kita bakal makek angka
4 ini sebagai ukuran jumlah elemen di dalam sebuah koleksi (collection) yang
isinya threads, yang mana itu adalah tujuan asli kenapa tipe usize dibikin, kayak yang udah
kita obrolin di “Tipe-tipe Angka Bulat (Integer Types)” di Bab 3.
Mari kita cek kodenya lagi:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no method named `execute` found for struct `ThreadPool` in the current scope
--> src/main.rs:17:14
|
17 | pool.execute(|| {
| -----^^^^^^^ method not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` (bin "hello") due to 1 previous error
Sekarang errornya kejadian gara-gara kita tidak punya method execute pada
struct ThreadPool kita. Ingat kembali materi dari “Ngebikin Sejumlah Threads dalam
Jumlah Terbatas (Finite Number of Threads)” tadi
di mana kita memutuskan kalau thread pool kita ini seharusnya punya interface (antarmuka)
yang mirip sama thread::spawn. Selain itu, kita bakal mengimplementasikan fungsi
execute ini sedemikian rupa sehingga dia nerima closure yang udah dikasih ke dia
lalu mengopernya ke sebuah thread yang lagi nganggur (idle thread) di dalam si pool
tersebut buat dijalanin.
Kita bakal mendefinisikan method execute pada ThreadPool ini supaya dia menerima
sebuah closure sebagai parameter. Ingat kembali dari “Mengoper Nilai yang Ditangkap
Keluar dari Closure dan Trait Fn” di Bab 13 kalau kita bisa nerima closures
sebagai parameter yang memakai tiga jenis trait yang berbeda: yaitu Fn, FnMut, dan
FnOnce. Kita harus memutuskan trait closure mana yang mau dipakai di sini. Kita tahu
kalau ujung-ujungnya kita ini bakal ngerjain hal yang mirip-mirip sama yang dilakuin
oleh implementasi thread::spawn punya standard library, jadi kita bisa nyontek (look at)
batasan-batasan (bounds) apa aja yang dipunyai sama signature si thread::spawn ini pada parameternya.
Dokumentasi di sana ngasih tahu kita hal berikut:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,Parameter bertipe F inilah yang lagi jadi fokus (concerned with) kita di sini;
sedangkan parameter bertipe T itu ada kaitannya sama nilai kembalian
(return value) dari fungsi itu, yang mana itu tidak jadi masalah buat kita. Kita bisa
ngelihat kalau si spawn ini memakai FnOnce sebagai trait bound (batasan trait)
buat F-nya. Ini juga merupakan trait yang kemungkinan besar kita inginkan, karena
nantinya argumen closure yang kita dapat di dalam execute ini juga pada akhirnya
bakal kita operin (pass) ke dalam spawn. Kita bisa makin yakin kalau FnOnce itu
adalah trait yang benar-benar pengen kita pake soalnya thread yang dijalanin buat
nanganin satu request itu emang cuma bakal mengeksekusi closure buat request tersebut
sebanyak satu kali doang, yang mana ya cocok persis (matches) sama embel-embel kata
Once (sekali) di dalam trait FnOnce.
Parameter bertipe F itu juga punya trait bound Send dan lifetime bound
(batasan rentang hidup) 'static, yang mana emang sangat berguna buat situasi kita
saat ini: kita butuh trait Send ini buat mindahin (transfer) si closure
ini dari satu thread ke thread yang lainnya dan 'static ini gara-gara kita tidak
tahu seberapa lama waktu yang dibutuhkan sama si thread tersebut buat selesai
melakukan eksekusi kodenya. Mari kita bikin method execute pada ThreadPool
yang bakal menerima parameter generik (generic parameter) bertipe F dengan
bounds berikut:
pub struct ThreadPool;
impl ThreadPool {
// --snip--
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}Kita tetep pake tambahan () setelah trait FnOnce tersebut karena si FnOnce
ini merepresentasikan sebuah closure yang mana dia tidak menerima parameter
apa-apa dan dia juga mengembalikan unit type (tipe unit kosong) (). Sama kayak
halnya definisi fungsi (function definitions), tipe return-nya bisa
aja disingkirkan (omitted) dari signature-nya, tapi meskipun kita tidak
nerima parameter apa-apa di dalam closure-nya, kita tetep wajib nulisin tanda kurung
yang kosong tersebut (parentheses).
Sekali lagi, ini adalah sekadar implementasi paling simpel (simplest) dari method
execute: dia sama sekali tidak ngelakuin apa-apa, tapi kan tujuan kita cuma
mau ngebikin kode kita sukses di-compile doang buat saat ini. Mari kita cek (check) lagi deh:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.24s
Kompilasi sukses! (It compiles!) Tapi perlu dicatet nih kalau seandainya kita
mencoba ngejalanin pake cargo run dan terus nyoba ngasih sebuah request dari browser,
kita bakal ngelihat lagi error-error di browser tadi yang sempat kita lihat di
bagian awal bab ini. Library kita ini masih belum secara harfiah (actually) memanggil
closure yang dioper ke dalem fungsi execute lho ya!
Catatan: Pepatah yang mungkin sering kita dengar soal bahasa-bahasa pemrograman yang compiler-nya rewel (strict compilers), kayak Haskell dan Rust, adalah “kalau kodenya berhasil di-compile, berarti kodenya jalan.” Tapi pepatah ini itu tidak selalu bener kok. Project kita ini sukses di-compile kan, padahal dia itu bener-bener tidak ngelakuin apa-apa sama sekali! Kalau seandainya kita ini lagi ngebangun project sungguhan yang lengkap, ini adalah saat-saat yang paling pas buat mulai nulisin unit tests buat ngetes (check) apakah kodenya sukses di-compile sekaligus punya perilaku yang emang kita mau atau tidak.
Renungkan ini: kira-kira apa yang bakal berbeda di sini kalau seandainya kita ini lagi mau ngejalanin sebuah future ketimbang sebuah closure?
Memvalidasi Jumlah Threads yang Ada di new
Kita sama sekali tidak ngelakuin tindakan apa-apa lho sama parameter-parameter
yang ada di fungsi new dan execute ini. Mari kita implementasikan body
(isi) dari fungsi-fungsi ini supaya punya perilaku yang emang kita inginkan. Buat
memulai, mari kita pikirin soal fungsi new. Sebelumnya kita udah milih (chose) tipe
tanpa tanda (unsigned type) buat parameter size karena ngebikin sebuah pool dengan jumlah threads
yang negatif itu emang tidak masuk akal (makes no sense). Tapi ya,
sebuah pool dengan angka nol threads juga tidak kalah tidak masuk akalnya dong,
padahal angka nol itu adalah angka yang sah-sah aja (perfectly valid) di tipe
usize. Kita bakal tambahin barisan kode buat ngecek (check) kalau variabel size
itu harus lebih gede dari angka nol sebelum kita mengembalikan sebuah instance
ThreadPool lalu ngebikin programnya jadi panic dengan memakai macro
assert! kalau ternyata kita dikasih angka nol, kayak yang kelihatan di
Listing 21-13.
pub struct ThreadPool;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
ThreadPool
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}ThreadPool::new supaya dia panic kalau size-nya nolKita juga udah nambahin secuil dokumentasi buat ThreadPool kita memakai komentar
dok (doc comments). Perhatikan kalau kita udah mengikuti (followed) kaidah penulisan dokumentasi
yang bagus (good documentation practices) dengan cara nambahin sebuah seksi yang mana
membeberkan kasus-kasus (call out the situations) di mana fungsi kita ini bisa jadi
panic, kayak yang dibahas di Bab 14. Silakan cobain jalanin cargo doc --open
lalu klik struct ThreadPool tersebut buat ngelihat kayak apa rupa dari docs
yang udah di-generate buat method new tersebut!
Ketimbang nambahin macro assert! kayak yang baru aja kita lakuin di sini,
kita sebenernya bisa aja kok ngerubah method new ini jadi build dan terus
ngembaliin (return) sebuah tipe Result persis kayak apa yang udah kita lakuin
sama fungsi Config::build di dalem project I/O kita di Listing 12-9.
Tapi kita udah memutuskan kalau di kasus kali ini usaha buat ngebikin sebuah thread pool
tanpa punya satupun threads di dalamnya (without any threads) itu seharusnya
dijadikan sebuah error yang tidak bisa dipulihkan (unrecoverable error). Kalau
kita lagi ngerasa ambisius hari ini, cobain deh buat nulis sebuah fungsi bernama
build dengan signature berikut buat ngebandingin hasilnya dengan fungsi
new ini:
pub fn build(size: usize) -> Result<ThreadPool, PoolCreationError> {Menyiapkan Tempat Buat Menyimpan Para Threads
Sekarang karena kita udah punya cara yang valid buat mengetahui (know) jumlah threads
yang harus disimpan di dalam pool, kita akhirnya bisa ngebikin threads tersebut lalu
menyimpan mereka di dalam struct ThreadPool sebelum kita ngembaliin si struct itu. Tapi
gimana ya caranya kita “menyimpan” sebuah thread? Mari kita ngelirik balik
(take another look) ke signature dari thread::spawn:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,Fungsi spawn ini ngembaliin (returns) sebuah JoinHandle<T>, di mana T itu
adalah tipe balasan (return type) dari closure tersebut. Mari kita cobain pakai
JoinHandle juga deh dan lihat apa yang bakal kejadian. Di kasus yang kita kerjain
sekarang, closures yang kita oper masuk ke dalem thread pool ini emang tugasnya
buat nanganin (handle) koneksi dan bukannya buat ngembaliin data apa pun juga, jadi si
T ini nilainya bakal berupa unit type ().
Kode yang ada di Listing 21-14 ini bakal berhasil di-compile tapi masih belum ngebikin
satu pun threads. Kita udah ngubah (changed) definisi dari ThreadPool supaya dia
menyimpan (hold) sebuah vector yang isinya berupa instances dari
thread::JoinHandle<()>, menginisialisasi vector tersebut supaya punya kapasitas memori
sejumlah size (with a capacity of size), nyiapin (set up) loop for yang
nantinya bakal njalanin beberapa kode buat ngebikin threads tersebut,
dan baru deh membalikkan (returned) sebuah instance ThreadPool yang ngandung mereka semua.
use std::thread;
pub struct ThreadPool {
threads: Vec<thread::JoinHandle<()>>,
}
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut threads = Vec::with_capacity(size);
for _ in 0..size {
// create some threads and store them in the vector
}
ThreadPool { threads }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}ThreadPool buat menampung para threads yang adaKita udah ngebawa (brought) std::thread masuk ke dalam scope di dalam library
crate kita gara-gara kita lagi mau makek thread::JoinHandle sebagai tipe buat
item-item yang bakal masuk ke dalam vector milik si ThreadPool.
Setelah angka size yang valid itu diterima (received), ThreadPool kita ini ngebikin
sebuah vector baru yang mana sanggup nampung sejumlah size item. Fungsi
with_capacity ini ngelakuin tugas yang sama persis kayak fungsi Vec::new
tapi dengan satu perbedaan krusial (important difference): dia udah mengalokasikan memori lebih dulu
(pre-allocates space) ke dalam vector tersebut. Karena kita tahu pasti (we know)
kalau kita ini perlu menyimpan size elemen di dalam vector ini, ngelakuin
proses alokasi (allocation) memori dari awal kayak gini itu slightly (sedikit)
lebih efisien dan cepet ketimbang makek fungsi Vec::new yang mana dia itu bakal
mengubah ukurannya sendiri (resizes itself) setiap kali ada elemen baru yang
dimasukin ke dalam situ.
Pas kita jalanin perintah cargo check lagi, dia harusnya berhasil (succeed).
Ngirimin Kode dari Dalam ThreadPool ke Sebuah Thread
Kita ninggalin (left) sebuah komentar di dalam loop for tadi yang ada di
Listing 21-14 mengenai (regarding) urusan pembuatan threads. Di sini, kita bakal
ngelihat gimana sebenarnya langkah yang kita tempuh buat ngebikin threads tersebut.
Standard library menyediakan fungsi thread::spawn sebagai cara buat bikin
threads baru, dan si thread::spawn ini ngeharepin buat langsung dikasih beberapa
kode yang harus dijalanin seketika (as soon as) pas thread tersebut selesai
dibikin. Padahal, di kasus yang kita punya, kita pengennya (want to)
ngebikin threads tersebut terus ngebikin mereka buat menunggu (wait) kode-kode
(tasks) yang bakal kita kirimin nanti (later). Implementasi (implementation) dari
threads bawaan (standard library) ini sama sekali tidak punya opsi (way) buat ngelakuin hal semacam
itu; jadinya kita harus mengimplementasikannya secara manual (manually).
Kita bakal mengimplementasikan perilaku (behavior) ini dengan cara
memperkenalkan sebuah struktur data baru (new data structure) di antara si
ThreadPool tersebut dan threads ini yang mana struktur data ini bakal bertugas
mengelola (manage) tingkah laku yang baru ini. Kita bakal namain struktur data ini
Worker (Pekerja), yang mana merupakan sebuah istilah lazim (common term) yang
suka dipakai di dalam berbagai implementasi model pemusatan (pooling). Sang Worker
ini tugasnya ngambilin (picks up) kode-kode (tasks) yang harus dijalanin terus
menjalanin kode-kode itu di dalam thread miliknya.
Coba bayangin (think of) kayak orang-orang yang lagi kerja di dalem dapur sebuah restoran: para pekerja dapur (workers) ini pada nungguin sampai pesanan (orders) datang dari para pelanggan (customers), dan terus mereka jadinya bertanggung jawab (responsible) buat nerima (taking) pesanan-pesanan tersebut terus menuhin (filling) pesanan itu (masak makanannya).
Ketimbang nyimpen vector yang isinya sekumpulan instances JoinHandle<()> di
dalam thread pool ini, kita sebaliknya bakal nyimpen instances dari struct
Worker. Masing-masing Worker ini bakal nge-store (menyimpan) sebuah instance
JoinHandle<()> tunggal. Kemudian kita bakal mengimplementasikan sebuah method pada
si Worker ini yang mana method itu nerima sebuah closure berisi kode yang harus
dijalanin terus method itu bakal ngirimin closure itu ke thread yang emang udah lagi pada nyala (already
running) supaya bisa tereksekusi. Kita juga bakal ngasih setiap Worker ini
sebuah id (identifikasi/identitas) supaya kita gampang mbedain di antara berbagai macam instances Worker
yang ada di dalam pool tersebut saat kita lagi nyatet log (logging) atau debugging.
Berikut ini adalah gambaran proses baru yang bakal berlangsung (happen) pas
kita ngebikin sebuah ThreadPool. Kita bakal mengimplementasikan kode yang tugasnya
ngirimin si closure tersebut ke thread itu setelah kita selesai nge-setup si Worker
ini memakai cara di bawah ini:
- Definisikan sebuah struct
Workeryang menampung (holds) sebuahiddan sebuahJoinHandle<()>. - Ubah
ThreadPoolsupaya dia itu sekarang malah nampung sebuah vector berisi instances dariWorker. - Definisikan sebuah fungsi
Worker::newyang nerima sebuah angka (number) buat jadiidterus dia ngembaliin sebuah instanceWorkeryang nampung siiditu beserta sebuah thread baru yang ditetaskan (spawned) memakai sebuah closure yang kosong. - Di dalam
ThreadPool::new, pakailah angka penghitung (counter) yang asalnya dari loopforitu buat di-generate (dijadiin) sebuahid, bikin sebuahWorkerbaru pakaiidtadi, terus masukin dan simpan siWorkerbaru itu ke dalam vector-nya.
Kalau kita ngerasa pengen nyari tantangan, coba deh kerjain sendiri perubahan-perubahan ini (implementing these changes on your own) sebelum kita ngelihat ke kodenya di Listing 21-15.
Udah siap (Ready)? Ini dia Listing 21-15 yang berisi salah satu cara buat ngebikin (make) serangkaian modifikasi-modifikasi sebelumnya.
use std::thread;
pub struct ThreadPool {
workers: Vec<Worker>,
}
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}ThreadPool supaya dia menampung instances Worker ketimbang menampung threads secara langsungKita udah mengganti nama field di ThreadPool dari asalnya threads menjadi
workers karena emang sekarang dia jadinya malah nyimpen instances Worker
ketimbang instances dari JoinHandle<()>. Kita pakai angka hitungan
(counter) dari loop for tersebut sebagai argumen buat Worker::new, lalu
menyimpan (store) tiap Worker yang baru dibikin ke dalam vector yang namanya workers.
Kode-kode luar (external code, seperti server kita yang ada di src/main.rs) tidak perlu
tahu detail-detail spesifik implementasinya sehubungan sama pemakaian struct Worker
di dalam sebuah ThreadPool, makanya kita membiarkan struct Worker dan fungsi
new-nya itu bernilai (sifatnya) private. Fungsi Worker::new tersebut memakai
id yang udah kita kasih terus menyimpan sebuah instance dari JoinHandle<()> yang mana
instance ini dibikin dengan cara menelurkan sebuah thread baru memakai closure kosong.
Catatan: Kalau sistem operasinya (OS) tidak mampu buat membikin sebuah thread gara-gara kekurangan sumber daya sistem (aren’t enough system resources), fungsi
thread::spawnitu jadinya bakal meledak (panic). Hal ini bakal ngebikin seluruh server kita jadi ikutan panik, sekalipun pembuatan dari beberapa threads yang lain itu sebenarnya berhasil dengan lancar (might succeed). Demi urusan kemudahan buat dipelajari (simplicity’s sake), membiarkan kelakuan ini terjadi itu sah-sah saja kok (is fine), tapi kalau di kasus implementasi thread pool tipe tingkat produksi (production), kita bakal jauh lebih direkomendasiin (likely want to) buat memakaistd::thread::Builderbarengan sama methodspawn-nya karena method tersebut nge-return (ngembaliin) tipeResultsebagai gantinya.
Kode kita ini bakal bisa di-compile dan bakal berhasil menyimpan jumlah dari
instances Worker sebanyak yang udah kita spesifikasikan sebagai argumen
waktu manggil ThreadPool::new. Tapi kita ini masih juga belum memproses
(processing) closure yang kita dapetin dari pemanggilan execute ya. Mari kita ngelihat
gimana caranya supaya kita bisa ngerjain langkah yang itu sekarang.
Mengirim Requests ke Dalem Threads Melalui Channels (Saluran Komunikasi)
Permasalahan (problem) berikutnya yang harus segera kita tangani adalah fakta kalau closures yang dikasihin ke
thread::spawn itu bener-bener nyatanya tidak berbuat apa-apa (do absolutely nothing). Saat ini,
kita ngedapetin closure yang mana pengen kita jalanin tersebut (execute) lewat method execute.
Tapi kita ini perlu bisa ngasih si fungsi thread::spawn tadi sebuah closure untuk dijalankan
ketika (when) kita lagi repot-repotnya membikin setiap Worker tersebut saat fase-fase (during)
pembentukan (creation) dari ThreadPool itu.
Kita pengennya supaya struct-struct Worker yang baru aja kita bikin ini bisa ngambilin
(fetch) kode yang mau mereka jalanin tersebut yang dapetnya dari sebuah antrean (queue) yang
ditampung (held) di dalam ThreadPool terus ngirimin kode (task) tersebut ke thread
miliknya buat dijalankan.
Saluran komunikasi (channels) yang sempat kita pelajarin di Bab 16—sebuah
cara yang simpel buat berkomunikasi di antara dua buah threads—itu bakal jadi pilihan
(candidate) yang luar biasa pas sekali (perfect) buat menangani skenario (use case)
ini. Kita bakal memakai sebuah channel supaya dia bisa bertindak (function) sebagai antrean
pekerjaan (queue of jobs) tersebut, dan method execute bakal mengirimkan (send)
sebuah pekerjaan (job) dari dalam ThreadPool menuju instances Worker, yang
mana kemudian bakal ngirimin si job tersebut menuju thread miliknya. Ini
dia rancangannya (plan):
ThreadPoolbakal membikin (create) sebuah channel (saluran) dan berpegang erat (hold on to) pada bagian ujung pengirimnya (sender).- Masing-masing
Workerbakal berpegangan (hold on to) pada bagian penerimanya (receiver). - Kita bakal membikin sebuah struct
Jobbaru yang mana tugasnya buat nampung (hold) closures yang pengen kita kirimkan masuk menyusuri (down) si channel tersebut. - Method
executebakal mengirim (send) si job (pekerjaan) yang mau dia eksekusi (execute) tersebut melalui si sender (pengirim) ini. - Di dalam thread masing-masing, si
Workerini bakal muter berulang-ulang (loop over) menanyai receiver-nya (penerimanya) lalu mengeksekusi closures yang asalnya dari semua jobs apa pun yang mana dia terima (receive).
Mari kita mulai (start by) dengan ngebikin sebuah channel di dalam ThreadPool::new
dan menyimpan (holding) si pengirim (sender) itu di dalam instance
ThreadPool kita ini, persis kayak apa yang ditunjukin di Listing 21-16. Struct Job
ini sendiri belum nampung benda apa pun sih buat saat ini tapi si Job inilah yang bakal jadi
tipe dari item yang lagi mau kita kirim menyusuri (down) ke dalam channel (saluran) ini.
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}ThreadPool buat menyimpan sender dari sebuah channel yang mentransmisikan instances JobDi dalam ThreadPool::new, kita membikin channel yang baru terus nyuruh si
pool tersebut buat menyimpen (hold) ujung si pengirimnya (sender). Kode ini
bakal berhasil sukses di-compile dengan mulus.
Mari kita cobain buat ngoper masuk sebuah ujung penerima (receiver) dari si channel ini
ke masing-masing Worker seiringan saat si thread pool lagi ngebikin si channel
tersebut. Kita tahu (know) kan kalau kita itu pengen makek bagian receiver (penerima) ini
dari dalam thread yang mana ditetaskan (spawn) oleh tiap instances si Worker tadi, jadi kita
bakal memasukkan referensi (reference) parameter si receiver ini di dalam closure yang
lagi kita buat itu. Sayangnya (won’t quite), kode yang ada di Listing 21-17 ini ternyata masih belum
bisa di-compile dengan sukses nih buat saat ini.
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, receiver));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}WorkerKita udah membuat sedikit perubahan kecil dan gampang (straightforward): kita oper si receiver
masuk ke dalam Worker::new, terus kita memakai si receiver itu di dalam
closure-nya.
Pas kita mencoba buat ngecek kode ini (check this code), kita langsung kejedot sama error ini nih:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0382]: use of moved value: `receiver`
--> src/lib.rs:26:42
|
21 | let (sender, receiver) = mpsc::channel();
| -------- move occurs because `receiver` has type `std::sync::mpsc::Receiver<Job>`, which does not implement the `Copy` trait
...
25 | for id in 0..size {
| ----------------- inside of this loop
26 | workers.push(Worker::new(id, receiver));
| ^^^^^^^^ value moved here, in previous iteration of loop
|
note: consider changing this parameter type in method `new` to borrow instead if owning the value isn't necessary
--> src/lib.rs:47:33
|
47 | fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
| --- in this method ^^^^^^^^^^^^^^^^^^^ this parameter takes ownership of the value
help: consider moving the expression out of the loop so it is only moved once
|
25 ~ let mut value = Worker::new(id, receiver);
26 ~ for id in 0..size {
27 ~ workers.push(value);
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `hello` (lib) due to 1 previous error
Kodenya ini lagi berusaha (trying to) ngoper nilai receiver yang cuma satu ini ke
banyak instances Worker secara bebarengan. Ini jelas tidak bisa jalan (won’t work), seperti
yang pasti kita masih ingat (recall) dari memori kita pas lagi ngebaca Bab 16: bentuk implementasi
channel yang disediain sama Rust itu formatnya adalah sistem banyak pengirim (multiple producer),
tapi cuma satu penerima (single consumer). Ini bermakna kalau kita ini tidak bisa lho sekadar nge-clone
(kloning) si bagian consumer (pengkonsumsi) dari saluran komunikasi ini buat mbetulin kode
yang lagi eror ini. Lagian, kita emang sebenernya juga tidak mau kok (don’t want to) buat
ngirimin pesan yang itu-itu lagi berkali-kali nuju ke bermacam consumers (penerima pesan);
kita sebaliknya pengen ngirimin satu list panjang isinya pesan ke banyak (multiple) instances
Worker tapi dengan harapan bahwa masing-masing pesannya itu cuma berhak (gets processed)
bakal diproses sekali doang secara giliran.
Sebagai tambahan (additionally), tindakan ngambil (taking) satu job pekerjaan ngelepasin
dari queue (antrian) saluran tersebut itu emang pastinya bakal mengubah wujud (mutating)
si receiver-nya ini, gara-gara hal ini makanya threads yang ada itu sangat perlu punya sebuah
mekanisme (way) yang dirasa aman (safe) supaya mereka bisa bagi-bagi (share) dan ngubah
(modify) isi receiver ini secara bebarengan; kalau tidak, kita malah bisa-bisa ngejeblos dapet
race conditions (perlombaan data) yang bikin program rusak (seperti yang udah dibahas babak
belur di Bab 16 kemaren).
Ingat balik soal tipe smart pointers (pointer cerdas) yang udah terjamin aman buat di
dalam thread (thread-safe) yang barusan kita obrolin di Bab 16 kemaren: buat membagikan
(share) hak kepemilikan (ownership) melintasi (across) banyak threads yang berbeda dan secara bebarengan
ngebolehin para threads tersebut buat ngubah (mutate) nilai datanya bareng-bareng, kita
sangat butuh pake Arc<Mutex<T>>. Tipe Arc ini yang bakal ngebolehin kalau banyak instances
Worker buat bisa sama-sama ngantongin (own) si receiver, dan tipe Mutex ini yang bakal
mastiin ke kita kalau di satu titik waktu tertentu (at a time) itu cuma ada bener-bener
satu doang dari sekian banyak Worker yang berhak ngambil sebuah job (kerjaan)
langsung dari si receiver (penerimanya) tersebut. Listing 21-18 di bawah ini mendemonstrasikan perubahan
macam apa yang wajib kita lakuin ini.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
// --snip--
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
// --snip--
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}Worker tersebut dengan cara makek Arc dan MutexDi dalam fungsi ThreadPool::new, kita ngeletakkin (put) si receiver tersebut ke dalam balutan
sebuah Arc dan sebuah Mutex. Buat masing-masing Worker yang baru dibikin (new), kita meng-clone
(bikin kloningan) si Arc ini tujuannya supaya dia bakal nge-bump (nambah) reference count-nya (hitungan referensinya)
sedemikian rupa sehingga keseluruhan instances dari Worker ini pada akhirnya bisa
saling ngebagi-bagi hak kepemilikannya bareng (share ownership) buat si penerima (receiver) tersebut.
Dengan berbekal semua perubahan ini, kodenya akhirnya bisa sukses di-compile! Kita udah hampir nyampe (getting there) ke tujuan akhir kita ini loh!
Mengimplementasikan Method execute
Mari kita benar-benar akhirnya mulai ngerjain dan mengimplementasikan method execute
pada ThreadPool tersebut secara tuntas. Kita juga bakal ngubah tipe Job ini dari asalnya sebuah struct menjadi
sebuah type alias (alias buat sebuah tipe) aja buat nampung si trait object (objek trait) yang mana
benar-benar bakal nampung (hold) secara bener tipe dari closure asli yang mana si execute ini tadi lagi nerima.
Kayak yang barusan kelar dibahas di “Membikin Sinonim Tipe dengan Type Aliases”
di dalem Bab 20 kemaren, fitur type aliases ini ngebolehin kita buat mempersingkat (make shorter)
nama dari tipe-tipe yang kelihatannya sumpek kepanjangan supaya nanti mereka itu jadi jauh lebih
enak plus lebih gampang (ease) buat dipakek sehari-hari. Coba tengok dan perhatikan Listing 21-19
ini deh.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}Job supaya nampung sebuah Box yang aslinya berisi masing-masing closure dan terus ngirimin si job ini menelusuri ke dalem channelnyaSehabis kita selesai kelar bikin (creating) instance dari sebuah Job yang baru yang
berbekalkan closure yang kebetulan kita raup (get) dan kita panen dari parameter di fungsi execute ini,
kita akhirnya ngirimin si job ini merosot lurus menuju saluran (channel) komunikasi nglewatin sending end
(ujung buat ngirim) si sender ini. Di situ kita itu emang manggil unwrap pas lagi manggil method send buat
antisipasi seandainya pengirimannya itu entah kenapa jadi gagal (fails). Hal macam error ini
sebenernya emang masih ada peluang kejadian (might happen), apalagi kalau misalnya contohnya,
kita itu nyetop secara paksa (stop) biar semua threads kita ini berhenti melakukan semua pekerjaan dan ngejalanin eksekusinya,
yang mana artinya si ujung penerimanya (receiving end) tersebut udah pasti juga ikutan
mandeg (stopped) alias udah tidak nerima pesen (messages) baru lagi. Sampai dengan menit saat
ini sih, emang jujurnya kita ini masih belum nyiapin fitur apa pun buat bisa
berhentiin (stop) segerombolan threads ini dari ngejalanin eksekusi programnya: threads
yang udah jalan milik kita ini masih bakal terus melenggang jalan narik ngegas pol gas terus beroperasi
(continue executing) sekuat lama umur (as long as) pool milik kita ini juga masih dibiarin buat tetep exist.
Satu-satunya alasan kenapa kita dengan berani masang (use) fitur unwrap di situ adalah karena
berbekal jaminan (know) dari diri kita sendiri kalau skenario kemungkinan gagalnya (failure case) ini sebenernya emang
benar-benar secara harfiah tidak bakal pernah terwujud kejadian sama sekali, tapi ya sayangnya si
compiler ini mana ngerti kalau di kenyataannya kelakuan ini itu tidak bakal pernah berbuat salah macam itu (doesn’t know that).
Tapi kita ini juga belum benar-benar beres juga nih kerjaannya! Di dalam bagian Worker itu, si closure
kepunyaan kita ini yang tadinya dioper ke dalem thread::spawn kan emang tugas utamanya dia itu cuma
lagi ngerujuk (meminjam referensi/references) doang kan ke si ujung penerima (receiving end) milik si saluran itu.
Padahal yang bener-bener kita harapkan di sini adalah, kita ngebutuhin sekali supaya
si closure ini benar-benar bisa berputar dan berkeliling di dalam loop buat selama-lamanya (forever),
nanyain dan malakin (asking) si ujung penerima channel ini mulu nanyain apaan dia ini lagi dapet kerjaan job
sambil setelahnya dia benar-benar ngejalanin isi dari si pekerjaan (running the job) ini langsung abis dia kebetulan berhasil
ngedapetin satu job. Makanya, mari kita lakuin rombakan perubahan barusan yang ada kelihatan nyempil di
Listing 21-20 tersebut ke dalam dalem fungsi Worker::new ini.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}Worker tersebutDi sini, hal pertama yang kita lakuin duluan itu adalah manggil lock dari si receiver
tadi tujuannya buat mengakuisisi atau merebut dan narik status si mutex ini, dan
baru abis narik status aman itu barulah kita berani manggil unwrap biar nantinya kodenya bisa otomatis njerit panik (panic)
atas segala bentukan macam rupa kesalahan (errors) yang mungkin keluar. Merebut (Acquiring) status kunci
(lock) itu pada aslinya sangat mungkin berpeluang buat jadi gagal berantakan kalau ternyata di balik bayangan layar,
kondisi status (state) dari dalem the mutex-nya ini udah keburu kejebak berubah menjadi beracun keracunan (poisoned state).
Kondisi beracun ini bisa terjadi kalau ternyata ada utas (thread) yang lainnya yang entah
salah apa dari mana dia tiba-tiba malahan udah milih panik meledak berantakan (panicked) tapi saat itu dia ini masih ngantongin status
kuncinya (holding the lock) ini alih-alih melepaskan kunci tersebut (releasing the lock) sebelum matinya.
Kalau kita lagi apes kejebak situasi (situation) yang semacam begini, maka tindakan manggil method unwrap biar si utasan (thread) kita
yang ini juga ikut-ikutan njerit panik ikutan hancur adalah langkah jalur yang emang diakui emang udah bener (correct action)
buat dikerjain. Silakan santai aja luangin bebasin dan rombak sendiri ini semua ngubah (change) bentuk unwrap ini
biar jadinya makek format dari expect yang disisipin makek pesan galat kesalahan (error message)
yang mungkin agak lebih masuk kerasa ngena bunyinya gampang dimengerti sama kuping (meaningful to you)
sendiri aja tidak masalah.
Kalau ternyata kita mulus-mulus aja sukses mulus kebagian ngunci gembok (got the lock) ke gembok mutex ini,
maka baru di saat itu kita bisa ikutan berani nekat manggil si perintah recv biar bisa nangkep nerima (receive) satu balok Job (Pekerjaan) dari si channel saluran komunikasi pipa tersebut.
Sebuah sematan paku tempelan unwrap yang nangkring di bagian pucuk paling terakhir ini
bener-bener membantu kita berjalan tegar dan melewati (moves past) nerjang segala bentuk halangan segala kelakuan aneh error macam apa aja yang
kebetulan mungkin aja tetiba nongol dari sini, error model macem ginian bisa aja pada nongol mencuat (occur) umpamanya di mana si utas thread
yang mana lagi sibuk-sibuknya naruh (holding) megangin ujung sender-nya ini ternyata tetiba udah keburu modar matikan paksa nutup jalan (shut down) ngedahuluin si penerimanya.
Yang ini sebenernya jalan nalar kerjanya emang nyerempet mirip-mirip (similar) nian loh percis dengan cara
fungsi metode send yang mana bakal pasti berontak ngebalik (returns) pesan Err semisal si utas sang receiver-nya yang ini malah mati berantakan nutup mendadak dari depan.
Panggilan metode lurus menuju si baris recv ini sifatnya membikin laju proses berhentinya kodenya jadi terblokir nunggu (blocks), makanya ini
menimbulkan efek di mana kalau andai kata aja ternyata eh emang belum nongol dateng kerjaan job satu biji doang pun di depan matanya saat itu (no job yet), maka di ujung akhir-akhirnya ini sih utas *thread yang lagi kerja saat ini (current thread) jadinya ya mau gimanapun bakal terus bengong nganggur nungguin nge-drop nunggu nunggu anteng (wait) sampe sebuah job bener-bener kelar udah nyampe hadir keluar di depannya. Struct si Mutex<T> pada intinya inilah si sosok kuncian yang menjamin mastiin pasti (ensures) ke semuanya ke kita kalau emang disisihkan pada sebuah jeda satu waktu yang spesifik
tertentu (at a time) bener-bener bakal pasti cuma bakal disidang dan diberika akses ke cuma satu doang thread punya Worker (only one Worker thread) yang dikasih dan dibolehin ijin buat nyoba manggil-manggil mau request nanyain apaan ada job (pekerjaan)
atau gaknya ke channel tadi.
Tadaa, selamat loh! Thread pool bikinan kita pada detik jaman tulisan ini dibikin sebenernya udah pada posisi sukses jalan ngacir lanjay ngebut dengan mulus (working state)!
Majuin cobain aja suruh tes dengan nge-running cargo run sekalian lu buat dikit requests ngetes jalannya juga ya:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
warning: field `workers` is never read
--> src/lib.rs:7:5
|
6 | pub struct ThreadPool {
| ---------- field in this struct
7 | workers: Vec<Worker>,
| ^^^^^^^
|
= note: `#[warn(dead_code)]` on by default
warning: fields `id` and `thread` are never read
--> src/lib.rs:48:5
|
47 | struct Worker {
| ------ fields in this struct
48 | id: usize,
| ^^
49 | thread: thread::JoinHandle<()>,
| ^^^^^^
warning: `hello` (lib) generated 2 warnings
Finished `dev` profile [unoptimized + debuginfo] target(s) in 4.91s
Running `target/debug/hello`
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Sukses mulus (Success)! Kita sekarang ngenalin kalau kita emang akhirnya sukses benar-benar punyain sebuah bentuk sejati dari sebuah thread pool murni yang mengeksekusi koneksi-koneksi yang singgah dari depan ini ngejalanin proses eksekusinya berbarengan asinkron tidak usah gantian satu-satu lgi secara sinkron (asynchronously). Emang kenyataannya kagak bakal pernah (never) ada riwayat kejadian di mana lebih dari jumlah sekian empet (four) potong threads ini di-lahirkan (created) pas lagi ngejalanin kode di depannya ini. Jaminan ini ngegaransi ke seisi segenap bangsa sistem (our system) kita ke semuanya tidak bakal pernah sekalipun ikutan panik mabuk jadi kepanasan (overloaded) bahkan bilamana semisal jikalau aja mesin server kita itu dikeroyok dikirim hujan dideras rentetan gelombang panah ngerima request super bertubi-tubi seabreg rupa yang pada berjejer dateng masuk (receives a lot of requests). Andaikata emang bener lho kita sampe sengaja jahil iseng-iseng kita nge-request secara spesifik (make a request) ke alamat lintasan jalur (path) tujuan kita ini di /sleep, maka server kita yang satu ini emang bakal teteupan tetep tegak berdiri bisa santai terus dengan gampangnya bisa ngelayanin ngeresponi (serve) panggilan para rentetan requests yang lainnya gara-gara dia tinggal nyuruh thread Worker lain yang emang dari kemaren emang nganggur buat sekalian ikutan terjun ngerjain bantu manggil fungsi tasks tersebut.
Catatan: Andai kata lu maksa nekat ngebuka path rute link URL tujuan yang ditaruh di dalem rute khusus jebakan si /sleep ini di dalem banyakan (multiple) jajaran tumpukan sekian puluhan (multiple) browser windows secara bareng-bareng langsung sekaligus jebred dalam waktu sekerdipan mata bebarengan (simultaneously), kita mungkina aja kelewatan bingung kepancing ngerasa panik dan nyangka kok kelihatannya dia ngeladenin ngememuat nge-load-nya ganti-gantian dengan selang pelan durasi santai (time intervals) per five-second (selang lima deik) sekali padahal kita udah makek pool multithread. Aslinya benar-benar sebagian (some) tipe dari program jenis peramban web browsers jaman di luar sekarang (today) emang emang punya perilaku ngeksekusi kelakuan ganjil ngerapihin nge-barisin numpuk antrian deretan dari satu deretan requests-nya yang asalnya identik dan modelnya bener-bener punya endpoint rute kembar sama persis ganjil secara sengaja satu per satu berurut bergantian (sequentially), ya murni semata-mata itu gara-gara (reasons) sekadar buat tujuan urusan nge-caching. Intinya pembatasan kebodohan macem (limitation) begini ini mah samsek seutuhnya tidak diakibatin bersumber murni disebabkan (not caused by) ulah dari kelakuan kinerja web server yang kita lagi pada bikin ini.
Saat-saat momen sekarang yang ini emang kelihatannya pas rasanya emang waktu jeda yang enak (good time)
buat minggir mingser ambil napas ngaso sebentar ngecoba ngebayangin nyimak (pause and consider) ngebandingin
gimanakah jeroannya raut muka model rancangan tatanan bentukan kode-kodean barisan yang pada nangkring mentereng
sedari di dalem bingkai bingkisan kotak Listings 21-18, 21-19, dan ujungnya juga di selipan 21-20 ini
seumpamanya bentuk mereka itu dibikin pada agak berbeda sedikit andaikata kta beralih ngeganti jalan pikir buat emang lebih
memilih (using) tatanan asinkron bernama futures ketimbang bertahan kukuh cuma memakai fungsional model closure doang buat emang
membedah ngerjain mengeksekusi semua rupa tugas (work) tersebut. Bagian tipe-tipe spesifik manakah (what types) di sana yang pada
bakal ngalamin ubah ganti baju (would change)? Kayak manakah (how) emangnya signatures aslinya dari method (method signatures)-nya ini
kudu ikutan berubah drastis diganti-ganti mingser ke sana-kemari, seandainya emang emang perlu perombakan bener-bener (if at all)? Sisi pinggiran belah pecahan (parts of the code) manakah sih
yang bakal tetep dibiarin aman bertahan (stay) anteng kagak perlu ikutan ngalamin diobok-obok perubahan (the same)?
Abis panjang lebar berpuas-puas dirimu beres nuntasin masa masa ngulik ngebaca bahan di pelajaran soal tata krama kelakuan dari jenis gubahan struktur kelakuan loop dari bentuk model while let ini yang kita kulik balik pas ngerampungin bab-bab awal di antara Bab 17 dan sembari selip di tengah-tengahnya Bab 19 pula, otak di kepala dirimu barangkali mulai berbisik kepikiran lari membatin (you might be wondering) kenapa yak pantesan kok kita nggak langsung main sabet milih aja buat mutusin secara kilat nekat naruh masang serangkaian urutan kode eksekusi milik utas thread khusus si Worker kita (Worker thread code) yang seolah nampak rupa cantiknya kayak yang sempet ngintip kepajang di dalem pajangan galeri Listing 21-21.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
while let Ok(job) = receiver.lock().unwrap().recv() {
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}Worker::new yang coba-coba ngandelin while letJujur emang barisan rombongan susunan set perabot alat tempur kode-kodean ini mah emang aslinya (this code compiles and runs) pantes sukses bisa di-compile lalu berhasil sukses diajak buat running nyala-nyala aja aslinya asalkan dipanggil mah tanpa cacat, akan tetapi (but) sayangnya kelakuannya dia tidak bakal sanggup membikin lalu menyetorkan membuahkan asilnya tingkah prilaku eksekusi pola ngantri tata perlintasan multi threading yang aslinya sembenernya emang jujur jadi inceran idam-idaman (desired threading behavior) sasaran awal milik hajat (desired) diri kita: gara-gara ujung-ujungnya ya ntar sebuah request yang super lelet lambat (a slow request) jalannya bakal cuman ngehasilkan requests yang berentet di antrean lain di belakangnya yang tetep ngadat mandek mandeg antri merana kudu terpaksa harus disuruh wait menunggu dan antri ngurut memanjang barisan kebagian jatah jadwal biar mereka bisa dieksekusi dikelarin dibereskan dan diproses (processed). Perkara alasan dibalik reason kejanggalan ginian ini tergolong ada sedari kelakuan halus subtle: bahwa sesungguhnya susunan wujud si struct Mutex ini emang takditakdirkan emang tidak dikasih public method (metode publik) khusus sengaja dikasih nama panggilan buat fitur nge-unlock karena nyatanya status penguasa kunci miliknya kepemilikan jatah buat kuncian rahasia tersebut ini aslinya udah emang based on terikat mutlak dikunci ditentuin dari seberapa panjang seberapa bentar siklus riwayat hidup umur lifetime umurnya si benda keramat bertipe perlindungan yang menyandang identitas MutexGuard<T> yang mana sosok tersebut disisipkan rapi di perut selimut isi LockResult<MutexGuardlock buat dia setorkan ngeluarin dia (returns) pas selesai beres dia dipanggil beroperasi jalan. Menjelang masa kompilasi (at compile time), sosok mandor tukang sensor pinjeman borrow checker inilah yang selanjutnya ganti berjaga bakal dengan telitinya bisa memelototi lalu memberlakukan narapain menegakkan menembakkan enforce the rule maklumat seputar tata kaidah yang ngegarisbawahi kalau setiap butir selongsong resource (sumber daya) yang tadinya ketat diselimuti diborgol ketat (guarded) diawasi pelindungan di belakang benteng pelindung sebuah palang gembok berjenis Mutex itu niscaya haram statusnya diharamkan (cannot be accessed) sama sekali dilarang terjamah alias tidak bakal mempan dibolehin buat bisa diutak-atik (diakses) oleh siapapun pun kalau seumpamanya status kita saat di kejadian eksekusi saat itu kondisinya lagi belom emang kita megang lalu punya si lock stempel kuncinya ini di tangan (unless we hold the lock). Masalahnya adalah, penerapan (implementation) kode yang bergaya ngasal semacam ini berisiko nimbul-nimbulin bahaya efek di mana wujud kuncian (lock) dari yang mestinya diserahin kembali ini ternyata masih dipaksa kudu bertahan kepeluk tertahan kepegang erat-erat tertahan di genggaman (being held) jauh memakan durasi yang kepanjangan sangat jauh di luar dari maksud jadwal normal target awal selesainya tugas aslinya seandainya (intended if we aren’t mindful) andaikata otak pikiran kita belom ngerasa gih hati-hati nyadari seputaran mindful ngeh dan perduli buat memandang mikirin masalah masa waktu jeda lifetime (lama waktu) dari MutexGuard
Sepetak bentuk kodingan susunan naskah dari balok kode di balikan dalem ruang gubahan Listing 21-20 yang menumpukan tumpuannya di dalam bentuk susunan gaya pemakaian dari format pemanggilan dari perkenalan lajur baris berupa panggilan let job = receiver.lock().unwrap().recv().unwrap(); benar-benar jalan bekerja karena aslinya dengan membiasakan manggil (with let), rupa jenis semua ragam dari kumpulan serpihan serentetan aneka serabut serangkaian sosok rentetan sekian harga biji temporary values nilai-nilai angka dadakan instan bayangan yang kebetulan aja sementara disisipin (temporary values) dipakai sengaja dipakai di daleman seonggok kumpulan bongkahan expression tersebut yang ada bertumpuk mojok mentereng ngendon mangkal terparkir mejeng di perbatasan tapal batas perlintasan di ruas sisi lajur paling right-hand side pojokan sebelah barisan pinggiran sisi seberang belahan sisi arah sebelah kanannya dari batasan silang palang lintasan lambang sama dengan (the equal sign) bakal emang nasibnya dengan sadar seketika cepatnya dalam detik waktu itu juga (immediately dropped) dimusnahin diputus di-drop hilang tak bersisa ditiadakan pas waktu (when) persis saat barisan deretan panggilan milik sang let statement ini nemuin garis ajalnya dan kelar nyampe berakhir tamat ngakhirin garis ends nasib eksekusinya. Beda malang apes nasib halnya, si konstruksi kelakuan si panggilan buat while let (dan tak pelak kelakuan yang kembar sama juga melekat pada panggilan buat deretan panggilan di struktur perlintasan buat konstruksi barisan kelakuan if let dan juga konstruksi yang ngerujuk seputaran kelakuan match) sifat kodrat aslinya pantang dan sejatinya anti dan juga (does not) tidak pernah sekalipun membuang secara sepihak memusnahkan (drop) barang bawaannya beruba wujud barang rakitan nilai-nilai aneka rentetan sosok figur temporary values angka naskah serpihan bawaan serba sementaranya (temporary values) sisaan tersebut sebelum rentetan eksekusinya ini benar-benar merayap tuntas tiba berjalan sampai ngejejak sukses nutup berhasil (until the end of) merambat tiba menapaki penghujung purna tutup gawang palang blok kodenya (the associated block). Merujuk narasi skenario paparan kejadian malang perbandingan percontohan yang tergambar pas nongkrong mojok di sela daleman sketsa yang terbingkai rapi di sela Listing 21-21 ini tadi, sosok batang kuncian yang ditugasin gembok gerbang (lock) tetep ajeg kepaksa bakal awet mangkal terkunci (remains held) nangkring mengunci selagi sepanjang (for the duration of) di sepanjang rentetan durasi berlangsungnya kelakuan waktu (the call to) lamanya rentang periode pas fungsi tugas sang job() tersebut lagi ngejalanin rutinitas gawang di dalam masa rutinitasnya buat menunaikan (call to) ngejalanin seisi jeroan badan pemanggilan tugas kerjanya tsb., niscaya memunculkan satu hal arti rupa artian yang maknanya adalah emang pada saat detik-detik nasib gembok lagi kehalang nutup rupa begini maka segenap sekompi pasukan komplotan deretan gerombolan Worker instances yang other (para punggawa lainnya) bakal pastinya pada terpojok tak kan sanggup alias buntu dilarang masuk narik cannot receive jobs alias tidak ada satu pun mereka yang bakal sukses nerima narik sisa gilir antrian tugas sisa deretan job sisanya tsb.
Graceful Shutdown (Mati Secara Anggun) dan Cleanup (Bersih-bersih)
Graceful Shutdown (Mati Secara Anggun) dan Cleanup (Bersih-bersih)
Kode di Listing 21-20 itu benar-benar udah merespons ke requests secara asinkron (asynchronously) melalui
penggunaan thread pool, sesuai sama apa yang kita rencanakan (intended). Tapi kita ngedapetin
beberapa pesan peringatan (warnings) soal fields workers, id, dan thread
yang nampaknya tidak kita pakai secara langsung, yang mana ngingetin (reminds) kita
kalau kita ini belum ngelakuin acara bersih-bersih (cleaning up) apa pun. Pas kita
memakai metode pencet tombol ctrl-C yang agak bar-bar (less elegant)
buat ngehentiin (halt) eksekusi si main thread, semua threads lain di dalamnya juga bakal
dihentiin seketika itu juga (immediately), biarpun mereka posisinya saat itu lagi di tengah-tengah
nugas (in the middle of) ngelayanin sebuah request.
Maka dari itu selanjutnya, kita bakal mengimplementasikan trait Drop buat manggil join
pada masing-masing threads di dalam pool tersebut supaya mereka bisa nyelesaiin
dulu (finish) requests yang lagi mereka kerjain sebelum akhirnya bener-bener ditutup (closing).
Baru deh setelah itu kita bakal mengimplementasikan sebuah cara buat ngasih tahu para threads
kalau mereka seharusnya berhenti nerima requests baru lalu mematikan diri (shut down).
Buat ngelihat aksi langsung dari kode ini, kita bakal memodifikasi server kita supaya dia
cuma nerima maksimal dua buah requests aja sebelum akhirnya secara anggun (gracefully)
mematikan semua proses di thread pool-nya.
Satu hal yang perlu diperhatiin (to notice) seiringan kita jalan: tidak ada satu pun dari proses ini yang bakal berdampak (affects) sama bagian-bagian kode yang tugasnya mengeksekusi (executing) closures, jadi segala hal yang ada di sini bakal tetep sama persis andaikata kita ini lagi memakai sebuah thread pool buat sebuah runtime async.
Mengimplementasikan Trait Drop pada ThreadPool
Mari kita mulai dengan mengimplementasikan Drop pada thread pool kita.
Pas si pool tersebut di-drop, seharusnya semua threads kita ini di-join (digabungin)
buat ngebuktiin dan mastiin (make sure) kalau mereka semua udah beres (finish) ngerjain
kerjaan mereka. Listing 21-22 nunjukin percobaan perdana (first attempt) buat bikin
implementasi Drop ini; tapi kode ini masih belum bakal jalan lho ya.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}Pertama-tama kita melakukan perulangan (loop) ngelewatin masing-masing elemen di workers
kepunyaan si thread pool. Kita memakai referensi &mut di sini karena self itu sendiri
kan emang sebuah referensi mutable (bisa diubah), dan kita juga perlu bisa ngubah (mutate)
si variabel worker. Buat masing-masing worker, kita mencetak sebuah pesan yang ngasih tahu
kalau instance spesifik Worker ini tuh lagi bersiap dimatikan (shutting down), dan baru
setelahnya kita manggil join pada nilai thread yang dimiliki instance Worker
tersebut. Kalau pemanggilan ke join ini ternyata gagal (fails), kita memakai unwrap
buat maksa Rust jadi panic dan masuk ke fase mati secara tidak anggun (ungraceful shutdown).
Ini dia error yang bakal kita dapat pas kita mencoba buat men-compile kode ini:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0507]: cannot move out of `worker.thread` which is behind a mutable reference
--> src/lib.rs:52:13
|
52 | worker.thread.join().unwrap();
| ^^^^^^^^^^^^^ ------ `worker.thread` moved due to this method call
| |
| move occurs because `worker.thread` has type `JoinHandle<()>`, which does not implement the `Copy` trait
|
note: `JoinHandle::<T>::join` takes ownership of the receiver `self`, which moves `worker.thread`
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/std/src/thread/mod.rs:1921:17
For more information about this error, try `rustc --explain E0507`.
error: could not compile `hello` (lib) due to 1 previous error
Pesan error ini ngasih tahu kita kalau kita itu tidak bisa manggil join gara-gara kita cuma
punya sebuah pinjaman mutable (mutable borrow) dari masing-masing worker sedangkan si
join ini mengambil hak kepemilikan (ownership) dari argumennya. Buat memecahkan
(solve) isu ini, kita perlu buat mindahin (move) si nilai thread tersebut keluar dari
instance Worker yang tadinya nge-hak miliki (owns) si thread itu supaya si
join bisa narik memakan (consume) thread tersebut. Salah satu cara buat melakukan ini
adalah dengan ngambil pendekatan (approach) yang sama kayak yang pernah kita lakuin di
Listing 18-15. Kalau si Worker ini tadinya nampung Option<thread::JoinHandle<()>>,
kita bisa aja manggil method take pada nilai Option tersebut buat mindahin (move) nilai
aslinya dari varian Some lalu ninggalin sebuah varian None buat menempati posisinya
(in its place). Dengan kata lain, sebuah Worker yang posisinya lagi jalan (running) bakal
punya sebuah varian Some di dalam thread, dan pas kita pengen ngebersihin (clean up)
sebuah Worker, kita bakal ngeganti si Some jadi None sehingga si Worker ini
tidak bakal punya thread buat dijalanin.
Namun masalahnya, momen di mana proses ini itu dibutuhkan (come up) satu-satunya cuma
terjadi saat kita lagi nge-drop si Worker aja kan. Konsekuensinya sebagai ganti rugi
(in exchange), kita jadinya mesti terus-terusan berurusan (deal with) sama tipe
Option<thread::JoinHandle<()>> di mana pun kita lagi nyoba ngakses worker.thread.
Penulisan bahasa Rust yang idiomatik itu emang cukup sering sekali (quite a bit) memakai
Option, tapi pas kita mulai nemuin diri kita lagi asik ngebungkusin (wrapping) sesuatu yang mana
padahal kita udah tahu (know) nilai itu tuh selalu ada dan eksis (present) ke dalam
sebuah Option cuma murni dijadiin sekadar jalan pintas buat ngakalin (workaround) hal macem
gini, maka ini merupakan tanda ide yang bagus buat mulai nyari pendekatan alternatif
(alternative approaches) supaya bisa ngebikin kode kita lebih rapi (cleaner) dan tidak
gampang rawan error (less error-prone).
Di kasus yang ini, sebenernya ada jalan alternatif yang lebih oke (better alternative):
yaitu method Vec::drain. Method ini menerima sebuah parameter jarak (range parameter) buat
menentukan items mana aja yang mau dihilangkan dari dalam vector tersebut lalu dia bakal
mengembalikan (returns) sebuah iterator dari item-item yang ditarik itu. Dengan memberikan
sintaks range .. kita bakal mengosongkan dan menghilangkan semua (every) nilai dari vector tersebut.
Jadi kita perlu meng-update implementasi drop untuk ThreadPool supaya jadi kayak gini:
#![allow(unused)]
fn main() {
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in self.workers.drain(..) {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}
}Kode ini ngeberesin dan nyelesein pesan error compiler tadi tanpa perlu adanya (require)
perubahan lain lagi ke dalem kode kita. Perhatikan kalau, karena drop bisa aja dipanggil pas
lagi masa-masa terjadi kepanikan (panicking), si unwrap ini juga bisa aja tiba-tiba ikutan panic
yang mana akhirnya nyebabin kepanikan tumpuk ganda (double panic), yang mana bakal langsung
membikin programnya crash (rusak) dan secara terpaksa ngakhirin semua proses pembersihan
(cleanup) yang lagi berjalan. Buat ukuran program contoh kayak gini, tindakan panic ini sah-sah aja (fine),
tapi hal kayak gini ya tidak disarankan (isn’t recommended) lho buat kode di level produksi.
Mengirim Sinyal ke Threads Supaya Berhenti Mendengarkan Jobs (Tugas) Baru
Dengan serangkaian perubahan yang udah kita bikin barusan, kode kita sekarang udah bisa
sukses di-compile tanpa ngeluarin peringatan apa-apa. Namun, kabar buruknya adalah
kalau kode ini itu masih belum (doesn’t function) berjalan pakai cara yang kita harepin. Kunci permasalahannya ada di
logika yang ada di dalem closures yang lagi dijalanin (run by) sama threads kepunyaan
instances si Worker: saat ini, kita emang udah manggil join, tapi hal itu tidak
bakal bisa nutup mematikan (shut down) si threads ini lho, soalnya mereka itu pada asyik
berputar (loop) nyari kerjaan (looking for jobs) buat selama-lamanya (forever). Kalau
kita coba buat nge-drop si ThreadPool kita ini pakai implementasi drop kita yang
sekarang, main thread-nya bakal malah ikutan mandek keblokir (block forever), diam selamanya nungguin thread
yang pertama itu kelar (finish) yang mana tidak bakal bisa kelar.
Buat mbetulin (fix) masalah ini, kita perlu ngebikin satu ubahan (change) di dalam implementasi drop buat ThreadPool
dan abis itu juga butuh satu ubahan di dalem perulangan (loop) si Worker.
Pertama-tama kita bakal ngubah implementasi drop pada ThreadPool supaya dia secara eksplisit nge-drop
si sender (pengirim) ini sebelum dia nungguin para threads-nya pada kelar jalan. Listing 21-23
nunjukin rupa ubahan-ubahan ke ThreadPool tersebut buat secara eksplisit nge-drop sender. Tidak kayak
yang terjadi di thread, di sini kita emang benar-benar butuh (do need) memakai
Option biar kita bisa memindahkan (move) variabel sender keluar dari
ThreadPool dengan memanggil Option::take.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
// --snip--
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in self.workers.drain(..) {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}sender sebelum nge-join para threads WorkerTindakan men-drop (dropping) sender ini otomatis bakal nutup (closes) channel-nya, yang mana mengindikasikan kalau
tidak bakal ada lagi pesan (messages) baru yang bakal dikirimin. Saat momen itu benar-benar terjadi,
semua pemanggilan (calls) ke recv yang lagi dikerjain sama instances si Worker di dalam infinite
loop (perulangan tiada henti)-nya bakal otomatis nge-return sebuah pesan error. Di Listing 21-24,
kita ngubah bagian perulangan Worker supaya dia mau keluar (exit the loop) dengan anggun (gracefully)
di dalam skenario kayak gitu (in that case), yang berarti threads-nya ini akhirnya benar-benar
bisa kelar (finish) pas implementasi drop milik ThreadPool manggil join
ke mereka-mereka semua.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in self.workers.drain(..) {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
}
});
Worker { id, thread }
}
}recv nge-return sebuah errorBuat bisa ngelihat sendiri aksi kode (code in action) ini benar-benar berjalan, mari kita modifikasi (modify) main
supaya dia ini cuma nerima batas (accept only) dua requests aja sebelum akhirnya dia nutup
(shutting down) si server-nya dengan anggun (gracefully), kayak yang ditunjukin di Listing 21-25.
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}kita pastinya sangat tidak mau ngarep (wouldn’t want) kalau sebuah web server betulan di dunia nyata tiba-tiba mati nutup sendiri (shut down) sesudah cuma ngelayanin dua buah requests doang. Tapi kan kode ini itu cuma murni (just demonstrates) dibikin buat pamer ngedemoin kalau kemampuan matikan proses secara anggun (graceful shutdown) dan fitur bersih-bersihnya (cleanup) emang benar-benar udah bisa kerja lancar beroperasi (in working order).
Method take ini aslinya udah didefinisikan secara bawaan di dalem trait Iterator
yang mana dia berfungsi ngebatesin (limits) iteration tersebut supaya paling banter (at most) dia
itu cuma muter buat ngerjain dua item pertama (first two items) doang. Terus, si ThreadPool ini jadinya
bakal terpaksa dihempaskan keluar dari scope (go out of scope) pada momen titik paling
ujung batas akhir dari fungsi main, dan otomatis implementasi fungsi drop miliknya bakal segera dioperasikan (will run).
Silakan nyalakan kembali (start) si server ini pakai instruksi cargo run, terus cobain bikin tiga (three) buah requests
masuk ke sana. Pemanggilan request yang ketiga ini harusnya langsung ngebentur pesan error (should error),
dan terus di dalem layar terminal kita itu kita kudu ngelihat tulisan keluaran (output)
yang lumayan kelihatan persis mirip-mirip (similar) kayak ini:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/hello`
Worker 0 got a job; executing.
Shutting down.
Shutting down worker 0
Worker 3 got a job; executing.
Worker 1 disconnected; shutting down.
Worker 2 disconnected; shutting down.
Worker 3 disconnected; shutting down.
Worker 0 disconnected; shutting down.
Shutting down worker 1
Shutting down worker 2
Shutting down worker 3
kita emang sangat mungkin ngelihat kalau rupa dari urutan-urutan (ordering) barisan teks Worker ID
dan tulisan pesannya yang nampil ke layar ini agak beda-beda tatanannya. Kita
bisa perhatiin dengan jelas (can see) gimana dalemnya proses cara kerja kode ini dari bacaan pesannya
(messages) tersebut: Instances si Worker urutan 0 dan 3 ternyata beruntung dapet
nyaplok ngerjain (got) kedua belah requests rentetan awal. Terus si server ini mulai ngadat berhenti dan ogah ngerima
(stopped accepting) adanya sambungan koneksi (connections) yang baru pas tepat habis selesai
ngurus koneksi yang ke-dua tadi, dan si implementasi metode Drop yang nempel pada si ThreadPool pun
langsung gas tancap jalan (starts executing) duluan padahal faktanya si Worker 3 aja malahan belom kelar nyalain (even starts)
pekerjaannya. Kejadian di-drop-nya (dropping) sender ini langsung tanpa tedeng aling-aling melepaskan putus (disconnects)
sambungan jembatan tali komunikasi ke semua penjuru instances si Worker
lalu lantang nyuruh ngomando ngasih tahu (tells) mereka biar pada mingser bubar barisan nutup layanan (shut down).
Tiap instances Worker masing-masing terus nyaut nge-print sebuah message saat tali
mereka terputus dilepas (disconnect), dan abis beres itu semua, si thread pool tadi gantian secara mandiri bergegas manggil
method join lurus dengan satu-satunya niat mau diem duduk setia menunggu (wait) supaya
setiap barisan satu per satu dari Worker thread kelar (finish) ngerampungin pekerjaannya.
Coba teliti merhatikan (notice) adanya satu aspek detail perlakuan (aspect) yang lumayan kerasa asik unik
(interesting) di balik serangkaian rentetan rupa spesifik proses eksekusi (execution) satu ini: di mana
si ThreadPool udah keburu kelar nge-drop si sender, dan bahkan sebelum sempet ada instances
Worker mana aja yang nangkep ngerima kode error (received an error), kita malahan udah ngebikin status program kita ini buat maksa nyoba nggabung
(join) ke Worker urutan 0. Waktu momen itu ya, si Worker 0 benar-benar belum ada dapetin sinyal kabar tangkepan error
apa-apa (not yet gotten an error) yang mana berasal dari tarikan recv, jadinya ya benar-benar wajar aja sih kalau si otak pusat jalan main thread-nya ini terpaksa mandeg macet diem nge-blok di jalan
(blocked), ngaso setia sembari nungguin si Worker 0 supaya ngerampungin pekerjaannya sampai tuntas (finish).
Eh pas lagi asik nunggu itu (In the meantime), si Worker 3 yang udah ketiban ngerima jatah mandat narik dapet
(received) satu butir kerjaan (a job) yang selanjutnya diikuti oleh riwayat sisa-sisa para threads sekaliannya yang ikutan kebagian serentak seragam dapet nerima cipratan pesan eror (error).
Terus nah pas begitu si Worker 0 kelar tuntas ngerjain jatah lapaknya (finished), si otak tengahnya (main thread) ini lantas lanjut ngecoba
nungguin antrean jejeran gerbong serombongan sisa komplotan (the rest) punggawa instances Worker ini biar pada cepetan (to finish) juga ikutan kelar nutup lapaknya. Pada pas
tibanya waktu masa (at that point) tersebut, eh ternyata semuanya tanpa basa-basi emang udah benar-benar pada
tuntas cabut ngeluarin diri (exited) berhamburan dari daleman siklus lingkar putaran (loops) rute hidup mereka itu lalu udah berhenti total dari segala aktivitas hidup (stopped).
Selamat ya (Congrats)! Kita bener-bener udah sanggup nyampe di titik purna ngerampungin project ini secara utuh (completed); kita sekarang ini udah sah punyain (have) sepenggal program web server murni kelas cetek mendasar (basic) yang aslinya juga udah bisa jalan gagah memanfaatkan pengerahan tenaga tatanan sekelompok balok (thread pool) demi sanggup ngeresponi secara sigap lalu melayani sambutan balik secara asinkron tak serentak (asynchronously). Kita udah sangat terbukti mampu benar-benar melancarkan (perform) atraksi sebuah tarian purna pemutusan nafas nyawa graceful shutdown terhadap si komponen server tersebut, yang mana benar-benar menuntaskan lalu ngebersihin angkat tuntas ngurus sisaan barang bongkaran kotoran riwayat sampah kelakuan (cleans up) riwayat para seantero rentetan threads di ruang bilik pool ini.
Nih ditaruh rupa segenap rincian barisan kode final seutuhnya (full code) secara utuh komplit di sini sebagai referensi pedoman (reference) ya:
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}Kita emang nyatanya masih sangat bisa sih buat ngerjain (could do more) lebih jauh dan memodifikasi lebih heboh hal-hal lainnya lagi di tempat ini lho! Kalau seumpamanya emang hasrat di hati emang kita kepengen (want to) buat sudi terus merutinkan niat maju ngelanjut (continue) nambahin memoles (enhancing) gubahan kerangka arsitektur project ini jadi makin keren lagi mantep ke depannya, ini di bawah disediain list segelintir barisan rupa corak deretan bayangan pencerahan curhatan ide (some ideas) racikan kreasi mantap:
- Lengkapin dan imbuhin rentetan sekelumit tambalan isi dari dokumentasi tambahan (more documentation) buat struct
ThreadPoolbeserta metode-metode rentetan methodpublicmiliknya juga ya. - Coba isengin rakit bikinin sisipin sederet rentetan program tes asinkron (tests) buat nguji kemantapan jalan kelakuan isi fungsionalitas (functionality) jeroan library-nya ini.
- Ganti rombak dan obrak-abrik rentetan pemanggilan wujud rupa
unwrapyang kelewat asal nabrak paksa njerit ini supaya berubah format menjadi bentukan rentetan taktik kelakuan pengurusan error (error handling) yang karakternya terasa sifat jauh lumayan lebih kokoh perkasa pantang rontok (robust). - Manfaatin fitur keberadaan balok struktur
ThreadPoolini untuk sengaja nyobain ngelaksanain rentetan panggilan tasks rutinitas yang bentukannya ini murni lain di luar formatnya sekadar menugas melayani (serving) serapan requests dari kancah rupa lalu-lalang aliran arus penjelajahan halaman dunia maya (web requests). - Sisihkan cari lirik bongkar-bongkar iseng nyari (Find) bentukan tipe produk paket rak buku kreasi buatan anak lain dari komunitas (thread pool crate) bertebaran liar pating mencelat lepas terpajang bebas melenggang kangkung rilis tebar nongol tersedia gratis pampang mejeng tayang di galeri pustaka etalase repositori perpustakaan lapak kerdus bebas gratis wadah pasar kumpulan crates.io sono terus pasang dan terapkan ngrakit lalu implement rupa susunan formasi wujud web server yang gaya alur kelakuan pola lagaknya miripin sebelas-dua-belas percis plek kayak (similar) gubahan hasil rancangan ini dengan murni nekat sekadar sepenuhnya murni berpatokan menunggang makek library produk kreasi bikinan orang laen the crate instead tersebut doang. Barulah (Then) setelah tuntasnya praktek pembuktian tsb. kelar disituasi tersebut silahkan monggo silakan (compare) coba banding-banding rupa rentetan kerangka rute API miliknya library itu sama wujud tingkat derajat kekuatan ketahanan banting kokoh (robustness) ketangguhan tahan uji banting tangguhnya punya dia dengan diukur diselidik secara adil membedakan dan aduin lurus dibandingin langsung dipajang sejajar teliti diseret ke hadapan dan disejajarkan ngebentur ke thread pool rakikan tangan pribadi asli mandiri punya yang baru kemaren udah sempet kita implement bikin bangun praktekin dari kemaren itu.
Ringkasan (Summary)
Mantap (Well done)! Kita udah berhasil nyampe tuntas tembus tamat nyentuh ujung akhir pucuk paling buntut sampul ujung (end) dari seri halaman buku ini! Kita semua dari diri kami di sini ini secara pribadi kepengen bener sekali pingin ngelempar sepatah kata berterima kasih sedalam-dalamnya buat ngaturin wujud hormat salam terima kasih tulus buat panjenengan-panjenengan semua yang udah ikhlas (thank you for) ngabisin waktu ngikut jalan jejer iring bersamai (joining) kita-kita nyusurin merambat rute panjang pelesiran perjalanan (tour) petualangan liburan berburu pesona Rust ini sedari titik garis pinggir batas mula dulu. Kini emang pastinya seutuhnya (now) kita ini udah sepenuhnya dirasa matang dan bener-bener dirasa dipastikan udah sangat siap sanggup sedia (ready to) langsung nge-gass terjang nerapin ngimplementasiin sendiri kreasi murni orisinil pribadi gagasan wujud gubahan deretan gagasan tatanan project rintisan (projects) program rill asli bikinan sendiri punya kita yang berbasis ngusung bendera teknologi sistem Rust lalu sekalian sudi dan rela rela buat ngeringanin naruh bantu campur turut menaruh campur tenaga ulur ngasih derma tangan ngebantu nambahin andil campur gotong berderma (help with) berkontribusi di gubahan wujud program garapan rintisan projects sumbangsih kreasi racikan buatan anak punggawa temen sejawat people’s projects (orang-orang) pahlawan tetangga sanak rupa saudara kita di sekitar sana. Harus dimasukin paksa (Keep in mind) diranap di simpen lekat ingatan tanam patri ke dalem nalar benak kepala ingat-ingat simpan resapin ya di ingatan (mind) dalem bawah sadar otak memori paten benak kepalamu ini andaikata (that) ini tuh sesungguhnya nyata terang bersinar nyata terang benderang niscaya terbentang terbentang mekar membentang subur emang masih menyisa (there is a) terhuni rupa sepetak jajaran luas gerombolan wadah kerumunan kelompok perhimpunan welcoming community (komunitas yang sangat terbuka nyambut ramah dan sedia hangat menjamu rupa tangan senyum terbuka gembira lebar dada tulus nyambut seneng asri hangat peluk) persaudaraan ikatan erat rupa serumpun bangsa perkumpulan perserikatan komplotan jejaring other Rustaceans (kalangan para pengabdi programmer pemuja aliran seiman setia pejuang pendekar kode penyuka aliran kepercayaan kasta Rust ksatria lain-lainnya sesama punggawa yang sealiran) lainnya di pelosok buana pelosok sana luar sekitar pojokan pelosok dunia sana ini yang tak ada bosannya tak kan bakal pernah nyerah sudi ikhlas niscaya aslinya emang would love to (pada seneng rela hati bakal cinta mati gemar nyenengin cinta ngebet pengen gemar dan hobi pake cinta bahagia hepi benar-benar girang tulus girang rela asyik seru sumringah demen kepingin riang berhati tulus bakal doyan bakal suka bakal sayang dan sangat girang sekali teramat rindu sangat ingin mau rela) ikhlas turun nolong bantu menyambut nyuapin nyuapin kasih (help you with) membina mandu memayungi mendampingin mandorin nyodor tangan mbopong mbimbing nolong kita-kita pada ikhlas terjun dan andil nimbrung bantuin mberesin dan nyikat beresin mengurus sedia ngadepin dan ngeberesin (any challenges) seberapa parah gawatnya semua aneka segudang rupa kendala aral ragam himpitan halang aneka lika rupa jurang duri kesulitan ujian badai cobaan halangan ragam perkara problema jerat tikungan batu cadas tantangan rintang terjalan problem himpitan perkara ganjalan segenap segala seberat sedempet serepot rupa kendala seisi sebentang onak seisi segala segenap (any) ragam masalah kendala benturan apa jua sekalipun belaka apa pun bentuknya rupa aja yang di jalan nanti kebetulan emang rupa nyata riil fakta nyatanya you encounter (kita tabrak kepentok dapati tabrak papasi bersua sandung hantam ketatap kebentur derita alami jumpa dapet tebas terjang lalui pergokin tempuh alami libas gilas temui tabrak lewati hantam rasakan langgar cicipin terjang tatap derita lintasi rasai cicip rasain hadapi cicip deritain hadapi hadapi) ke-tubruk kepentok bersua melintang terlintas nyandung hadap temui hadapi sandung kita di belantara sepanjang masa-masa pelayaran peruntungan jalan pendakian jalur petualang perjalanan lintas jalur rute jelajah ngeluyur (journey) pengembaraan karir kiprah rekam pelesiran perjalanan Rust (kancah rute perjalanan karir Rust) asuhan panjenengan kita seiring maju langkah laju menapaki jejak berjejak kita maju panjang menjejak merentas jauh berjalan ini di waktu ke detik harinya nanti menjejak (your Rust journey).
Lampiran
Bagian-bagian berikut berisi materi referensi yang mungkin berguna bagi Kita dalam perjalanan Rust Kita.
A - Kata Kunci (Keywords)
Lampiran A: Kata Kunci (Keywords)
Daftar berikut ini berisi keywords (kata kunci) yang direservasi buat penggunaan saat ini maupun penggunaan di masa depan oleh bahasa Rust. Oleh karena itu, kata-kata ini tidak bisa dipakai sebagai identifiers (pengidentifikasi) (terkecuali dipakai sebagai raw identifiers, seperti yang bakal kita obrolin di bagian “Raw Identifiers”). Identifiers adalah nama-nama fungsi, variabel, parameter, field struct, modul, crates, konstanta, macros, nilai statis, atribut, tipe, traits, atau lifetimes.
Keywords yang Saat Ini Dipakai
Berikut adalah daftar keywords yang saat ini sedang dipakai, beserta penjelasan fungsionalitasnya.
as: melakukan casting (pengubahan tipe) primitif, menghilangkan ambiguitas trait spesifik yang menampung sebuah item, atau mengganti nama item di dalam statementuseasync: mengembalikan sebuahFutureketimbang memblokir thread saat iniawait: menahan eksekusi sampai hasil dari sebuahFuturesudah siapbreak: keluar dari sebuah perulangan (loop) secara langsungconst: mendefinisikan item konstanta atau raw pointers konstantacontinue: lanjut ke iterasi perulangan berikutnyacrate: di dalam module path, ini merujuk ke akar crate (crate root)dyn: penyaluran dinamis (dynamic dispatch) ke sebuah trait objectelse: jalan alternatif (fallback) untuk struktur control flowifdanif letenum: mendefinisikan sebuah enumerasiextern: menautkan (link) sebuah fungsi atau variabel eksternalfalse: nilai literal salah (false) pada Booleanfn: mendefinisikan sebuah fungsi atau tipe dari function pointerfor: perulangan (loop) melewati item-item dari sebuah iterator, mengimplementasikan sebuah trait, atau menentukan higher-ranked lifetimeif: percabangan berdasarkan hasil dari ekspresi kondisionalimpl: mengimplementasikan fungsionalitas bawaan (inherent) atau fungsionalitas traitin: bagian dari sintaks perulanganforlet: mengikat (bind) sebuah variabelloop: perulangan (loop) tanpa syaratmatch: mencocokkan sebuah nilai terhadap patterns (pola-pola)mod: mendefinisikan sebuah modulmove: membuat closure mengambil alih kepemilikan (ownership) atas semua nilai yang ditangkapnya (captures)mut: menandakan mutabilitas pada referensi, raw pointers, atau pattern bindingspub: menandakan visibilitas publik pada field struct, blokimpl, atau modulref: mengikat berdasarkan referensireturn: mengembalikan nilai dari fungsiSelf: type alias untuk tipe yang sedang kita definisikan atau implementasikanself: subjek dari method atau modul saat inistatic: variabel global atau lifetime yang berlangsung selama keseluruhan eksekusi programstruct: mendefinisikan sebuah struktursuper: modul induk (parent module) dari modul saat initrait: mendefinisikan sebuah traittrue: nilai literal benar (true) pada Booleantype: mendefinisikan type alias atau associated typeunion: mendefinisikan union; hanya menjadi keyword saat dipakai di dalam deklarasi unionunsafe: menandakan kode, fungsi, trait, atau implementasi yang tidak amanuse: membawa symbols ke dalam scope; menentukan tangkapan pasti (precise captures) untuk batasan generic dan lifetimewhere: menandakan klausa yang membatasi (constrain) sebuah tipewhile: perulangan bersyarat berdasarkan hasil dari sebuah ekspresi
Keywords yang Direservasi buat Penggunaan di Masa Depan
Keywords berikut ini belum punya fungsionalitas apa pun, tapi sudah direservasi oleh Rust buat potensi pemakaian di masa depan:
abstractbecomeboxdofinalgenmacrooverrideprivtrytypeofunsizedvirtualyield
Raw Identifiers
Raw identifiers adalah sintaks yang memungkinkan kita memakai keywords di tempat-tempat
di mana mereka biasanya tidak diperbolehkan. Kita bisa memakai raw identifier dengan
menambahkan awalan r# pada sebuah keyword.
Misalnya, match itu adalah sebuah keyword. Kalau kita mencoba men-compile
fungsi berikut yang memakai match sebagai namanya:
Nama File: src/main.rs
fn match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}kita bakal mendapat error ini:
error: expected identifier, found keyword `match`
--> src/main.rs:4:4
|
4 | fn match(needle: &str, haystack: &str) -> bool {
| ^^^^^ expected identifier, found keyword
Error tersebut menunjukkan kalau kita tidak bisa memakai keyword match sebagai
identifikasi fungsi. Supaya bisa memakai match sebagai nama fungsi, kita perlu
memakai sintaks raw identifier, kayak gini:
Nama File: src/main.rs
fn r#match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}
fn main() {
assert!(r#match("foo", "foobar"));
}Kode ini bakal berhasil di-compile tanpa error. Perhatikan awalan r# pada
nama fungsi di bagian definisinya sekaligus di tempat fungsi tersebut dipanggil
di dalam main.
Raw identifiers membiarkan kita memakai kata apa pun sebagai identifier, bahkan
jika kata tersebut kebetulan adalah keyword yang direservasi. Hal ini ngasih
kita kebebasan lebih dalam memilih nama identifier, sekaligus memungkinkan kita
berintegrasi dengan program yang ditulis di bahasa lain di mana kata-kata
tersebut bukanlah keywords. Selain itu, raw identifiers juga memungkinkan
kita memakai libraries yang ditulis dalam edisi (edition) Rust yang berbeda
dari yang dipakai oleh crate kita. Misalnya, try bukanlah keyword di edisi 2015,
tapi dia menjadi keyword di edisi 2018, 2021, dan 2024. Kalau kita bergantung
pada sebuah library yang ditulis pakai edisi 2015 dan punya fungsi try, kita
harus memakai sintaks raw identifier, yaitu r#try di kasus ini, buat memanggil
fungsi tersebut dari kode kita di edisi-edisi yang lebih baru. Lihat Lampiran E
untuk informasi lebih lanjut tentang editions.
B - Operator dan Simbol
Lampiran B: Operator dan Simbol
Lampiran ini berisi glosarium (kamus ringkas) tentang sintaks Rust, termasuk operator dan simbol-simbol lain yang muncul sendirian maupun di dalam konteks seperti paths, generics, trait bounds, macros, atribut, komentar, tuples, dan tanda kurung.
Operator
Tabel B-1 berisi daftar operator di Rust, contoh gimana operator tersebut muncul di dalam konteksnya, penjelasan singkat, dan apakah operator tersebut bisa di-overload (overloadable) atau tidak. Kalau sebuah operator bisa di-overload, trait relevan yang dipakai buat nge-overload operator tersebut juga dicantumkan.
Tabel B-1: Operator
| Operator | Contoh | Penjelasan | Bisa Di-overload? |
|---|---|---|---|
! | ident!(...), ident!{...}, ident![...] | Ekspansi macro | |
! | !expr | Bitwise atau logical complement (komplemen logika) | Not |
!= | expr != expr | Perbandingan ketidaksamaan (nonequality) | PartialEq |
% | expr % expr | Sisa hasil bagi (remainder) aritmatika | Rem |
%= | var %= expr | Sisa hasil bagi aritmatika dan assignment (penugasan) | RemAssign |
& | &expr, &mut expr | Meminjam (Borrow) | |
& | &type, &mut type, &'a type, &'a mut type | Tipe pointer pinjaman (Borrowed pointer type) | |
& | expr & expr | Bitwise AND | BitAnd |
&= | var &= expr | Bitwise AND dan assignment | BitAndAssign |
&& | expr && expr | Logical AND (hubungan singkat/short-circuiting) | |
* | expr * expr | Perkalian aritmatika | Mul |
*= | var *= expr | Perkalian aritmatika dan assignment | MulAssign |
* | *expr | Dereference (Membuka rujukan) | Deref |
* | *const type, *mut type | Raw pointer | |
+ | trait + trait, 'a + trait | Batasan tipe gabungan (Compound type constraint) | |
+ | expr + expr | Penjumlahan aritmatika | Add |
+= | var += expr | Penjumlahan aritmatika dan assignment | AddAssign |
, | expr, expr | Pemisah argumen dan elemen | |
- | - expr | Negasi aritmatika | Neg |
- | expr - expr | Pengurangan aritmatika | Sub |
-= | var -= expr | Pengurangan aritmatika dan assignment | SubAssign |
-> | fn(...) -> type, |…| -> type | Tipe balasan (return type) fungsi dan closure | |
. | expr.ident | Akses ke field | |
. | `expr.ident(expr, … | + | trait + trait, 'a + trait |
+ | expr + expr | Penjumlahan aritmatika | Add |
+= | var += expr | Penjumlahan aritmatika dan assignment | AddAssign |
, | expr, expr | Pemisah argumen dan elemen | |
- | - expr | Negasi aritmatika | Neg |
- | expr - expr | Pengurangan aritmatika | Sub |
-= | var -= expr | Pengurangan aritmatika dan assignment | SubAssign |
-> | fn(...) -> type, |…| -> type | Tipe balasan (return type) fungsi dan closure | |
. | expr.ident | Akses ke field | |
. | `expr.ident(expr, … | ||
^ | expr ^ expr | Bitwise exclusive OR | BitXor |
^= | var ^= expr | Bitwise exclusive OR dan assignment | BitXorAssign |
| | pat | pat | Alternatif di pattern | |
| | expr | expr | Bitwise OR | BitOr |
|= | var |= expr | Bitwise OR dan assignment | BitOrAssign |
|| | expr || expr | Logical OR (hubungan singkat/short-circuiting) | |
? | expr? | Propagasi error |
Simbol Non-Operator
Tabel-tabel berikut ini berisi semua simbol yang tidak berfungsi sebagai operator; yang artinya, mereka tidak berperilaku seperti pemanggilan fungsi atau method.
Tabel B-2 menunjukkan simbol-simbol yang muncul sendirian dan valid dipakai di berbagai macam tempat.
Tabel B-2: Sintaks Berdiri Sendiri (Stand-Alone Syntax)
| Simbol | Penjelasan |
|---|---|
| `’ |
Tabel B-3 nunjukin simbol-simbol yang muncul di dalam konteks penulisan jalur (path) melewati hierarki modul menuju sebuah item.
Tabel B-3: Sintaks Terkait Path
Tabel B-4 nunjukin simbol-simbol yang muncul di konteks pemakaian parameter tipe generic.
Tabel B-4: Generics
Tabel B-5 menunjukkan simbol-simbol yang muncul di dalam konteks untuk membatasi (constraining) parameter tipe generik dengan trait bounds (batasan trait).
Tabel B-5: Batasan Trait Bound
| Simbol | Penjelasan |
|---|---|
T: U | Parameter generik T dibatasi pada tipe-tipe yang mengimplementasikan U |
T: 'a | Tipe generik T wajib berumur lebih panjang (outlive) dari lifetime 'a (artinya tipe tersebut tidak boleh secara transitif menampung referensi yang punya lifetime lebih pendek dari 'a) |
T: 'static | Tipe generik T tidak punya referensi pinjaman (borrowed references) selain referensi yang bersifat 'static |
'b: 'a | Lifetime generik 'b wajib berumur lebih panjang (outlive) dari lifetime 'a |
T: ?Sized | Mengizinkan parameter tipe generik untuk bisa berupa tipe yang berukuran dinamis (dynamically sized type) |
'a + trait, trait + trait | Batasan tipe gabungan (Compound type constraint) |
Tabel B-6 menunjukkan simbol-simbol yang muncul di konteks untuk memanggil atau mendefinisikan macros dan nentuin atribut buat sebuah item.
Tabel B-6: Macros dan Atribut
| Simbol | Penjelasan |
|---|---|
#[meta] | Atribut luar (Outer attribute) |
#![meta] | Atribut dalam (Inner attribute) |
$ident | Substitusi (penggantian) macro |
$ident:kind | Metavariabel macro |
$(...)... | Pengulangan macro (Macro repetition) |
ident!(...), ident!{...}, ident![...] | Pemanggilan (invocation) macro |
Tabel B-7 menunjukkan simbol-simbol yang berfungsi buat ngebikin komentar.
Tabel B-7: Komentar
| Simbol | Penjelasan |
|---|---|
// | Komentar baris |
//! | Komentar dokumentasi baris bagian dalam (Inner line doc comment) |
/// | Komentar dokumentasi baris bagian luar (Outer line doc comment) |
/*...*/ | Komentar blok (Block comment) |
/*!...*/ | Komentar dokumentasi blok bagian dalam (Inner block doc comment) |
/**...*/ | Komentar dokumentasi blok bagian luar (Outer block doc comment) |
Tabel B-8 nunjukin konteks di mana tanda kurung biasa (parentheses) dipakai.
Tabel B-8: Tanda Kurung Biasa (Parentheses)
| Simbol | Penjelasan |
|---|---|
() | Tuple kosong (dikenal juga dengan sebutan unit), baik literal maupun tipenya |
(expr) | Ekspresi yang dibungkus tanda kurung |
(expr,) | Ekspresi tuple dengan satu elemen tunggal |
(type,) | Tipe tuple dengan satu elemen tunggal |
(expr, ...) | Ekspresi tuple |
(type, ...) | Tipe tuple |
expr(expr, ...) | Ekspresi pemanggilan fungsi; juga dipakai buat menginisialisasi tuple structs dan varian dari tuple enum |
Tabel B-9 nunjukin konteks di mana kurung kurawal (curly brackets) dipakai.
Tabel B-9: Kurung Kurawal (Curly Brackets)
| Konteks | Penjelasan |
|---|---|
{...} | Ekspresi blok |
Type {...} | Literal struct |
Tabel B-10 nunjukin konteks di mana kurung siku (square brackets) dipakai.
Tabel B-10: Kurung Siku (Square Brackets)
| Konteks | Penjelasan |
|---|
C - Trait yang Bisa Di-derive
Lampiran C: Derivable Traits (Trait yang Bisa Di-derive)
Di berbagai tempat di buku ini, kita udah ngebahas atribut derive,
yang mana bisa kita sematkan ke definisi struct atau enum. Atribut derive
ini bakal menghasilkan kode yang mengimplementasikan (implement) sebuah trait
lengkap dengan implementasi default (bawaan)-nya pada tipe yang udah kita
anotasi (annotated) memakai sintaks derive tersebut.
Di lampiran ini, kita menyediakan referensi dari semua traits di standard library
yang mana bisa kita pakai dengan atribut derive. Masing-masing bagian mencakup:
- Operator dan method apa saja yang bakal difungsikan (enable) dengan nge-derive trait ini
- Apa saja yang dilakukan sama implementasi trait yang disediain oleh
derivetersebut - Apa makna (signifies) dari mengimplementasikan trait tersebut bagi tipe kita
- Persyaratan dan kondisi di mana kita dibolehkan atau tidak dibolehkan buat mengimplementasikan trait ini
- Contoh-contoh operasi yang mewajibkan adanya trait ini
Kalau kita pengen mendapatkan perilaku yang berbeda dari yang disediain sama atribut
derive, silakan cek dokumentasi standard library buat setiap trait
demi mendapatkan detail soal gimana caranya buat mengimplementasikan mereka secara manual.
Trait-trait yang terdaftar di sini adalah satu-satunya trait yang didefinisikan sama
standard library yang bisa diimplementasikan ke tipe kita memakai derive. Trait
lain yang didefinisikan di standard library itu tidak punya perilaku bawaan (default)
yang masuk akal (sensible), jadinya itu semua tergantung kita buat mengimplementasikannya
pakai cara yang paling masuk akal sejalan dengan apa yang mau kita capai.
Contoh dari sebuah trait yang tidak bisa di-derive adalah Display, yang mana
bertugas menangani format teks buat para pengguna akhir (end users). Kita harus
selalu mempertimbangkan cara yang paling pantas buat menampilkan sebuah tipe ke
end user. Bagian mana aja dari tipe tersebut yang boleh dilihat sama end user?
Bagian mana aja yang bakal mereka anggap relevan? Format data kayak gimana yang
bakal paling gampang dimengerti sama mereka? Compiler Rust tidak punya wawasan
(insight) kayak gini, jadinya dia tidak bisa menyediakan perilaku default
yang pantas buat kita.
Daftar derivable traits (trait yang bisa di-derive) yang disediain di
lampiran ini itu tidaklah komprehensif: libraries lain bisa aja ngimplementasiin
derive buat trait mereka sendiri, ngebikin daftar trait yang bisa kita pakai
dengan derive itu bener-bener jadi tanpa batas (open-ended). Mengimplementasikan
derive ini melibatkan pemakaian procedural macro, yang mana udah dibahas di
bagian “Custom derive Macros” di Bab 20.
Debug Buat Output Programmer
Trait Debug memfungsikan (enables) pemformatan debug di dalem format strings,
yang mana bisa kita indikasikan dengan nambahin sisipan :? ke dalem kurung
kurawal {} (placeholders).
Trait Debug ngasih kita kebebasan buat mencetak instances dari sebuah tipe buat
tujuan debugging (pemeriksaan error), supaya kita dan programmer lainnya yang
lagi makek tipe kita tersebut bisa menginspeksi instance tersebut pas ada di
satu titik tertentu di program pas lagi dieksekusi.
Trait Debug diwajibkan, misalnya, saat kita menggunakan macro assert_eq!. Macro ini akan mencetak nilai-nilai dari instances yang diberikan kepadanya sebagai argumen jika equality assertion gagal sehingga para programmer bisa melihat dengan jelas alasan mengapa kedua instance tersebut tidak sama.
PartialEq dan Eq Buat Perbandingan Kesamaan (Equality Comparisons)
Trait PartialEq ngasih kita kemungkinan buat ngebandingin instances dari sebuah tipe
buat mengecek apakah mereka itu sama atau tidak, dan juga memfungsikan pemakaian
operator == dan !=.
Nge-derive PartialEq bakal mengimplementasikan method eq. Pas PartialEq di-derive pada structs, dua instances dianggap sama hanya jika semua fields-nya sama, dan kedua instances itu bakal dianggap tidak sama kalau ada field apa pun yang tidak sama. Saat di-derive pada enums, masing-masing varian bakal dianggap sama dengan dirinya sendiri dan tidak sama dengan varian lainnya.
Trait PartialEq diwajibkan, misalnya, pas lagi memakai macro assert_eq!,
yang mana dia perlu bisa ngebandingin dua buah instances dari suatu tipe buat
ngelihat apakah mereka sama (equality).
Trait Eq tidak punya method apa-apa. Tujuannya adalah sekadar buat ngasih tanda
(signal) bahwa untuk setiap nilai dari tipe yang dianotasi, nilai itu dijamin pasti
sama dengan dirinya sendiri. Trait Eq ini cuma bisa diterapin (applied) ke tipe-tipe
yang juga mengimplementasikan PartialEq, walaupun tidak semua tipe yang
mengimplementasikan PartialEq itu otomatis bisa mengimplementasikan Eq. Salah satu
contohnya adalah pada tipe floating point number: implementasi perbandingan buat angka floating
point menyatakan kalau dua instances dari nilai not-a-number (NaN) itu tidaklah sama
(not equal) dengan satu sama lain.
Salah satu contoh kasus di mana Eq diwajibkan adalah untuk keys (kunci) di dalem
sebuah HashMap<K, V> supaya si HashMap<K, V> ini bisa ngebedain apakah dua keys
yang ada itu benar-benar sama (same) atau tidak.
PartialOrd dan Ord Buat Perbandingan Pengurutan (Ordering Comparisons)
Trait PartialOrd memungkinkan kita buat membandingkan instances dari suatu tipe buat
keperluan sorting (pengurutan). Sebuah tipe yang mengimplementasikan PartialOrd bisa
dipakai dengan operator <, >, <=, dan >=. Kita cuma bisa memakai atribut trait
PartialOrd ini ke tipe-tipe yang juga udah mengimplementasikan PartialEq.
Nge-derive PartialOrd bakal mengimplementasikan method partial_cmp, yang bakal
mengembalikan sebuah Option<Ordering> yang mana isinya bakal berupa None kalau
nilai-nilai yang dikasih itu ternyata gagal memproduksi sebuah urutan (ordering).
Contoh dari sebuah nilai yang gagal memproduksi urutan, sekalipun sebagian besar nilai di
tipe tersebut aslinya bisa dibandingin, adalah nilai not-a-number (NaN) pada floating
point. Manggil partial_cmp memakai angka floating-point mana pun dicampur dengan nilai
NaN floating-point pasti bakal mengembalikan None.
Saat di-derive pada structs, PartialOrd ngebandingin dua buah instances dengan
cara ngebandingin setiap nilai di dalam tiap fields-nya berdasarkan dengan urutan kemunculan
fields tersebut di saat struct-nya didefinisikan (struct definition). Saat
di-derive pada enums, varian-varian enum yang dideklarasikan (muncul) lebih awal di dalam
definisi enum bakal dianggap lebih kecil (less than) ketimbang varian-varian yang muncul belakangan.
Trait PartialOrd diwajibkan, misalnya, buat pemakaian method gen_range dari crate
rand yang tugasnya menghasilkan nilai acak di dalem jangkauan (range) yang
udah dispesifikasikan pakai ekspresi range.
Trait Ord ngasih tahu kita kalau, untuk sembarang dua nilai apa pun dari tipe yang udah
dianotasi, pastilah selalu ada sebuah sistem pengurutan yang valid yang bakal eksis (exist).
Trait Ord mengimplementasikan method cmp, yang mengembalikan sebuah tipe Ordering dan bukan
Option<Ordering> karena sebuah pengurutan yang valid itu bakal selalu dijamin selalu mungkin
buat terjadi. Kita cuma boleh naruh atribut trait Ord ke tipe yang mana juga udah
mengimplementasikan PartialOrd sekaligus Eq (dan perlu diingat kalau Eq juga mewajibkan adanya
PartialEq). Saat di-derive pada structs dan enums, method cmp bakal beroperasi (behaves)
pakai cara yang sama persis kayak apa yang dilakuin sama implementasi yang di-derive untuk method
partial_cmp yang ada di dalam PartialOrd.
Salah satu contoh pas Ord diwajibkan (required) adalah saat kita mau nyimpen nilai-nilai
ke dalam sebuah BTreeSet<T>, yaitu struktur data yang nyimpen data berdasarkan urutan sort (pengurutan)
dari nilai-nilai tersebut.
Clone dan Copy Buat Menduplikasi Nilai (Duplicating Values)
Trait Clone membiarkan kita secara eksplisit ngebikin deep copy (salinan mendalam) dari
sebuah nilai, dan proses duplikasi ini juga bisa jadi ngelibatin pengeksekusian
(running) kode apa pun dan penyalinan data heap. Silakan lihat bagian “Variabel dan
Data Berinteraksi dengan Clone”
di Bab 4 buat informasi lebih jauh soal Clone.
Nge-derive Clone bakal mengimplementasikan method clone, yang mana saat diimplementasikan
buat keseluruhan tipe, dia bakal memanggil clone juga secara beruntun pada masing-masing
komponen dari tipe tersebut. Artinya semua fields atau bagian nilai yang ada di tipe tersebut
harus mutlak udah mengimplementasikan Clone juga supaya tipe utamanya bisa nge-derive
Clone.
Sebuah contoh kapan Clone diwajibkan adalah pas kita lagi manggil method to_vec pada
sebuah slice. Si slice ini kan emang tidak ngantongin (doesn’t own) instances dari tipe
yang disimpennya, tapi vector yang dikembalikan dari panggilan to_vec itu jelas butuh
dan wajib punya hak milik (own) buat instances yang ada di dalemnya, makanya si to_vec
ini bakal manggil method clone buat setiap item yang ada. Dengan demikian, tipe yang
disimpan di dalam slice tersebut wajib mengimplementasikan Clone.
Trait Copy membiarkan kita buat menduplikasi sebuah nilai cuma dengan cara meng-copy bits
yang ada di dalam memori stack aja; jadinya tidak perlu ada pengeksekusian kode
tambahan apa-apa di sini. Lihat bagian “Stack-Only Data: Copy”
di Bab 4 buat informasi lebih jauh soal Copy.
Trait Copy ini sama sekali tidak mendefinisikan method apa pun karena tujuannya itu buat
mencegah (prevent) para programmer dari nge-overload method tersebut dan ngelanggar (violating)
asumsi mutlak bahwa tidak ada eksekusi kode acak apa pun yang berjalan selama proses duplikasi ini.
Dengan cara kayak gini, semua programmer bisa berasumsi dengan aman (assume) kalau aksi
meng-copy sebuah nilai yang punya trait ini bakal kerasa cepet sekali (very fast).
Kita bisa nge-derive Copy pada tipe apa pun yang mana semua elemen komponennya itu udah mengimplementasikan Copy. Tipe yang udah mengimplementasikan Copy juga wajib mutlak mengimplementasikan Clone, karena sebuah tipe yang mengimplementasikan Copy otomatis udah punya implementasi buat Clone yang sepele (trivial implementation) yang menunaikan tugas yang sama persis kayak Copy tersebut.
Trait Copy itu jarang sekali diwajibkan secara eksplisit; tapi tipe-tipe yang
mengimplementasikan Copy punya privilese ketersediaan buat dioptimasi (optimizations
available), yang artinya kita jadinya tidak perlu rajin-rajin ngetik manggil clone, yang mana
ngebikin kodenya jadi lebih padat (concise) dan ringkas.
Segala apa pun yang bisa dicapai (possible) pakai Copy tentu juga bisa kita capai (accomplish)
dengan memakai Clone, tapi ya kodenya itu mungkin bisa jadi agak lebih lelet (slower) atau
menuntut keharusan buat manggil clone di mana-mana (in places).
Hash Buat Memetakan Nilai ke Nilai Lain Berukuran Tetap (Fixed Size)
Trait Hash ngasih kita kapabilitas buat ngambil instance dari sebuah tipe dengan ukuran
yang sembarang (arbitrary size) lalu memetakan (map) instance tersebut menjadi sebuah nilai yang
punya ukuran tetap (fixed size) menggunakan sebuah fungsi hash. Nge-derive Hash bakal
mengimplementasikan method hash. Implementasi derived dari method hash ini bakal
ngegabungin (combines) seluruh hasil dari pemanggilan method hash ke setiap komponen (parts) dari
tipe tersebut, yang artinya bahwa semua fields atau nilai yang ada di dalem tipe ini wajib juga udah
mengimplementasikan Hash supaya si tipe utamanya ini bisa di-derive sama Hash.
Contoh dari kasus di mana Hash diwajibkan (required) adalah pas kita mau nyimpen
keys (kunci) di dalam koleksi HashMap<K, V> buat tujuan menyimpen data secara
lebih efisien (efficiently).
Default Buat Pembuatan Nilai Bawaan (Default Values)
Trait Default ngebolehin kita buat ngebikin nilai bawaan (default value) buat sebuah tipe.
Nge-derive Default bakal mengimplementasikan fungsi default. Implementasi turunan
(derived implementation) dari fungsi default ini bakal ngerjain tugasnya dengan cara
ikut-ikutan manggil fungsi default buat setiap komponen/elemen dari tipe tersebut, yang mana
tentu artinya semua fields atau bagian-bagian nilai di dalam tipe tersebut juga diwajibkan
(must also) buat udah mengimplementasikan Default biar tipe utamanya bisa nge-derive
trait Default.
Fungsi Default::default ini umumnya sering dipakai digabungin barengan sama sintaks pembaruan struct (struct update syntax) yang pernah kita obrolin di bagian “Ngebikin Instances dari Instances Lain dengan Struct Update Syntax” di Bab 5. Kita bisa mengkustomisasi beberapa fields tertentu aja dari sebuah struct dan sesudahnya itu mengatur (set) lalu memakai nilai default bawaannya buat ngisi sisa bidang-bidang (rest of the fields) yang belum diisi dengan cara memakai ..Default::default().
Trait Default diwajibkan saat kita memakai method unwrap_or_default pada instances dari
tipe Option<T>, contohnya. Kalau nilai Option<T>-nya ternyata adalah None, method
unwrap_or_default ini nantinya bakal nge-return (ngembaliin) hasil tebakan tebasan yang asalnya dari panggilan
Default::default buat si tipe T yang lagi disimpen di dalam Option<T> tersebut.
D - Alat Bantu Pengembangan yang Berguna
Lampiran D - Alat Bantu (Tools) Pengembangan yang Berguna
Di lampiran ini, kita bakal ngomongin soal beberapa alat bantu pengembangan yang berguna yang mana emang disediain sama project Rust ini. Kita bakal ngelihat alat pemformatan otomatis, cara-cara cepet buat nerapin perbaikan dari pesan peringatan, sebuah linter (pemeriksa kode), dan juga seputar cara integrasi dengan IDEs.
Pemformatan Otomatis dengan rustfmt
Alat rustfmt merombak dan memformat ulang (reformats) kode kita sedemikian
rupa sehingga mengikuti gaya kode standar dari komunitas. Banyak proyek
kolaboratif memakai rustfmt untuk membantu mencegah terjadinya perdebatan
seputar gaya penulisan kode mana yang seharusnya dipakai saat menulis kode Rust:
intinya, semua orang memformat kode mereka secara seragam memakai alat ini.
Instalasi Rust secara bawaan (default) sudah menyertakan rustfmt, jadi kita
seharusnya saat ini sudah punya program rustfmt dan cargo-fmt di sistem kita.
Dua perintah ini pada dasarnya serupa dengan rustc dan cargo di mana rustfmt
memberikan opsi pengaturan yang lebih mendetail dan cargo-fmt memahami konvensi
dari sebuah proyek yang memakai Cargo. Untuk memformat proyek Cargo apa pun,
silakan ketik perintah berikut:
$ cargo fmt
Menjalankan perintah ini otomatis bakal memformat ulang seantero kode Rust yang ada
di dalam crate saat ini. Perintah ini murni cuma bakal mengubah gaya kodenya saja,
bukan mengubah semantik dari kodenya. Buat dapat info lebih lanjut soal rustfmt,
silakan baca dokumentasinya di sini.
Perbaiki Kode kita dengan rustfix
Alat bantu rustfix sudah disertakan bareng instalasi Rust dan bisa secara otomatis membetulkan pesan peringatan compiler yang punya rute perbaikan yang jelas untuk masalah tersebut, yang kemungkinan besar merupakan apa yang kita inginkan. Kita kemungkinan besar sudah pernah melihat pesan peringatan dari compiler sebelumnya. Sebagai contoh, perhatikan kode berikut ini:
Nama File: src/main.rs
fn main() {
let mut x = 42;
println!("{x}");
}Di sini, kita mendefinisikan variabel x sebagai sesuatu yang bisa diubah (mutable),
tapi kita tidak pernah mengubahnya. Rust bakal otomatis memberi tahu kita pesan peringatan:
$ cargo build
Compiling myprogram v0.1.0 (file:///projects/myprogram)
warning: variable does not need to be mutable
--> src/main.rs:2:9
|
2 | let mut x = 0;
| ----^
| |
| help: remove this `mut`
|
= note: `#[warn(unused_mut)]` on by default
Pesan peringatan ini menyarankan supaya kita menyingkirkan keyword mut tersebut.
Kita bisa secara otomatis menerapkan saran tersebut menggunakan bantuan alat rustfix
dengan menjalankan perintah cargo fix:
$ cargo fix
Checking myprogram v0.1.0 (file:///projects/myprogram)
Fixing src/main.rs (1 fix)
Finished dev [unoptimized + debuginfo] target(s) in 0.59s
Saat kita melihat isi file src/main.rs lagi, kita bakal melihat kalau cargo fix
telah membetulkan kodenya:
Nama File: src/main.rs
fn main() {
let x = 42;
println!("{x}");
}Sekarang variabel x sudah tidak bisa diubah (immutable), dan pesan peringatan
itu sudah tidak muncul lagi.
Kita juga bisa memanfaatkan perintah cargo fix buat ngebantu mengurus masa transisi
kode kita di antara edisi-edisi (editions) Rust yang berbeda-beda. Perkara seputar
editions ini diulas di Lampiran E.
Lints (Peringatan Tambahan) yang Lebih Beragam Memakai Clippy
Alat Clippy adalah sebuah koleksi lints (aturan pemeriksa kode) yang bertugas menganalisis kode kita sehingga kita bisa menangkap kesalahan umum dan meningkatkan kualitas kode Rust kita. Clippy sudah disertakan di dalam standar instalasi Rust.
Buat menjalankan lints Clippy pada sembarang project Cargo, silakan ketik perintah berikut:
$ cargo clippy
Misalnya, katakanlah kita sedang menulis sebuah program yang memakai estimasi nilai aproksimasi buat sebuah konstanta matematika, seperti pi, seperti yang dilakukan program ini:
fn main() {
let x = 3.1415;
let r = 8.0;
println!("the area of the circle is {}", x * r * r);
}Menjalankan cargo clippy pada project ini bakal menghasilkan pesan error berikut:
error: approximate value of `f{32, 64}::consts::PI` found
--> src/main.rs:2:13
|
2 | let x = 3.1415;
| ^^^^^^
|
= note: `#[deny(clippy::approx_constant)]` on by default
= help: consider using the constant directly
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#approx_constant
Pesan error ini memberi tahu kita kalau Rust sudah punya konstanta PI yang jauh
lebih presisi, dan program kita bakal jadi lebih benar kalau kita memakai konstanta
tersebut. Jadinya kita bisa mengubah kode tersebut supaya memakai konstanta PI.
Kode berikut ini tidak bakal memicu munculnya error atau peringatan apa pun dari Clippy:
fn main() {
let x = std::f64::consts::PI;
let r = 8.0;
println!("the area of the circle is {}", x * r * r);
}Untuk informasi lebih rinci tentang Clippy, silakan tuju halaman dokumentasinya.
Integrasi IDE Memakai rust-analyzer
Untuk membantu masalah integrasi IDE, komunitas Rust merekomendasikan penggunaan
rust-analyzer. Alat ini adalah sekumpulan utilitas berbasis
compiler yang memakai protokol Language Server Protocol (LSP), yang mana
merupakan sebuah spesifikasi bagi IDE dan bahasa pemrograman supaya mereka bisa
berkomunikasi satu sama lain. Berbagai clients bisa memakai rust-analyzer, termasuk
di antaranya plug-in Rust analyzer untuk Visual Studio Code.
Silakan kunjungi home page dari project rust-analyzer untuk
mendapatkan petunjuk instalasinya, lalu pasang dukungan language server tersebut
ke dalam IDE spesifik kita. IDE kita bakal mendapatkan tambahan kapabilitas istimewa
seperti autocompletion (penyelesaian otomatis), jump to definition (loncat ke definisi),
dan inline errors (pesan error yang muncul sebaris dengan kode).
E - Edisi
Lampiran E - Edisi (Editions)
Di Bab 1, kita sudah melihat kalau perintah cargo new itu menambahkan sedikit
metadata ke dalam file Cargo.toml kita terkait sebuah edition (edisi). Lampiran
ini membahas tentang apa arti dari hal tersebut!
Bahasa pemrograman Rust dan compiler-nya punya siklus rilis yang bergulir tiap enam minggu, yang mana berarti para pengguna bakal mendapatkan serangkaian fitur baru secara konstan. Bahasa pemrograman lain biasanya merilis perubahan- perubahan besar dengan frekuensi yang lebih jarang; sedangkan Rust merilis pembaruan-pembaruan kecil lebih sering. Setelah sekian lama, semua perubahan kecil ini pada akhirnya bakal menumpuk. Tapi kalau dilihat dari satu rilis ke rilis yang lain, kadang bisa jadi susah buat menengok ke belakang dan bilang, “Wow, di antara Rust 1.10 dan Rust 1.31, Rust ternyata udah berubah sangat banyak!”
Setiap tiga tahun sekali, tim Rust memproduksi sebuah edition (edisi) baru buat Rust. Setiap edisi merangkul semua fitur yang sudah berhasil mendarat menjadi sebuah paket yang jelas beserta kelengkapan dokumentasi dan peralatan (tooling) yang sudah dimutakhirkan. Edisi-edisi baru ini dikirim sebagai bagian dari rute proses rilis reguler enam mingguan.
Edisi-edisi ini memiliki tujuan yang berbeda-beda bagi kelompok orang yang berbeda:
- Buat para pengguna aktif Rust, sebuah edisi baru menggabungkan perubahan-perubahan tambahan tersebut menjadi sebuah paket yang mudah dipahami.
- Buat orang-orang yang belum memakai Rust, sebuah edisi baru menjadi sinyal kalau ada beberapa kemajuan besar yang sudah terealisasi, yang mana barangkali bakal bikin Rust jadi layak buat dilirik lagi.
- Buat para pengembang yang ikut mengerjakan bahasa Rust, sebuah edisi baru menyediakan sebuah titik kumpul (rallying point) yang memacu semangat proyek ini secara keseluruhan.
Saat buku ini sedang ditulis, ada empat edisi Rust yang tersedia: Rust 2015, Rust 2018, Rust 2021, dan Rust 2024. Buku ini sendiri sepenuhnya ditulis memakai pola dan gaya bahasa (idioms) dari edisi Rust 2024.
Kunci edition yang ada di dalam Cargo.toml menandakan edisi mana yang seharusnya
dipakai sama si compiler untuk kode kita. Kalau kuncinya tidak ada, Rust otomatis
bakal memakai 2015 sebagai nilai edisinya demi alasan kompabilitas ke belakang
(backward compatibility).
Setiap project berhak memilih untuk masuk (opt in) ke sebuah edisi lain selain edisi bawaan 2015. Edisi bisa saja mengandung perubahan-perubahan yang tidak kompatibel (incompatible changes), seperti memasukkan kata kunci (keyword) baru yang mana mungkin berkonflik dengan nama-nama identifiers yang ada di dalam kode. Namun, terkecuali kita secara sadar setuju masuk (opt in) ke perubahan-perubahan tersebut, kode kita bakal dijamin terus bisa di-compile dengan mulus sekalipun kita meng-upgrade versi dari compiler Rust yang kita pakai.
Semua versi compiler Rust menyokong edisi apa pun yang memang udah eksis sebelum versi compiler tersebut dirilis, dan mereka juga sanggup menautkan (link) crates dari sembarang edisi yang disokong untuk jalan bersama-sama. Perubahan edisi itu cuma berdampak pada cara sang compiler mengurai (parses) kode kita pada awalnya. Oleh karena itu, kalau kita lagi memakai Rust 2015 dan salah satu dependency (dependensi) kita memakai Rust 2018, project kita dijamin bakal tetap bisa sukses di-compile dan bisa memakai dependensi tersebut. Dari sisi sebaliknya pun begitu.
Biar lebih jelas: sebagian besar fitur itu bakal tetap tersedia di semua edisi. Para pengembang yang memakai edisi Rust yang mana pun bakal terus bisa melihat adanya perbaikan seiringan dengan dibuatnya rilis-rilis versi stabil yang baru. Namun, di dalam beberapa kasus tertentu, utamanya pas lagi ada keywords baru yang ditambahkan, beberapa fitur baru itu barangkali cuma bakal tersedia di edisi- edisi yang dirilis belakangan. Kita harus berpindah (switch) edisi kalau kita pengen bisa memanfaatkan fitur-fitur semacam itu.
Untuk detail lebih lanjut, buku The Rust Edition Guide
adalah buku komplit seputar edisi yang memaparkan semua perbedaan di antara
tiap-tiap edisi dan menjelaskan gimana caranya meng-upgrade kode kita secara
otomatis ke edisi baru melalui perintah cargo fix.
F - Terjemahan-terjemahan Buku Ini
Lampiran F: Terjemahan-terjemahan Buku Ini
Buat mencari sumber bacaan (resources) dalam bahasa selain bahasa Inggris. Sebagian besar di antaranya masih dalam taraf pengerjaan; silakan cek label Translations andaikata kita ingin membantu atau ingin memberi tahu kami tentang adanya proyek terjemahan baru!
- Português (BR)
- Português (PT)
- 简体中文: KaiserY/trpl-zh-cn, gnu4cn/rust-lang-Zh_CN
- 正體中文
- Українська
- Español, alternate, Español por RustLangES
- Русский
- 한국어
- 日本語
- Français
- Polski
- Cebuano
- Tagalog
- Esperanto
- ελληνική
- Svenska
- Farsi, Persian (FA)
- Deutsch
- हिंदी
- ไทย
- Danske
- O’zbek
- Tiếng Việt
- Italiano
- বাংলা
G - Gimana Rust Dibuat dan “Nightly Rust”
Lampiran G - Bagaimana Rust Dibuat dan “Nightly Rust”
Lampiran ini membahas bagaimana Rust dibuat dan pengaruhnya bagi kita sebagai pengembang Rust.
Kestabilan Tanpa Kemandekan
Sebagai sebuah bahasa, Rust sangat peduli pada kestabilan kode kita. Kami ingin Rust menjadi fondasi kokoh untuk membangun program. Jika segalanya terus berubah, hal itu mustahil dilakukan. Di sisi lain, tanpa eksperimen fitur baru, kita tidak akan menemukan kekurangan sebelum fitur dirilis dan tidak bisa diubah lagi.
Solusi kami adalah “kestabilan tanpa kemandekan”. Prinsipnya: kita tidak perlu takut melakukan upgrade ke versi stabil Rust yang baru. Setiap upgrade harusnya mudah, membawa fitur baru, lebih sedikit bug, dan kompilasi lebih cepat.
Saluran Rilis dan Model Kereta
Pengembangan Rust beroperasi dengan jadwal kereta. Semua pengembangan dilakukan di branch master. Rilis mengikuti model kereta rilis perangkat lunak. Ada tiga saluran rilis Rust:
- Nightly
- Beta
- Stable
Kebanyakan pengembang menggunakan saluran stable. Mereka yang ingin mencoba fitur eksperimental bisa menggunakan nightly atau beta.
Setiap enam minggu, rilis baru disiapkan. Branch beta memisahkan diri dari branch master. Jika ditemukan masalah di beta, perbaikan diterapkan di master (nightly) lalu di-backport ke beta. Setelah enam minggu, beta menjadi stable yang baru, dan prosesnya berulang untuk versi berikutnya.
Proses ini memastikan rilis baru selalu bisa diuji terlebih dahulu di saluran beta sebelum menjadi stabil.
Waktu Pemeliharaan
Proyek Rust mendukung versi stabil terbaru. Saat versi baru dirilis, versi lama mencapai akhir masa pakainya (EOL). Setiap versi didukung selama enam minggu.
Fitur Tidak Stabil
Rust menggunakan “feature flags” untuk fitur yang masih dikembangkan. Fitur ini ada di branch master dan nightly di balik flag tersebut. Kita bisa mencobanya dengan menggunakan Rust nightly dan mengaktifkan flag-nya di kode kita.
Fitur semacam ini tidak bisa digunakan di versi beta atau stable. Ini memungkinkan kami menguji fitur baru secara praktis sebelum dinyatakan stabil selamanya. Buku ini hanya membahas fitur stabil.
Rustup dan Peran Rust Nightly
Rustup memudahkan kita berganti antar saluran rilis. Secara default kita menggunakan stable. Untuk menginstal nightly:
$ rustup toolchain install nightly
kita bisa melihat daftar toolchain dengan rustup toolchain list. Kita juga bisa mengatur toolchain tertentu untuk proyek tertentu menggunakan rustup override set nightly di direktori proyek tersebut.
Proses RFC dan Tim
Fitur baru diawali dengan proses Request For Comments (RFC). Siapa pun bisa menulis proposal RFC untuk meningkatkan Rust. Proposal tersebut akan diulas dan didiskusikan oleh tim Rust.
Jika disetujui, issue baru dibuka dan fitur tersebut diimplementasikan. Setelah implementasi siap, fitur tersebut masuk ke branch master di balik feature gate. Setelah diuji oleh pengguna nightly, tim akan memutuskan apakah fitur tersebut layak masuk ke versi stabil atau tidak. Jika ya, feature gate dihapus dan fitur tersebut menjadi stabil.